
Dynamic Grouping within Minimax Optimal Strategy for Stochastic Multi-ArmedBandits in Reinforcement Learning Recommendation

Abstract
1. Introduction
- We propose a new dynamic grouping within the minimax optimal strategy in the stochastic case (DG-MOSS) algorithm for reinforcement learning and providing multiple action selections. The algorithm uses dynamic grouping to ensure the balance of exploration and exploitation, and fully considers the feedback information in the selection process in a sufficient training recommendation.
- This paper presents the design of an adaptive episode length to effectively improve the training efficiency so that the parameters of the episode in the training are automatically rather than manually adjusted.
- We analyze and prove DG-MOSS’s upper bound of the regret value, which provides strong theoretical support for the feasibility of the algorithm.
- Extensive experiments were conducted on four different scales, densities, and field datasets with total rewards and average rewards evaluation metric settings. The experimental results demonstrate that the proposed approach outperforms nine baseline competitors. Furthermore, random attacks and average attacks prove that DG-MOSS has better robustness with sufficiently trained recommendation.
2. Related Works
3. Problem Formulation
4. DG-MOSS
4.1. Action Selection
4.1.1. UCB
| Algorithm 1 UCB |
Input: all arms
|
4.1.2. MOSS
| Algorithm 2 MOSS (minimax optimal strategy in the stochastic case) |
Input: all arms
|
4.2. DG-MOSS Algorithm Description
| Algorithm 3 DG-MOSS |
| Input: Select each arm k in the set A once of K possible arms.
Initialize: episode number , episode length , number of iterations .
|
4.3. The Upper Bound of the DM-MOSS Regret
5. Experiments
