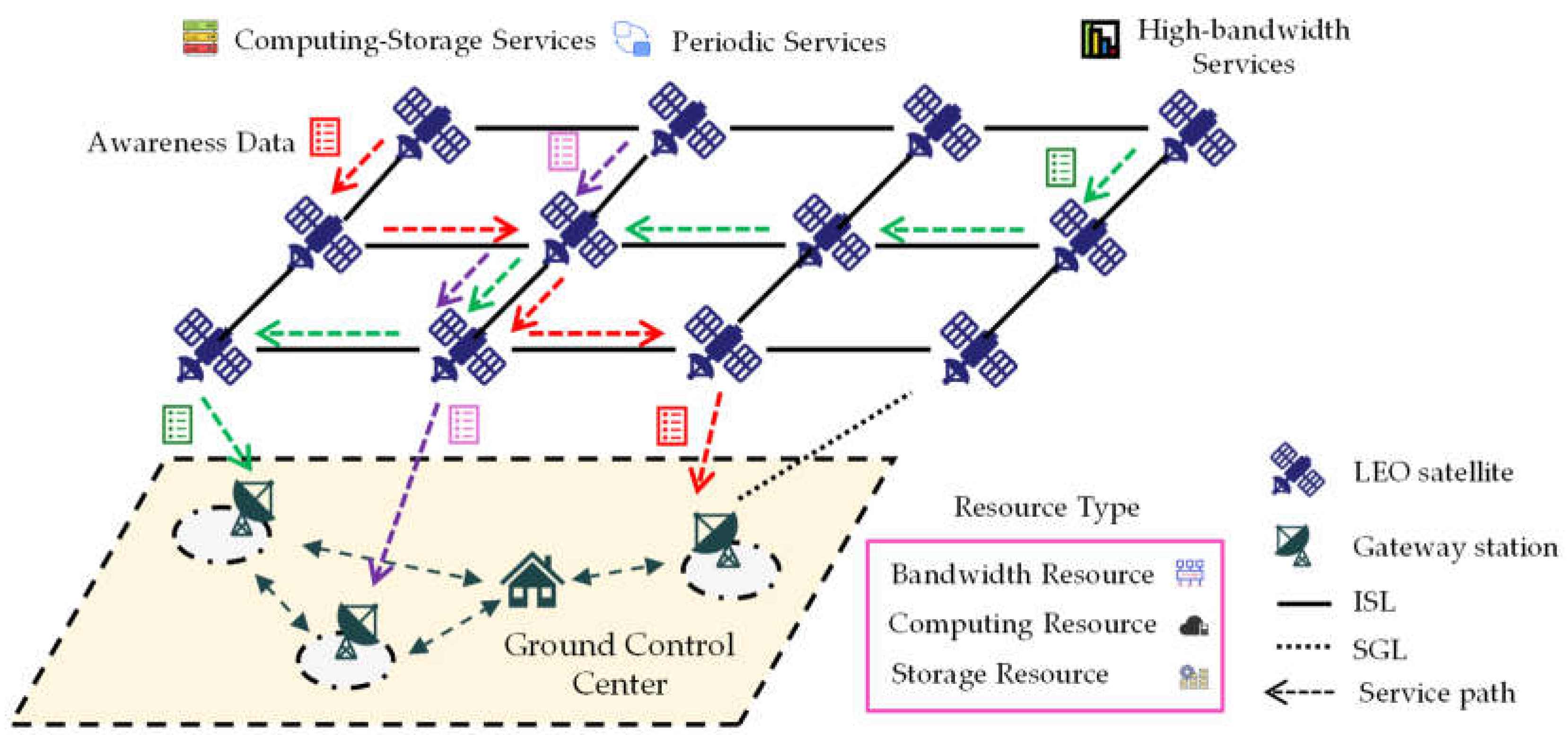
1. Introduction
The services in low-Earth-orbit (LEO) satellite networks have diversified with the continuous expansion of these networks and the increase in the associated number of users. The demand for network resources to guarantee network transmission in concurrent, multiservice scenarios has experienced exponential growth [
1]. However, the available network resources on the satellite, including bandwidth, computing power, and storage, are severely limited by the harsh space environment, resulting in a bottleneck in network service performance. The varying demands for resources among different services further increase the complexity of network resource management and scheduling [
2]. Therefore, it is necessary to utilize network resource allocation technology, in conjunction with the resource demands of services, to jointly optimize the allocation of multi-dimensional network resources and enhance the service capability of LEO satellite networks.
