
Heterogeneous Graph Neural-Network-Based Scheduling Optimization for Multi-Product and Variable-Batch Production in Flexible Job Shops


Abstract
1. Introduction
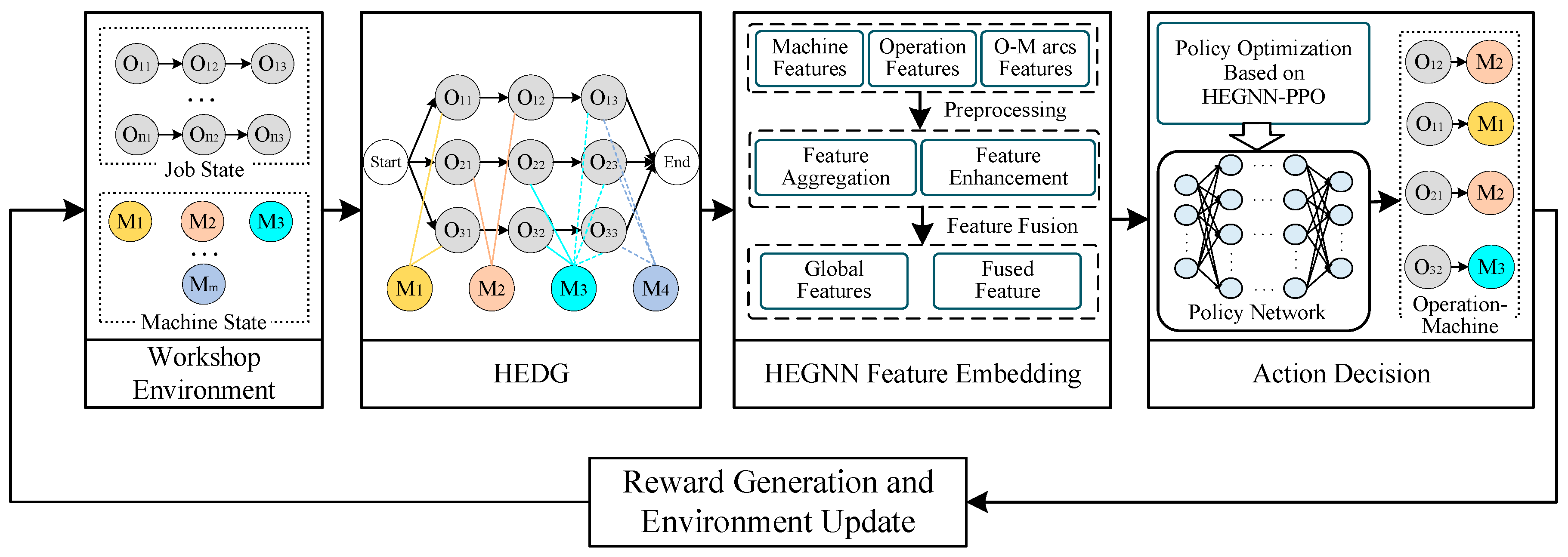
- This study introduces the HEDG structure for modeling the FJSP. The HEDG captures both the precedence constraints and the compatibility between operations and machines, enabling dynamic, real-time updates of scheduling states. This dynamic feature enhances traditional static models, making the framework adaptable to changing production environments and real-time scheduling decisions.
- A heterogeneous enhanced graph neural network (HEGNN) architecture is proposed to extract rich feature representations from the HEDG. By effectively capturing the complex interactions and dependencies between operations and machines, the HEGNN enhances the feature representation, providing deep insights into the scheduling state. This leads to improved decision-making for both operation assignment and machine selection.
- The integration of HEGNN with the PPO algorithm allows for joint optimization of both operation assignment and machine selection. This end-to-end learning framework adapts dynamically, avoiding the pitfalls of local optima that are common in traditional rule-based methods. The method’s effectiveness is further validated through its ability to handle various FJSP instances with different production scales, confirming its practical applicability in real-world industrial settings.
2. Problem Formulation
2.1. Problem Definition and Assumptions
- (1)
- Completeness of Job Processing: Every job must complete all its constituent operations.
- (2)
- Non-Interruptibility and No Rework: Once a job starts processing, it cannot be interrupted or subjected to rework.
- (3)
- Precedence Constraints: There are strict precedence relations between different operations within the same job, enforcing a specific execution order.
- (4)
- Machine Assignment: Each operation must be processed on one and only one assigned machine.
- (5)
- Deterministic Processing Times: The processing time for each operation is fixed and known in advance for each eligible machine.
- (6)
- Inclusive Setup Times: The setup times required for each operation are encompassed within the processing times.
- (7)
- Machine Exclusivity: At any given moment, a machine can process only one operation.
