

Time of Flight Distance Sensor–Based Construction Equipment Activity Detection Method


Abstract
1. Introduction
2. Literature Review and Background
2.1. Vision-Based Method for Recognizing Equipment Activity
2.2. Sensor-Based Method for Recognizing Equipment Activity
2.3. Optimization with Adaptive Moment Estimation (Adam) Algorithm
3. Methodologies
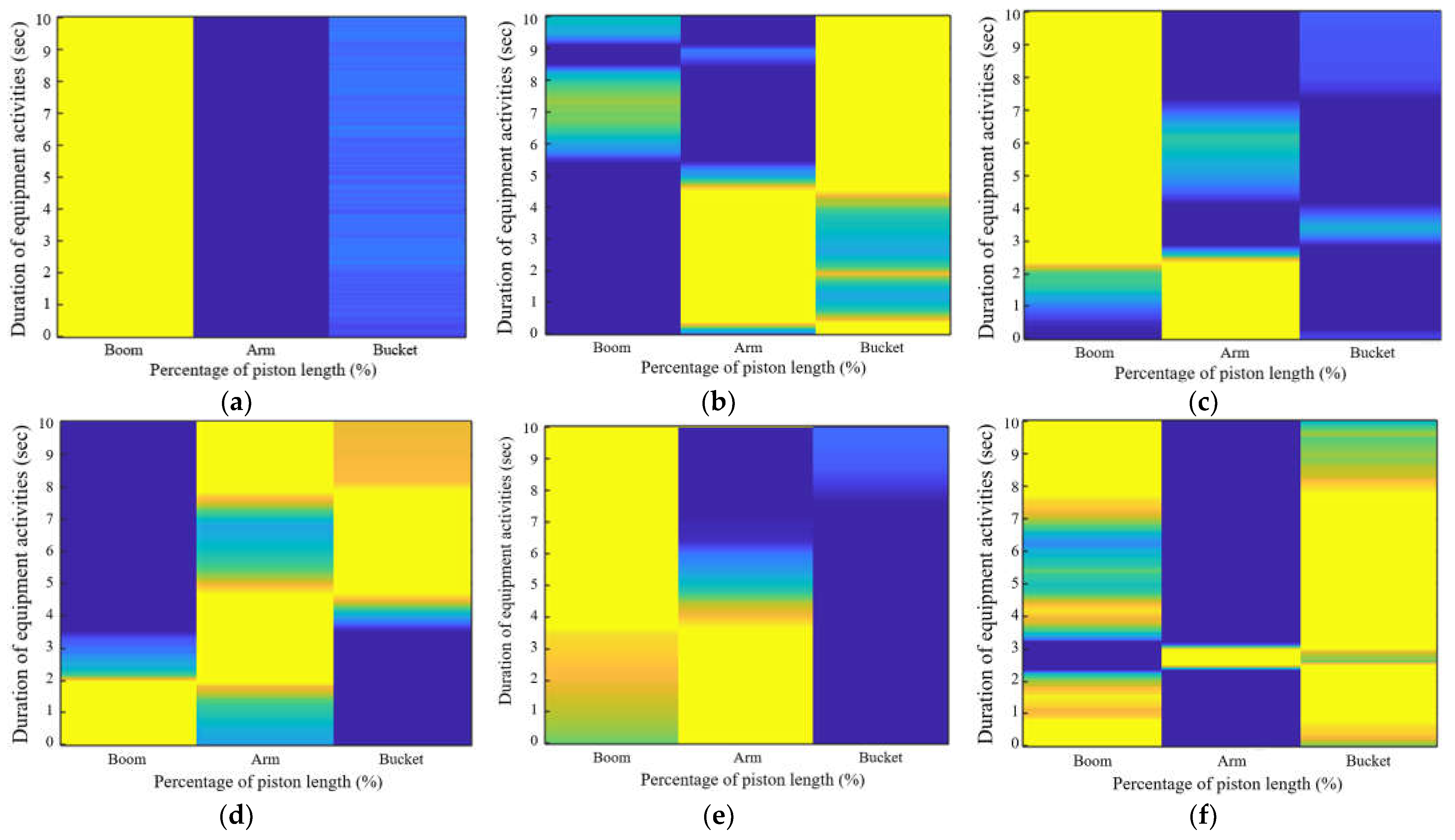
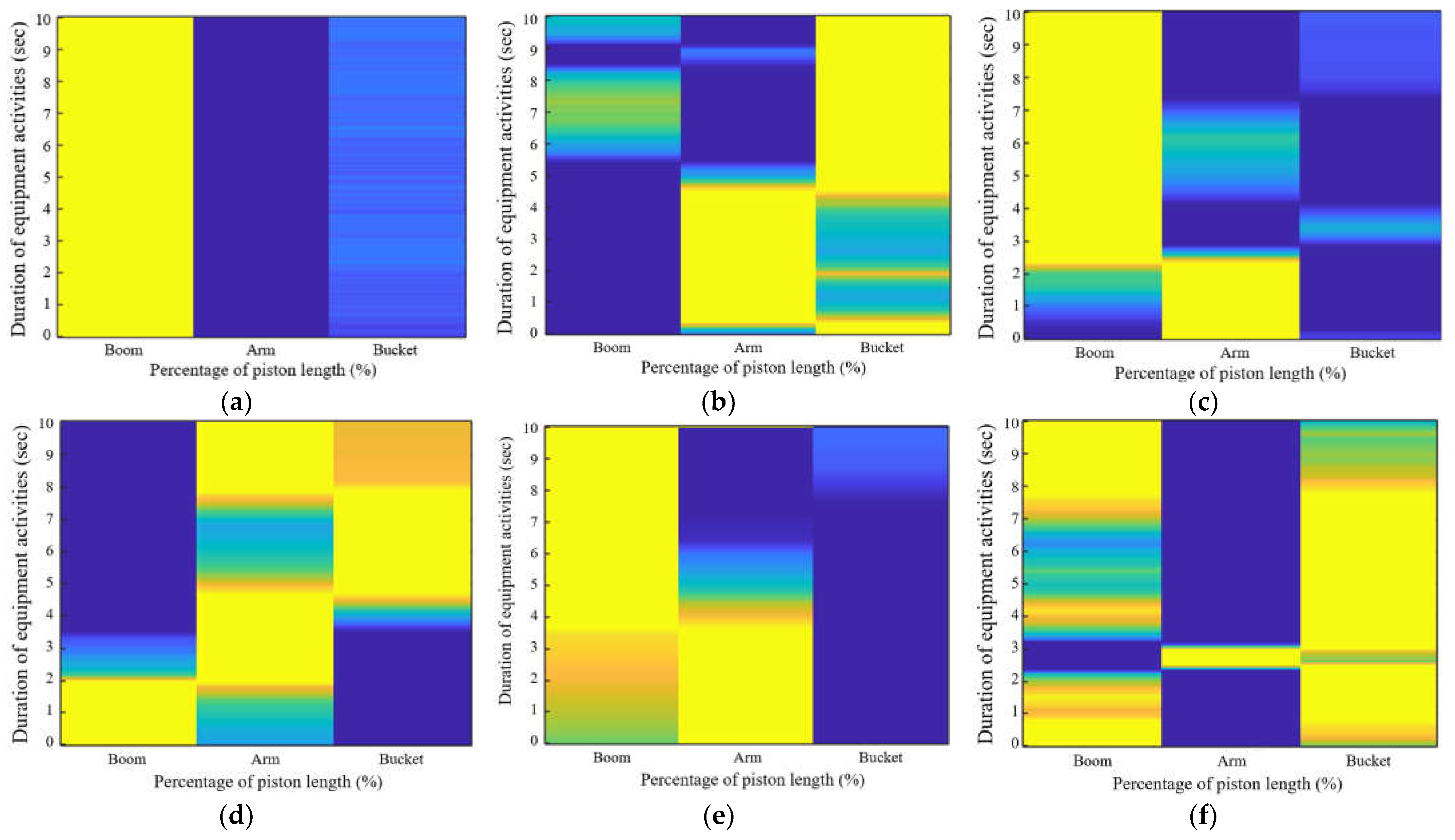
3.1. Equipment Activities for Analysis
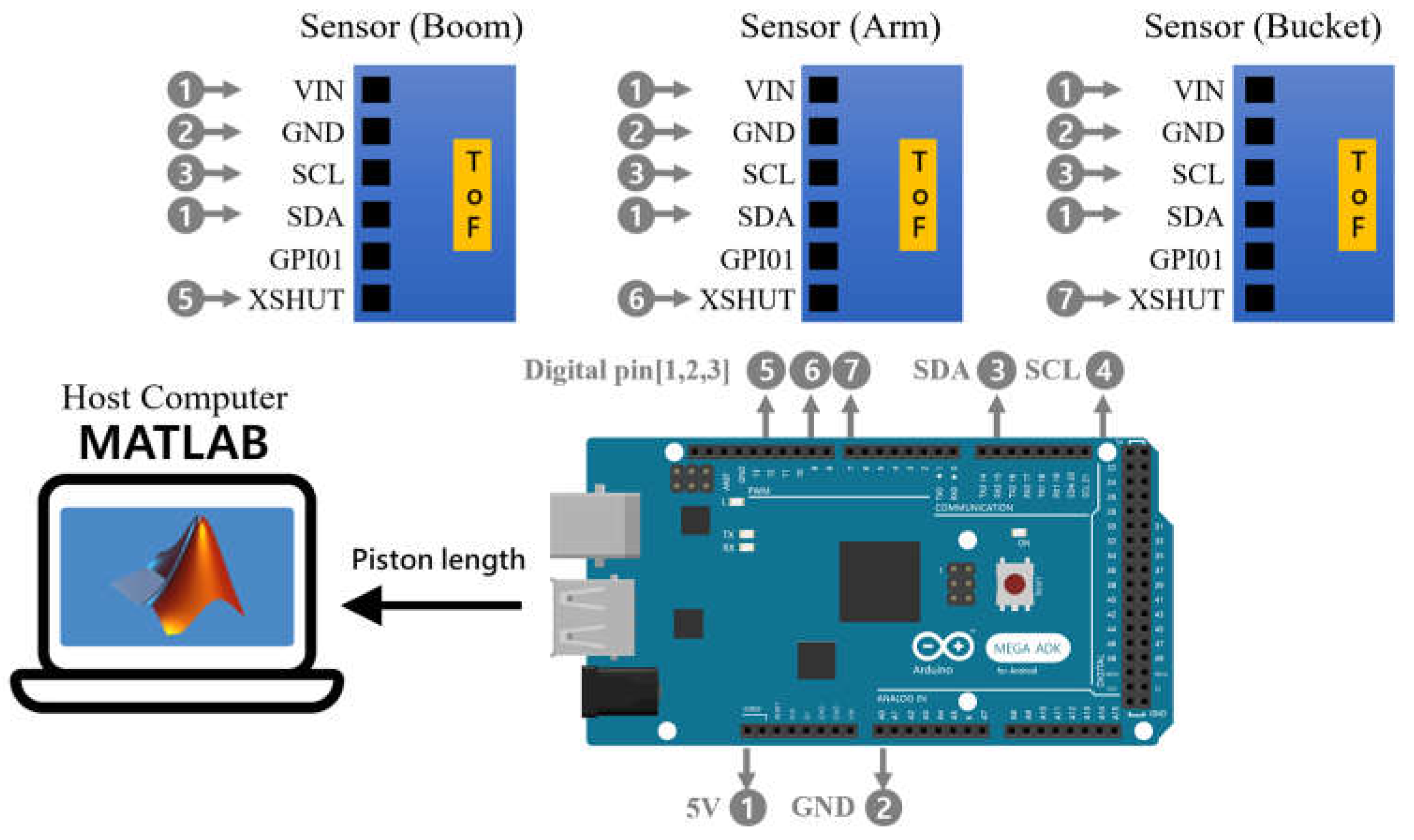
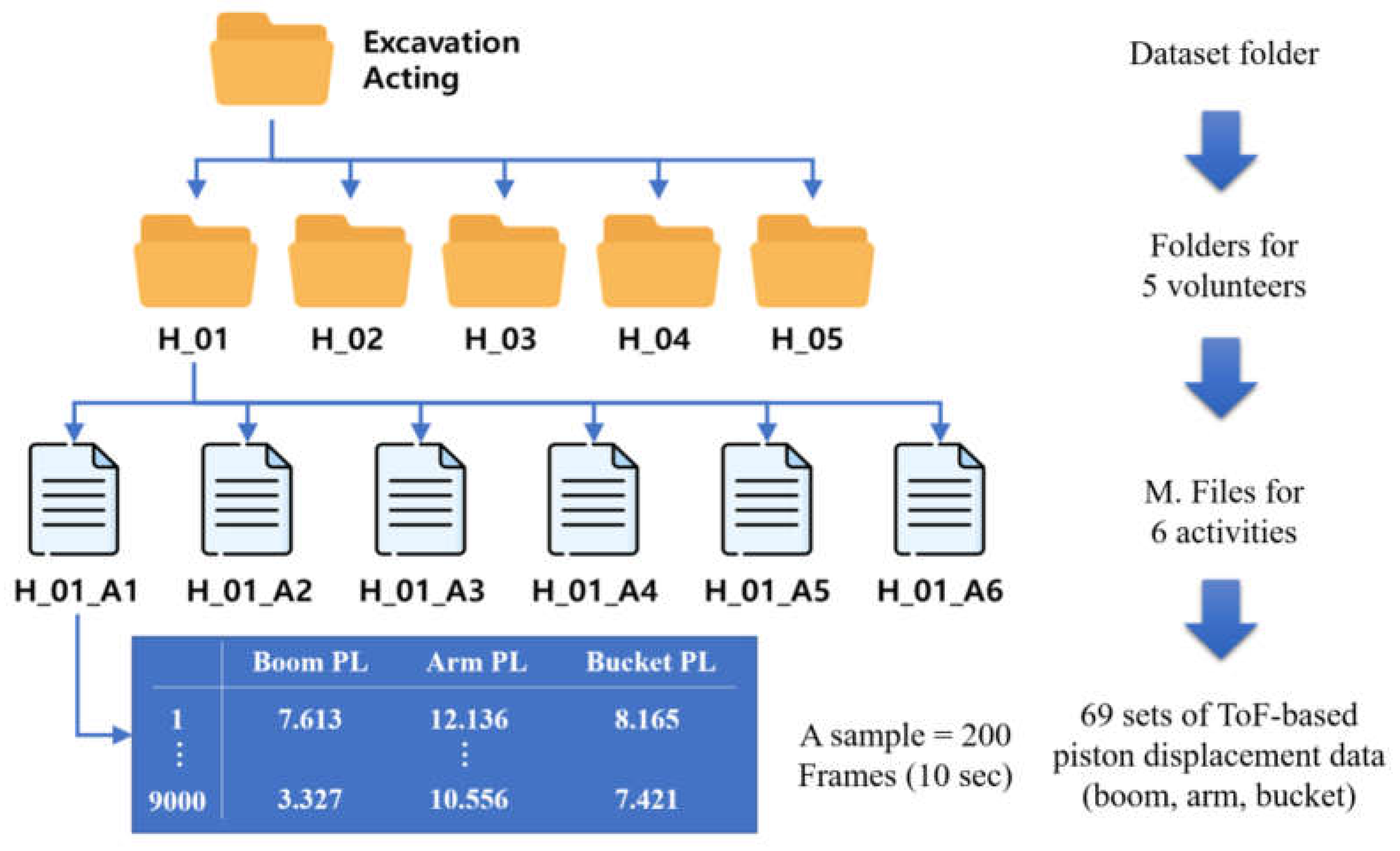
3.2. Data Collection and Participants
3.3. Detecting Equipment Activity
3.3.1. Aligning Data Standards
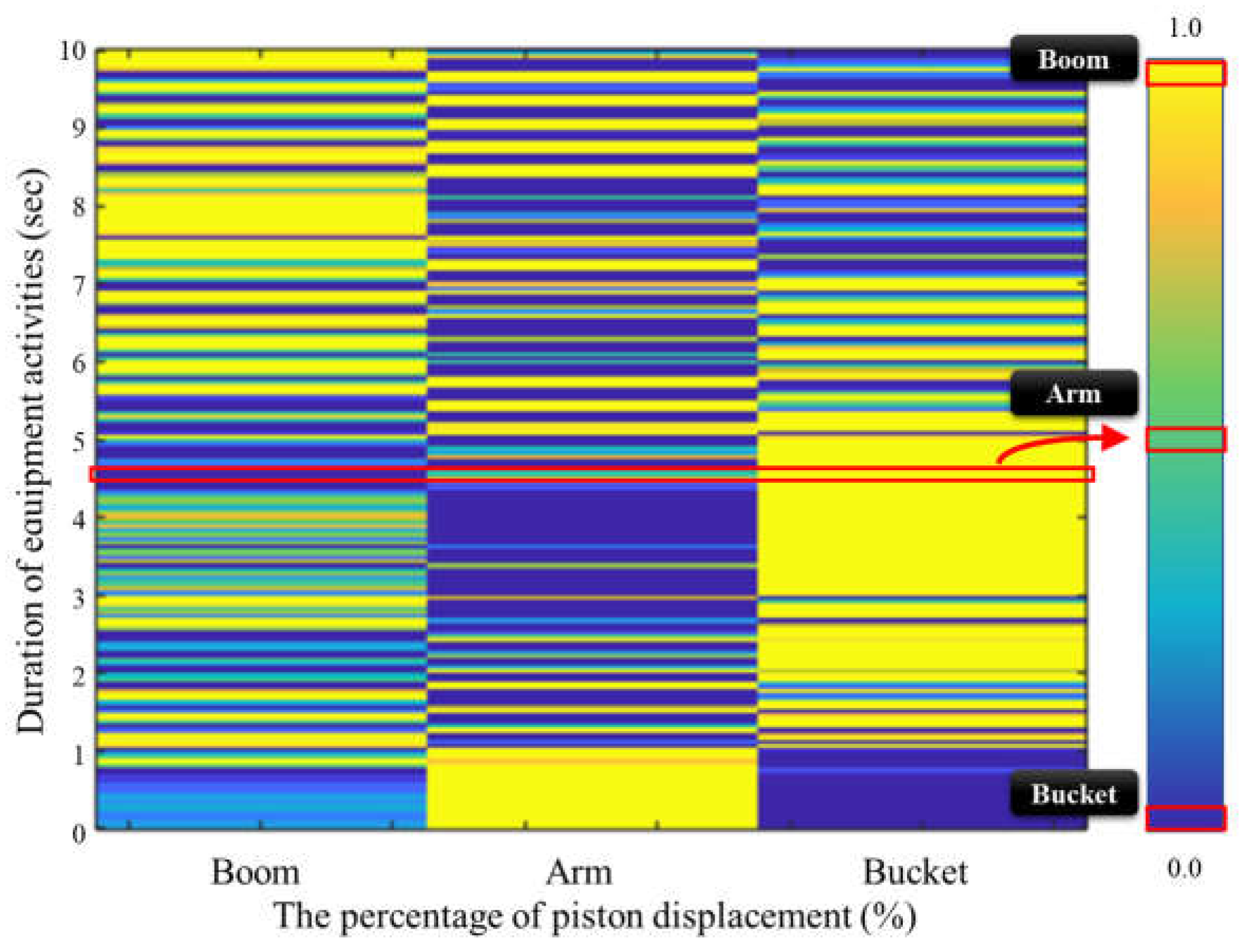
3.3.2. Data Analysis Techniques
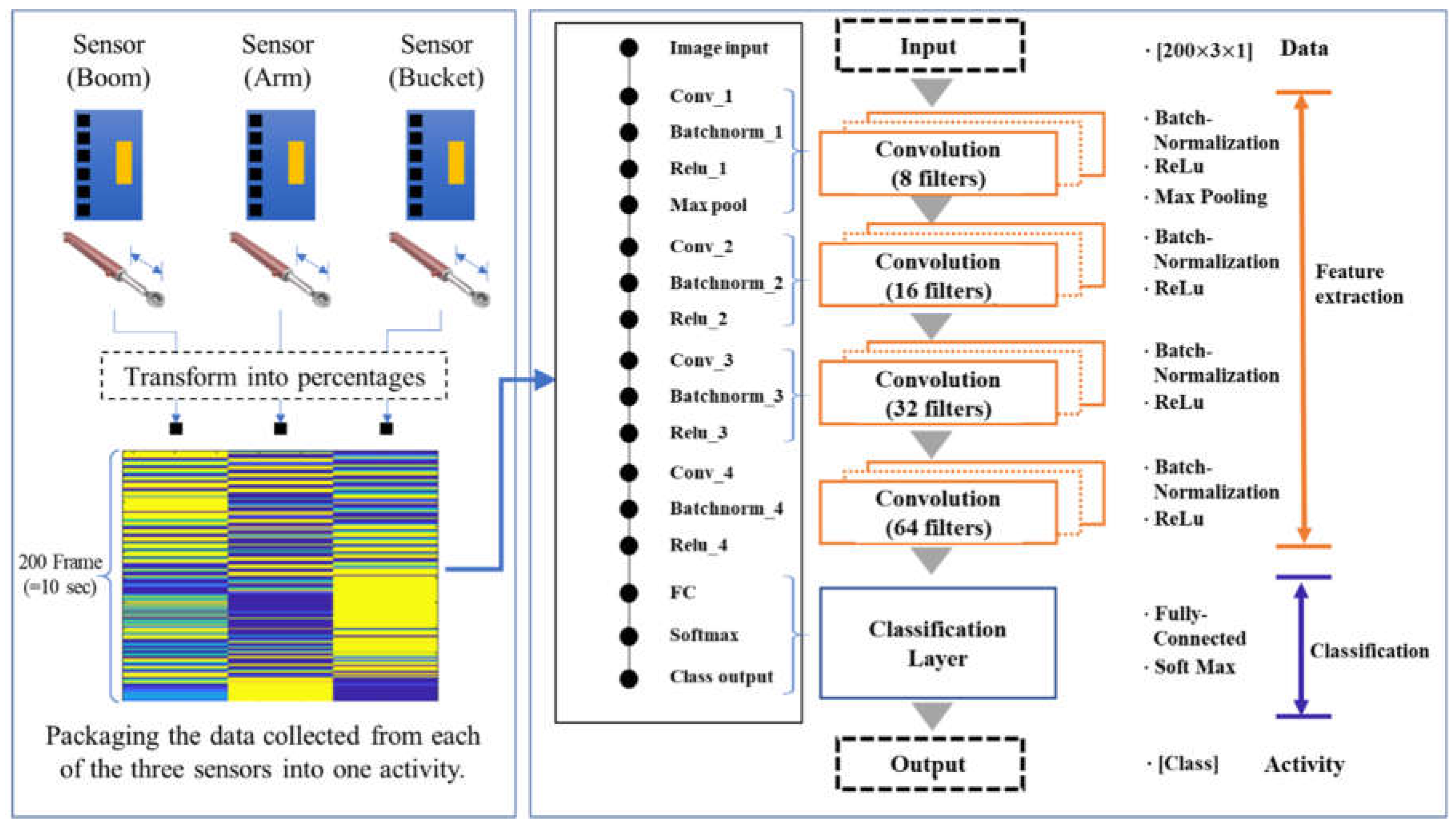
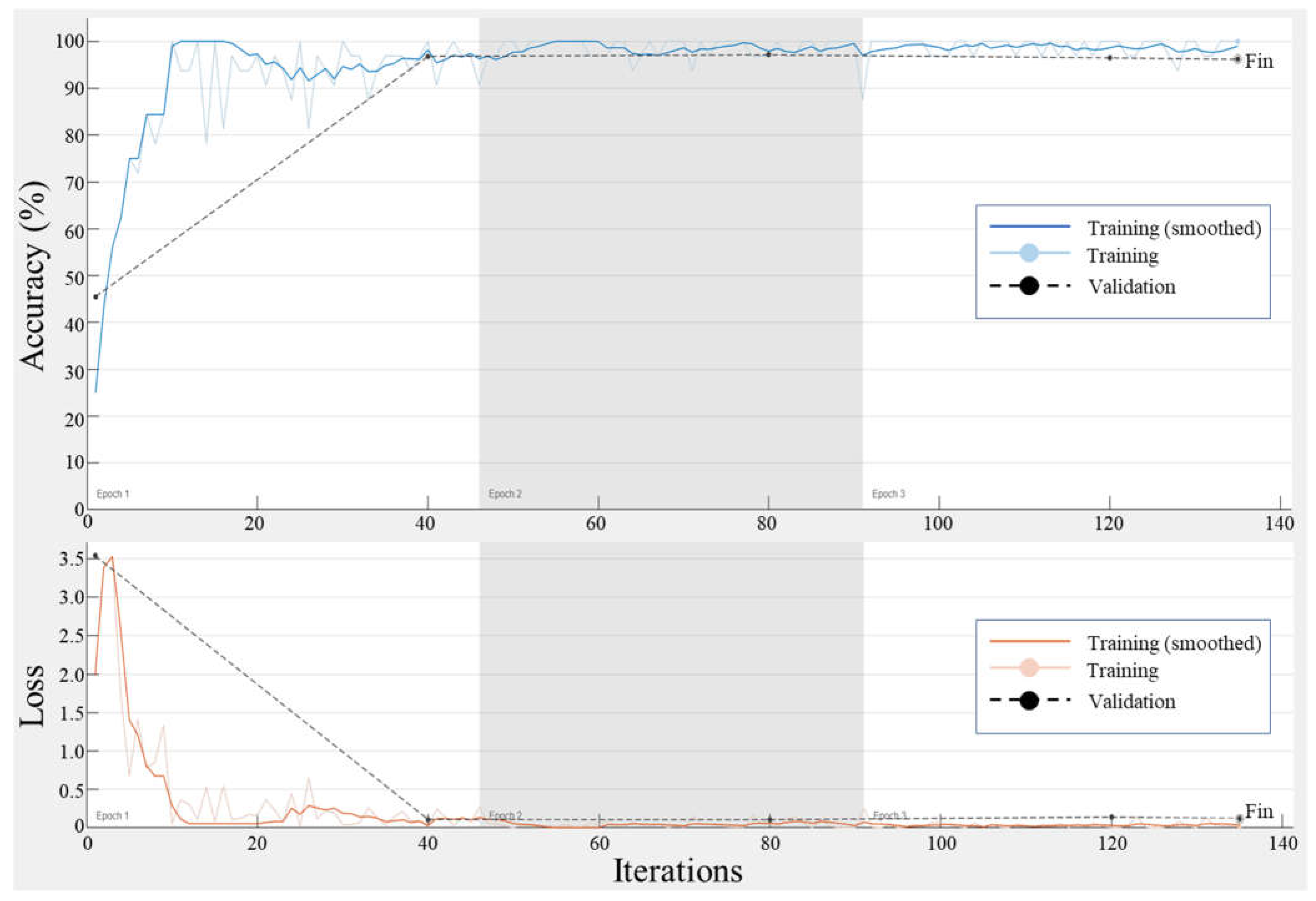
3.3.3. DCNN-Based Activity Recognitions
- Input section
- Feature extraction stage
- Classification stage
- Output section
- Training options configuration
4. Results and Discussion
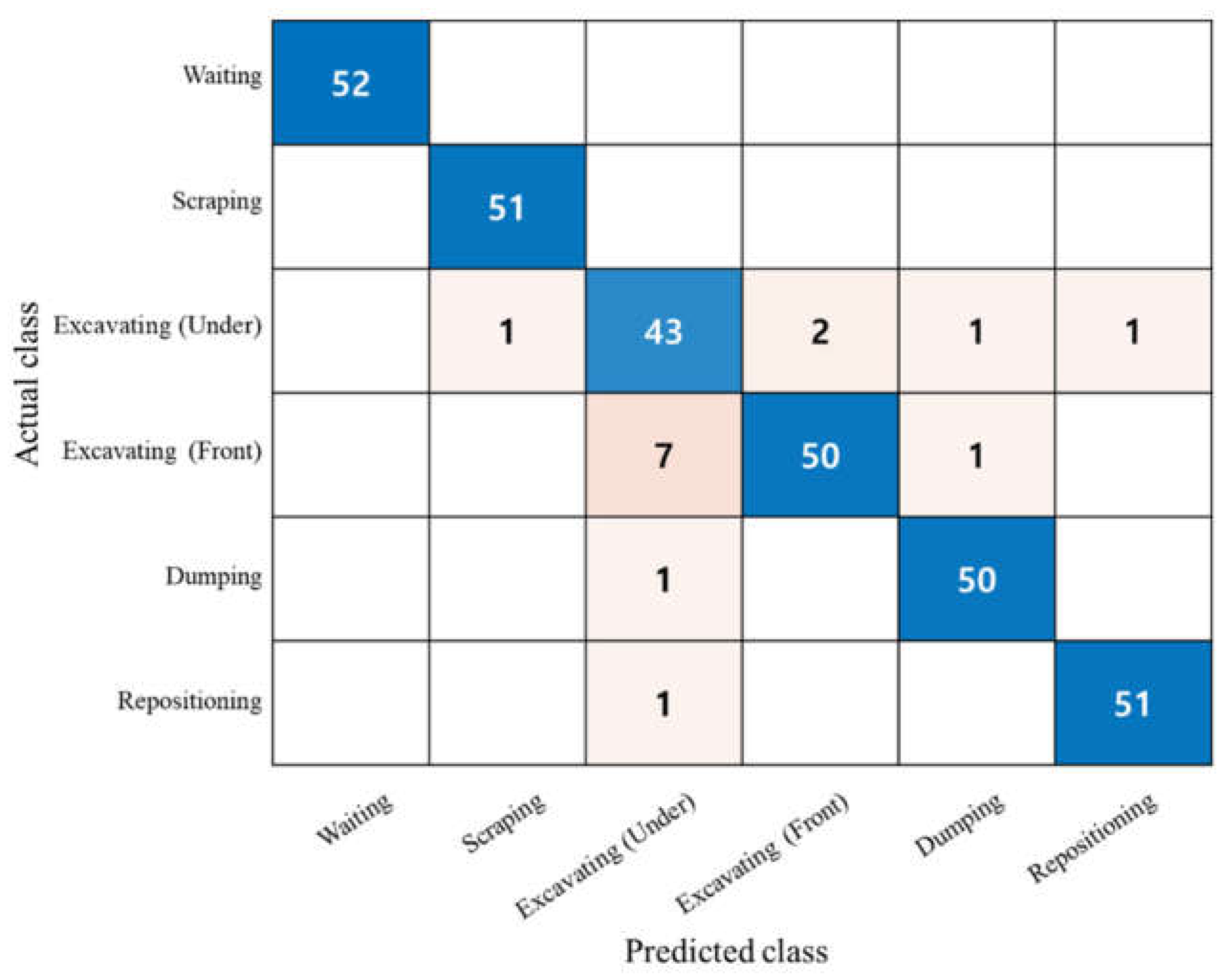
4.1. Performance Verification of the Proposed Model
4.2. Comparison with Other Models
4.3. Contributions and Limitations
4.4. Generalizability of the Proposed Method
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cheng, C.-F.; Rashidi, A.; Davenport, M.A.; Anderson, D.V. Activity Analysis of Construction Equipment Using Audio Signals and Support Vector Machines. Autom. Constr. 2017, 81, 240–253. [Google Scholar] [CrossRef]
- Harichandran, A.; Raphael, B.; Mukherjee, A. A Hierarchical Machine Learning Framework for the Identification of Automated Construction. J. Inf. Technol. Constr. 2021, 26, 591–623. [Google Scholar] [CrossRef]
