

YOLO-SAD: An Efficient SAR Aircraft Detection Network



Abstract
1. Introduction
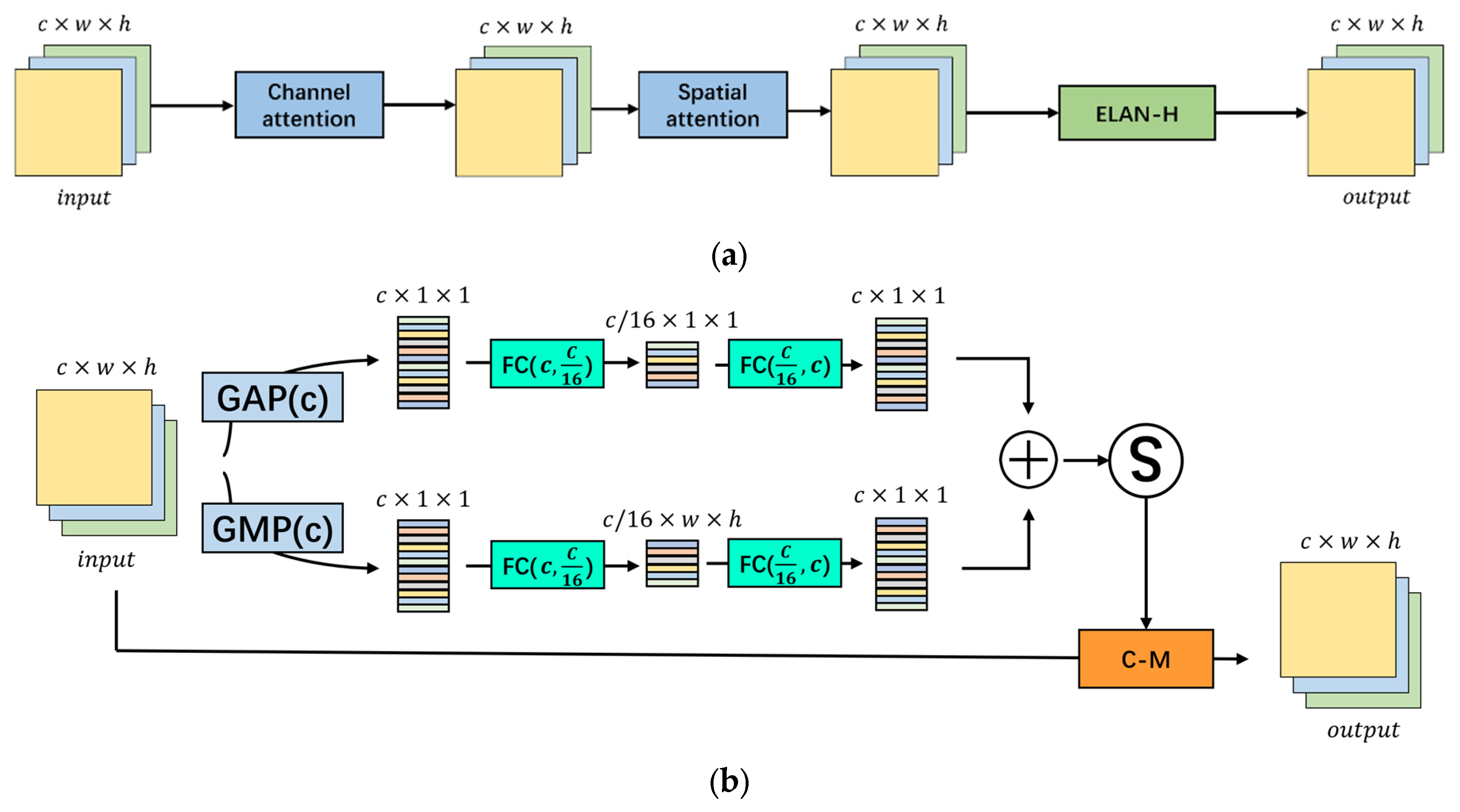
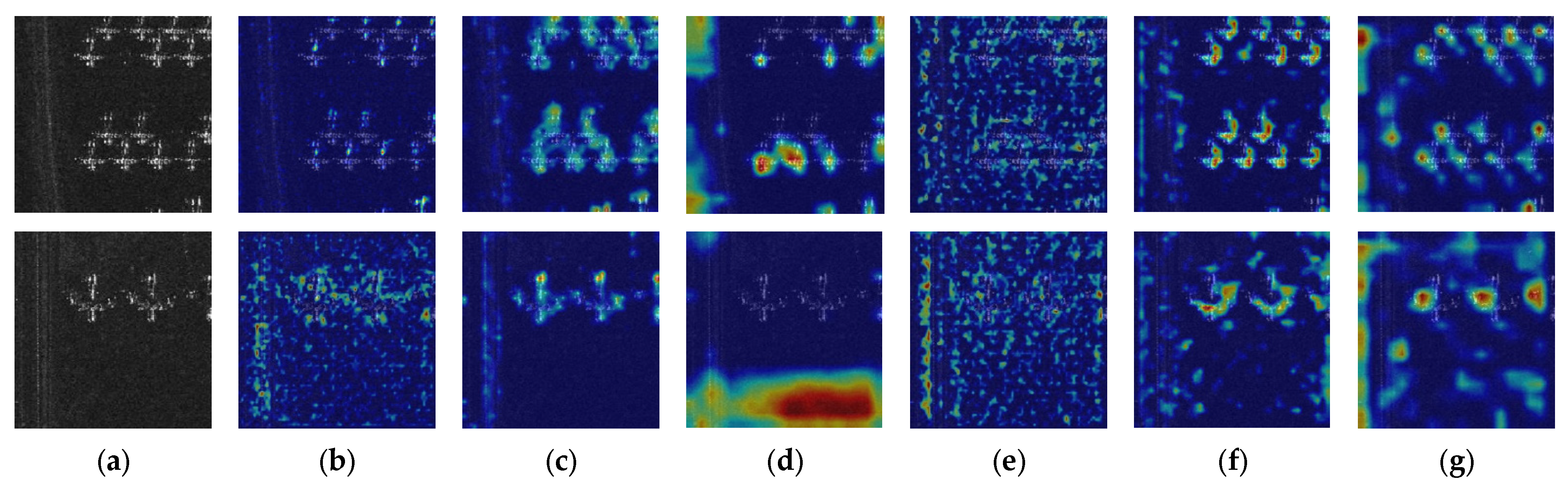
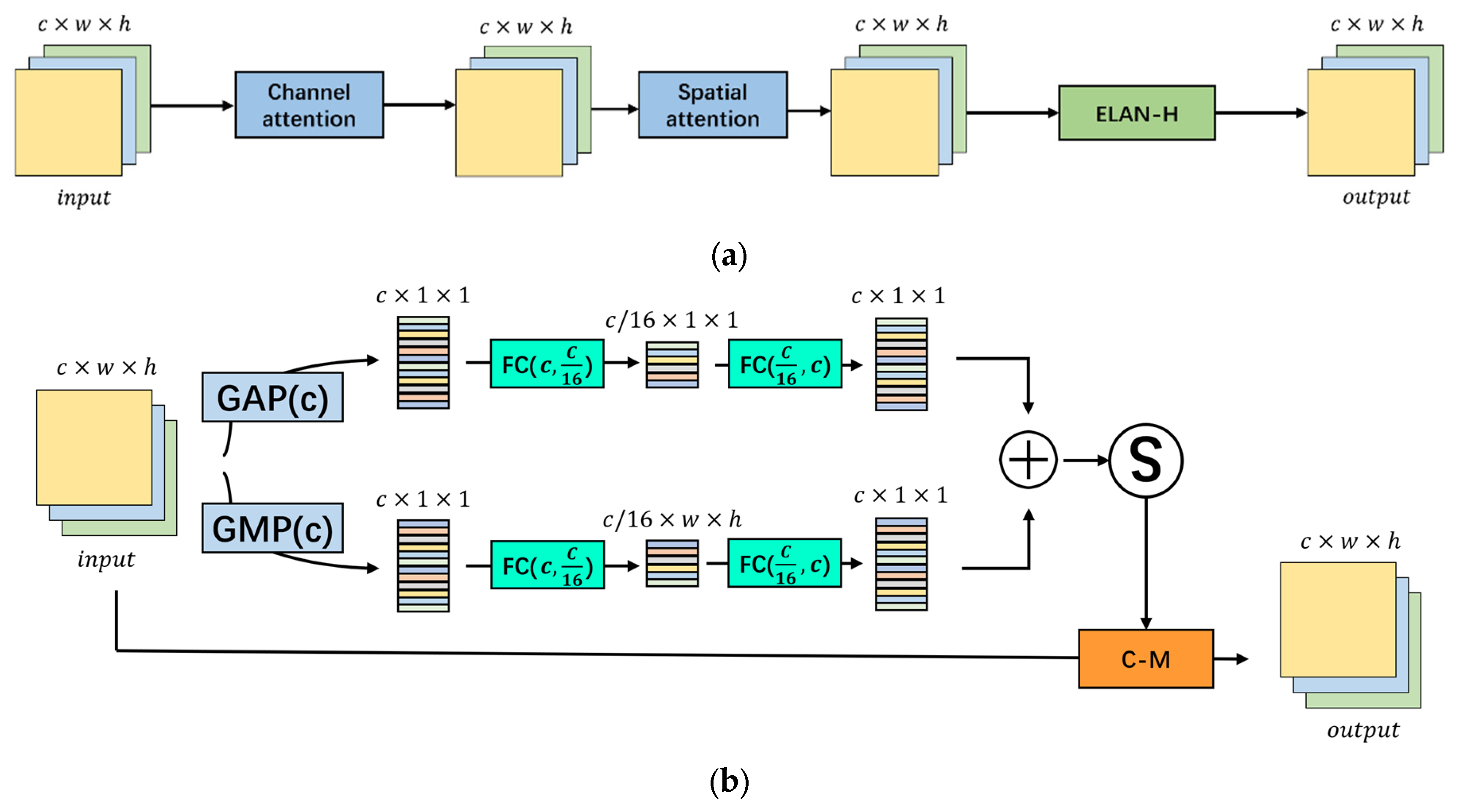
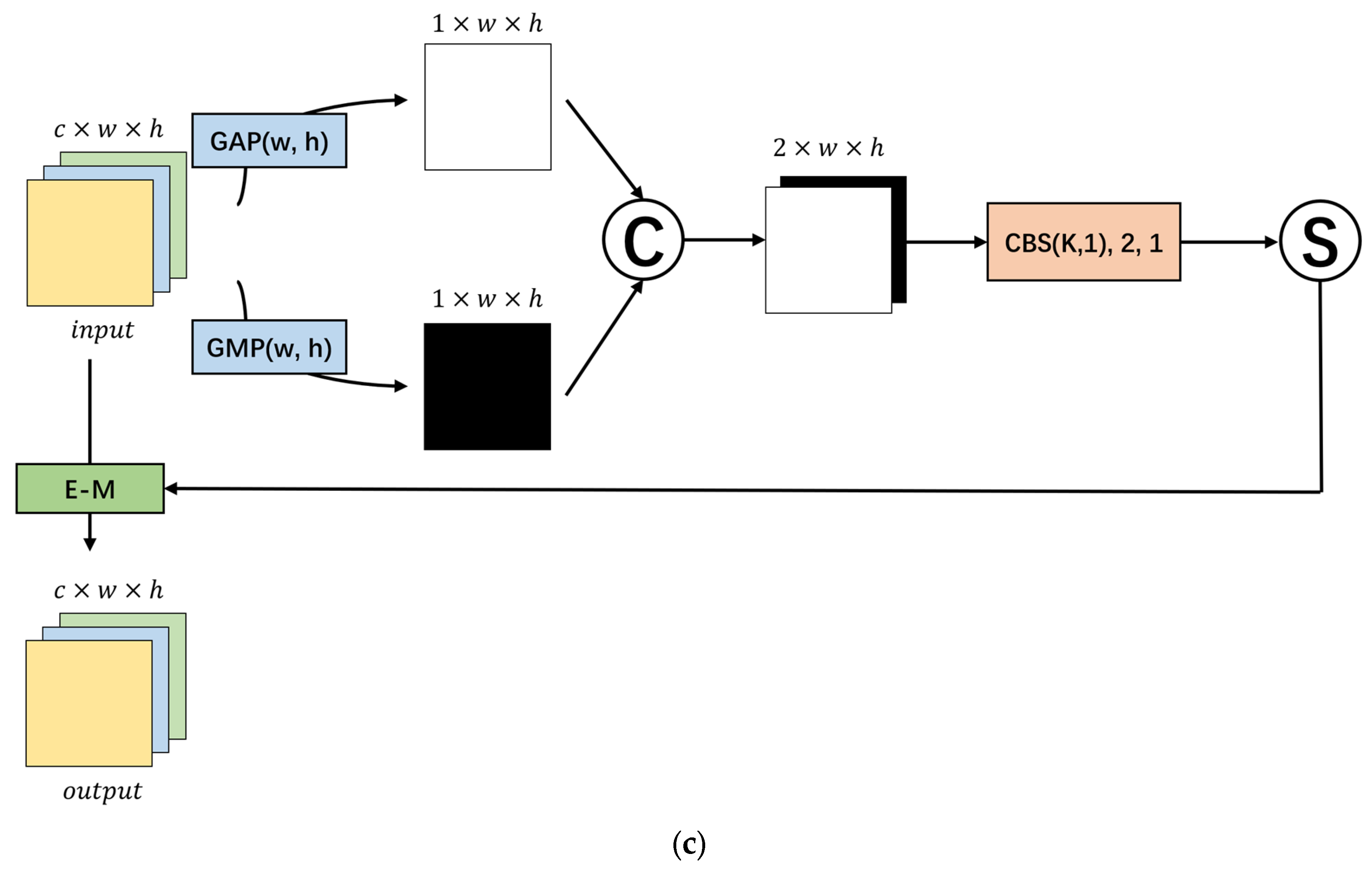
- We present YOLO-SAD, a cutting-edge network for SAR aircraft detection, which includes the SAR Aircraft Detection-Feature Pyramid Network (SAD-FPN). This feature fusion network is customized for SAR imagery, adept at harnessing the rich texture information while filtering out less valuable data. Additionally, the Attention-Efficient Layer Aggregation Network-Head (A-ELAN-H) module integrates channel and spatial attention mechanisms to highlight critical information from SAR image feature maps.
- To tackle the issue of overlapping detection boxes in SAR aircraft detection, we introduce the Enhanced Non-Maximum Suppression (EH-NMS) post-processing technique. This method significantly refines the detection accuracy and enhances the clarity of the output visualization.
2. Related Work
2.1. Object Detection Networks
2.2. SAR Remote Sensing Object Detection Methods
- -
- Guo et al.’s Scattering Information Enhancement (SIE) method, which uses the Harris–Laplace detector and DBSCAN for preprocessing to enhance aircraft scattering and employs GMM for modeling [34].
- -
- Yang et al.’s R-RetinaNet, introducing Rotatable Bounding Boxes (RBoxes) to address feature scale mismatch in SAR detection tasks [35].
