
Region-of-Interest Extraction Method to Increase Object-Detection Performance in Remote Monitoring System



Abstract
:1. Introduction
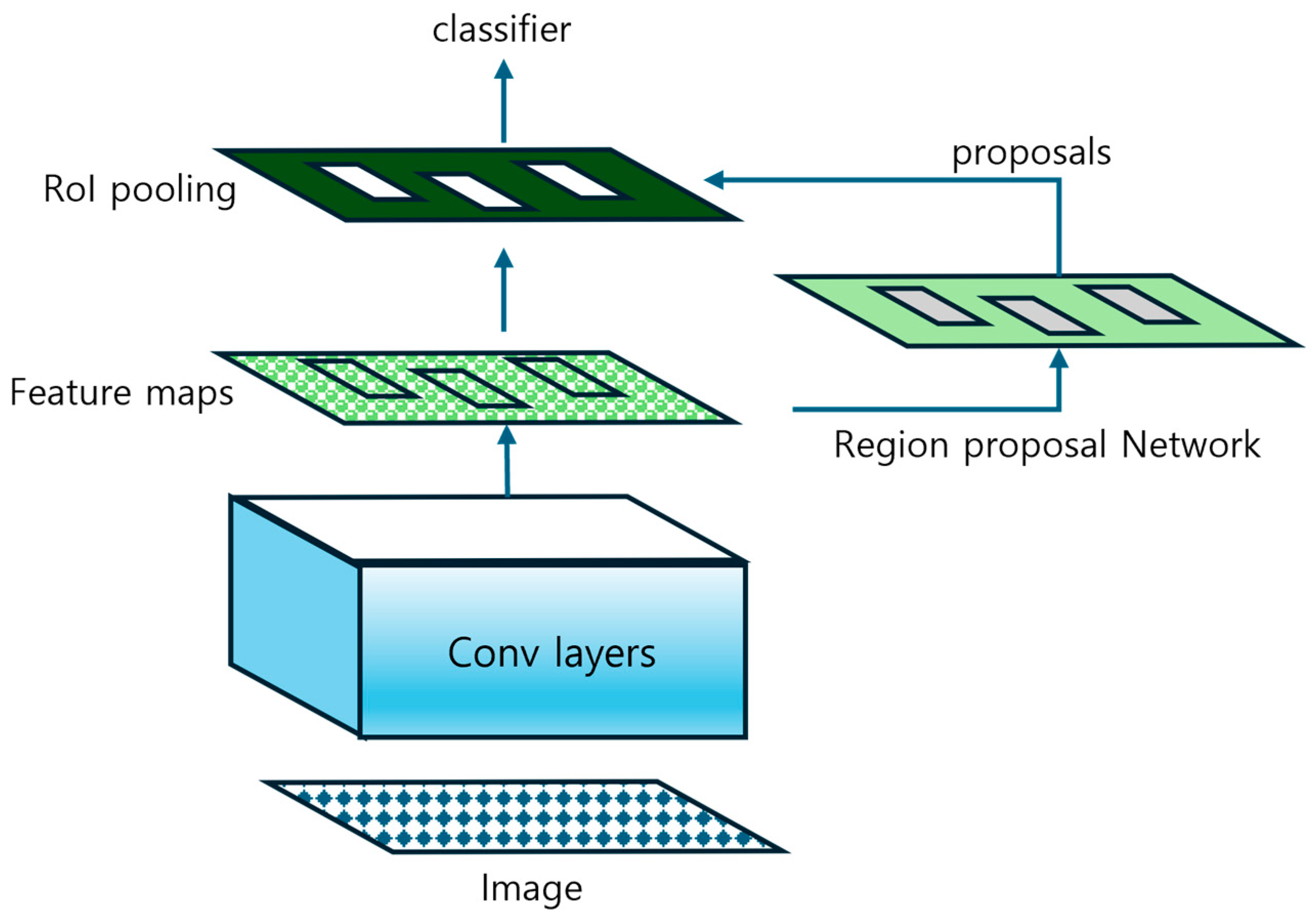
2. Related Research
3. Proposed Method
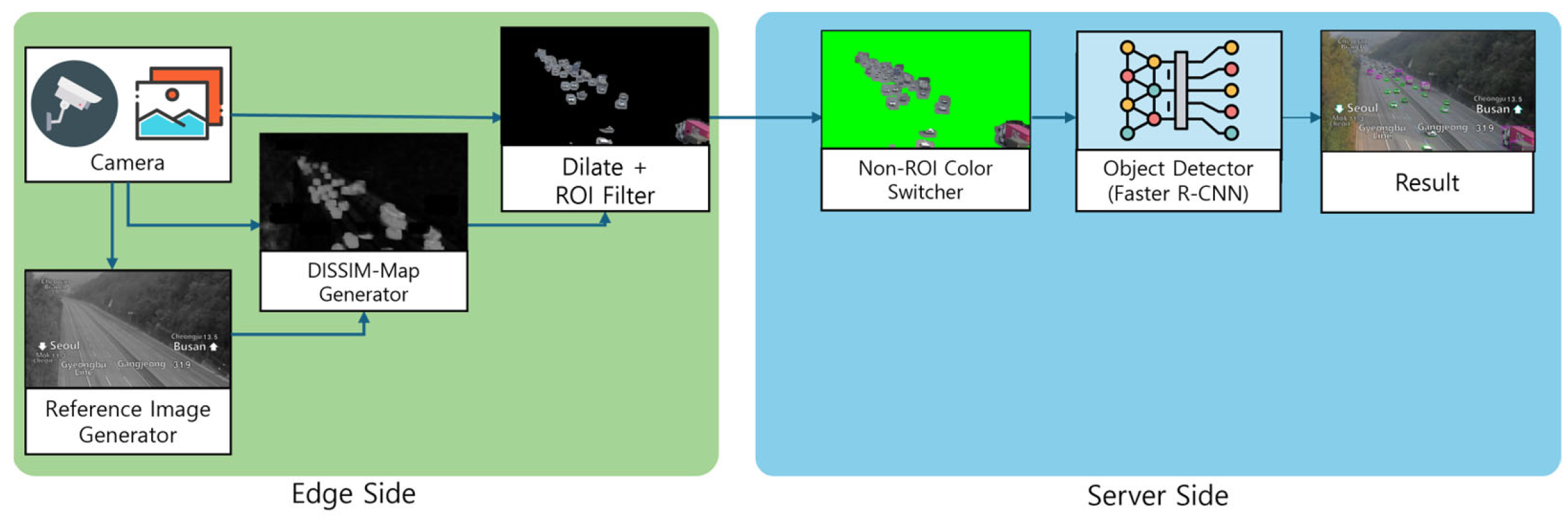
3.1. Method Overview
3.2. Reference Image Generator
| Algorithm 1: Background Extraction using Gaussian Mixture Modeling |
| Input: video—input video sequence |
| Parameters: width—width of video frame |
| height—height of video frame |
| channels—number of color channels in video frame |
| numClusters—number of Gaussian clusters (default: 2) |
| Output: backgroundImage—static background reference image |
| procedure ExtractBackground(video) |
| stackedFramesframes ← Stack(ExtractFramesFromVideo(video)) |
| backgroundImage ← InitializeImage(width, height, channels) |
| for x = 0 to width-1 do |
| for y = 0 to height-1 do |
| for c = 0 to channels-1 do |
| pixelIntensities[] ← extract intensities(stackedFrames, x, y, c) |
| clusters[] ← fit GaussianMixtureModel(pixelIntensities, numClusters = 2) |
