1. Introduction
Because of the significant capacity, high efficiency, energy consumption, and low transport costs of heavy rail transport, it is both widely used and valued in different countries across the world. Rail transport has been internationally recognized as the direction of development for bulk cargo transport, especially in China due to its vast, uneven distribution of resources across the country [
1,
2]. However, with the increase in train speeds and railway capacity, railway defects and even failures occur frequently. The type of railway section fault in mountainous areas has also changed from the previous type of rail fault—which is based on the side grinding of the upper strand of the curve, the thick edge of the lower strand, and the abrasion of the rail on the long gradient—to the rail defect—which is based on stripping off the blocks, cracks, and abrasions. The rail is an essential part of the line equipment, directly bearing the rolling stock load, so the service state of the rail directly affects the operational state of the heavy railway. Therefore, it is essential for the operation of heavy railways to accurately detect the operating condition of rails and predict their RUL [
3].
The RUL of rails is realized via feature extraction, construction of life prediction models, and other techniques based on current or historical inspection data and other information. Therefore, the research focus, when considering RUL, is on how to use data-processing and -mining techniques to construct suitable models and extract typical features from rail data. Residual life prediction models are generally classified as physical model methods, statistical model methods, and data-driven methods [
4]. The physical modeling approach assesses the health of a system through the construction of mathematical models based on failure mechanisms or first principles of damage [
5]. Li et al. [
6] proposed a numerical model based on the simulation of rail profile wear, which, by applying improved models such as Kalker’s non-Hertzian contact, simulated the shape of the worn rail profile in general agreement with the field measurements. Wang et al. [
7] developed a numerical model of vehicle track based on the multi-body dynamics and the improved Archard wear formula, and a numerical model of vehicle trajectory was developed to characterize the development of high rail-side wear in a heavily trafficked transport track. This approach is highly descriptive as system degradation modeling relies on natural laws. However, the method suffers from problems, such as high cost and complexity of implementation, and is not readily accepted in engineering practice [
8]. The statistical modeling method is based on historical data and statistical learning, which builds a prediction model by fitting and analyzing historical data to predict the RUL. Xu et al. [
9] used an inverse Gaussian (IG) stochastic process to establish a structural resistance degradation model, which was updated in real time using the Bayesian updating theory and demonstrated the feasibility of the method with numerical examples. Due to the irregularity of the track structure damage, it is very difficult to establish the exact mathematical statistics in practical applications, and the dynamic characteristics of the machine cannot be taken into account.
In recent years, neural network methods, like convolutional neural networks (CNNs) [
10,
11] and recurrent neural networks (RNNs), have become the most commonly used data-driven-based methods [
12]. By extracting features, they reveal potential correlations and causal relationships between the collected data and the health state of the machinery and provide an end-to-end solution for solving the RUL prediction problem [
13]. Therefore, these data-driven approaches have gradually become mainstream in recent years. The long short-term memory network (long short-term memory, LSTM) [
14] and its variants have all been successfully adapted to the field of RUL prediction in succession. Ma et al. [
15] introduced a deep neural network based on a convolutional long short-term memory (CLSTM) network, which contains the time-frequency information as well as the temporal information of the signal. This network retains the advantages of LSTM and incorporates time-frequency features to accurately predict RUL. However, the LSTM only predicts future data by capturing past data. Bi-directional long short-term memory (BiLSTM) simultaneously acquires future and past information, demonstrating better qualities in RUL prediction [
16]. Zhao et al. [
17] used a BiLSTM neural network to learn intrinsic features in both directions and improved the fault recognition accuracy. Li et al. [
18] proposed a multi-branch improved convolutional network (MBCNN)-BiLSTM model for predicting bearing RUL. MBCNN achieves spatial feature extraction of orientation input data, and then BiLSTM further mines the temporal features of the data, thus improving the prediction accuracy of bearing RUL. Sun et al. [
19] proposed a complete ensemble empirical mode decomposition (CEEMD)-CNN-LSTM model, which was experimentally verified to have higher prediction accuracy than single CNN and LSTM. The above study shows that fully extracting data features can improve the prediction performance and achieve better prediction accuracy. Although CNNs and LSTM can extract data features well, they are not fully suitable for rail vibration signals, because CNN is deficient in temporal feature extraction and LSTM is deficient in local feature extraction. In contrast, combining the two can make better use of the advantages of both, thus improving the ability of feature extraction.
