
Testing Pretrained Large Language Models to Set Up a Knowledge Hub of Heterogeneous Multisource Environmental Documents

 ,
,  , , ,
, , ,  , and
, and
Abstract
1. Introduction
- First, the application of pretrained foundation LLMs for the ad hoc retrieval task of heterogeneous documents with highly variable length is still an open issue [9];
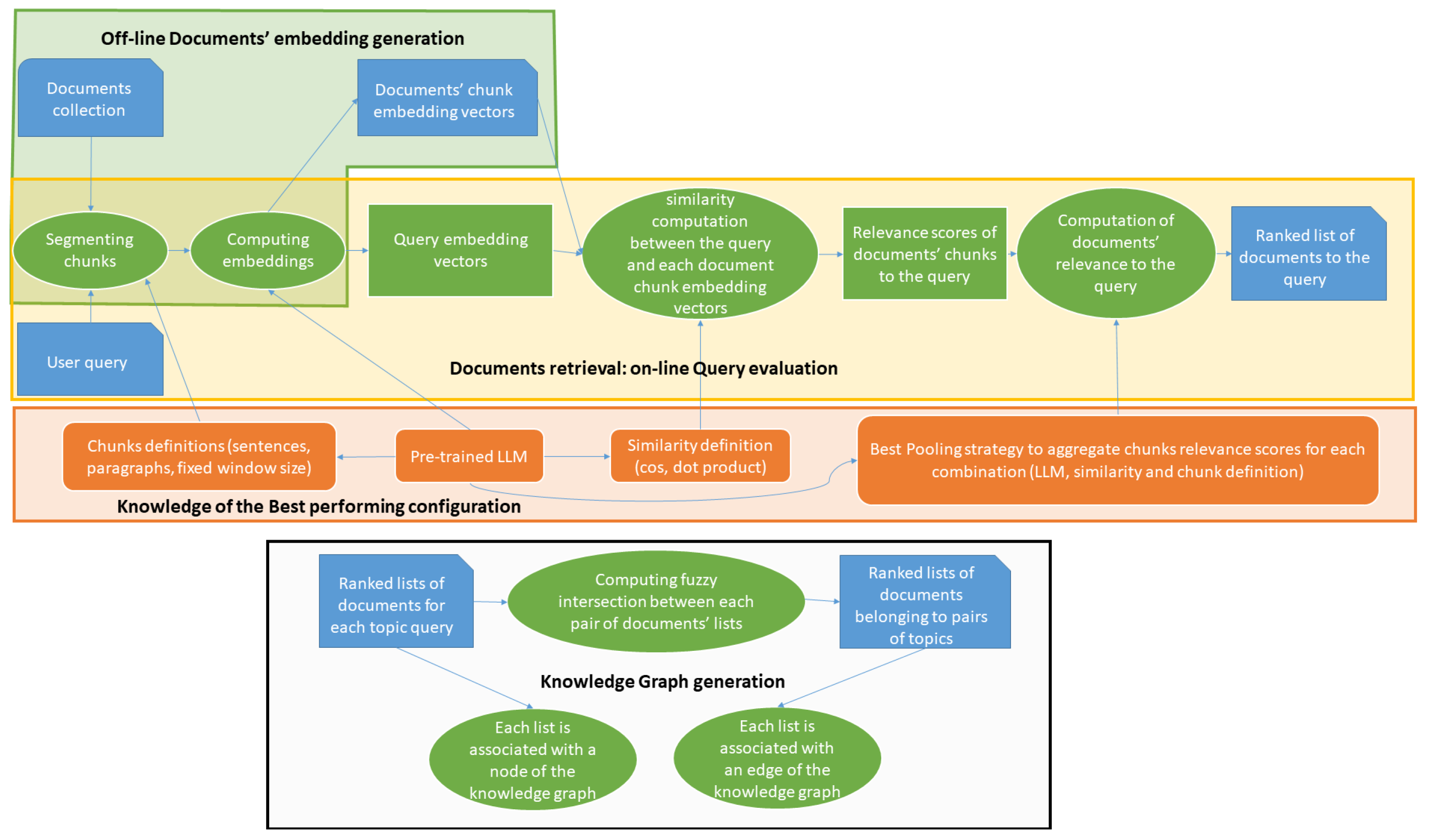
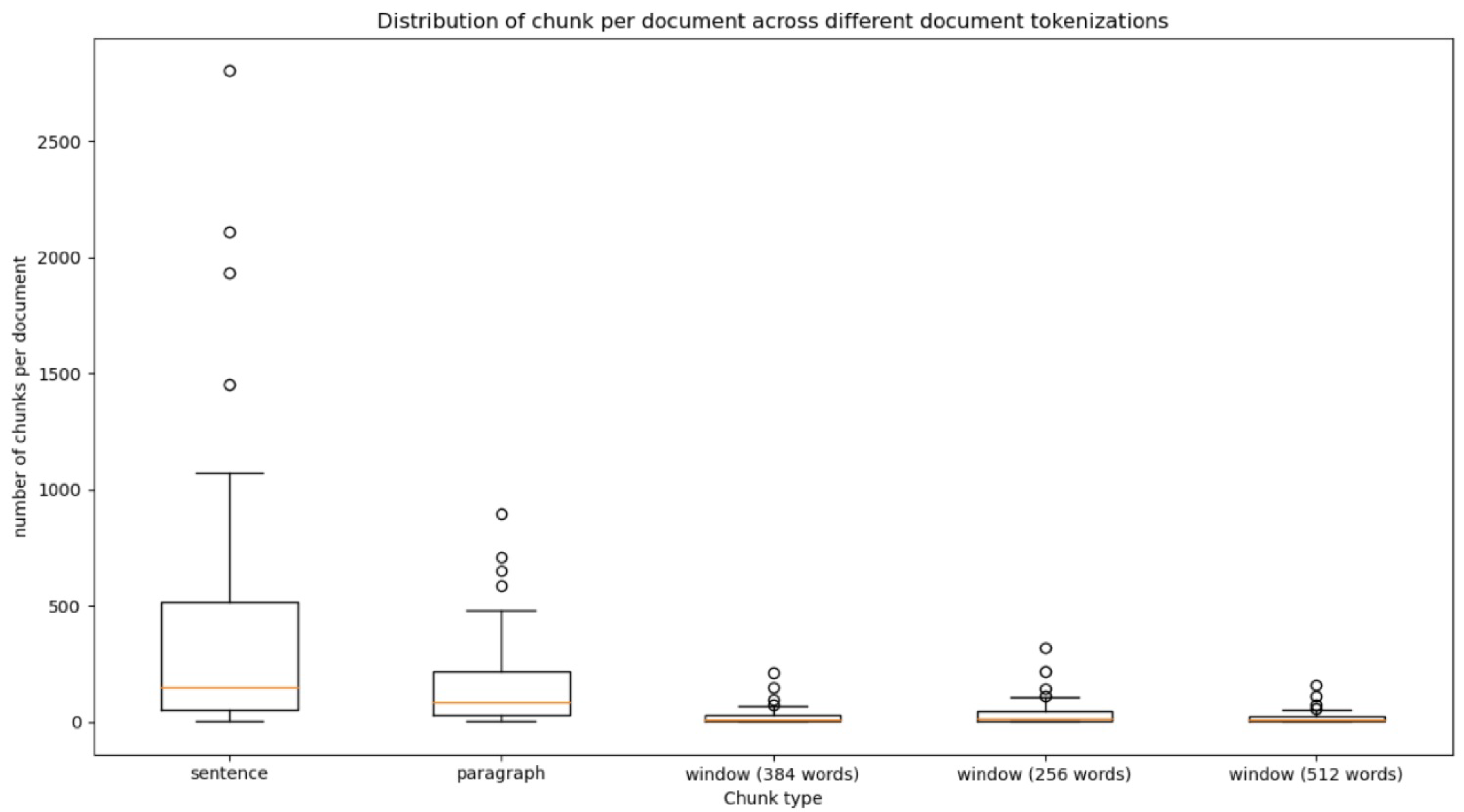
- Second, the following need to be investigated: the identification of the most effective combination of pretrained LLMs and the settings of both the document segments, named chunks, that are represented by embedding vectors, and the similarity matching function.