5.1. Experiment Platform and Data Preprocessing
5.2. Experimental Results and Analysis
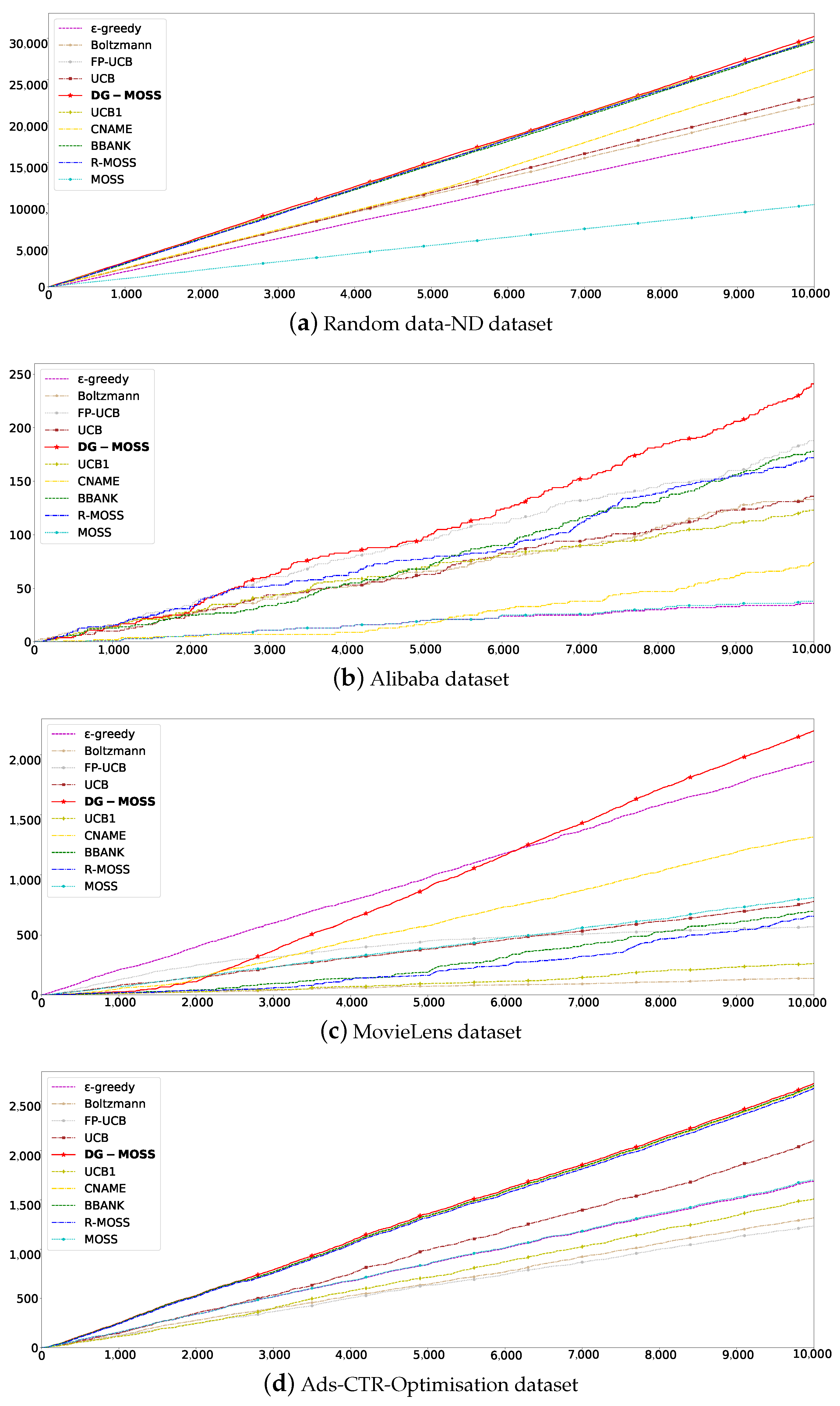
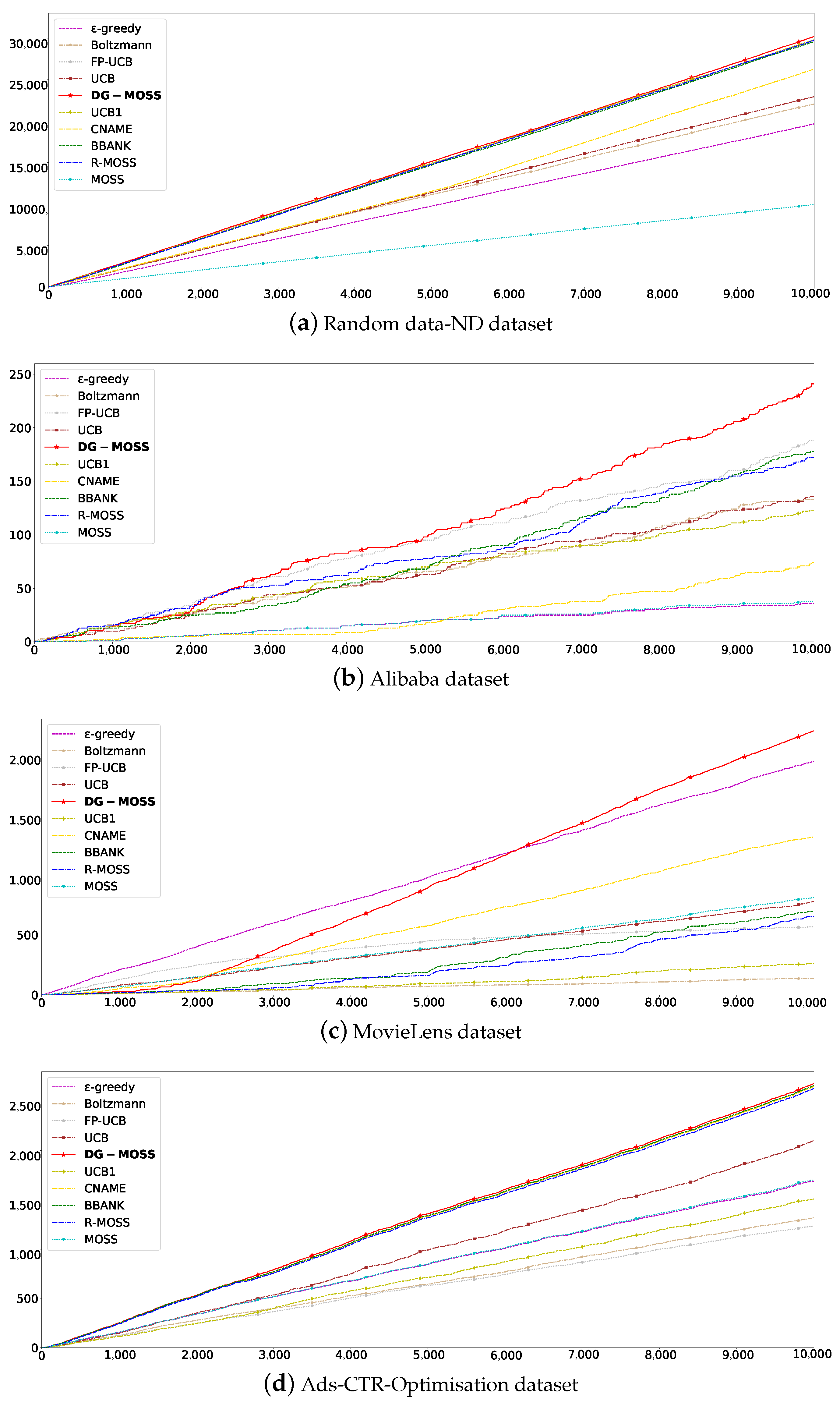
5.2.1. Total Rewards
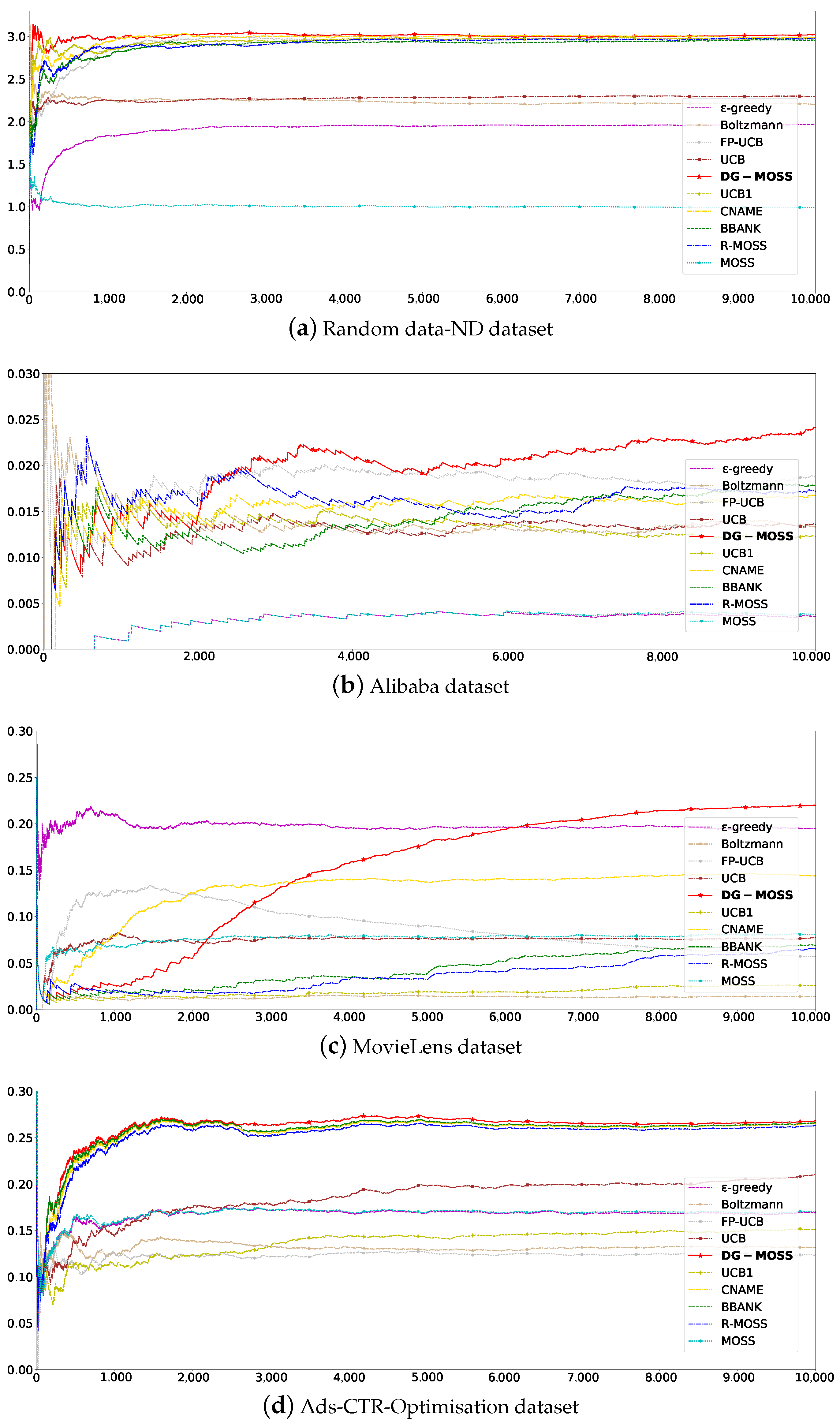
5.2.2. Average Rewards
5.2.3. Parameter Analysis
5.2.4. Adaptive
5.2.5. Robustness
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sutton, R.; Barto, A. Reinforcement learning: An Introduction. Robotica 1999, 17, 229–235. [Google Scholar] [CrossRef]
- Silver, D.; Singh, S.; Precup, D. Reward is enough. Artif. Intell. 2021, 299, 103535. [Google Scholar] [CrossRef]
- Auer, P. Finite-time analysis of the multiarmed bandit problem. Robotica 2002, 47, 235–256. [Google Scholar]
- Gutowski, N.; Amghar, T.; Camp, O. Gorthaur: A portfolio approach for dynamic selection of multi-armed bandit algorithms for recommendation. In Proceedings of the 31th International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 1164–1171. [Google Scholar]
- Tong, X.; Wang, P.; Niu, S. Reinforcement learning-based denoising network for sequential recommendation. Appl. Intell. 2023, 53, 1324–1335. [Google Scholar] [CrossRef]
- Qin, J.; Wei, Q.; Zhou, B. Research on optimal selection strategy of search engine keywords based on multi-armed bandit. In Proceedings of the 49th Hawaii International Conference on System Sciences (HICSS), Koloa, HI, USA, 5–8 January 2016; pp. 726–734. [Google Scholar]
- Takeuchi, S.; Hasegawa, M.; Kanno, K. Dynamic channel selection in wireless communications via a multi-armed bandit algorithm using laser chaos time series. Sci. Rep. 2020, 10, 1574. [Google Scholar] [CrossRef]
- Angulo, C.; Falomir, Z.; Anguita, D. Bridging cognitive models and recommender systems. Cogn. Comput. 2020, 12, 426–427. [Google Scholar] [CrossRef]
