
Seeing the Unseen: Real-Time Micro-Expression Recognition with Action Units and GPT-Based Reasoning




Abstract
Featured Application
Abstract
1. Introduction
2. Related Work
2.1. Foundations of Micro-Expression Research
2.2. Traditional Computational Approaches
2.3. Deep Learning and Spatiotemporal Modeling
2.4. Language Models in Emotion Recognition
2.5. The Role of CASME II and Dataset-Centric Advances
2.6. Challenges and Gaps in Existing Research
- Lack of robustness in real-world conditions—most models are sensitive to variations in lighting, occlusion, and camera angles;
- Dataset scarcity and class imbalance—the small size and uneven emotion distribution in datasets like CASME II reduce generalization;
- Emotion confusion—visual overlap between pairs like fear and surprise or disgust and sadness lead to misclassification;
- Cultural and individual variation—facial expression interpretation varies significantly across individuals and social contexts;

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Achievements |
|---|---|
| Enhancement of micro-expression recognition through a lightweight MFE-Net using multi-scale features and attention [29]. | Demonstrated effectiveness of MFE-Net on CASME II and MEGC2019 datasets, improving feature extraction. |
| Integration of GANs with CNNs to enhance micro-expression dataset diversity and classification accuracy [32]. | Outperformed existing CNN models with augmented dataset from CASME II, improving classification accuracy. |
| Development of a multimodal large language model for facial expression and attribute understanding [33]. | Face-LLaVA outperformed existing models on multiple datasets, enhancing performance in facial processing tasks. |
| Improvement of multi-class facial emotion identification using deep learning techniques [34]. | Achieved high accuracy, showing effectiveness of the combined use of EfficientNetB0 and WKELM. |
| Utilization of advanced deep learning techniques for emotion recognition from visual and textual data [30]. | Demonstrated the ability to recognize seven primary human emotions effectively. |
| A systematic review on emotion detection methodologies utilizing deep learning and computer vision [35]. | Identified trends in models used for emotion detection, emphasizing CNNs and their effectiveness. |