- -
- -
- Yu et al.’s modification of the YOLOX-s structure, eliminating the computationally heavy pyramidal framework for quicker detection [38].
- -
- Wang et al.’s Semantic Condition Constraint Guided Feature Aware Network (SCFNet), which integrates semantic condition constraints to boost the network’s discriminative capabilities for multi-label aircraft detection in SAR images [39].
2.3. Post-Processing Methods for Object Detection
- -
- Soft-NMS, introduced by Bodla et al., mitigates the issue by reducing confidence scores of overlapping boxes rather than eliminating them, thus improving overall detection accuracy [42].
- -
- Adaptive NMS, proposed by Liu et al., is an iterative algorithm that dynamically adjusts the suppression threshold based on the dimensions and aspect ratios of candidate regions, enhancing detection efficiency [43].
- -
- DIoU-NMS, developed by Zheng et al., employs the Distance-IoU (DIoU) metric in place of IoU, refining the suppression process and further improving accuracy [44].
- -
- Truncated NMS, presented by Shen et al., addresses the challenge of overlapping regions during result merging in remote sensing image detection [45].
3. Materials and Methods
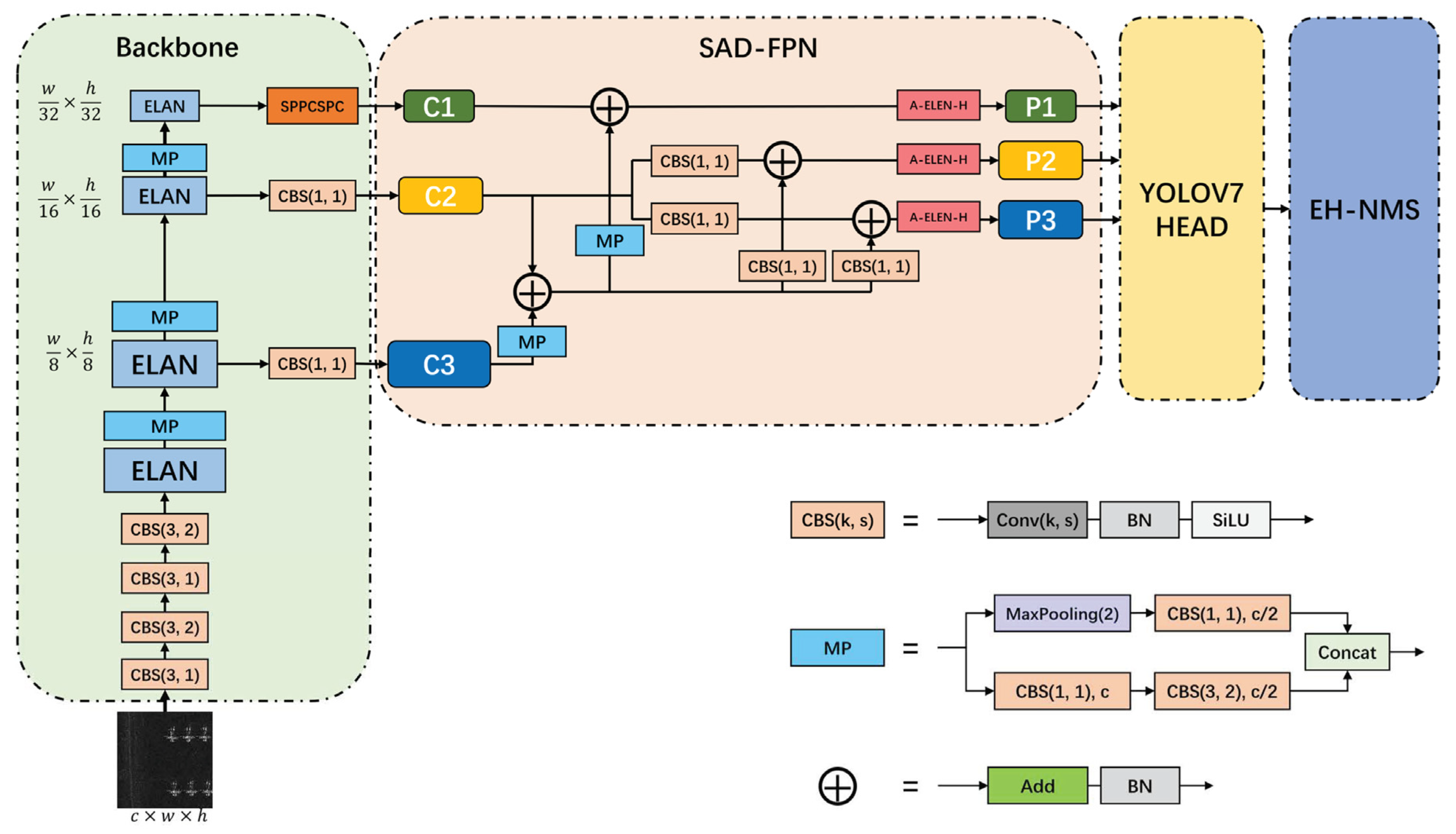
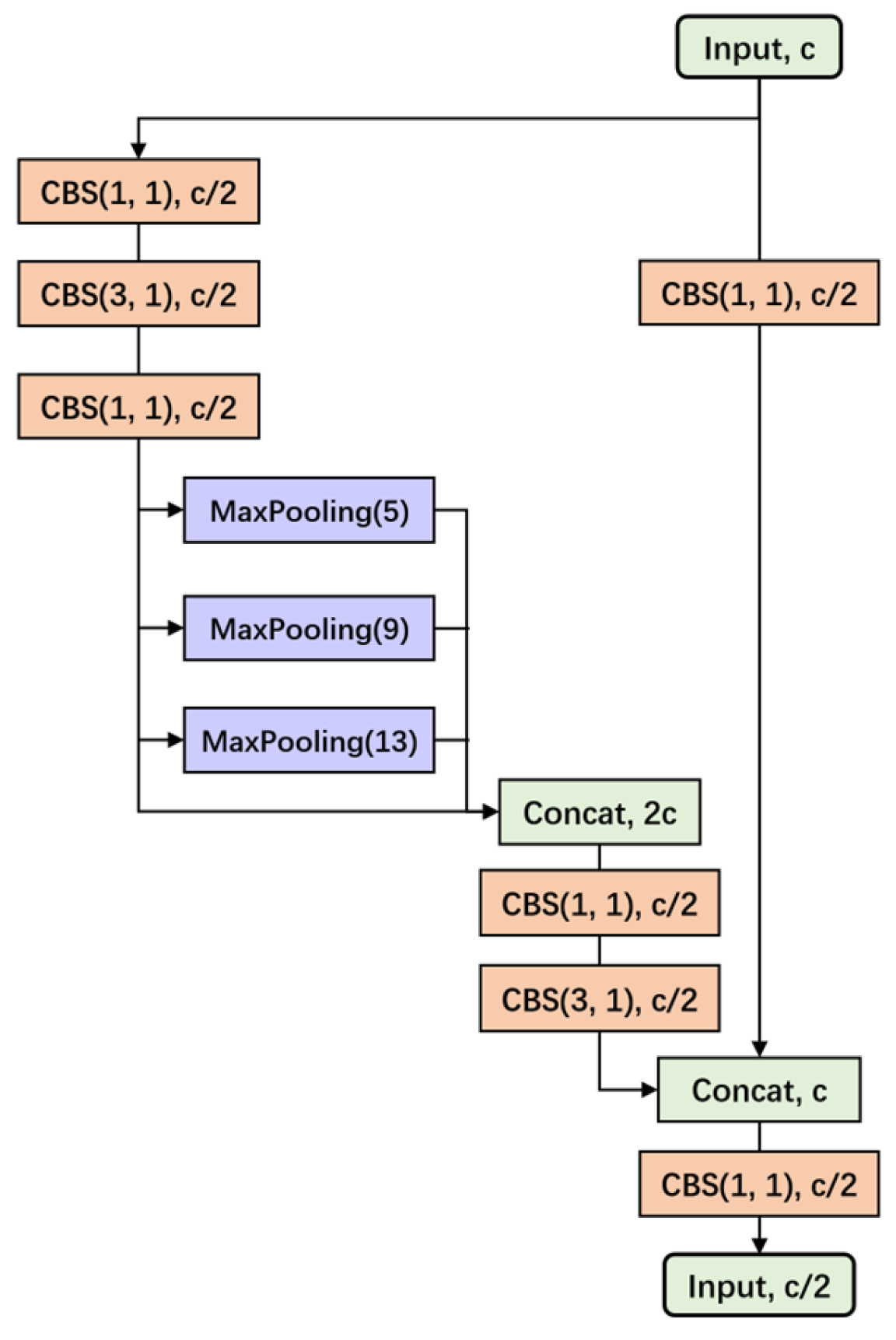
3.1. The Network Structure of YOLO-SAD
3.1.1. Backbone Network
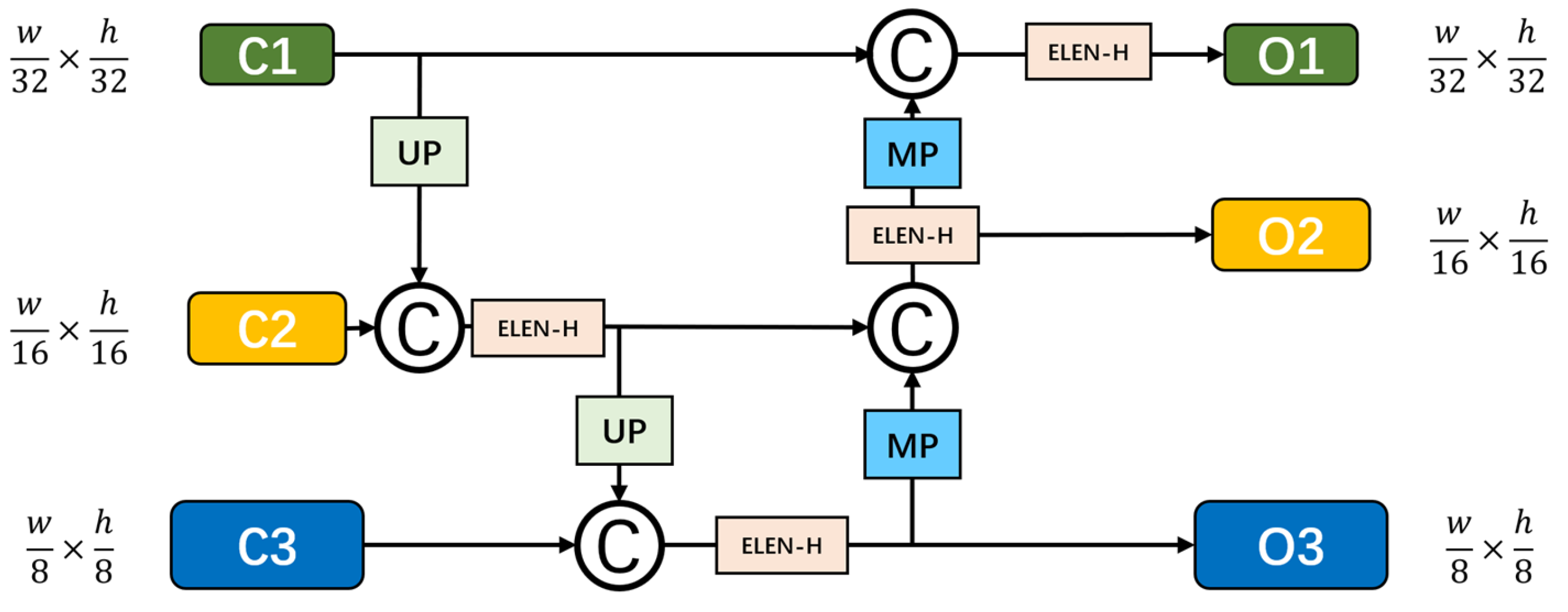
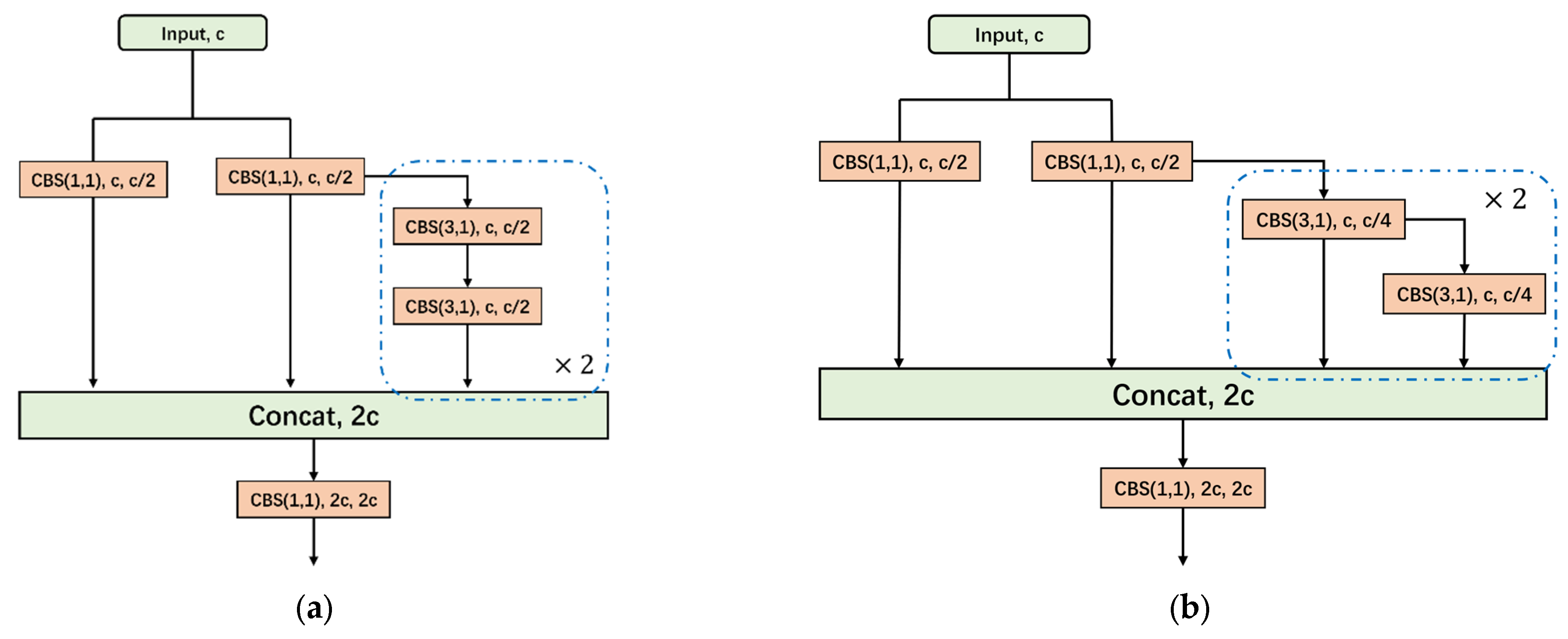