2.2. Mathematical Model Building
3. Method
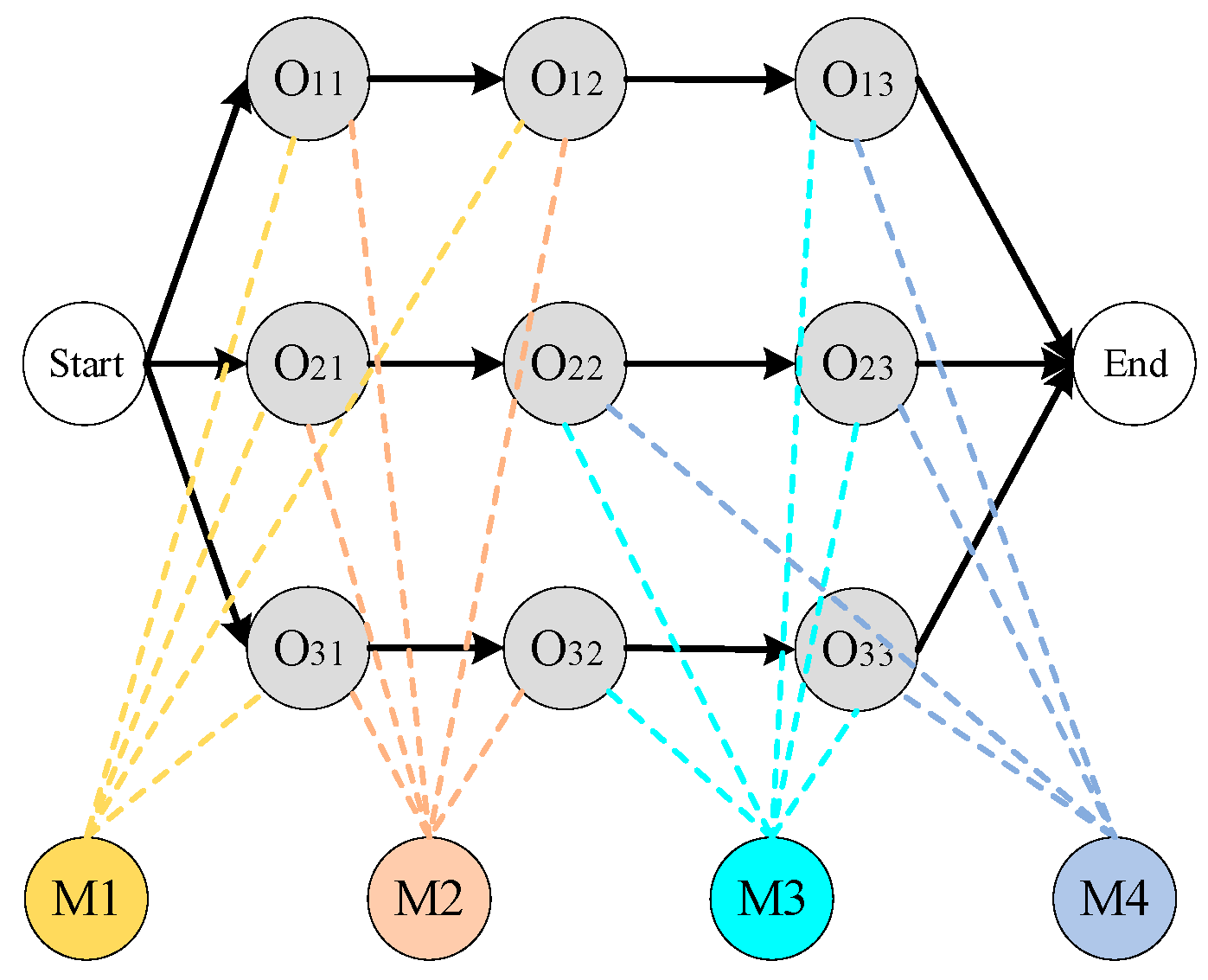
3.1. Heterogeneous Enhanced Disjunctive Graph Model
- includes all operation nodes and two virtual operation nodes representing the start and end points of the scheduling process (with zero processing time).
- represents all machines in the workshop.
- is the set of conjunctive arcs that define the product’s processing routes. For example, the arc → indicates that operation begins processing after the completion of operation .
- is the set of O−M arcs that connect operation nodes to machine nodes. Each element is an undirected arc connecting operation node with a selectable machine node .
- (1)
- Scheduling Status: Indicates whether the operation has been scheduled (0 or 1).
- (2)
- Number of Adjacent machines: The number of available machines that can be selected for processing.
- (3)
- Number of Unscheduled Operations: The count of subsequent unscheduled operations within the current job.
- (4)
- Proportion of Unscheduled Operations: The ratio of unscheduled operations to the total number of operations in the current job.
- (5)
- Priority: The priority of the job defined based on the delivery date as .
- (6)
- Processing Time: If scheduled, this is the actual processing time ; otherwise, it is the estimated average processing time , calculated as the average processing time across all available machines.
- (7)
- Start Time: The estimated or actual start time during partial scheduling. If operation has been scheduled, represents the actual start time. If has not been scheduled, the start time is predicted based on the status of preceding operations and available machines. Specifically, if the preceding operation has started processing on machine , then . Otherwise, the estimated average processing time is used for prediction.
- (8)
- Job Completion Time: The estimated or actual completion time during partial scheduling. If operation has been scheduled, the completion time is . If has not been scheduled, the completion time is predicted as , where is the estimated start time and is the average processing time.
- (1)
- Available Time: The time at which the machine becomes available after completing all currently scheduled operations.
- (2)
- Number of Adjacent Operations: The number of operations that the machine is capable of processing.
