



Efficient Optimization of a Support Vector Regression Model with Natural Logarithm of the Hyperbolic Cosine Loss Function for Broader Noise Distribution


Abstract
1. Introduction
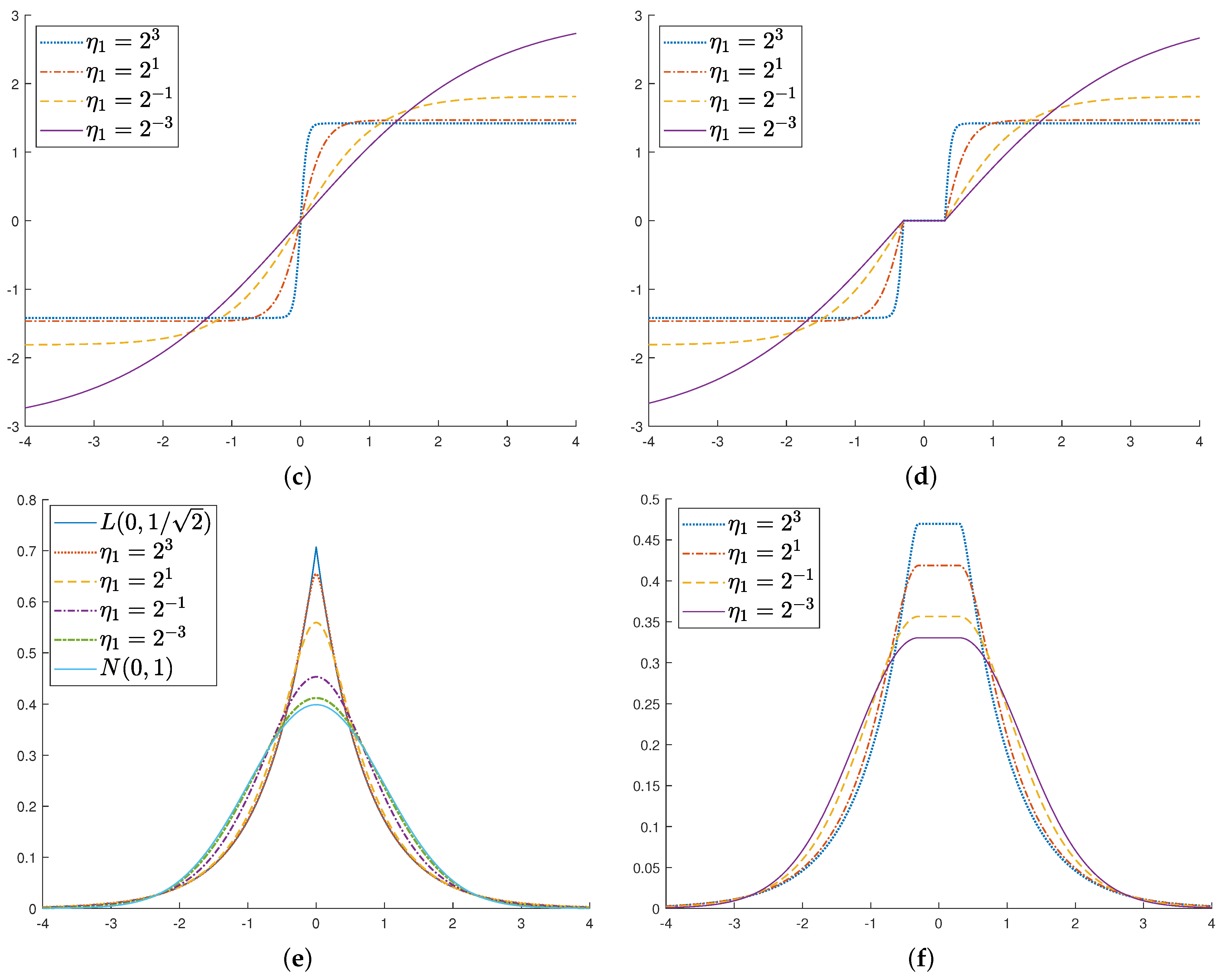
2. -ln SVR and Its Dual Problem
2.1. The Smooth Dual Problem of -ln SVR
2.2. The Nonsmooth Version of -ln SVR
3. The SMO-like Algorithm for the Nonsmooth Dual Problem of -ln SVR
3.1. Decomposition and Solution Based on Brent’s Method
3.2. Stopping Criterion
3.3. Working Set Selection
- (1)
- For all t, s defineselectwhere
- (2)
- Return
| Algorithm 1: SMO-like algorithm for the nonsmooth nonlinear dual problem |
input: Training data output: , b Initialize by setting: , , , and repeat  until the stopping criterion (35) is satisfied as ; Calculate |
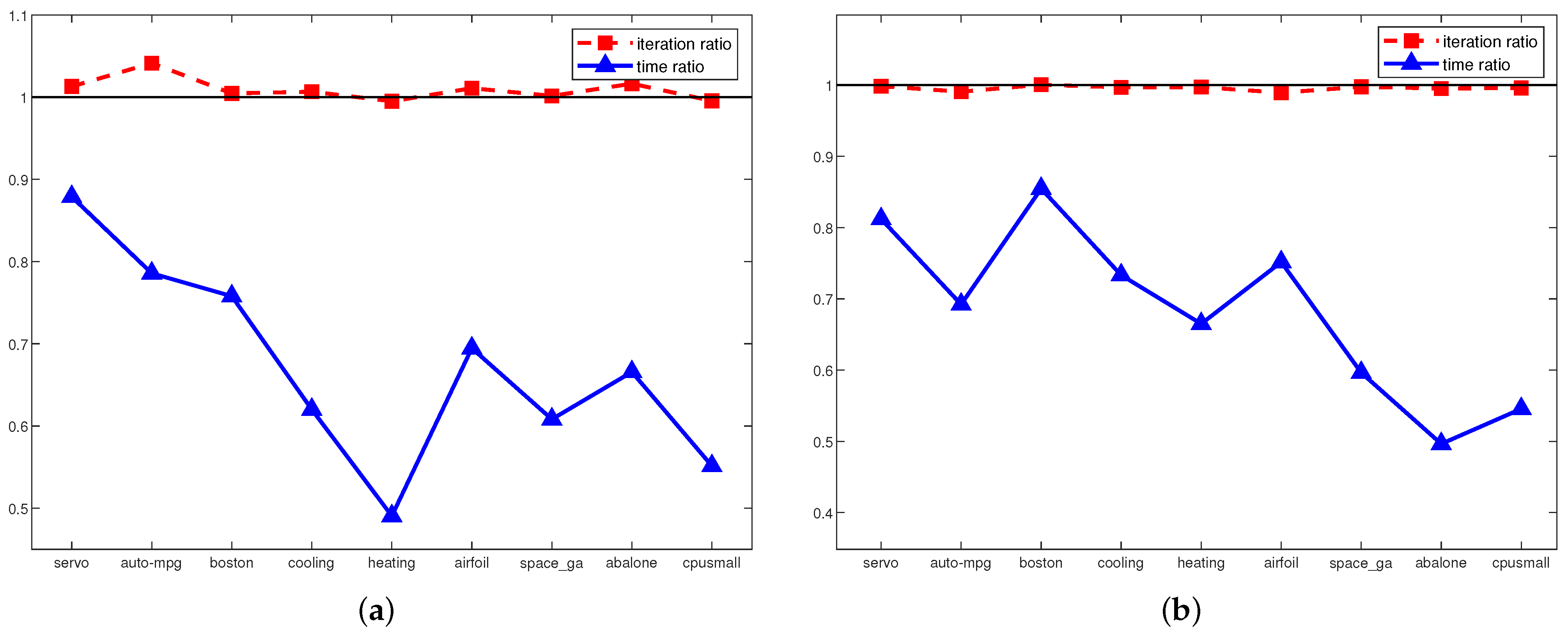
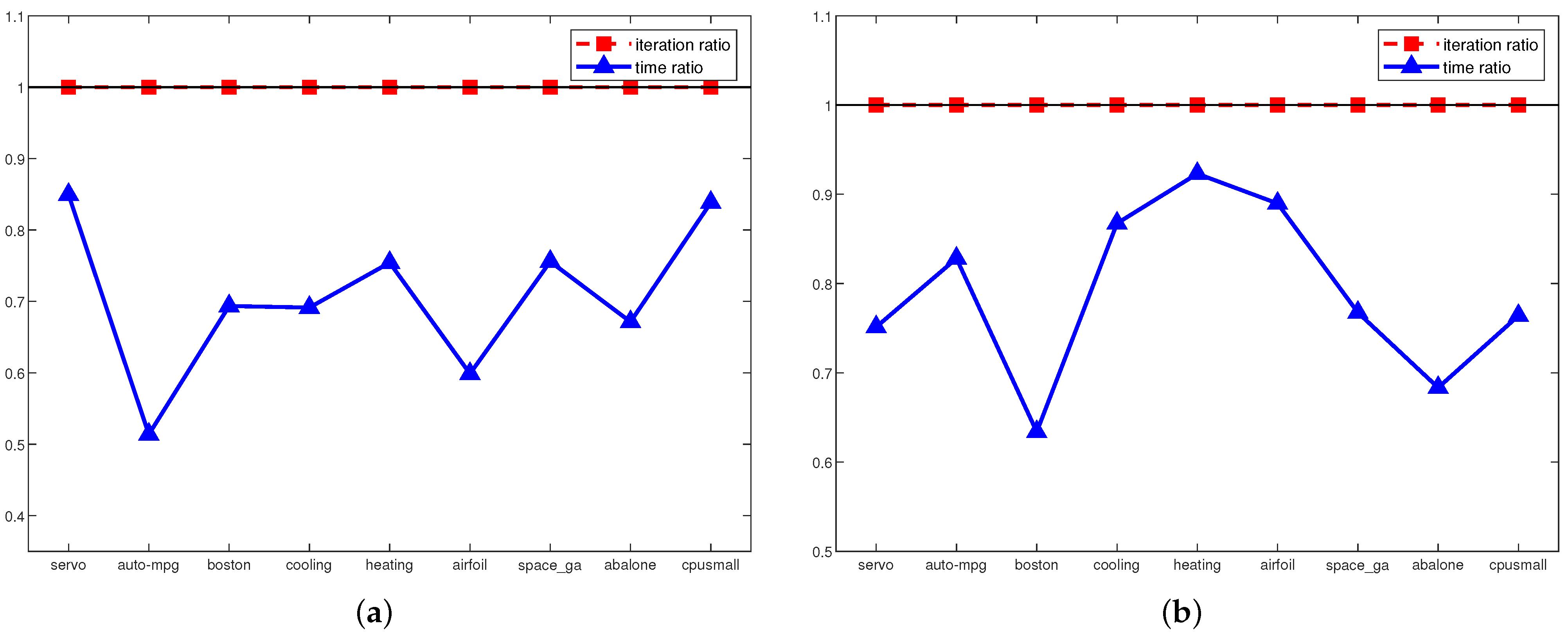
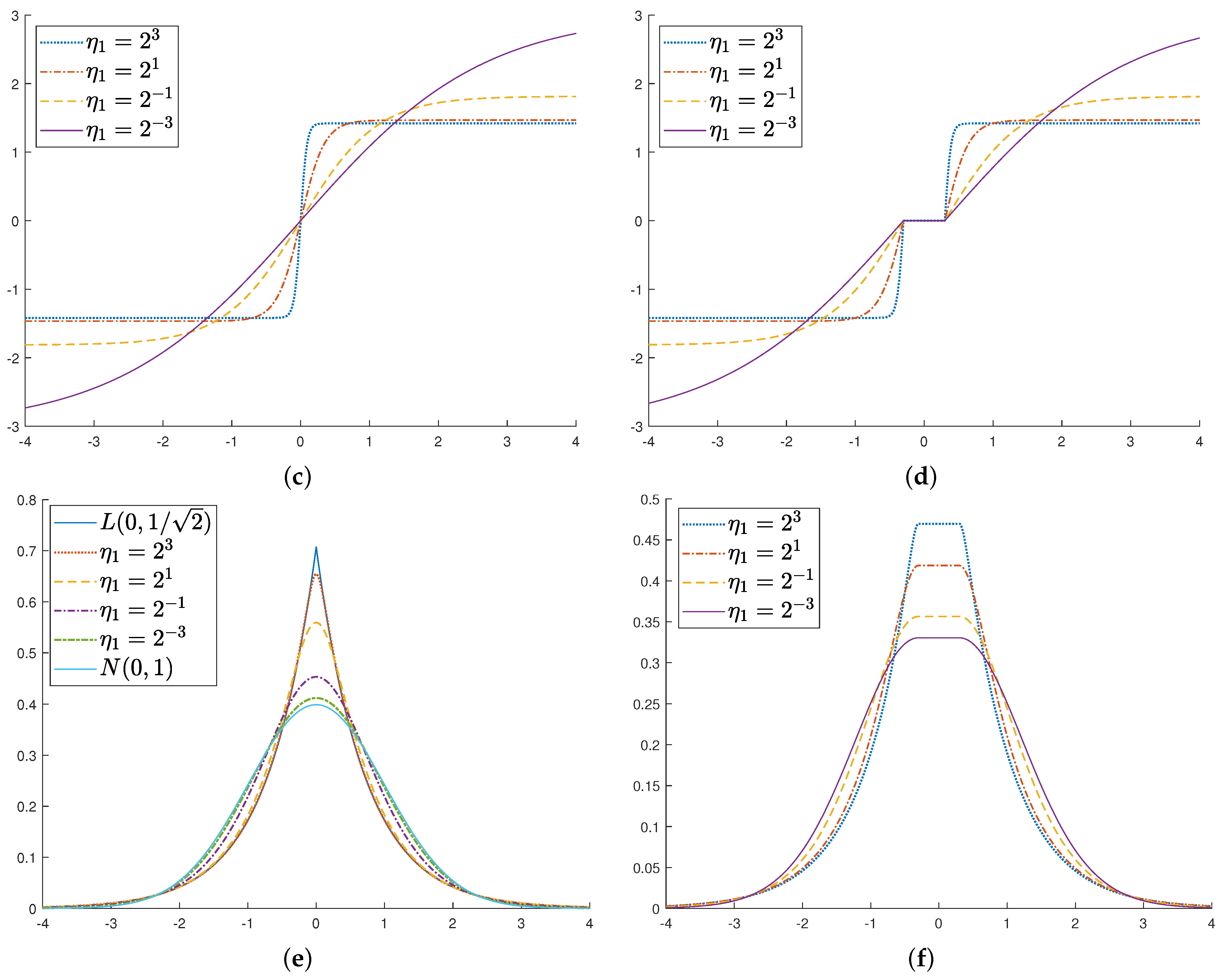
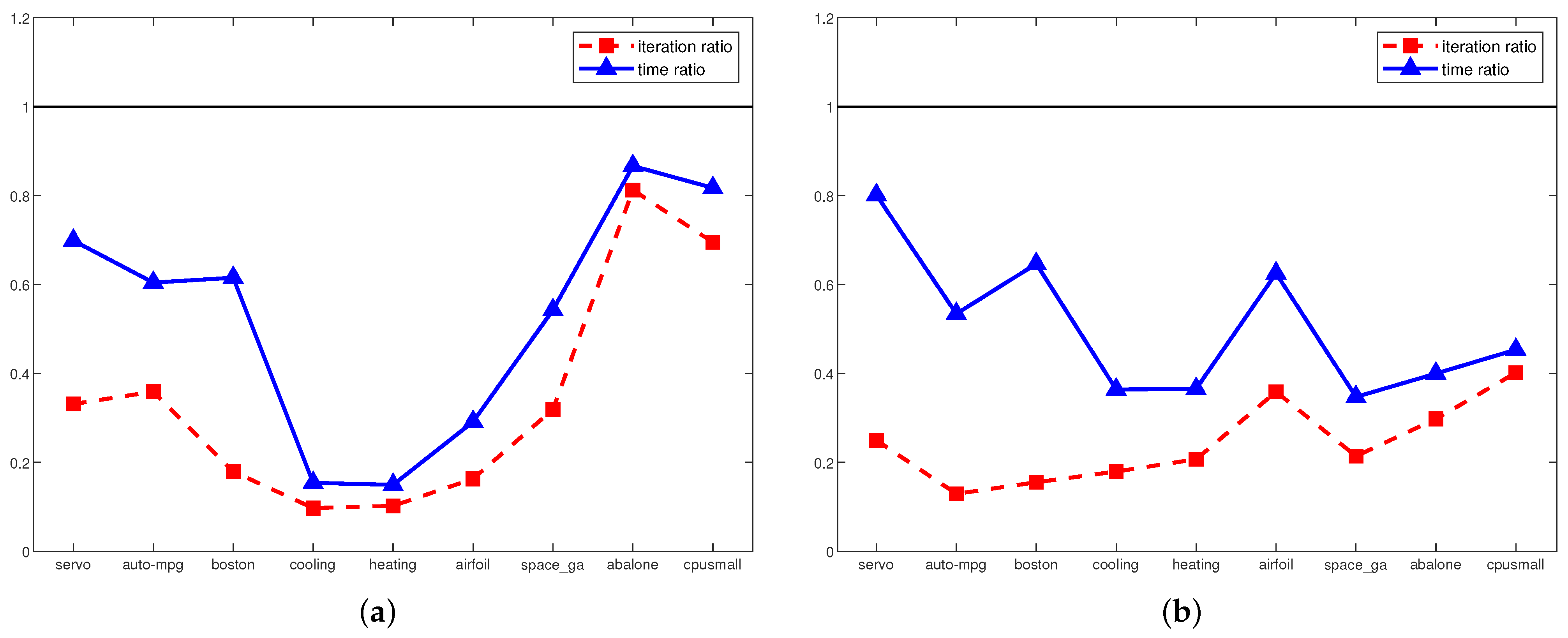
4. Experiments
5. Discussion
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Vapnik, V.N. Statistical Learning Theory; John Wiley & Sons: New York, NY, USA, 1998. [Google Scholar]
- Boser, B.; Guyon, I.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992. [Google Scholar]
- Cortes, C.; Vapnik, V.N. Support-vector network. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Arnosti, N.A.; Kalita, J.K. Cutting Plane Training for Linear Support Vector Machines. IEEE Trans. Knowl. Data Eng. 2013, 25, 1186–1190. [Google Scholar] [CrossRef]
- Chu, D.; Zhang, C.; Tao, Q. A Faster Cutting Plane Algorithm with Accelerated Line Search for Linear SVM. Pattern Recognit. 2017, 67, 127–138. [Google Scholar] [CrossRef]