- Li, Y.; Wang, S.; Pan, Q. Learning binary codes with neural collaborative filtering for efficient recommendation systems. Knowl. Based Syst. 2019, 172, 64–75. [Google Scholar] [CrossRef]
- Dhelim, S.; Aung, N.; Bouras, M.A. A survey on personality-aware recommendation systems. Artif. Intell. Rev. 2022, 55, 2409–2454. [Google Scholar] [CrossRef]
- Yang, Y.; Chen, C.; Lu, T. Hierarchical reinforcement learning for conversational recommendation with knowledge graph reasoning and heterogeneous questions. IEEE Trans. Serv. Comput. 2023, 16, 3439–3452. [Google Scholar] [CrossRef]
- Pang, G.; Wang, X.; Wang, L.; Hao, F.; Lin, Y.; Wan, P.; Min, G. Efficient Deep Reinforcement Learning-Enabled Recommendation. IEEE Trans. Sci. Eng. 2023, 10, 871–886. [Google Scholar] [CrossRef]
- Gu, H.; Xia, Y.; Xie, H.; Shi, X.; Shang, M. Robust and efficient algorithms for conversational contextual bandit. Inf. Sci. 2024, 657, 119993. [Google Scholar] [CrossRef]
- Kanade, V.; Liu, Z.; Kanade, V. Distributed non-stochastic experts. Adv. Neural Inf. Process. Syst. 2012, 25, 260–268. [Google Scholar]
- Agrawal, P.; Tulabandula, T. Learning by repetition: Stochastic multi-armed bandits under priming effect. In Proceedings of the 36th International Conference on Uncertainty in Artificial Intelligence (UAI), Online, 3–6 August 2020; pp. 470–479. [Google Scholar]
- Gopalan, P.; Hofman, J.M.; Blei, D.M. Scalable recommendation with hierarchical poisson factorization. In Proceedings of the 31th International Conference on Uncertainty in Artificial Intelligence (UAI), Amsterdam, The Netherlands, 12–16 July 2015; pp. 326–335. [Google Scholar]
- Wang, L.; Bai, Y.; Sun, W. Fairness of exposure in stochastic bandits. In Proceedings of the 38th International Conference on Machine Learning (ICML), Online, 18–24 July 2021; pp. 7700–7709. [Google Scholar]