3.1.2. SAD-FPN for SAR Image Feature
3.1.3. Attention Feature Encoding Module A-ELAN-H
3.1.4. Detection Head
3.2. Loss Function
3.3. Area-Based EH-NMS Post-Processing Method
| Algorithm 1 EH-NMS | |
| Input: B = [b1,…, bn], S = [s1,…, sn], IoUt, θ | |
| B is the list of all candidate detection boxes | |
| S is the list of scores corresponding to all candidate boxes | |
| IoUt is the IoU threshold | |
| θ is the threshold of the ratio of the parallel area to the maximum possible detection frame area | |
| Output: K | |
| K indicates the detection boxes retained after the EH-NMS | |
| 1 | : for image in images |
| 2 | : K ← [ ] |
| 3 | : while B ≠ ø do: |
| 4 | : m ← argmax(S) |
| 5 | : M ← bm |
| 6 | : K ← K ∪ M |
| 7 | : B ← B—bm; S ← S—sm |
| 8 | : for bi in B do: |
| 9 | : if IoU(M, bi) < IoUt: |
| 10 | : B ← B—bi; S ← S—si |
| 11 | : else: |
| 12 | : B ← B; S ← S |
| 13 | : if ratio(union(M, bi), area(M)) > θ: |
| 14 | : B ← B; S ← S |
| 15 | : else: |
| 16 | : B ← B—bi; S ← S—si |
| 17 | : return K |
| 18 | : end |
4. Experiment and Results
4.1. Dataset and Evaluation Metrics Introduction
4.1.1. Dataset Introduction
4.1.2. Experimental Setup
4.1.3. Evaluation Metrics
4.2. Ablation Experiment
4.2.1. Ablation Experiment on Feature Fusion Methods
- Feature concatenation compared to addition results in lower FPS by 0.8, a 1.3 GB increase in model parameters, and a 0.6 MB increase in model size, due to doubling the channel number.