| Proposal of a two-level feature fused two-stream network for improved micro-expression recognition [31]. | Achieved UAR exceeding 0.905 on CASME II and significant improvements on other datasets. |
| Development of a method for magnifying subtle facial movements for better detection of micro-expressions [36]. | Introduced a technique that successfully enhanced the detection of micro-expressions in facial videos. |
| Review of advances in facial emotion recognition using neural network models [37]. | Highlighted the dominance of CNN architectures in facial emotion recognition tasks with ongoing challenges. |
| Evaluation of ChatGPT applications in psychiatry and potential for emotion recognition [38]. | Identified the potential for ChatGPT to enhance psychiatric care through emotion detection and automated systems. |
| Development of a real-time approach for sign language recognition using pose estimation [39]. | Demonstrated effectiveness in recognizing signs with the aid of facial and body movements. |
| Emotion detection in Hindi–English code-mixed text using deep learning [40]. | Achieved 83.21% classification accuracy in detecting emotions in social media texts. |
| Review of multimodal data integration in oncology using deep neural networks [41]. | Emphasized the importance of GNNs and Transformers for improving cancer diagnosis and treatment. |
- MediaPipe-based facial landmark tracking for efficient AU detection;
- Expert rule systems grounded in FACS to resolve ambiguous emotion pairs;
- LLM-based classification for robust and context-aware interpretation;
- Weak signal amplification to enhance detection of low-intensity expressions;
- Real-time capabilities validated on CASME II under practical constraints.
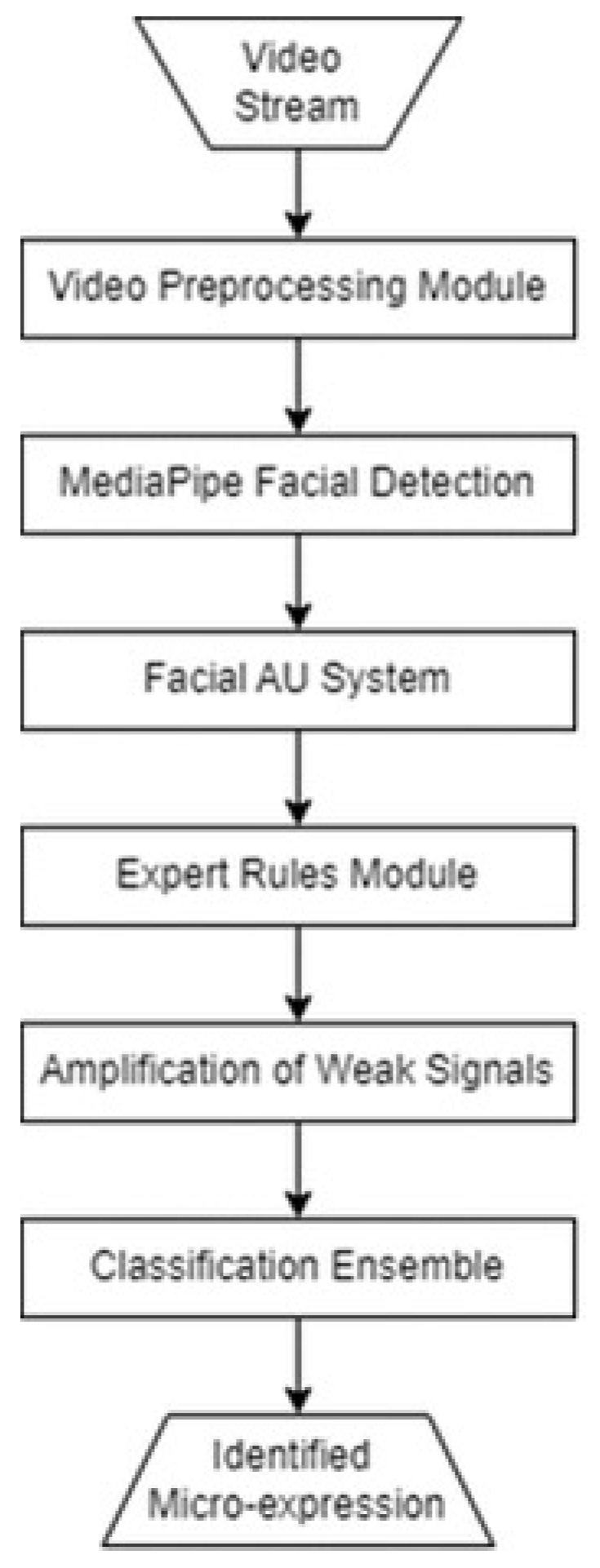
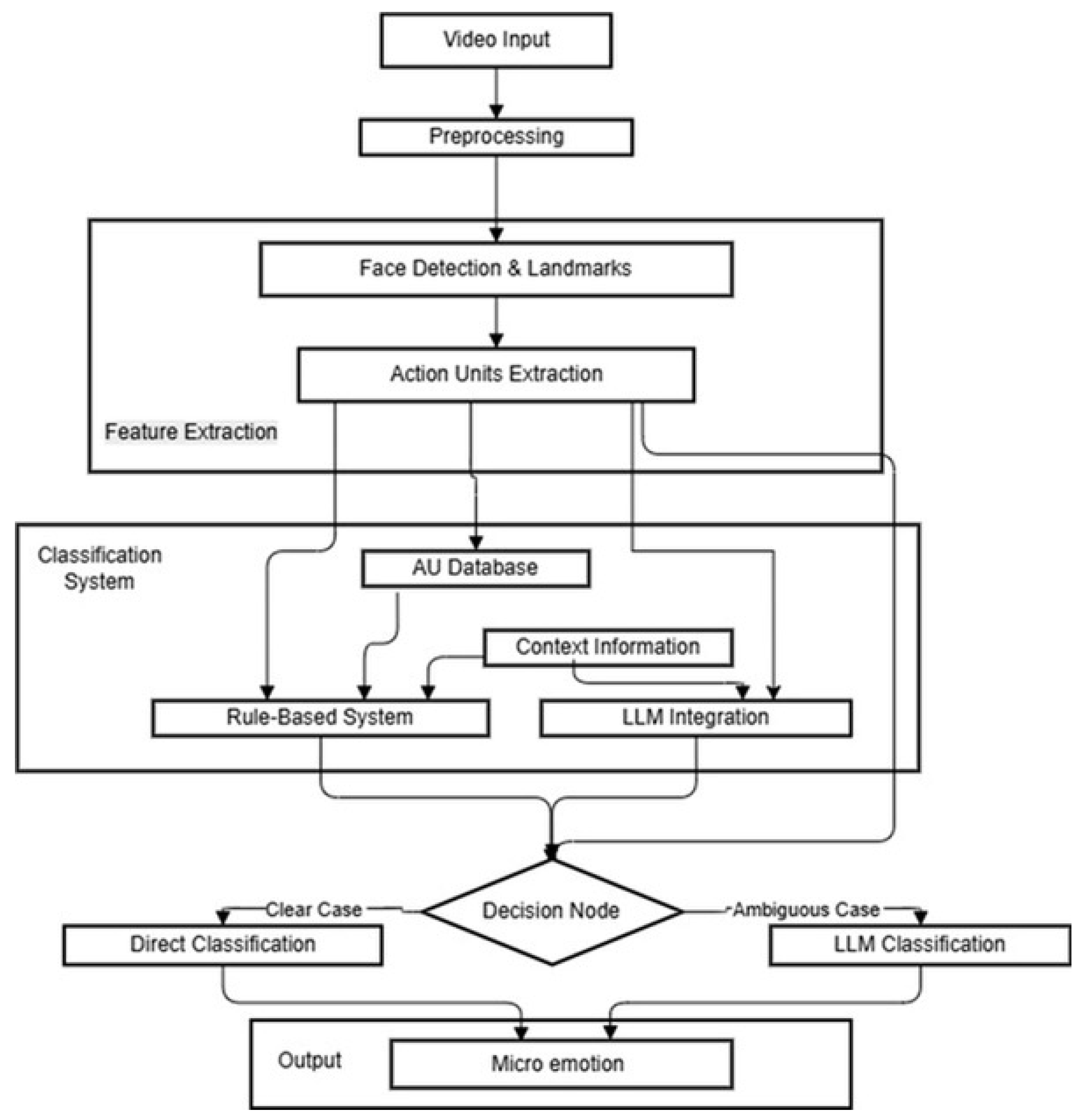
3. Materials and Methods
3.1. Materials
- Limited dataset: with only 247 examples and an unbalanced distribution, deep learning models cannot efficiently generalize;
- AU specificity: psychological research has established clear correspondences between certain AUs and specific emotions;
- Need for interpretability: in critical applications, it is essential to be able to explain why the system classified a particular expression.
