1. Introduction
A knowledge graph (KG) [
1] is a network of concepts where the fundamental element is a triple in the form of (entity, relationship, entity). Many knowledge graphs, including WordNet [
2], NELL [
3], and Freebase [
4], have been developed and successfully applied in intelligent service areas like information retrieval, recommendation systems, and question answering systems. Since these large-scale knowledge graphs are often incomplete and require constant supplementation, knowledge reasoning [
5,
6] involves deducing new entities or relationships from existing data, thus continually enhancing the knowledge graph. As a result, knowledge reasoning has emerged as a hot topic in the field of knowledge graph research in recent years.
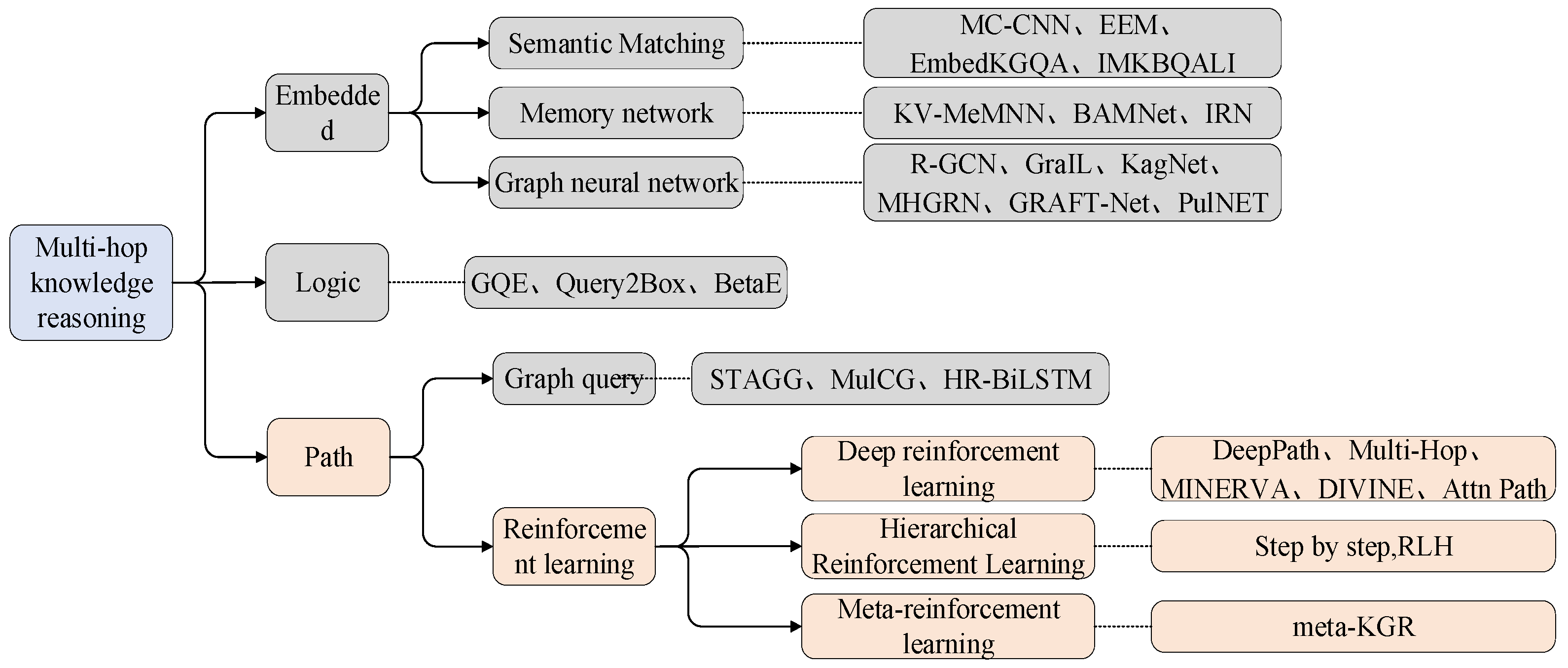
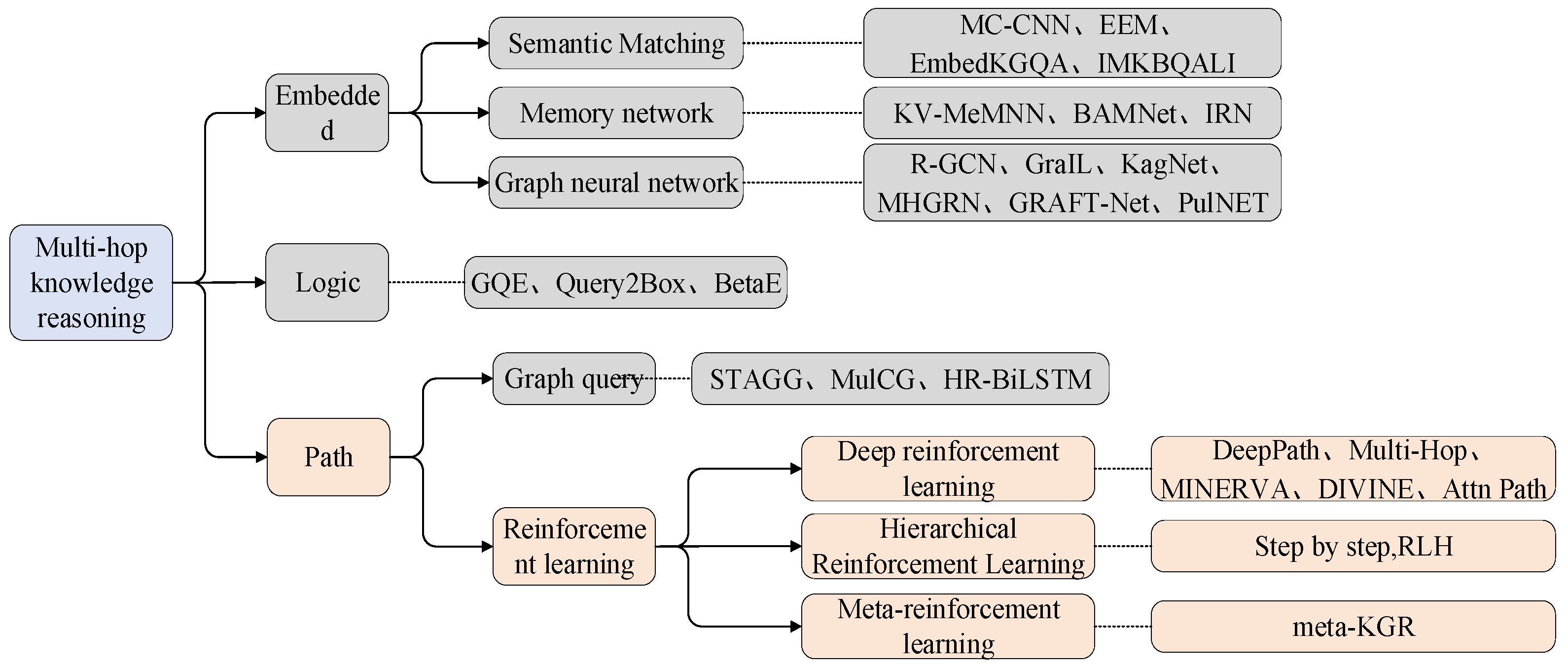
Currently, studies on KG reasoning can be broadly categorized into three types: embedding-based reasoning, logic-based multi-hop reasoning, and path-based multi-hop reasoning, as illustrated in
Figure 1. Multi-hop refers to the process of going from one node to another node in a graph network through multiple intermediate nodes. Multi-hop knowledge graph inference starts from one entity, goes through multiple entities and relationships, and finally reaches the target entity, focusing on learning the logical rules between semantics from the relational path of the knowledge graph. One popular approach for knowledge reasoning is to use neural networks to learn entity and relation embeddings [
7,
8,
9]. These methods represent entities and relations as low-dimensional dense vectors and use the similarity between vectors to reason about relationships between entities or determine the truth of a given triplet, thus completing the KG. However, their capacity to capture multi-hop path relationships is limited since they rely on the triplet representation of the KG, making them less applicable for more complex reasoning tasks. As a result, another solution is to combine multi-hop path information between entity pairs for knowledge reasoning. The Path Ranking Algorithm (PRA) [
10] uses a random walk based on a restart inference mechanism to perform multiple bounded depth-first searches and utilizes supervised learning to choose more reasonable paths, thereby mitigating the aforementioned issue. Recently, multi-hop reasoning has been formulated as a Markov decision process (MDP) [
11] due to its interpretability and excellent performance. Reinforcement learning (RL) [
12,
13] has been used to conduct efficient path search. DeepPath [
14] is the first multi-hop reasoning method to transfer RL to KGs, wherein entities are mapped to states and relations to actions. The goal is to use RL to sample relationships and expand the path. These methods present new research directions for KG reasoning.