| dominantCluster ← get most weighted cluster(clusters) |
| backgroundImage[x, y, c] ← dominantCluster.mean |
| return backgroundImage |
3.3. DSSIM-Map Generator
3.4. ROI Filter
3.5. Non-ROI Color Switcher
3.6. Object Detector
4. Implementation
4.1. Experiment Environment
4.1.1. Datasets
4.1.2. Experimental Environment
4.2. Edge Side
4.2.1. Reference Image Generator
4.2.2. DSSIM Generator
4.2.3. ROI Filter
4.2.4. Video Transmission
4.3. Server Side
4.3.1. Model
4.3.2. Inference Time
4.3.3. Model Performance
4.4. Objectness Clarification Process
4.4.1. Method to Enhance Objectness
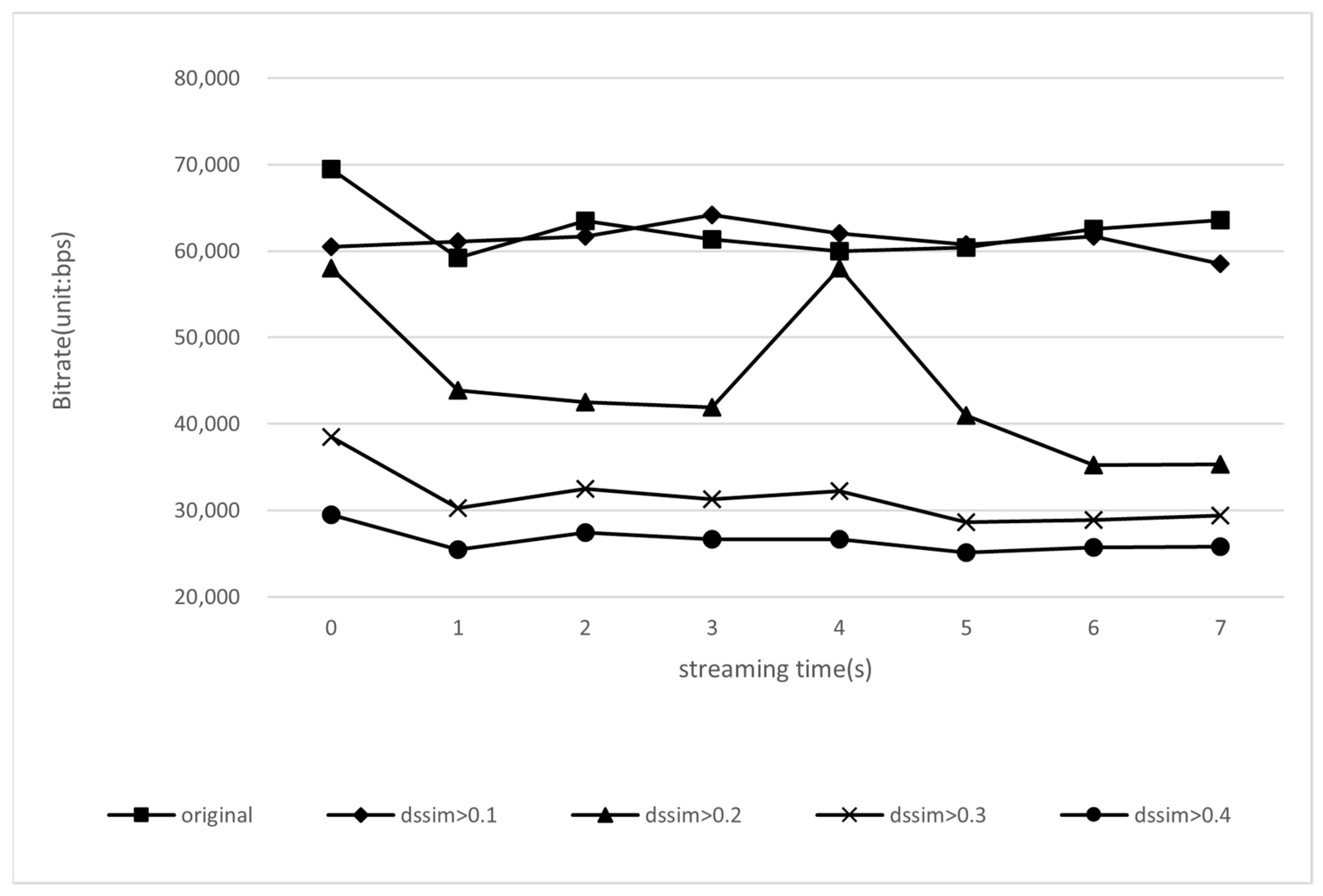
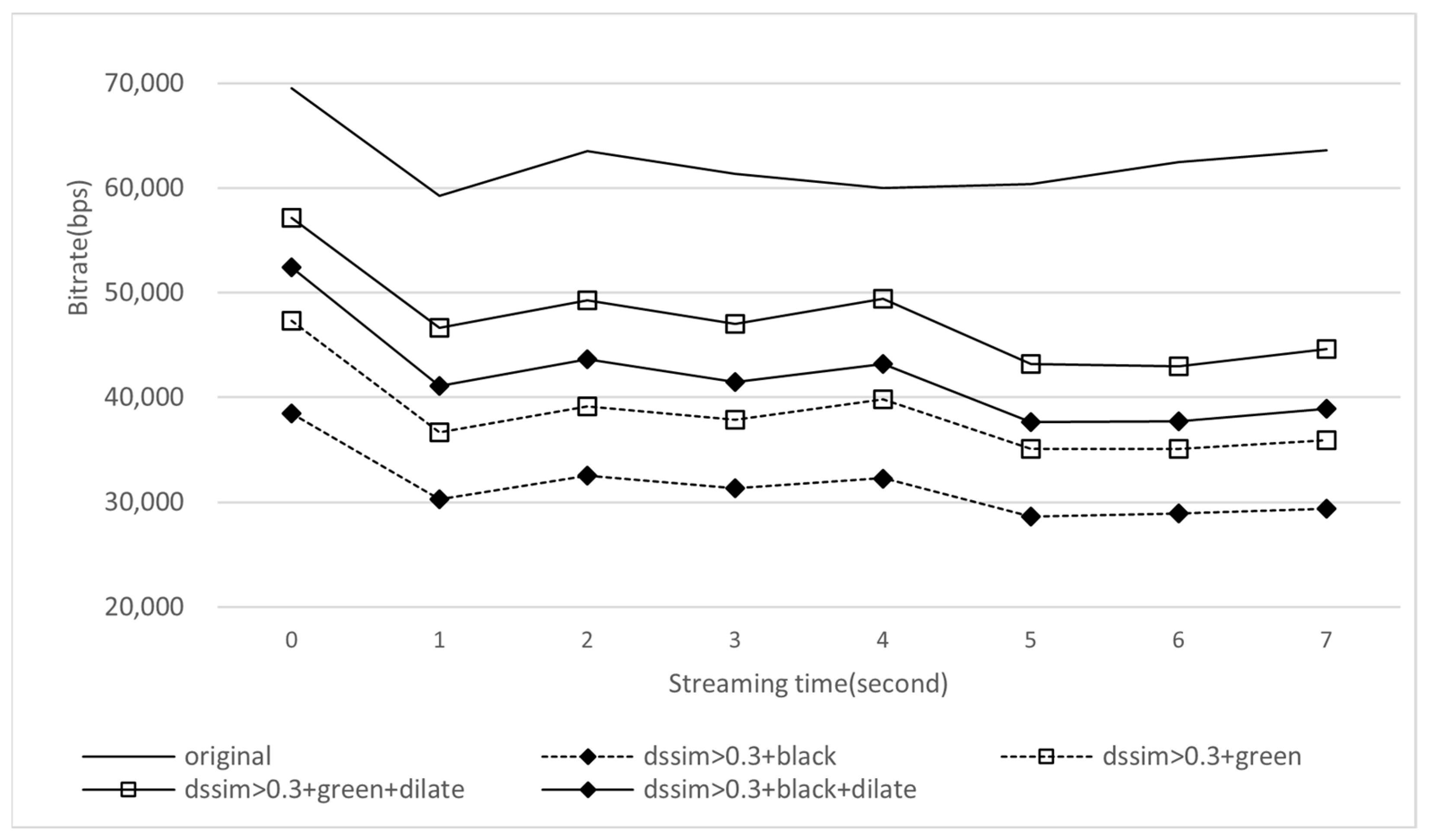
4.4.2. Bitrate
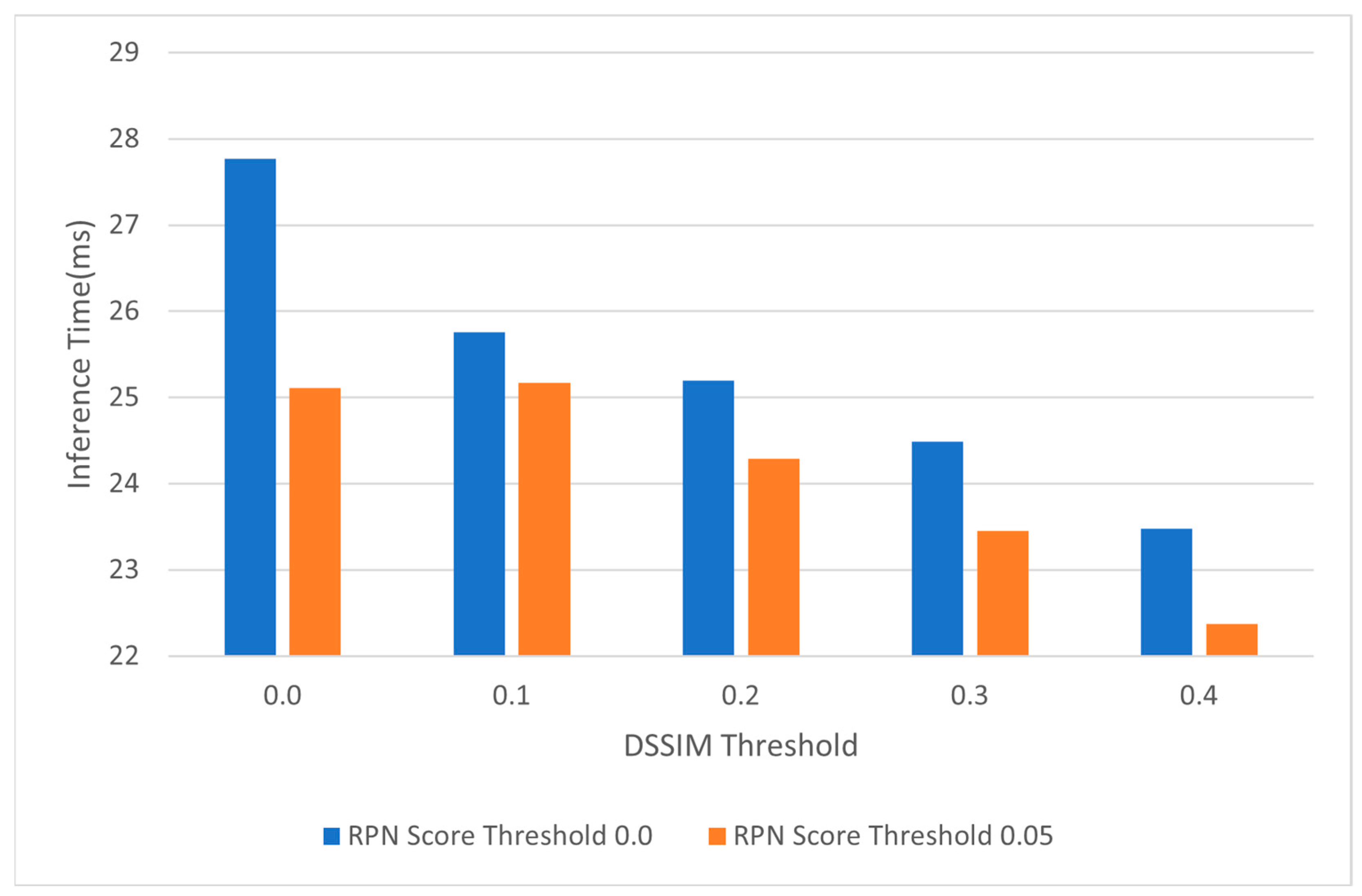
4.4.3. Inference Time
4.4.4. Model Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Navalgund, U.V.; Priyadharshini, K. Crime Intention Detection System Using Deep Learning. In Proceedings of the 2018 International Conference on Circuits and Systems in Digital Enterprise Technology (ICCSDET), Kottayam, India, 21–22 December 2018; pp. 1–6. [Google Scholar]