Network resource allocation methods primarily encompass static pre-allocation of resources and dynamic adaptive scheduling of resources. Due to the fixed position of terrestrial network nodes and the stability of links, the method of allocating resources on demand is commonly employed to achieve dynamic resource scheduling, while static pre-allocation is used for special services [
3]. However, the topology of satellite networks undergoes dynamic changes, characterized by large inter-satellite distances and poor link stability. As such, the transmission of operational or management commands is subject to large latency and latency deviation, leading to inadequate timeliness in dynamic resource allocation processes, including resource status awareness, decision-making, and the dispatch of commands [
4]. The intelligent and dynamic online decision-making approach for terrestrial networks has become ineffective due to the limited computing capabilities on satellites and the complexity of time-varying scenarios. Static resource allocation and resource reservation mechanisms are therefore frequently adopted in satellite networks, helping to guarantee the stable transmission of network services.
The efficient real-time awareness of the resource status of the satellite [
5] and the precise prediction of changes in resource status are important prerequisites for network resource allocation. However, the application of terrestrial network awareness and prediction methodologies to satellite networks encounters challenges such as inadequate awareness latency and imprecise resource state predictions, owing to the dynamic characteristics of the network topology and the unpredictability of services. On the one hand, the instability of inter-satellite and satellite–ground links, coupled with the significant distance involved, results in propagation delay, transmission delay, and onboard processing delay at each node as the awareness data traverse multiple nodes within the network [
6]. The cumulative effect of these delays leads to a certain degree of awareness latency when the awareness data are relayed back to the ground, meaning that the awareness data received on the ground exhibit lag. On the other hand, satellite network resources exhibit complex temporal and spatial distributions, with resource status characterized by nonlinearity and discontinuity. Furthermore, the operations within the network demonstrate significant randomness, leading to considerable uncertainty in resource variations. The insufficient availability of data to guarantee the robustness and generalization capabilities of prediction models poses challenges in accurately forecasting the resource status. Consequently, developing an efficient network resource awareness method, augmented with precise and agile prediction techniques, is necessary to facilitate accurate and flexible resource allocation.
There have been numerous studies on resource allocation based on satellite network resource awareness and the prediction of network resource status. However, research on these two aspects is often conducted in isolation. In other words, relevant research may solely concentrate on optimizing awareness methods or enhancing prediction accuracy while neglecting the relationship between them. For example, in the case of satellite network awareness technology, the method of [
7] employs telemetry technology to perceive the network status in real time and implements dynamic adaptive routing based on the awareness data. However, it fails to take into account the issue of awareness delay during the telemetry process. The volume of awareness transmission data is enhanced by employing dynamic channel allocation, enabling the establishment of an awareness method characterized by low latency and high bandwidth [
8]. However, this approach also increases the complexity and awareness overhead of the network. Research on the allocation of network resources has employed intelligent prediction models [
9,
10], such as RNNs, long short-term memory (LSTM) [
11], graph convolutional networks (GCNs) [
12], and transfer learning [
13], to forecast network traffic or resource status, subsequently making intelligent computing or dynamic allocation decisions based on the predictions. However, due to the limited onboard computing resources, these models struggle to fulfill the dynamic and intricate resource allocation demands of the network in terms of their real-time capability and deployment ability. Reference [
14] predicted the computing, storage, and bandwidth resources of onboard control plane units and user plane units using an LSTM in order to improve the dynamic resource allocation capability for network service functions. The authors of [
15] proposed a routing strategy based on cache resource awareness and prediction, which can reduce the end-to-end transmission delay by sensing user needs and using cache prediction results for dynamic routing planning. However, unpredictable random events and subsequent data perturbations are prone to arise within the network due to the dynamic and uncertainty of network topology, leading to a decline in the prediction accuracy of the model [
16]. Additionally, the sparsity of data and the non-stationarity of time series further impact the authenticity and reliability of the data.
Aiming at the problems of poor awareness latency and low resource prediction accuracy, a network resource allocation method for LEO satellite networks based on awareness–prediction joint compensation (NRA-PPJC) is proposed in this study. This method can be utilized to dynamically compensate for resource prediction results, improve the timeliness and accuracy of data, and build an efficient network resource allocation method. Satellite networks have fewer available open-source resource data than terrestrial networks, while the data gathered by terrestrial networks lack complex and time-evolving characteristics. Therefore, the variations in resource occupancy and release of satellite network resources during the arrival and transmission processes of service were simulated in this work using service arrival models. These simulations were tailored to account for differences in the service generation period, user distributions, and varying resource demands among different types of services. In-band network telemetry (INT) technology was utilized to obtain the resource status of each node. To address the issue of significant awareness latency unique to satellite networks, node resource awareness data were correlated with awareness latency to create a resource dataset that sequences data based on latencies. Using the differentiated awareness delay between nodes as the prediction step size, the LSTM method was employed to flexibly forecast the resource status for various nodes. Furthermore, an awareness–prediction joint compensation model was designed considering the impact of awareness latency between nodes on the timeliness of awareness data, as well as the varying prediction accuracies of various resources. This model assesses the accuracy of awareness data based on the extent of awareness latency and subsequently determines the compensation weights for various resource prediction accuracy scenarios. A dynamic network resource allocation algorithm based on the accelerated alternating direction method of multipliers (ADMM) is proposed, which uses compensation data as an input with the optimization objective of maximizing the service resource coverage ratio (SRCR). Considering the differences in service priorities and resource requirements, the ability of resources between nodes to carry service was calculated, and the local variable initialization process of the ADMM was optimized to reduce search iterations, improve algorithm convergence speed, and achieve efficient network resource allocation.