- (3)
- Utilization: The ratio of the machine’s operating time to the total elapsed time, ranging between 0 and 1.
- (1)
- Processing Time: The processing time of operation on machine .
3.2. Markov Decision Process
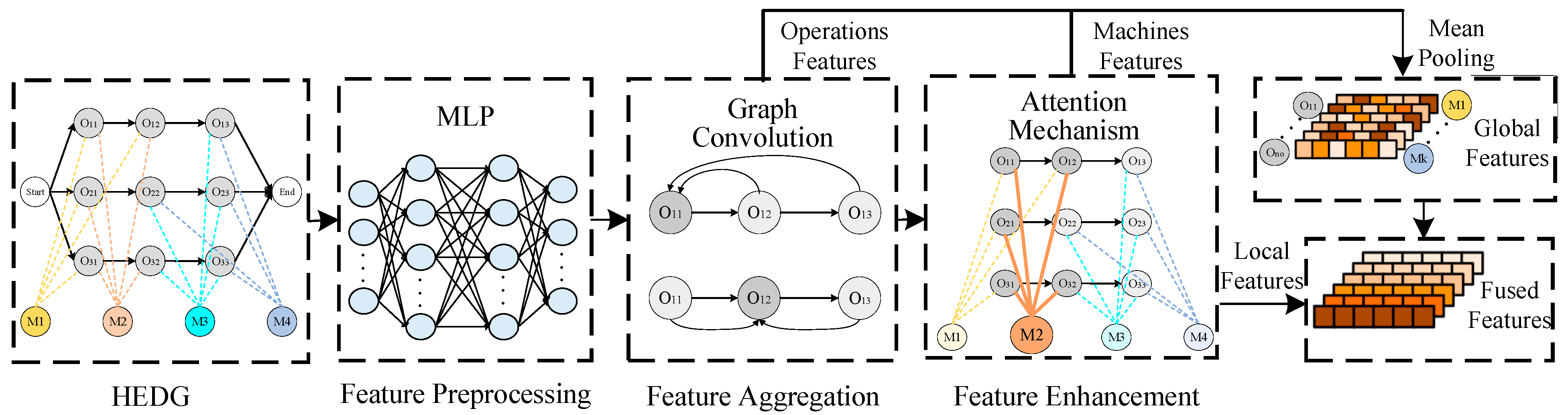
3.3. Heterogeneous Enhanced Graph Neural Network Feature Embedding Framework
- (1)
- Feature Preprocessing: The features of operation nodes and machine nodes are normalized and enhanced to eliminate dimensional differences among feature dimensions. This step improves the representational capability of the features.
- (2)
- Node Feature Aggregation: Using graph convolutional operations, the framework aggregates the neighboring features of operation nodes, capturing the local structural information among nodes and updating the feature representation of the nodes.
- (3)
- Attention-Based Feature Enhancement: A multi-head attention mechanism is introduced to dynamically adjust the weights of machine nodes in aggregating the features of operation nodes. This enhances the model’s ability to capture complex relationships.
- (4)
- Feature Fusion: After extracting local features, global pooling operations are performed to extract global features. These local and global features are then fused to provide more comprehensive feature support for scheduling decisions.
3.3.1. Feature Preprocessing
3.3.2. Node Feature Aggregation
3.3.3. Attention Feature Enhancement
3.3.4. Feature Fusion
3.4. Scheduling Policy Optimization Algorithm Based on HEGNN-PPO
3.4.1. Scheduling Decision
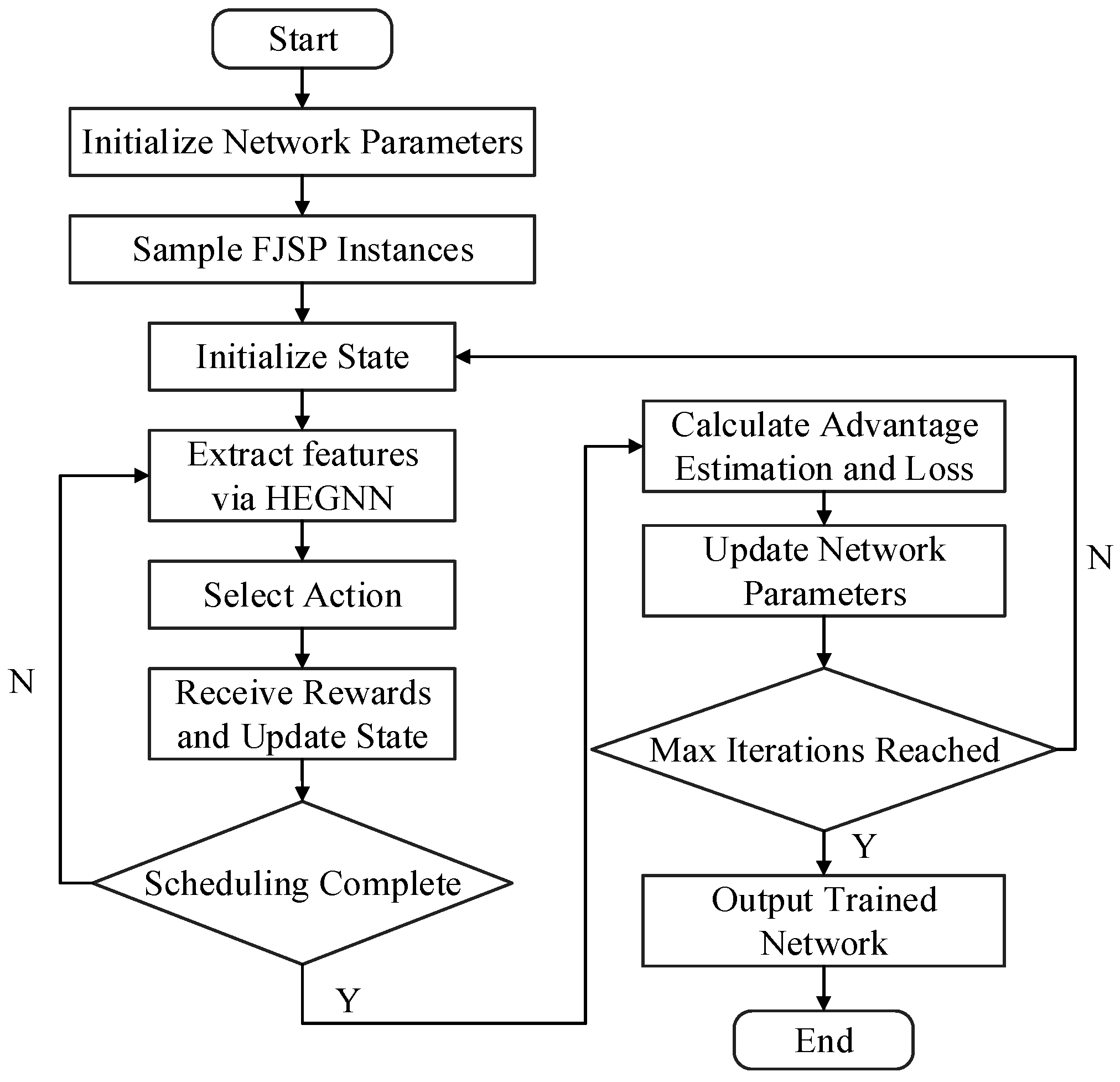
3.4.2. Algorithm Training
| Algorithm 1: Training Process |
| Initialize HEGNN network parameters ; |
| Initialize policy network parameters ; |
| Initialize critic network parameters ; |
| Sample an initial S of FJSP instances with batch size B; |
| for i = 1, 2, …, I do: |
| if i mod 20 == 1 then |
| sample (B) new FJSP instances; |
| Initialize the experience buffer D; |
| for b = 1, 2, …, B do: |
| Initialize the state based on instance b; |
| while is not a terminal state do: |
| Extract features ; |
| Sample action according to the policy ; |
| Select action , obtain reward and next state ; |
| Store the experience in buffer D; |
| Update the state ; |
| end while |
| end for |
| for k = 1 to K do: |
| Randomly shuffle D and divide it into batches |
| Compute the estimated advantages and the loss for each batch; |
| Update the network parameters and ; |
| end for |
| if i mod 10 = 0 then |
| evaluate the current policy performance using the validation set; |
| end if |
| end for |
| Output: the trained network parameters; |
4. Experiment
4.1. Experimental Design
4.2. Experimental Results and Comparison
- AC-SD Method [46]: An end-to-end DRL framework based on an improved pointer network and attention mechanisms, considering both static and dynamic features.
- DRL-AC Method [47]: A reinforcement learning approach based on an actor–critic architecture, utilizing parameterized priority rules and Beta distribution action sampling.