- Liu, Y.-X.; Yang, Y.; Shi, A.; Jigang, P.; Haowei, L. Intelligent Monitoring of Indoor Surveillance Video Based on Deep Learning. In Proceedings of the 2019 21st International Conference on Advanced Communication Technology (ICACT), PyeongChang, Republic of Korea, 17–20 February 2019; pp. 648–653. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Uijlings, J.R.R.; van de Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 February 2015; pp. 1440–1448. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.-Y. DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection. arXiv 2022, arXiv:2203.03605. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar] [CrossRef]
- Du, B.; Du, H.; Liu, H.; Niyato, D.; Xin, P.; Yu, J.; Qi, M.; Tang, Y. YOLO-Based Semantic Communication With Generative AI-Aided Resource Allocation for Digital Twins Construction. IEEE Internet Things J. 2024, 11, 7664–7678. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2021, arXiv:2010.04159. [Google Scholar] [CrossRef]
- Terven, J.; Cordova-Esparza, D. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Revathi, R.; Hemalatha, M. Moving and Immovable Object in Video Processing Using Intuitionistic Fuzzy Logic. In Proceedings of the 2013 Fourth International Conference on Computing, Communications and Networking Technologies (ICCCNT), Tiruchengode, India, 4–6 July 2013; pp. 1–6. [Google Scholar]
- Song, Y.; Noh, S.; Yu, J.; Park, C.; Lee, B. Background Subtraction Based on Gaussian Mixture Models Using Color and Depth Information. In Proceedings of the 2014 International Conference on Control, Automation and Information Sciences (ICCAIS 2014), Gwangju, Republic of Korea, 2–5 February 2014; pp. 132–135. [Google Scholar]
- Najar, F.; Bourouis, S.; Bouguila, N.; Belghith, S. A Comparison Between Different Gaussian-Based Mixture Models. In Proceedings of the 2017 IEEE/ACS 14th International Conference on Computer Systems and Applications (AICCSA), Hammamet, Tunisia, 30 October–3 November 2017; pp. 704–708. [Google Scholar]