- Ultimately, the idea of constructing a kind of knowledge graph in which nodes represent concepts (topic meanings in this case) pertinent to a specific application, as described in various documents, mirror the fusion of different instances of these concepts discussed in each document. This last aspect is only proposed herein at the theoretical level and is not yet implemented.
2. Materials and Methods
2.1. Harvesting Documents’ Collection
2.2. Enabling Document Search
- (a)
- msmarco-distilbert-cos-v5 [22,25]: It maps sentences and paragraphs to a 768-dimensional dense vector space and was designed for “semantic” search. It has been trained on 500k (query, answer) pairs from the MS MARCO Passages dataset (Microsoft Machine Reading Comprehension), which is a large-scale dataset focused on machine reading comprehension, question answering, and passage ranking.
- (b)
- all-MiniLM-L6-v2 [26]: It maps sentences and paragraphs to a 384-dimensional dense vector space and can be used for tasks like clustering or “semantic” search.
- (c)
- msmarco-roberta-base-ance-firstp [27,28]: This is a port of the ANCE FirstP model, which uses a training mechanism to select more realistic negative training instances to the sentence-transformer model. It maps sentences and paragraphs to a 768-dimensional dense vector space and can be used for tasks like clustering or “semantic” search.
- (d)
- msmarco-bert-base-dot-v5 [29]: It maps sentences and paragraphs to a 768-dimensional dense vector space and was designed for “semantic” search. It has been trained on 500K (query, answer) pairs from the MS MARCO dataset.
- (e)
- msmarco-distilbert-base-tas-b [30]: It is a port of the DistilBert TAS-B model to the sentence-transformer model. It maps sentences and paragraphs to a 768-dimensional dense vector space and is optimized for the task of “semantic” search.
