

Document Retrieval System for Biomedical Question Answering


Abstract
Featured Application
Abstract
1. Introduction
2. Materials and Methods
2.1. Ranking Models
2.1.1. Vector Space Model
2.1.2. Okapi BM25
2.1.3. Bayesian Smoothing with Dirichlet Priors
2.1.4. Sequential Dependence Model
2.2. QA System Components
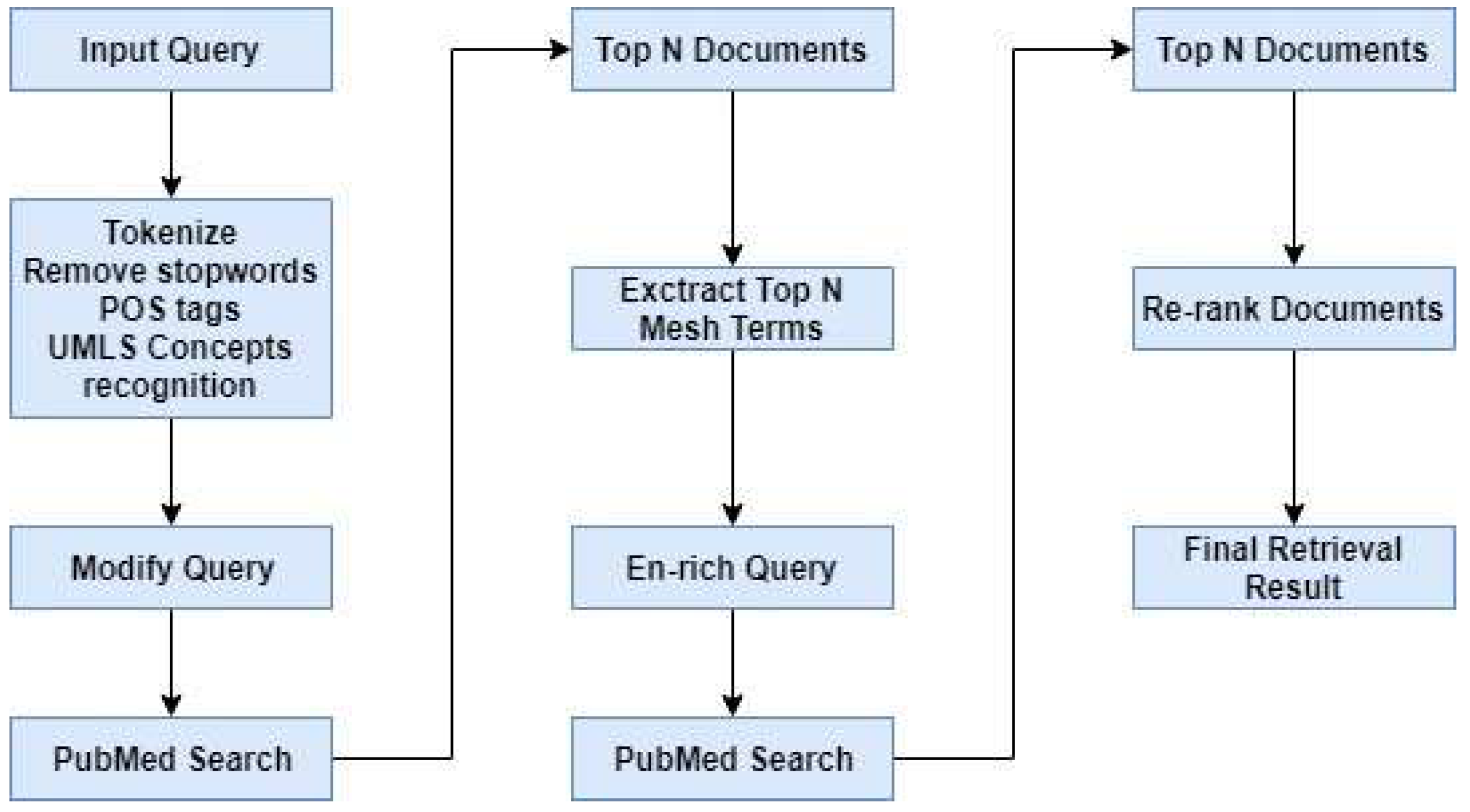
- Question Analysis
- Document Retrieval
- Answer Extraction
2.2.1. Question Analysis
- Tokenization: involves breaking down a sequence of text into smaller units, known as tokens.
- Stemming: a process that substitutes all word variations with the word’s single stem or root. This typically includes removing any attached suffixes and prefixes from words. For instance, the words “reading”, “reader”, and “reads” are transformed into the root “read”.
- Stop-words are a series of commonly used words in a language. They can be safely ignored without compromising the meaning of the sentence. Examples of stop words in English include “a”, “the”, “is”, “our”, etc. Eliminating these terms helps increase the accuracy of the findings.