- Indirect fusion, already slower than concatenation, is further hindered by additional convolutional layers, leading to a 0.7 FPS decrease and a 0.4 GB parameter increase. Despite a 0.3% improvement in AP(0.5) and a 6.3% rise in precision, there is a 1% drop in AP(0.5:0.95) and a 2.6% decrease in recall.
- Feature addition-based fusion outperforms both indirect fusion and concatenation in accuracy and speed. While SiLU activation and batch normalization do not add complexity, SiLU negatively affects the addition method, lowering AP(0.5) by 1% and AP(0.5:0.95) by 0.9%. However, batch normalization improves these metrics by 0.5% and 0.3%, reaching 92.0% and 56.3%, respectively.
- Combining SiLU and batch normalization in feature addition reduces primary accuracy metrics compared to using batch normalization alone, with a 2.7% and 1% decrease in AP(0.5) and AP(0.5:0.95).
4.2.2. Ablation Experiment on the A-ELAN-H Module
- Adding the channel attention mechanism before the ELAN module significantly improved detection accuracy, with AP(0.5) and AP(0.5:0.95) increasing by 1.6% and 1%, respectively. The model’s speed also increased by 0.6 FPS, although model size grew by 3.1 MB and complexity rose by 0.4 GB. This enhancement justifies the inclusion of channel attention before the ELAN module.
- Introducing a spatial attention mechanism with a 5 × 5 kernel size also improved detection speed, with a 3.5 MB reduction in model size and a 2.6 FPS speed-up. There was a slight increase in AP(0.5) (1.3%) but a minor decrease in AP(0.5:0.95) (0.6%), indicating a trade-off between speed and bounding box precision.
- Combining both channel and spatial attention mechanisms before the ELAN module achieved the highest overall accuracy, with a 56.6% AP(0.5:0.95) and a 92.2% AP(0.5) when using kernel sizes of [5, 7, 5, 3]. Despite no change in model size and complexity, detection speed decreased by 0.6 to 1.8 FPS compared to using only channel attention.
4.2.3. Ablation Experiment on EH-NMS
- On both SADD and SSDD, AP(0.5) and AP(0.5:0.95) initially rise with increasing θ, then decline. This is due to EH-NMS effectively reducing overlaps at low θ but becoming overly restrictive at high θ, leading to the exclusion of valid bounding boxes and reduced accuracy.
- For SADD, AP(0.5) and AP(0.5:0.95) peak at 90.1% and 55.4% with θ at 1.2. On SSDD, the highest values of 93.9% and 61.6% are achieved with θ at 1.05. This indicates that the optimal θ varies with target geometry, with 1.05 to 1.2 being effective for SAR aircraft and 1.00 to 1.10 for SAR ships.
- Precision and recall show a dual fluctuation on both datasets, with initial increases followed by decreases at different stages. The first increase in precision is due to reduced false positives, while the second is from further reduction in overlaps. Recall initially rises as confident false positives are removed, but then falls as true positives are mistakenly excluded.
- EH-NMS excels in SAR aircraft detection by effectively eliminating highly overlapping bounding boxes, achieving superior results with 90.1% AP(0.5), 55.4% AP(0.5:0.95), and 93.0% precision. These figures surpass the next best techniques by 0.3%, 0.1%, and 0.2%, respectively.
- Soft-NMS and WBF show a decline in accuracy, likely due to their optimization for natural images rather than SAR remote sensing. Meanwhile, DIoU-NMS demonstrates a slight enhancement in accuracy, indicating its robustness and generalizability.
- When applying the EH-NMS post-processing method to the YOLOv7 and YOLOr-p6 models demonstrates a significant improvement in the precision metric. Comparing with YOLOv7, there is a 0.4% improvement, while compared with YOLOr-p6, the improvement reaches 0.8%. Additionally, there is a slight improvement in the AP(0.5) metric, with an increase of 0.3% compared with YOLOv7 and 0.5% compared with YOLOr-p6. Similarly, there is a slight improvement in the AP(0.5:0.95) metric, with an increase of 0.2% compared with YOLOv7 and 0.3% compared with YOLOr-p6. Notably, the EH-NMS post-processing method does not result in a decrease in the recall metric.
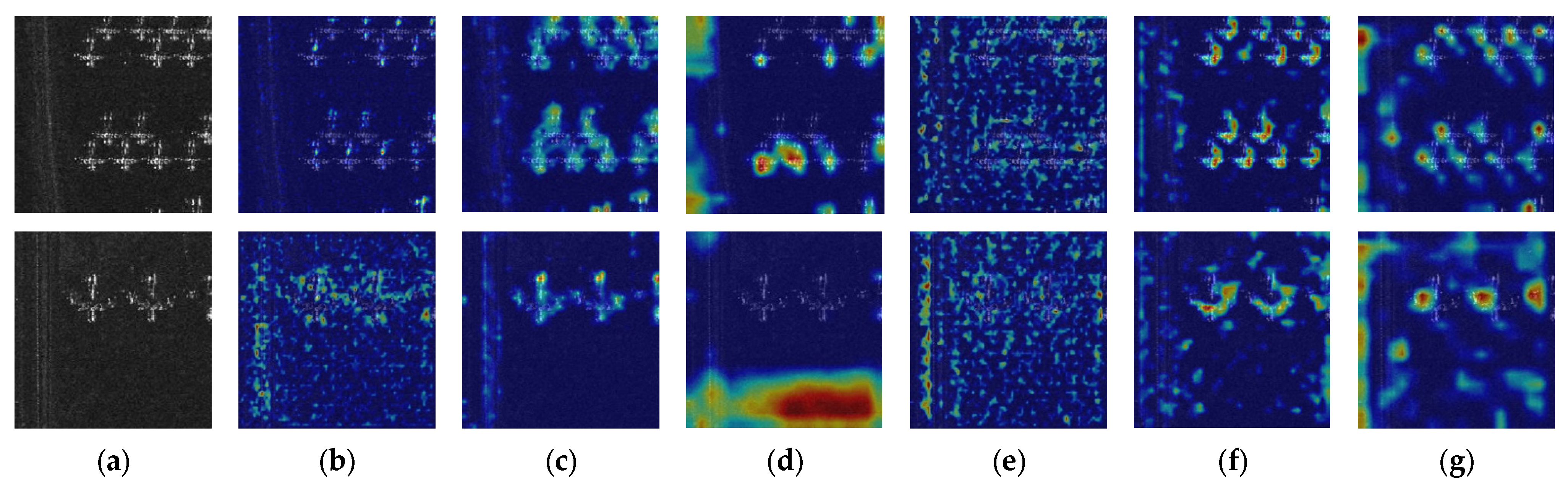
- Through the visualized results in Figure 9, it is evident that the EH-NMS post-processing method accurately eliminates incorrectly overlapped bounding boxes, consequently resulting in improved visual outcomes. This experiment confirms the effectiveness of the proposed EH-NMS post-processing method.
