
Survivability Prediction of Open Source Software with Polynomial Regression


Abstract
1. Introduction
- RQ1
- Can the survivability of OSS be predicted through polynomial regression?
- RQ2
- Can the survivability of OSS be modeled through polynomial regression?
2. Background
2.1. Survivability Prediction
- Project dependency: Software development projects can have dependencies on other systems or components. These dependencies can cause maintenance to be more difficult if failures in other systems affect the main system.
- Change management: Changes to software or dependencies must be managed to ensure that new issues do not arise. This is necessary to minimize the impact of changes on the system.
- Documentation: Documentation can provide a clear understanding of software design, functionality, and dependencies, making maintenance tasks easier. Clear documentation can also facilitate knowledge transfer among team members and prevent important information from being lost over time.
- Testing: Regular testing is essential to ensure that the software continue to function and meet user requirements. This includes unit testing, integration testing, and acceptance testing, among others.
- Security and compliance: Security and compliance requirements may change over time, so existing software must be updated and maintained to meet new requirements.
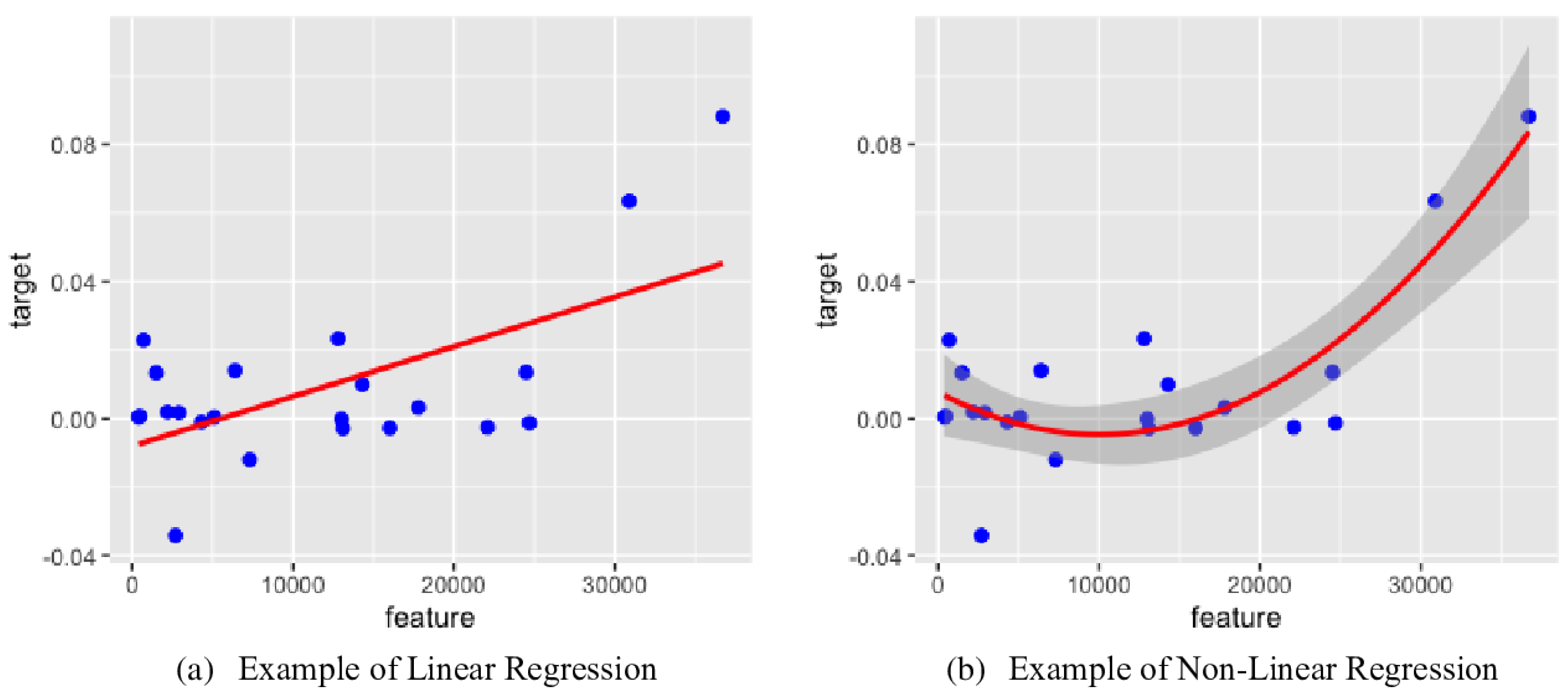
2.2. Polynomial Regression
2.2.1. Regression Model
2.2.2. Model Optimization Algorithm
- Matrix (Vector) Transformation: The model is expressed in matrix form to encapsulate the linear, quadratic terms, and interaction terms for five features () based on Equation (2). The regression coefficients are organized in a vector W ([21 × 1]) as:For all n observations, the matrix X that includes five independent variables, their squares, and interaction terms is defined as the [n × 21] matrix as follows:And the dependent variable vector Y for all n observations is:The model in matrix notation is then expressed as:
- Calculation of Least Squares Estimator: The optimal regression coefficient matrix W, known as the least squares estimator, is calculated by solving:where is the inverse of the matrix product , and is the transpose of X. This yields the least squares estimates for the regression coefficients.
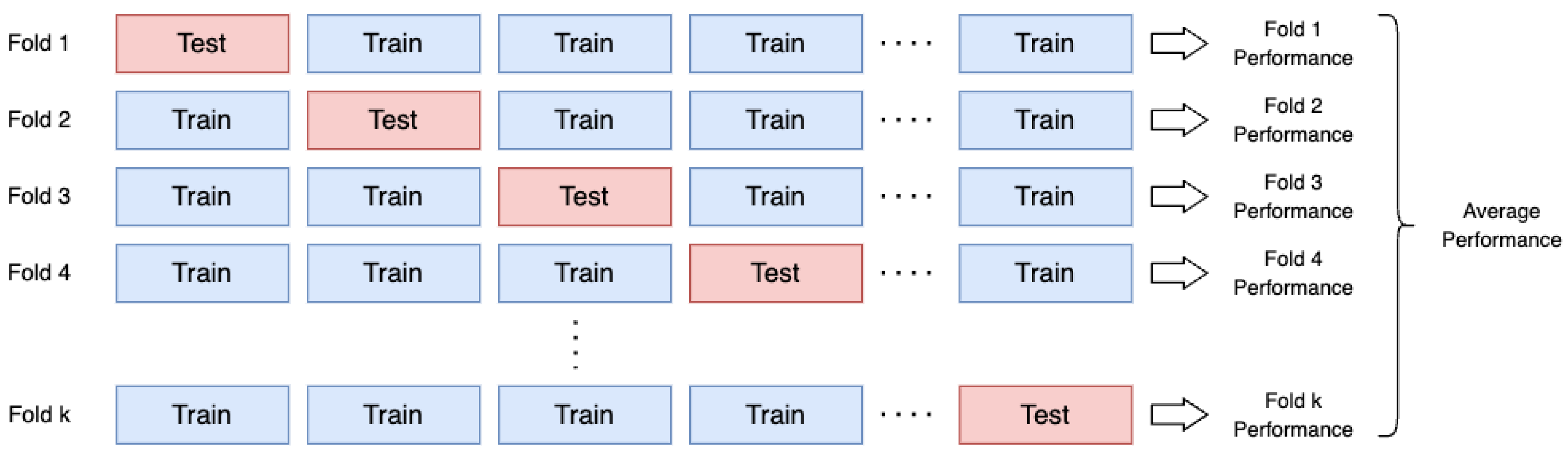
2.2.3. Evaluation Metrics
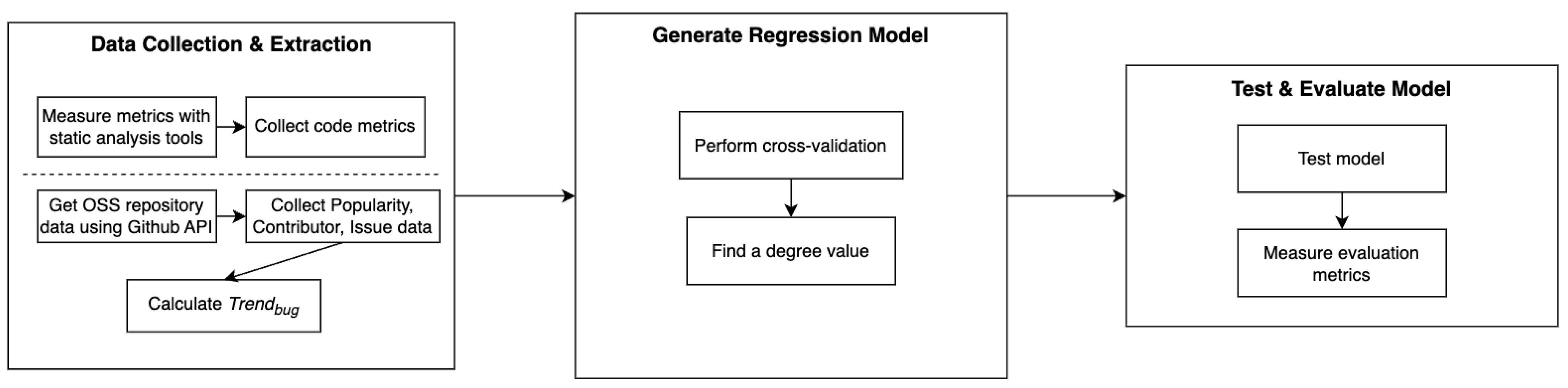
3. Proposed Methodology: Predicting OSS Survivability with Maintenance Activity
3.1. Feature and Target Data
3.2. Data Collection and Extraction
3.2.1. Collecting Feature Data
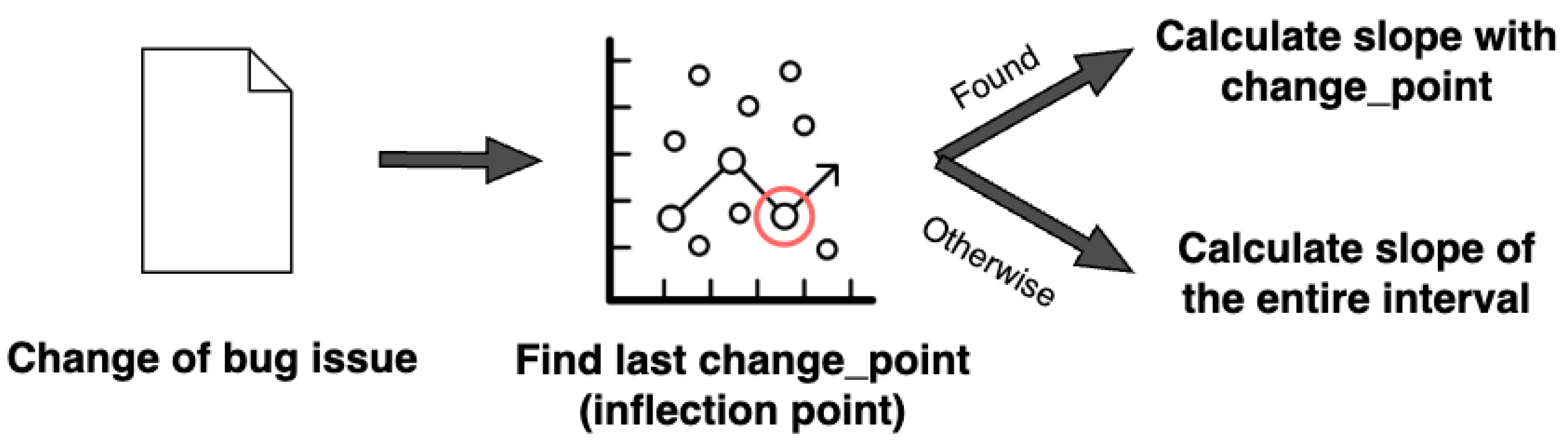
3.2.2. Extracting Target Data
| Algorithm 1 Calculating the slope of the last segment |
| Require:
Use library as if is NA then end if |
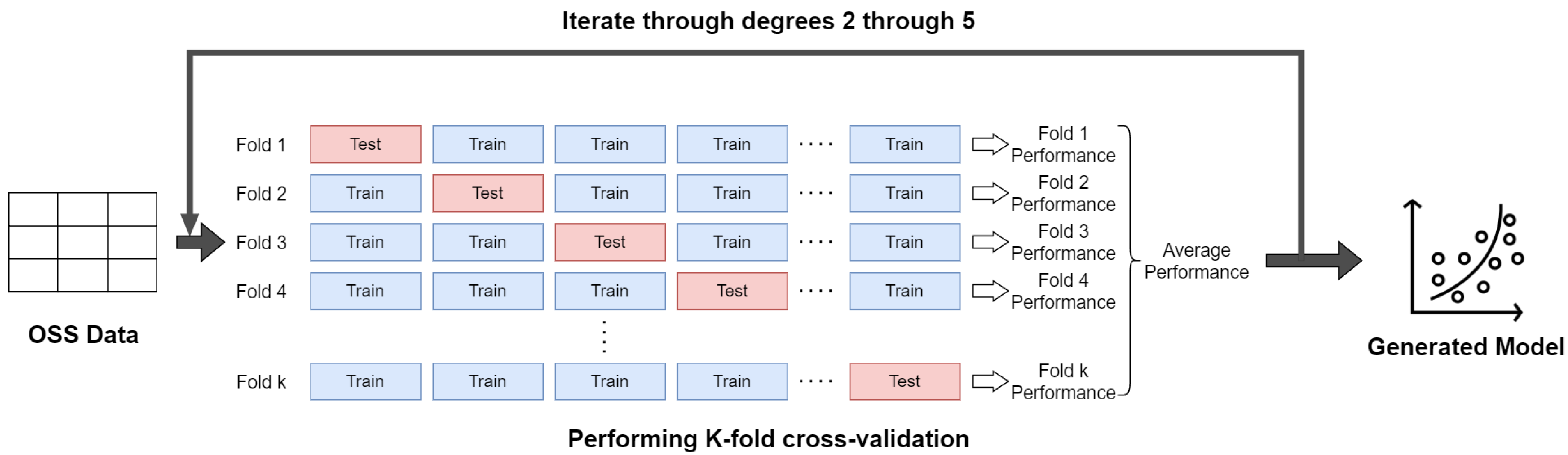
3.3. Generating Regression Model
| Algorithm 2 Generating polynomial model |
|
for to 5 do for to 4 do end for end for return |
4. Results and Analysis
4.1. Target Application
4.2. RQ1: Experiment Results
- normalize.css is over twice as old as CodableCSV, which may have led to a slower decline in community and development activities, resulting in less fluctuation in activities and a lower trend.
- Compared to CodableCSV, normalize.css has approximately 150 times more forks and 10 times more stars. These characteristics contribute to the differences in GitHub issue activities between the OSS projects. CodableCSV has fewer new issues and a similarly low pull request activity. In contrast, normalize.css continues to generate a significant number of issues and, accordingly, more pull requests. Therefore, while CodableCSV might not be maintained further due to a lack of users and contributors, normalize.css seems more likely to find individuals to continue its legacy due to sustained interest.