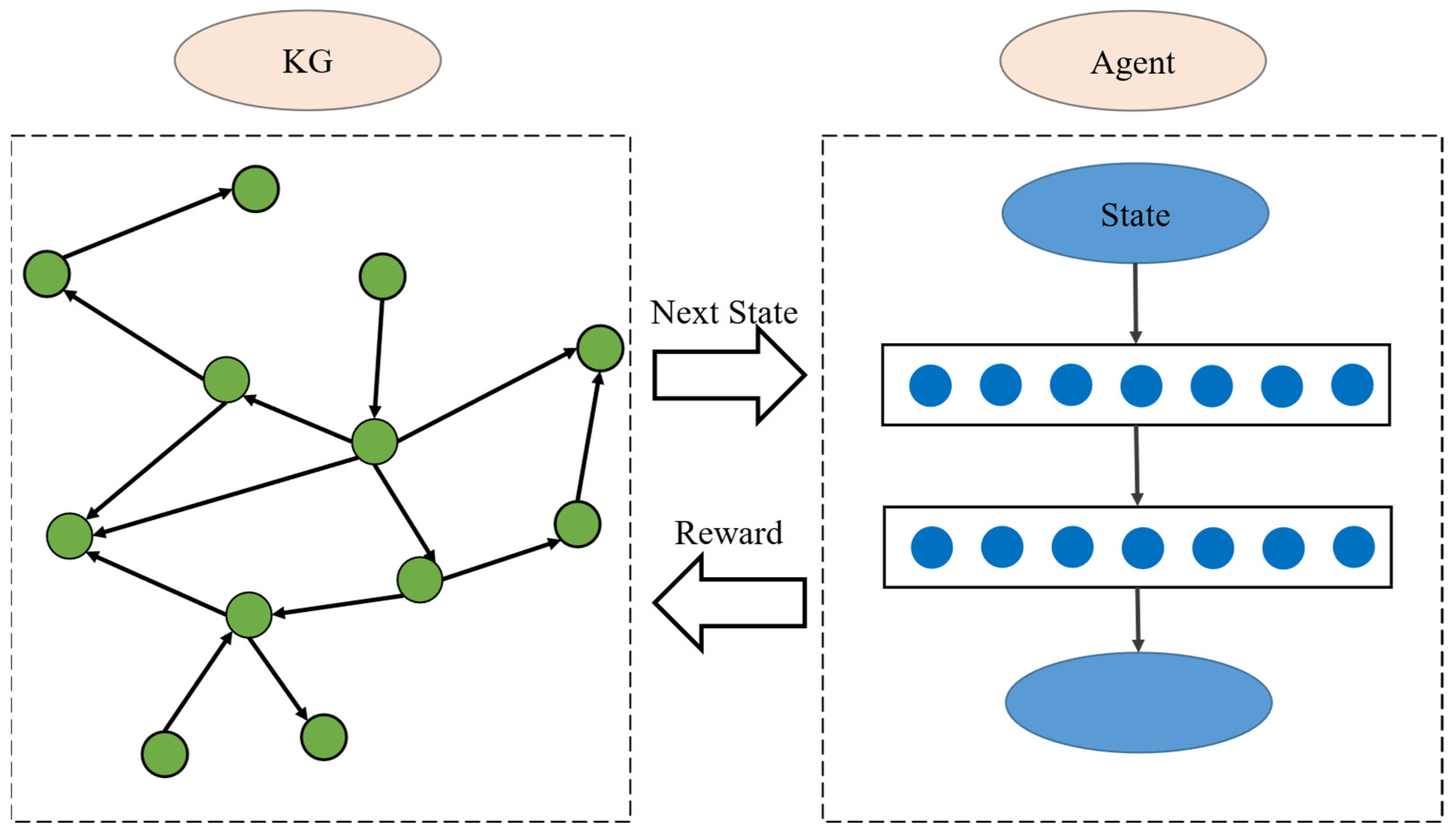
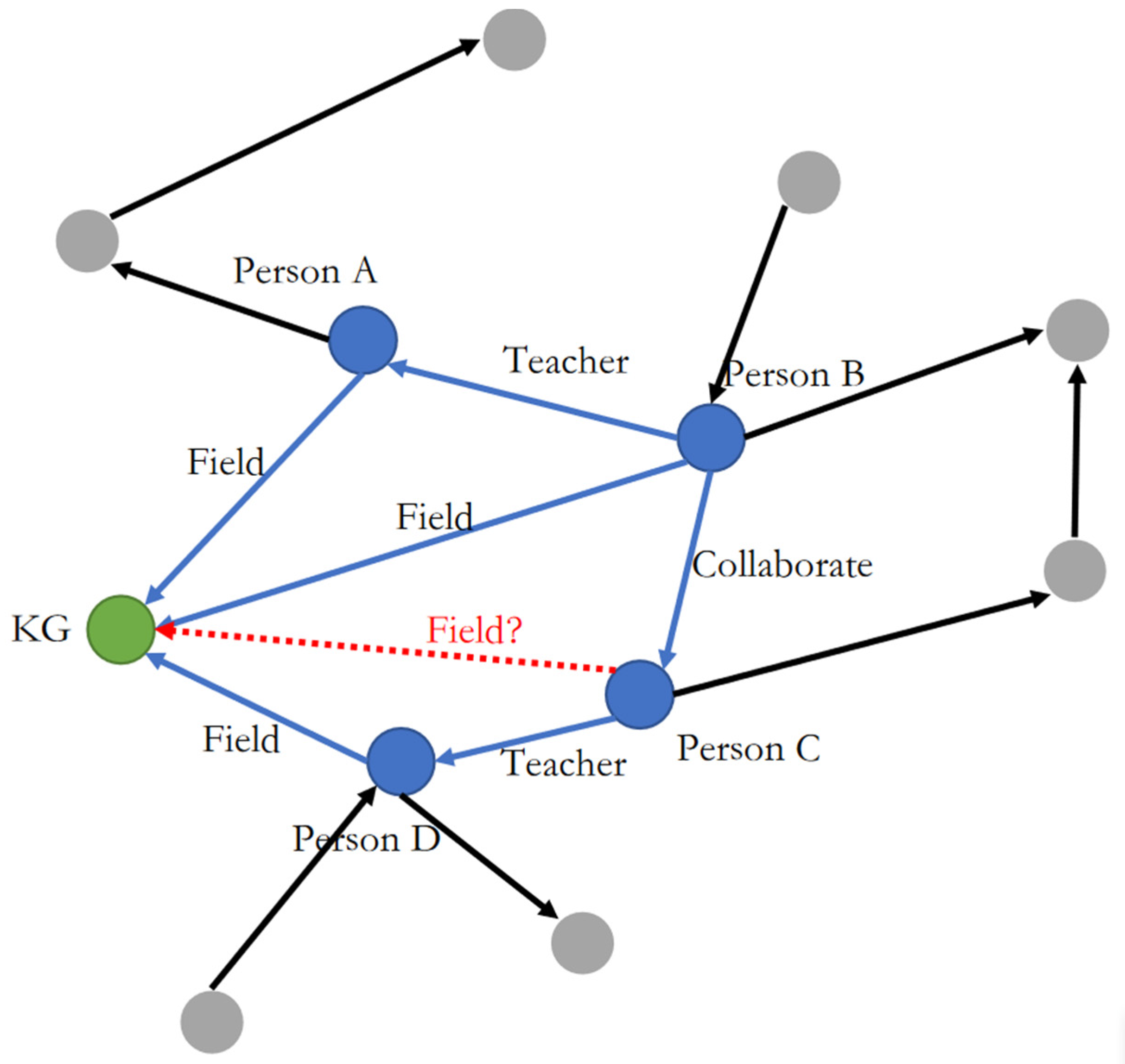
However, using RL for path search in actual knowledge reasoning tasks is inefficient. Firstly, most RL methods fail to embed entities and relations effectively when constructing the KG environment, resulting in a low success rate for the agent’s path search. Secondly, the KG has many invalid paths. For example, given the triplets Person A, Field, knowledge graph; Person B, Teacher, Person A; Person B, Field, knowledge graph; Person B, Collaborate, Person C; Person C, Teacher, Person D; and Person D, Field, knowledge graph, it is possible to infer Person C, Field, knowledge graph, as depicted in
Figure 2.
During the reasoning process, the relationship “Field” plays a critical role, and the gray dots represent invalid actions due to the inability of gray entities to serve as the subject or object of “Field”. When the agent selects an invalid action during the traversal process, it retraces its steps and makes a new selection. However, there is a possibility that the agent might repeatedly choose the same invalid action, leading to inefficiency. Similarly, there may be instances where the agent selects the same valid path repeatedly, resulting in a loop.
Presently, the latest research progress on reinforcement learning is as follows. Hildebrandt et al. [
15] proposed a knowledge graph reasoning method based on the dynamics of discussion, which defines a tuple classification task as a game between two opposing reinforcement learning agents. In this method, a searcher iteratively completes the model’s training by searching for parameters that can persuade the discriminator to accept its position. The downside of this method might be that it could require extensive iterations and interactions, which can be computationally expensive, and it may be difficult to find a global optimum due to getting stuck in local optima. In response to the issue of multiple semantics for entities or relations in the multi-hop inference process, Wan et al. [
16] proposed the RLH model that includes a hierarchical decision-making process. In this model, the high-level strategy learns from historical information, while the low-level strategy is responsible for learning specific sub-actions and the division of the action space. The limitation of this method could be the coordination and efficiency between the high-level and low-level strategies, as well as the acquisition and application of historical information in complex environments. To address the problem of sparse reward signals in knowledge reasoning, the RuleGuider [
17] model uses high-quality rules generated by symbolic reasoning methods to provide reward supervision for a walk-based agent. This model combines a symbolic logic rule generation model and a walk-based rule guide inference model, enhancing the interpretability of the inference paths. However, this model’s flaw might be the difficulty of generating high-quality rules and the reliance on the quality of the rules, which may not cover all inference paths sufficiently. The DacKGR [
18] model, targeting the problem of multi-hop reasoning on sparse graphs, utilizes embedding models to predict the current state’s action space and dynamically adds additional reliable actions to the path search space to alleviate sparsity issues in multi-hop reasoning. However, this approach may lead to an overly large state space due to the dynamic addition of actions, increasing the complexity of the search. Fu et al. [
19] proposed the CPL model for open-domain knowledge graph reasoning tasks, which jointly trains a multi-hop reasoning agent and a fact extraction agent, using facts extracted from external data to assist the path reasoning process. The downside of this approach might lie in its dependency on external data and the challenge of effectively integrating external data to ensure the consistency of the information. At the same time, the LSTM model is used in all of the above methods. Typically, reinforcement learning with LSTM networks is used for knowledge graph reasoning, storing the agent’s historical actions. However, the LSTM model is prone to overfitting and struggles to capture long-term dependencies in long sequence data, which can result in a performance decline on new data. All of these issues lead to a reduction in the accuracy of path selection and may make it challenging for the agent to obtain rewards from the policy network during the initial traversal stage. Typically, reinforcement learning with LSTM networks is used for knowledge graph reasoning, storing the agent’s historical actions. However, the LSTM model is prone to overfitting and struggles to capture long-term dependencies in long sequence data, which can result in a performance decline on new data. All of these issues lead to a reduction in the accuracy of path selection and may make it challenging for the agent to obtain rewards from the policy network during the initial traversal stage.
The problems of the low efficiency and accuracy issues in path selection can actually be solved through “Strong memory ability”. “Strong memory” refers to the ability to effectively retain and retrieve information across multiple iterations or steps of the learning process. This ability is critical for tasks that involve understanding long-term relationships or making inferences across multiple steps. Existing methods may lack this capability due to limitations in information representation or model architecture. Therefore, in our work, we propose a fusion of representation learning and reinforcement learning, combining ConvR embeddings and reinforcement learning to form a knowledge graph reasoning method with strong memory ability, named ConvR-based reinforcement learning knowledge graph reasoning with “Strong memory ability” (ConvRL-KGM). The proposed model transforms the path selection problem into a sequence decision problem and makes three key contributions.
Using ConvR embeddings to generate vector representations of entities and relationships in the knowledge graph, the intelligent agent can accurately search for paths during its interaction with the knowledge graph environment, thus enhancing the efficiency of the reasoning method.
To address the problem of invalid actions, random dropout operations are performed on actions to reduce their interference with the intelligent agent. This enables the agent to receive comprehensive training and enhances the model’s generalization ability by encouraging the policy network to select different relationships.
To overcome the limitations of the LSTM model, this paper proposes an improved SLSTM (SELU-activated LSTM) model that uses SLSTM to store the agent’s historical actions and introduces self-attention to force the agent to choose different actions and avoid constant pauses on the same entity node. This approach also prevents overfitting to the training data and helps the model find higher success rate paths for reasoning tasks during the training process, thereby improving the model’s “Strong memory ability”.