The main contributions of this paper are as follows:
- (1)
A network resource dataset that utilizes the different awareness latencies of each node as its temporal sequence was constructed. The changes in node resource occupancy and release were simulated based on the service arrival models. INT was used for resource awareness, and a dataset was compiled using the corresponding awareness latency as the time interval. The dataset served as the foundation for resource status prediction, data compensation, and resource allocation.
- (2)
An awareness–prediction joint compensation model was designed. The LSTM is used to dynamically predict the onboard resource status for each node using the different awareness latencies between nodes as the prediction steps. An innovative method for constructing compensation parameters based on awareness latency and prediction accuracy is also proposed. This approach can compensate for the prediction results based on the resource prediction accuracy combined with awareness data, thereby improving the timeliness and accuracy of the data.
- (3)
A dynamic network resource allocation algorithm based on the ADMM is proposed. The initialization process of the ADMM’s local variables was refined based on the actual service carrying capacity of satellites, using compensation data as the input and with the optimization objective of maximizing the SRCR. This enhances the algorithm’s convergence speed and enables efficient resource allocation.
The remainder of this paper is organized as follows:
Section 2 introduces the scenario of the LEO satellite network, service model, and resource model.
Section 3 introduces resource state awareness based on INT and resource state prediction based on LSTM.
Section 4 introduces the awareness–prediction joint compensation model.
Section 5 proposes a dynamic network resource allocation algorithm based on accelerated ADMM.
Section 6 validates the proposed method through simulation experiments.
Section 7 provides a brief summary of the paper.
4. Awareness–Prediction Joint Compensation Methods
LSTM is a traditional resource state prediction approach [
23,
26]. However, the innovation of this study lies in applying the prediction model to the specific challenges faced by satellite network resource awareness. The issues of varying time intervals in data awareness among nodes and differing prediction step sizes are addressed by dynamically adjusting the prediction step size based on node-aware latency. The prediction accuracy of network resource status based on LSTM varies with the change in the prediction step size. When the awareness latency is high, the error in the resource status prediction results increases. Additionally, the randomness of services and the instability of links in satellite networks lead to significant fluctuations in resource changes, which result in poor data continuity and stability, thereby reducing the prediction accuracy. Specifically, in scenarios characterized by significant resource fluctuations, such as those exhibiting spikes in resource curves, the retention of early growth trends in resources, attributed to the gating mechanism and the cumulative impact of errors, can cause prediction results to diverge substantially from actual values, thereby generating significant errors. Consequently, relying on these predictions can undermine the reliability and precision of the decision-making.
The awareness data also have poor timeliness due to the awareness latency caused by the dynamic topology of LEO satellite networks. Specifically, after the satellite node completes the writing operation of the metadata at time , the ground control center can only receive the resource status data after a certain awareness latency , with the current time being . At the current moment, the onboard resources may have already changed, meaning that the awareness data received at the ground control center do not represent the real-time resource status of the node, but rather awareness latency data. The actual resource status on the satellite may fall into one of the following situations. (1) With no new services arriving, the resources occupied by previous services on the satellite remain unreleased. The state of onboard resources unchanged, and the awareness latency data are equivalent to the quantity of onboard resources. (2) With no new services or fewer services arriving, the resources occupied by previous services are significantly released, resulting in an increase in available onboard resources. The quantity of awareness latency data is smaller than the quantity of onboard resources. (3) With the arrival of new services, the resources occupied by previous services have yet to be released, and the quantity of onboard resources is smaller than the awareness latency data. (4) With the arrival of new services, the resources occupied by previous services are released and the onboard resources may not change, or they may be greater or less than that of the awareness latency data.
As shown in
Figure 2, both the awareness latency data received on the ground and the resource status prediction results exhibit poor accuracy and timeliness. To address the above problem, a dynamic compensation model based on awareness data and prediction results is proposed. The model dynamically compensates for awareness latency data based on the prediction results and dynamically adjusts the compensation weights for each node according to the awareness latency and prediction accuracy, ensuring that the authenticity and accuracy of the compensated data are closer to the actual onboard resource status.