- Xu, Y.; Akrotirianakis, I.; Chakraborty, A. Proximal gradient method for huberized support vector machine. Pattern Anal. Appl. 2016, 19, 989–1005. [Google Scholar] [CrossRef]
- Ito, N.; Takeda, A.; Toh, K.C. A unified formulation and fast accelerated proximal gradient method for classification. J. Mach. Learn. Res. 2017, 18, 1–49. [Google Scholar]
- Majlesinasab, N.; Yousefian, F.; Pourhabib, A. Self-Tuned Mirror Descent Schemes for Smooth and Nonsmooth High-Dimensional Stochastic Optimization. IEEE Trans. Autom. Control 2019, 64, 4377–4384. [Google Scholar] [CrossRef]
- Balasundaram, S.; Gupta, D.; Kapil. Lagrangian support vector regression via unconstrained convex minimization. Neural Netw. 2014, 51, 67–79. [Google Scholar] [CrossRef]
- Balasundaram, S.; Yogendra, M. A new approach for training Lagrangian support vector regression. Knowl. Inf. Syst. 2016, 49, 1097–1129. [Google Scholar] [CrossRef]
- Balasundaram, S.; Benipal, G. On a new approach for Lagrangian support vector regression. Neural Comput. Appl. 2018, 29, 533–551. [Google Scholar] [CrossRef]
- Wang, H.; Shi, Y.; Niu, L.; Tian, Y. Nonparallel Support Vector Ordinal Regression. IEEE Trans. Cybern. 2017, 47, 3306–3317. [Google Scholar] [CrossRef]
- Yin, J.; Li, Q. A semismooth Newton method for support vector classification and regression. Comput. Optim. Appl. 2019, 73, 477–508. [Google Scholar] [CrossRef]
- Platt, J.C. Fast training of support vector machines using sequential minimal optimization. In Kernel Methods: Support Vector Machines; Schölkopf, B., Burges, C., Smola, A., Eds.; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Keerthi, S.S.; Shevade, S.K.; Bhattacharyya, C.; Murthy, K.R.K. Improvements to Platt’s SMO algorithm for SVM classifier design. Neural Comput. 2001, 13, 637–649. [Google Scholar] [CrossRef]