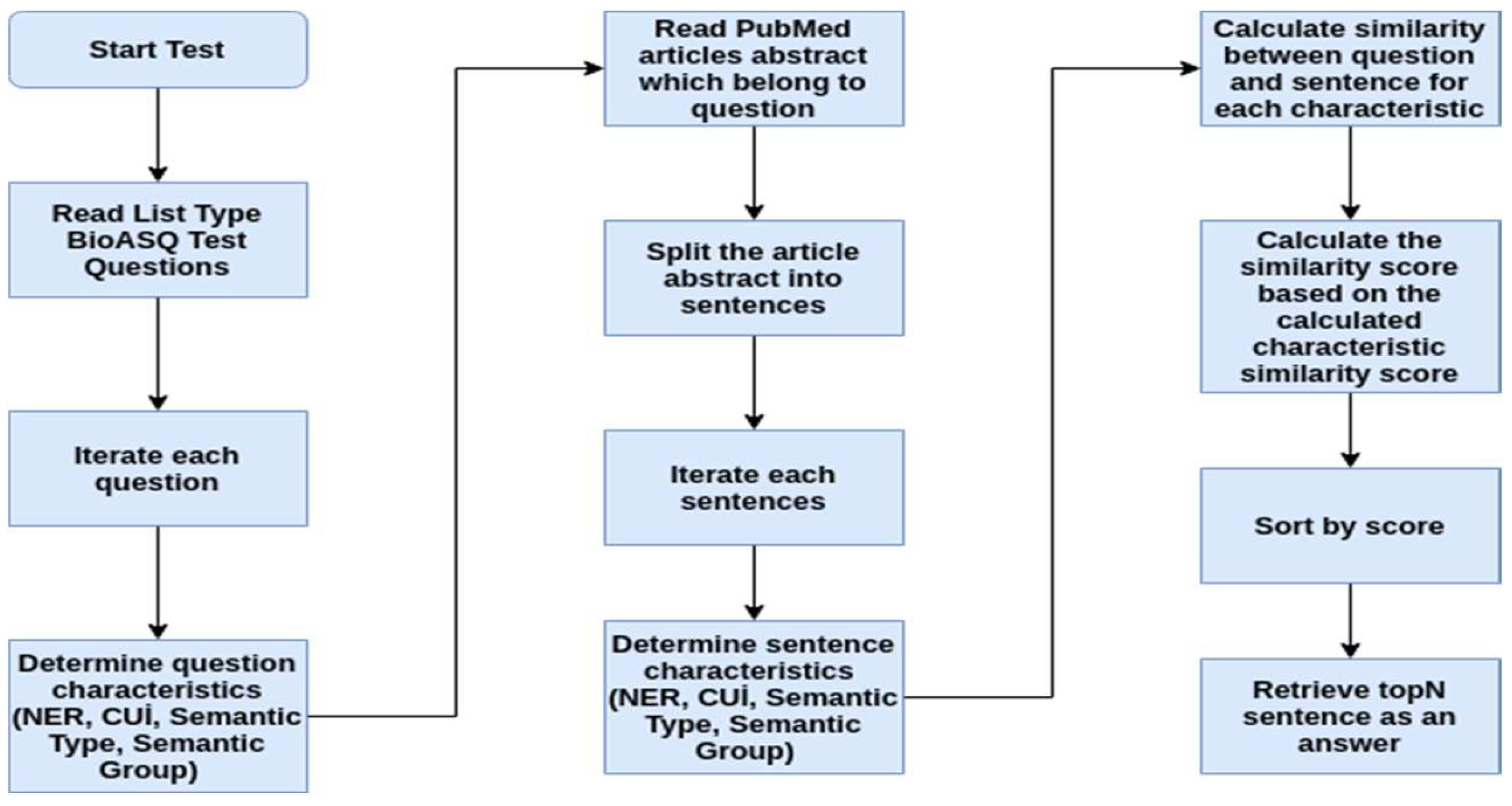
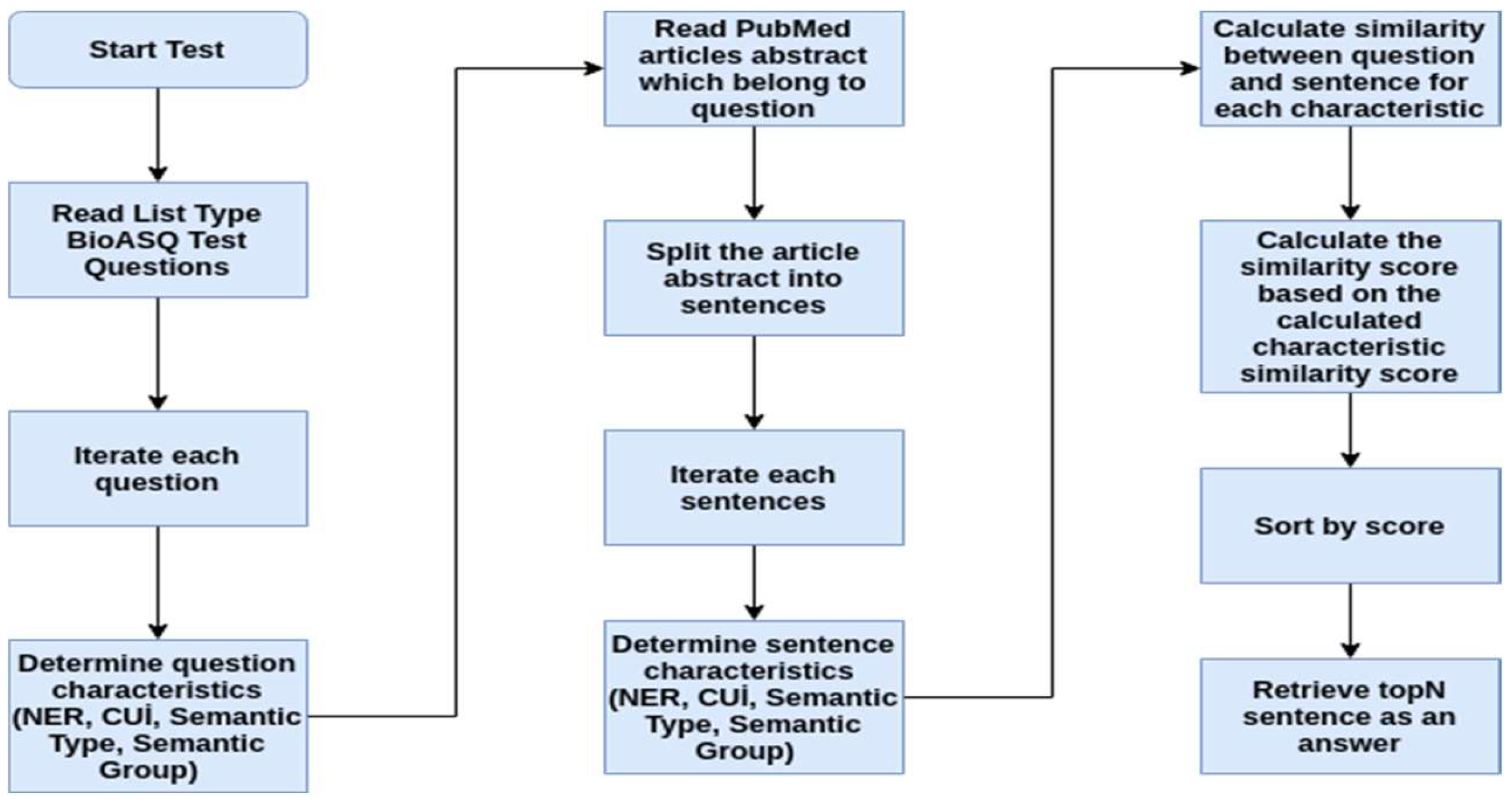
2.2.2. Document Retrieval
2.2.3. Answer Extraction
Named Entity Recognition (NER)
UMLS Concept Unique Identifiers (CUI)
Semantic Types and Groups
- Semantic Type Sentence: mamm, aapp, qlco, bsoj, aapp, rcpt
- Semantic Group Sentence: LIVB, CHEM, CONC, ANAT, CHEM, CHEM
Similarity Calculation
- Query: Which are the different isoforms of the mammalian Notch receptor?