- Combinations of Shortest Processing Time (SPT + NINQ), Most Work Remaining (MWKR + NINQ), and Earliest Due Date (EDD + NINQ) rules.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| FJSP | Flexible Job-shop Scheduling Problem |
| DRL | Deep Reinforcement Learning |
| GNN | Graph Neural Network |
| HEDG | Heterogeneous Enhanced Disjunctive Graph |
| HEGNN | Heterogeneous Enhanced Graph Neural Network |
| PPO | Proximal Policy Optimization |
| MDP | Markov Decision Process |
| MILP | Mixed-Integer Linear Programming |
| MLP | Multi-Layer Perceptron |
| CNN | Convolutional Neural Networks |
| HDPSO | Hybrid Discrete Particle Swarm Optimization |
| DDPG | Deep Deterministic Policy Gradient |
| PDRs | Priority Dispatching Rules |
| JSSP | Job Shop Scheduling Problem |
References
- Zhang, J.; Ding, G.; Zou, Y.; Qin, S.; Fu, J. Review of Job Shop Scheduling Research and Its New Perspectives under Industry 4.0. J. Intell. Manuf. 2019, 30, 1809–1830. [Google Scholar] [CrossRef]
- Kusiak, A. Smart Manufacturing. Int. J. Prod. Res. 2018, 56, 508–517. [Google Scholar] [CrossRef]
- Zhang, X.; Ming, X.; Bao, Y. A Flexible Smart Manufacturing System in Mass Personalization Manufacturing Model Based on Multi-Module-Platform, Multi-Virtual-Unit, and Multi-Production-Line. Comput. Ind. Eng. 2022, 171, 108379. [Google Scholar] [CrossRef]
- Ji, S.; Wang, Z.; Yan, J. A Multi-Type Data Driven Framework for Solving Flexible Job Shop Scheduling Problem Considering Multiple Production Resource States. Comput. Ind. Eng. 2025, 200, 110835. [Google Scholar] [CrossRef]
- Xie, J.; Gao, L.; Peng, K.; Li, X.; Li, H. Review on Flexible Job Shop Scheduling. IET Collab. Intell. Manuf. 2019, 1, 67–77. [Google Scholar] [CrossRef]
- Li, J.; Li, H.; He, P.; Xu, L.; He, K.; Liu, S. Flexible Job Shop Scheduling Optimization for Green Manufacturing Based on Improved Multi-Objective Wolf Pack Algorithm. Appl. Sci. 2023, 13, 8535. [Google Scholar] [CrossRef]
- Gao, K.; Cao, Z.; Zhang, L.; Chen, Z.; Han, Y.; Pan, Q. A Review on Swarm Intelligence and Evolutionary Algorithms for Solving Flexible Job Shop Scheduling Problems. IEEE/CAA J. Autom. Sin. 2019, 6, 904–916. [Google Scholar] [CrossRef]
- Zheng, P.; Xiao, S.; Zhang, P.; Lv, Y. A Two-Individual-Based Evolutionary Algorithm for Flexible Assembly Job Shop Scheduling Problem with Uncertain Interval Processing Times. Appl. Sci. 2024, 14, 10304. [Google Scholar] [CrossRef]
- Kong, J.; Yang, Y. Research on Multi-Objective Flexible Job Shop Scheduling Problem with Setup and Handling Based on an Improved Shuffled Frog Leaping Algorithm. Appl. Sci. 2024, 14, 4029. [Google Scholar] [CrossRef]
- Li, X.; Guo, X.; Tang, H.; Wu, R.; Wang, L.; Pang, S.; Liu, Z.; Xu, W.; Li, X. Survey of Integrated Flexible Job Shop Scheduling Problems. Comput. Ind. Eng. 2022, 174, 108786. [Google Scholar] [CrossRef]
- Meng, L.; Zhang, C.; Shao, X.; Ren, Y. MILP Models for Energy-Aware Flexible Job Shop Scheduling Problem. J. Clean. Prod. 2019, 210, 710–723. [Google Scholar] [CrossRef]
- Ortíz, M.A.; Betancourt, L.E.; Negrete, K.P.; De Felice, F.; Petrillo, A. Dispatching Algorithm for Production Programming of Flexible Job-Shop Systems in the Smart Factory Industry. Ann. Oper. Res. 2018, 264, 409–433. [Google Scholar] [CrossRef]