Amplification of Weak Signals
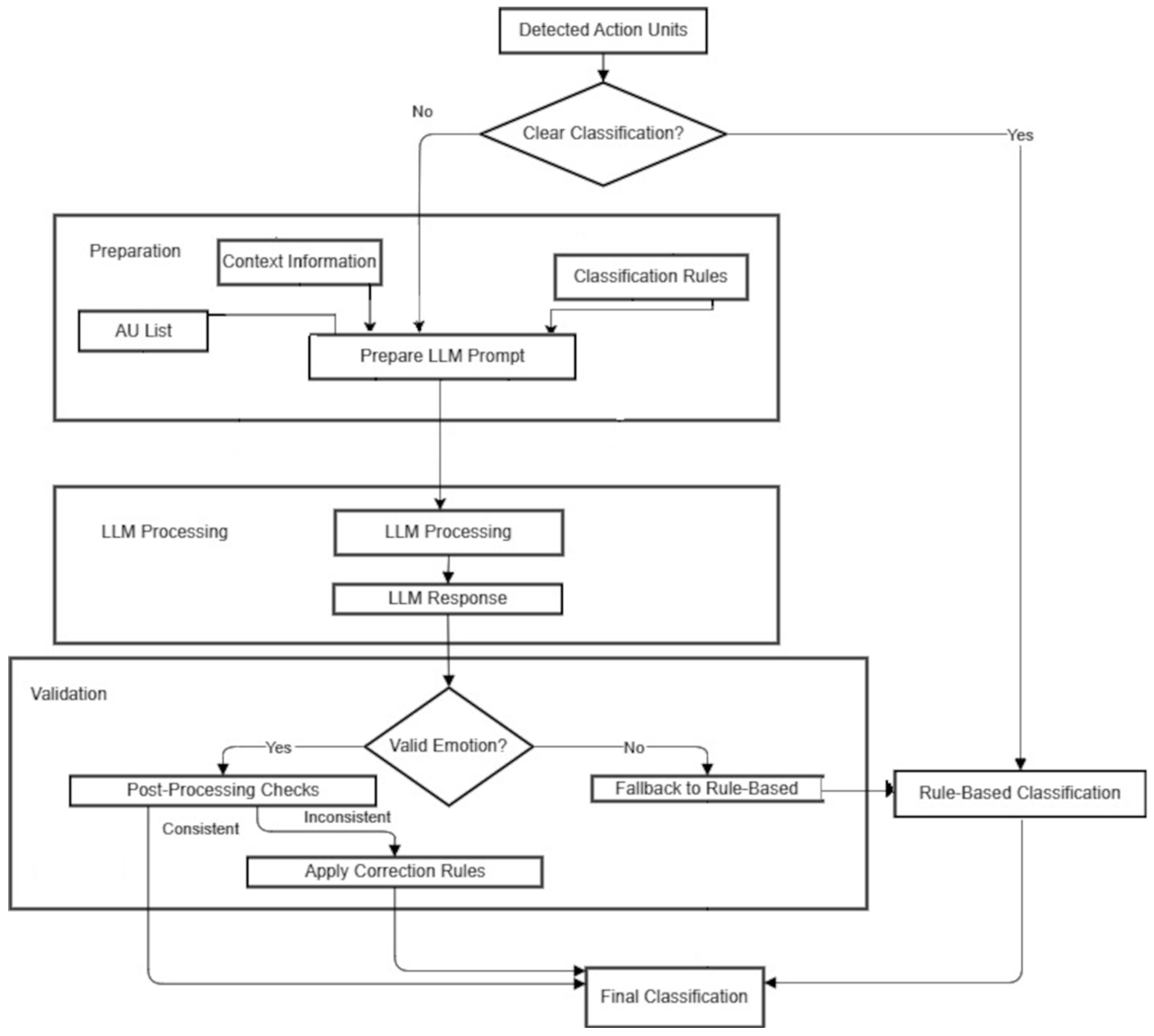
- Rule-based classification—direct application of expert rules for clear cases;
- Prototype similarity—comparing detected AU configurations with known patterns for each emotion;
- Contextual analysis—considering subject-specific characteristics;
- Language model assistance—using OpenAI for difficult cases.