Due to the special characteristics of the existing rail inspection, the full life-cycle data of rail injury and damage have the characteristics of low frequency and long time span, and at the same time, it is difficult and costly to explore the failure mechanism of rails involving complex wheel–rail relationship problems. In addition, a series of problems, such as gradient explosion and disappearance, and large memory occupation, have not been properly solved during the process of model training. Meanwhile, if the prediction accuracy is not enough, it may cause significant economic damage and casualties. This poses a challenge to deep learning-based RUL prediction for railway tracks.
In recent years, attention has arguably become one of the most important concepts in the field of deep learning. With the development of deep neural networks, the attention mechanism has been widely used in various application areas [
20]. It has been shown that the attention mechanism has better access to the extracted feature information [
21]. Mnih et al. [
22] proposed an attention mechanism to solve problems such as gradient vanishing and gradient explosion. The method calculates different weights given to different features of the model. Liu et al. [
23] proposed an end-to-end RUL prediction method based on feature-attention, which applies the proposed feature-attention mechanism directly to the input data so as to dynamically assign greater weights to more important features during training, thereby improving the prediction performance. The residual connection can enhance the gradient propagation, thus solving the problem of the increase in network depth that can easily cause gradient disappearance and gradient explosion [
24]. Xu et al. [
25] proposed a CNN-LSTM-Skip model to estimate the State of Health (SOH) of lithium-ion batteries. Jump connections were added to the Convolutional Neural Network–Long Short-Term Memory (CNN-LSTM) model in order to solve the problem of neural network degradation caused by multilayer LSTM. Cao et al. [
26] presented a temporal convolutional network–residual self-attention mechanism (TCN-RSA), where the RSA scans through the global information and discovers local useful information, thus achieving the function of enhancing useful information and suppressing redundant information. The above method provides ideas for solving the problem of defects in rail inspection data.
This paper presents a new approach to deriving the RUL of railway rails from the vibration information caused by wave abrasion and other injuries in heavy railways and to construct a feature extraction module, CNN-BiLSTM, which extracts the temporal features of the data and effectively extracts the forward and reverse dependencies of the data without requiring significant familiarity with the failure mechanisms of the rails. This effectively overcomes the limitations of the above literature in performing more comprehensive feature extraction from the data, including the challenge of using expert knowledge to build accurate damage-tracking models. Different attention mechanisms have satisfactory results. However, the self-attention mechanism in the above literature involves a large number of weight matrix operations; the optimization of the weight matrix optimization is usually difficult in traditional deep learning methods, the gradient of the error function must be back-propagated layer by layer, and the error function has a poorer optimization effect or the gradient disappears after back-propagation on the weight matrix. To address this problem, the RSA module is constructed, which solves the above problem by adding the residual self-attention mechanism with residual connection; at the same time, the RSA can also obtain the internal correlation features, which effectively improves the expressive ability of the model. The proposed method is validated and analyzed by experimenting with the vibration data collected by our team in a railway section. The contributions are as follows:
- (1)
A CNNBiLSTM-RSA model is proposed to establish an end-to-end prediction model between monitoring the data and the remaining service life of rails by using indirect data such as vibration signals caused by rail damage. A case study of the proposed method is carried out on different types of rail damage and roll bearings, and the CNN-BiLSTM-RSA has a better nature in terms of prediction accuracy, as well as a certain generalization ability.