- NER Sentence: SO, TAXON, PROTEIN, GENE_OR_GENE_PRODUCT
- CUI Sentence: C0024660, C0597298, C1705242, C1235660, C0597357
- Semantic Type Sentence: mamm, aapp, qlco, bsoj, aapp, rcpt
- Semantic Group Sentence: LIVB, CHEM, CONC, ANAT, CHEM, CHEM
3. Results
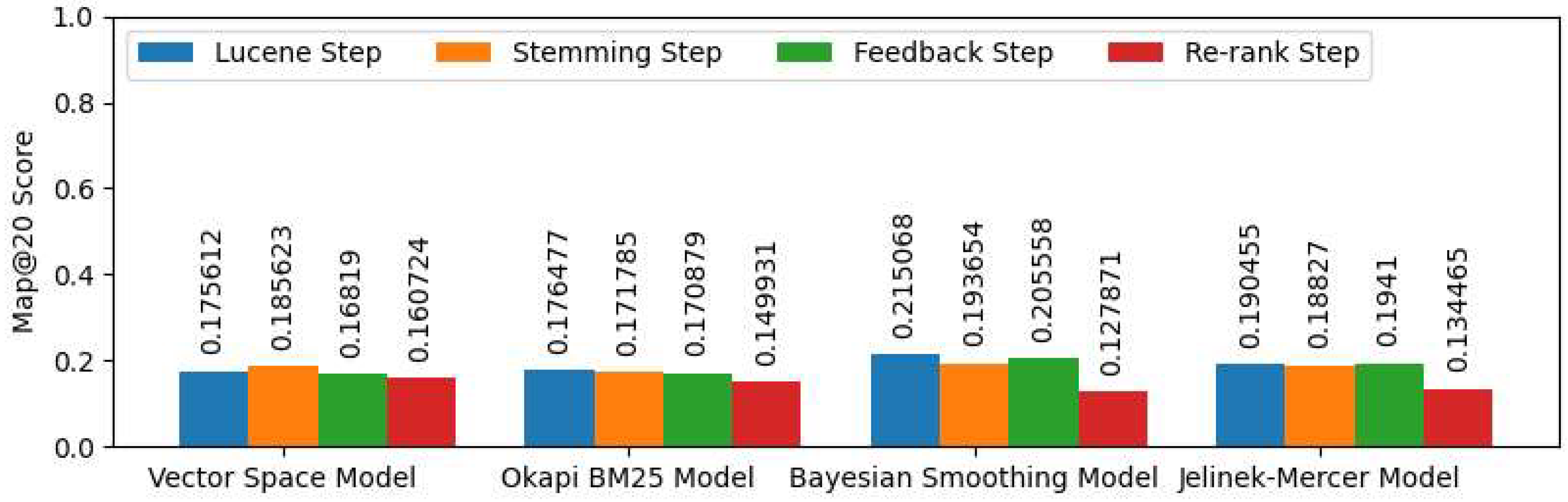
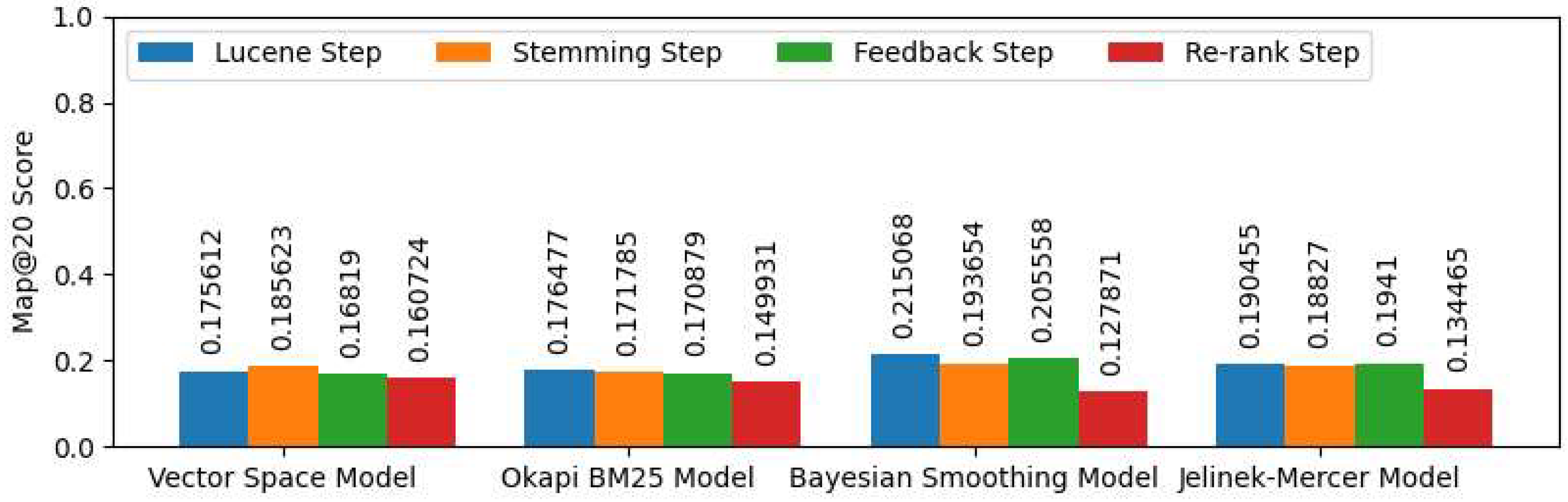
3.1. Document Retrieval Component Evaluation
- Dirichlet similarity method with expanding query with MESH terms produces the best performance for 100 questions and MAP@20.