3. Reinforcement Learning Framework Algorithm Based on ConvR Embedding
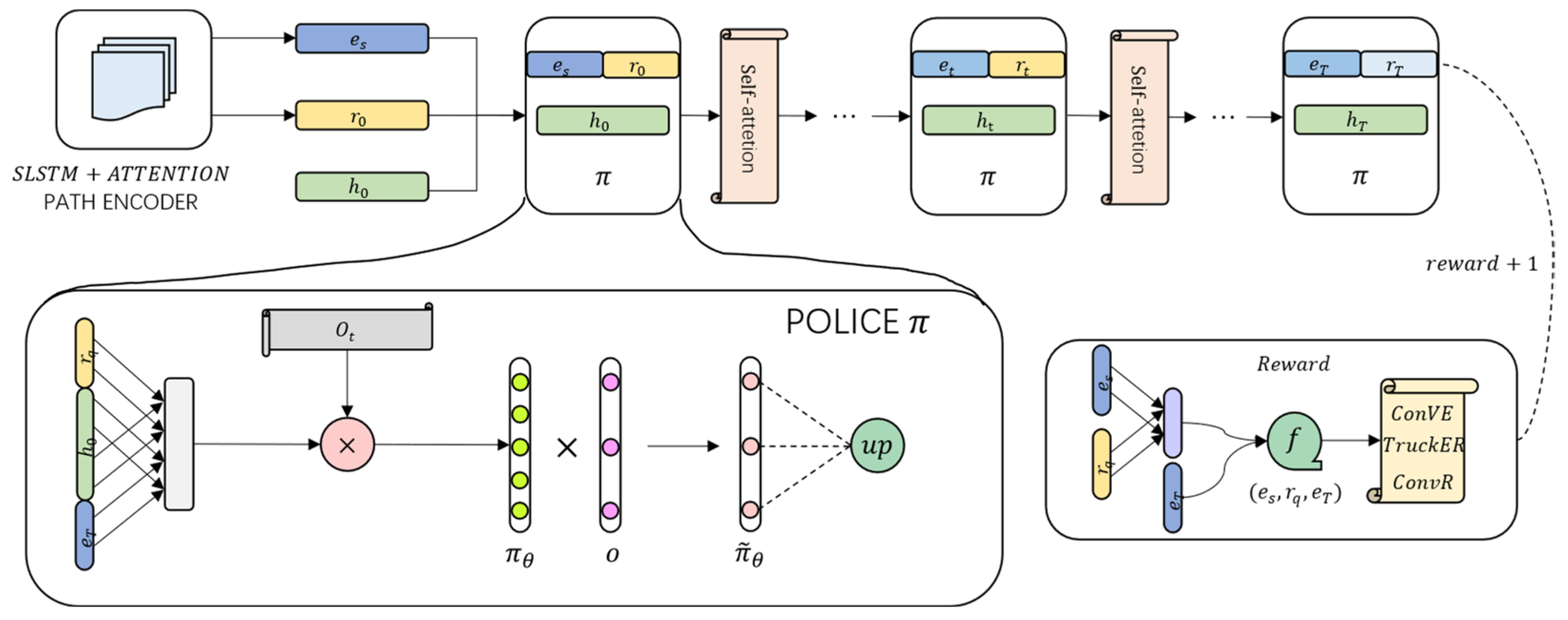
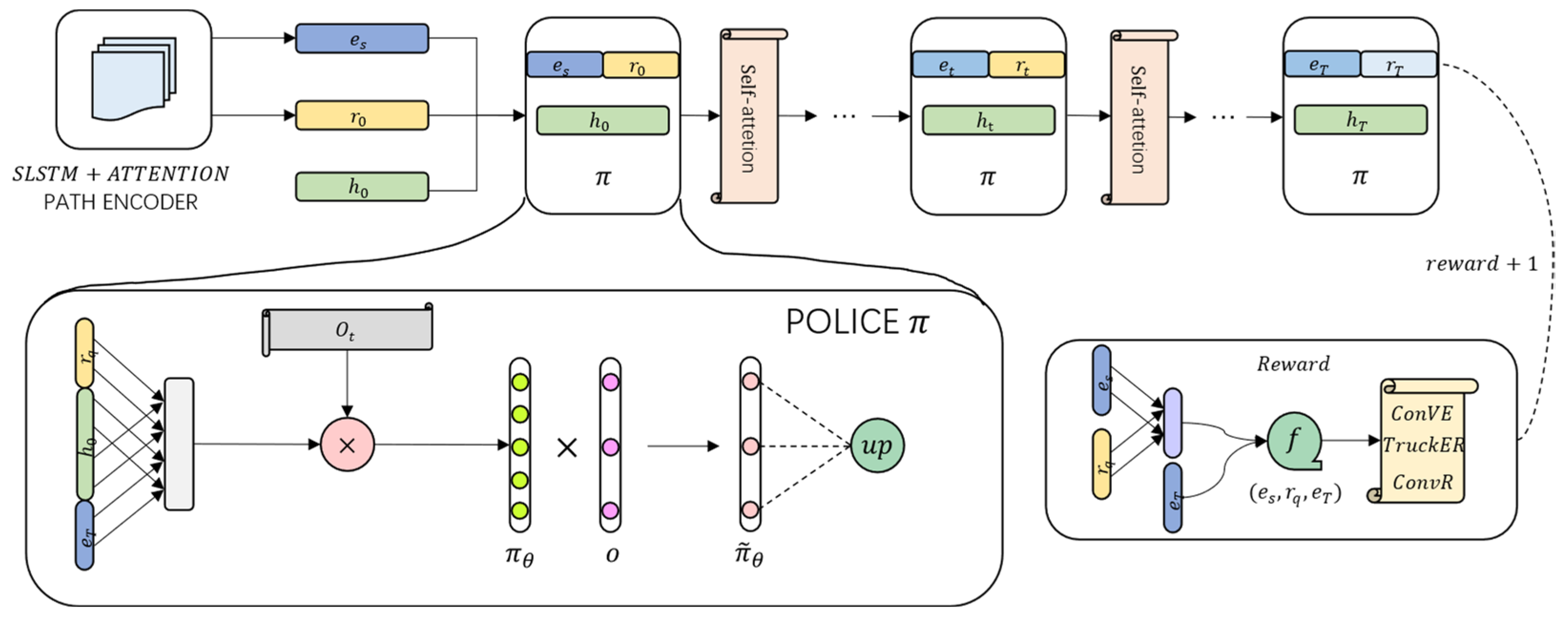
The goal of knowledge reasoning is to predict the reliable path between entity pairs. Therefore, in order to improve the overall quality and efficiency of prediction, in our work, we propose a knowledge reasoning method ConvRL-KGM (ConvR-based Reinforcement Learning Knowledge Graph Reasoning with Strong Memory) based on reinforcement learning of ConvR embedding, which will find the path between entity pairs. Possible relationships and path information are transformed into sequential decision-making problems for reinforcement learning. The model is shown in
Figure 6.
First, we use ConvR embedding to map entities and relationships into vectors containing triplet semantic information and score the path corresponding to each entity. Then, we use the continuous vectorized representation of entities and relationships obtained by ConvR embedding as a neural network based on reinforcement learning. The input of the network enables the model to make full use of the existing triplet information of the knowledge graph, and the RL agent trains the strategy network during the walking process. Finally, action pruning and SLSTM+self-attention are used to control the path selection search and path and take effective actions in the reinforcement learning strategy to improve the overall performance of the model.
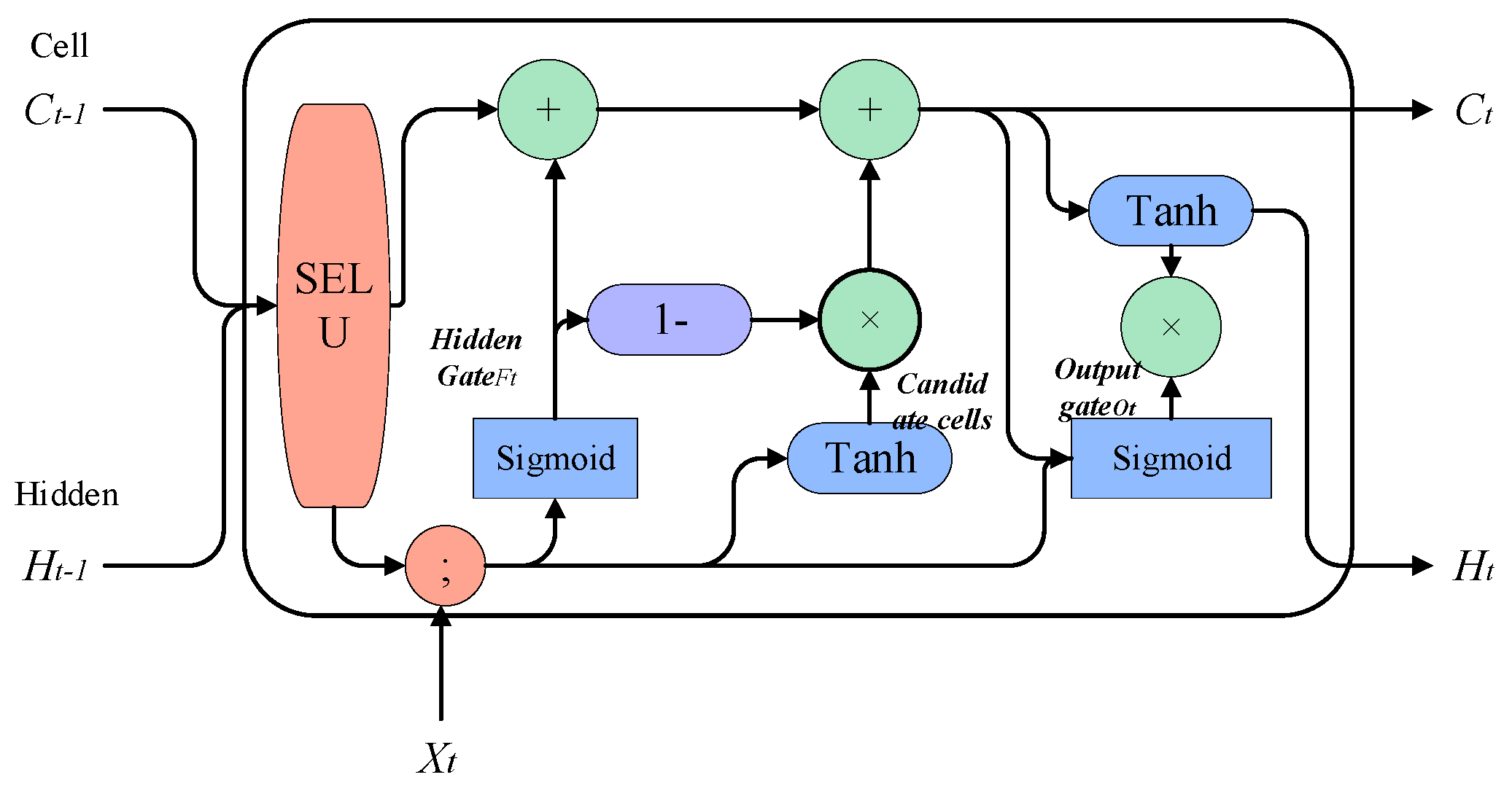
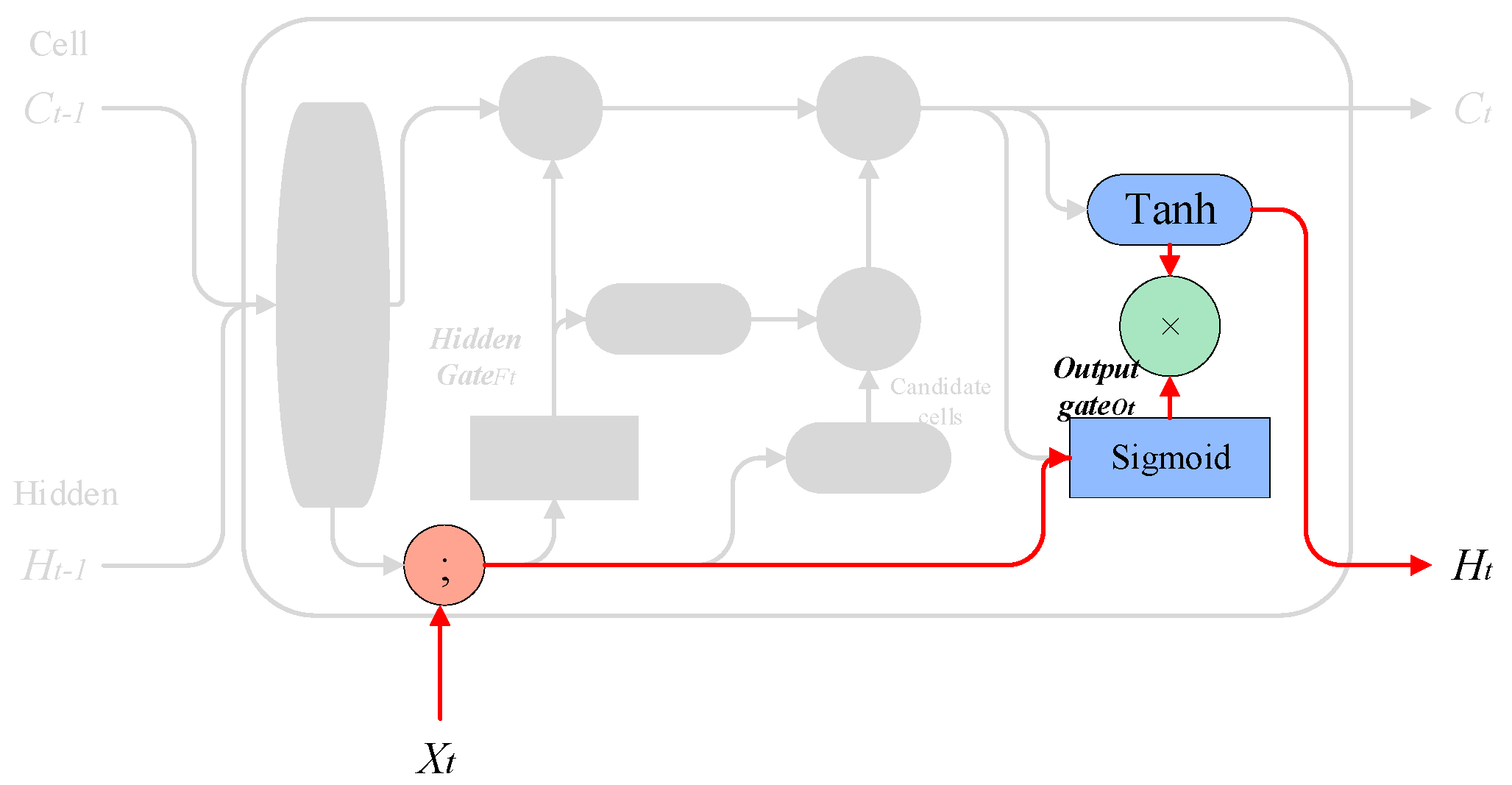
3.1. SLSTM
