
An End-to-End Deep Learning Framework for Predicting Hematoma Expansion in Hemorrhagic Stroke Patients from CT Images

 , and
, and
Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset
2.1.1. Data Preprocessing
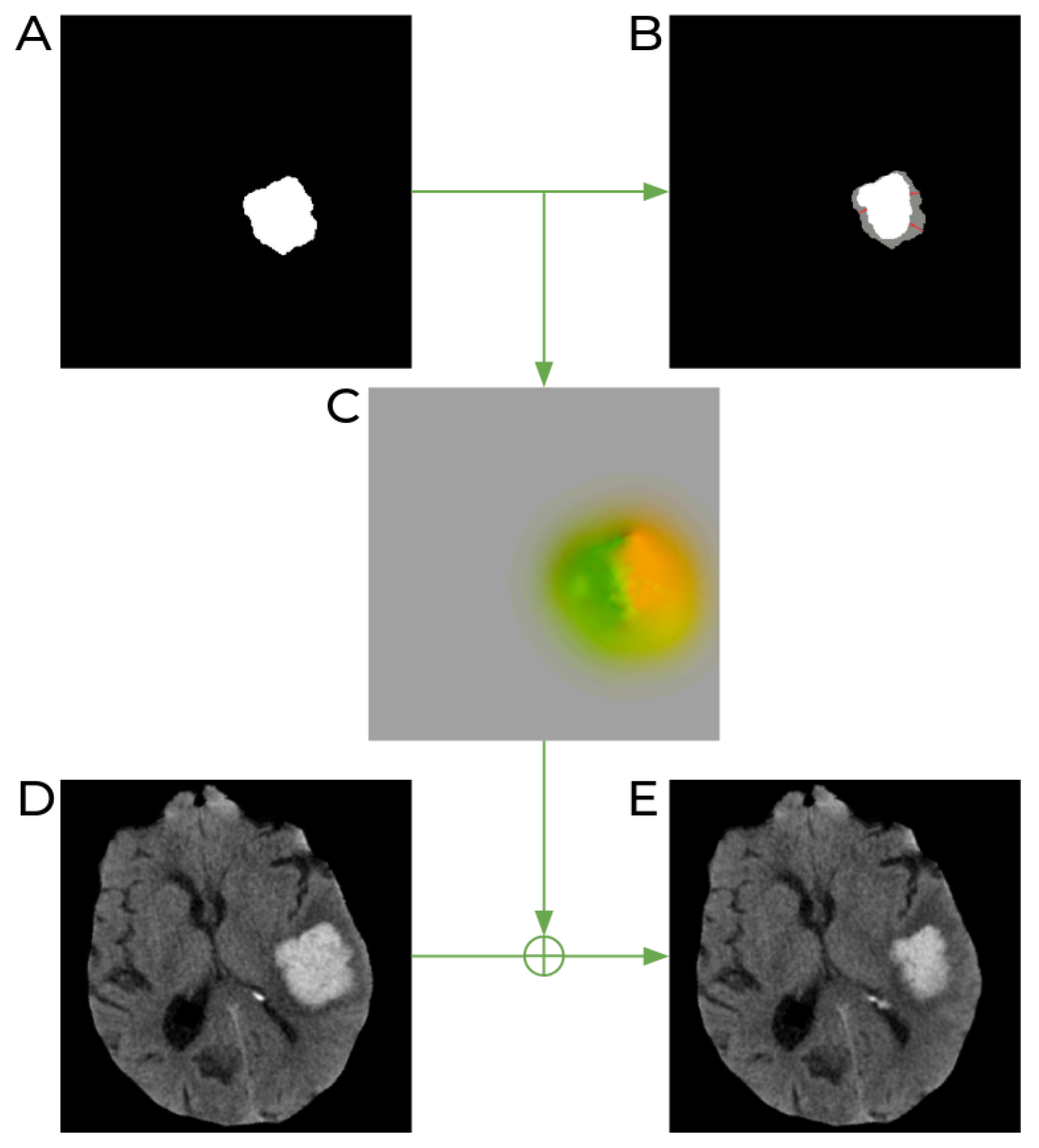
2.1.2. Synthetic Dataset Generation
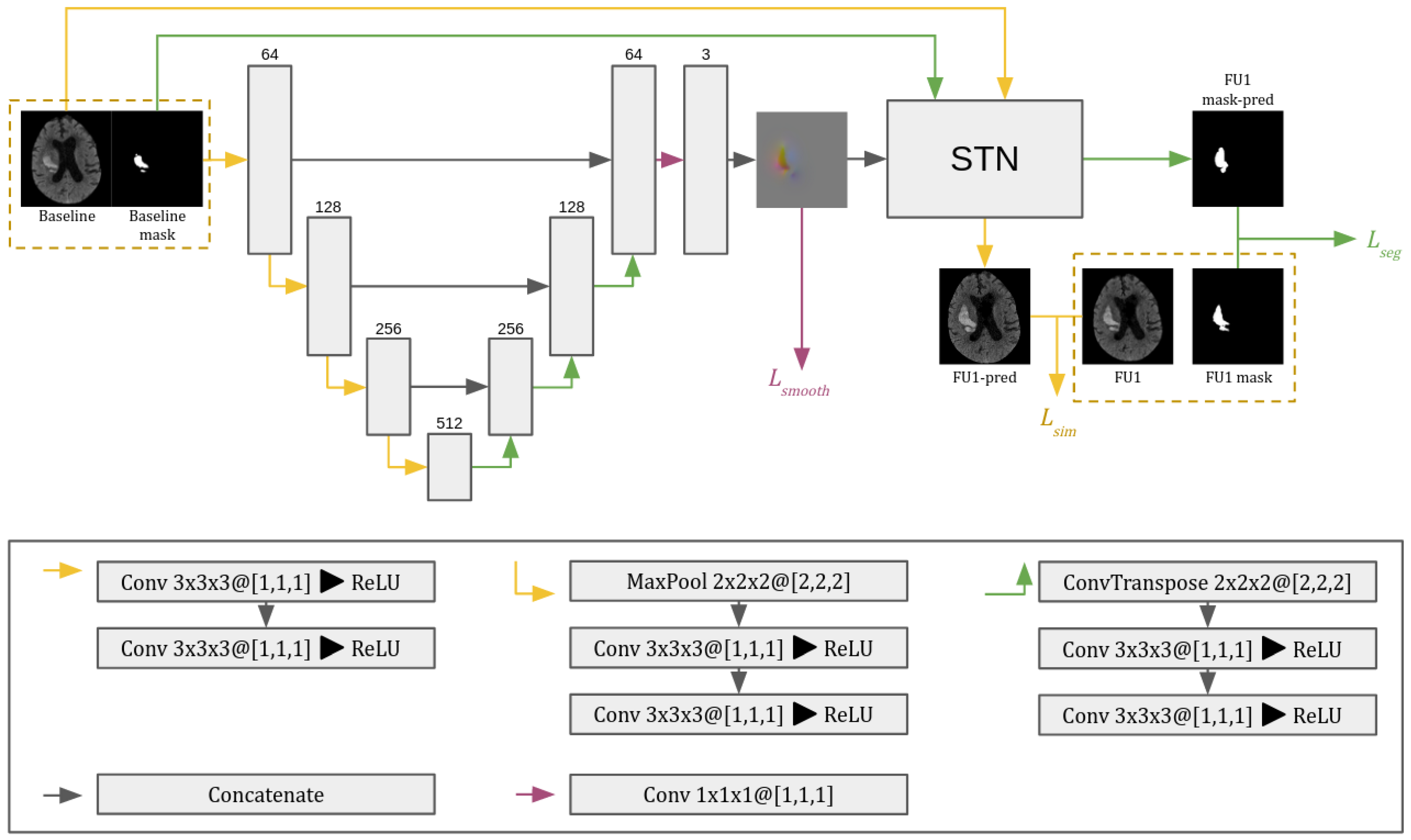
2.2. Method Description
2.3. Patch Sampling
2.4. Network Architecture
2.4.1. Training and Testing Processes
2.4.2. Implementation Details
3. Experimental Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Feigin, V.L.; Stark, B.A.; Johnson, C.O.; Roth, G.A.; Bisignano, C.; Abady, G.G.; Abbasifard, M.; Abbasi-Kangevari, M.; Abd-Allah, F.; Abedi, V.; et al. Global, regional, and national burden of stroke and its risk factors, 1990–2019: A systematic analysis for the Global Burden of Disease Study 2019. Lancet Neurol. 2021, 20, 795–820. [Google Scholar] [CrossRef] [PubMed]
- Norrving, B.; Kissela, B. The global burden of stroke and need for a continuum of care. Neurology 2013, 80, S5–S12. [Google Scholar] [CrossRef]
- Yang, W.S.; Zhang, S.Q.; Shen, Y.Q.; Wei, X.; Zhao, L.B.; Xie, X.F.; Deng, L.; Li, X.H.; Lv, X.N.; Lv, F.J.; et al. Noncontrast Computed Tomography Markers as Predictors of Revised Hematoma Expansion in Acute Intracerebral Hemorrhage. J. Am. Heart Assoc. 2021, 10, e018248. [Google Scholar] [CrossRef]
- Brott, T.; Broderick, J.; Kothari, R.; Barsan, W.; Tomsick, T.; Sauerbeck, L.; Spilker, J.; Duldner, J.; Khoury, J. Early Hemorrhage Growth in Patients with Intracerebral Hemorrhage. Stroke 1997, 28, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Haupenthal, D.; Schwab, S.; Kuramatsu, J.B. Hematoma expansion in intracerebral hemorrhage—The right target? Neurol. Res. Pract. 2023, 5, 36. [Google Scholar] [CrossRef]
