IFMIR-VR: Visual Relocalization for Autonomous Vehicles Using Integrated Feature Matching and Image Retrieval



Abstract
1. Introduction
2. Related Works
2.1. Visual Relocalization
2.2. Feature Matching
3. Methods
3.1. Visual Relocalization in Autonomous Vehicles
- 1.
- Construction of the Map Scene Database;
- 2.
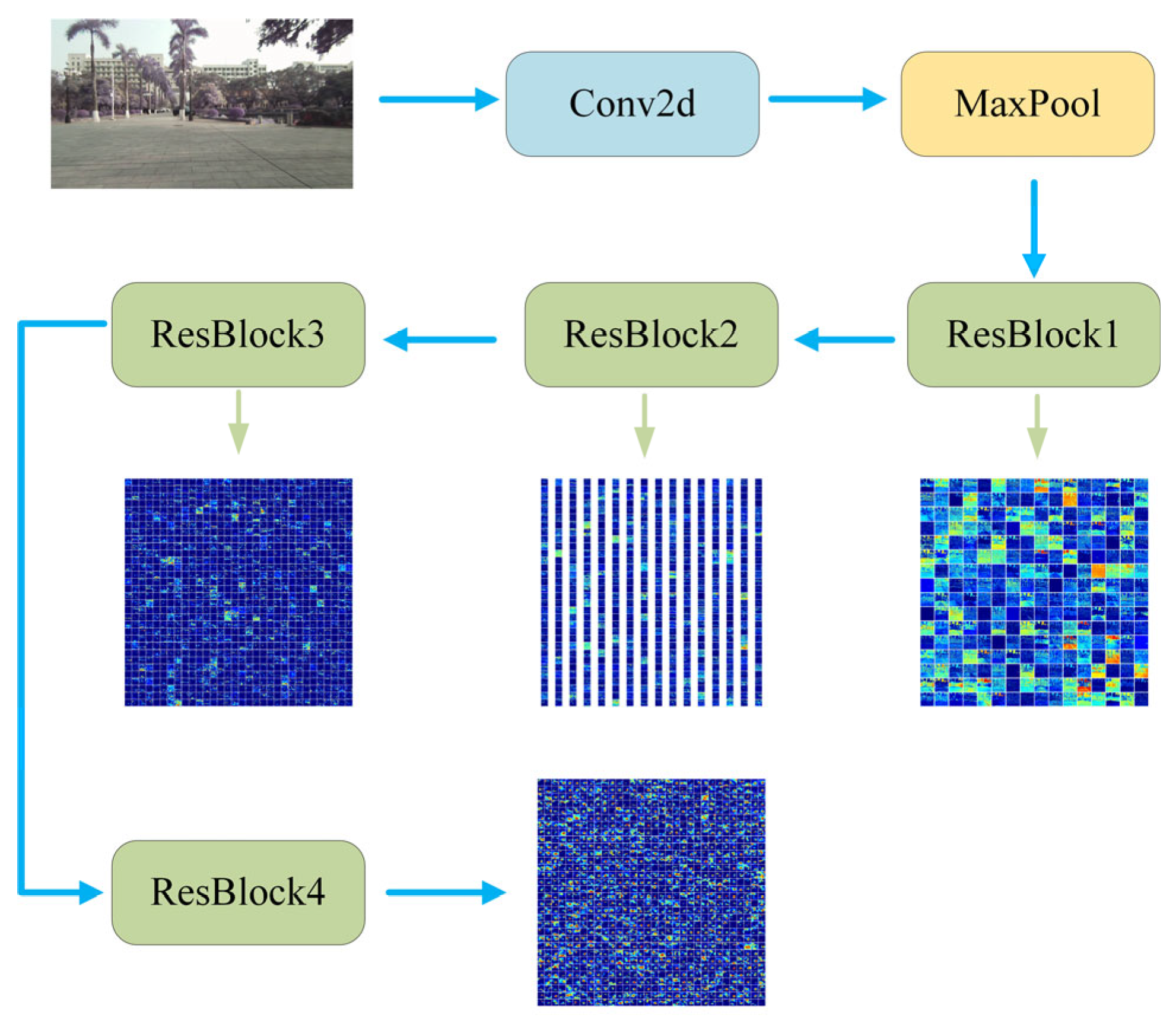
- Neural Network-Based Image Retrieval System;
- 3.
