
Detection of Safety Signs Using Computer Vision Based on Deep Learning



Abstract
1. Introduction
- (I).
- The safety sign image dataset contained 2000 images with 10 categories: wearing protective gloves, wearing a safety helmet, wearing electric shock, warning electric shock, waring poisoning, emergency exit, emergency shelter, no climbing, no smoking, and no fireworks.
- (II).
- Attention mechanisms were introduced to make the network focus on important information and reduce the influence of useless information.
- (III).
- The Soft-Non Maximum Suppression (Soft-NMS) algorithm was used to replace the traditional NMS algorithm so that more correct prediction boxes can be retained and thus further optimize the detection model.
- (IV).
- Since YOLOV4-tiny is a one-stage detection model, it lacks the first-step selection of prediction box samples in multi-stage detection. Focal Loss was proposed to suppress the loss function value of the well-classified sample box. At the same time, the sample box with poor classification was not suppressed, thereby alleviating the problem of category imbalance in one-stage object detection.
2. Related Works
2.1. Related Research of Computer Vision
2.2. Computer Vision in Safety Applications
3. Deep Neural Network
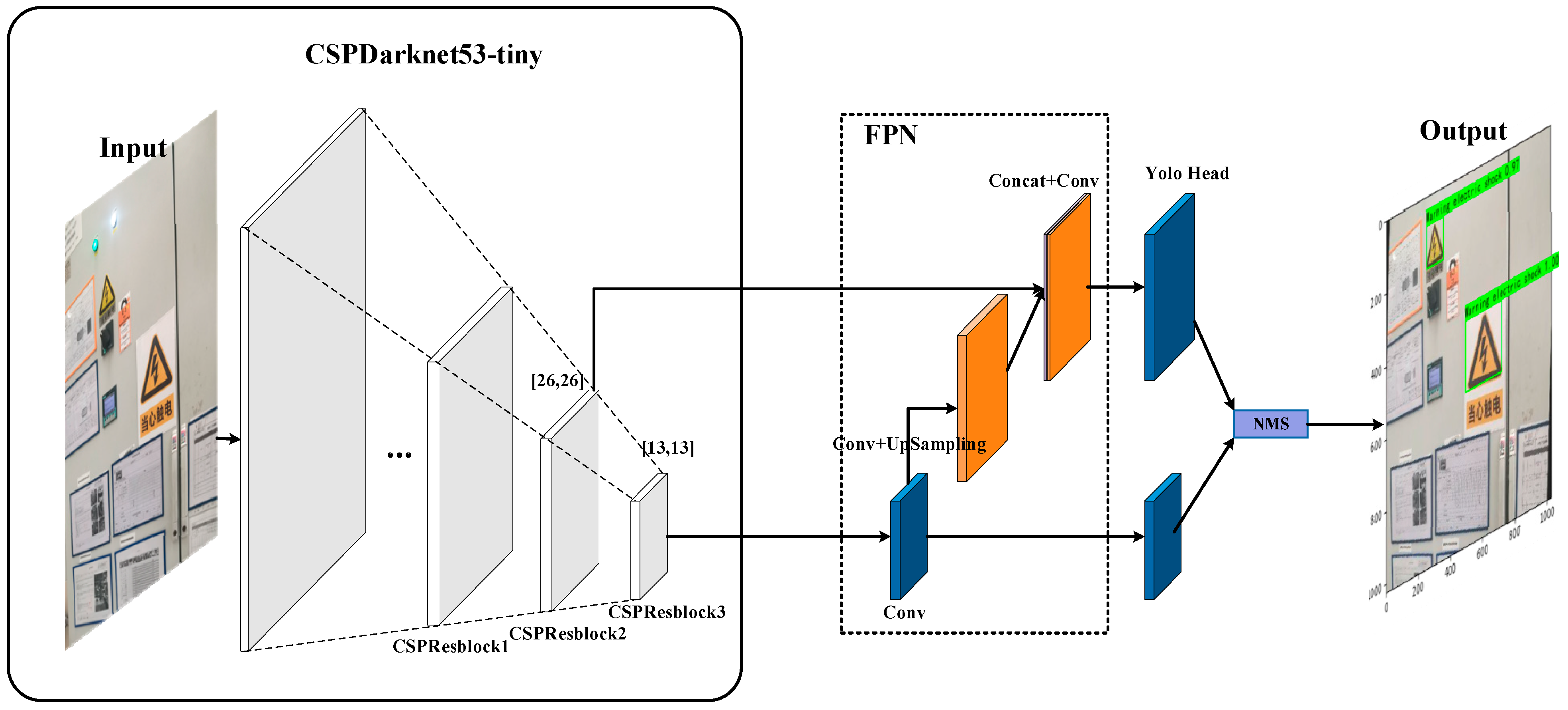
3.1. YOLOV4-Tiny Network
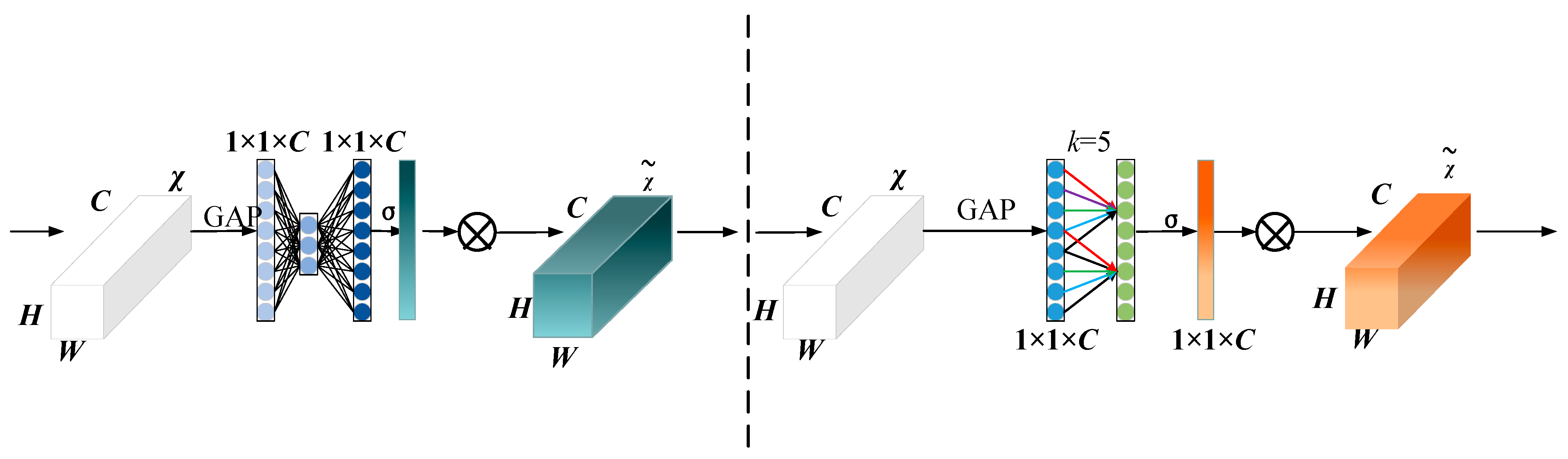
3.2. Attention Mechanisms
3.3. Loss Function
3.4. Improved NMS Algorithm
4. Experiments
4.1. Dataset Collection and Pre-Processing
4.2. Experimental Environment and Evaluation Index
- (i)
- Three attention mechanisms, SENet, CBAM, and ECANet, were compared to investigate the influence of different attention mechanisms on detection accuracy and speed.
- (ii)
- The Soft-NMS algorithm was introduced to replace the previous traditional NMS algorithm;
- (iii)
- The Focal Loss algorithm was introduced.
- (iv)
- The traditional YOLOV4-tiny model and the Faster-RCNN algorithm were compared to validate the improved models.