- Yang, J.; Park, M.-W.; Vela, P.A.; Golparvar-Fard, M. Construction Performance Monitoring via Still Images, Time-Lapse Photos, and Video Streams: Now, Tomorrow, and the Future. Adv. Eng. Inform. 2015, 29, 211–224. [Google Scholar] [CrossRef]
- Lu, M.; Dai, F.; Chen, W. Real-Time Decision Support for Planning Concrete Plant Operations Enabled by Integrating Vehicle Tracking Technology, Simulation, and Optimization Algorithms. Can. J. Civ. Eng. 2007, 34, 912–922. [Google Scholar] [CrossRef]
- Akhavian, R.; Behzadan, A.H. Construction Equipment Activity Recognition for Simulation Input Modeling Using Mobile Sensors and Machine Learning Classifiers. Adv. Eng. Inform. 2015, 29, 867–877. [Google Scholar] [CrossRef]
- Peurifoy, R.L.; Schexnayder, C.; Schmitt, R.; Shapira, A. Construction Planning, Equipment, and Methods, 9th ed.; McGraw-Hill Education: New York, NY, USA, 2018. [Google Scholar]
- Chen, C.; Zhu, Z.; Hammad, A. Automated Excavators Activity Recognition and Productivity Analysis from Construction Site Surveillance Videos. Autom. Constr. 2020, 110, 103045. [Google Scholar] [CrossRef]
- Duan, R.; Deng, H.; Tian, M.; Deng, Y.; Lin, J. SODA: A Large-Scale Open Site Object Detection Dataset for Deep Learning in Construction. Autom. Constr. 2022, 142, 104499. [Google Scholar] [CrossRef]
- Xiao, B.; Kang, S.-C. Development of an Image Data Set of Construction Machines for Deep Learning Object Detection. J. Comput. Civ. Eng. 2021, 35, 05020005. [Google Scholar] [CrossRef]
- Lee, Y.-C.; Scarpiniti, M.; Uncini, A. Advanced Sound Classifiers and Performance Analyses for Accurate Audio-Based Construction Project Monitoring. J. Comput. Civ. Eng. 2020, 34, 04020030. [Google Scholar] [CrossRef]