- Fan, R.E.; Chen, P.H.; Lin, C.J. Working set selection using second order information for training support vector machines. J. Mach. Learn. Res. 2005, 6, 1889–1918. [Google Scholar]
- Flake, G.W.; Lawrence, S. Efficient SVM regression training with SMO. Mach. Learn. 2002, 46, 271–290. [Google Scholar] [CrossRef]
- Guo, J.; Takahashi, N.; Nishi, T. A novel sequential minimal optimization algorithm for support vector regression. In Neural Information Processing. ICONIP 2006. Lecture Notes in Computer Science; King, I., Wang, J., Chan, L.W., Wang, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 827–836. [Google Scholar]
- Takahashi, N.; Guo, J.; Nishi, T. Global convergence of SMO algorithm for support vector regression. IEEE Trans. Neural Netw. 2008, 19, 971–982. [Google Scholar] [CrossRef]
- Kocaoğlu, A. An efficient SMO algorithm for Solving non-smooth problem arising in ε-insensitive support vector regression. Neural Process. Lett. 2019, 50, 933–955. [Google Scholar] [CrossRef]
- Kocaoğlu, A. A sequential minimal optimization algorithm with second-order like information to solve a non-smooth support vector regression constrained dual problem. Uludağ Univ. J. Fac. Eng. 2021, 26, 1111–1120. [Google Scholar] [CrossRef]
- Tang, L.; Tian, Y.; Yang, C.A. Nonparallel support vector regression model and its SMO-type solver. Neural Netw. 2018, 105, 431–446. [Google Scholar] [CrossRef]
- Abe, S. Optimizing working sets for training support vector regressors by Newton’s method. In Proceedings of the International Joint Conference on Neural Networks, Killarney, Ireland, 12–17 July 2015. [Google Scholar]
- Keerthi, S.S.; Shevade, S.K. SMO algorithm for least-squares SVM formulations. Neural Comput. 2003, 15, 487–507. [Google Scholar] [CrossRef]