- Depth Estimate;
- 4.
- Feature Matching;
- 5.
- Pose Estimation;
3.2. Integrated Matching Model Framework
4. Experiment
4.1. Experimental Setup
4.2. Evaluation of Feature Matching Accuracy
4.2.1. Datasets
4.2.2. Metrics
4.2.3. Results
4.3. Homography Estimation Experiment
4.3.1. Datasets
4.3.2. Metrics
4.3.3. Results of the Homography Estimation Experiment
4.4. Pose Estimation Experiments in Indoor and Outdoor Environments
4.4.1. Datasets
4.4.2. Metrics
4.4.3. Experimental Results on Scannet and MegaDepth
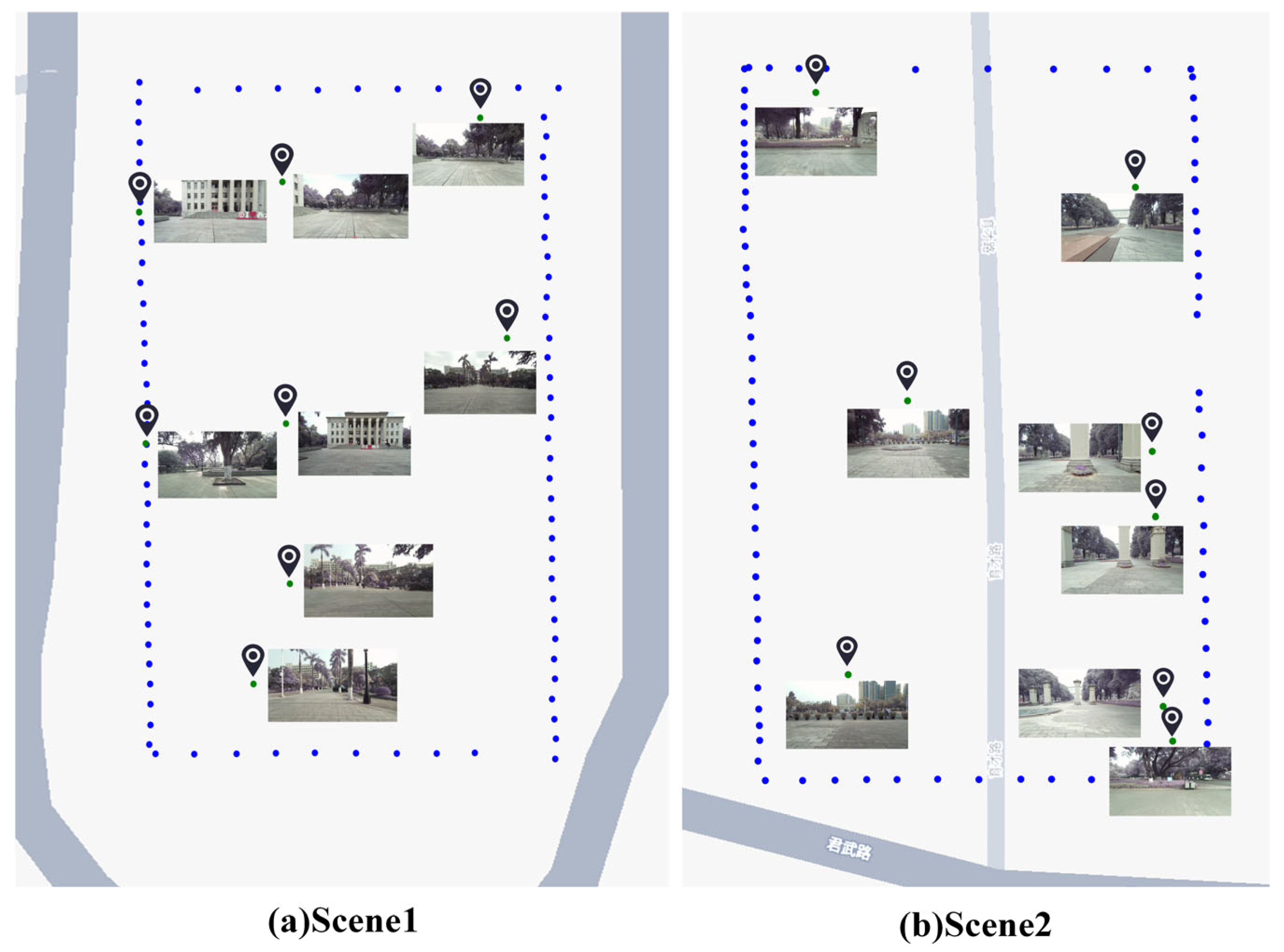
4.5. Experiments in Outdoor Real-World Scenarios
4.5.1. Preparation Phase
4.5.2. Preparation Phase
4.6. Experiments in Indoor Real-World Scenarios
5. Discussion
5.1. Performance Comparison Experiment
5.2. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, Q.; Guo, X.; Wang, Y.; Sun, H.; Yang, L. A survey of feature matching methods. IET Image Process. 2024, 18, 1385–1410. [Google Scholar] [CrossRef]
- Zhao, K.W.G.; Wang, Y.; Ma, S.; Lu, J. SaliencyVR: Saliency Matching Based Visual Relocalization for Autonomous Vehicle. IEEE Trans. Intell. Veh. 2024. [Google Scholar] [CrossRef]
- Zins, M.; Simon, G.; Berger, M.-O. Oa-slam: Leveraging objects for camera relocalization in visual slam. In Proceedings of the 2022 IEEE international Symposium on Mixed and Augmented Reality (ISMAR), Singapore, 17–21 October 2022; pp. 720–728. [Google Scholar]
- Wu, H.; Zhang, Z.; Lin, S.; Mu, X.; Zhao, Q.; Yang, M.; Qin, T. Maplocnet: Coarse-to-fine feature registration for visual re-localization in navigation maps. In Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 14–18 October 2024; pp. 13198–13205. [Google Scholar]