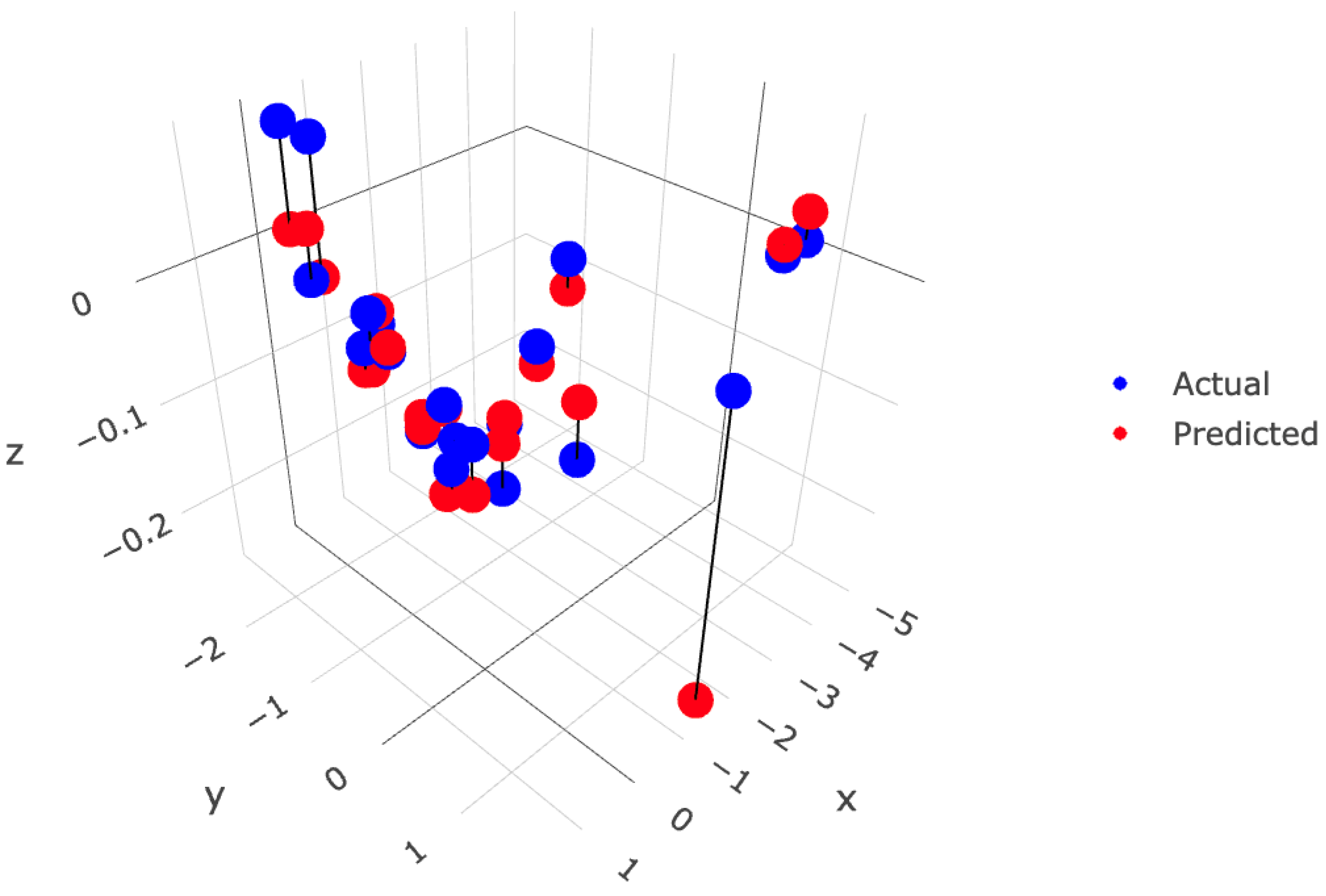
4.3. RQ2: Model Evaluation
4.4. Discussion
4.5. Threats to Validity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- OpenLogic.com. 2022 Open Source Report Overview: Motivations for OSS Adoption. 2022. Available online: https://www.openlogic.com/blog/2022-open-source-report-overview (accessed on 6 March 2023).