- Lopez, J.; Suykens, J.A.K. First and Second Order SMO Algorithms for LS-SVM Classifiers. Neural Process. Lett. 2011, 33, 31–44. [Google Scholar] [CrossRef]
- Kumar, R.; Sinha, A.; Chakrabarti, S.; Vyas, O.P. A fast learning algorithm for one-class slab support vector machines. Knowl. Based Syst. 2021, 53, 107267. [Google Scholar] [CrossRef]
- Gu, B.; Shan, Y.; Quan, X.; Zheng, G. Accelerating sequential minimal optimization via Stochastic subgradient descent. IEEE Trans. Cybern. 2021, 51, 2215–2223. [Google Scholar] [CrossRef] [PubMed]
- Galvan, G.; Lapucci, M.; Lin, C.J. A two-Level decomposition framework exploiting first and second order information for SVM training problems. J. Mach. Learn. Res. 2021, 22, 1–38. [Google Scholar]
- Huang, X.; Shi, L.; Suykens, J.A.K. Support vector machine classifier with pinball loss. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 984–997. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Shi, L.; Suykens, J.A.K. Sequential minimal optimization for SVM with pinball loss. Neurocomputing 2015, 149, 1596–1603. [Google Scholar] [CrossRef]
- Huang, X.; Shi, L.; Suykens, J.A.K. Asymmetric least squares support vector machine classifiers. Comput. Stat. Data Anal. 2014, 70, 395–405. [Google Scholar] [CrossRef]
- Farooq, F.; Steinwart, I. An SVM-like approach for expectile regression. Comput. Stat. Data Anal. 2017, 109, 159–181. [Google Scholar] [CrossRef]
- Balasundaram, S.; Meena, Y. Robust Support Vector Regression in Primal with Asymmetric Huber Loss. Neural Process. Lett. 2019, 49, 1399–1431. [Google Scholar] [CrossRef]
- Zhang, S.; Hu, Q.; Xie, Z.; Mi, J. Kernel ridge regression for general noise model with its application. Neurocomputing 2015, 149, 836–846. [Google Scholar] [CrossRef]