- Heit, J.J.; Iv, M.; Wintermarkl, M. Imaging of Intracranial Hemorrhage. J. Stroke 2017, 19, 11–27. [Google Scholar] [CrossRef] [PubMed]
- Demchuk, A.M.; Dowlatshahi, D.; Rodriguez-Luna, D.; Molina, C.A.; Blas, Y.S.; Dzialowski, I.; Kobayashi, A.; Boulanger, J.M.; Lum, C.; Gubitz, G.; et al. Prediction of haematoma growth and outcome in patients with intracerebral haemorrhage using the CT-angiography spot sign (PREDICT): A prospective observational study. Lancet Neurol. 2012, 11, 307–314. [Google Scholar] [CrossRef]
- Nehme, A.; Ducroux, C.; Panzini, M.A.; Bard, C.; Bereznyakova, O.; Boisseau, W.; Deschaintre, Y.; Diestro, J.D.B.; Guilbert, F.; Jacquin, G.; et al. Non-contrast CT markers of intracerebral hematoma expansion: A reliability study. Eur. Radiol. 2022, 32, 6126–6135. [Google Scholar] [CrossRef]
- Morotti, A.; Boulouis, G.; Dowlatshahi, D.; Li, Q.; Shamy, M.; Salman, R.A.S.; Ros, J.; Cordonnier, C.; Goldstein, J.N.; Charidimou, A. Intracerebral haemorrhage expansion: Definitions, predictors, and prevention. Lancet Neurol. 2023, 22, 159–171. [Google Scholar] [CrossRef]
- Morotti, A.; Boulouis, G.; Dowlatshahi, D.; Li, Q.; Barras, C.D.; Delcourt, C.; Yu, Z.; Zheng, J.; Zhou, Z.; Aviv, R.I.; et al. Standards for Detecting, Interpreting, and Reporting Noncontrast Computed Tomographic Markers of Intracerebral Hemorrhage Expansion. Ann. Neurol. 2019, 86, 480–492. [Google Scholar] [CrossRef]