2.3. Approach for the Fuzzy Classification of Documents into Topics
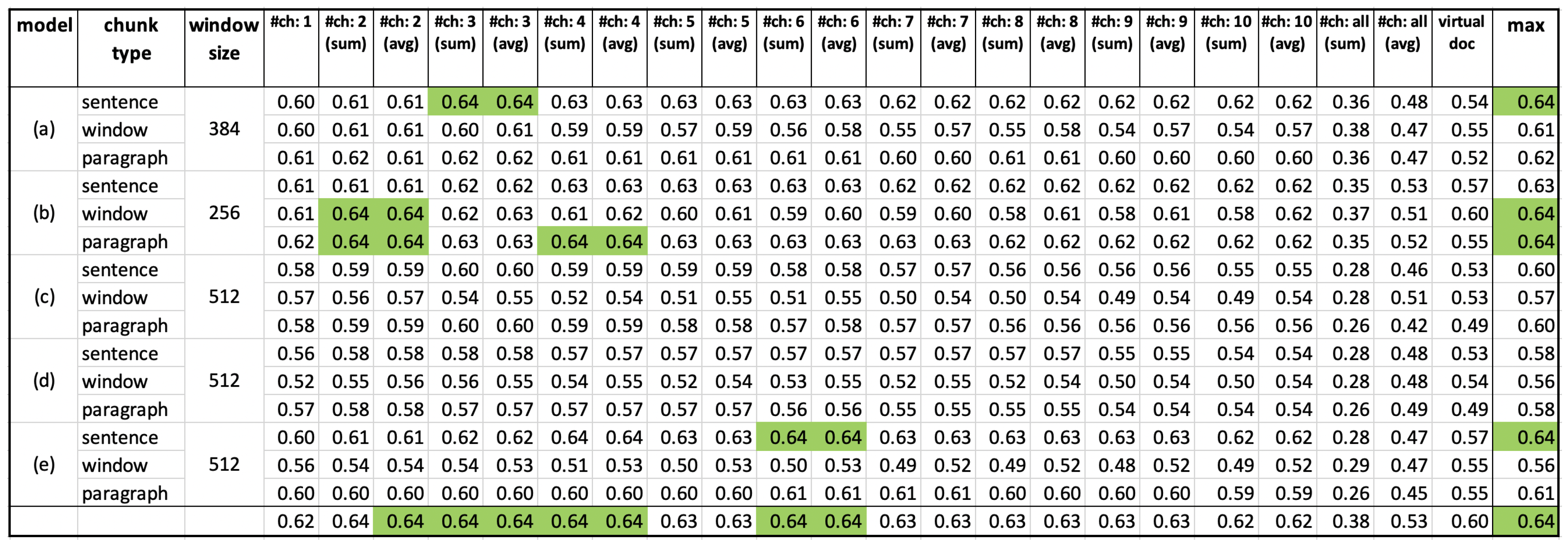
3. Results: The User-Evaluation Experiment of the Pretrained LLMs
- “#ch: N (sum)” indicates that the sum of the first N best chunk scores of each document was computed;
- “#ch: N (avg)” indicates that the average of the first N best chunk scores of each document was computed.
4. Discussion
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| UNEP/MAP | Mediterranean Action Plan of the United Nations Environmental Programme |
| KH | Knowledge Hub |
| KMaP | Knowledge Management Platform |
| Portable Document Format | |
| HTML | HyperText Markup Language |
| JPG | Joint Photographic Experts Group image compression format |
| IR | Information Retrieval |
| LLM | Large Language Model |
| RAC | Regional Activty Centre |
| REMPEC | Regional Marine Pollution Emergency Response Centre |
| for the Mediterranean Sea | |
| SPA/RAC | Regional Activity Centre for Specially Protected Areas |
| SCP/RAC | Regional Activity Centre for Sustainable Consumption and Production |
| PAP/RAC | Priority Actions Programme/Regional Activity Centre |
| CNR-IREA | National Research Council of Italy |
| Institute for the Electromagnetic Sensing of the Environment | |
| GNU GPL | GNU General Public License |
| BERT | Bidirectional Encoder Representations from Transformers |
| NLTK | Natural Language Toolkit |
| KNN | K-Nearest Neighbor |
| RSV | Relevance Score Value |
| RDF | Resource Description Framework |
| SKOS | Simple Knowledge Organization System |
| SPARQL | SPARQL Protocol and RDF Query Language |
| mAP | Mean Average Precision |
References
- UNEP. Mediterranean Action Plan (MAP)—Barcelona Convention. Available online: https://www.unep.org/mediterranean-action-plan-map-barcelona-convention (accessed on 1 March 2025).