- Expanded query with noun/noun phrases increases the performance.
- Expanded query with mesh terms increases the performance.
- Expanded query with stemming terms has a better performance than expanded query with UMLS concept.
- In general, expanded query with the UMLS concept decreases the system performance.
3.2. Answer Extraction Evaluation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Athenikos, S.J.; Han, H. Biomedical question answering: A survey. Comput. Methods Programs Biomed. 2010, 99, 1–24. [Google Scholar] [CrossRef] [PubMed]
- Rinaldi, F.; Dowdall, J.; Schneider, G.; Persidis, A. Answering questions in the genomics domain. In Proceedings of the ACL 2004 Workshop on Question Answering in Restricted Domains, Barcelona, Spain, 25 July 2004; pp. 46–53. [Google Scholar]
- Zweigenbaum, P. Question answering in biomedicine. In Proceedings of the Workshop on Natural Language Processing for Question Answering, Budapest, Hungary, 14 April 2003. [Google Scholar]
- Tsatsaronis, G.; Balikas, G.; Malakasiotis, P.; Partalas, I.; Zschunke, M.; Alvers, M.R.; Weissenborn, D.; Krithara, A.; Petridis, S.; Polychronopoulos, D.; et al. An overview of the BIOASQ large-scale biomedical semantic indexing and question answering competition. BMC Bioinform. 2015, 16, 138. [Google Scholar] [CrossRef] [PubMed]
- Jin, Z.-X.; Zhang, B.-W.; Fang, F.; Zhang, L.-L.; Yin, X.-C. A Multi-strategy Query Processing Approach for Biomedical Question Answering: USTB_PRIR at BioASQ 2017 Task 5B. BioNLP 2017, 2017, 373–380. [Google Scholar]
- Mao, Y.; Wei, C.H.; Lu, Z. NCBI at the 2014 BioASQ challenge task: Large-scale biomedical semantic indexing and question answering. CEUR Workshop Proc. 2014, 1180, 1319–1327. [Google Scholar]
- Aronson, R.; Lang, F.-M. An overview of MetaMap: Historical perspective and recent advances. J. Am. Med. Inform. Assoc. 2010, 13, 229–236. [Google Scholar] [CrossRef] [PubMed]
- Neves, M. HPI in-memory-based database system in Task 2b of BioASQ. In Proceedings of the CEUR Workshop Proceedings, Sheffield, UK, 15–18 September 2014. [Google Scholar]
- Yang, Z.; Gupta, N.; Sun, X.; Xu, D.; Zhang, C.; Nyberg, E. Learning to answer biomedical factoid & list questions: OAQA at BioASQ 3B. In Proceedings of the CEUR Workshop Proceedings, Toulouse, France, 8–11 September 2015. [Google Scholar]
- Zhang, Z.J.; Liu, T.T.; Zhang, B.W.; Li, Y.; Zhao, C.H.; Feng, S.H.; Yin, X.C.; Zhou, F. A generic retrieval system for biomedical literatures: USTB at BioASQ2015 Question Answering Task. In Proceedings of the CEUR Workshop Proceedings, Toulouse, France, 8–11 September 2015. [Google Scholar]
- Peng, S.; You, R.; Xie, Z.; Wang, B.; Zhang, Y.; Zhu, S. The Fudan participation in the 2015 BioASQ Challenge: Large-scale biomedical semantic indexing and question answering. In Proceedings of the CEUR Workshop Proceedings, Toulouse, France, 8–11 September 2015. [Google Scholar]
- Yenala, H.; Kamineni, A.; Shrivastava, M.; Chinnakotla, M. IIITH at BioASQ challange 2015 task 3b: Bio-medical question answering system. In Proceedings of the CEUR Workshop Proceedings, Toulouse, France, 8–11 September 2015. [Google Scholar]
- Choi, S.; Choi, J. Classification and retrieval of biomedical literatures: SNUMedinfo at CLEF QA track BioASQ 2014. In Proceedings of the Question Answering Lab at CLEF, Sheffield, UK, 15–18 September 2014; pp. 1283–1295. [Google Scholar]
- Choi, S. SNUMedinfo at CLEF QA track BioASQ 2015. In Proceedings of the CEUR Workshop Proceedings, Toulouse, France, 8–11 September 2015. [Google Scholar]
- Lee, H.-G.; Kim, M.; Kim, H.; Kim, J.; Kwon, S.; Seo, J.; Choi, J.; Kim, Y.-R. KSAnswer: Question-answering System of Kangwon National University and Sogang University in the 2016 BioASQ Challenge. In Proceedings of the Fourth BioASQ Workshop, Berlin, Germany, 12–13 August 2016; pp. 45–49. [Google Scholar]
- Dimitriadis, D.; Tsoumakas, G. Word embeddings and external resources for answer processing in biomedical factoid question answering. J. Biomed. Inform. 2019, 92, 103–118. [Google Scholar] [CrossRef] [PubMed]
- Brokos, G.; Liosis, P.; McDonald, R.; Pappas, D.; Ion, A. AUEB at BioASQ 6: Document and Snippet Retrieval. In Proceedings of the 6th BioASQ Workshop A Challenge on Large-Scale Biomedical Semantic Indexing and Question Answering, Brussels, Belgium, 1 November 2018; pp. 30–39. [Google Scholar]
- Ma, J.; Korotkov, I.; Yang, Y.; Hall, K.B.; McDonald, R.T. Zero-shot Neural Passage Retrieval via Domain-targeted Synthetic Question Generation. arXiv 2020, arXiv:2004.14503. [Google Scholar]
- Pappas, D.; McDonald, R.; Brokos, G.-I.; Androutsopoulos, I. AUEB at BioASQ 7: Document and Snippet Retrieval. In Proceedings of the Seventh BioASQ Workshop: A Challenge on Large-Scale Biomedical Semantic Indexing and Question Answering, Würzburg, Germany, 20 September 2019. [Google Scholar]
- Almeida, T.; Jonker, R.; Poudel, R.; Silva, J.; Matos, S. Two-stage IR with synthetic training and zero-shot answer generation at BioASQ 11. In Proceedings of the CLEF2023: Conference and Labs of the Evaluation Forum, Thessaloniki, Greece, 18–21 September 2023. [Google Scholar]
- Ateia, S.; Kruschwitz, U. Is ChatGPT a Biomedical Expert? In Proceedings of the BioASQWorkshop at CLEF 2023, Thessaloniki, Greece, 18–21 September 2023.