- Lv, Q.H.; Chen, J.; Chen, P.; Xun, Q.F.; Gao, L. Flexible Job-Shop Scheduling Problem with Parallel Operations Using Reinforcement Learning: An Approach Based on Heterogeneous Graph Attention Networks. Adv. Prod. Eng. Manag. 2024, 19, 157–181. [Google Scholar] [CrossRef]
- Zhang, C.; Song, W.; Cao, Z.; Zhang, J.; Tan, P.S.; Chi, X. Learning to Dispatch for Job Shop Scheduling via Deep Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1621–1632. [Google Scholar]
- Chen, B.; Matis, T.I. A Flexible Dispatching Rule for Minimizing Tardiness in Job Shop Scheduling. Int. J. Prod. Econ. 2013, 141, 360–365. [Google Scholar] [CrossRef]
- Sobeyko, O.; Mönch, L. Heuristic Approaches for Scheduling Jobs in Large-Scale Flexible Job Shops. Comput. Oper. Res. 2016, 68, 97–109. [Google Scholar] [CrossRef]
- Türkyılmaz, A.; Şenvar, Ö.; Ünal, İ.; Bulkan, S. A Research Survey: Heuristic Approaches for Solving Multi Objective Flexible Job Shop Problems. J. Intell. Manuf. 2020, 31, 1949–1983. [Google Scholar] [CrossRef]
- Stanković, A.; Petrović, G.; Ćojbašić, Ž.; Marković, D. An Application of Metaheuristic Optimization Algorithms for Solving the Flexible Job-Shop Scheduling Problem. Oper. Res. Eng. Sci. Theory Appl. 2020, 3, 13–28. [Google Scholar] [CrossRef]
- Kui, C.; Li, B. Research on FJSP of Improved Particle Swarm Optimization Algorithm Considering Transportation Time. J. Syst. Simul. 2021, 33, 845–853. [Google Scholar] [CrossRef]
- Mei, Z.; Lu, Y.; Lv, L. Research on Multi-Objective Low-Carbon Flexible Job Shop Scheduling Based on Improved NSGA-II. Machines 2024, 12, 590. [Google Scholar] [CrossRef]
- Heik, D.; Bahrpeyma, F.; Reichelt, D. Study on the Application of Single-Agent and Multi-Agent Reinforcement Learning to Dynamic Scheduling in Manufacturing Environments with Growing Complexity: Case Study on the Synthesis of an Industrial IoT Test Bed. J. Manuf. Syst. 2024, 77, 525–557. [Google Scholar] [CrossRef]
- Huang, D.; Zhao, H.; Tian, W.; Chen, K. A Deep Reinforcement Learning Method Based on a Multiexpert Graph Neural Network for Flexible Job Shop Scheduling. Comput. Ind. Eng. 2025, 200, 110768. [Google Scholar] [CrossRef]
- Bouazza, W.; Sallez, Y.; Beldjilali, B. A Distributed Approach Solving Partially Flexible Job-Shop Scheduling Problem with a Q-Learning Effect. IFAC-PapersOnLine 2017, 50, 15890–15895. [Google Scholar] [CrossRef]
- Chen, R.; Yang, B.; Li, S.; Wang, S. A Self-Learning Genetic Algorithm Based on Reinforcement Learning for Flexible Job-Shop Scheduling Problem. Comput. Ind. Eng. 2020, 149, 106778. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, X.; Liu, X.; Zhang, L.; Wei, S.; Zhang, W. An Effective Two-Stage Algorithm Based on Convolutional Neural Network for the Bi-Objective Flexible Job Shop Scheduling Problem with Machine Breakdown. Expert Syst. Appl. 2022, 203, 117460. [Google Scholar] [CrossRef]
- Zhao, Y.; Wang, Y.; Tan, Y.; Zhang, J.; Yu, H. Dynamic Jobshop Scheduling Algorithm Based on Deep Q Network. IEEE Access 2021, 9, 122995–123011. [Google Scholar] [CrossRef]