5. Results and Discussion
5.1. Influence of Different Attention Mechanisms
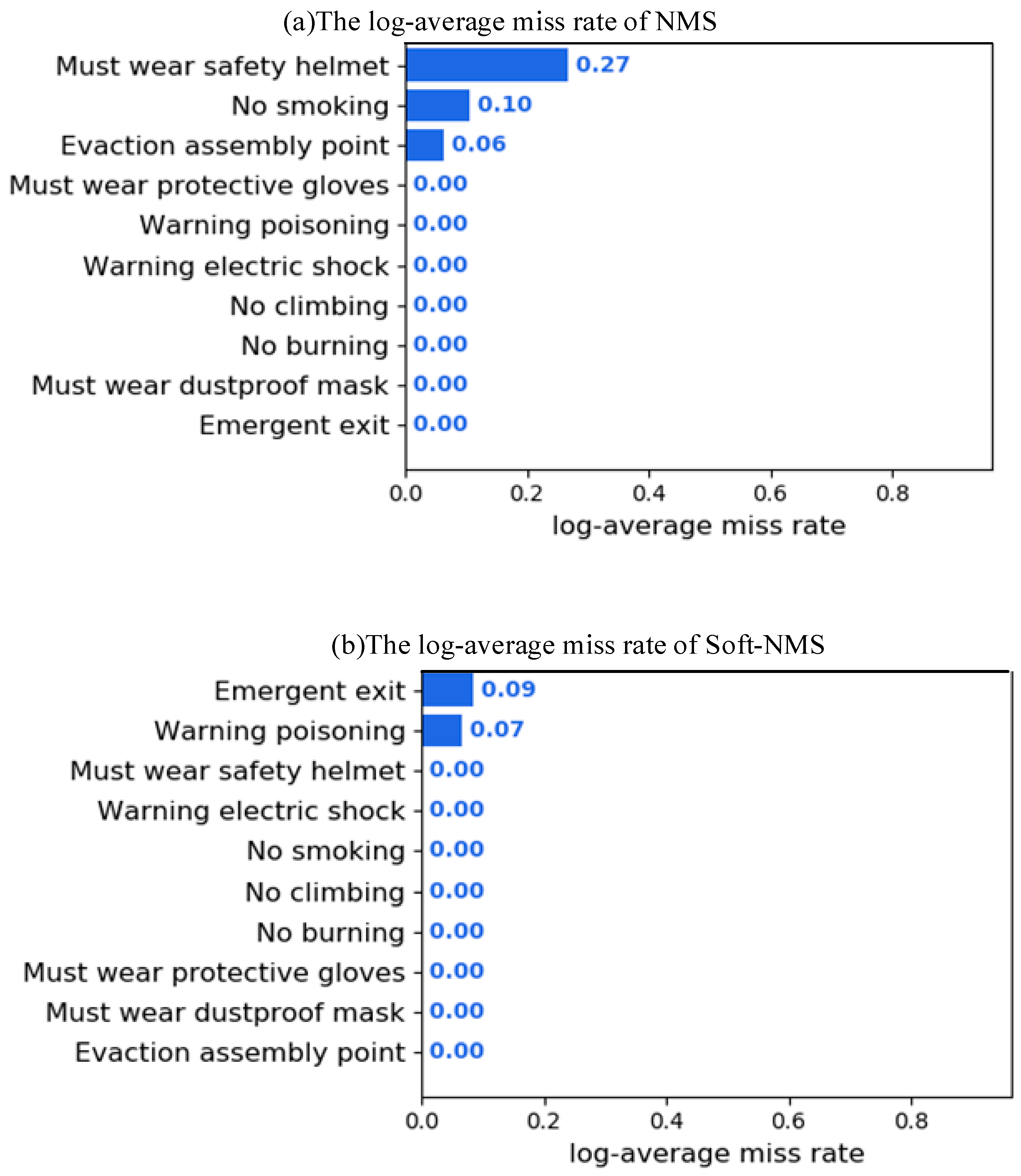
5.2. Influence of Soft-NMS