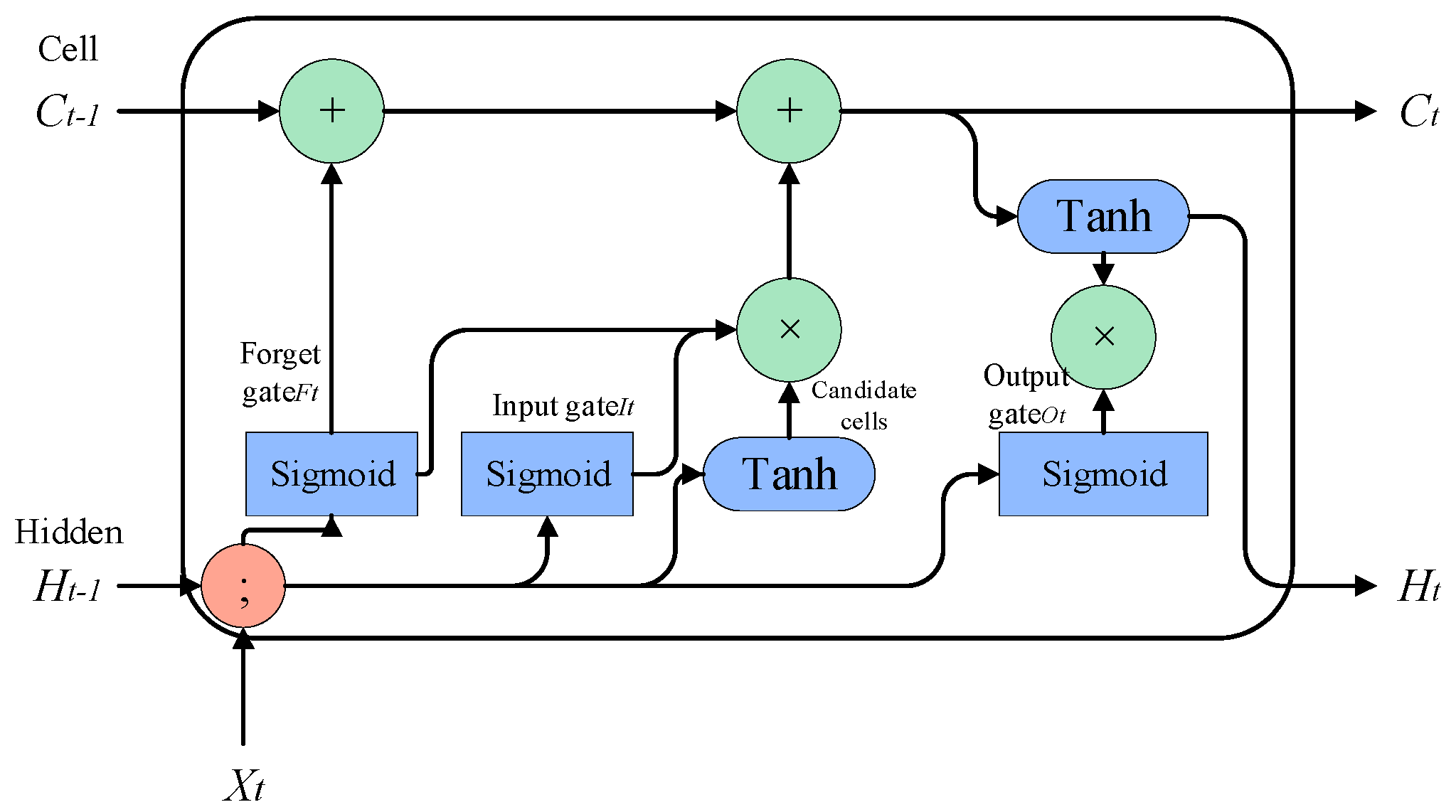
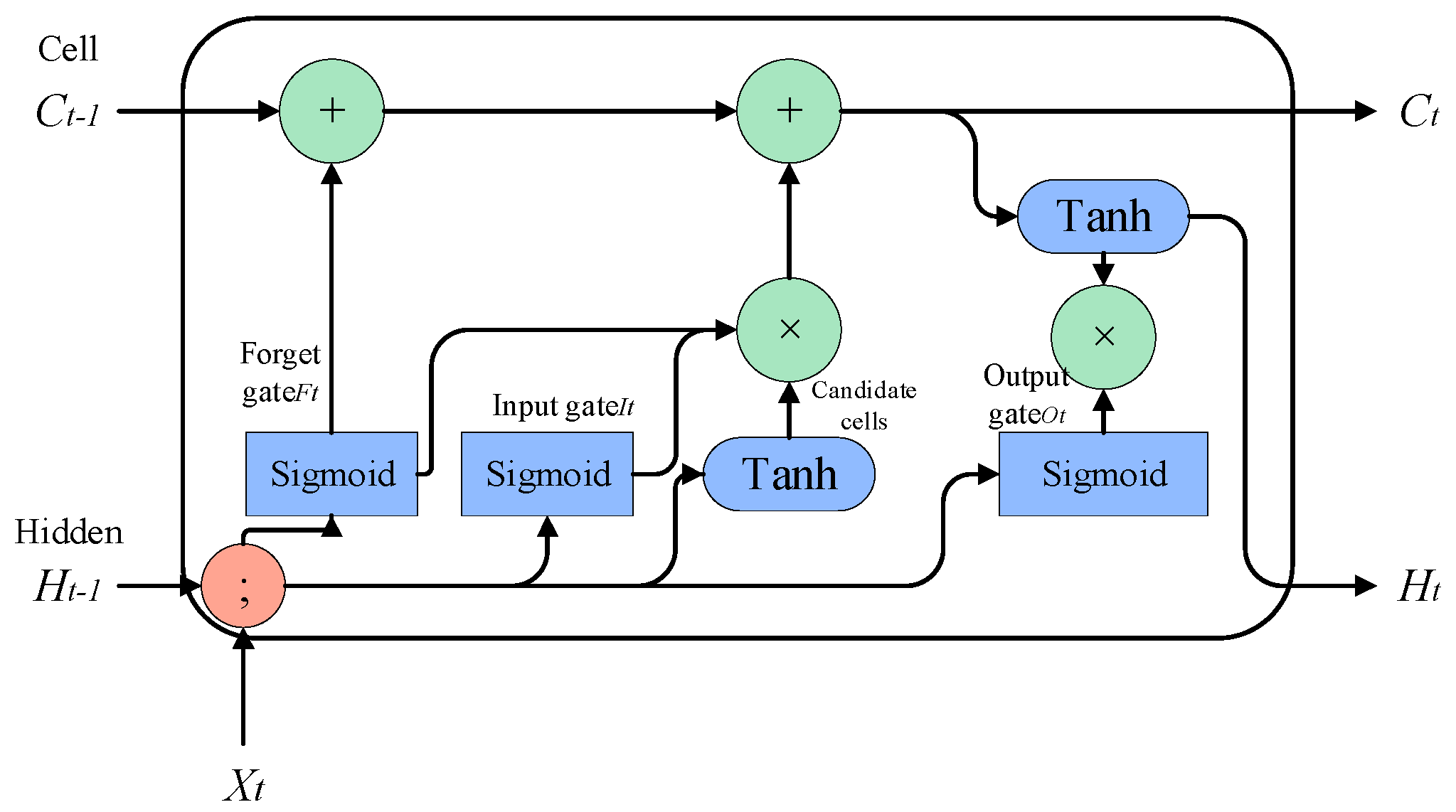
The core idea of the LSTM model is to use the “cell state” . The “cell state” acts like a conveyor belt that runs directly throughout the entire chain, with only a small amount of linear interaction. Information flowing through it can easily be kept unchanged. LSTM removes or adds information to the cell state using a carefully designed structure called “gates”. A gate is a way of selectively allowing information to pass through, and it consists of a sigmoid neural network layer and a pointwise multiplication operation. Three gate functions are introduced in LSTM: the input gate, forget gate, and output gate, which are used to control input values, memory values, and output values, respectively.
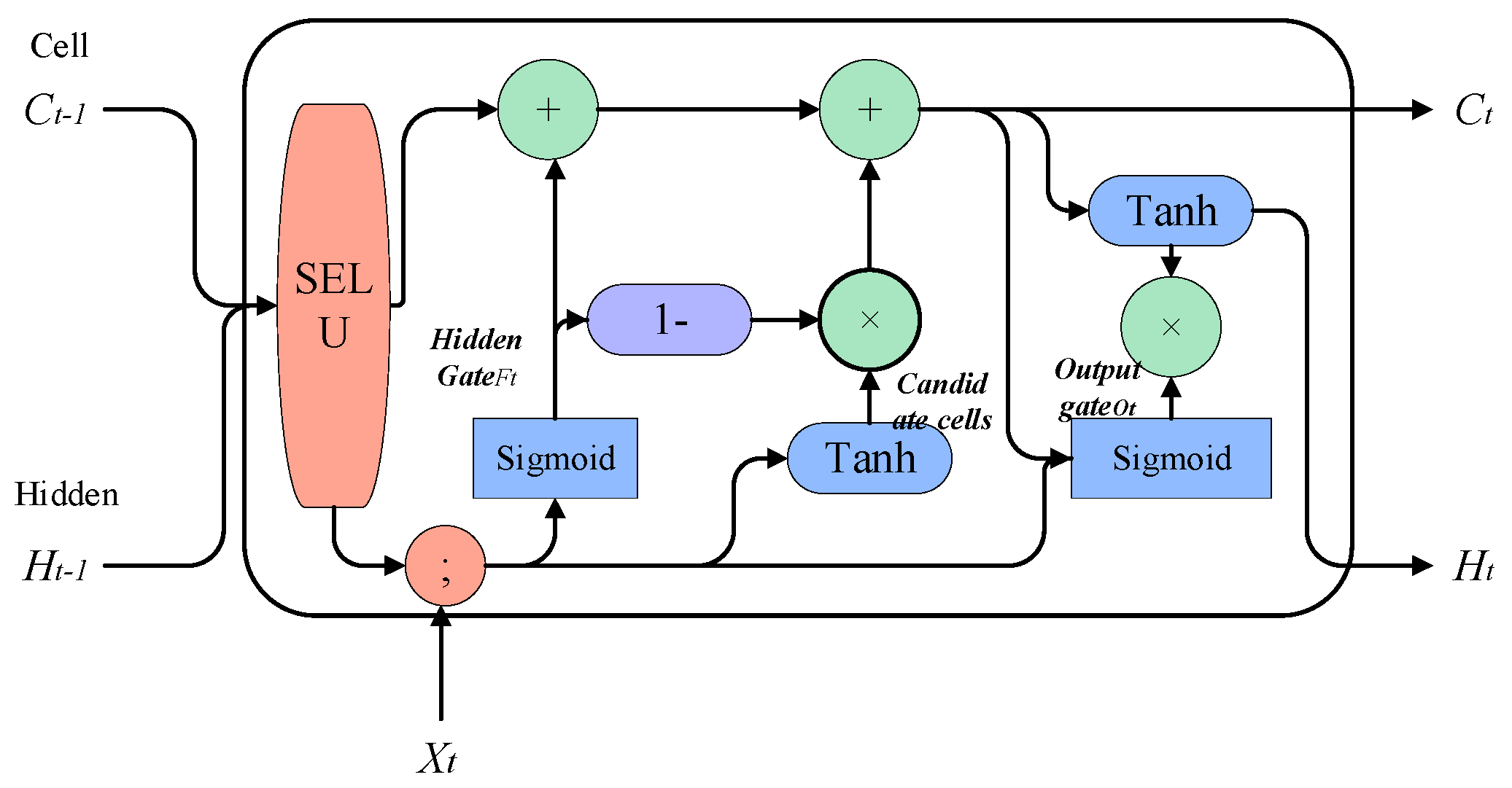
However, the LSTM model may face the problem of long-term dependencies when processing long sequence data, where earlier inputs have less impact on subsequent predictions. This is because the memory unit of the LSTM model may gradually decay as the time step increases, causing it to gradually forget earlier input information. This may lead to a decrease in the performance of the LSTM model in long sequence data. Moreover, as the amount of data increases and the network deepens, there is a risk of gradient vanishing. Therefore, in our work, we propose an improved LSTM algorithm—the SELU-activated LSTM (SLSTM) algorithm—to address the problems of long-term dependencies, gradient vanishing, and exploding. The model is shown in
Figure 5.