4.2.4. Ablation Experiment on the Overall Network Structure
- The integration of the lightweight SAD-FPN architecture into the network resulted in a 3.4 FPS increase and improvements in AP(0.5) and AP(0.5:0.95) of 2.2% and 1.1%, respectively, over the baseline. Despite a 1.2 FPS decrease upon adding the A-ELAN-H module, detection accuracy saw a significant boost, with AP(0.5) and AP(0.5:0.95) improving by 1.6% and 1.4%, respectively.
- Combining SAD-FPN with the A-ELAN-H module led to a 0.7% increase in AP(0.5:0.95) and a 2% rise in AP(0.5) over using SAD-FPN alone. Compared to the baseline, this configuration achieved a 91.8% AP(0.5) and a 57.0% AP(0.5:0.95). The SAD-FPN structure’s efficiency and A-ELAN-H’s accuracy complement each other, reducing the additional complexity introduced by A-ELAN-H. This combination decreased the model size by 1.7 MB and complexity by 8.3 GB compared to using A-ELAN-H alone, and improved detection speed by 4.6 FPS.
- The EH-NMS post-processing method slightly improves AP(0.5) and AP(0.5:0.95) without affecting model size, complexity, or speed. When applied to the SAD-FPN and A-ELAN-H combination, it further increased AP(0.5:0.95) to 57.1% and AP(0.5) to 91.9%.
4.3. Comparative Experiment
- Our YOLO-SAD network outperforms the baseline on SADD, with a 2.1% increase in AP(0.5) to 91.9% and a 1.9% increase in AP(0.5:0.95) to 57.1%. Detection speed also slightly improved from 41.6 to 43.7 FPS. The SAD-FPN structure efficiently reduces high-level feature redundancy in PAN, and the attention mechanisms do not significantly increase model complexity. YOLO-SAD thus balances accuracy and speed effectively.
- YOLO-SAD exceeds other SOTA methods on SADD. ResNeXt50-CSP, the next best, achieves 91.5% AP(0.5) and 55.9% AP(0.5:0.95), which are lower than YOLO-SAD’s 91.9% and 57.1%. This indicates YOLO-SAD’s high accuracy in SAR aircraft detection.
- YOLO-SAD’s detection speed is 43.7 FPS on SADD, a 2 FPS improvement over the baseline and 2.8 FPS over YOLO-V4. Although it does not match the highest speed networks like ResNet50-CSP, YOLOr-p6, and ResNeXt50-CSP, its accuracy is notably superior. YOLO-SAD’s 0.5% improvement in AP(0.5) and 1.2% in AP(0.5:0.95) over the top-performing ResNeXt50-SCP justifies the slight speed difference.
5. Discussion
6. Conclusions
- Developing larger-scale SAR aircraft detection datasets for fine-grained classification, enabling the exploration of network architectures tailored to SAR features.
- Investigating neural network design strategies for small-scale datasets, exploring data augmentation, meta-learning, self-supervised learning, and other techniques suited for SAR object detection.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tsokas, A.; Rysz, M.; Pardalos, P.M.; Dipple, K. Sar data applications in earth observation: An overview. Expert Syst. Appl. 2022, 205, 117342. [Google Scholar] [CrossRef]
- Kang, Y.; Wang, Z.; Fu, J.; Sun, X.; Fu, K. SFR-Net: Scattering feature relation network for aircraft detection in complex SAR images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5218317. [Google Scholar] [CrossRef]
- Zhang, P.; Xu, H.; Tian, T.; Gao, P.; Li, L.; Zhao, T.; Zhang, N.; Tian, J. SEFEPNet: Scale expansion and feature enhancement pyramid network for SAR aircraft detection with small sample dataset. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3365–3375. [Google Scholar] [CrossRef]
- Han, P.; Liao, D.; Han, B.; Cheng, Z. SEAN: A Simple and Efficient Attention Network for Aircraft Detection in SAR Images. Remote Sens. 2022, 14, 4669. [Google Scholar] [CrossRef]
- Zhang, X.; Hu, D.; Li, S.; Luo, Y.; Li, J.; Zhang, C. Aircraft detection from low SCNR SAR imagery using coherent scattering enhancement and fused attention pyramid. Remote Sens. 2023, 15, 4480. [Google Scholar] [CrossRef]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-t.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2014, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision 2015, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-Cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; Volume 28, pp. 91–99. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Gao, G. A parzen-window-kernel-based CFAR algorithm for ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2010, 8, 557–561. [Google Scholar] [CrossRef]
- An, W.; Xie, C.; Yuan, X. An improved iterative censoring scheme for CFAR ship detection with SAR imagery. IEEE Trans. Geosci. Remote Sens. 2013, 52, 4585–4595. [Google Scholar]
- Hou, B.; Chen, X.; Jiao, L. Multilayer CFAR detection of ship targets in very high resolution SAR images. IEEE Geosci. Remote Sens. Lett. 2014, 12, 811–815. [Google Scholar]
- Atteia, G.; Collins, M.J. On the use of compact polarimetry SAR for ship detection. ISPRS J. Photogramm. Remote Sens. 2013, 80, 1–9. [Google Scholar] [CrossRef]
- Gao, G.; Gao, S.; He, J.; Li, G. Ship detection using compact polarimetric SAR based on the notch filter. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5380–5393. [Google Scholar] [CrossRef]
- Zhang, T.; Ji, J.; Li, X.; Yu, W.; Xiong, H. Ship detection from PolSAR imagery using the complete polarimetric covariance difference matrix. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2824–2839. [Google Scholar] [CrossRef]
- Zhang, T.; Jiang, L.; Xiang, D.; Ban, Y.; Pei, L.; Xiong, H. Ship detection from PolSAR imagery using the ambiguity removal polarimetric notch filter. ISPRS J. Photogramm. Remote Sens. 2019, 157, 41–58. [Google Scholar] [CrossRef]
- Jiang, S.; Wang, C.; Zhang, B.; Zhang, H. Ship detection based on feature confidence for high resolution SAR images. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 6844–6847. [Google Scholar]
- Kuiying, Y.; Lin, J.; Changchun, Z.; Jin, J. Sar automatic target recognition based on shadow contour. In Proceedings of the 2013 Fourth International Conference on Digital Manufacturing & Automation, Qingdao, China, 29–30 June 2013; pp. 1179–1183. [Google Scholar]