- Zhou, Q.; Agostinho, S.; Ošep, A.; Leal-Taixé, L. Is geometry enough for matching in visual localization? In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 407–425. [Google Scholar]
- Suomela, L.; Kalliola, J.; Dag, A.; Edelman, H.; Kämäräinen, J.-K. Benchmarking visual localization for autonomous navigation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 2945–2955. [Google Scholar]
- Chum, O.; Matas, J.; Kittler, J. Locally optimized RANSAC. In Proceedings of the Joint Pattern Recognition Symposium, Madison, WI, USA, 18–20 June 2003; pp. 236–243. [Google Scholar]
- Kendall, A.; Grimes, M.; Cipolla, R. Posenet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2938–2946. [Google Scholar]
- Radwan, N.; Valada, A.; Burgard, W. Vlocnet++: Deep multitask learning for semantic visual localization and odometry. IEEE Robot. Autom. Lett. 2018, 3, 4407–4414. [Google Scholar] [CrossRef]
- Walch, F.; Hazirbas, C.; Leal-Taixe, L.; Sattler, T.; Hilsenbeck, S.; Cremers, D. Image-based localization using lstms for structured feature correlation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 627–637. [Google Scholar]
- Malhotra, P.; Vig, L.; Shroff, G.; Agarwal, P. Long Short Term Memory Networks for Anomaly Detection in Time Series. 2015; p. 94. Available online: https://books.google.co.uk/books?hl=en&lr=&id=USGLCgAAQBAJ&oi=fnd&pg=PA89&dq=Long+short+term+memory+networks+for+anomaly+detection+in+time+series&ots=FugfnuH-RI&sig=D_o6UAjCbnzQMxPy7rT2fwGOUS8#v=onepage&q=Long%20short%20term%20memory%20networks%20for%20anomaly%20detection%20in%20time%20series&f=false (accessed on 8 April 2025).