- Prada, J.; Dorronsoro, J.R. General noise support vector regression with non-constant uncertainty intervals for solar radiation prediction. J. Mod. Power Syst. Clean Energy 2018, 6, 268–280. [Google Scholar] [CrossRef]
- Wanga, Y.; Yang, L.; Yuan, C. A robust outlier control framework for classification designed with family of homotopy loss function. Neural Netw. 2019, 112, 41–53. [Google Scholar] [CrossRef] [PubMed]
- Anand, P.; Khemchandani, R.R.; Chandra, S. A class of new support vector regression models. Appl. Soft Comput. 2020, 94, 106446. [Google Scholar] [CrossRef]
- Dong, H.; Yang, L. Kernel-based regression via a novel robust loss function and iteratively reweighted least squares. Knowl. Inf. Syst. 2021, 63, 1149–1172. [Google Scholar] [CrossRef]
- Karal, O. Maximum likelihood optimal and robust Support Vector Regression with lncosh loss function. Neural Netw. 2017, 94, 1–12. [Google Scholar] [CrossRef]
- Kocaoğlu, A.; Karal, Ö.; Güzeliş, C. Analysis of chaotic dynamics of Chua’s circuit with lncosh nonlinearity. In Proceedings of the 8th International Conference on Electrical and Electronics Engineering, Bursa, Turkey, 28–30 November 2013. [Google Scholar]
- Liu, C.; Jiang, M. Robust adaptive filter with lncosh cost. Signal Process. 2020, 168, 107348. [Google Scholar] [CrossRef]
- Liang, T.; Li, Y.; Zakharov, Y.V.; Xue, W.; Qi, J. Constrained least lncosh adaptive filtering algorithm. Signal Process. 2021, 183, 108044. [Google Scholar] [CrossRef]
- Liang, T.; Li, Y.; Xue, W.; Li, Y.; Jiang, T. Performance and analysis of recursive constrained least lncosh algorithm under impulsive noises. IEEE Trans. Circuits Syst. II 2021, 68, 2217–2221. [Google Scholar] [CrossRef]