- Wang, C.; Bi, F.; Chen, L.; Chen, J. A novel threshold template algorithm for ship detection in high-resolution SAR images. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 100–103. [Google Scholar]
- Wang, S.; Wang, M.; Yang, S.; Jiao, L. New hierarchical saliency filtering for fast ship detection in high-resolution SAR images. IEEE Trans. Geosci. Remote Sens. 2016, 55, 351–362. [Google Scholar] [CrossRef]
- Zhu, J.; Qiu, X.; Pan, Z.; Zhang, Y.; Lei, B. Projection shape template-based ship target recognition in TerraSAR-X images. IEEE Geosci. Remote Sens. Lett. 2016, 14, 222–226. [Google Scholar] [CrossRef]
- Gan, L.; Liu, P.; Wang, L. Rotation sliding window of the hog feature in remote sensing images for ship detection. In Proceedings of the 2015 8th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 12–13 December 2015; pp. 401–404. [Google Scholar]
- Song, S.; Xu, B.; Yang, J. SAR target recognition via supervised discriminative dictionary learning and sparse representation of the SAR-HOG feature. Remote Sens. 2016, 8, 683. [Google Scholar] [CrossRef]
- Lin, H.; Song, S.; Yang, J. Ship classification based on MSHOG feature and task-driven dictionary learning with structured incoherent constraints in SAR images. Remote Sens. 2018, 10, 190. [Google Scholar] [CrossRef]
- Tello, M.; López-Martínez, C.; Mallorqui, J.J. Automatic vessel monitoring with single and multidimensional SAR images in the wavelet domain. ISPRS J. Photogramm. Remote Sens. 2006, 61, 260–278. [Google Scholar] [CrossRef]
- Schwegmann, C.P.; Kleynhans, W.; Salmon, B.P. Synthetic aperture radar ship detection using Haar-like features. IEEE Geosci. Remote Sens. Lett. 2016, 14, 154–158. [Google Scholar] [CrossRef]
- Ai, J.; Tian, R.; Luo, Q.; Jin, J.; Tang, B. Multi-scale rotation-invariant Haar-like feature integrated CNN-based ship detection algorithm of multiple-target environment in SAR imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10070–10087. [Google Scholar] [CrossRef]
- Zhou, D.; Zeng, L.; Zhang, K. A novel SAR target detection algorithm via multi-scale SIFT features. J. Northwest. Polytech. Univ. 2015, 33, 867–873. [Google Scholar]
- Agrawal, A.; Mangalraj, P.; Bisherwal, M.A. Target detection in SAR images using SIFT. In Proceedings of the 2015 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Abu Dhabi, United Arab Emirates, 7–10 December 2015; pp. 90–94. [Google Scholar]
- Guo, Q.; Wang, H.; Xu, F. Scattering enhanced attention pyramid network for aircraft detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7570–7587. [Google Scholar] [CrossRef]
- Yang, R.; Pan, Z.; Jia, X.; Zhang, L.; Deng, Y. A novel CNN-based detector for ship detection based on rotatable bounding box in SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1938–1958. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Xu, P.; Li, Q.; Zhang, B.; Wu, F.; Zhao, K.; Du, X.; Yang, C.; Zhong, R. On-board real-time ship detection in HISEA-1 SAR images based on CFAR and lightweight deep learning. Remote Sens. 2021, 13, 1995. [Google Scholar] [CrossRef]
- Yu, W.; Wang, Z.; Li, J.; Luo, Y.; Yu, Z. A lightweight network based on one-level feature for ship detection in SAR images. Remote Sens. 2022, 14, 3321. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, N.; Guo, J.; Zhang, C.; Wang, B. Scfnet: Semantic Condition Constraint Guided Feature Aware Network for Aircraft Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5239420. [Google Scholar] [CrossRef]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06) 2006, Hong Kong, China, 20–24 August 2006; pp. 850–855. [Google Scholar]
- Gong, M.; Wang, D.; Zhao, X.; Guo, H.; Luo, D.; Song, M. A review of non-maximum suppression algorithms for deep learning target detection. In Proceedings of the Seventh Symposium on Novel Photoelectronic Detection Technology and Applications, Kunming, China, 5–7 November 2020; SPIE: Bellingham, WA, USA, 2021; pp. 821–828. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-Nms--improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Adaptive nms: Refining pedestrian detection in a crowd. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 6459–6468. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence 2020, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Shen, Y.; Liu, D.; Chen, J.; Wang, Z.; Wang, Z.; Zhang, Q. On-Board Multi-Class Geospatial Object Detection Based on Convolutional Neural Network for High Resolution Remote Sensing Images. Remote Sens. 2023, 15, 3963. [Google Scholar] [CrossRef]
- Zhang, X.; Zeng, H.; Guo, S.; Zhang, L. Efficient long-range attention network for image super-resolution. In Proceedings of the European Conference on Computer Vision 2022, Tel Aviv, Israel, 23–27 October 2022; pp. 649–667. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef]
- Lee, Y.; Hwang, J.-w.; Lee, S.; Bae, Y.; Park, J. An energy and GPU-computation efficient backbone network for real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops 2019, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops 2020, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Wang, W.; Xie, E.; Song, X.; Zang, Y.; Wang, W.; Lu, T.; Yu, G.; Shen, C. Efficient and accurate arbitrary-shaped text detection with pixel aggregation network. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2019, Seoul, Republic of Korea, 27–28 October 2019; pp. 8440–8449. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Zhirui, W.; Yuzhuo, K.; Xuan, Z.; Yuelei, W.; Ting, Z.; Xian, S. Sar-aircraft-1.0: High-resolution sar aircraft detection and recognition dataset. J. Radars 2023, 12, 906–922. [Google Scholar]