- Brachmann, E.; Krull, A.; Nowozin, S.; Shotton, J.; Michel, F.; Gumhold, S.; Rother, C. Dsac-differentiable ransac for camera localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6684–6692. [Google Scholar]
- Brachmann, E.; Rother, C. Learning less is more-6d camera localization via 3d surface regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4654–4662. [Google Scholar]
- Brachmann, E.; Rother, C. Visual camera re-localization from RGB and RGB-D images using DSAC. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5847–5865. [Google Scholar] [CrossRef] [PubMed]
- Abouelnaga, Y.; Bui, M.; Ilic, S. DistillPose: Lightweight camera localization using auxiliary learning. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 7919–7924. [Google Scholar]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Sattler, T.; Leibe, B.; Kobbelt, L. Efficient & effective prioritized matching for large-scale image-based localization. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1744–1756. [Google Scholar] [PubMed]
- Sattler, T.; Leibe, B.; Kobbelt, L. Fast image-based localization using direct 2d-to-3d matching. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 667–674. [Google Scholar]
- Liu, L.; Li, H.; Dai, Y. Efficient global 2d-3d matching for camera localization in a large-scale 3d map. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2372–2381. [Google Scholar]
- Song, Z.; Wang, C.; Liu, Y.; Shen, S. Recalling direct 2d-3d matches for large-scale visual localization. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 1191–1197. [Google Scholar]
- Jégou, H.; Douze, M.; Schmid, C.; Pérez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3304–3311. [Google Scholar]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN architecture for weakly supervised place recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5297–5307. [Google Scholar]
- Gordo, A.; Almazan, J.; Revaud, J.; Larlus, D. End-to-end learning of deep visual representations for image retrieval. Int. J. Comput. Vis. 2017, 124, 237–254. [Google Scholar] [CrossRef]
- Revaud, J.; Almazán, J.; Rezende, R.S.; Souza, C.R.d. Learning with average precision: Training image retrieval with a listwise loss. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5107–5116. [Google Scholar]
- Liu, G.-H.; Yang, J.-Y. Content-based image retrieval using color difference histogram. Pattern Recognit. 2013, 46, 188–198. [Google Scholar] [CrossRef]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 20, 1254–1259. [Google Scholar] [CrossRef]
- Liu, G.-H.; Yang, J.-Y.; Li, Z. Content-based image retrieval using computational visual attention model. Pattern Recognit. 2015, 48, 2554–2566. [Google Scholar] [CrossRef]
- Gordo, A.; Almazán, J.; Revaud, J.; Larlus, D. Deep image retrieval: Learning global representations for image search. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VI 14, 2016. pp. 241–257. [Google Scholar]
- Li, K.; Ma, Y.; Wang, X.; Ji, L.; Geng, N. Evaluation of Global Descriptor Methods for Appearance-Based Visual Place Recognition. J. Robot. 2023, 2023, 9150357. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 224–236. [Google Scholar]
- Tyszkiewicz, M.; Fua, P.; Trulls, E. DISK: Learning local features with policy gradient. Adv. Neural Inf. Process. Syst. 2020, 33, 14254–14265. [Google Scholar]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-net: A trainable cnn for joint description and detection of local features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8092–8101. [Google Scholar]
- Sarlin, P.-E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4938–4947. [Google Scholar]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-free local feature matching with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8922–8931. [Google Scholar]
- Cheng, J.; Liu, L.; Xu, G.; Wang, X.; Zhang, Z.; Deng, Y.; Zang, J.; Chen, Y.; Cai, Z.; Yang, X. MonSter: Marry Monodepth to Stereo Unleashes Power. arXiv 2025, arXiv:2501.08643. [Google Scholar]
- Lindenberger, P.; Sarlin, P.-E.; Pollefeys, M. Lightglue: Local feature matching at light speed. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 17627–17638. [Google Scholar]
- Barath, D.; Noskova, J.; Ivashechkin, M.; Matas, J. MAGSAC++, a fast, reliable and accurate robust estimator. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1304–1312. [Google Scholar]
- Balntas, V.; Lenc, K.; Vedaldi, A.; Mikolajczyk, K. HPatches: A benchmark and evaluation of handcrafted and learned local descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5173–5182. [Google Scholar]
- Revaud, J.; De Souza, C.; Humenberger, M.; Weinzaepfel, P. R2d2: Reliable and repeatable detector and descriptor. Adv. Neural Inf. Process. Syst. 2019, 32. Available online: https://proceedings.neurips.cc/paper/2019/hash/3198dfd0aef271d22f7bcddd6f12f5cb-Abstract.html (accessed on 8 April 2025).
