
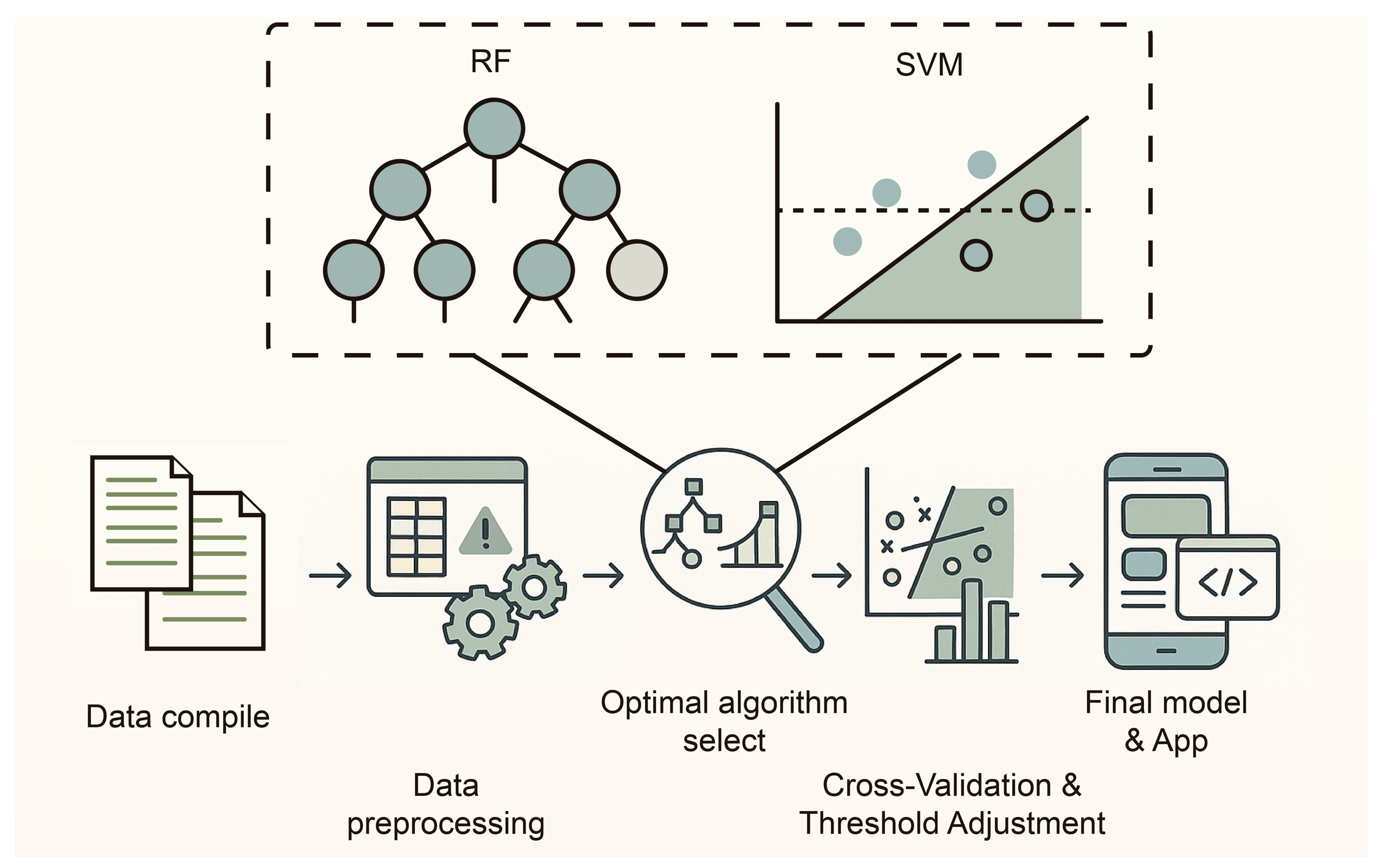
Machine Learning Reveals Magmatic Fertility of Skarn-Type Tungsten Deposits

 , ,
, ,
Abstract
1. Introduction
2. Dataset and Data Preprocessing
2.1. Dataset
2.2. Data Preprocessing
- Outlier Detection and Processing
- b.
- Missing Value Imputation
- c.
- Centered Log-Ratio (clr) Transformation
- d.