- (2)
The CNN-BiLSTM feature extraction module is constructed to make full use of the advantages of both to enhance the feature extraction capability, which can adaptively extract features and reduce the influence of artificial factors to a certain extent.
The rest of the paper is structured as follows: The framework of the presented prediction method is presented in
Section 2, and the individual components are described in detail.
Section 3 presents the rail data and details the experimental results and related analyses. Finally, the conclusions are presented in
Section 4.
2. RUL Prediction for Rails Based on CNNBiLSTM-RSA
Trains run on and between the track coupling process is complex and variable, thereby giving rise to various types of rail injuries. Among them, stripping, wave abrasion, fish scale, and other defects are the most common, and different types of rail defects have different impacts on line operation. For example, if the stripping length is more than 15 mm and the width is more than 3 mm, it is regarded as a slight defect and needs to be polished. When the stripping reaches a length of 25 mm and a depth of more than 3 mm, it is considered to be a serious defect and requires replacement of the rail [
27]. RUL is a predictive maintenance metric used to estimate the remaining time or service life of a component or system before it reaches a critical state or a failure state. In this study, the direct structure of the data-driven approach [
28] is adopted for typical injuries and damages to rails. The RUL of a railway track can be directly derived from the vibration information caused by spalling and other injuries during the whole life cycle of heavy railway rails. The method can be applied to the track life prediction of in-service railway tracks. The schematic diagram of the proposed end-to-end prediction model is shown in
Figure 1. The prediction model mainly consists of a feature extraction layer, a residual self-attention module, and a fully connected layer.
The original vibration data of the rail are preprocessed as the sample of the model input. The feature extraction module is composed of a combination of CNN and BiLSTM, which effectively combines the feature processing capability of CNN and the temporal association capability of BiLSTM. This allows the model to better extract the vibration signal features from the rail. Meanwhile, to make better use of the extracted timing information, the position encoder in the transformer model is used to encode the position of the features extracted by the CNNBiLSTM model. Then, an RSA mechanism is constructed behind it to obtain the contribution of different moments in the time series. Meanwhile, residual connectivity is introduced into the CNNBiLSTM-RSA network through its feature of transmitting data across layers. This avoids the gradient vanishing problem in the network and enhances the trainability and network expressiveness of the network. Finally, the mapping between the rail features and the RUL labels is established through the fully connected layer.
2.1. Feature Extraction Module
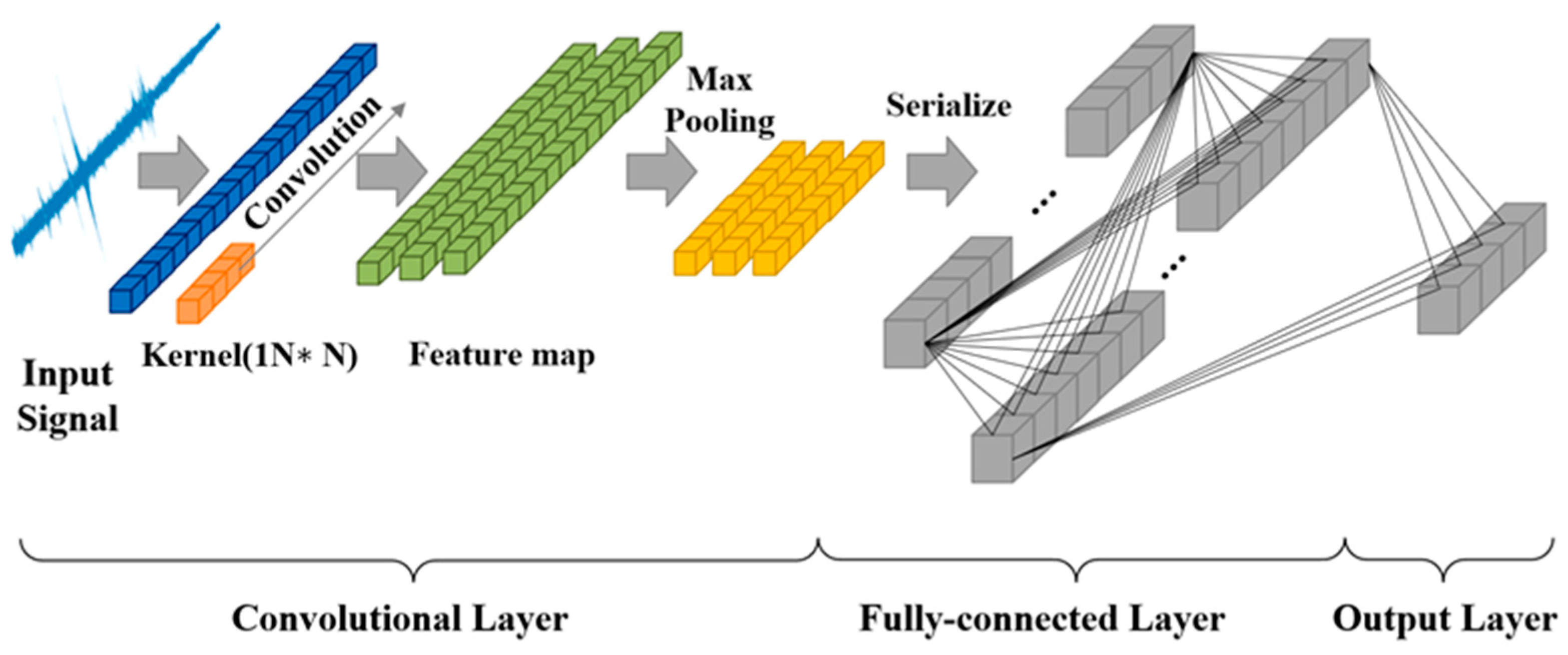