- Guo, X.; Song, J.; Fang, Y. Explain in Simple Terms Reinforcement Learning; Publishing House of Electronics Industry: Beijing, China, 2020. [Google Scholar]
- Zhang, X.; Zou, Q.; Liang, B. An adaptive algorithm in multi-armed bandit problem. Comput. Res. Dev. 2019, 56, 643–654. [Google Scholar]
- Green, L.; Fry, A.; Myerson, J. Discounting of delayed rewards: A life-span comparison. Psychol. Sci. 1994, 5, 33–36. [Google Scholar] [CrossRef]
- Hong, X.; Qiao, T.; Qingsheng, Z. A multiplier bootstrap approach to designing robust algorithms for contextual bandits. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 9887–9899. [Google Scholar]
- Wang, T.; Shi, X.; Shang, M. Diversity-Aware Top-N Recommendation: A Deep Reinforcement Learning Way. In Proceedings of the 8th CCF International Conference on Big Data (CCF BigData), Chongqing, China, 22–24 October 2020; pp. 1324–1335. [Google Scholar]
- Panaganti, K.; Kalathil, D.M. Bounded regret for finitely parameterized multi-armed bandits. IEEE Control Syst. Lett. 2021, 5, 1073–1078. [Google Scholar] [CrossRef]
- Audibert, J.; Bubeck, S. Minimax policies for adversarial and stochastic bandits. In Proceedings of the 22nd International Conference on Learning Theory (COLT), Montreal, QC, Canada, 18–21 June 2009; pp. 217–226. [Google Scholar]
- Wei, L.; Srivastava, V. Nonstationary stochastic multiarmed bandits: Ucb policies and minimax regret. arXiv 2021, arXiv:2101.08980. [Google Scholar]
- Karpov, N.; Zhang, Q. Batched coarse ranking in multi-armed bandits. In Proceedings of the 34th International Conference on Neural Information Processing Systems (HeurIPS), Online, 6–12 December 2020; pp. 16037–16047. [Google Scholar]