- Data Augmentation Using Generative Adversarial Networks (GANs)
3. Method
3.1. Machine Learning Algorithms
3.2. Evaluation Metrics
3.3. Strategies
- Optimal Algorithm Selection
- b.
- Cross-Validation
- c.
- Threshold Adjustment
- d.
- t-SNE Discriminant
- e.
- Independent Case Validation
3.4. Feature Importances
4. Results
4.1. Optimal Algorithm
4.2. Cross-Validation
4.3. Independent Case Validation
4.4. Feature Importances
5. Discussion
5.1. Limitations of Machine Learning Models
5.2. Reliability of Apatite as an Indicator of Magmatic Fertility
5.3. Geochemical Implications of Feature Importance Analysis
5.4. Geological Implications of the Nanling Case
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shen, L.; Li, X.; Lindberg, D.; Taskinen, P. Tungsten Extractive Metallurgy: A Review of Processes and Their Challenges for Sustainability. Miner. Eng. 2019, 142, 105934. [Google Scholar] [CrossRef]
- Miranda, A.C.R.; Beaudoin, G.; Rottier, B. Scheelite Chemistry from Skarn Systems: Implications for Ore-Forming Processes and Mineral Exploration. Min. Depos. 2022, 57, 1469–1497. [Google Scholar] [CrossRef]
- Roy-Garand, A.; Adlakha, E.; Hanley, J.; Elongo, V.; Lecumberri-Sanchez, P.; Falck, H.; Boucher, B. Timing and Sources of Skarn Mineralization in the Canadian Tungsten Belt: Revisiting the Paragenesis, Crystal Chemistry and Geochronology of Apatite. Min. Depos. 2022, 57, 1391–1413. [Google Scholar] [CrossRef]
- Mao, M.; Rukhlov, A.S.; Rowins, S.M.; Spence, J.; Coogan, L.A. Apatite Trace Element Compositions: A Robust New Tool for Mineral Exploration. Econ. Geol. 2016, 111, 1187–1222. [Google Scholar] [CrossRef]
- Shu, Q.; Chang, Z.; Lai, Y.; Hu, X.; Wu, H.; Zhang, Y.; Wang, P.; Zhai, D.; Zhang, C. Zircon Trace Elements and Magma Fertility: Insights from Porphyry (-Skarn) Mo Deposits in NE China. Min. Depos. 2019, 54, 645–656. [Google Scholar] [CrossRef]
- Hu, X.; Li, H.; Zhu, D.; Bouvier, A.; Wu, J.; Meng, Y. Differentiating Jurassic Cu-, W-, and Sn (—W)-Bearing Plutons in the Nanling Range (South China): An Integrated Apatite Study. Ore Geol. Rev. 2024, 170, 106137. [Google Scholar] [CrossRef]
- Watson, E.B. Apatite and Phosphorus in Mantle Source Regions: An Experimental Study of Apatite/Melt Equilibria at Pressures to 25 Kbar. Earth Planet. Sci. Lett. 1980, 51, 322–335. [Google Scholar] [CrossRef]
- Hughes, J.M.; Rakovan, J.F. Structurally Robust, Chemically Diverse: Apatite and Apatite Supergroup Minerals. Elements 2015, 11, 165–170. [Google Scholar] [CrossRef]
- Bouzari, F.; Hart, C.J.R.; Bissig, T.; Barker, S. Hydrothermal Alteration Revealed by Apatite Luminescence and Chemistry: A Potential Indicator Mineral for Exploring Covered Porphyry Copper Deposits. Econ. Geol. 2016, 111, 1397–1410. [Google Scholar] [CrossRef]
- Chew, D.M.; Sylvester, P.J.; Tubrett, M.N. U–Pb and Th–Pb Dating of Apatite by LA-ICPMS. Chem. Geol. 2011, 280, 200–216. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, T.; Fan, Y.; Yuan, F.; Qian, B.; Ma, L. A LA-ICP-MS Study of Apatite from the Taocun Magnetite-Apatite Deposit, Ningwu Basin. Acta Geol. Sin. 2011, 85, 834–848. [Google Scholar]
- Miles, A.J.; Graham, C.M.; Hawkesworth, C.J.; Gillespie, M.R.; Hinton, R.W.; Bromiley, G.D. Apatite: A New Redox Proxy for Silicic Magmas? Geochim. Et Cosmochim. Acta 2014, 132, 101–119. [Google Scholar] [CrossRef]