- Jung, S.; Jeoung, J.; Lee, D.; Jang, H.; Hong, T. Visual–Auditory Learning Network for Construction Equipment Action Detection. Comput.-Aided Civ. Infrastruct. Eng. 2023, 38, 1916–1934. [Google Scholar] [CrossRef]
- Slaton, T.; Hernandez, C.; Akhavian, R. Construction Activity Recognition with Convolutional Recurrent Networks. Autom. Constr. 2020, 113, 103138. [Google Scholar] [CrossRef]
- Rashid, K.M.; Louis, J. Automated Activity Identification for Construction Equipment Using Motion Data from Articulated Members. Front. Built Environ. 2020, 5, 144. [Google Scholar] [CrossRef]
- Langroodi, A.K.; Vahdatikhaki, F.; Doree, A. Activity Recognition of Construction Equipment Using Fractional Random Forest. Autom. Constr. 2021, 122, 103465. [Google Scholar] [CrossRef]
- Montaser, A.; Moselhi, O. RFID+ for Tracking Earthmoving Operations. In Proceedings of the Construction Research Congress 2012, West Lafayette, IN, USA, 21–23 May 2012; American Society of Civil Engineers: Reston, VA, USA, 2012; pp. 1011–1020. [Google Scholar]
- Golparvar-Fard, M.; Heydarian, A.; Niebles, J.C. Vision-Based Action Recognition of Earthmoving Equipment Using Spatio-Temporal Features and Support Vector Machine Classifiers. Adv. Eng. Inform. 2013, 27, 652–663. [Google Scholar] [CrossRef]
- Memarzadeh, M.; Golparvar-Fard, M.; Niebles, J.C. Automated 2D Detection of Construction Equipment and Workers from Site Video Streams Using Histograms of Oriented Gradients and Colors. Autom. Constr. 2013, 32, 24–37. [Google Scholar] [CrossRef]