Specifically, the LSTM-based prediction algorithm uses the awareness latency
as the prediction step length, so the predicted result of node
for the
-th type of resource status at time
is
. The actual awareness data received by the ground control center at the current moment for node
are
, where
is the awareness latency of the node, and
. The dynamic compensation model based on the awareness data and the predicted results is as follows:
where
is the compensation weight, and
. Furthermore, the design of
is based on the awareness latency and the accuracy of the prediction model, and its calculation formula is as follows:
where
is the awareness latency,
is the awareness latency threshold,
is the latency coefficient, and
is the resource type weight.
is the prediction error of the
-th resource. The impact analysis of each parameter is as follows:
- (1)
is the weight of the awareness latency data and the prediction results in the compensation process. When is large, the credibility of the current awareness data is high, and its weight is relatively large. When is small, the prediction results account for a larger proportion in the compensation process, thereby dynamically adjusting the ratio of awareness latency data and prediction results.
- (2)
controls the speed of the change in weight, representing the sensitivity to changes in awareness latency and prediction error during the compensation process. When is large, if , then . If , then . If , then , and at this point, the weights of awareness latency data and prediction results are the same, independent of the parameters.
- (3)
is the awareness latency threshold. When increases, it enhances the tolerance of the compensation data to latency, meaning that at this time, there is a greater reliance on prediction data. When is small, it is more sensitive to awareness latency and relies more on awareness latency data.
- (4)
is used to adjust the impact of prediction errors on weights, as there are differences in prediction accuracy when using LSTM models for different types of resources on the satellite. Therefore, if the current resource prediction results are unreliable, the value of can be increased to ensure that the impact of awareness delays is more significant during the weight update process. When is small, it reduces the impact of prediction errors on , making the compensation process more reliant on adjusting weights based on latency differences.
- (5)
is the prediction error for different resource types. When is large, the compensation process relies more on awareness latency data. When is small, its corrective effect on is stronger, and the reliability of the prediction results during the compensation process is higher.
The above compensation model complies with the characteristics of LEO satellite networks. The awareness latency of the node is higher for satellites that are relatively far from the gateway station in the network, and the reliability of the awareness latency data decreases significantly with the increase in latency. At this point, compensation for the awareness latency data can be performed based on the predicted results of the node’s re-sources. The awareness latency is small in the case of satellites in the network that are relatively close to the gateway station. The real-time performance of the awareness data at this time is better, and the error between the actual onboard resource status and the awareness data is smaller, which means the compensation weight of the awareness data is larger. For instance, when the resource state undergoes a sudden peak shift due to services, resulting in a significant prediction error, the accuracy of the awareness data be-comes more pronounced. Consequently, the proportion of awareness data dynamically increases.
There are also differences in the speed and magnitude of changes in the onboard bandwidth, computation, and storage resources in the same node, leading to variation in the prediction accuracy of the LSTM algorithm for three types of resources. Regarding re-source types exhibiting poor prediction accuracy, the impact of prediction results on compensation data can be mitigated through the application of Equation (18). For example, in the scenario where the resource state changes abruptly, the prediction result error is relatively large. Although there is a delay in the awareness data, the error may be relatively small. Therefore, the impact of the awareness data can be improved by adjusting the compensation weight. The compensation effect of the prediction results on data is strengthened for resource types with better prediction results. For instance, the compensation weight of the prediction results can be elevated to bolster the compensating impact of pre-diction results on the data in scenarios with significant delays and substantial awareness data error.
6. Simulation Results and Analysis
This paper evaluates the proposed NRA-PPJC method through numerical simulations. A LEO satellite network consisting of 293 nodes is simulated, comprising both polar and inclined orbits. The inclined orbit has an altitude of 550 km and an inclination angle of 50°, with a total of 19 orbital planes, each containing 11 satellites. The polar orbit has an altitude of 560 km and an inclination angle of 86.5°, with a total of 6 orbital planes, each containing 14 satellites. The arrival processes of periodic services, high-bandwidth services, and computing–storage services are simulated in the network. Then, dataset construction and preprocessing of node resource awareness data are also conducted.