3.2. Experiment
4. Results
4.1. Performance Metrics
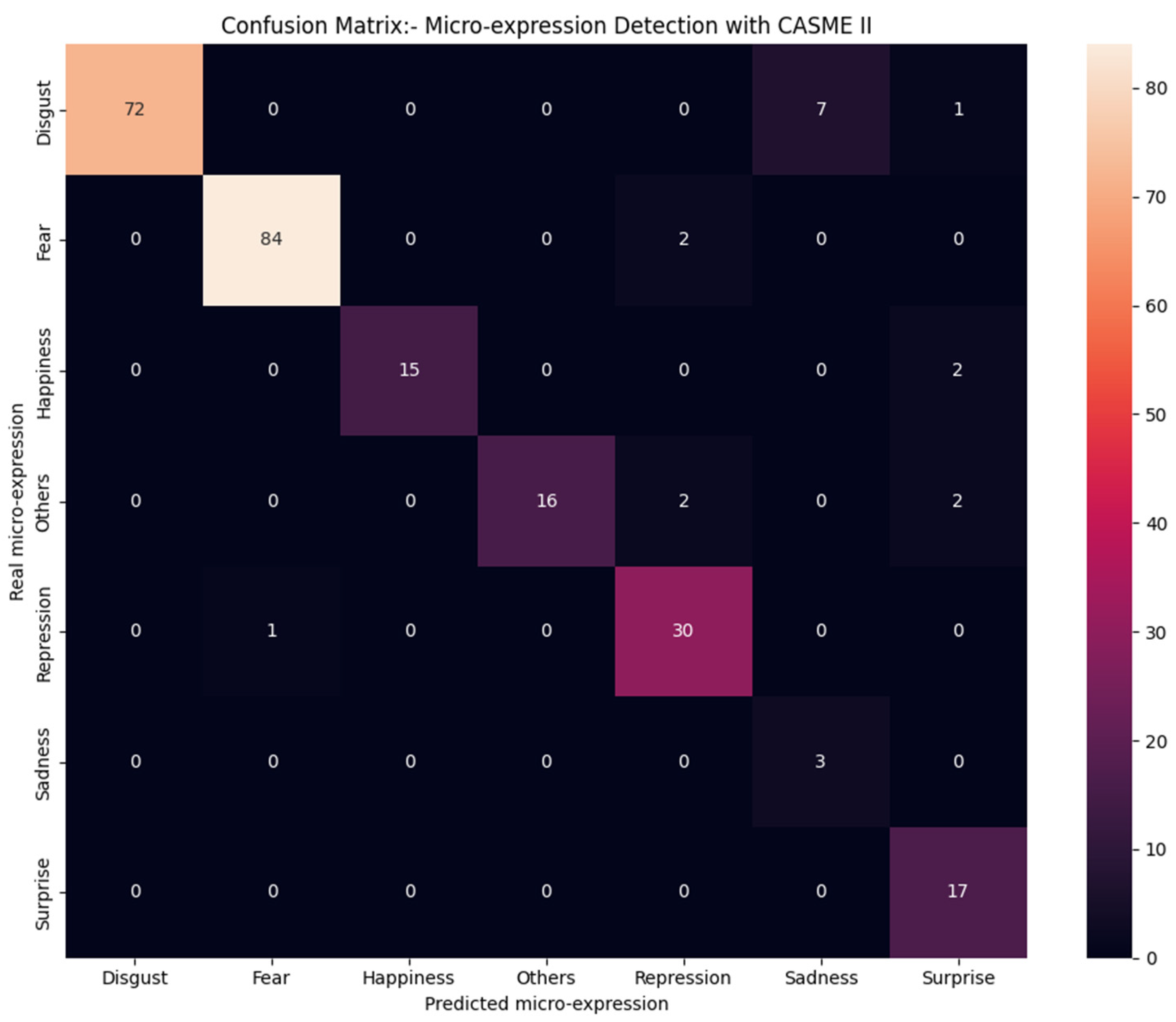
4.2. Confusion Matrix Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ekman, P.; Friesen, W.V. The Repertoire of Nonverbal Behavior: Categories, Origins, Usage, and Coding. Semiotica 1969, 1, 49–98. [Google Scholar] [CrossRef]
- Yan, W.J.; Wu, Q.; Liang, J.; Chen, Y.H.; Fu, X. How Fast are the Leaked Facial Expressions: The Duration of Micro-Expressions. J. Nonverbal Behav. 2013, 37, 217–230. [Google Scholar] [CrossRef]
- Frank, M.G.; Svetieva, E. Microexpressions and Deception. In Understanding Facial Expressions in Communication; Springer: Dordrecht, The Netherlands, 2014; pp. 227–242. [Google Scholar] [CrossRef]
- Yan, W.J.; Li, X.; Wang, S.J.; Zhao, G.; Liu, Y.J.; Chen, Y.H.; Fu, X. CASME II: An Improved Spontaneous Micro-Expression Database and the Baseline Evaluation. PLoS ONE 2014, 9, e86041. [Google Scholar] [CrossRef] [PubMed]
- Haggard, E.A.; Isaacs, K.S. Micromomentary Facial Expressions as Indicators of Ego Mechanisms in Psychotherapy. In Methods of Research in Psychotherapy; Springer: Boston, MA, USA, 1966. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Facial Action Coding System; Consulting Psychologists Press: Palo Alto, CA, USA, 1978. [Google Scholar] [CrossRef]
- Cohn, J.F.; Ambadar, Z.; Ekman, P. Observer-Based Measurement of Facial Expression with the Facial Action Coding System. In Handbook of Emotion Elicitation and Assessment; Coan, J.A., Allen, J.J.B., Eds.; Oxford University Press: New York, NY, USA, 2007; pp. 203–221. Available online: https://psycnet.apa.org/record/2007-08864-013 (accessed on 20 February 2025).