- Xiao, B.; Kang, S.-C. Vision-Based Method Integrating Deep Learning Detection for Tracking Multiple Construction Machines. J. Comput. Civ. Eng. 2021, 35, 04020071. [Google Scholar] [CrossRef]
- Kim, J.; Chi, S. Action Recognition of Earthmoving Excavators Based on Sequential Pattern Analysis of Visual Features and Operation Cycles. Autom. Constr. 2019, 104, 255–264. [Google Scholar] [CrossRef]
- Shen, Y.; Wang, J.; Feng, C.; Wang, Q. Dual Attention-Based Deep Learning for Construction Equipment Activity Recognition Considering Transition Activities and Imbalanced Dataset. Autom. Constr. 2024, 160, 105300. [Google Scholar] [CrossRef]
- Bohn, J.S.; Teizer, J. Benefits and Barriers of Construction Project Monitoring Using High-Resolution Automated Cameras. J. Constr. Eng. Manag. 2010, 136, 632–640. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, L. Vision-Based Excavator Activity Analysis and Safety Monitoring System. In Proceedings of the 38th International Symposium on Automation and Robotics in Construction, Dubai, United Arab Emirates, 2–4 November 2021. [Google Scholar]
- Zhang, J.; Zi, L.; Hou, Y.; Wang, M.; Jiang, W.; Deng, D. A Deep Learning-Based Approach to Enable Action Recognition for Construction Equipment. Adv. Civ. Eng. 2020, 2020, 8812928. [Google Scholar] [CrossRef]
- Cheng, T.; Venugopal, M.; Teizer, J.; Vela, P.A. Performance Evaluation of Ultra Wideband Technology for Construction Resource Location Tracking in Harsh Environments. Autom. Constr. 2011, 20, 1173–1184. [Google Scholar] [CrossRef]
- Teizer, J.; Venugopal, M.; Walia, A. Ultrawideband for Automated Real-Time Three-Dimensional Location Sensing for Workforce, Equipment, and Material Positioning and Tracking. Transp. Res. Rec. J. Transp. Res. Board. 2008, 2081, 56–64. [Google Scholar] [CrossRef]