- Esfandiari, H.; Karbasi, A.; Mehrabian, A.; Mirrokni, V. Regret bounds for batched bandits. In Proceedings of the 35th International AAAI Conference on Artifical Intelligence (AAAI), Online, 2–9 February 2021; pp. 7340–7348. [Google Scholar]
- Sun, D. Wald’s identity and geometric expectation. Am. Math. Mon. 2020, 127, 716. [Google Scholar] [CrossRef]
- Hoeffding, W. Probability inequalities for sums of bounded random variables. Am. Stat. Assoc. 1963, 58, 13–30. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Algorithms | Parameters 1 | Parameters 2 | Average Rewards | Average Regrets |
|---|---|---|---|---|
| -greedy | 0.05 | NULL | 0.1690 | 0.8310 |
| Boltzmann | 1 | NULL | 0.1318 | 0.8669 |
| CNAME | 0.1 | 0.2648 | 0.7342 | |
| UCB | NULL | 0.2103 | 0.7897 | |
| UCB1 | NULL | 0.1510 | 0.8490 | |
| FP-UCB | 0.1 | 0.1237 | 0.7562 | |
| BBANK | 0.1 | 0.2654 | 0.7346 | |
| MOSS | NULL | 0.1703 | 0.8297 | |
| R-MOSS | 0.1 | 0.2631 | 0.7369 | |
| DG-MOSS | 0.1 | 0.2681 | 0.7319 |
| Parameters | Average Rewards |
|---|---|
| 0.2076 | |
| 0.2673 | |
| 0.2681 | |
| 0.2656 | |
| 0.2659 |
| Datasets | Episode |
|---|---|
| Initial | 1000 |
| Random data-ND | 24 |
| Alibaba | 44 |
| Movie | 34 |
| Ads-CTR-Optimisation | 638 |
| Algorithms | Original | 1% R | 3% R | 5% R | 10% R | 1% A | 3% A | 5% A | 10% A |
|---|---|---|---|---|---|---|---|---|---|
| -greedy | 0.1944 | 0.1932 | 0.2015 | 0.2070 | 0.2186 | 0.1969 | 0.2131 | 0.2291 | 0.2574 |
| Boltzmann | 0.0139 | 0.0192 | 0.0276 | 0.0368 | 0.0546 | 0.0143 | 0.0157 | 0.0181 | 0.0266 |
| CNAME | 0.2296 | 0.2266 | 0.1671 | 0.2496 | 0.2562 | 0.2420 | 0.2347 | 0.2696 | 0.2860 |
| UCB | 0.0778 | 0.0815 | 0.0870 | 0.0962 | 0.1092 | 0.0850 | 0.1022 | 0.1179 | 0.1504 |
| UCB1 | 0.0262 | 0.0357 | 0.0356 | 0.0415 | 0.0614 | 0.0310 | 0.0406 | 0.0411 | 0.0678 |