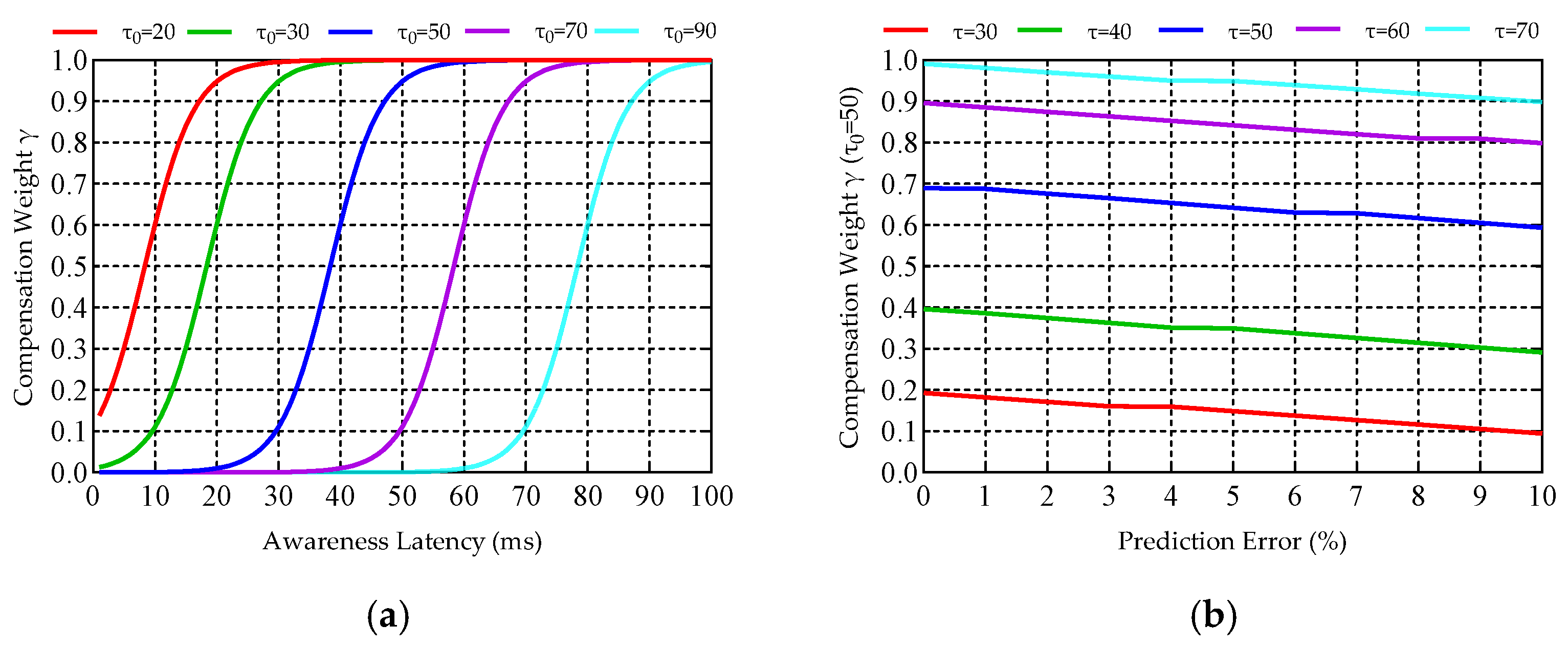
Figure 3 presents a comparison of the robustness evaluation of the awareness–prediction joint compensation method.
Figure 3a demonstrates the influence of awareness latency on compensation weights across different awareness latency threshold benchmarks. The prediction error of node resources is fixed at 5%, which is based on the average value of the relative prediction error of node resources in the whole network. It can be seen from the figure that as the awareness latency threshold is set lower, the compensation weight converges to 1 within a shorter awareness latency. This implies that when the awareness latency threshold is small, a smaller awareness latency results in a larger proportion of awareness latency data in the compensation data, and as the awareness latency increases, the proportion of prediction results will also rise.
Figure 3b illustrates the variation in compensation weights in relation to prediction accuracy across different awareness latencies. Since the prediction accuracy of various resource types falls within 10%, the compensation weight will decrease as the prediction error rises, meaning that the proportion of prediction results in the compensation process will decrease accordingly. Moreover, for a fixed awareness latency threshold, the compensation weight increases rapidly as the latency increases, thereby increasing the proportion of prediction results in the compensation process. In summary, the proposed method allows for the adjustment of compensation weights based on prediction accuracy, and it can further undergo dynamic optimization in response to latency, enhancing the robustness of the method in scenarios characterized by high dynamics and varying prediction accuracies.