- Rosso-Mateus, A.; Muñoz-Serna, L.A.; Montes-y-Gómez, M.; González, F.A. Deep Metric Learning for Effective Passage Retrieval in the BioASQ Challenge. In Proceedings of the CLEF2023: Conference and Labs of the Evaluation Forum, Thessaloniki, Greece, 18–21 September 2023. [Google Scholar]
- Nentidis, A.; Katsimpras, G.; Krithara, A.; Lima López, S.; Farr, E.; Gasco, L.; Krallinger, M.; Paliouras, G. Overview of bioasq 2023: The eleventh bioasq challenge on large-scale biomedical semantic indexing and question answering. In Proceedings of the International Conference of the Cross-Language Evaluation Forum for European Languages, Thessaloniki, Greece, 8–21 September 2023. [Google Scholar]
- Shin, A.; Jin, Q.; Lu, Z. Multi-stage Literature Retrieval System Trained by PubMed Search Logs for Biomedical Question Answering. In Proceedings of the CLEF2023: Conference and Labs of the Evaluation Forum, Thessaloniki, Greece, 18–21 September 2023. [Google Scholar]
- Salton, G.; Wong, A.; Yang, C.S. A Vector Space Model for Automatic Indexing. Commun. ACM 1975, 18, 613–620. [Google Scholar] [CrossRef]
- Robertson, S.; Jones, K.S. Simple, Proven Approaches to Text Retrieval; University of Cambridge, Computer Laboratory: Cambridge, UK, 1994. [Google Scholar]
- Zhai, C.; Lafferty, J. A study of smoothing methods for language models applied to Ad Hoc information retrieval. In Proceedings of the 24th Annual İnternational ACM SIGIR Conference on Research and Development in İnformation Retrieval—SIGIR ‘01, New Orleans, LA, USA, 9–13 September 2001; pp. 334–342. [Google Scholar]
- Metzler, D.; Croft, W.B. A Markov random field model for term dependencies. In Proceedings of the 28th Annual İnternational ACM SIGIR Conference on Research and Development in İnformation Retrieval SIGIR 05, Salvador, Brazil, 15–19 August 2005; p. 472. [Google Scholar]
- Natural Language Toolkit. Available online: https://www.nltk.org/ (accessed on 13 February 2024).
- Aronson, R. Effective mapping of biomedical text to the UMLS Metathesaurus: The MetaMap program. In Proceedings of the AMIA Symposium, Washington, DC, USA, 3–7 November 2001; p. 17. [Google Scholar]
- Medical Subject Headings. Available online: https://www.nlm.nih.gov/mesh/meshhome.html (accessed on 13 February 2024).
- scispaCy. Available online: https://spacy.io/universe/project/scispacy (accessed on 13 February 2024).
- Industrial-Strength Natural Language Processing. Available online: https://spacy.io/ (accessed on 13 February 2024).
- BioASQ Participants Area Task 10b: Test Results of Phase A. Available online: http://participants-area.bioasq.org/results/10b/phaseA/ (accessed on 13 February 2024).