- Guo, K.; Guo, L.; Li, Y.; Zhang, L.; Dai, Z.; Yin, J. Efficient DOA estimation based on variable least Lncosh algorithm under impulsive noise interferences. Digital Signal Process. 2022, 122, 103383. [Google Scholar] [CrossRef]
- Yang, Y.; Zhou, H.; Gao, Y.; Wu, J.; Wang, Y.-G.; Fu, L. Robust penalized extreme learning machine regression with applications in wind speed forecasting. Neural Comput. Appl. 2022, 34, 391–407. [Google Scholar] [CrossRef]
- Zhao, H.; Wang, Z.; Xu, W. Augmented complex least lncosh algorithm for adaptive frequency estimation. IEEE Trans. Circuits Syst. II 2023, 70, 2685–2689. [Google Scholar] [CrossRef]
- Yang, Y.; Zhou, H.; Wu, J.; Ding, Z.; Tian, Y.-C.; Yue, D.; Wang, Y.-G. Robust adaptive rescaled lncosh neural network regression toward time-series forecasting. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 5658–5669. [Google Scholar] [CrossRef]
- Faliva, M.; Zoia, M.G. A distribution family bridging the Gaussian and the Laplace laws, Gram–Charlier expansions, Kurtosis behaviour, and entropy features. Entropy 2017, 19, 149. [Google Scholar] [CrossRef]
- Debruyne, M.; Hubert, H.; Suykens, J.A.K. Model selection in kernel based regression using the influence function. J. Mach. Learn. Res. 2008, 9, 2377–2400. [Google Scholar]
- Bubeck, S. Convex Optimization: Algorithms and Complexity. Found. Trends Mach. Learn. 2015, 8, 231–357. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines software. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
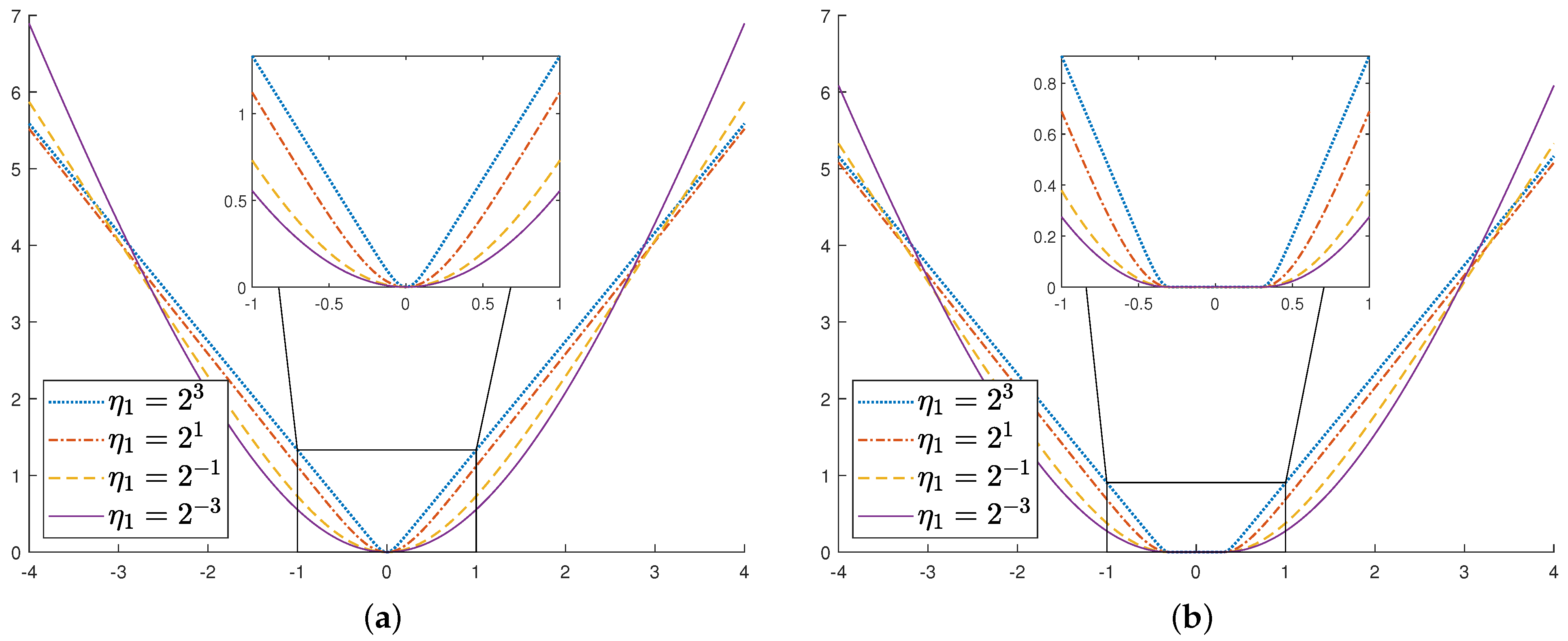


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method | (C, , , ) | # of SVs | Test RMSE | Training Cpu Time | # of Iterations |
|---|---|---|---|---|---|---|