Based on the latest research results on activation functions, the improved LSTM model makes the state
and
enter an activation function during the gate computation process, and the output end also needs to go through an activation function. The activation function selected is the SELU function [
35], which ensures that the gradient of each layer is transmitted in a stable manner during the optimization process, and the SELU function has the function of automatically converging the activation values of neurons to zero mean and unit variance, achieving the purpose of self-normalization. In addition, the normalization of SELU restricts the range of variance and also ensures robustness in multi-level training, effectively avoiding the problem of gradient vanishing and exploding during the training process. The function is presented in Eq. (1) as follows:
where
refers to the value entered into the activation function; both
and
are hyperparameters, and their values are obtained by proof rather than training.
in formula 1 is the scaling coefficient,
is the scaling parameter, and the values of
and
are derived mathematically, where
is usually chosen as 1.0507 and
is usually chosen as 1.6733.
Then, the input gate is removed and combined with the forget gate, and the addition of new information and the retention of the old state are set as complementary values (with a sum of 1). That is, we only forget when new information needs to be added, and we only add new information when forgetting is necessary. For knowledge reasoning, in order to ensure the accuracy of reasoning, long-term effective memory is required. Therefore, combined with the “peephole connections” proposed by Gers and Schmidhuber, 2000 [
36], the hidden gate is connected to the state of the previous unit, and the output gate is connected to the current unit. Status connection is established. The overall improved SLSTM model is shown in
Figure 7.
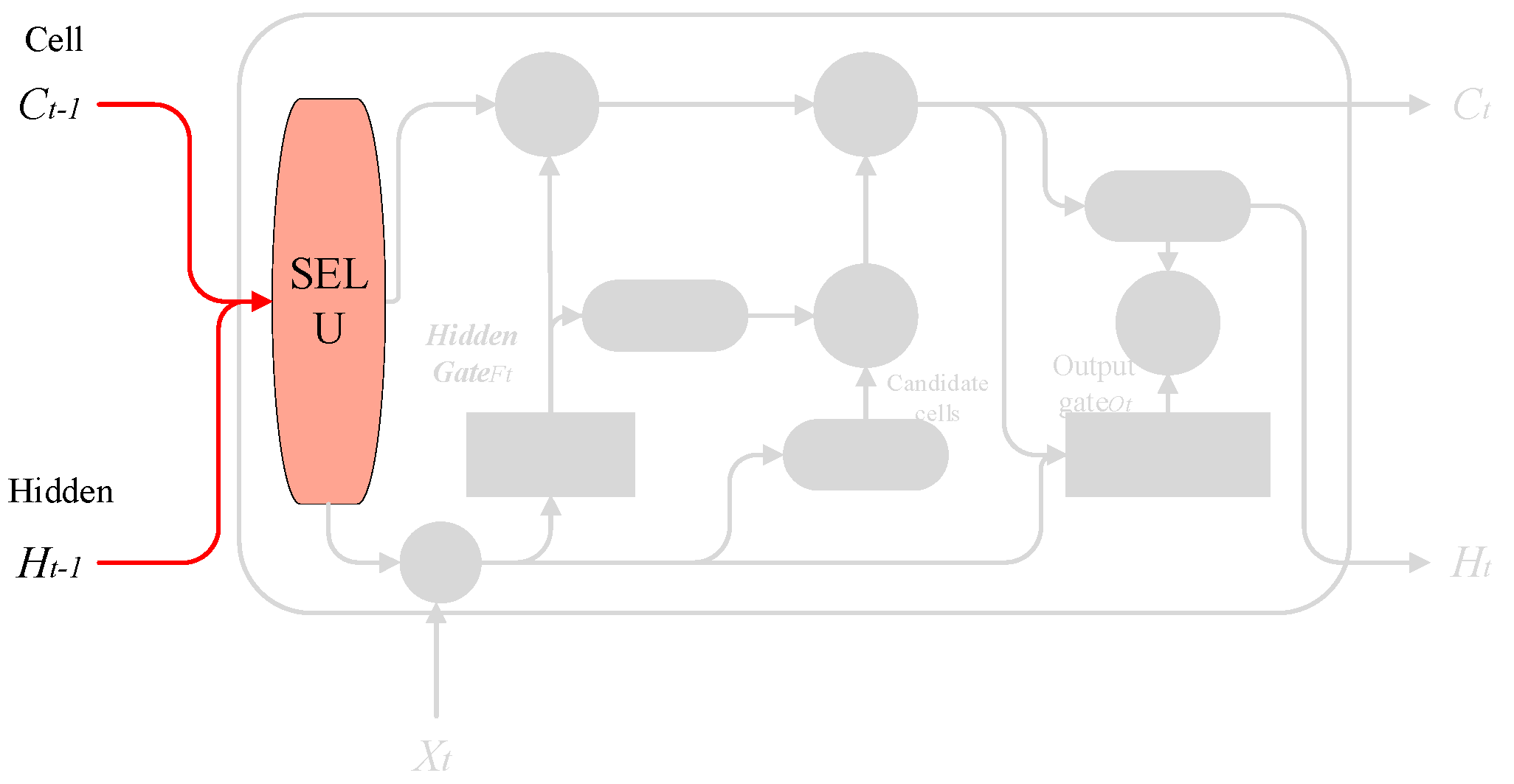
3.1.1. Input Preprocessing
The SELU function has the function that the excitation value of neurons automatically converges to zero mean and unit variance so as to achieve the purpose of self-normalization, and the normalization of SELU limits the range of variance, which can also ensure it in multi-level training. It maintains robustness, thereby effectively avoiding the problem of gradient disappearance and explosion during training. First, we use SELU to preprocess the input, and the process is shown in
Figure 8.
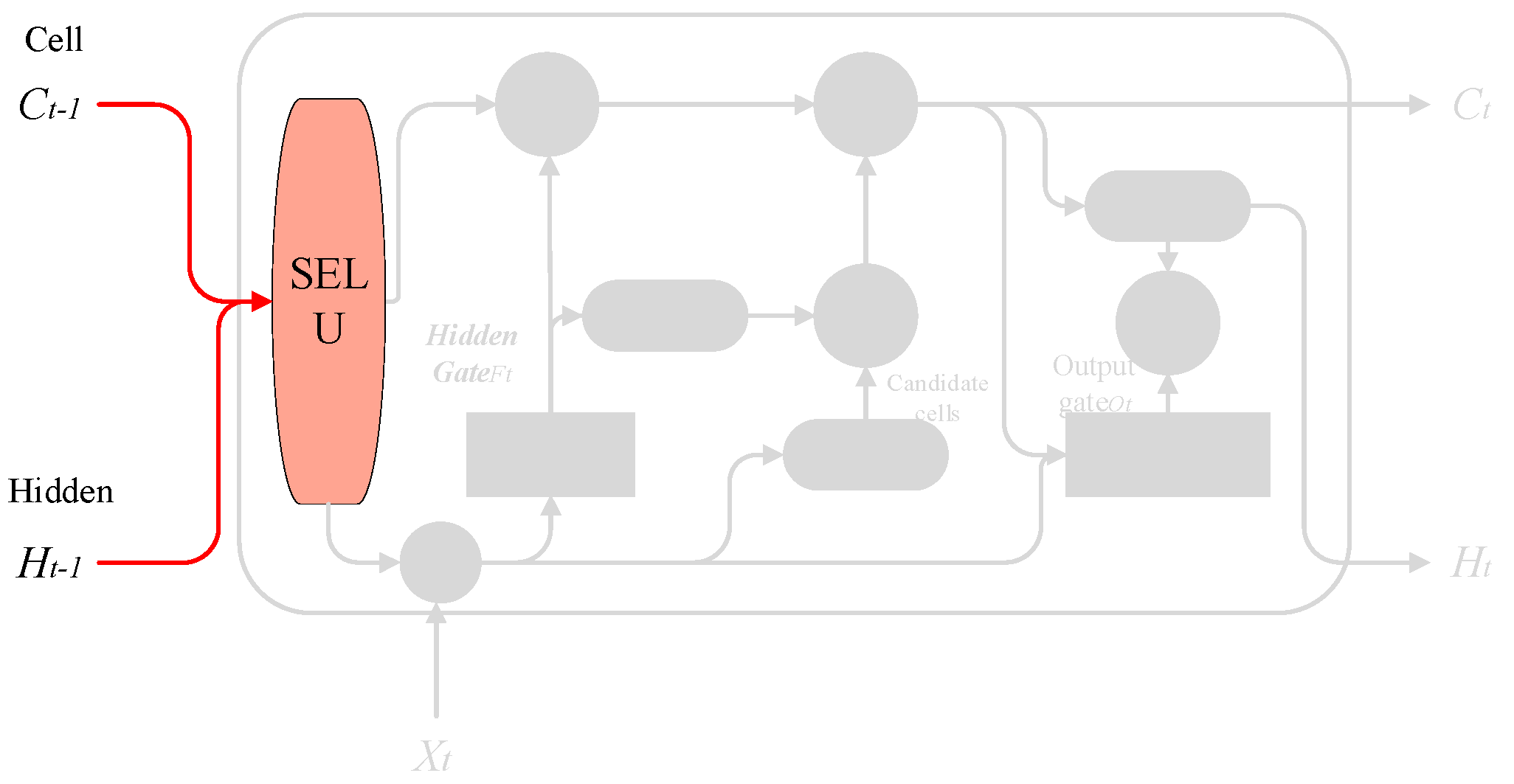
3.1.2. Hidden Gate
This step is performed to decide how much information in the cell state to keep and to selectively forget the information in the cell state in the previous step. The achieved effect is the same as the forget gate in LSTM. For example, if you want the model to obtain a new subject, it will automatically hide the old subject. For example, “She works so hard, so I…”, and when the model starts to deal with “I”, it will hide the previous subject “she”.
Implementation method: The
layer
in the previous step and
in this step are used as inputs, and then a value between 0 and 1 is output for each number in
, which is recorded as
, indicating how much information to keep (1 means completely retained, 0 means completely discarded). The process is shown in
Figure 9.
where
is the cell state at the previous time,
is the hidden state at the previous time,
is the value of the input sequence at the current time,
and
are the weights and biases, respectively, and
represents the sigmoid function.