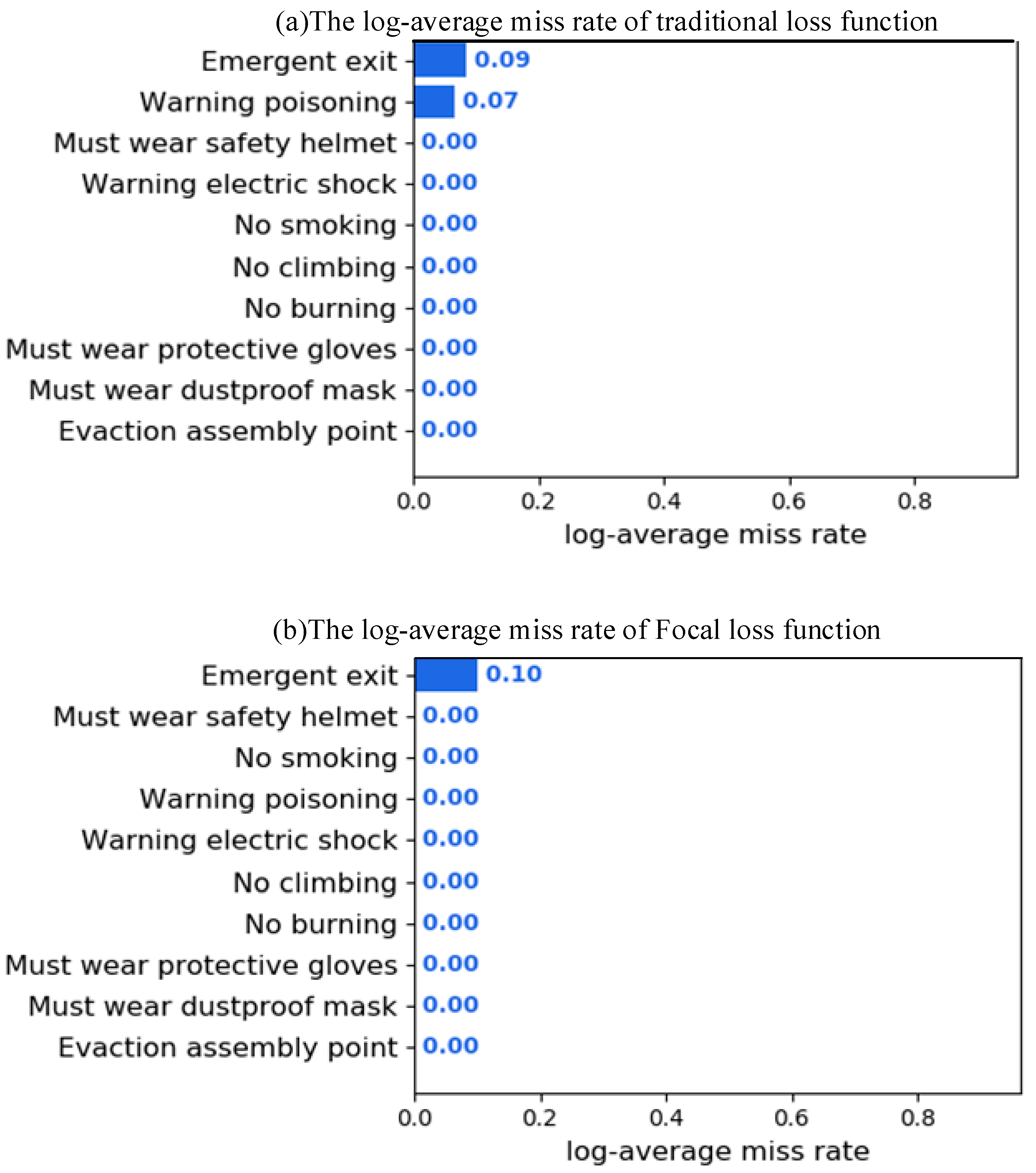
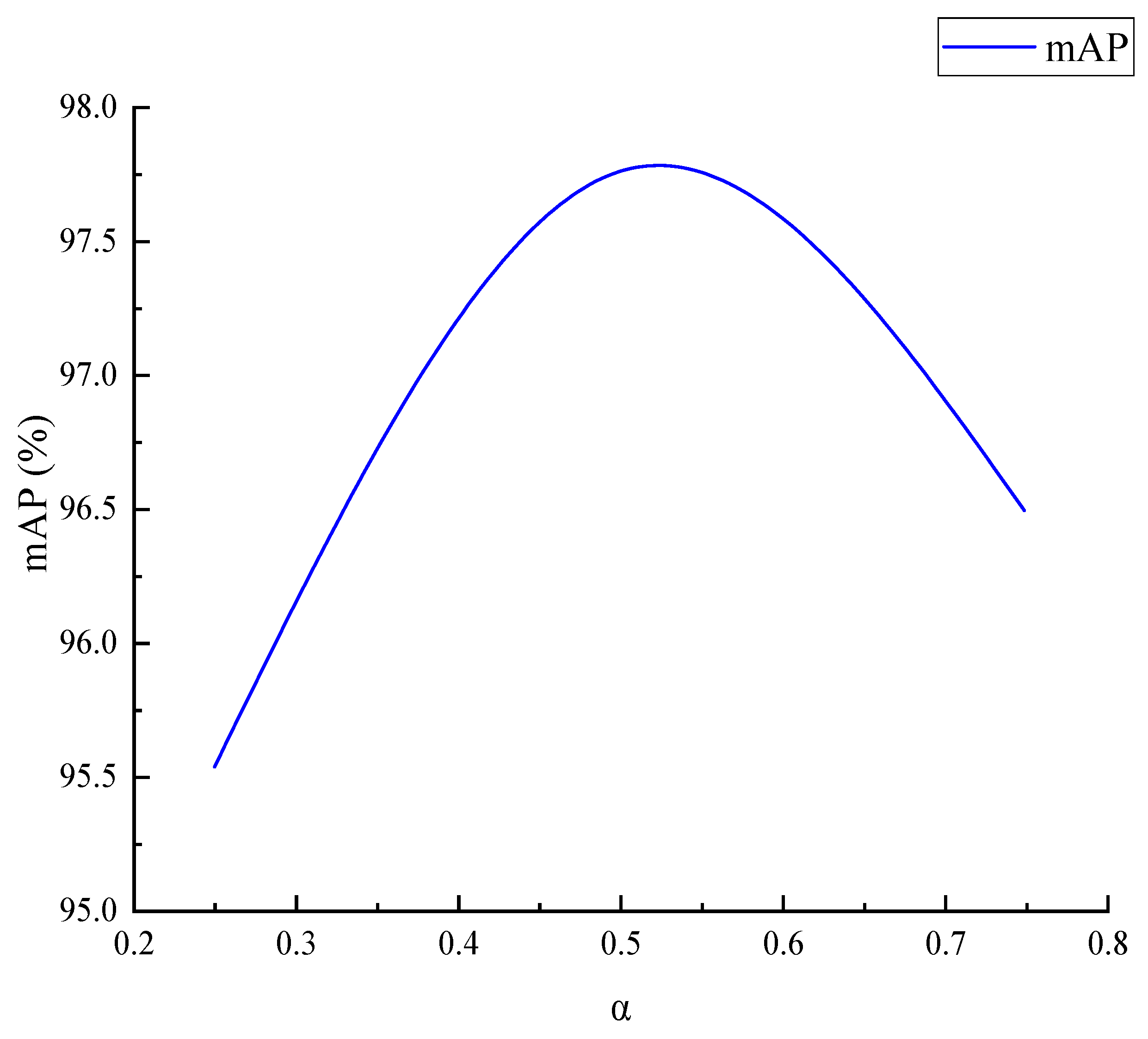