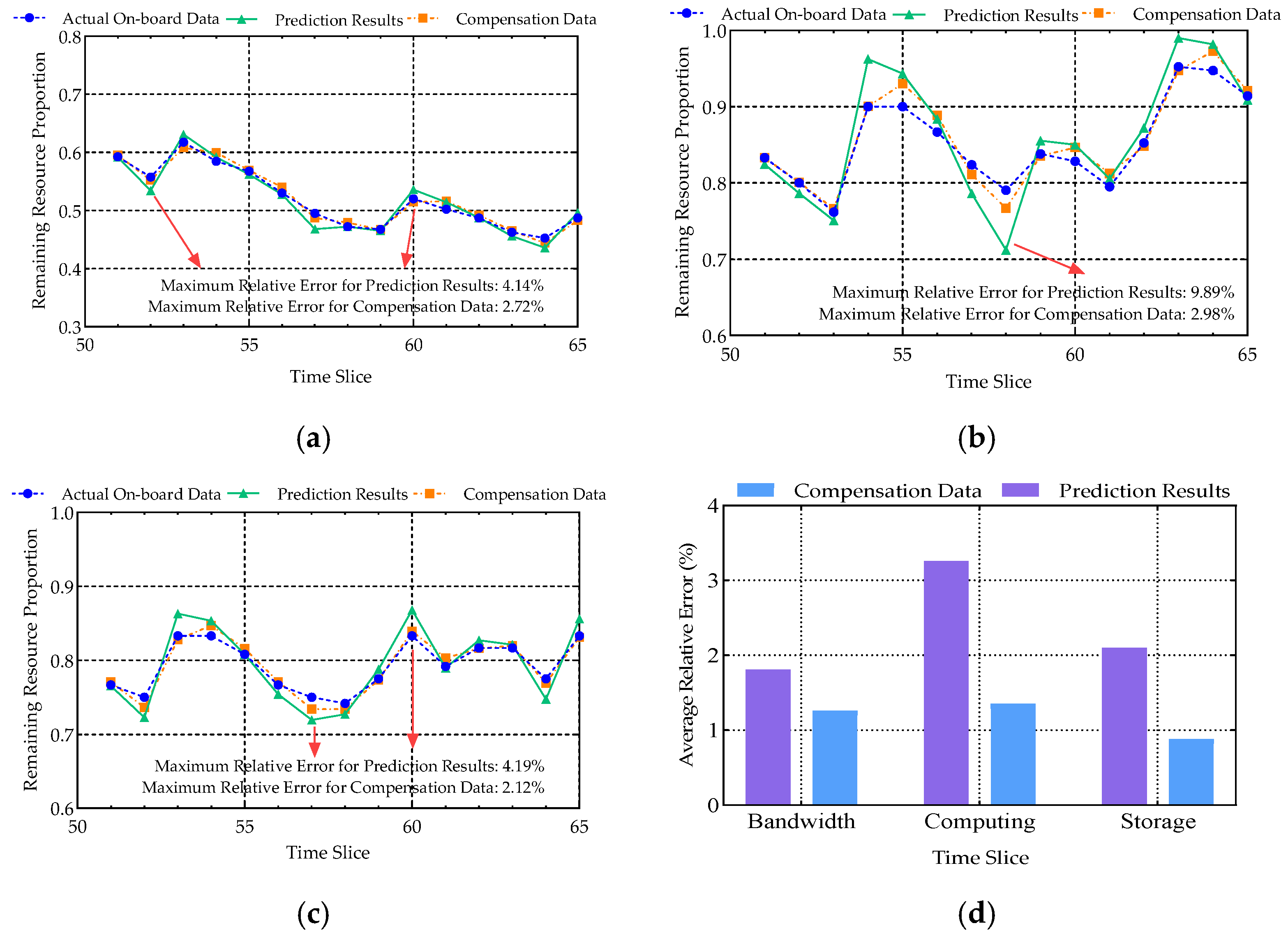
Figure 4 shows comparisons of the compensation data, prediction results, and the awareness data, representing the actual status of onboard resources.
Figure 4a shows the comparison for bandwidth resources. It can be seen from the figure that although the bandwidth resources are heavily utilized, the usage of high-bandwidth services is continuous. Therefore, the trend of change is relatively smooth over time. The prediction results based on the LSTM algorithm are close to the actual resource status, with a small error. After the compensation based on the prediction results, the compensation data can fit the actual results. The maximum relative error between prediction results and actual onboard state data is 4.14%, and the error of the compensation data is 2.72%, demonstrating the accuracy and reliability of the proposed algorithm.
Figure 4b shows the comparison for computing resources. It can be seen from the figure that although the resource utilization is relatively low, the speed of resource occupation and release is rapid due to the characteristics of the services. This leads to significant fluctuations in resource trends, which in turn reduces the prediction accuracy. The compensation data fit well with the awareness data. However, the compensation results can reduce some of the prediction errors for the rapidly changing peak areas. The maxi-mum relative error between prediction results and actual onboard state data is 9.89%, and the error of the compensation data is 2.98%, effectively addressing the issue of poor prediction accuracy in dynamic environments.
Figure 4c shows the comparison for storage resources. It can be seen from the figure that the utilization is relatively low. However, the frequency of resource occupation and release is higher than that of computing resources, resulting in many spikes, which also affects the prediction accuracy. The maximum relative error between prediction results and actual onboard state data is 4.19%. This indicates that although spikes can affect ac-curacy, the inherent characteristics of resource occupation and release still allow for better prediction performance than scenarios with rapid fluctuations in computing resources. The compensation data fit well with the awareness data. The maximum relative error be-tween compensation data and actual onboard state data is 2.12%, which effectively enhances the fitting accuracy and improves data reliability.