- Bromiley, G.D. Do Concentrations of Mn, Eu and Ce in Apatite Reliably Record Oxygen Fugacity in Magmas? Lithos 2021, 384–385, 105900. [Google Scholar] [CrossRef]
- Xiong, Y.Q.; Fan, Z.; Yu, H.; Di, H.; Cao, Y.; Wen, C.; Jiang, S. Genetic linkage between parent granite and zoned rare metal pegmatite in the Renli-Chuanziyuan granite-pegmatite system, South China. GSA Bulletin 2025, 137, 1607–1627. [Google Scholar] [CrossRef]
- Tan, H.M.R.; Huang, X.-W.; Meng, Y.-M.; Xie, H.; Qi, L. Multivariate Statistical Analysis of Trace Elements in Apatite: Discrimination of Apatite with Different Origins. Ore Geol. Rev. 2023, 153, 105269. [Google Scholar] [CrossRef]
- Belousova, E.A.; Griffin, W.L.; O’Reilly, S.Y.; Fisher, N.I. Apatite as an Indicator Mineral for Mineral Exploration: Trace-Element Compositions and Their Relationship to Host Rock Type. J. Geochem. Explor. 2002, 76, 45–69. [Google Scholar] [CrossRef]
- Duan, D.-F.; Jiang, S.-Y. Using Apatite to Discriminate Synchronous Ore-Associated and Barren Granitoid Rocks: A Case Study from the Edong Metallogenic District, South China. Lithos 2018, 310–311, 369–380. [Google Scholar] [CrossRef]
- Zhong, S.; Li, S.; Liu, Y.; Cawood, P.A.; Seltmann, R. I-Type and S-Type Granites in the Earth’s Earliest Continental Crust. Commun. Earth Env. 2023, 4, 1–9. [Google Scholar] [CrossRef]
- Gernon, T.M.; Hincks, T.K.; Merdith, A.S.; Rohling, E.J.; Palmer, M.R.; Foster, G.L.; Bataille, C.P.; Müller, R.D. Global Chemical Weathering Dominated by Continental Arcs since the Mid-Palaeozoic. Nat. Geosci. 2021, 14, 690–696. [Google Scholar] [CrossRef]
- Chen, G.; Cheng, Q.; Lyons, T.W.; Shen, J.; Agterberg, F.; Huang, N.; Zhao, M. Reconstructing Earth’s Atmospheric Oxygenation History Using Machine Learning. Nat. Commun. 2022, 13, 5862. [Google Scholar] [CrossRef]
- Doucet, L.S.; Tetley, M.G.; Li, Z.-X.; Liu, Y.; Gamaleldien, H. Geochemical Fingerprinting of Continental and Oceanic Basalts: A Machine Learning Approach. Earth-Sci. Rev. 2022, 233, 104192. [Google Scholar] [CrossRef]
- Zheng, Y.; Xu, B.; Lentz, D.R.; Yu, X.; Hou, Z.; Wang, T. Machine Learning Applied to Apatite Compositions for Determining Mineralization Potential. Am. Mineral. 2024, 109, 1394–1405. [Google Scholar] [CrossRef]
- Karbalaeiramezanali, A.; Yousefi, F.; Lentz, D.R.; Thorne, K.G. Machine Learning Classification of Fertile and Barren Adakites for Refining Mineral Prospectivity Mapping: Geochemical Insights from the Northern Appalachians, New Brunswick, Canada. Minerals 2025, 15, 372. [Google Scholar] [CrossRef]
- Liang, Q.; Chen, G.; Luo, L.; Huang, X.; Hu, H. Appraising the Porphyry Cu Fertility Using Apatite Trace Elements: A Machine Learning Method. J. Geochem. Explor. 2025, 270, 107664. [Google Scholar] [CrossRef]
- Yuan, L.; Chai, P.; Hou, Z.; Quan, H.; Su, C. Machine Learning for Characterizing Magma Fertility in Porphyry Copper Deposits: A Case Study of Southeastern Tibet. Acta Geol. Sin.—Engl. Ed. 2025, 99, 611–624. [Google Scholar] [CrossRef]
- Abubakar, J.; Zhang, Z.; Cheng, Z.; Yao, F.; Bio Sidi, D.; Bouko, A.-A. Advancing Skarn Iron Ore Detection through Multispectral Image Fusion and 3D Convolutional Neural Networks (3D-CNNs). Remote Sens. 2024, 16, 3250. [Google Scholar] [CrossRef]