- Rocco, I.; Arandjelović, R.; Sivic, J. Efficient neighbourhood consensus networks via submanifold sparse convolutions. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, part IX 16, 2020. pp. 605–621. [Google Scholar]
- Zhou, Q.; Sattler, T.; Leal-Taixe, L. Patch2pix: Epipolar-guided pixel-level correspondences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4669–4678. [Google Scholar]
- Wang, Q.; Zhang, J.; Yang, K.; Peng, K.; Stiefelhagen, R. Matchformer: Interleaving attention in transformers for feature matching. In Proceedings of the Asian Conference on Computer Vision, Macao, China, 4–8 December 2022; pp. 2746–2762. [Google Scholar]
- Liu, J.; Zhang, X. DRC-NET: Densely connected recurrent convolutional neural network for speech dereverberation. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 166–170. [Google Scholar]
- Tang, S.; Zhang, J.; Zhu, S.; Tan, P. Quadtree attention for vision transformers. arXiv 2022, arXiv:2201.02767. [Google Scholar]
- Giang, K.T.; Song, S.; Jo, S. TopicFM: Robust and interpretable topic-assisted feature matching. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 2447–2455. [Google Scholar]
- Bian, J.; Lin, W.-Y.; Matsushita, Y.; Yeung, S.-K.; Nguyen, T.-D.; Cheng, M.-M. GMS: Grid-based motion statistics for fast, ultra-robust feature correspondence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4181–4190. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Overall | Illumination | Viewpoint |
|---|---|---|---|
| Accuracy ( < 1/3/5 Pixel) | |||
| D2-Net [34] | 0.38/0.71/0.82 | 0.66/0.95/0.98 | 0.12/0.49/0.67 |
| R2D2 [41] | 0.47/0.77/0.82 | 0.63/0.93/0.98 | 0.32/0.64/0.70 |
| SP [32]+LG [38] | 0.39/0.85/0.90 | 0.52/0.96/0.98 | 0.28/0.75/0.84 |
| Sparse-NCNet [42] | 0.36/0.65/0.76 | 0.62/0.92/0.97 | 0.13/0.40/0.58 |
| Patch2Pix [43] | 0.50/0.79/0.87 | 0.71/0.95/0.98 | 0.30/0.64/0.76 |
| LoFTR [36] | 0.55/0.81/0.86 | 0.74/0.95/0.98 | 0.38/0.69/0.76 |
| MatchFormer [44] | 0.55/0.81/0.87 | 0.75/0.95/0.98 | 0.37/0.68/0.78 |
| OURS | 0.55/0.83/0.88 | 0.76/0.96/0.98 | 0.33/0.69/0.78 |
| Category | Method | Pose Estimation AUC% | ||
|---|---|---|---|---|
| AUC@5° | AUC@10° | AUC@20° | ||
| Sparse | SP [32] + NN | 31.7 | 46.8 | 60.1 |
| SP [32] + SG [35] | 49.7 | 67.1 | 80.6 | |
| SP [32] + LG [38] | 49.9 | 67.0 | 80.1 | |
| Semi-Dense | DRC-Net [45] | 27.0 | 42.9 | 58.3 |
| LoFTR [36] | 52.8 | 69.2 | 81.2 | |
| QuadTree [46] | 54.6 | 70.5 | 82.2 | |
| MatchFormer [44] | 53.3 | 69.7 | 81.8 | |