- Bordogna, G.; Tagliolato, P.; Lotti, A.; Minelli, A.; Oggioni, A.; Babbini, L. Report 2—Semantic Information Retrieval–Knowledge Hub. Zenodo 2023. [Google Scholar] [CrossRef]
- Tagliolato Acquaviva d’Aragona, P.; Babbini, L.; Bordogna, G.; Lotti, A.; Minelli, A.; Oggioni, A. Design of a Knowledge Hub of Heterogeneous Multisource Documents to support Public Authorities. In Proceedings of the Ital-IA Intelligenza Artificiale—Thematic Workshops Co-Located with the 4th CINI National Lab AIIS Conference on Artificial Intelligence (Ital-IA 2024), Naples, Italy, 29–30 May 2024; Martino, S.D., Sansone, C., Masciari, E., Rossi, S., Gravina, M., Eds.; CEUR-WS.org, 2024, CEUR Workshop Proceedings. Volume 3762, pp. 458–463. [Google Scholar]
- Kadhim, A.I. Survey on supervised machine learning techniques for automatic text classification. Artif. Intell. Rev. 2019, 52, 273–292. [Google Scholar] [CrossRef]
- Oggioni, A.; Bordogna, G.; Lotti, A.; Minelli, A.; Tagliolato, P.; Babbini, L. Types of Users and Requirements—Report 0. Zenodo 2023. [Google Scholar] [CrossRef]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval, Online Edition; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Zhou, C.; Li, Q.; Li, C.; Yu, J.; Liu, Y.; Wang, G.; Zhang, K.; Ji, C.; Yan, Q.; He, L.; et al. A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT. arXiv 2023, arXiv:2302.09419. [Google Scholar] [CrossRef]
- Kraft, D.H.; Bordogna, G.; Pasi, G. Fuzzy Set Techniques in Information Retrieval. In Fuzzy Sets in Approximate Reasoning and Information Systems; Bezdek, J.C., Dubois, D., Prade, H., Eds.; Springer: Boston, MA, USA, 1999; pp. 469–510. [Google Scholar] [CrossRef]
- Wang, J.; Huang, J.X.; Tu, X.; Wang, J.; Huang, A.J.; Laskar, M.T.R.; Bhuiyan, A. Utilizing BERT for Information Retrieval: Survey, Applications, Resources, and Challenges. ACM Comput. Surv. 2024, 56, 1–33. [Google Scholar] [CrossRef]
- REMPEC. Regional Marine Pollution Emergency Response Centre for the Mediterranean Sea (REMPEC). Available online: https://www.rempec.org (accessed on 1 March 2025).
- SPA/RAC. Regional Activity Centre for Specially Protected Areas. Available online: https://www.rac-spa.org (accessed on 1 March 2025).
- SCP/RAC. Regional Activity Centre for Sustainable Consumption and Production. Available online: http://www.cprac.org (accessed on 1 March 2025).
- PAP/RAC. Priority Actions Programme/Regional Activity Centre. Available online: https://paprac.org (accessed on 1 March 2025).
- UNEP/MAP. UNEP/MAP: All Publications. Available online: https://www.unep.org/unepmap/resources/publications?/resources (accessed on 1 March 2025).
- United Nations Environment Program. United Nations Environment Program: Documents Repository. Available online: https://wedocs.unep.org/discover?filtertype=author&filter_relational_operator=equals&filter=UNEP%20MAP (accessed on 1 March 2025).
- Scraping Library. Available online: https://github.com/INFO-RAC/KMP-library-scraping (accessed on 1 March 2025).
- Inforac Ground Truth Data Used for the User Evaluation Experiment. Available online: https://github.com/IREA-CNR-MI/inforac_ground_truth (accessed on 1 March 2025).
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-art Natural Language Processing. arXiv 2020, arXiv:1910.03771. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 4–9 December 2017; NIPS’17. pp. 6000–6010. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MI, USA, 6 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; pp. 4171–4186. [Google Scholar] [CrossRef]
- Ding, M.; Zhou, C.; Yang, H.; Tang, J. CogLTX: Applying BERT to Long Texts. In Proceedings of the Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: San Jose, CA, USA, 2020; Volume 33, pp. 12792–12804. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Hong Kong, China, 3–7 November 2019. [Google Scholar] [CrossRef]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python, 1st ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Yager, R.R. On the fuzzy cardinality of a fuzzy set. Int. J. Gen. Syst. 2006, 35, 191–206. [Google Scholar] [CrossRef]
- Reimers, N.; Espejel, O.; Cuenca, P.; Aarsen, T. Msmarco-Distilbert-Cos-v5 Model Card. Available online: https://huggingface.co/sentence-transformers/msmarco-distilbert-cos-v5 (accessed on 1 March 2025).
- Reimers, N.; Espejel, O.; Cuenca, P.; Aarsen, T. All-MiniLM-L6-v2 Model Card. Available online: https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2 (accessed on 1 March 2025).