- Shahi, A.; Aryan, A.; West, J.S.; Haas, C.T.; Haas, R.C.G. Deterioration of UWB Positioning during Construction. Autom. Constr. 2012, 24, 72–80. [Google Scholar] [CrossRef]
- Montaser, A.; Bakry, I.; Alshibani, A.; Moselhi, O. Estimating Productivity of Earthmoving Operations Using Spatial Technologies 1 This Paper Is One of a Selection of Papers in This Special Issue on Construction Engineering and Management. Can. J. Civ. Eng. 2012, 39, 1072–1082. [Google Scholar] [CrossRef]
- Vahdatikhaki, F.; Hammad, A. Framework for near Real-Time Simulation of Earthmoving Projects Using Location Tracking Technologies. Autom. Constr. 2014, 42, 50–67. [Google Scholar] [CrossRef]
- Mathur, N.; Aria, S.S.; Adams, T.; Ahn, C.R.; Lee, S. Automated Cycle Time Measurement and Analysis of Excavator’s Loading Operation Using Smart Phone-Embedded IMU Sensors. In Proceedings of the Computing in Civil Engineering 2015, Austin, TX, USA, 21–23 June 2015; American Society of Civil Engineers: Reston, VA, USA, 2015; pp. 215–222. [Google Scholar]
- Akhavian, R.; Behzadan, A.H. An Integrated Data Collection and Analysis Framework for Remote Monitoring and Planning of Construction Operations. Adv. Eng. Inform. 2012, 26, 749–761. [Google Scholar] [CrossRef]
- Ahn, C.R.; Lee, S.; Peña-Mora, F. Application of Low-Cost Accelerometers for Measuring the Operational Efficiency of a Construction Equipment Fleet. J. Comput. Civ. Eng. 2015, 29, 04014042. [Google Scholar] [CrossRef]