- Song, W.; Chen, X.; Li, Q.; Cao, Z. Flexible Job-Shop Scheduling via Graph Neural Network and Deep Reinforcement Learning. IEEE Trans. Ind. Inform. 2023, 19, 1600–1610. [Google Scholar] [CrossRef]
- Liu, C.-L.; Chang, C.-C.; Tseng, C.-J. Actor-Critic Deep Reinforcement Learning for Solving Job Shop Scheduling Problems. IEEE Access 2020, 8, 71752–71762. [Google Scholar] [CrossRef]
- Du, Y.; Li, J.; Li, C.; Duan, P. A Reinforcement Learning Approach for Flexible Job Shop Scheduling Problem with Crane Transportation and Setup Times. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 5695–5709. [Google Scholar] [CrossRef]
- Du, Y.; Li, J.; Chen, X.; Duan, P.; Pan, Q. Knowledge-Based Reinforcement Learning and Estimation of Distribution Algorithm for Flexible Job Shop Scheduling Problem. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 7, 1036–1050. [Google Scholar] [CrossRef]
- He, Z.; Tran, K.P.; Thomassey, S.; Zeng, X.; Xu, J.; Yi, C. Multi-Objective Optimization of the Textile Manufacturing Process Using Deep-Q-Network Based Multi-Agent Reinforcement Learning. J. Manuf. Syst. 2022, 62, 939–949. [Google Scholar] [CrossRef]
- Tassel, P.; Gebser, M.; Schekotihin, K. A Reinforcement Learning Environment for Job-Shop Scheduling. arXiv 2021. [Google Scholar] [CrossRef]
- Liu, C.-L.; Huang, T.-H. Dynamic Job-Shop Scheduling Problems Using Graph Neural Network and Deep Reinforcement Learning. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 6836–6848. [Google Scholar] [CrossRef]
- Fattahi, P.; Saidi Mehrabad, M.; Jolai, F. Mathematical Modeling and Heuristic Approaches to Flexible Job Shop Scheduling Problems. J. Intell. Manuf. 2007, 18, 331–342. [Google Scholar] [CrossRef]
- Park, J.; Chun, J.; Kim, S.H.; Kim, Y.; Park, J. Learning to Schedule Job-Shop Problems: Representation and Policy Learning Using Graph Neural Network and Reinforcement Learning. Int. J. Prod. Res. 2021, 59, 3360–3377. [Google Scholar] [CrossRef]
- Wang, D.; Liu, S.; Zou, J.; Qiao, W.; Jin, S. Flexible Robotic Cell Scheduling with Graph Neural Network Based Deep Reinforcement Learning. J. Manuf. Syst. 2025, 78, 81–93. [Google Scholar] [CrossRef]
- Liu, R.; Piplani, R.; Toro, C. A Deep Multi-Agent Reinforcement Learning Approach to Solve Dynamic Job Shop Scheduling Problem. Comput. Oper. Res. 2023, 159, 106294. [Google Scholar] [CrossRef]
- Jing, X.; Yao, X.; Liu, M.; Zhou, J. Multi-Agent Reinforcement Learning Based on Graph Convolutional Network for Flexible Job Shop Scheduling. J. Intell. Manuf. 2024, 35, 75–93. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, H.; Tang, D.; Zhou, T.; Gui, Y. Dynamic Job Shop Scheduling Based on Deep Reinforcement Learning for Multi-Agent Manufacturing Systems. Robot. Comput.-Integr. Manuf. 2022, 78, 102412. [Google Scholar] [CrossRef]
- Zhang, W.; Zhao, F.; Li, Y.; Du, C.; Feng, X.; Mei, X. A Novel Collaborative Agent Reinforcement Learning Framework Based on an Attention Mechanism and Disjunctive Graph Embedding for Flexible Job Shop Scheduling Problem. J. Manuf. Syst. 2024, 74, 329–345. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4–24. [Google Scholar] [CrossRef]