- Nurhadiyatna, A.; Jatmiko, W.; Hardjono, B.; Wibisono, A.; Sina, I.; Mursanto, P. Background Subtraction Using Gaussian Mixture Model Enhanced by Hole Filling Algorithm (GMMHF). In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 4006–4011. [Google Scholar]
- Yang, Y.; Liu, Y. An Improved Background and Foreground Modeling Using Kernel Density Estimation in Moving Object Detection. In Proceedings of the 2011 International Conference on Computer Science and Network Technology, Harbin, China, 24–26 February 2011; Volume 2, pp. 1050–1054. [Google Scholar]
- Gidel, S.; Blanc, C.; Chateau, T.; Checchin, P.; Trassoudaine, L. Comparison between GMM and KDE Data Fusion Methods for Particle Filtering: Application to Pedestrian Detection from Laser and Video Measurements. In Proceedings of the 2010 13th International Conference on Information Fusion, Edinburgh, UK, 26–29 July 2010; pp. 1–7. [Google Scholar]
- Akl, A.; Yaacoub, C. Image Analysis by Structural Dissimilarity Estimation. In Proceedings of the 2019 Ninth International Conference on Image Processing Theory, Tools and Applications (IPTA), Istanbul, Turkey, 6–9 November 2019; pp. 1–4. [Google Scholar]
- Rouse, D.M.; Hemami, S.S. Understanding and Simplifying the Structural Similarity Metric. In Proceedings of the 2008 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 1188–1191. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- AI-Hub: CCTV Traffic Footage to Solve Traffic Problems (Highways). Available online: https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=data&dataSetSn=164 (accessed on 30 March 2025).
- OpenCV: Background Subtraction. Available online: https://docs.opencv.org/3.4/de/df4/tutorial_js_bg_subtraction.html (accessed on 29 December 2024).
- Bailly, R. Romigrou/Ssim 2024. Available online: http://github.com/romigrou/ssim (accessed on 29 December 2024).
- Fasterrcnn_resnet50_fpn_v2—Torchvision Main Documentation. Available online: https://pytorch.org/vision/main/models/generated/torchvision.models.detection.fasterrcnn_resnet50_fpn_v2.html (accessed on 29 December 2024).