The use of expert knowledge to determine the rail degradation to manage the full life-cycle data of the rail can increase the interference of artificial factors to a certain extent. Allowing the feature extraction module to adaptively learn the fault features without any signal processing to a certain extent can avoid processing the original sample data, thereby reducing the impact of artificial factors. The CNN-BiLSTM module is constructed and includes a convolutional layer, ReLU, MAXpool, and BiLSTM layer. The rail vibration signal belongs to the single-dimensional time series signal, for which 1DCNN is usually used. A typical 1DCNN structure is illustrated in
Figure 2. The input vibration signal is expressed as
. Features in different regions are extracted by multiple one-dimensional convolution kernels. The convolution operation is defined as follows:
where
and
denote the bias term and activation function, respectively. The ReLU function is expressed in the following form:
Then, the features extracted through the convolution calculation are used as inputs for the pooling layer, the sequence is downsized, the network model is simplified by pooling calculation, and the maximum pooling is selected in this paper. A multi-layer convolutional layer and pooling layer are designed. This allows the characteristics of the rail vibration signal to be effectively extracted. Finally, the output of the pooling layer is used as the input for the fully connected layer. However, CNNs have a weak ability to associate features in long sequence information [
29].
Although CNN has the ability to automatically extract features from data, it is less capable of handling time-series data with strong time dependence; in contrast, LSTM can effectively solve the long-term dependence problem due to the introduction of gating units. By combining the two, the extraction of spatial and temporal features can be enhanced and the computation time can be relatively reduced. BiLSTM and LSTM are both variants of RNNs (recurrent neural networks), which can effectively avoid the long-term dependency problem caused by gradient vanishing or gradient explosion during the training process of RNN [
30]. Compared to the RNN, the LSTM enables the learning of long-term memory through gating units. Many studies have demonstrated that LSTM is effective in dealing with the temporal relationship between inputs and outputs and in learning the data correlation of the time series [
31]. LSTM maintains the current recurrent neuron state based on the current inputs and the previous recurrent neuron states. The LSTM unit introduces four gating units defined as the input gate, the output gate, the forgetting gate, and the self-recycling memory unit in order to control the different memory units in their information flow interactions with each other [
32]. In the hidden unit, the forgetting gate chooses which state information to keep or forget from previous time steps; the input gate determines what pattern of input vectors needs to be fed into that memory cell state; by comparison, the output gate controls how it changes other memory cell states. It is assumed that
and
denote sequential input data and cyclic output state at time step t, respectively. The gate, hidden output, and cell state are expressed as follows:
where
U denotes the weight matrix of the respective gate;
,
,
, and
denote the corresponding recursive weight matrix of the respective gate.