Figure 4d demonstrates the average relative errors between the prediction results and the actual onboard data as well as the average relative errors of the compensation data. From the graph, it can be seen that the relative errors of the compensation data are consistently smaller than those of the prediction results, suggesting that the compensation model can significantly enhance the accuracy of the data.
To further evaluate the effectiveness of the proposed method, actual awareness data are introduced for testing. Due to the limited availability of open-source satellite network data, a LEO satellite network consisting of 293 satellites was established based on existing systems using container technology. Programmable switches were employed to measure the transmission port rate (TPR) and reception port rate (RPR) per second of device ports in both non-service and high-bandwidth service scenarios, thereby showcasing the actual bandwidth capabilities of the nodes. Especially when there is no traffic passing through, due to the presence of awareness packets or other signals in the network, the node port rate remains small but is not zero.
Figure 5 illustrates the comparison among the actual awareness data, prediction results, and compensation data. The background flow, acting as noise, exhibits a high degree of randomness and is characterized by frequent and significant changes. Regarding the issue of frequent changes, prediction algorithms may produce deteriorated prediction results at peak points, and their prediction performance may be reduced compared to simulated awareness data. This is exemplified in the 57th time slot in
Figure 5a, where the error between the predicted result and the actual awareness data is approximately 22.7%. However, after joint compensation, the error between the compensated data and the actual awareness data drops to only 6.8%. For problems involving significant changes, the prediction method will produce significant errors. For instance, in the 57th time slice depicted in
Figure 5b, the prediction method exhibits a relative error of 14.5%, whereas the compensated data demonstrates a relative prediction error of only 5.7%. The above analysis indicates that for actual awareness data, prediction algorithms cannot maintain the high prediction accuracy during simulation due to the volatility and randomness inherent in the data. Nevertheless, the joint compensation algorithm presented in this paper has the potential to enhance the accuracy and reliability of the data.
From the
Figure 5c,d, it can be seen that the actual awareness data are similar to the simulation results in this article in terms of overall trend. However, spikes are observed at certain time points, indicating sudden increases or decreases in rate. This is due to the protocol acceleration of actual switch hardware or differences in switch output queue management strategies, leading to more complex characteristics of actual awareness data and consequently affecting the corresponding prediction performance. From
Figure 5c, the prediction results based on actual measurement data have a large error in the 55th time slot. The relative error of the prediction method is 21.6%, while the relative error of the compensation method is 9.3%, indicating a significant improvement in data accuracy. From
Figure 5d, it can be seen that for the time period of 60 to 65, when there is significant fluctuation in the data, the predicted results for the resource situation at the node are opposite to the actual data. However, the compensation method, by comprehensively considering the perception latency data and the predicted results, can not only reduce relative errors but also retain the trend of resource data changes, further improving the reliability of the data and providing support for subsequent resource allocation.
Figure 6 presents a comparison of the SRCR for various datasets following network resource allocation utilizing the accelerated ADMM algorithm. It can be seen from the figure that when the number of service requests is less than 80, the SRCR is 100% in all data scenarios; that is, the service resource requirements in the network can be met at this time. The resource allocation approach, which relies on awareness data, suffers from the inherent latency, resulting in outdated resource status information for certain nodes and consequently rendering some services unable to fulfill their resource coverage needs. Based on the predicted results, the SRCR effect is weaker than that of the compensation data. Due to significant fluctuations in prediction accuracy, the corresponding SRCR also experiences fluctuations, resulting in poor stability of allocation performance. The SRCR based on compensation data aligns closely with the actual onboard data, accurately reflecting node status and capacity and demonstrating an effective SRCR. When the number of service requests reaches 200, the SCRC based on compensation data deviates from the actual onboard data by just 10.2%, representing a 15.8% improvement over the predicted data and a 62% enhancement compared to the awareness data with latency. Consequently, the resource allocation method using compensation data can significantly enhance the efficiency of network resource utilization.
Figure 7 presents a comparison of the SRCR among the proposed NRA-PPJC algorithm and two other algorithms in various service scenarios. The HEAA algorithm [
27] is a historical experience average method which uses each node to allocate corresponding resources for services on an average basis according to historical experience. PBRA is a priority-based network resource allocation method [
28] which gives precedence to the re-source requirements of high-priority services. It can be seen from the figure that the SRCR of the NRA-PPJC method proposed in this paper is higher than that of the HEAA algorithm because HEAA does not take into account the differences in resource requirements between services, and the average division of resources for each service leads to wasted resources when the number of service requests increases. The PBRA algorithm allocates resources for high-priority services, so when the number of service requests is small, its SRCR is higher than that of the NRA-PPJC algorithm. As the number of service requests grows, despite some nodes having surplus resources, they can no longer fulfill the requirements of additional service demands. The SRCR consequently declines rapidly and may even fall below that of the HEAA algorithm once a specific service threshold is reached. Taking a number of services of 160 as an example, the network experiences a moderate demand pressure for service resources. In comparison to HEAA, the SRCR of NRA-PPJC has an improvement of 20.4% and a 4.17% increase when compared to the PBRA, which means it can effectively allocate based on business resource requirements and onboard resource status.