- Zhang, Z.; Zuo, R.; Xiong, Y. A Comparative Study of Fuzzy Weights of Evidence and Random Forests for Mapping Mineral Prospectivity for Skarn-Type Fe Deposits in the Southwestern Fujian Metallogenic Belt, China. Sci. China Earth Sci. 2016, 59, 556–572. [Google Scholar] [CrossRef]
- Meng, F.; Li, X.; Chen, Y.; Ye, R.; Yuan, F. Three-Dimensional Mineral Prospectivity Modeling for Delineation of Deep-Seated Skarn-Type Mineralization in Xuancheng–Magushan Area, China. Minerals 2022, 12, 1174. [Google Scholar] [CrossRef]
- Li, H.; Li, X.; Yuan, F.; Zhang, M.; Li, X.; Ge, C.; Wang, Z.; Guo, D.; Lan, X.; Tang, M.; et al. Genetic Algorithm Optimized Light Gradient Boosting Machine for 3D Mineral Prospectivity Modeling of Cu Polymetallic Skarn-Type Mineralization, Xuancheng Area, Anhui Province, Eastern China. Nat. Resour. Res. 2023, 32, 1897–1916. [Google Scholar] [CrossRef]
- Lou, Y.; Liu, Y. Mineral Prospectivity Mapping of Tungsten Polymetallic Deposits Using Machine Learning Algorithms and Comparison of Their Performance in the Gannan Region, China. Earth Space Sci. 2023, 10, e2022EA002596. [Google Scholar] [CrossRef]
- Xie, H.; Huang, X.; Meng, Y.; Tan, H.; Qi, L. Discrimination of Mineralization Types of Skarn Deposits by Magnetite Chemistry. Minerals 2022, 12, 608. [Google Scholar] [CrossRef]
- Nogueira, P.; Maia, M. Magnetite Talks: Testing Machine Learning Models to Untangle Ore Deposit Classification—A Case Study in the Ossa-Morena Zone (Portugal, SW Iberia). Minerals 2023, 13, 1009. [Google Scholar] [CrossRef]
- Ghosh, U.; Chakraborty, T. Classification of Different Skarn Deposits Based on the Compositional Variability of Associated Grandite Garnets: A Data Science and Machine Learning Approach. In Proceedings of the EGU General Assembly 2021, Online, 19–30 April 2021. Copernicus Meetings. [Google Scholar]
- Tan, R.; Shao, Y.; Brzozowski, M.J.; Zheng, Y.; Xiong, Y.-Q. Development of a Machine Learning Model to Classify Mineral Deposits Using Sphalerite Chemistry and Mineral Assemblages. Ore Geol. Rev. 2024, 169, 106076. [Google Scholar] [CrossRef]
- Trott, M.; Leybourne, M.; Hall, L.; Layton-Matthews, D. Random Forest Rock Type Classification with Integration of Geochemical and Photographic Data. Appl. Comput. Geosci. 2022, 15, 100090. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, Q.; Han, S.; Zhang, J.; Yang, P.; Liu, X. A Study on Geological Structure Prediction Based on Random Forest Method. Artif. Intell. Geosci. 2022, 3, 226–236. [Google Scholar] [CrossRef]
- Huang, Y.; Zhao, L. Review on Landslide Susceptibility Mapping Using Support Vector Machines. Catena 2018, 165, 520–529. [Google Scholar] [CrossRef]
- Yin, S.; Lin, X.; Huang, Y.; Zhang, Z.; Li, X. Application of Improved Support Vector Machine in Geochemical Lithology Identification. Earth Sci. Inf. 2023, 16, 205–220. [Google Scholar] [CrossRef]
- Mao, J.; Chen, Y.; Chen, M.; Franco, P. Major Types and Time–Space Distribution of Mesozoic Ore Deposits in South China and Their Geodynamic Settings. Min. Depos. 2013, 48, 267–294. [Google Scholar] [CrossRef]
- He, X.; Zhang, D.; Di, Y.; Wu, G.; Hu, B.; Huo, H.; Li, N.; Li, F. Evolution of the Magmatic–Hydrothermal System and Formation of the Giant Zhuxi W–Cu Deposit in South China. Geosci. Front. 2022, 13, 101278. [Google Scholar] [CrossRef]