- Shreve, M.; Godavarthy, S.; Manohar, V.; Goldgof, D.; Sarkar, S. Towards Macro- and Micro-Expression Spotting in Video Using Strain Patterns. In Proceedings of the 2009 Workshop on Applications of Computer Vision (WACV), Snowbird, UT, USA, 7–8 December 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Pfister, T.; Li, X.; Zhao, G.; Pietikäinen, M. Recognising Spontaneous Facial Micro-Expressions. In Proceedings of the 2011 International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 1449–1456. [Google Scholar] [CrossRef]
- Wang, Y.; See, J.; Phan, R.C.W.; Oh, Y.H. LBP with Six Intersection Points: Reducing Redundant Information in LBP-TOP for Micro-Expression Recognition. In Computer Vision—ACCV 2014; Cremers, D., Reid, I., Saito, H., Yang, M.H., Eds.; Springer: Cham, Switzerland, 2015; Volume 9003, pp. 525–537. [Google Scholar] [CrossRef]
- Huang, X.; Zhao, G.; Hong, X.; Zheng, W.; Pietikäinen, M. Spontaneous Facial Micro-Expression Analysis Using Spatiotemporal Completed Local Quantized Patterns. Neurocomputing 2016, 175, 564–578. [Google Scholar] [CrossRef]
- Yang, H.; Huang, S.; Li, M. MSOF: A main and secondary bi-directional optical flow feature method for spotting micro-expression. Neurocomputing 2025, 630, 129676. [Google Scholar] [CrossRef]
- Yang, X.; Yang, H.; Li, J.; Wang, S. Simple but effective in-the-wild micro-expression spotting based on head pose segmentation. In Proceedings of the 3rd Workshop on Facial Micro-Expression: Advanced Techniques for Multi-Modal Facial Expression Analysis, Ottawa, ON, Canada, 29 October 2023; pp. 9–16. [Google Scholar] [CrossRef]
- Patel, D.; Hong, X.; Zhao, G. Selective Deep Features for Micro-Expression Recognition. In Proceedings of the 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2258–2263. [Google Scholar] [CrossRef]
- Zhang, H.; Huang, B.; Tian, G. Facial Expression Recognition Based on Deep Convolution Long Short-Term Memory Networks of Double-Channel Weighted Mixture. Pattern Recognit. Lett. 2020, 131, 128–134. [Google Scholar] [CrossRef]
- Sălăgean, G.L.; Leba, M.; Ionica, A.C. Leveraging Symmetry and Addressing Asymmetry Challenges for Improved Convolutional Neural Network-Based Facial Emotion Recognition. Symmetry 2025, 17, 397. [Google Scholar] [CrossRef]
- Lei, L.; Li, J.; Chen, T.; Li, S. A Novel Graph-TCN with a Graph Structured Representation for Micro-Expression Recognition. In Proceedings of the 28th ACM International Conference on Multimedia (MM ‘20), Seattle, WA, USA, 12–16 October 2020; pp. 2237–2245. [Google Scholar] [CrossRef]
- Kumar, A.J.R.; Bhanu, B. Micro-Expression Classification Based on Landmark Relations with Graph Attention Convolutional Network. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 1511–1520. [Google Scholar] [CrossRef]
- Phan, H.T.; Nguyen, N.T.; Hwang, D. Aspect-level sentiment analysis: A survey of graph convolutional network methods. Inf. Fusion 2023, 91, 149–172. [Google Scholar] [CrossRef]
- Shehu, H.A.; Browne, W.N.; Eisenbarth, H. Emotion categorization from facial expressions: A review of datasets, methods, and research directions. Neurocomputing 2025, 624, 129367. [Google Scholar] [CrossRef]
- Ma, F.; Sun, B.; Li, S. Transformer-Augmented Network with Online Label Correction for Facial Expression Recognition. IEEE Trans. Affect. Comput. 2024, 15, 593–605. [Google Scholar] [CrossRef]
- Zhao, Z.; Patras, I. Prompting Visual-Language Models for Dynamic Facial Expression Recognition. arXiv 2024, arXiv:2308.13382. [Google Scholar]
- Nguyen, X.-B.; Duong, C.N.; Li, X.; Gauch, S.; Seo, H.-S.; Luu, K. Micron-BERT: BERT-Based Facial Micro-Expression Recognition. arXiv 2023, arXiv:2304.03195. [Google Scholar]
- Lian, Z.; Sun, L.; Sun, H.; Chen, K.; Wen, Z.; Gu, H.; Liu, B.; Tao, J. GPT-4V with Emotion: A Zero-shot Benchmark for Generalized Emotion Recognition. arXiv 2024, arXiv:2312.04293. [Google Scholar] [CrossRef]