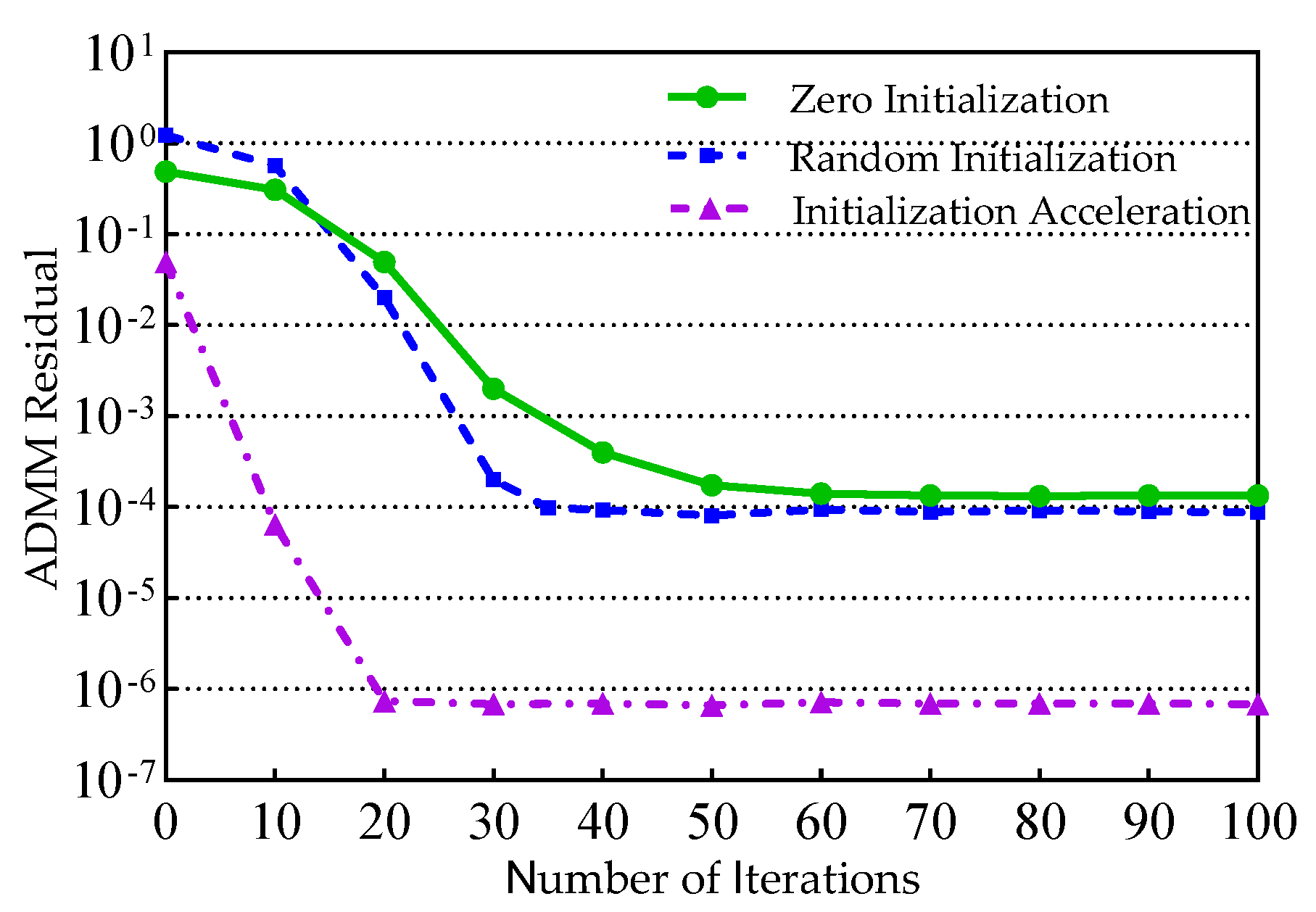
Figure 8 shows the comparison of convergence speed of the proposed ADMM algorithm with other common initialization scenarios. From the graph, it can be seen that both zero initialization and random initialization [
29] have residual values greater than those based on the compensation data. Moreover, since the initialization method may initially align local and global variables closer to a local optimal solution, its convergence speed tends to be faster than that of the zero-initialization approach. The dynamic initialization approach proposed in this paper, which is based on compensated data, facilitates the rapid update of local variables, subsequently expediting the convergence of global variables. When compared to the zero-initialization method, this approach enhances convergence speed by 60%, and when compared to the random initialization method, it improves by 41%.


 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}