- Bae, J.; Kim, K.; Hong, D. Automatic Identification of Excavator Activities Using Joystick Signals. Int. J. Precis. Eng. Manuf. 2019, 20, 2101–2107. [Google Scholar] [CrossRef]
- Rashid, K.M.; Louis, J. Times-Series Data Augmentation and Deep Learning for Construction Equipment Activity Recognition. Adv. Eng. Inform. 2019, 42, 100944. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Kim, J.; Chi, S.; Ahn, C.R. Hybrid Kinematic–Visual Sensing Approach for Activity Recognition of Construction Equipment. J. Build. Eng. 2021, 44, 102709. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Activity | Description | Start | End | Image |
|---|---|---|---|---|---|
| 1 | Waiting | Standby state, without performing any operations | No movement | No movement | 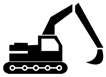 |
| 2 | Scraping | Gathering or pushing surface soil with a constant height | No soil in the bucket, and the blade touches the ground | The bucket moves in the opposite direction after dragging | 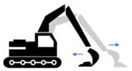 |
| 3 | Excavating (under) | Digging below the ground to excavate soil | The blade touches the soil | The bucket is filled with soil and is fixed | 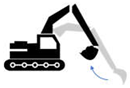 |
| 4 | Excavating (front) | Excavating soil from the surface at a specific location | The blade moves down to the ground | The blade comes up from the ground, and the boom is fixed | 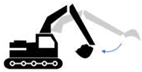 |
| 5 | Dumping | Disposing of the collected soil from the bucket | The bucket piston contracts with soil in the bucket | The soil is emptied from the bucket, and the bucket piston is fixed |  |