- BioASQ Participants Area Task 11b: Test Results of Phase A. Available online: http://participants-area.bioasq.org/results/11b/phaseA/ (accessed on 13 February 2024).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Description |
|---|---|
| en_core_sci_md | A full spaCy pipeline for biomedical data with a ~360 k vocabulary and 50 k word vectors. |
| en_ner_craft_md | A spaCy NER model trained on the CRAFT corpus. |
| en_ner_jnlpba_md | A spaCy NER model trained on the JNLPBA corpus. |
| en_ner_bc5cdr_md | A spaCy NER model trained on the BC5CDR corpus. |
| en_ner_bionlp13cg_md | A spaCy NER model trained on the BIONLP13CG corpus. |
| Text | NER Label | NER Packages |
|---|---|---|
| isoforms | SO | en_ner_craft_md |
| mammalian Notch | TAXON | en_ner_craft_md |
| mammalian Notch receptor | PROTEIN | en_ner_jnlpba_md |
| Notch receptor | GENE_OR_GENE_PRODUCT | en_ner_bionlp13cg_md |
| Canonical Name | CUI | SemTypes |
|---|---|---|
| Mammals | C0024660 | ‘mamm’ |
| Protein Isoforms | C0597298 | ‘aapp’ |
| Different | C1705242 | ‘qlco’ |
| Notch | C1235660 | ‘bsoj’ |
| receptor | C0597357 | ‘aapp’, ‘rcpt’ |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| First Model | 0.274064906 | 0.245539628 | 0.231359422 |
| Second Model | 0.332755776 | 0.284086961 | 0.275641907 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| First Model | 0.242457733 | 0.390003171 | 0.27177337 |
| Second Model | 0.277873399 | 0.435362065 | 0.310362465 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| Simsentence(q,s) | 0.325974658869396 | 0.279680589455593 | 0.265812642336408 |
| Simcui(q,s) | 0.342272347535505 | 0.281147607835646 | 0.281588644081949 |
| Simner(q,s) | 0.212858535226956 | 0.191798144966908 | 0.172229828518593 |
| Simsemgroup(q,s) | 0.215350877192982 | 0.203630576246875 | 0.188343480739234 |
| Simsemtype(q,s) | 0.292933723196881 | 0.249584375421712 | 0.240911648270888 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| Simsentence(q,s) | 0.289389042782395 | 0.424083519409149 | 0.309619576459582 |
| Simcui(q,s) | 0.302934938705673 | 0.39415030999297 | 0.319192207483652 |
| Simner(q,s) | 0.207102918113998 | 0.30844905664532 | 0.220466137401454 |
| Simsemgroup(q,s) | 0.211441982148353 | 0.338489889693882 | 0.236935883722674 |
| Simsemtype(q,s) | 0.252875243664717 | 0.396181088045895 | 0.280014580422107 |
| F1-Score | Weight | |
|---|---|---|
| Simsentence(q,s) | 0.265812642336408 | 0.231365501795192 |
| Simcui(q,s) | 0.281588644081949 | 0.245097062973383 |
| Simner(q,s) | 0.172229828518593 | 0.14991025388805 |
| Simsemgroup(q,s) | 0.188343480739234 | 0.163935708806267 |
| Simsemtype(q,s) | 0.240911648270888 | 0.209691472537108 |
| Total | 1.14888624394707 | 1 |
| F1-Score | Weight | |
|---|---|---|
| Simsentence(q,s) | 0.309619576459582 | 0.226623586325691 |
| Simcui(q,s) | 0.319192207483652 | 0.233630197464604 |
| Simner(q,s) | 0.220466137401454 | 0.16136843571909 |
| Simsemgroup(q,s) | 0.236935883722674 | 0.173423335541216 |
| Simsemtype(q,s) | 0.280014580422107 | 0.204954444949398 |
| Total | 1.36622838548947 | 1 |
| Weight | |
|---|---|
| Simsentence(q,s) | 0.229 |
| Simcui(q,s) | 0.2394 |
| Simner(q,s) | 0.1556 |
| Simsemgroup(q,s) | 0.1687 |
| Simsemtype(q,s) | 0.2073 |
| Total | 1 |
| Expanding with MESH Terms | ||||
|---|---|---|---|---|
| MAP@20 | Precision | Recall | F-Score | |
| Stemming Step | 0.185622998 | 0.1365 | 0.313774059 | 0.170787548 |
| Lucene Step | 0.175612249 | 0.146 | 0.324434555 | 0.180734369 |
| Feedback Step | 0.168189783 | 0.133 | 0.279311939 | 0.162600221 |
| Re-rank Step | 0.160724312 | 0.133 | 0.288003006 | 0.163057893 |
| Expanding with Nouns + MESH terms | ||||
| Re-rank Step | 0.195301138 | 0.147 | 0.326268938 | 0.18126985 |
| Feedback Step | 0.187320721 | 0.1455 | 0.305923523 | 0.177812071 |
| Stemming Step | 0.185622998 | 0.1365 | 0.313774059 | 0.170787548 |
| Lucene Step | 0.181111162 | 0.1445 | 0.324625142 | 0.179234937 |
| Expanding with UMLS Concepts + MESH terms | ||||
| Stemming Step | 0.185622998 | 0.1365 | 0.313774059 | 0.170787548 |
| Feedback Step | 0.146463232 | 0.1225 | 0.258905059 | 0.147602393 |
| Re-rank Step | 0.124201021 | 0.1005 | 0.222639395 | 0.123955225 |
| Lucene Step | 0.106554958 | 0.091 | 0.190680698 | 0.108733966 |
| Expanding with MESH Terms | ||||
|---|---|---|---|---|
| MAP@20 | Precision | Recall | F-Score | |