| Servo (167x4) | - SVR | (, , 0) | 133.5 ± 0.53 | 0.886 ± 0.18 | 0.033 ± 0.04 | 459 ± 13.6 |
| -SVR | (, , ) | 130.9 ± 1.79 | 0.785 ± 0.27 | 0.138 ± 0.03 | 57,100.2 ± 16,430.5 | |
| -ln SVR | (, , 0, ) | 133.6 ± 0.52 | 0.726 ± 0.28 | 0.052 ± 0.04 | 1253 ± 53.5 | |
| Auto-mpg (392x7) | - SVR | (, , ) | 257.9 ± 7.23 | 2.776 ± 0.33 | 0.064 ± 0.03 | 1049.1 ± 37.7 |
| -SVR | (, , ) | 245.5 ± 4.06 | 2.674 ± 0.36 | 0.022 ± 0.03 | 5236.1 ± 938.0 | |
| -ln SVR | (, , , ) | 160.2 ± 6.11 | 2.595 ± 0.27 | 0.039 ± 0.02 | 967.9 ± 88.9 | |
| Boston (560x13) | - SVR | (, , 0) | 404.8 ± 0.42 | 4.626 ± 1.72 | 0.059 ± 0.03 | 4827.3 ± 106.9 |
| -SVR | (, , 1) | 265.8 ± 8.32 | 3.461 ± 0.78 | 0.058 ± 0.05 | 4062.1 ± 820.9 | |
| -ln SVR | (, , 1, ) | 269.3 ± 5.12 | 3.151 ± 0.38 | 0.061 ± 0.03 | 5261.9 ± 252.4 | |
| Cooling (768x8) | - SVR | (, , 0) | 614.4 ± 0.52 | 3.031 ± 0.33 | 0.044 ± 0.03 | 2339.4 ± 59.1 |
| -SVR | (, , 0) | 614.4 ± 0.52 | 1.981 ± 0.20 | 0.222 ± 0.06 | 39,150.1 ± 4705.9 | |
| -ln SVR | (, , 0, ) | 614.4 ± 0.52 | 1.772 ± 0.15 | 0.153 ± 0.08 | 65,277.4 ± 1747.3 | |
| Heating (768x8) | - SVR | (, , 0) | 614.3 ± 0.67 | 1.980 ± 0.21 | 0.098 ± 0.02 | 9212.6 ± 213.4 |
| -SVR | (, , ) | 421.9 ± 8.28 | 1.124 ± 0.10 | 0.621 ± 0.19 | 143,945.9 ± 27,282.0 | |
| -ln SVR | (, , 0, ) | 614.4 ± 0.52 | 0.939 ± 0.06 | 0.267 ± 0.07 | 91,786.0 ± 2373.9 | |
| Airfoil (1503x5) | - SVR | (, , 0) | 1202.4 ± 0.52 | 3.849 ± 1.32 | 0.083 ± 0.05 | 4840.6 ± 130.3 |
| -SVR | (, , ) | 1103.5 ± 5.97 | 2.776 ± 0.26 | 0.147 ± 0.08 | 28,317.0 ± 3876.7 | |
| -ln SVR | (, , 1, ) | 789.7 ± 9.52 | 2.778 ± 0.27 | 0.120 ± 0.03 | 15,367.1 ± 451.2 | |
| Space ga (3107x6) | - SVR | (, , 0) | 2485.4 ± 0.70 | 1.232 ± 0.40 | 0.243 ± 0.03 | 8361.1 ± 655.1 |