- Greenberg, S.M.; Ziai, W.C.; Cordonnier, C.; Dowlatshahi, D.; Francis, B.; Goldstein, J.N.; Hemphill, J.C.; Johnson, R.; Keigher, K.M.; Mack, W.J.; et al. Guideline for the Management of Patients with Spontaneous Intracerebral Hemorrhage: A Guideline from the American Heart Association/American Stroke Association. Stroke 2022, 53, e282–e361. [Google Scholar] [CrossRef] [PubMed]
- Samak, Z.A.; Clatworthy, P.; Mirmehdi, M. FeMA: Feature matching auto-encoder for predicting ischaemic stroke evolution and treatment outcome. Comput. Med. Imaging Graph. 2022, 99, 102089. [Google Scholar] [CrossRef] [PubMed]
- Wouters, A.; Robben, D.; Christensen, S.; Marquering, H.A.; Roos, Y.B.; van Oostenbrugge, R.J.; van Zwam, W.H.; Dippel, D.W.; Majoie, C.B.; Schonewille, W.J.; et al. Prediction of Stroke Infarct Growth Rates by Baseline Perfusion Imaging. Stroke 2022, 53, 569–577. [Google Scholar] [CrossRef] [PubMed]
- Xiao, T.; Zheng, H.; Wang, X.; Chen, X.; Chang, J.; Yao, J.; Shang, H.; Liu, P. Intracerebral Haemorrhage Growth Prediction Based on Displacement Vector Field and Clinical Metadata. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2021, Strasbourg, France, 27 September–1 October 2021; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 741–751. [Google Scholar] [CrossRef]
- Song, Z.; Guo, D.; Tang, Z.; Liu, H.; Li, X.; Luo, S.; Yao, X.; Song, W.; Song, J.; Zhou, Z. Noncontrast Computed Tomography-Based Radiomics Analysis in Discriminating Early Hematoma Expansion after Spontaneous Intracerebral Hemorrhage. Korean J. Radiol. 2021, 22, 415. [Google Scholar] [CrossRef] [PubMed]