- Di, H.; Shao, Y.-J.; Xiong, Y.-Q.; Zheng, H.; Fang, X.; Fang, W. Scheelite as a Microtextural and Geochemical Tracer of Multistage Ore-Forming Processes in Skarn Mineralization: A Case Study from the Giant Xintianling W Deposit, South China. Gondwana Res. 2024, 136, 104–125. [Google Scholar] [CrossRef]
- Barnett, V.; Lewis, T. Outliers in Statistical Data; Wiley: New York, NY, USA, 1994; Volume 3. [Google Scholar]
- Scheffer, J. Dealing with missing data. Res. Lett. Inf. Math. Sci. 2002, 3, 153–160. [Google Scholar]
- Zhang, S. Nearest Neighbor Selection for Iteratively kNN Imputation. J. Syst. Softw. 2012, 85, 2541–2552. [Google Scholar] [CrossRef]
- Beretta, L.; Santaniello, A. Nearest Neighbor Imputation Algorithms: A Critical Evaluation. BMC Med. Inf. Decis. Mak. 2016, 16, 74. [Google Scholar] [CrossRef]
- Zhang, Z. Missing Data Imputation: Focusing on Single Imputation. Ann. Transl. Med. 2016, 4, 9. [Google Scholar] [CrossRef] [PubMed]
- Aitchison, J. The Statistical Analysis of Compositional Data. J. R. Stat. Soc. Ser. B (Methodol.) 1982, 44, 139–160. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative Adversarial Networks: An Overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Harris, J.R.; Grunsky, E.C. Predictive Lithological Mapping of Canada’s North Using Random Forest Classification Applied to Geophysical and Geochemical Data. Comput. Geosci. 2015, 80, 9–25. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Petrelli, M.; Perugini, D. Solving Petrological Problems through Machine Learning: The Study Case of Tectonic Discrimination Using Geochemical and Isotopic Data. Contrib. Miner. Pet. 2016, 171, 81. [Google Scholar] [CrossRef]
- Fawcett, T. An Introduction to ROC Analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A Systematic Analysis of Performance Measures for Classification Tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Chen, J.J.; Tsai, C.-A.; Moon, H.; Ahn, H.; Young, J.J.; Chen, C.-H. Decision Threshold Adjustment in Class Prediction. SAR QSAR Environ. Res. 2006, 17, 337–352. [Google Scholar] [CrossRef] [PubMed]
- Maaten, L.V.D.; Hinton, G. Visualizing Data Using T-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Thabtah, F.; Hammoud, S.; Kamalov, F.; Gonsalves, A. Data Imbalance in Classification: Experimental Evaluation. Inf. Sci. 2020, 513, 429–441. [Google Scholar] [CrossRef]
- Wang, H.; Feng, C.; Li, R.; Zhao, C.; Liu, P.; Wang, G.; Hao, Y. Petrogenesis of the Xingluokeng W-Bearing Granitic Stock, Western Fujian Province, SE China and Its Genetic Link to W Mineralization. Ore Geol. Rev. 2021, 132, 103987. [Google Scholar] [CrossRef]
- Zhang, X.; Pan, J.-Y.; Lehmann, B.; Li, J.; Yin, S.; Ouyang, Y.-P.; Wu, B.; Fu, J.-L.; Zhang, Y.; Sun, Y.; et al. Diagnostic REE Patterns of Magmatic and Hydrothermal Apatite in the Zhuxi Tungsten Skarn Deposit, China. J. Geochem. Explor. 2023, 252, 107271. [Google Scholar] [CrossRef]
- Ge, L.; Xie, Q.; Yan, J.; Huang, S.; Yang, L.; Li, Q.; Xie, J. Geochemistry of Apatite from Zhuxiling Tungsten Deposit, Eastern China: A Record of Magma Evolution and Tungsten Enrichment. Solid. Earth Sci. 2024, 9, 100163. [Google Scholar] [CrossRef]
- Bonin, B. A-Type Granites and Related Rocks: Evolution of a Concept, Problems and Prospects. Lithos 2007, 97, 1–29. [Google Scholar] [CrossRef]