| FP-UCB | 0.0568 | 0.0421 | 0.0496 | 0.0546 | 0.0706 | 0.0636 | 0.0498 | 0.0547 | 0.0792 |
| BBANK | 0.1983 | 0.2379 | 0.2526 | 0.2562 | 0.2643 | 0.2421 | 0.2441 | 0.2494 | 0.2978 |
| MOSS | 0.0809 | 0.0847 | 0.0908 | 0.0983 | 0.1130 | 0.0887 | 0.1073 | 0.1220 | 0.1541 |
| R-MOSS | 0.0653 | 0.0621 | 0.0710 | 0.751 | 0.0908 | 0.0667 | 0.0752 | 0.0865 | 0.1430 |
| DG-MOSS | 0.2378 | 0.2396 | 0.2539 | 0.2585 | 0.2720 | 0.2422 | 0.2609 | 0.2729 | 0.2996 |
| Algorithms | Original | 1% R | 3% R | 5% R | 10% R | 1% A | 3% A | 5% A | 10% A |
|---|---|---|---|---|---|---|---|---|---|
| -greedy | 0.1690 | 0.1720 | 0.1756 | 0.1846 | 0.1935 | 0.1774 | 0.1896 | 0.2052 | 0.2405 |
| Boltzmann | 0.1318 | 0.1332 | 0.1460 | 0.1503 | 0.1568 | 0.1346 | 0.1469 | 0.1587 | 0.1805 |
| CNAME | 0.2648 | 0.2657 | 0.2712 | 0.2725 | 0.2829 | 0.2698 | 0.2841 | 0.3006 | 0.3315 |
| UCB | 0.2103 | 0.2088 | 0.2113 | 0.2289 | 0.2312 | 0.2091 | 0.2344 | 0.2409 | 0.2753 |
| UCB1 | 0.1510 | 0.1581 | 0.1584 | 0.1681 | 0.1780 | 0.1572 | 0.1695 | 0.1768 | 0.220 |
| FP-UCB | 0.1237 | 0.1180 | 0.1314 | 0.1400 | 0.1576 | 0.1190 | 0.1340 | 0.1392 | 0.1614 |
| BBANK | 0.2654 | 0.2684 | 0.2711 | 0.2755 | 0.2850 | 0.2745 | 0.2867 | 0.3011 | 0.3317 |
| MOSS | 0.1703 | 0.1736 | 0.1780 | 0.1855 | 0.1987 | 0.1786 | 0.1938 | 0.2082 | 0.2440 |
| R-MOSS | 0.2631 | 0.2640 | 0.2678 | 0.2719 | 0.2831 | 0.2704 | 0.2834 | 0.2983 | 0.2766 |
| DG-MOSS | 0.2681 | 0.2693 | 0.2723 | 0.2762 | 0.2853 | 0.2748 | 0.2868 | 0.3013 | 0.3322 |
| Algorithms | Original | 1% R | 3% R | 5% R | 10% R | 1% A | 3% A | 5% A | 10% A |
|---|---|---|---|---|---|---|---|---|---|
| -greedy | 0.0036 | 0.0075 | 0.0089 | 0.0076 | 0.0096 | 0.0041 | 0.0037 | 0.035 | 0.0040 |
| Boltzmann | 0.0133 | 0.0158 | 0.0153 | 0.0155 | 0.0199 | 0.0144 | 0.0151 | 0.0154 | 0.0155 |