- Zhang, L.; Luo, Z.; Wu, S.; Nakashima, Y. MicroEmo: Time-Sensitive Multimodal Emotion Recognition with Subtle Clue Dynamics in Video Dialogues. In Proceedings of the 2nd International Workshop on Multimodal and Responsible Affective Computing (MRAC ‘24). Association for Computing Machinery, Melbourne, VIC, Australia, 28 October 2024–1 November 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 110–115. [Google Scholar] [CrossRef]
- Zhao, Z.; Cao, Y.; Gong, S.; Patras, I. Enhancing Zero-Shot Facial Expression Recognition by LLM Knowledge Transfer. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Tucson, AZ, USA, 28 February–4 March 2025; pp. 815–824. [Google Scholar] [CrossRef]
- Lan, X.; Xue, J.; Qi, J.; Jiang, D.; Lu, K.; Chua, T.S. ExpLLM: Towards Chain of Thought for Facial Expression Recognition. arXiv 2024, arXiv:2409.02828. [Google Scholar] [CrossRef]
- Talib, H.K.B.; Xu, K.; Cao, Y.; Xu, Y.P.; Xu, Z.; Zaman, M.; Akhunzada, A. Micro-Expression Recognition Using Convolutional Variational Attention Transformer (ConVAT) with Multihead Attention Mechanism. IEEE Access 2025, 13, 20054–20070. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Q.; Shu, X. Micro-Expression Recognition Using a Multi-Scale Feature Extraction Network with Attention Mechanisms. Signal Image Video Process. 2024, 18, 5137–5147. [Google Scholar] [CrossRef]
- Gupta, D.K.; Agarwal, D.; Perwej, Y.; Vishwakarma, O.; Mishra, P.; Nitya. Sensing Human Emotion Using Emerging Machine Learning Techniques. Int. J. Sci. Res. Sci. Eng. Technol. 2024, 11, 80–91. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, M.; Jiao, Q.; Xu, L.; Han, B.; Li, Y.; Tan, X. Two-Level Spatio-Temporal Feature Fused Two-Stream Network for Micro-Expression Recognition. Sensors 2024, 24, 1574. [Google Scholar] [CrossRef] [PubMed]
- Naidana, K.S.; Divvela, L.P.; Yarra, Y. Micro-Expression Recognition Using Generative Adversarial Network-Based Convolutional Neural Network. In Proceedings of the 2024 4th International Conference on Pervasive Computing and Social Networking (ICPCSN), Salem, India, 7–8 March 2024. [Google Scholar] [CrossRef]
- Chaubey, A.; Guan, X.; Soleymani, M. Face-LLaVA: Facial Expression and Attribute Understanding through Instruction Tuning. arXiv 2025, arXiv:2504.07198. [Google Scholar]
- Anand, M.; Babu, S. Multi-Class Facial Emotion Expression Identification Using DL-Based Feature Extraction with Classification Models. Int. J. Comput. Intell. Syst. 2024, 17, 25. [Google Scholar] [CrossRef]
- Pereira, R.; Mendes, C.; Ribeiro, J.; Ribeiro, R.; Miragaia, R.; Rodrigues, N.M.M.; Costa, N.M.; Costa, N.; Pereira, A. Systematic Review of Emotion Detection with Computer Vision and Deep Learning. Sensors 2024, 24, 3484. [Google Scholar] [CrossRef] [PubMed]
- Flotho, P.; Heiß, C.; Steidl, G.; Strauß, D.J. Lagrangian Motion Magnification with Double Sparse Optical Flow Decomposition. Front. Appl. Math. Stat. 2023, 9, 1164491. [Google Scholar] [CrossRef]
- Cîrneanu, A.-L.; Popescu, D.; Iordache, D.D. New Trends in Emotion Recognition Using Image Analysis by Neural Networks: A Systematic Review. Sensors 2023, 23, 7092. [Google Scholar] [CrossRef] [PubMed]
- Cheng, S.-W.; Chang, C.-W.; Chang, W.-J.; Wang, H.; Liang, C.-S.; Kishimoto, T.; Chang, J.P.-C.; Kuo, J.S.; Su, K. The Now and Future of ChatGPT and GPT in Psychiatry. Psychiatry Clin. Neurosci. 2023, 77, 592–596. [Google Scholar] [CrossRef]
- Amrutha, K.; Prabu, P.; Paulose, J. Human Body Pose Estimation and Applications. In Proceedings of the Innovations in Power and Advanced Computing Technologies (i-PACT), Kuala Lumpur, Malaysia, 27–29 November 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Sasidhar, T.T.; Premjith, B.; Soman, K.P. Emotion Detection in Hinglish (Hindi+English) Code-Mixed Social Media Text. Procedia Comput. Sci. 2020, 171, 1346–1352. [Google Scholar] [CrossRef]
- Waqas, A.; Tripathi, A.; Ramachandran, R.P.; Stewart, P.A.; Rasool, G. Multimodal Data Integration for Oncology in the Era of Deep Neural Networks: A Review. Front. Artif. Intell. 2024, 7, 1408843. [Google Scholar] [CrossRef]
- iMotions. Learning the Facial Action Coding System (FACS). Available online: https://imotions.com/blog/learning/research-fundamentals/facial-action-coding-system/ (accessed on 12 December 2024).