- Zhao, K.-D.; Jiang, S.-Y.; Chen, W.-F.; Chen, P.-R.; Ling, H.-F. Zircon U–Pb Chronology and Elemental and Sr–Nd–Hf Isotope Geochemistry of Two Triassic A-Type Granites in South China: Implication for Petrogenesis and Indosinian Transtensional Tectonism. Lithos 2013, 160–161, 292–306. [Google Scholar] [CrossRef]
- Pan, L.-C.; Hu, R.-Z.; Wang, X.-S.; Bi, X.-W.; Zhu, J.-J.; Li, C. Apatite Trace Element and Halogen Compositions as Petrogenetic-Metallogenic Indicators: Examples from Four Granite Plutons in the Sanjiang Region, SW China. Lithos 2016, 254–255, 118–130. [Google Scholar] [CrossRef]
- Ding, T.; Ma, D.; Lu, J.; Zhang, R. Apatite in Granitoids Related to Polymetallic Mineral Deposits in Southeastern Hunan Province, Shi–Hang Zone, China: Implications for Petrogenesis and Metallogenesis. Ore Geol. Rev. 2015, 69, 104–117. [Google Scholar] [CrossRef]
- Yang, J.-H.; Kang, L.-F.; Peng, J.-T.; Zhong, H.; Gao, J.-F.; Liu, L. In-Situ Elemental and Isotopic Compositions of Apatite and Zircon from the Shuikoushan and Xihuashan Granitic Plutons: Implication for Jurassic Granitoid-Related Cu-Pb-Zn and W Mineralization in the Nanling Range, South China. Ore Geol. Rev. 2018, 93, 382–403. [Google Scholar] [CrossRef]
- Nathwani, C.L.; Loader, M.A.; Wilkinson, J.J.; Buret, Y.; Sievwright, R.H.; Hollings, P. Multi-Stage Arc Magma Evolution Recorded by Apatite in Volcanic Rocks. Geology 2020, 48, 323–327. [Google Scholar] [CrossRef]
- Jennings, E.S.; Marschall, H.R.; Hawkesworth, C.J.; Storey, C.D. Characterization of Magma from Inclusions in Zircon: Apatite and Biotite Work Well, Feldspar Less So. Geology 2011, 39, 863–866. [Google Scholar] [CrossRef]
- Zhang, B.; Hu, X.; Li, P.; Tang, Q.; Wen-Ge, Z. Trace Element Partitioning between Amphibole and Hydrous Silicate Glasses at 0.6–2.6 GPa. Acta Geochim. 2019, 38, 414–429. [Google Scholar] [CrossRef]
- Olin, P.H.; Wolff, J.A. Partitioning of Rare Earth and High Field Strength Elements between Titanite and Phonolitic Liquid. Lithos 2012, 128–131, 46–54. [Google Scholar] [CrossRef]
- Prowatke, S.; Klemme, S. Trace Element Partitioning between Apatite and Silicate Melts. Geochim. Et Cosmochim. Acta 2006, 70, 4513–4527. [Google Scholar] [CrossRef]
- Hilyard, M.; Nielsen, R.L.; Beard, J.S.; Patinõ-Douce, A.; Blencoe, J. Experimental Determination of the Partitioning Behavior of Rare Earth and High Field Strength Elements between Pargasitic Amphibole and Natural Silicate Melts. Geochim. Et Cosmochim. Acta 2000, 64, 1103–1120. [Google Scholar] [CrossRef]
- Tiepolo, M.; Vannucci, R.; Bottazzi, P.; Oberti, R.; Zanetti, A.; Foley, S. Partitioning of Rare Earth Elements, Y, Th, U, and Pb between Pargasite, Kaersutite, and Basanite to Trachyte Melts: Implications for Percolated and Veined Mantle. Geochem. Geophys. Geosystems 2000, 1, 2000GC000064. [Google Scholar] [CrossRef]
- Prowatke, S.; Klemme, S. Rare Earth Element Partitioning between Titanite and Silicate Melts: Henry’s Law Revisited. Geochim. Et Cosmochim. Acta 2006, 70, 4997–5012. [Google Scholar] [CrossRef]
- Chelle-Michou, C.; Chiaradia, M. Amphibole and Apatite Insights into the Evolution and Mass Balance of Cl and S in Magmas Associated with Porphyry Copper Deposits. Contrib. Miner. Pet. 2017, 172, 105. [Google Scholar] [CrossRef]