| Lucene Step | 0.176476534 | 0.1385 | 0.317339643 | 0.172960292 |
| Stemming Step | 0.17178517 | 0.1285 | 0.294956484 | 0.161146813 |
| Feedback Step | 0.170879462 | 0.1425 | 0.304541115 | 0.174698454 |
| Re-rank Step | 0.149931031 | 0.126 | 0.282706299 | 0.155884138 |
| Expanding with Nouns + MESH terms | ||||
| Lucene Step | 0.180069828 | 0.135 | 0.309152083 | 0.168453201 |
| Feedback Step | 0.175457903 | 0.1415 | 0.297708004 | 0.1739497 |
| Stemming Step | 0.17178517 | 0.1285 | 0.294956484 | 0.161146813 |
| Re-rank Step | 0.13464953 | 0.1255 | 0.290344766 | 0.157827754 |
| Expanding with UMLS Concepts + MESH terms | ||||
| Stemming Step | 0.17178517 | 0.1285 | 0.294956484 | 0.161146813 |
| Feedback Step | 0.112866675 | 0.1 | 0.205279922 | 0.119236051 |
| Re-rank Step | 0.087949646 | 0.083 | 0.189413613 | 0.102009508 |
| Lucene Step | 0.087049388 | 0.077 | 0.164406585 | 0.09273419 |
| Expanding with MESH Terms | ||||
|---|---|---|---|---|
| MAP@20 | Precision | Recall | F-Score | |
| Lucene Step | 0.215067938 | 0.1675 | 0.378670918 | 0.207030739 |
| Feedback Step | 0.205558147 | 0.1605 | 0.338886485 | 0.197606624 |
| Stemming Step | 0.193653656 | 0.145 | 0.334537667 | 0.182408129 |
| Re-rank Step | 0.127871192 | 0.1175 | 0.258922228 | 0.144890457 |
| Expanding with Nouns + MESH terms | ||||
| Feedback Step | 0.212765534 | 0.1615 | 0.352054511 | 0.199110331 |
| Lucene Step | 0.211291773 | 0.1555 | 0.347947469 | 0.193621451 |
| Stemming Step | 0.193653656 | 0.145 | 0.334537667 | 0.182408129 |
| Re-rank Step | 0.128392227 | 0.109 | 0.244808347 | 0.13491335 |
| Expanding with UMLS Concepts + MESH terms | ||||
| Stemming Step | 0.193653656 | 0.145 | 0.334537667 | 0.182408129 |
| Feedback Step | 0.150857459 | 0.1315 | 0.272468562 | 0.158882982 |
| Lucene Step | 0.131512942 | 0.1125 | 0.239383041 | 0.136570818 |
| Re-rank Step | 0.063413178 | 0.066 | 0.172869037 | 0.083156168 |
| Expanding with MESH Terms | ||||
|---|---|---|---|---|
| MAP@20 | Precision | Recall | F-Score | |
| Feedback Step | 0.194099982 | 0.153 | 0.320348831 | 0.186614216 |
| Lucene Step | 0.190455137 | 0.146 | 0.330585442 | 0.180809385 |
| Stemming Step | 0.188270263 | 0.139 | 0.318224318 | 0.174046006 |
| Re-rank Step | 0.134464863 | 0.115 | 0.257101004 | 0.141889457 |
| Expanding with Nouns + MESH terms | ||||
| Feedback Step | 0.194228485 | 0.1505 | 0.311523233 | 0.183403315 |
| Stemming Step | 0.188270263 | 0.139 | 0.318224318 | 0.174046006 |
| Lucene Step | 0.186934951 | 0.1435 | 0.328282514 | 0.17944826 |
| Re-rank Step | 0.148731105 | 0.124 | 0.28247245 | 0.153743885 |
| Expanding with UMLS Concepts + MESH terms | ||||
| Stemming Step | 0.188270263 | 0.139 | 0.318224318 | 0.174046006 |
| Feedback Step | 0.137930359 | 0.1195 | 0.253599299 | 0.144541146 |
| Re-rank Step | 0.094030546 | 0.0815 | 0.196744006 | 0.102584254 |
| Lucene Step | 0.092639625 | 0.081 | 0.174941453 | 0.097931787 |
| Reference | MAP |
|---|---|
| [6] | 0.0903 |
| [12] | 0.1099 |
| [11] | 0.2264 |
| Proposed System | 0.2150 |
| [5] | 0.3083 |
| [15] | 0.5333 |
| System | Mean Precision | Recall | F-Measure | MAP | GMAP |
|---|---|---|---|---|---|
| RYGH-1 | 0.2889 | 0.6122 | 0.2999 | 0.5624 | 0.0992 |
| RYGH-4 | 0.2774 | 0.6177 | 0.2943 | 0.5620 | 0.1286 |
| RYGH-3 | 0.2765 | 0.6162 | 0.2937 | 0.5538 | 0.1267 |
| RYGH | 0.2730 | 0.5980 | 0.2911 | 0.5365 | 0.0980 |
| gsl_zs_rrf1 | 0.2311 | 0.5658 | 0.2584 | 0.4779 | 0.0590 |
| gsl_zs_rrf2 | 0.2289 | 0.5529 | 0.2550 | 0.4759 | 0.0533 |
| bioinfo-1 | 0.2311 | 0.5569 | 0.2539 | 0.4673 | 0.0694 |
| gsl_zs_hybrid | 0.2222 | 0.5514 | 0.2482 | 0.4633 | 0.0571 |
| bioinfo-3 | 0.2289 | 0.5529 | 0.2508 | 0.4627 | 0.0709 |
| bioinfo-0 | 0.2289 | 0.5574 | 0.2532 | 0.4616 | 0.0764 |
| bioinfo-2 | 0.2256 | 0.5550 | 0.2504 | 0.4577 | 0.0743 |
| gsl_zs_nn | 0.2067 | 0.5269 | 0.2314 | 0.4570 | 0.0465 |
| gsl_zs_rrf3 | 0.2200 | 0.5167 | 0.2449 | 0.4325 | 0.0382 |
| The basic end-to-end | 0.2496 | 0.5135 | 0.2787 | 0.4278 | 0.0272 |
| Basic e2e mid speed | 0.2396 | 0.4960 | 0.2668 | 0.4165 | 0.0249 |
| bio-answerfinder | 0.3908 | 0.4170 | 0.3553 | 0.4129 | 0.0138 |
| bio-answerfinder-2 | 0.2613 | 0.4715 | 0.2578 | 0.4123 | 0.0293 |
| AUEB-System2 | 0.2100 | 0.4634 | 0.2280 | 0.4035 | 0.0137 |
| AUEB-System1 | 0.1678 | 0.4092 | 0.1899 | 0.3394 | 0.0073 |
| Fleming-1 | 0.0878 | 0.1590 | 0.0866 | 0.1285 | 0.0003 |