- Matsumoto, D.; Hwang, H.S. Evidence for Training the Ability to Read Microexpressions of Emotion. Motiv. Emot. 2011, 35, 181–191. [Google Scholar] [CrossRef]
- Davison, A.K.; Lansley, C.; Costen, N.P.; Tan, K.; Yap, M.H. SAMM: A Spontaneous Micro-Facial Movement Dataset. IEEE Trans. Affect. Comput. 2018, 9, 116–129. [Google Scholar] [CrossRef]
- Talluri, K.K.; Fiedler, M.-A.; Al-Hamadi, A. Deep 3D Convolutional Neural Network for Facial Micro-Expression Analysis from Video Images. Appl. Sci. 2022, 12, 11078. [Google Scholar] [CrossRef]
- Belaiche, R.; Liu, Y.; Migniot, C.; Ginhac, D.; Yang, F. Cost-Effective CNNs for Real-Time Micro-Expression Recognition. Appl. Sci. 2020, 10, 4959. [Google Scholar] [CrossRef]
- Hong, J.; Lee, C.; Jung, H. Late Fusion-Based Video Transformer for Facial Micro-Expression Recognition. Appl. Sci. 2022, 12, 1169. [Google Scholar] [CrossRef]
- Li, J.; Wang, T.; Wang, S.-J. Facial Micro-Expression Recognition Based on Deep Local-Holistic Network. Appl. Sci. 2022, 12, 4643. [Google Scholar] [CrossRef]


| Action Unit | Description |
|---|---|
| AU1 | “browInnerUp”, “browInnerUpLeft”,”browInnerUpRight”, “browInnerRaiser” |
| AU2 | “browOuterUpLeft”, “browOuterUpRight” |
| AU4 | “browDown”, “browDownLeft”, “browDownRight”, “browLowerer”, “browFurrower” |
| AU5 | “eyeLookUpLeft”, “eyeLookUpLeft”, “eyeLookUpLeft”, “eyeLookUpRight”, “eyeWideLeft”, “eyeWideRight”, “upperLidRaiser” |
| AU6 | “cheekSquintLeft”, “cheekSquintRight”, “cheekRaiser” |
| AU7 (Crucial for Repression) | “lidTightener”, “eyeSquintLeft”, “eyeSquintRight” |
| AU9 (Crucial for Disgust) | “noseSneerLeft”, “noseSneerRight”, “noseWrinkler” |
| AU10 | “mouthUpperUpLeft”, “mouthUpperUpRight”, “upperLipRaiser” |
| AU12 (Crucial for Happiness) | “lipCornerPuller”, “lipCornerPullerLeft”, “lipCornerPullerRight”, “mouthSmileLeft”, “mouthSmileRight” |
| AU14 | “mouthDimpleLeft”, “mouthDimpleRight” |
| AU15 (Crucial for Sadness) | “lipCornerDepressor”, “lipCornerDepressorLeft”, “lipCornerDepressorRight”, “mouthFrownLeft”, “mouthFrownRight” |
| AU16 | “mouthLowerDownLeft”, “mouthLowerDownRight” |
| AU17 | “chinRaiser” |
| AU20 (Crucial for Fear) | “mouthStretchLeft”, “mouthStretchRight”, “lipStretcher” |
| AU23 | “lipsTogether” |
| AU24 | “lipPressLeft”, “lipPressRight” |
| AU25 | “lipsPart” |
| AU26 | “jawOpen”, “mouthOpen” |
| AU45 | ”eyeBlinkLeft”, “eyeBlinkRight” |
| AU29 | “jawForward” |
| AU28 | “jawLeft”, “jawRight” |
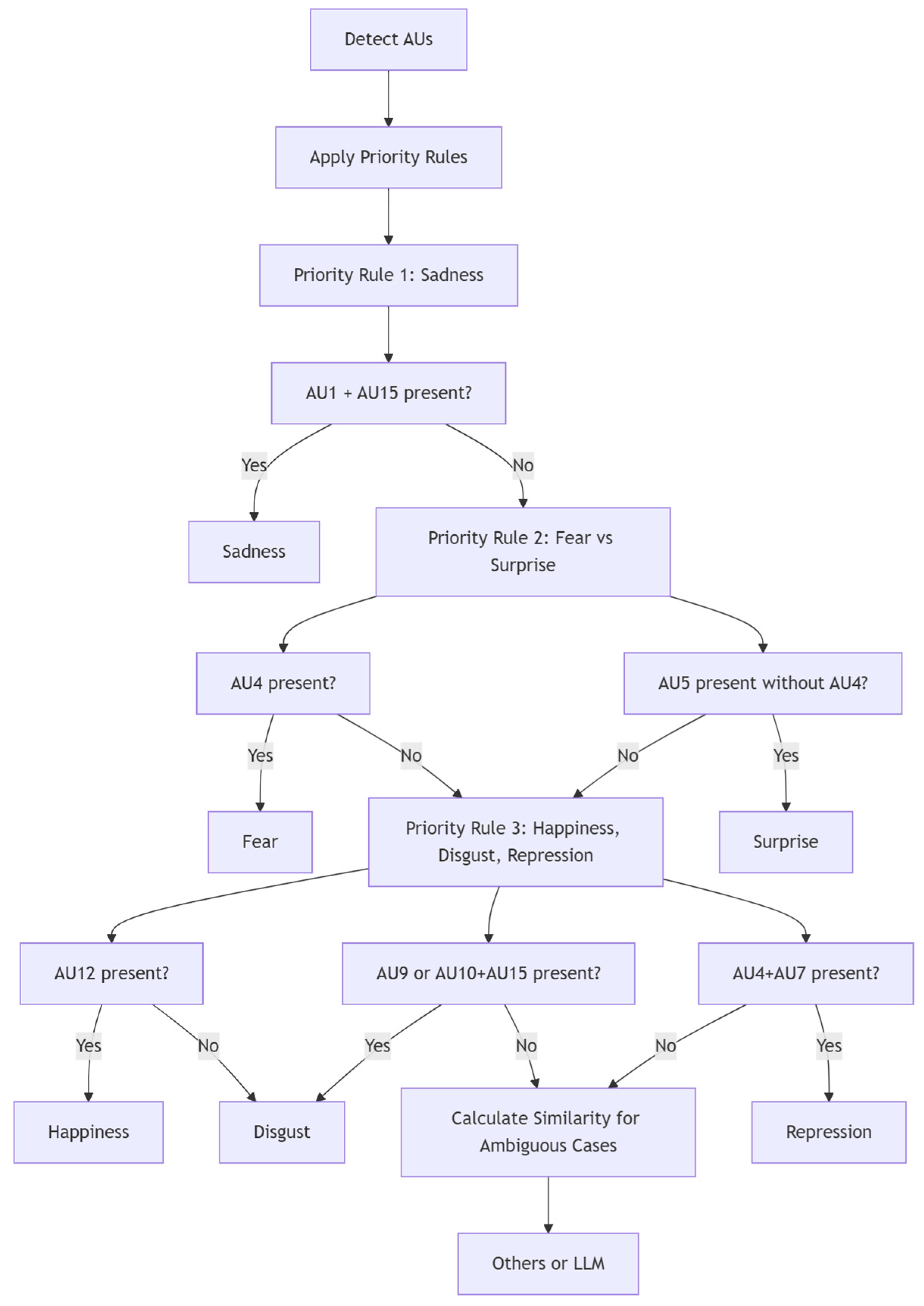
| Emotion | AU |
|---|---|
| Happiness | AU12, AU6 |
| Disgust | AU9, AU10, AU15 |
| Repression | AU4, AU7, AU23 |
| Fear | AU1, AU2, AU4, AU20 |
| Surprise | AU1, AU2, AU5, AU26 |
| Sadness | AU1, AU15, AU17 |