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2019, arXiv:1711.05101. [Google Scholar] [CrossRef]
- Padilla, R.; Netto, S.L.; da Silva, E.A.B. A Survey on Performance Metrics for Object-Detection Algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niterói, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar]
- JeonHyeonggi JeonsLab/Roi_extract_data 2025. Available online: https://github.com/jeonslab/roi_extract_data (accessed on 30 April 2025).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Side | Component | Specifications |
|---|---|---|
| Edge Side | OS | Raspberry Pi OS |
| CPU | Cortex-A76 CPU | |
| GPU | VideoCore VII GPU | |
| RAM | LPDDR4X 8GB | |
| Cloud Side | OS | Windows 11 |
| CPU | Intel(R) Core(TM) i7-13700K | |
| GPU | Nvidia RTX4090 | |
| RAM | DDR5 32 GB |
| Image Resolution | Processing Time (ms) |
|---|---|
| 1920 × 1080 | 269.59 |
| 1280 × 720 | 112.68 |
| 960 × 540 | 56.24 |
| 800 × 450 | 37.12 |
| 640 × 360 | 23.37 |
| DSSIM Threshold | Class | Precision | Recall | F1 | mAP |
|---|---|---|---|---|---|
| Original | Bus | 0.54 | 0.86 | 0.67 | 76.32 |
| Car | 0.54 | 0.91 | 0.68 | ||
| Truck | 0.45 | 0.95 | 0.61 | ||
| DSSIM >0.1 | Bus | 0.49 | 0.80 | 0.61 | 66.09 |
| Car | 0.51 | 0.82 | 0.63 | ||
| Truck | 0.47 | 0.87 | 0.61 | ||
| DSSIM >0.2 | Bus | 0.52 | 0.73 | 0.61 | 56.92 |
| Car | 0.52 | 0.70 | 0.60 | ||
| Truck | 0.52 | 0.74 | 0.62 | ||
| DSSIM >0.3 | Bus | 0.59 | 0.64 | 0.62 | 40.14 |
| Car | 0.52 | 0.50 | 0.51 | ||
| Truck | 0.50 | 0.48 | 0.49 | ||
| DSSIM >0.4 | Bus | 0.67 | 0.23 | 0.35 | 15.56 |
| Car | 0.56 | 0.19 | 0.28 | ||
| Truck | 0.41 | 0.25 | 0.31 |
| Background Color and Dilation | Class | Precision | Recall | F1 | mAP |
|---|---|---|---|---|---|
| white | Bus | 0.62 | 0.81 | 0.70 | 50.65 |
| Car | 0.51 | 0.65 | 0.57 | ||
| Truck | 0.42 | 0.71 | 0.53 | ||
| black | Bus | 0.59 | 0.64 | 0.62 | 40.14 |
| Car | 0.52 | 0.50 | 0.51 | ||
| Truck | 0.50 | 0.48 | 0.49 | ||
| green | Bus | 0.64 | 0.83 | 0.72 | 66.20 |
| Car | 0.59 | 0.91 | 0.72 | ||
| Truck | 0.65 | 0.55 | 0.60 | ||
| white with dilation | Bus | 0.56 | 0.86 | 0.68 | 69.45 |
| Car | 0.54 | 0.87 | 0.67 | ||
| Truck | 0.43 | 0.89 | 0.58 | ||
| black with dilation | Bus | 0.57 | 0.85 | 0.68 | 70.98 |
| Car | 0.54 | 0.87 | 0.67 | ||
| Truck | 0.54 | 0.88 | 0.67 | ||
| green with dilation | Bus | 0.55 | 0.88 | 0.68 | 75.34 |
| Car | 0.56 | 0.90 | 0.69 | ||
| Truck | 0.59 | 0.90 | 0.71 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeon, H.-G.; Lee, K.-H. Region-of-Interest Extraction Method to Increase Object-Detection Performance in Remote Monitoring System. Appl. Sci. 2025, 15, 5328. https://doi.org/10.3390/app15105328
Jeon H-G, Lee K-H. Region-of-Interest Extraction Method to Increase Object-Detection Performance in Remote Monitoring System. Applied Sciences. 2025; 15(10):5328. https://doi.org/10.3390/app15105328
Chicago/Turabian StyleJeon, Hyeong-GI, and Kyoung-Hee Lee. 2025. "Region-of-Interest Extraction Method to Increase Object-Detection Performance in Remote Monitoring System" Applied Sciences 15, no. 10: 5328. https://doi.org/10.3390/app15105328
APA StyleJeon, H.-G., & Lee, K.-H. (2025). Region-of-Interest Extraction Method to Increase Object-Detection Performance in Remote Monitoring System. Applied Sciences, 15(10), 5328. https://doi.org/10.3390/app15105328