- Fan, C.; Xu, C.; Shi, A.; Smith, M.P.; Kynicky, J.; Wei, C. Origin of Heavy Rare Earth Elements in Highly Fractionated Peraluminous Granites. Geochim. Et Cosmochim. Acta 2023, 343, 371–383. [Google Scholar] [CrossRef]
- Stokes, T.N.; Bromiley, G.; Potts, N.J.; Saunders, K.E.; Miles, A. The Effect of Melt Composition and Oxygen Fugacity on Manganese Partitioning between Apatite and Silicate Melt. Chem. Geol. 2018, 506, 162–174. [Google Scholar] [CrossRef]
- Roda-Robles, E.; Gil-Crespo, P.P.; Pesquera, A.; Lima, A.; Garate-Olave, I.; Merino-Martínez, E.; Cardoso-Fernandes, J.; Errandonea-Martin, J. Compositional Variations in Apatite and Petrogenetic Significance: Examples from Peraluminous Granites and Related Pegmatites and Hydrothermal Veins from the Central Iberian Zone (Spain and Portugal). Minerals 2022, 12, 1401. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, W.; Wu, J.; Liang, H.; Lin, S. Geological Implications of Apatite within the Granite-Related Jiepai W–(Cu) Deposit, Guangxi, South China. Ore Geol. Rev. 2021, 139, 104548. [Google Scholar] [CrossRef]
- Keppler, H. Influence of Fluorine on the Enrichment of High Field Strength Trace Elements in Granitic Rocks. Contr. Mineral. Petrol. 1993, 114, 479–488. [Google Scholar] [CrossRef]
- Xiong, Y.-Q.; Shao, Y.-J.; Cheng, Y.; Jiang, S.-Y. Discrete Jurassic and Cretaceous Mineralization Events at the Xiangdong W(-Sn) Deposit, Nanling Range, South China. Econ. Geol. 2020, 115, 385–413. [Google Scholar] [CrossRef]
- Zhao, D.; Han, R.; Liu, F.; Fu, Y.; Zhang, X.; Qiu, W.; Tao, Q. Constructing the Deep-Spreading Pattern of Tectono-Geochemical Anomalies and Its Implications on the Huangshaping W-Sn-Pb-Zn Polymetallic Deposit in Southern Hunan, China. Ore Geol. Rev. 2022, 148, 105040. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Sample | Deposit Name | Fertile/Unfertile | Model Prediction |
| 1 | 195 | Weijia | Fertile | Fertile |
| 2 | 602 | Tongshanling | Unfertile | Unfertile |
| 3 | 8S5 | Tongshanling | Unfertile | Unfertile |
| 4 | XHS-5 | Xihuashan | Fertile | Fertile |
| 5 | XHS-6 | Xihuashan | Fertile | Fertile |
| 6 | XHS-18 | Xihuashan | Fertile | Unfertile |
| 7 | XHS-21 | Xihuashan | Fertile | Fertile |
| 8 | SKS-31 | Shuikoushan | Unfertile | Unfertile |
| 9 | SKS-36 | Shuikoushan | Unfertile | Unfertile |
| 10 | SKS-37 | Shuikoushan | Unfertile | Unfertile |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, R.-C.; Shao, Y.-J.; Xiong, Y.-Q.; Fan, Z.-W.; Di, H.-F.; Wang, Z.-J.; Xu, K.-Q. Machine Learning Reveals Magmatic Fertility of Skarn-Type Tungsten Deposits. Appl. Sci. 2025, 15, 5237. https://doi.org/10.3390/app15105237
Tan R-C, Shao Y-J, Xiong Y-Q, Fan Z-W, Di H-F, Wang Z-J, Xu K-Q. Machine Learning Reveals Magmatic Fertility of Skarn-Type Tungsten Deposits. Applied Sciences. 2025; 15(10):5237. https://doi.org/10.3390/app15105237
Chicago/Turabian StyleTan, Rui-Chang, Yong-Jun Shao, Yi-Qu Xiong, Zhi-Wei Fan, Hong-Fei Di, Zhao-Jun Wang, and Kang-Qi Xu. 2025. "Machine Learning Reveals Magmatic Fertility of Skarn-Type Tungsten Deposits" Applied Sciences 15, no. 10: 5237. https://doi.org/10.3390/app15105237
APA StyleTan, R.-C., Shao, Y.-J., Xiong, Y.-Q., Fan, Z.-W., Di, H.-F., Wang, Z.-J., & Xu, K.-Q. (2025). Machine Learning Reveals Magmatic Fertility of Skarn-Type Tungsten Deposits. Applied Sciences, 15(10), 5237. https://doi.org/10.3390/app15105237