| Contempt | AU14, AU24 |
| Anger | AU 4, AU5, AU7, AU23 |
| Micro-Expression | Precision | Recall | F1-Score | Support Image Number |
|---|---|---|---|---|
| Disgust | 1.00 | 0.86 | 0.93 | 80 |
| Fear | 0.99 | 1.00 | 0.99 | 86 |
| Happiness | 1.00 | 0.94 | 0.97 | 17 |
| Repression | 0.97 | 1.00 | 0.98 | 31 |
| Sadness | 0.30 | 1.00 | 0.46 | 3 |
| Surprise | 0.68 | 1.00 | 0.81 | 17 |
| Others | 1.00 | 0.75 | 0.86 | 20 |
| Method Type | Accuracy (%) | Main Advantage | Limitation |
|---|---|---|---|
| 3D CNN + Apex Frame Selection [45] | 88.2 | Strong deep learning baseline with optimized video selection | Less interpretable, requires large data |
| Hybrid CNN (DLHN) + Handcrafted Features [48] | 60.3 | Good balance of learned and handcrafted features | Lower accuracy on fine-grained classes |
| Video Transformer + Optical Flow [47] | 73.2 | Transformer model for subtle motion capture | Computationally intensive, comparable accuracy only |
| Shallow CNN (ResNet-optimized) + Optical Flow [46] | 60.2 | Fast, low-resource, real-time compatible | Lower accuracy, limited class resolution |
| Transformer-based (µ-BERT) with Diagonal Micro-Attention and PoI modules [23] | 90.34 | State-of-the-art micro-expression accuracy using unsupervised pretraining | High computational demand, less interpretability, needs massive pretraining |
| Multimodal LLM (GPT-4V), zero-shot prompting [24] | 14.64 | Zero-shot capability across multiple GER tasks, strong multimodal reasoning | Low accuracy in micro-expression tasks due to lack of specialized knowledge |
| Our modular system + OpenAI API + Expert Rules | 93.3 | High accuracy, interpretable, handles emotional confusion | Requires prompt design and external API |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sălăgean, G.L.; Leba, M.; Ionica, A.C. Seeing the Unseen: Real-Time Micro-Expression Recognition with Action Units and GPT-Based Reasoning. Appl. Sci. 2025, 15, 6417. https://doi.org/10.3390/app15126417
Sălăgean GL, Leba M, Ionica AC. Seeing the Unseen: Real-Time Micro-Expression Recognition with Action Units and GPT-Based Reasoning. Applied Sciences. 2025; 15(12):6417. https://doi.org/10.3390/app15126417
Chicago/Turabian StyleSălăgean, Gabriela Laura, Monica Leba, and Andreea Cristina Ionica. 2025. "Seeing the Unseen: Real-Time Micro-Expression Recognition with Action Units and GPT-Based Reasoning" Applied Sciences 15, no. 12: 6417. https://doi.org/10.3390/app15126417
APA StyleSălăgean, G. L., Leba, M., & Ionica, A. C. (2025). Seeing the Unseen: Real-Time Micro-Expression Recognition with Action Units and GPT-Based Reasoning. Applied Sciences, 15(12), 6417. https://doi.org/10.3390/app15126417