| TopicFM [47] | 54.1 | 70.1 | 81.6 | |
| OURS | 55.6 | 70.6 | 82.1 | |
| Category | Method | Pose Estimation AUC% | ||
|---|---|---|---|---|
| AUC@5° | AUC@10° | AUC@20° | ||
| Sparse | ORB [31] + GMS [48] | 5.2 | 13.7 | 25.4 |
| SP [32] + NN | 7.5 | 18.6 | 32.1 | |
| SP [32] + SG [35] | 16.2 | 32.8 | 49.7 | |
| SP [32] + LG [38] | 14.8 | 30.8 | 47.5 | |
| Semi-Dense | DRC-Net [45] | 7.7 | 17.9 | 30.5 |
| LoFTR [36] | 16.9 | 33.6 | 50.6 | |
| MatchFormer [44] | 15.8 | 32.0 | 48.0 | |
| TopicFM [47] | 17.3 | 35.5 | 50.9 | |
| OURS | 19.1 | 36.4 | 52.6 | |
| Actual Coordinates | Relocalization | Metrics | |||
|---|---|---|---|---|---|
| Input Images | Measured Coordinates (N, E) | Matching Image | Predicted Coordinates (N, E) | Coordinate Error (▲N, ▲E) | Translation Error (m) |
| Test1 | (2,526,947.321, 529,196.851) | Map03 | (2,526,947.469, 529,196.997) | (−0.148, −0.146) | 0.208 |
| Test2 | (2,526,950.403, 529,197.401) | Map09 | (2,526,950.003, 529,197.494) | (0.400, −0.093) | 0.411 |
| Test3 | (2,526,955.328, 529,197.345) | Map21 | (2,526,954.959, 529,197.237) | (0.369, 0.108) | 0.384 |
| Test4 | (2,526,962.757, 529,197.288) | Map27 | (2,526,963.033, 529,197.179) | (−0.276, 0.109) | 0.297 |
| Test5 | (2,526,964.728, 529,200.288) | Map40 | (2,526,964.317, 529,200.125) | (0.411, 0.163) | 0.442 |
| Test6 | (2,526,961.826, 529,195.117) | Map25 | (2,526,962.651, 529,194.450) | (−0.825, 0.667) | 1.061 |
| Test7 | (2,526,957.945, 529,200.695) | Map56 | (2,526,958.586, 529,200.175) | (−0.641, 0.520) | 0.825 |
| Test8 | (2,526,954.711, 529,195.219) | Map14 | (2,526,955.301, 529,195.683) | (−0.590, −0.464) | 0.751 |
| Actual Coordinates | Relocalization | Metrics | |||
|---|---|---|---|---|---|
| Input Images | Measured Coordinates (N, E) | Matching Image | Predicted Coordinates (N, E) | Coordinate Error (▲N, ▲E) | Translation Error (m) |
| Test1 | (2,526,492.846, 529,213.087) | Map87 | (2,526,492.263, 529,213.078) | (−0.582, −0.009) | 0.583 |
| Test2 | (2,526,494.824, 529,212.805) | Map05 | (2,526,494.824, 529,213.010) | (0.000, 0.205) | 0.205 |
| Test3 | (2,526,505.666, 529,212.576) | Map13 | (2,526,506.105, 529,212.897) | (0.439, 0.321) | 0.544 |
| Test4 | (2,526,509.387, 529,212.480) | Map15 | (2,526,509.351, 529,212.906) | (−0.036, 0.426) | 0.428 |
| Test5 | (2,526,524.473, 529,211.980) | Map25 | (2,526,524.934, 529,211.925) | (0.461, −0.055) | 0.464 |
| Test6 | (2,526,529.884, 529,202.476) | Map37 | (2,526,530.136, 529,202.393) | (0.252, −0.083) | 0.265 |