- Spinellis, D.; Szyperski, C. How is open source affecting software development? IEEE Softw. 2004, 21, 28–33. [Google Scholar] [CrossRef]
- Lavallée, M.; Robillard, P.N. Why good developers write bad code: An observational case study of the impacts of organizational factors on software quality. In Proceedings of the 2015 IEEE/ACM 37th IEEE International Conference on Software Engineering, Florence, Italy, 16–24 May 2015; Volume 1, pp. 677–687. [Google Scholar] [CrossRef]
- snyk.io. 5 Potential Risks of Open Source Software. 2023. Available online: https://snyk.io/learn/risks-of-open-source-software/ (accessed on 6 March 2023).
- Mansfield-Devine, S. The secure way to use open source. Comput. Fraud. Secur. 2016, 2016, 15–20. [Google Scholar] [CrossRef]
- Goodin, D. Extremely severe bug leaves dizzying number of software and devices vulnerable. ARS Tech. 2016. Available online: https://arstechnica.com/information-technology/2016/02/extremely-severe-bug-leaves- (accessed on 6 March 2023).
- Spinellis, D. Choosing and using open source components. IEEE Softw. 2011, 28, 96. [Google Scholar] [CrossRef]
- Coelho, J.; Valente, M.T.; Silva, L.L.; Shihab, E. Identifying unmaintained projects in github. In Proceedings of the 12th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, Oulu, Finland, 11–12 October 2018; pp. 1–10. [Google Scholar] [CrossRef]
- Zhou, H.; Ravi, H.; Muniz, C.M.; Azizi, V.; Ness, L.; de Melo, G.; Kapadia, M. Gitevolve: Predicting the evolution of github repositories. arXiv 2020, arXiv:2010.04366. [Google Scholar]
- Decan, A.; Constantinou, E.; Mens, T.; Rocha, H. GAP: Forecasting commit activity in git projects. J. Syst. Softw. 2020, 165, 110573. [Google Scholar] [CrossRef]
- Samoladas, I.; Angelis, L.; Stamelos, I. Survival analysis on the duration of open source projects. Inf. Softw. Technol. 2010, 52, 902–922. [Google Scholar] [CrossRef]
- Mari; Eila. The impact of maintainability on component-based software systems. In Proceedings of the 2003 29th Euromicro Conference, Belek-Antalya, Turkey, 1–6 September 2003; pp. 25–32. [Google Scholar] [CrossRef]
- Ostertagová, E. Modelling using polynomial regression. Procedia Eng. 2012, 48, 500–506. [Google Scholar] [CrossRef]
- AbouHawa, M.; Eissa, A. Corner cutting accuracy for thin-walled CFRPC parts using HS-WEDM. Discov. Appl. Sci. 2024, 6, 1–20. [Google Scholar] [CrossRef]
- Oliveira, C.H.X.; Demarqui, F.N.; Mayrink, V.D. A Class of Semiparametric Yang and Prentice Frailty Models. arXiv 2024, arXiv:2403.07650. [Google Scholar]
- Xiong, J.; Sun, Y.; Wang, J.; Li, Z.; Xu, Z.; Zhai, S. Multi-stage equipment optimal configuration of park-level integrated energy system considering flexible loads. Int. J. Electr. Power Energy Syst. 2022, 140, 108050. [Google Scholar] [CrossRef]
- Yang, W.C.; Yang, J.Y.; Kim, R.C. Multiple Quadratic Polynomial Regression Models and Quality Maps for Tensile Mechanical Properties and Quality Indices of Cast Aluminum Alloys according to Artificial Aging Heat Treatment Condition. Adv. Mater. Sci. Eng. 2023, 2023, 7069987. [Google Scholar] [CrossRef]
- Borges, H.; Hora, A.; Valente, M.T. Understanding the factors that impact the popularity of GitHub repositories. In Proceedings of the 2016 IEEE International Conference on Software Maintenance and Evolution (ICSME), Raleigh, NC, USA, 2–7 October 2016; pp. 334–344. [Google Scholar] [CrossRef]