- Al Khalil, Y.; Amirrajab, S.; Lorenz, C.; Weese, J.; Pluim, J.; Breeuwer, M. On the usability of synthetic data for improving the robustness of deep learning-based segmentation of cardiac magnetic resonance images. Med. Image Anal. 2023, 84, 102688. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z.; Tang, J.; Qi, C.; Yao, D.; Liu, C.; Zhan, Y.; Lukasiewicz, T. Cross-domain attention-guided generative data augmentation for medical image analysis with limited data. Comput. Biol. Med. 2024, 168, 107744. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Yang, L.; Zheng, Y. Translating and Segmenting Multimodal Medical Volumes with Cycle- and Shape-Consistency Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 9242–9251. [Google Scholar]
- Zhang, Z.; Deng, H.; Li, X. Unsupervised Liver Tumor Segmentation with Pseudo Anomaly Synthesis. In Proceedings of the SASHIMI 2023: Simulation and Synthesis in Medical Imaging, Vancouver, BC, Canada, 8 October 2023; Lecture Notes in Computer Science. Springer Nature Switzerland: Cham, Switzerland, 2023; pp. 86–96. [Google Scholar] [CrossRef]
- Basaran, B.D.; Qiao, M.; Matthews, P.M.; Bai, W. Subject-Specific Lesion Generation and Pseudo-Healthy Synthesis for Multiple Sclerosis Brain Images. In Proceedings of the SASHIMI 2022: Simulation and Synthesis in Medical Imaging, Singapore, 18 September 2022; Lecture Notes in Computer Science. Springer International Publishing: Cham, Switzerland, 2022; pp. 1–11. [Google Scholar] [CrossRef]
- Wang, Y.; Ji, Y.; Xiao, H. A data augmentation method for fully automatic brain tumor segmentation. Comput. Biol. Med. 2022, 149, 106039. [Google Scholar] [CrossRef] [PubMed]