- Ketkar, N.; Ketkar, N. Stochastic gradient descent. In Deep Learning with Python; Apress: Berkeley, CA, USA, 2017; pp. 113–132. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. You only learn one representation: Unified network for multiple tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H. SAR ship detection dataset (SSDD): Official release and comprehensive data analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Value |
|---|---|
| Optimizer | SGD |
| Initial learning rate | 0.01 |
| Cyclic learning rate decay | 0.1 |
| Momentum | 0.937 |
| Weight decay | 0.0005 |
| Batch size | 20 |
| Epochs | 300 |
| Method | AP(0.5) | AP(0.5:0.95) | Precision | Recall | Params (M) | Flops (G) | FPS |
|---|---|---|---|---|---|---|---|
| Concat + Conv | 89.6% | 55.7% | 88.9% | 82.7% | 71.5 | 98.5 | 42.9 |
| Concat | 89.9% | 54.7% | 95.2% | 80.1% | 71.7 | 98.9 | 42.2 |
| Add | 91.5% | 56.0% | 91.5% | 87.4% | 69.9 | 97.2 | 43.7 |
| Add + SiLU | 90.5% | 55.1% | 90.2% | 84.2% | 69.9 | 97.2 | 43.7 |
| Add + BN | 92.0% | 56.3% | 94.2% | 83.3 | 69.9 | 97.2 | 43.7 |
| Add + BN + SiLU | 89.3% | 55.3% | 95.6% | 80.1% | 69.9 | 97.2 | 43.7 |
| Channel Attention | Space Attention | AP(0.5) | AP(0.5:0.95) | Precision | Recall | Params (M) | Flops (G) | FPS |
|---|---|---|---|---|---|---|---|---|
| - | - | 89.8% | 55.2% | 92.6% | 82.7% | 74.8 | 105.1 | 40.3 |
| - | (5, 5, 5, 5) | 91.1% | 54.6% | 90.2% | 82.0% | 71.3 | 105.1 | 42.9 |
| √ | - | 91.4% | 56.2% | 91.9% | 83.4% | 71.7 | 105.5 | 40.9 |
| √ | (5, 7, 5, 3) | 92.2% | 55.8% | 88.1% | 89.7% | 71.7 | 105.5 | 40.3 |
| √ | (3, 3, 3, 3) | 88.9% | 53.8% | 90.2% | 84.9% | 71.7 | 105.5 | 39.1 |
| √ | (5, 5, 5, 5) | 91.4% | 56.6% | 93.8% | 84.2% | 71.7 | 105.5 | 39.1 |
| √ | (7, 7, 7, 7) | 91.4% | 55.8% | 95.2% | 82.7% | 71.7 | 105.5 | 39.7 |
| θ | AP(0.5) | AP(0.5:0.95) | Precision | Recall |
|---|---|---|---|---|
| 1.00 | 89.8% | 55.3% | 92.6% | 82.7% |
| 1.05 | 89.8% | 55.3% | 93.0% | 82.7% |
| 1.10 | 89.9% | 55.4% | 93.0% | 82.7% |
| 1.15 | 90.0% | 55.4% | 93.0% | 82.7% |
| 1.20 | 90.1% | 55.4% | 93.0% | 82.7% |
| 1.25 | 89.5% | 55.0% | 92.9% | 81.6% |
| 1.30 | 88.1% | 54.3% | 92.8% | 80.5% |
| 1.35 | 86.9% | 53.7% | 92.8% | 80.5% |
| 1.40 | 87.0% | 53.8% | 92.8% | 80.5% |
| 1.45 | 86.9% | 53.6% | 90.1% | 83.5% |
| 1.50 | 86.3% | 53.2% | 90.7% | 82.4% |
| θ | AP(0.5) | AP(0.5:0.95) | Precision | Recall |
|---|---|---|---|---|
| 1.00 | 93.4% | 61.4% | 92.5% | 86.4% |
| 1.05 | 93.9% | 61.6% | 93.6% | 86.3% |
| 1.10 | 93.4% | 61.4% | 93.1% | 87.7% |
| 1.15 | 93.1% | 61.2% | 93.8% | 86.6% |
| 1.20 | 91.8% | 60.7% | 92.2% | 88.5% |
| 1.25 | 90.2% | 59.9% | 93.0% | 87.0% |
| 1.30 | 87.1% | 58.4% | 93.3% | 83.9% |
| 1.35 | 84.2% | 56.9% | 92.4% | 80.6% |
| 1.40 | 81.5% | 55.2% | 93.8% | 77.8% |
| 1.45 | 79.7% | 54.1% | 93.3% | 76.9% |
| 1.50 | 77.9% | 52.7% | 91.6% | 75.6% |
| Algorithm | AP(0.5) | AP(0.5:0.95) | Precision | Recall |
|---|---|---|---|---|
| NMS | 89.8% | 55.2% | 92.6% | 82.7% |
| Soft-NMS | 85.5% | 53.3% | 92.6% | 82.7% |
| DIoU-NMS | 89.9% | 55.3% | 92.6% | 82.7% |
| WBF | 88.4% | 43.5% | 92.8% | 80.0% |
| EH-NMS | 90.1% | 55.4% | 93.0% | 82.7% |
| Model | NMS | AP(0.5) | AP(0.5:0.95) | Precision | Recall |
|---|---|---|---|---|---|
| YOLOv7 | - | 89.8% | 55.2% | 92.6% | 82.7% |
| √ | 90.1% | 55.4% | 93.0% | 82.7% | |
| YOLOr-p6 | - | 89.2% | 53.5% | 93.6% | 80.5% |
| √ | 89.7% | 53.8% | 94.4% | 80.5% | |
| our | - | 91.8% | 57.0% | 94.0% | 81.2% |
| √ | 91.9% | 57.1% | 94.0% | 81.2% |
| Method | AP(0.5) | AP(0.5:0.95) | Precision | Recall | Params (M) | Flops (G) | FPS | ||
|---|---|---|---|---|---|---|---|---|---|
| SAD-FPN | A-ELAN-H | EH-NMS | |||||||
| - | - | - | 89.8% | 55.2% | 92.6% | 82.7% | 74.8 | 105.1 | 40.3 |
| √ | - | - | 92.0% | 56.3% | 94.2% | 83.3% | 69.9 | 97.2 | 43.7 |
| - | √ | - | 91.4% | 56.6% | 93.8% | 84.2% | 71.7 | 105.5 | 39.1 |
| - | - | √ | 90.1% | 55.4% | 93.0% | 82.7% | 74.8 | 105.1 | 40.3 |
| √ | √ | - | 91.8% | 57.0% | 94.0% | 81.2% | 70.0 | 97.2 | 43.7 |
| - | √ | √ | 91.4% | 56.6% | 94.6% | 84.2% | 71.7 | 105.5 | 39.1 |
| √ | - | √ | 92.3% | 56.4% | 94.2% | 83.3% | 69.9 | 97.2 | 43.7 |
| √ | √ | √ | 91.9% | 57.1% | 94.0% | 81.2% | 70.0 | 97.2 | 43.7 |
| Model | Epochs | AP(0.5) | AP(0.5:0.95) | Precision | Recall | Params (M) | Flops (G) | FPS |
|---|---|---|---|---|---|---|---|---|
| ResNet50-CSP | 300 | 91.5% | 55.9% | 92.3% | 83.5% | 65.1 | 64.4 | 55.7 |
| ResNeXt50-CSP | 300 | 91.3% | 55.4% | 88.9% | 85.3% | 64.3 | 59.7 | 56.9 |
| YOLOv4 | 300 | 87.8% | 54.0% | 93.8% | 77.5% | 105.5 | 119.7 | 40.9 |
| YOLOr-p6 | 300 | 89.2% | 53.5% | 93.6% | 80.5% | 74.3 | 80.6 | 56.9 |
| YOLOv7 | 300 | 89.8% | 55.2% | 92.6% | 82.7% | 74.8 | 105.1 | 41.6 |
| Our | 300 | 91.9% | 57.1% | 94.0% | 81.2% | 69.9 | 97.2 | 43.7 |
| Model | Epochs | AP(0.5) | AP(0.5:0.95) | Precision | Recall | Params (M) | Flops (G) | FPS |
|---|---|---|---|---|---|---|---|---|
| ResNet50-CSP | 400 | 88.9% | 60.9% | 89.5% | 84.2% | 65.1 | 64.4 | 55.7 |
| ResNeXt50-CSP | 400 | 82.9% | 51.5% | 84.1% | 77.8% | 64.3 | 59.7 | 56.9 |
| YOLOv4 | 400 | 81.6% | 51.3% | 85.9% | 73.3% | 105.5 | 119.7 | 40.9 |
| YOLOr-p6 | 400 | 80.8% | 51.6% | 81.4% | 77.2% | 74.3 | 80.6 | 56.9 |
| YOLOv7 | 400 | 89.8% | 63.0% | 88.0% | 87.8% | 74.8 | 105.1 | 41.6 |
| Our | 400 | 90.8% | 63.8% | 89.3% | 87.9% | 69.9 | 97.2 | 43.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Shen, Y.; Liang, Y.; Wang, Z.; Zhang, Q. YOLO-SAD: An Efficient SAR Aircraft Detection Network. Appl. Sci. 2024, 14, 3025. https://doi.org/10.3390/app14073025
Chen J, Shen Y, Liang Y, Wang Z, Zhang Q. YOLO-SAD: An Efficient SAR Aircraft Detection Network. Applied Sciences. 2024; 14(7):3025. https://doi.org/10.3390/app14073025
Chicago/Turabian StyleChen, Junyi, Yanyun Shen, Yinyu Liang, Zhipan Wang, and Qingling Zhang. 2024. "YOLO-SAD: An Efficient SAR Aircraft Detection Network" Applied Sciences 14, no. 7: 3025. https://doi.org/10.3390/app14073025
APA StyleChen, J., Shen, Y., Liang, Y., Wang, Z., & Zhang, Q. (2024). YOLO-SAD: An Efficient SAR Aircraft Detection Network. Applied Sciences, 14(7), 3025. https://doi.org/10.3390/app14073025