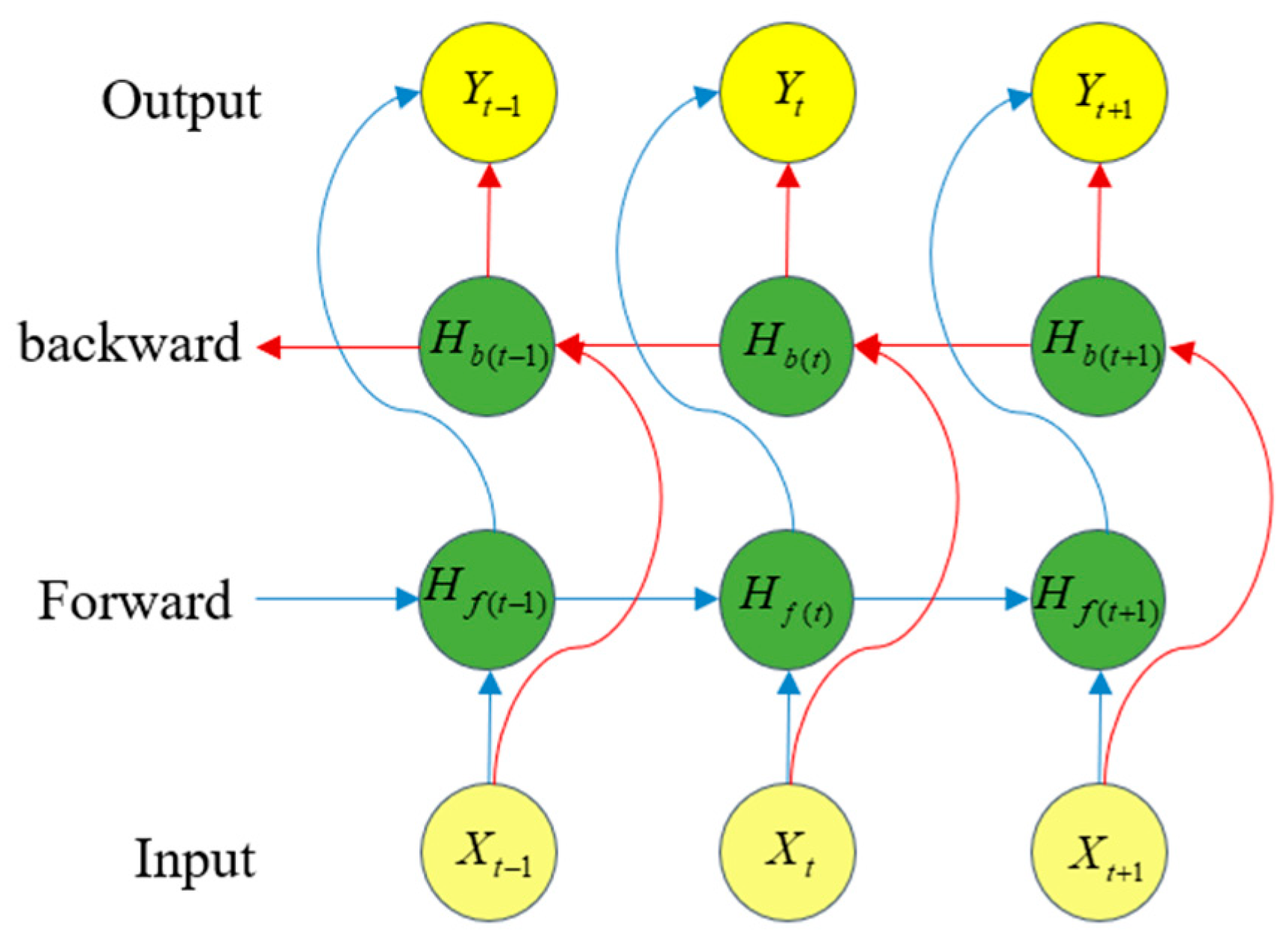
However, LSTM only uses previous information to predict the current state. It cannot use information from a future time. To address this problem, BiLSTM obtains bi-directional information from both historical and future time data and has a more powerful feature learning performance than LSTM. BiLSTM is designed with a bi-directional structure. This structure captures the time series data representations in both forward and backward directions, as shown in
Figure 3. BiLSTM superimposes two parallel layers of LSTM in both the forward and backward directions of propagation. The internal state stores information from past time-series values in
in the forward direction; information from future sequence values is stored in
in the backward direction. Separate hidden states
and
at time step t are sequentially connected to obtain the final output. The recursive states of the BiLSTM are expressed as follows:
The final output vector is obtained using the following equation:
where
and
are the forward and backward weights, respectively, and
is the activation function.
2.2. Residual Self-Attention Module
In order to fit the characteristics of low frequency and long time span of the full life-cycle data of rail injury and damage, to enhance the temporal feature information, to retain the long-term dependence, and to enhance the weight of the useful information in order to improve the prediction