- Bernal, J.; Valverde, S.; Kushibar, K.; Cabezas, M.; Oliver, A.; Lladó, X. Generating Longitudinal Atrophy Evaluation Datasets on Brain Magnetic Resonance Images Using Convolutional Neural Networks and Segmentation Priors. Neuroinformatics 2021, 19, 477–492. [Google Scholar] [CrossRef]
- Larson, K.E.; Oguz, I. Synthetic Atrophy for Longitudinal Cortical Surface Analyses. Front. Neuroimaging 2022, 1, 861687. [Google Scholar] [CrossRef]
- Abramova, V.; Abramova, V.; Clerigues, A.; Quiles, A.; Figueredo, D.G.; Silva, Y.; Pedraza, S.; Oliver, A.; Lladó, X. Hemorrhagic stroke lesion segmentation using a 3D U-Net with squeeze-and-excitation blocks. Comput. Med. Imaging Graph. 2021, 90, 101908. [Google Scholar] [CrossRef]
- Beare, R.; Lowekamp, B.; Yaniv, Z. Image Segmentation, Registration and Characterization in R with SimpleITK. J. Stat. Softw. 2018, 86, 1–35. [Google Scholar] [CrossRef] [PubMed]
- Yaniv, Z.; Lowekamp, B.C.; Johnson, H.J.; Beare, R. SimpleITK Image-Analysis Notebooks: A Collaborative Environment for Education and Reproducible Research. J. Digit. Imaging 2017, 31, 290–303. [Google Scholar] [CrossRef] [PubMed]
- Lowekamp, B.C.; Chen, D.T.; Ibáñez, L.; Blezek, D. The Design of SimpleITK. Front. Neuroinform. 2013, 7, 45. [Google Scholar] [CrossRef] [PubMed]
- Yushkevich, P.A.; Pluta, J.; Wang, H.; Wisse, L.E.; Das, S.; Wolk, D. IC-P-174: Fast Automatic Segmentation of Hippocampal Subfields and Medial Temporal Lobe Subregions In 3 Tesla and 7 Tesla T2-Weighted MRI. Alzheimer’s Dement. 2016, 12, 126–127. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; De Vito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the NIPS-W, Long Beach, CA, USA, 4–9 December 2017; pp. 1–4. [Google Scholar]