- Xiong, L.; Xiong, C.; Li, Y.; Tang, K.F.; Liu, J.; Bennett, P.; Ahmed, J.; Overwijk, A. Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval. arXiv 2020, arXiv:2007.00808. [Google Scholar] [CrossRef]
- Reimers, N.; Espejel, O.; Cuenca, P.; Aarsen, T. Msmarco-Roberta-Base-Ance-Firstp Model Card. Available online: https://huggingface.co/sentence-transformers/msmarco-roberta-base-ance-firstp (accessed on 1 March 2025).
- Reimers, N.; Espejel, O.; Cuenca, P.; Aarsen, T. Msmarco-Bert-Base-Dot-v5 Model Card. Available online: https://huggingface.co/sentence-transformers/msmarco-bert-base-dot-v5 (accessed on 1 March 2025).
- Reimers, N.; Espejel, O.; Cuenca, P.; Aarsen, T. Msmarco-Distilbert-Base-Tas-b Model Card. Available online: https://huggingface.co/sentence-transformers/msmarco-distilbert-base-tas-b (accessed on 1 March 2025).
- UNESCO Thesaurus. Available online: http://vocabularies.unesco.org/thesaurus (accessed on 1 March 2025).
- Get-It Inforac Thesaurus—Linked Open Data Access. Available online: http://rdfdata.get-it.it/inforac/ (accessed on 1 March 2025).
- Get-It Inforac Thesaurus—Sparql Endpoint (Web Service). Available online: http://fuseki1.get-it.it/dataset.html (accessed on 1 March 2025).
- Beitzel, S.M.; Jensen, E.C.; Frieder, O. MAP. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: Boston, MA, USA, 2009; pp. 1691–1692. [Google Scholar] [CrossRef]
- Smucker, M.D.; Allan, J.; Carterette, B. A comparison of statistical significance tests for information retrieval evaluation. In Proceedings of the Sixteenth ACM Conference on Conference on Information and Knowledge Management, New York, NY, USA, 6–10 November 2007; CIKM’07; pp. 623–632. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Topic Keyword | Definition Source |
|---|---|
| Climate change | United Nations (UN) |
| Marine biodiversity | UN |
| Sustainability and blue economy | UN |
| Pollution | National Geographic |
| Marine spatial planning | EU Commission |
| Fishery and aquaculture | FAO |
| Governance | UN Dev. Progr. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tagliolato Acquaviva d’Aragona, P.; Bordogna, G.; Babbini, L.; Lotti, A.; Minelli, A.; Zilioli, M.; Oggioni, A. Testing Pretrained Large Language Models to Set Up a Knowledge Hub of Heterogeneous Multisource Environmental Documents. Appl. Sci. 2025, 15, 5415. https://doi.org/10.3390/app15105415
Tagliolato Acquaviva d’Aragona P, Bordogna G, Babbini L, Lotti A, Minelli A, Zilioli M, Oggioni A. Testing Pretrained Large Language Models to Set Up a Knowledge Hub of Heterogeneous Multisource Environmental Documents. Applied Sciences. 2025; 15(10):5415. https://doi.org/10.3390/app15105415
Chicago/Turabian StyleTagliolato Acquaviva d’Aragona, Paolo, Gloria Bordogna, Lorenza Babbini, Alessandro Lotti, Annalisa Minelli, Martina Zilioli, and Alessandro Oggioni. 2025. "Testing Pretrained Large Language Models to Set Up a Knowledge Hub of Heterogeneous Multisource Environmental Documents" Applied Sciences 15, no. 10: 5415. https://doi.org/10.3390/app15105415
APA StyleTagliolato Acquaviva d’Aragona, P., Bordogna, G., Babbini, L., Lotti, A., Minelli, A., Zilioli, M., & Oggioni, A. (2025). Testing Pretrained Large Language Models to Set Up a Knowledge Hub of Heterogeneous Multisource Environmental Documents. Applied Sciences, 15(10), 5415. https://doi.org/10.3390/app15105415