| -SVR | (, , ) | 2184.9 ± 11.01 | 0.134 ± 0.01 | 0.508 ± 0.11 | 21,577.9 ± 2162.1 | |
| -ln SVR | (, , 0, ) | 2485.1 ± 0.74 | 0.116 ± 0.01 | 0.319 ± 0.06 | 20,649.9 ± 648.4 | |
| Abalone (4177x8) | - SVR | (, , 0) | 3341.2 ± 0.63 | 2.406 ± 0.22 | 0.308 ± 0.07 | 6336.3 ± 119.7 |
| -SVR | (, , ) | 1367.8 ± 20.42 | 2.288 ± 0.12 | 0.156 ± 0.02 | 916.5 ± 29.2 | |
| -ln SVR | (, , , ) | 1351.5 ± 19.13 | 2.208 ± 0.10 | 0.216 ± 0.06 | 8339.0 ± 594.8 | |
| Cpusmall (8192x12) | - SVR | (, , 0) | 6553.3 ± 0.48 | 3.478 ± 0.17 | 3.411 ± 0.28 | 14,239.7 ± 127.7 |
| -SVR | (, , 1) | 4542.1 ± 28.83 | 3.257 ± 0.06 | 0.713 ± 0.28 | 5976.9 ± 445.6 | |
| -ln SVR | (, , , ) | 5497.7 ± 16.87 | 3.126 ± 0.05 | 2.119 ± 0.53 | 48,499.2 ± 1151.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kocaoğlu, A. Efficient Optimization of a Support Vector Regression Model with Natural Logarithm of the Hyperbolic Cosine Loss Function for Broader Noise Distribution. Appl. Sci. 2024, 14, 3641. https://doi.org/10.3390/app14093641
Kocaoğlu A. Efficient Optimization of a Support Vector Regression Model with Natural Logarithm of the Hyperbolic Cosine Loss Function for Broader Noise Distribution. Applied Sciences. 2024; 14(9):3641. https://doi.org/10.3390/app14093641
Chicago/Turabian StyleKocaoğlu, Aykut. 2024. "Efficient Optimization of a Support Vector Regression Model with Natural Logarithm of the Hyperbolic Cosine Loss Function for Broader Noise Distribution" Applied Sciences 14, no. 9: 3641. https://doi.org/10.3390/app14093641
APA StyleKocaoğlu, A. (2024). Efficient Optimization of a Support Vector Regression Model with Natural Logarithm of the Hyperbolic Cosine Loss Function for Broader Noise Distribution. Applied Sciences, 14(9), 3641. https://doi.org/10.3390/app14093641