- Kuang, Z.; Deng, X.; Yu, L.; Wang, H.; Li, T.; Wang, S. Ψ-Net: Focusing on the border areas of intracerebral hemorrhage on CT images. Comput. Methods Programs Biomed. 2020, 194, 105546. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
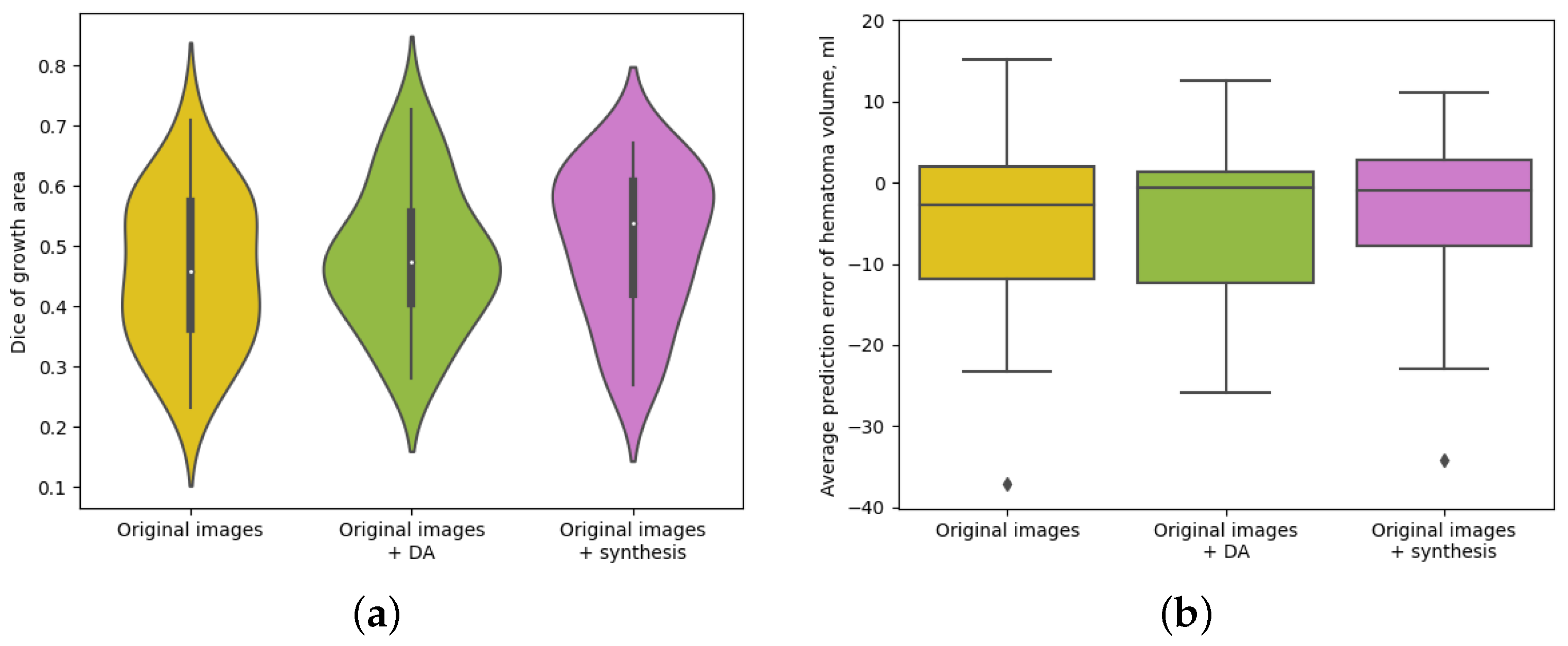
| Dice of Growth (↑) | AEV, mL (↔) | AAEV, mL (↓) | |
|---|---|---|---|
| Original images | 0.458 ± 0.125 | 9.20 ± 8.96 | |
| Original images + DA | 0.481 ± 0.118 | 8.15 ± 7.77 | |
| Original images + synthesis | 0.506 ± 0.120 * | * | 8.49 ± 8.85 |
| Xiao et al. [14] | 0.467 | 4.80 | 10.50 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abramova, V.; Oliver, A.; Salvi, J.; Terceño, M.; Silva, Y.; Lladó, X. An End-to-End Deep Learning Framework for Predicting Hematoma Expansion in Hemorrhagic Stroke Patients from CT Images. Appl. Sci. 2024, 14, 2708. https://doi.org/10.3390/app14072708
Abramova V, Oliver A, Salvi J, Terceño M, Silva Y, Lladó X. An End-to-End Deep Learning Framework for Predicting Hematoma Expansion in Hemorrhagic Stroke Patients from CT Images. Applied Sciences. 2024; 14(7):2708. https://doi.org/10.3390/app14072708
Chicago/Turabian StyleAbramova, Valeriia, Arnau Oliver, Joaquim Salvi, Mikel Terceño, Yolanda Silva, and Xavier Lladó. 2024. "An End-to-End Deep Learning Framework for Predicting Hematoma Expansion in Hemorrhagic Stroke Patients from CT Images" Applied Sciences 14, no. 7: 2708. https://doi.org/10.3390/app14072708
APA StyleAbramova, V., Oliver, A., Salvi, J., Terceño, M., Silva, Y., & Lladó, X. (2024). An End-to-End Deep Learning Framework for Predicting Hematoma Expansion in Hemorrhagic Stroke Patients from CT Images. Applied Sciences, 14(7), 2708. https://doi.org/10.3390/app14072708