| 6 | Repositioning | Adjusting its position by supporting the body with the boom on the ground | Place the bucket in a stable position on the ground | After the body is raised and lowered, lift the bucket |  |
| Feature | Details |
|---|---|
| Package | Optical LGA12 |
| Size | 4.40 × 2.40 × 1.00 mm |
| Operating voltage | 2.6 to 3.5 V |
| Operating temperature | −20–70 °C |
| Infrared emitter | 940 nm |
| I2C | Up to 400 kHz (FAST mode) serial bus Address: 0 × 52 |
| Detectable distance | 10–300 mm (experimental measurements) |
| Parameter | Value | Description |
|---|---|---|
| Gradient Decay Factor | 0.9 | Rate at which past gradients are decayed. |
| Squared Gradient Decay Factor | 0.999 | Rate at which past squared gradients are decayed. |
| Epsilon | 1 × 10−8 | Constant added to prevent division by zero. |
| Initial Learning Rate | 1 × 10−3 | Starting learning rate for the training process. |
| Max Epochs | 3 | Maximum number of epochs for training. |
| Learning Rate Schedule | ‘none’ | Approach to adjusting the learning rate (constant in this study). |
| Learning Rate Drop Factor | 0.1 | Factor by which the learning rate is reduced when scheduled. |
| Learning Rate Drop Period | 10 | Epochs between learning rate reductions. |
| Mini-Batch Size | 32 | Number of samples per gradient update. |
| Shuffle | ‘once’ | Shuffling of the dataset before training. |
| L2 Regularization | 1 × 10−4 | Regularization factor to prevent overfitting. |
| Gradient Threshold Method | ‘L2Norm’ | Method for clipping gradients (not applied with ‘Inf’ threshold). |
| Gradient Threshold | Inf | Threshold for gradient clipping. |
| No. | Method | Category | Data Set | Activity | Performance Metrics | ||