| Fleming-2 | 0.0878 | 0.1596 | 0.0862 | 0.1253 | 0.0003 |
| Fleming-3 | 0.0878 | 0.1596 | 0.0862 | 0.1253 | 0.0003 |
| simple baseline solr | 0.0022 | 0.0015 | 0.0018 | 0.0008 | 0.0000 |
| System | Mean Precision | Recall | F-Measure | MAP | GMAP |
|---|---|---|---|---|---|
| dmiip5 | 0.2587 | 0.6469 | 0.2823 | 0.5577 | 0.1350 |
| dmiip3 | 0.2547 | 0.6559 | 0.2801 | 0.5576 | 0.1520 |
| dmiip2 | 0.2400 | 0.6201 | 0.2633 | 0.5222 | 0.1253 |
| bioinfo-2 | 0.2471 | 0.6144 | 0.2837 | 0.5132 | 0.1235 |
| A&Q4 | 0.2147 | 0.6097 | 0.2440 | 0.5122 | 0.1473 |
| A&Q3 | 0.2147 | 0.6097 | 0.2440 | 0.5122 | 0.1473 |
| A&Q5 | 0.2107 | 0.6026 | 0.2396 | 0.5084 | 0.1296 |
| bioinfo-3 | 0.2712 | 0.6220 | 0.3075 | 0.5075 | 0.1134 |
| bioinfo-1 | 0.3085 | 0.6004 | 0.3365 | 0.5057 | 0.0920 |
| bioinfo-0 | 0.3052 | 0.6100 | 0.3381 | 0.5053 | 0.1014 |
| dmiip1 | 0.2347 | 0.6248 | 0.2622 | 0.5001 | 0.1234 |
| dmiip4 | 0.2387 | 0.5952 | 0.2596 | 0.4940 | 0.0809 |
| bioinfo-4 | 0.2516 | 0.6035 | 0.2840 | 0.4894 | 0.0939 |
| Fleming-4 | 0.1600 | 0.5764 | 0.2062 | 0.4257 | 0.0577 |
| Fleming-3 | 0.1600 | 0.5764 | 0.2062 | 0.4254 | 0.0570 |
| Fleming-2 | 0.1600 | 0.5800 | 0.2079 | 0.4109 | 0.0402 |
| Fleming-1 | 0.1587 | 0.5796 | 0.2072 | 0.4103 | 0.0403 |
| A&Q2 | 0.1747 | 0.5378 | 0.2069 | 0.3995 | 0.0465 |
| UR-gpt4-zero-ret | 0.2290 | 0.3529 | 0.2369 | 0.3058 | 0.0046 |
| A&Q | 0.1427 | 0.4814 | 0.1733 | 0.2931 | 0.0115 |
| MindLab QA System | 0.2820 | 0.3369 | 0.2692 | 0.2631 | 0.0039 |
| MindLab QA System++ | 0.2820 | 0.3369 | 0.2692 | 0.2631 | 0.0039 |
| UR-gpt3.5-turbo-zero | 0.1901 | 0.2966 | 0.2068 | 0.2410 | 0.0028 |
| Deep ML methods for | 0.2067 | 0.5695 | 0.2299 | 0.2400 | 0.0299 |
| MindLab QA Reloaded | 0.2362 | 0.4677 | 0.2513 | 0.2247 | 0.0166 |
| UR-gpt4-simple | 0.1967 | 0.2676 | 0.2001 | 0.2012 | 0.0015 |
| MindLab Red Lions++ | 0.2389 | 0.4002 | 0.2341 | 0.1974 | 0.0087 |
| UR-gpt3.5-t-simple | 0.1913 | 0.2492 | 0.1943 | 0.1962 | 0.0011 |
| ES and re-ranking 2 | 0.2129 | 0.1951 | 0.1674 | 0.1074 | 0.0007 |
| ES and re-ranking | 0.1493 | 0.3736 | 0.1641 | 0.0995 | 0.0056 |
| New minimize func | 0.1333 | 0.3472 | 0.1455 | 0.0871 | 0.0043 |
| MarkedCEDR_0 | 0.0013 | 0.0019 | 0.0016 | 0.0004 | 0.0000 |
| OWLMan-phaseB-V1 | - | - | - | - | - |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| First Method (5 feature F1 weight) | 0.30609410430839 | 0.268139543582234 | 0.256271218796207 |
| Second Method (3 feature F1 weight) | 0.313103254769921 | 0.272229307505606 | 0.260814282105723 |
| Third Method (NER Filter with 0.2 weight) | 0.303397311305475 | 0.260304412863095 | 0.249995189380743 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| First Method (5 feature F1 weight) | 0.265168962321771 | 0.424878821734178 | 0.297632486789945 |
| Second Method (3 feature F1 weight) | 0.260647496638209 | 0.413577298763878 | 0.290564749074941 |
| Third Method (NER Filter with 0.2 weight) | 0.263240786175486 | 0.401791106023006 | 0.289514758013646 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| One-by-One (NER Filter, 0.2 weight) top10 | 0.387081128747795 | 0.277551033286955 | 0.310881366606519 |
| One-by-One (5 feature F1 weight) top10 | 0.391542408209075 | 0.279592440704706 | 0.313518331658926 |
| One-by-One (NER Filter, 0.2 weight) top20 | 0.388586258638562 | 0.353901592287224 | 0.366408330602294 |
| One-by-One (5 feature F1 weight) top20 | 0.39447408426323 | 0.358815277016613 | 0.371677466230661 |
| One-by-One (NER Filter, 0.2 weight) | 0.392802991978339 | 0.385307940268726 | 0.388352093573967 |
| One-by-One (5 feature F1 weight) | 0.396920212051186 | 0.389355326112682 | 0.392433244564683 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bolat, H.; Şen, B. Document Retrieval System for Biomedical Question Answering. Appl. Sci. 2024, 14, 2613. https://doi.org/10.3390/app14062613
Bolat H, Şen B. Document Retrieval System for Biomedical Question Answering. Applied Sciences. 2024; 14(6):2613. https://doi.org/10.3390/app14062613
Chicago/Turabian StyleBolat, Harun, and Baha Şen. 2024. "Document Retrieval System for Biomedical Question Answering" Applied Sciences 14, no. 6: 2613. https://doi.org/10.3390/app14062613
APA StyleBolat, H., & Şen, B. (2024). Document Retrieval System for Biomedical Question Answering. Applied Sciences, 14(6), 2613. https://doi.org/10.3390/app14062613