- Borges, H.; Hora, A.; Valente, M.T. Predicting the popularity of github repositories. In Proceedings of the 12th International Conference on Predictive Models and Data Analytics in Software Engineering, Ciudad Real, Spain, 9 September 2016; pp. 1–10. [Google Scholar] [CrossRef]
- Hayes, J.H.; Patel, S.C.; Zhao, L. A metrics-based software maintenance effort model. In Proceedings of the Eighth European Conference on Software Maintenance and Reengineering, Tampere, Finland, 24–26 March 2004; CSMR 2004. pp. 254–258. [Google Scholar] [CrossRef]
- Campbell, G.A. Cognitive complexity: An overview and evaluation. In Proceedings of the 2018 International Conference on Technical Debt, Gothenburg, Sweden, 27–28 May 2018; pp. 57–58. [Google Scholar] [CrossRef]
- Ebert, C.; Cain, J.; Antoniol, G.; Counsell, S.; Laplante, P. Cyclomatic complexity. IEEE Softw. 2016, 33, 27–29. [Google Scholar] [CrossRef]
- Kenmei, B.; Antoniol, G.; Di Penta, M. Trend analysis and issue prediction in large-scale open source systems. In Proceedings of the 2008 12th European Conference on Software Maintenance and Reengineering, Athens, Greece, 1–4 April 2008; pp. 73–82. [Google Scholar]
- Akatsu, S.; Masuda, A.; Shida, T.; Tsuda, K. A Study of Quality Indicator Model of Large-Scale Open Source Software Projects for Adoption Decision-making. Procedia Comput. Sci. 2020, 176, 3665–3672. [Google Scholar] [CrossRef]
- 2023. Available online: https://www.sonarsource.com/products/sonarcloud/ (accessed on 11 October 2023).
- Maulud, D.; Abdulazeez, A.M. A review on linear regression comprehensive in machine learning. J. Appl. Sci. Technol. Trends 2020, 1, 140–147. [Google Scholar] [CrossRef]
- Soper, D.S. Greed is good: Rapid hyperparameter optimization and model selection using greedy k-fold cross validation. Electronics 2021, 10, 1973. [Google Scholar] [CrossRef]
- Ramezan, C.A.; Warner, T.A.; Maxwell, A.E. Evaluation of sampling and cross-validation tuning strategies for regional-scale machine learning classification. Remote Sens. 2019, 11, 185. [Google Scholar] [CrossRef]
- Tanwar, S.; Ramani, T.; Tyagi, S. Dimensionality reduction using PCA and SVD in big data: A comparative case study. In Proceedings of the Future Internet Technologies and Trends: First International Conference, ICFITT 2017, Surat, India, 31 August–2 September 2017; Proceedings 1. Springer: Berlin/Heidelberg, Germany, 2018; pp. 116–125. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Coelho et al. [8] | Zhou et al. [9] | Decan et al. [10] | |
|---|---|---|---|
| Research Background | Analyzes the moment when GitHub projects become inactive to identify potentially unmaintained OSS | Aims to understand the progression and developmental trajectory of GitHub projects | Uses commit activity as an indicator of project health and ongoing engagement |
| Research Objective | Seeks to determine the precise point at which GitHub projects are no longer maintained | Investigates the predictability of GitHub repository evolution over time | Examines the feasibility of predicting future commit activity in Git projects |
| Methodology | Utilizes data analysis of commits, forks, issues, and pull requests to assess project activity | Analyzes past repository activity data to forecast developmental changes | Predicts future commit activities and their timing by analyzing historical data |