| Test7 | (2,526,512.270, 529,205.204) | Map61 | (2,526,512.405, 529,204.933) | (0.135, −0.271) | 0.303 |
| Test8 | (2,526,496.651, 529,203.441) | Map72 | (2,526,496.683, 529,203.215) | (0.032, −0.226) | 0.228 |
| Scene | RPE_Mean (m) | RPE_RMSE (m) | ATE_Mean (m) | ATE_RMSE (m) |
|---|---|---|---|---|
| Scene1 | 0.2985 | 0.4553 | 0.5071 | 0.6139 |
| Scene2 | 0.2459 | 0.3431 | 0.4089 | 0.4541 |
| Scene | Input Image | Translation Error (m) | ||
|---|---|---|---|---|
| LoFTR | SP+LG | OURS | ||
| Scene1 | Test1 | 0.471 | 0.351 | 0.208 |
| Test2 | 5.419 | 0.664 | 0.411 | |
| Test3 | 4.902 | 2.913 | 0.384 | |
| Test4 | 1.385 | 0.640 | 0.256 | |
| Test5 | 0.559 | 0.521 | 0.442 | |
| Test6 | 1.236 | 1.236 | 1.061 | |
| Test7 | 0.945 | 0.884 | 0.825 | |
| Test8 | 0.774 | 0.874 | 0.751 | |
| Scene2 | Test1 | 0.625 | 3.665 | 0.583 |
| Test2 | 0.219 | 0.220 | 0.205 | |
| Test3 | 0.911 | 0.553 | 0.544 | |
| Test4 | 0.496 | 0.442 | 0.428 | |
| Test5 | 1.097 | 1.392 | 0.464 | |
| Test6 | 0.477 | 0.301 | 0.265 | |
| Test7 | 1.785 | 2.098 | 0.303 | |
| Test8 | 1.851 | 1.415 | 0.228 | |
| Scene | SP + LG | LoFTR | OURS | |||
|---|---|---|---|---|---|---|
| Mean | RMSE | Mean | RMSE | Mean | RMSE | |
| Scene1 | 0.5072 | 0.8393 | 0.5096 | 0.8872 | 0.2985 | 0.4553 |
| Scene2 | 0.2807 | 0.4808 | 0.3051 | 0.4586 | 0.2459 | 0.3431 |
| Scene | SP + LG | LoFTR | OURS | |||
|---|---|---|---|---|---|---|
| Mean | RMSE | Mean | RMSE | Mean | RMSE | |
| Scene1 | 0.9181 | 1.13 87 | 0.9164 | 1.1623 | 0.5071 | 0.6139 |
| Scene2 | 0.7385 | 0.8523 | 0.7626 | 0.8821 | 0.4089 | 0.4541 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, G.; Xu, X.; Yu, J.; Luo, H. IFMIR-VR: Visual Relocalization for Autonomous Vehicles Using Integrated Feature Matching and Image Retrieval. Appl. Sci. 2025, 15, 5767. https://doi.org/10.3390/app15105767
Li G, Xu X, Yu J, Luo H. IFMIR-VR: Visual Relocalization for Autonomous Vehicles Using Integrated Feature Matching and Image Retrieval. Applied Sciences. 2025; 15(10):5767. https://doi.org/10.3390/app15105767
Chicago/Turabian StyleLi, Gang, Xiaoman Xu, Jian Yu, and Hao Luo. 2025. "IFMIR-VR: Visual Relocalization for Autonomous Vehicles Using Integrated Feature Matching and Image Retrieval" Applied Sciences 15, no. 10: 5767. https://doi.org/10.3390/app15105767
APA StyleLi, G., Xu, X., Yu, J., & Luo, H. (2025). IFMIR-VR: Visual Relocalization for Autonomous Vehicles Using Integrated Feature Matching and Image Retrieval. Applied Sciences, 15(10), 5767. https://doi.org/10.3390/app15105767