- Tang, H.; Dong, J. Solving Flexible Job-Shop Scheduling Problem with Heterogeneous Graph Neural Network Based on Relation and Deep Reinforcement Learning. Machines 2024, 12, 584. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, L.; Liu, Y.; Zhao, C.; Wang, K. Solving Task Scheduling Problems in Cloud Manufacturing via Attention Mechanism and Deep Reinforcement Learning. J. Manuf. Syst. 2022, 65, 452–468. [Google Scholar] [CrossRef]
- Luo, S. Dynamic Scheduling for Flexible Job Shop with New Job Insertions by Deep Reinforcement Learning. Appl. Soft Comput. 2020, 91, 106208. [Google Scholar] [CrossRef]
- Brandimarte, P. Routing and Scheduling in a Flexible Job Shop by Tabu Search. Ann. Oper. Res. 1993, 41, 157–183. [Google Scholar] [CrossRef]
- Han, B.A.; Yang, J.J. A Deep Reinforcement Learning Based Solution for Flexible Job Shop Scheduling Problem. Int. J. Simul. Model. 2021, 20, 375–386. [Google Scholar] [CrossRef]
- Zhao, C.; Deng, N. An Actor-Critic Framework Based on Deep Reinforcement Learning for Addressing Flexible Job Shop Scheduling Problems. Math. Biosci. Eng. 2023, 21, 1445–1471. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Category | Advantages | Disadvantages | |
|---|---|---|---|
| Exact Methods | Mathematical Programming/ Constraint Programming et al. | (1) Precise modeling (2) Theoretically optimal solutions | (1) High computational complexity (2) Long computation time for large-scale problems |
| Approximate Methods | Rule-Based Heuristics | (1) Low computational cost (2) Simple implementation | (1) Local optimization (2) Poor solution quality |
| Intelligent Optimization Algorithms | (1) Near-optimal solutions | (1) High complexity (2) Parameter sensitivity | |
| CNN/MLP-Based DRL | (1) Adaptable to dynamic environments | (1) Limited scalability for varying complexity (2) Ignores node relationships | |
| GNN-Based DRL | (1) Captures topological dependencies | Oversimplified node heterogeneity handling | |
| Parameters | Definitions |
|---|---|
| Makespan (maximum completion time across all jobs) | |
| , 0 otherwise | |
| , 0 otherwise | |
| based on due date urgency | |
| Current time, representing a specific time point in the scheduling process |
| Instance | Number of Jobs | Number of Operations Per Job | Maximum Number of Selectable Machines | Processing Time (h) |
|---|---|---|---|---|
| S1 | 10 | [5, 10] | [3, 5] | [0.5, 36] |
| S2 | 15 | |||
| S3 | 20 | |||
| S4 | 25 | |||
| S5 | 30 |
| Composite Dispatching Rule | Descriptions |
|---|---|
| SPT + NINQ | Shortest Processing Time + Fewest Idle Number of Queues |
| SPT + WINQ | Shortest Processing Time + Fewest Work in Number of Queues |
| MWKR + NINQ | Maximum Work Remaining + Fewest Idle Number of Queues |
| MWKR + WINQ | Maximum Work Remaining + Fewest Work in Number of Queues |
| EDD + NINQ | Earliest Due Date + Fewest Idle Number of Queues |
| EDD + WINQ | Earliest Due Date + Fewest Work in Number of Queues |
| Parameters | Value |
|---|---|
| Dimension of node embedding | 16 |
| Dimension of the MLP hidden layer | 128 |