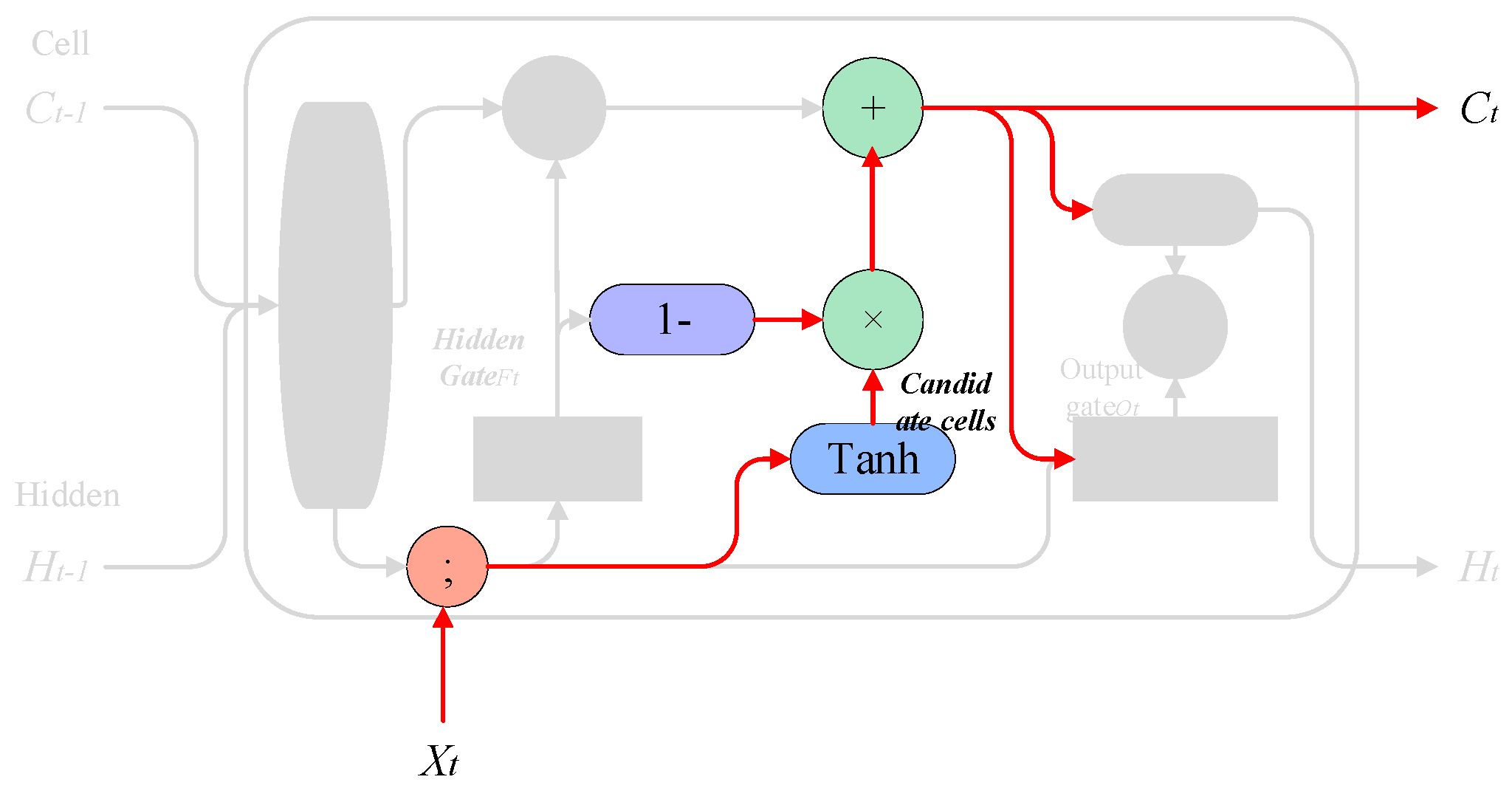
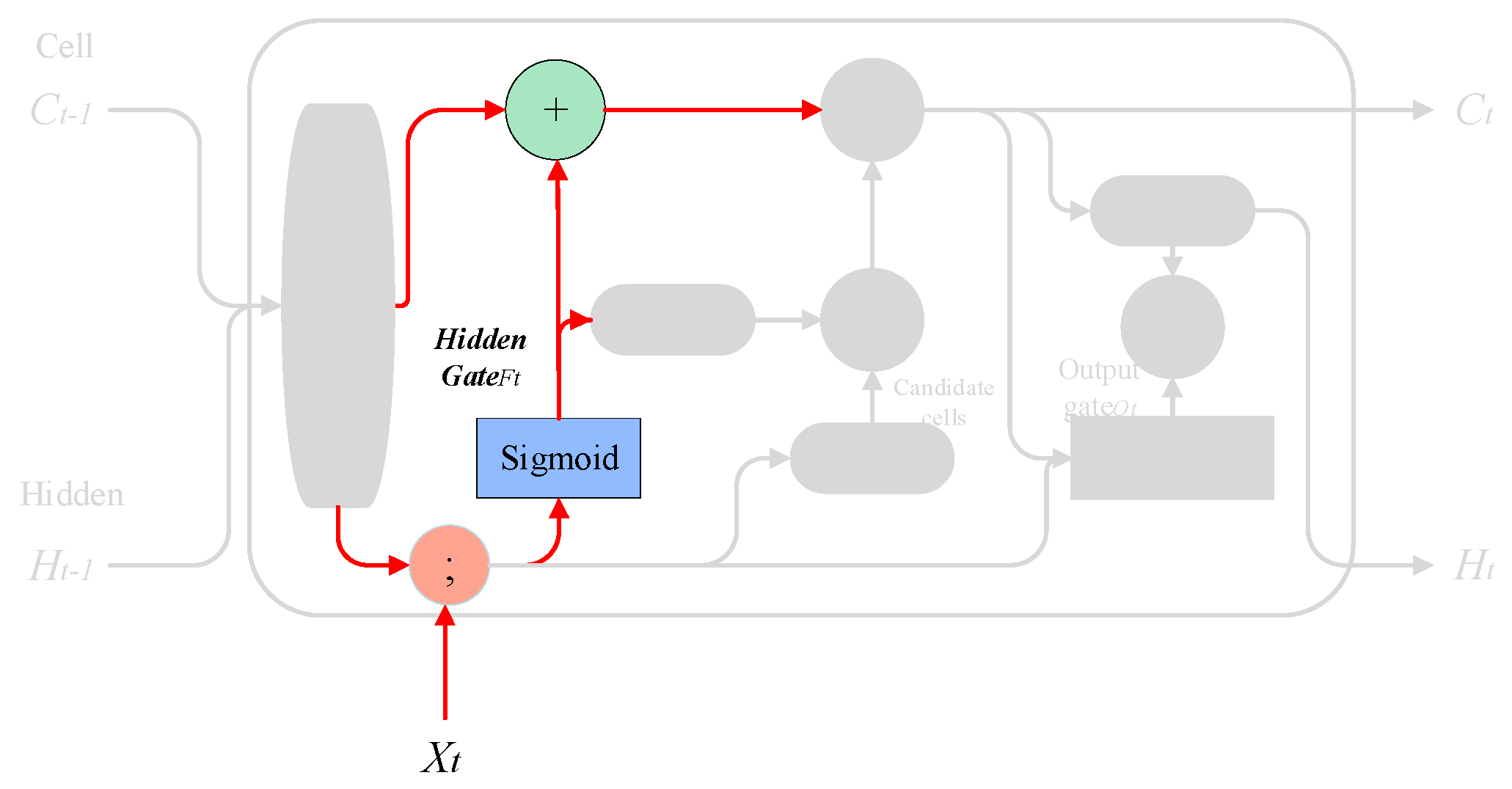
3.1.3. Memory Merge
This step decides what to store in the cell state and selectively records new information in the cell state. For example, we want to add new subject categories to the cell state to replace old subjects that need to be forgotten. For example, “She works so hard, so I…”, and when the model starts processing “I”, it will update the subject “I” into the cell.
Implementation method: The model uses the result obtained by the hidden gate to negate so as to determine the update value. The probability is expressed as
, and the
layer creates a vector of candidate values
that will be added to the cell state, which is then combined to update the cell state. The process is shown in
Figure 10.
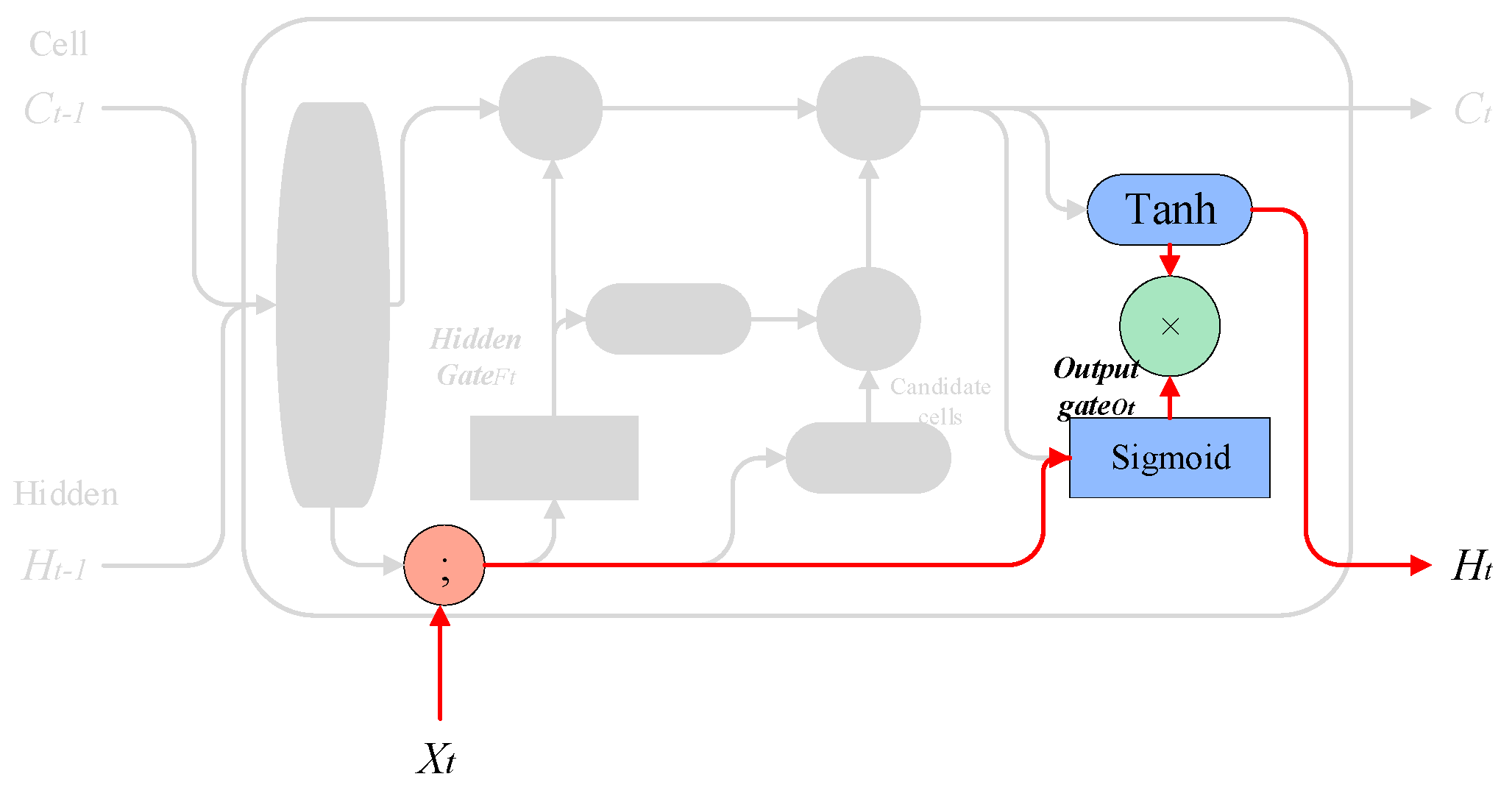
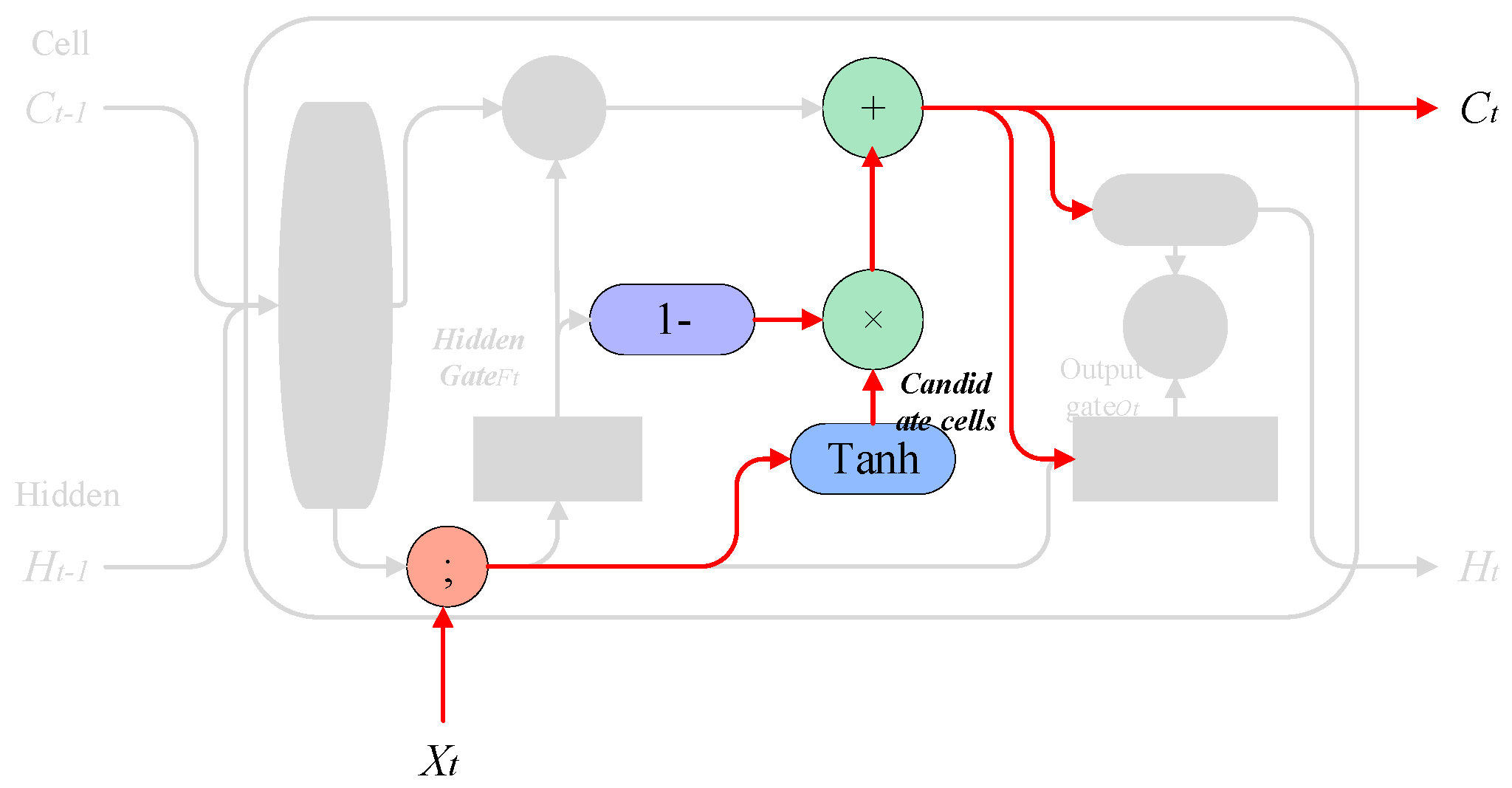
3.1.4. Output Gate
This step determines what kind of predictions to make.