|---|---|---|---|---|---|---|---|
| Precision | Recall | Accuracy | |||||
| 1 | C. Chen, et al. [7] | Vision (Image size: 1280 × 720) | 351 | Digging | 95 | 86 | |
| Swinging | 86 | 93 | |||||
| Loading | 84 | 80 | |||||
| Average | 88 | 88 | 87.6 | ||||
| 2 | Slaton T, et al. [12] | Sensor (Acceleration sensor) | 242 | Idling | 100 | 81 | |
| Traveling | 99 | 57 | |||||
| Scooping | 73 | 96 | |||||
| Dropping | 83 | 65 | |||||
| Rotating (left) | 69 | 93 | |||||
| Rotating (right) | 94 | 80 | |||||
| Average | 85 | 83 | 83 | ||||
| 3 | Proposed Model | Sensor (Distance sensor) | 312 | Waiting | 100 | 100 | |
| Scraping | 100 | 100 | |||||
| Excavating (Under) | 82.7 | 89.6 | |||||
| Excavating (Front) | 96.2 | 86.2 | |||||
| Dumping | 96.2 | 98.0 | |||||
| Repositioning | 98.1 | 98.1 | |||||
| Average | 95.5 | 95.3 | 95.2 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, Y.-J.; Yi, C.-Y. Time of Flight Distance Sensor–Based Construction Equipment Activity Detection Method. Appl. Sci. 2024, 14, 2859. https://doi.org/10.3390/app14072859
Park Y-J, Yi C-Y. Time of Flight Distance Sensor–Based Construction Equipment Activity Detection Method. Applied Sciences. 2024; 14(7):2859. https://doi.org/10.3390/app14072859
Chicago/Turabian StylePark, Young-Jun, and Chang-Yong Yi. 2024. "Time of Flight Distance Sensor–Based Construction Equipment Activity Detection Method" Applied Sciences 14, no. 7: 2859. https://doi.org/10.3390/app14072859
APA StylePark, Y.-J., & Yi, C.-Y. (2024). Time of Flight Distance Sensor–Based Construction Equipment Activity Detection Method. Applied Sciences, 14(7), 2859. https://doi.org/10.3390/app14072859