accuracy of rail RUL, the residual self-attention module is constructed. This module consists of the residual self-attention mechanism that incorporates the residual connection, which can obtain the contribution of temporal information and improve the sensitivity of feature mapping to temporal information. Finally, the predicted value of the rail RUL is obtained by the fully connected layer.
2.2.1. Residual Connections
Due to their ability to transfer information across layers, residual connections are an effective approach for training deep networks. The residual block includes branches that lead to a number of transformations of H as shown in
Figure 4. The output of the changes in H and the original output merged are expressed as follows:
Typically, the network becomes more expressive and performs better as the number of layers in the network deepens. However, the increase in the number of layers brings problems such as gradient vanishing and gradient explosion. Meanwhile, residual connectivity is very beneficial for very deep networks by allowing the learning layer to modify the identity mapping without performing the entire transformation. Therefore, at the end of the CNNBiLSTM-RSA residual connections are used so as to avoid problems like gradient vanishing and gradient explosion.
2.2.2. Self-Attention Mechanism
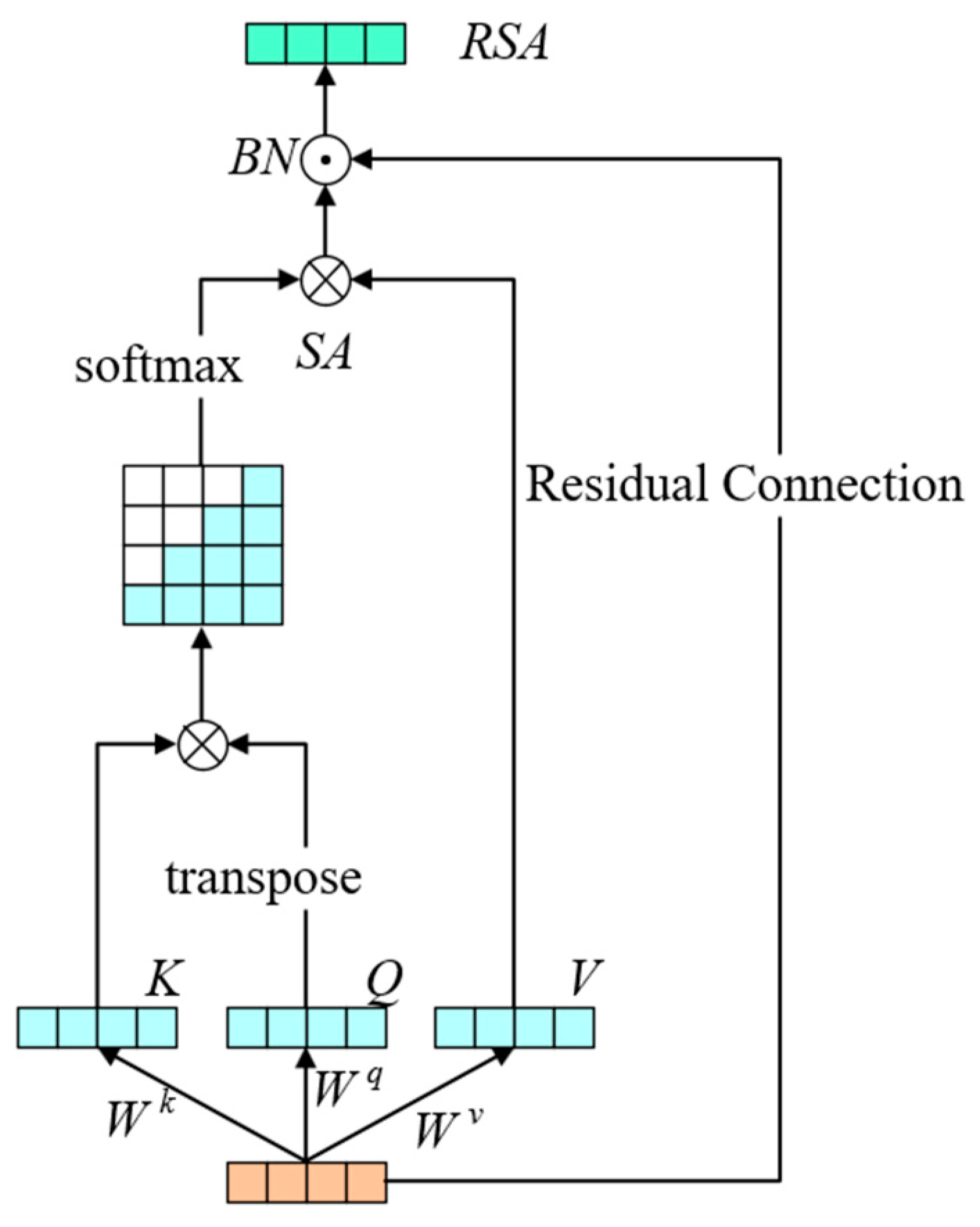
The self-attention (SA) mechanism is the central idea of the transformer model [
33]. The SA mechanism allows the model to focus more on the information that contributes more to the output. The RSA mechanism module is improved to capture information with different contributions in the sequences, which improves the expressive ability of the network. This also enables the model to better learn the mapping relationship between the features and RUL labels. As shown in
Figure 5, the model calculates the different weights between the elements in the sequence.
The input of the RSA mechanism consists of three parts, which are query (query,
Q), key (key,
K), and value (value,
V) [
29]. They are computed using the following equation:
where
,
, and
are weight matrices.
The value of
SA is calculated as follows:
where
is the dimension of the key vector; the
function obtains the weight of each value.
Finally, the
SA and the inputs are fed through the residual connection into the batch-regression layer to compute the value of the
RSA:
In order to better utilize the timing information in the features coming out of the feature extraction module, the position encoder in the transformer model is added to encode the position of this signal feature before the RSA mechanism [
34]:
where
pos denotes the position number in the sequence;
d denotes the dimension of the sensor; 2
i denotes an even number of sensors; 2
i + 1 denotes an odd number of sensors.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}