Implementation method: The model utilizes a layer to determine which parts of the output cell state are significant. Subsequently, the cell state is passed through a layer to ensure the values range between −1 and 1. The final output is obtained by multiplying the output of the sigmoid layer with the output of the layer. The process can be represented mathematically as follows:
is the output gate activation vector,
and
are the weights and bias for the output gate,
and
are the previous cell state and hidden state, respectively,
is the current input,
is the final output at the time step, and
is the current cell state. The process is shown in
Figure 11.
3.1.5. The Final Memory of the Current Time Step
In order to ensure the consistency of input and output, therefore, the final output memory also needs to be processed as follows:
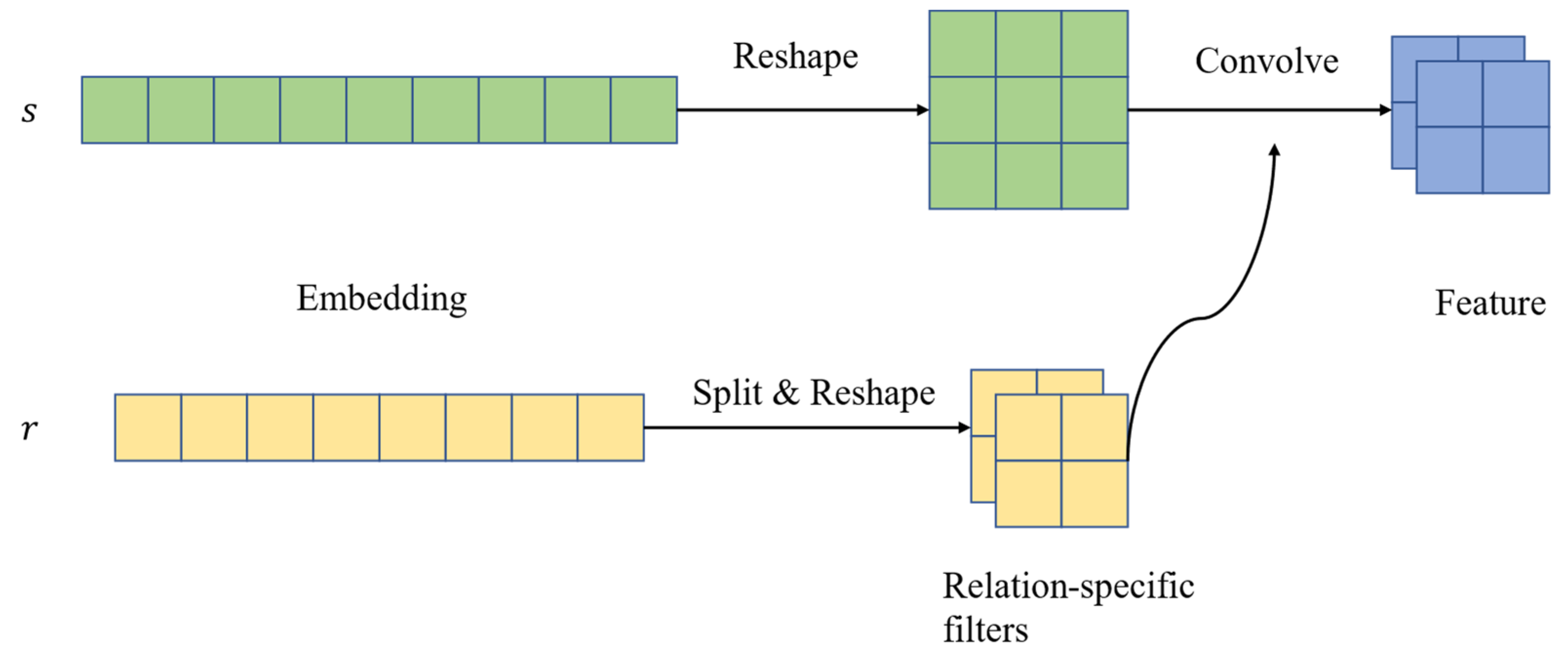
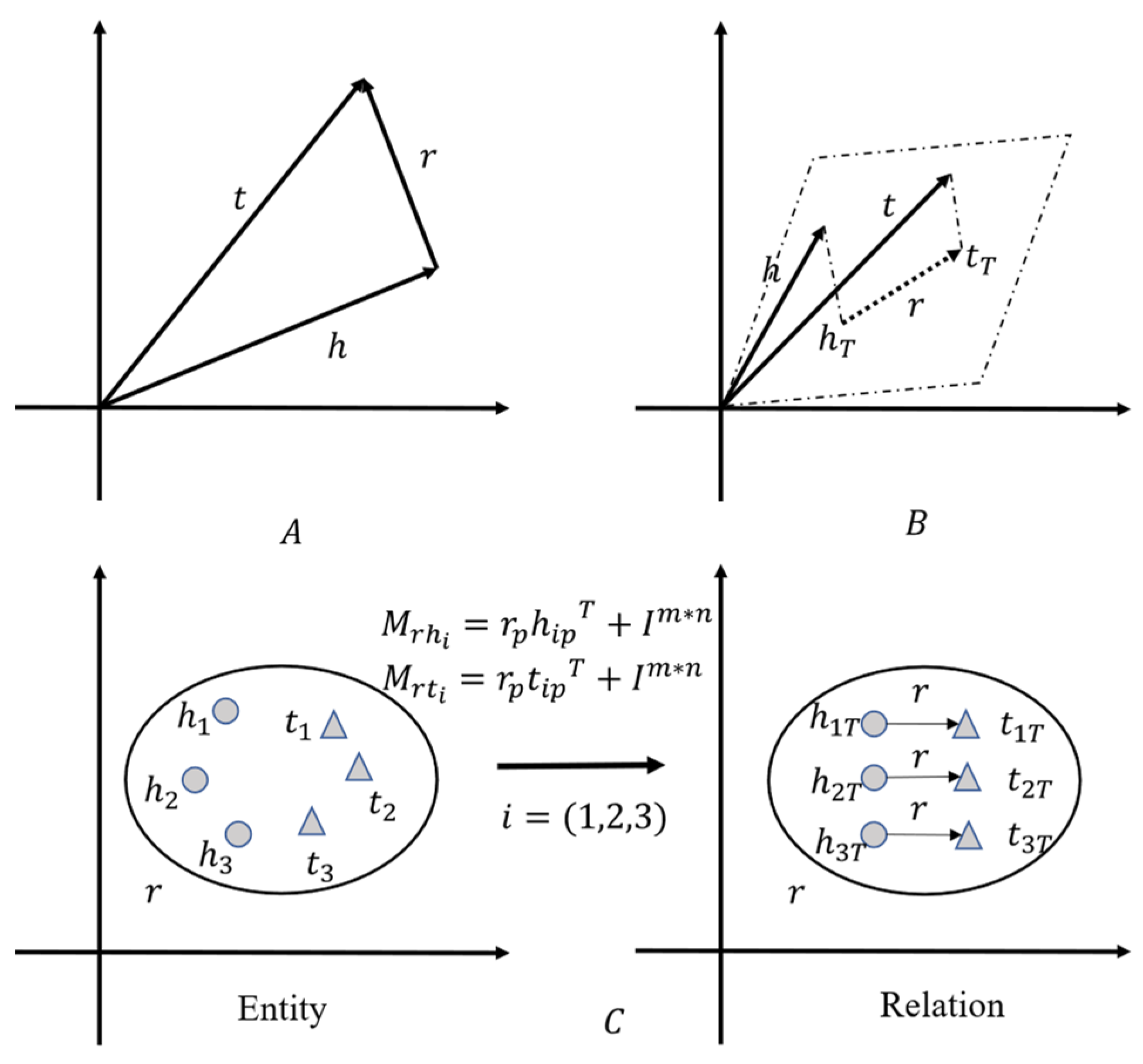
3.2. ConvR Embedding Model
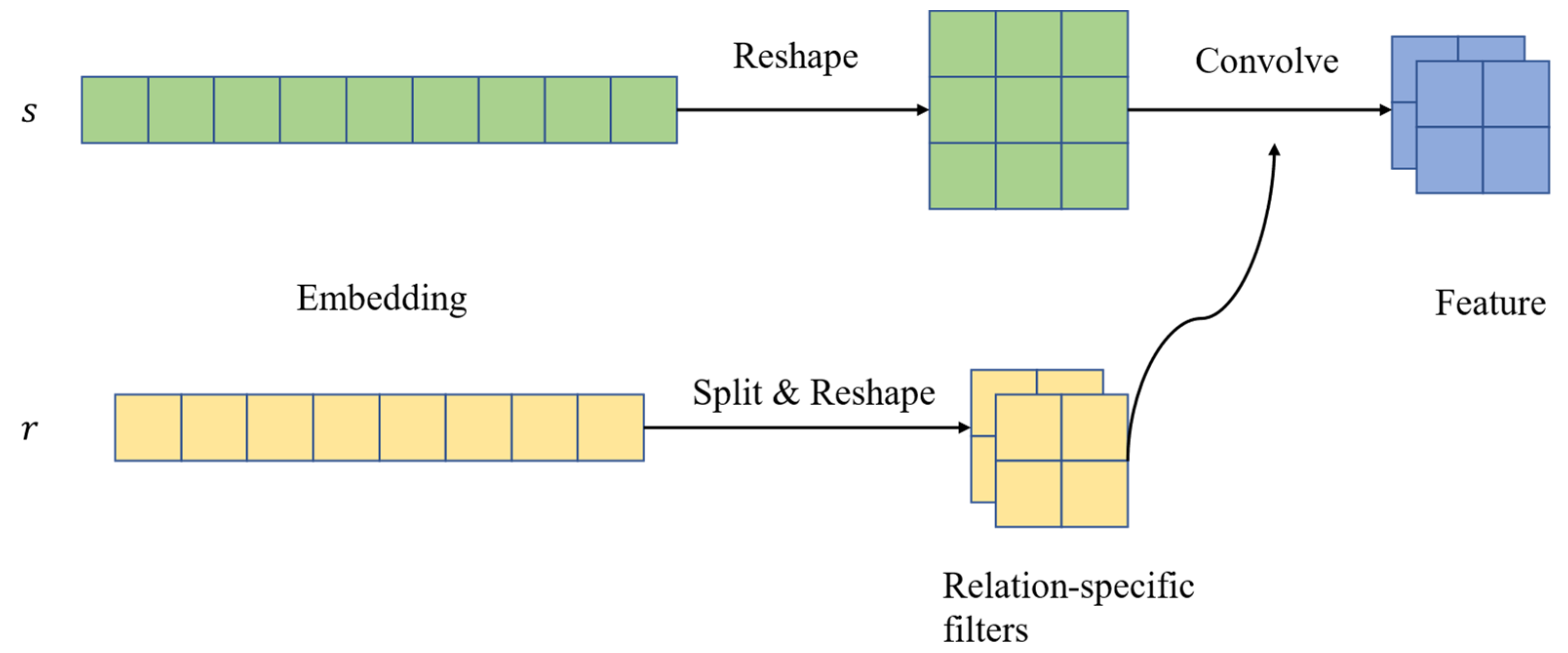
The ConvE model is insufficient to comprehensively capture the interactions between input entities and relations, as it models interactions in the region of matrix adjacency of input entities and relations. In order to maximize the interaction between entities and relations, Jiang [
37] et al. proposed the ConvR model, which continues the framework of ConvE. The difference is that the relation is used as the convolution kernel. The essence lies in adaptively building the relation embedding into a convolution kernel and interacting with the entity embedding so that each convolution is 100% interactive. The overall model is shown in
Figure 12.