| Dimension of policy network and value network | 64 |
| Number of layers in policy network and value network | 3 |
| Number of attention heads | 4 |
| Number of iterations | 2000 |
| Batch size | 20 |
| Discount factor | 0.99 |
| Optimizer | Adam |
| Learning rate | 3 × 10⁻⁴ |
| Clipping ratio | 0.2 |
| Policy loss coefficient | 1 |
| Value loss coefficient | 0.5 |
| Exploration strategy | linear decay from 0.5 to 0.1 |
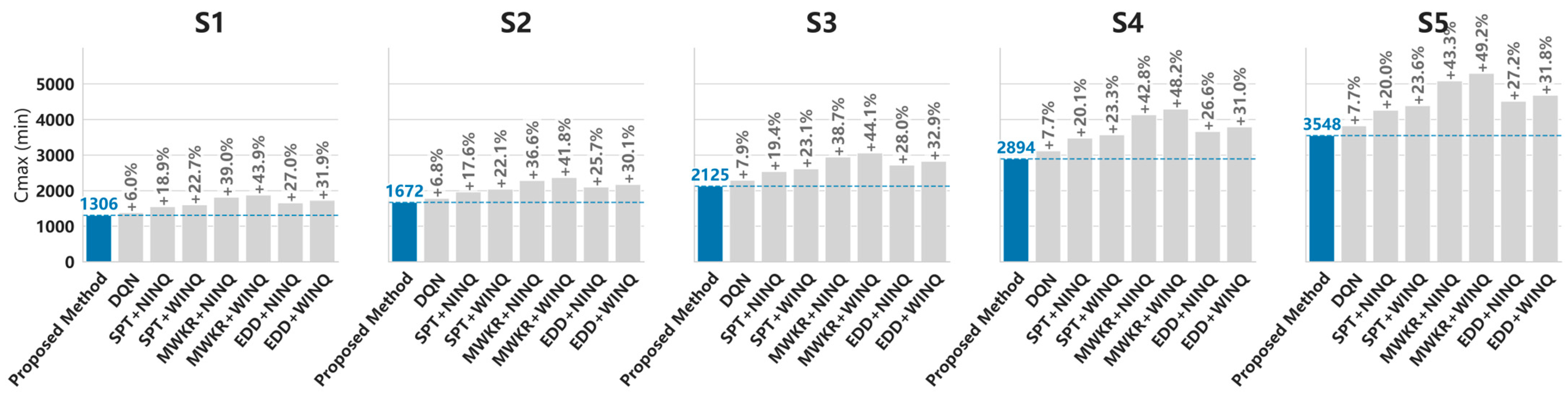
| Method | S1 | S2 | S3 | S4 | S5 |
|---|---|---|---|---|---|
| Proposed Method | 1306 | 1672 | 2125 | 2894 | 3548 |
| DQN | 1384 | 1786 | 2293 | 3117 | 3821 |
| SPT + NINQ | 1553 | 1967 | 2538 | 3476 | 4259 |
| SPT + WINQ | 1602 | 2041 | 2615 | 3568 | 4387 |
| MWKR + NINQ | 1815 | 2284 | 2947 | 4132 | 5083 |
| MWKR + WINQ | 1879 | 2371 | 3062 | 4289 | 5295 |
| EDD + NINQ | 1658 | 2102 | 2719 | 3664 | 4512 |
| EDD + WINQ | 1723 | 2176 | 2825 | 3791 | 4678 |
| Method | S1 | S2 | S3 | S4 | S5 |
|---|---|---|---|---|---|
| Proposed Method | 0.32 | 0.63 | 0.99 | 1.27 | 1.9 |
| DQN | 0.85 | 1.12 | 1.45 | 1.98 | 2.35 |
| SPT + NINQ | 0.15 | 0.29 | 0.42 | 0.58 | 0.87 |
| SPT + WINQ | 0.15 | 0.31 | 0.44 | 0.6 | 0.9 |
| MWKR + NINQ | 0.16 | 0.31 | 0.45 | 0.6 | 0.93 |
| MWKR + WINQ | 0.16 | 0.33 | 0.48 | 0.65 | 0.98 |
| EDD + NINQ | 0.17 | 0.35 | 0.5 | 0.68 | 1.05 |
| EDD + WINQ | 0.18 | 0.36 | 0.52 | 0.7 | 1.1 |
| Instance | DRL-Based Methods | Rule-Based Heuristic Methods | ||||
|---|---|---|---|---|---|---|
| Proposed Method | [46] | [47] | SPT + NINQ | MWKR + NINQ | EDD + NINQ | |
| MK01 | 52 | 48 | 45 | 49 | 57 | 55 |
| MK02 | 34 | 34 | 31 | 43 | 41 | 39 |
| MK03 | 212 | 235 | 220 | 205 | 234 | 230 |
| MK04 | 73 | 77 | 72 | 78 | 99 | 78 |
| MK05 | 182 | 192 | 185 | 184 | 202 | 184 |
| MK06 | 90 | 121 | 97 | 92 | 114 | 92 |
| MK07 | 199 | 216 | 210 | 214 | 220 | 214 |
| MK08 | 528 | 523 | 534 | 541 | 579 | 541 |
| MK09 | 340 | 375 | 356 | 350 | 397 | 350 |
| MK10 | 263 | 317 | 283 | 278 | 294 | 278 |
| Average | 197.1 | 213.8 | 203.3 | 203.4 | 223.7 | 206.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, Y.; Lyu, Y.; Zhang, J.; Chu, Y. Heterogeneous Graph Neural-Network-Based Scheduling Optimization for Multi-Product and Variable-Batch Production in Flexible Job Shops. Appl. Sci. 2025, 15, 5648. https://doi.org/10.3390/app15105648
Peng Y, Lyu Y, Zhang J, Chu Y. Heterogeneous Graph Neural-Network-Based Scheduling Optimization for Multi-Product and Variable-Batch Production in Flexible Job Shops. Applied Sciences. 2025; 15(10):5648. https://doi.org/10.3390/app15105648
Chicago/Turabian StylePeng, Yuxin, Youlong Lyu, Jie Zhang, and Ying Chu. 2025. "Heterogeneous Graph Neural-Network-Based Scheduling Optimization for Multi-Product and Variable-Batch Production in Flexible Job Shops" Applied Sciences 15, no. 10: 5648. https://doi.org/10.3390/app15105648
APA StylePeng, Y., Lyu, Y., Zhang, J., & Chu, Y. (2025). Heterogeneous Graph Neural-Network-Based Scheduling Optimization for Multi-Product and Variable-Batch Production in Flexible Job Shops. Applied Sciences, 15(10), 5648. https://doi.org/10.3390/app15105648