| CNAME | 0.015 | 0.0156 | 0.0223 | 0.0178 | 0.0176 | 0.0284 | 0.0235 | 0.0252 | 0.0206 |
| UCB | 0.0136 | 0.0152 | 0.0195 | 0.0178 | 0.0182 | 0.0154 | 0.0189 | 0.0188 | 0.0196 |
| UCB1 | 0.0123 | 0.0148 | 0.0163 | 0.0157 | 0.0173 | 0.0155 | 0.0149 | 0.0158 | 0.0148 |
| FP-UCB | 0.0188 | 0.0202 | 0.0235 | 0.0233 | 0.0246 | 0.0214 | 0.0287 | 0.0265 | 0.0265 |
| BBANK | 0.0220 | 0.0241 | 0.0283 | 0.0266 | 0.0265 | 0.0291 | 0.0333 | 0.0343 | 0.0315 |
| MOSS | 0.0038 | 0.0071 | 0.0090 | 0.0078 | 0.0096 | 0.0038 | 0.0038 | 0.0038 | 0.0038 |
| R-MOSS | 0.0172 | 0.0145 | 0.0229 | 0.0220 | 0.0243 | 0.0228 | 0.0275 | 0.0239 | 0.0286 |
| DG-MOSS | 0.0223 | 0.0250 | 0.0283 | 0.0268 | 0.0280 | 0.0295 | 0.0339 | 0.0344 | 0.0316 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, J.; Zhu, J.; Zhao, X.; Ji, Z. Dynamic Grouping within Minimax Optimal Strategy for Stochastic Multi-ArmedBandits in Reinforcement Learning Recommendation. Appl. Sci. 2024, 14, 3441. https://doi.org/10.3390/app14083441
Feng J, Zhu J, Zhao X, Ji Z. Dynamic Grouping within Minimax Optimal Strategy for Stochastic Multi-ArmedBandits in Reinforcement Learning Recommendation. Applied Sciences. 2024; 14(8):3441. https://doi.org/10.3390/app14083441
Chicago/Turabian StyleFeng, Jiamei, Junlong Zhu, Xuhui Zhao, and Zhihang Ji. 2024. "Dynamic Grouping within Minimax Optimal Strategy for Stochastic Multi-ArmedBandits in Reinforcement Learning Recommendation" Applied Sciences 14, no. 8: 3441. https://doi.org/10.3390/app14083441
APA StyleFeng, J., Zhu, J., Zhao, X., & Ji, Z. (2024). Dynamic Grouping within Minimax Optimal Strategy for Stochastic Multi-ArmedBandits in Reinforcement Learning Recommendation. Applied Sciences, 14(8), 3441. https://doi.org/10.3390/app14083441