Firstly, after being given a triplet, the relational representation should be split and reshaped into a set of filters. Next, the relational representation of the head entity should be reshaped and used as the input for the convolutional layer. Then, the filter should be applied to the input to capture interactions between filters (part of the relational representation) and different regions of the input (entity representation). Finally, the convolutional features are projected and matched to the representation of the tail entity. In comparison to ConvE, which utilizes a global filter, ConvR employs an adaptive filter that is constructed from a relational representation and uses the relation as a convolution kernel.
In order to use the relation as the convolution kernel, the relation embedding is first divided into several small blocks of the same size. This process is called “Split”. At the same time, because 2D convolution is used, each small block , is reshaped into a height , width , and convolution kernel , .
During convolution, the relational specialized convolution kernel
is used for operations, and the mathematical expression of the convolution process is as follows:
where
represents the response of the l-th filter at position
on the convolved feature map. The function
is an activation function, such as ReLU, etc.
is a part of the input entity embedding, and
is the value at position
in the l-th filter. The entire summation process is the convolution operation, which calculates the dot product of the filter with the entity embedding at each position.
For instance, when training on the FB15K-237 dataset, the data that participate in the convolution primarily include entity embeddings and relation embeddings. Entity embeddings are representations of entities obtained through pre-training of the model, while relation embeddings are a series of convolutional filters obtained through splitting and reshaping the relational representations. These embeddings are updated along with the model parameters during the training process to ultimately capture the complex interactions between entities.
3.3. Reasoning Framework Algorithm
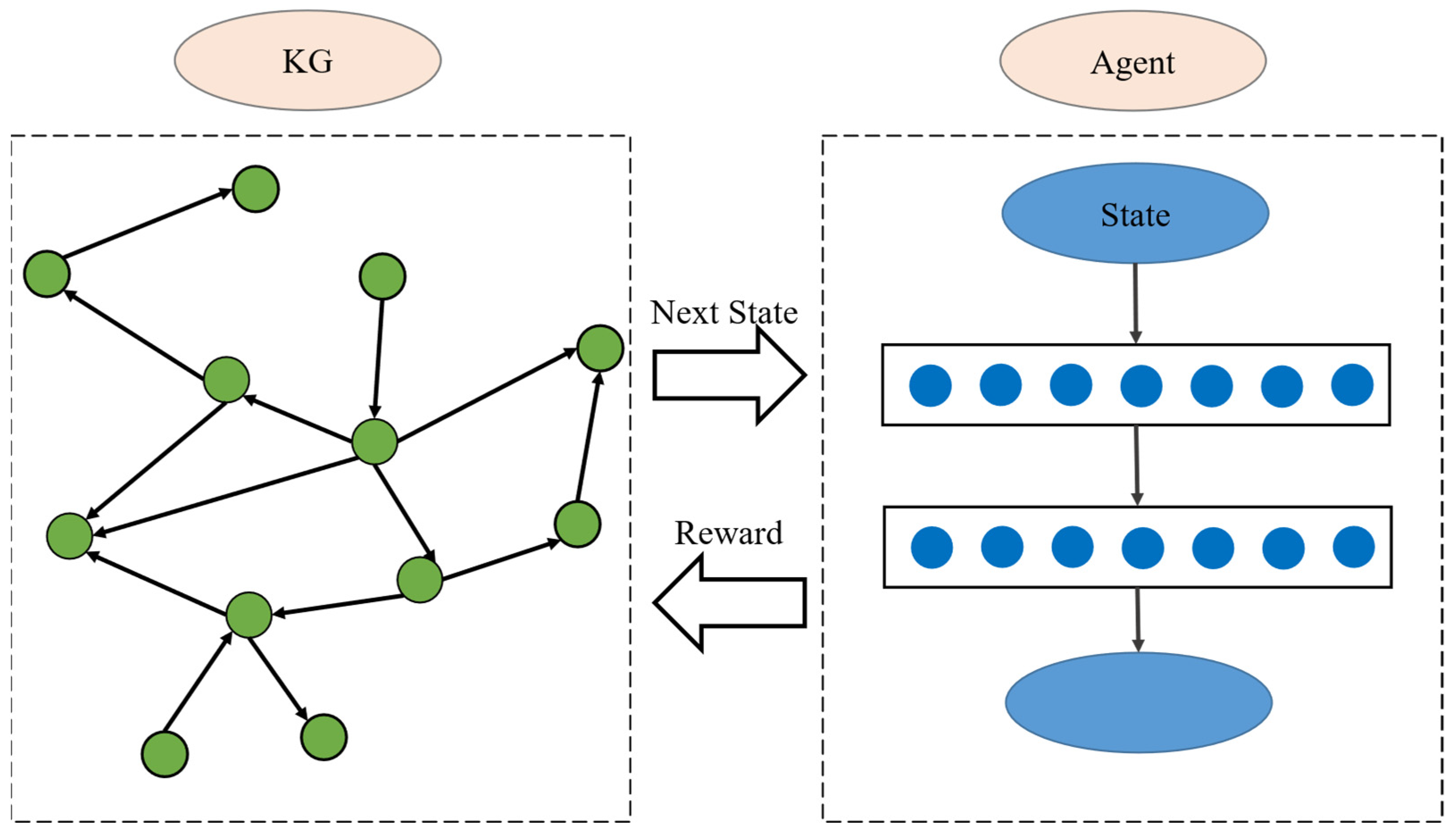
ConvRL-KGM is a method of transforming simple reasoning tasks into Markov decision problems, where the state transitions and action selection of the agent are all performed within a knowledge graph environment. This section mainly focuses on how to convert knowledge graphs into decision problems for intelligent agents.
3.3.1. State
The relationship selection strategy is not only dependent on the current entity information but also on the queried relationship. At time step
t, the state
is composed of the source entity
, the queried relationship
, and the current entity
. Its representation is as follows:
Given a pair of entity relationships , the initial state is represented as , and the agent starts its traversal from the source entity .
3.3.2. Action Space
Let
denote all the relationships in the knowledge graph
that are associated with the current entity
at state
.
where
represents the tail entity. To select the action
from
based on the policy
, a fixed time step limit is imposed for the search process to facilitate a comprehensive search.
3.3.3. State Transition
State transition refers to the process by which an agent moves from the current state to the next state based on the action taken. Specifically, the agent, in the current state, selects an action, and the transition to the next state is determined by the interaction with the environment, represented by the knowledge graph
. The state transition probability
is denoted as follows:
3.3.4. Construction of Reward Function Based on Knowledge Embeddings
In the previous reinforcement learning strategy, the agent only received binary rewards based on the observed answers in
.
However,
is inherently incomplete, and this approach assigns the same reward to negative outcomes as positive outcomes. To address this, we adopt the ConvR embedding approach and set soft rewards for result entities whose correctness are unknown. Formally, the embedding model maps entities
and relations
into a vector space and uses the ConvR composite function to estimate the likelihood of each fact. Therefore, we shape the policy with the following reward function:
The environment returns intermediate rewards for subsequent reward estimation. If the agent reaches the target entity, a reward of 1 is returned at the current time step; otherwise, a penalty less than 1 is returned. To evaluate the reliability of the predicted triplet , we utilize the pre-trained embedding model ConvR to score it.
3.3.5. Policy
Due to the fact that invalid paths are often more numerous than correct paths and are easier to detect, the burden of path search is increased, especially when the KG grows with the increase in path length, resulting in an exponential increase in action space and thus increasing the search burden. This phenomenon is even more severe for entities with large outdegrees (i.e., entities with many connecting relations). Enumerating all possible relation paths between entity pairs on a large-scale knowledge graph is infeasible, so conducting effective path exploration and identifying reasoning paths is particularly important.
Therefore, we leverage the advantage of ConvR embedding to obtain, in the action space, all tail entities that are connected to the corresponding head entity and relation. Specifically, for the current entity and selected relation, we compute the probability of all entities becoming the tail entity and then select the top K entities as our action space, where K is predetermined for each dataset. A large K value may lead to information confusion, while a small K value may lead to insufficient information. Therefore, we can refine the action space to enable the goal to reach the target entity.
- 2.
Policy network
Each entity and relation in the knowledge graph (KG) are represented by a low-dimensional dense vector with semantic information through ConvR embeddings. In order to construct a search sequence more effectively, the agent needs to not only understand the current information but also the past events that have occurred. Therefore, we utilize the SLSTM algorithm proposed in this paper to encode the historical information of the search history
into a hidden state denoted as
, representing the historical information at time step t. The output of the historical information is then passed through a self-attention layer. Assuming the initial state is
, the search history
is composed of the action sequence taken from step 1 to step t.
In the self-attention layer, we first set up a linear function
, which should be twice the size of
due to the use of bidirectional SLSTM in reinforcement learning knowledge reasoning.
Then, we calculate the attention weights using the SoftMax function.
Finally, we obtain the final output
by multiplying the attention weights with the linear function
.
The reinforcement learning policy
, which maps state
to action space
, can be represented as
, where
and
is the embedding dimension.
where
represents the SoftMax function, “;” denotes the concatenation operation,
,
, and
is the entity dimension,
is the dimension of historical hidden states, and
is the number of hidden units in the fully connected layer. Then, a dropout method is added to make the process more random. The upgraded strategy is expressed as follows:
where
is sampled from a Bernoulli distribution, which randomly masks some options in its action space.
is a very small value when
.
- 3.
Optimization of the Policy Function
The model employs the REINFORCE gradient policy method to optimize the parameters θ of the policy network
following the formula
where
represents the batch reward and
denotes the expectation over different triplets in the training set. The REINFORCE gradient policy method utilizes a series of historical trajectories (iterating over all triplets in
) generated by the current policy to estimate the stochastic gradient, which is then used to update the parameters as follows:
The training process of the model is shown in Algorithm 1
| Algorithm 1: Policy Network |
| Initialize, |
|
| using SLSTM+self-attention |
| for to Epoch num do |
| for to Time step do |
| Initialize |
|
|
|
| end for |
| Optimize parameters |
| end for |
6. Conclusions and Future Work
In this paper, we propose a knowledge graph inference model based on embedding-based reinforcement learning, ConvRL-KGM. This method adopts a new path traversal and reward strategy based on embedded reinforcement learning, which integrates ConvR’s action pruning mechanism, SLSTM neural network, and self-attention mechanism into the relationship selection and path traversal process of reinforcement learning agents.
The improved SLSTM model based on LSTM effectively solves the problem of constant pauses at the same node in the process of knowledge reasoning and can more accurately capture the complex dependence between entities and relations, which is very suitable for complex relations and deep understanding tasks. Thanks to the self-attention mechanism, the LSTM can be endowed with better sequence processing capabilities, so that the model can better capture long-distance dependencies, thus achieving more accurate reasoning. According to the existing technology, traditional LSTM tends to have the problem of gradient disappearance and explosion when dealing with long sequences, resulting in limited feature learning. The SLSTM proposed in this study effectively solves this problem, which can better learn effective feature representations, and is more suitable for dynamically changing knowledge graphs, such as real-time monitoring systems and social media analysis. In addition, the SLSTM model can better deal with structured knowledge data and unstructured text data and is suitable for the scenario of integrating multiple data types. In addition, ConvRL-KGM, compared with the previous reinforcement learning methods, is more conducive to the agent to effectively mine high-quality paths in the inference process so as to complete the knowledge graph inference task. ConvR embedment is introduced as a reward function so that the complex relationship between entities can be fully learned in the inference process, which is of great importance in improving the accuracy and efficiency of inference. Traditional multi-hop reasoning is not effective in the face of complex reasoning because the interaction between entities cannot be fully utilized. The ConvR embedding introduced in this study effectively solves the limitations of traditional multi-hop reasoning.
Meanwhile, this method also has certain limitations. For example, it relies heavily on data quality, as errors or incomplete data will affect the accuracy of reasoning, and the generalization ability is limited, so it needs to be adjusted for specific tasks. In future studies, it is necessary to explore the impact of different reinforcement learning methods on reasoning, and the generalization ability of the model needs to be further improved to make it adapt to more fields and tasks. It is considered to combine the improvements in this study with other cutting-edge technologies, such as Variational Autoencoders (VAEs), to explore new application scenarios and functions. At the same time, meta-learning can be introduced to solve the inference problem of small sample data, which may bring better inference performance.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}