| Contribution | Helps users identify unmaintained projects to choose more stable OSS options | Offers insights into project sustainability and the likelihood of continued evolution | Enables project vitality anticipation, guiding project managers and contributors |
| Type | Name | Description | |
|---|---|---|---|
| Feature | User | Star | Interest level of open source users |
| Developer | Contributor | Measure of development and maintenance activities. | |
| Code | LoC (line of code) | Project size | |
| Cognitive complexity | Developers’ code comprehension | ||
| Cyclomatic complexity | |||
| Target | Maintainability | Bug-fixing activity |
| Environmental Factors | Input Data |
|---|---|
| OSS source | KakaoTalk |
| Data collection period | ∼30 September 2023 |
| Total number of OSS | 24 |
| Learning method | Cross-validation |
| Cross-validation iterations (k) | 4 |
| Training data (by 1 iteration) | 18 |
| Testing data (by 1 iteration) | 6 |
| Degree | 2 |
| Optimization algorithm | OLS |
| Metric | Degree 2 | Degree 3 | Degree 4 | Degree 5 |
|---|---|---|---|---|
| Mean of RMSE | 1.3100 | 99.6080 | 83,642.7561 | 33,254,864.4670 |
| Mean of RSE | 0.0101 | 0.0056 | 5.4098 | 2.5035 |
| Name | Age | Number of Contributors | Number of Residual Bugs | Number of Contributors (Last 1 Month) | Number of Commits (Last 1 Month) |
|---|---|---|---|---|---|
| CocoaPods | 12 | 316 | 53 | 3 | 13 |
| CodableCSV | 5 | 11 | 1 | 0 | 0 |
| normalize.css | 12 | 45 | 0 | 0 | 0 |
| Realm SwiftLint | 8 | 354 | 47 | 14 | 72 |
| Sentry Cocoa SDK | 7 | 81 | 46 | 4 | 61 |
| Metric | Fold 1 | Fold 2 | Fold 3 | Fold 4 | Mean |
|---|---|---|---|---|---|
| RMSE | 5.0024 | 0.1810 | 0.0350 | 0.0215 | 1.3100 |
| RSE | 0.0099 | 0.0098 | 0.0142 | 0.0067 | 0.0101 |
| Our Study | Coelho et al. [8] | Zhou et al. [9] | Decan et al. [10] | |
|---|---|---|---|---|
| Feature | Number of Stars and Contributors, LoC, Cognitive complexity, Cyclomatic complexity | Commit, fork, issue, pull request, number of consecutive days without commit, contribution by developer, etc. | 3-tuple (event type, user group, time stamp) event type: any activity that may occur in the repository, such as create, delete, fork, issue, etc. | Previous and recent commit activities of each contributor |
| Target | (Trend of bug-fixing activities) | Release presence in the past month | Analyzes past repository activity data to forecast developmental changes | When contributors are next active |
| Technique | Multiple quadratic polynomial regression | Random forest | End-to-end multitasking sequential deep network | ARIMA (auto-regressive integrated moving average) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, S.; Kwon, R.; Kwon, G. Survivability Prediction of Open Source Software with Polynomial Regression. Appl. Sci. 2024, 14, 2812. https://doi.org/10.3390/app14072812
Park S, Kwon R, Kwon G. Survivability Prediction of Open Source Software with Polynomial Regression. Applied Sciences. 2024; 14(7):2812. https://doi.org/10.3390/app14072812
Chicago/Turabian StylePark, Sohee, Ryeonggu Kwon, and Gihwon Kwon. 2024. "Survivability Prediction of Open Source Software with Polynomial Regression" Applied Sciences 14, no. 7: 2812. https://doi.org/10.3390/app14072812
APA StylePark, S., Kwon, R., & Kwon, G. (2024). Survivability Prediction of Open Source Software with Polynomial Regression. Applied Sciences, 14(7), 2812. https://doi.org/10.3390/app14072812