5.3. Influence of Focal Loss
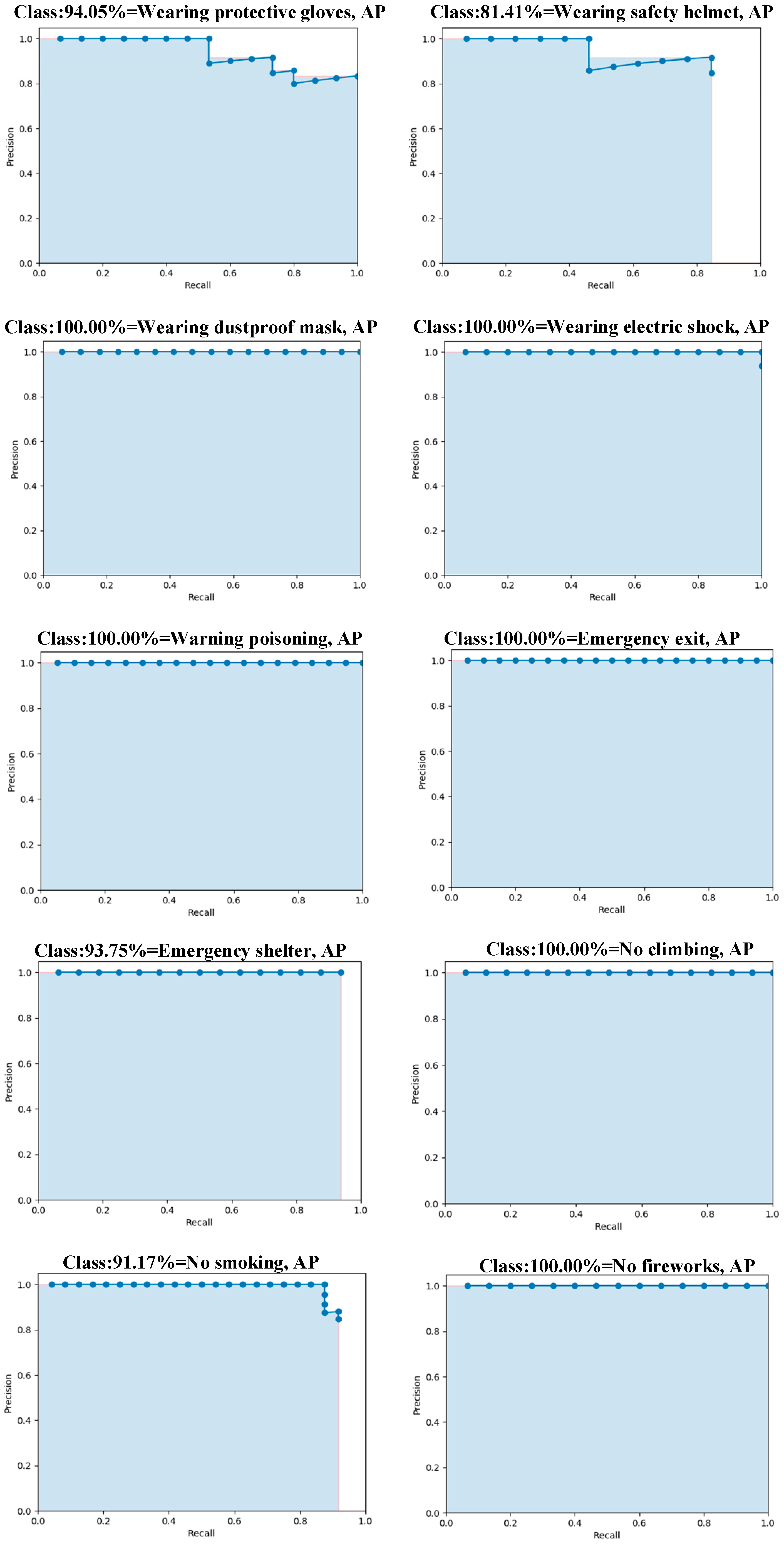
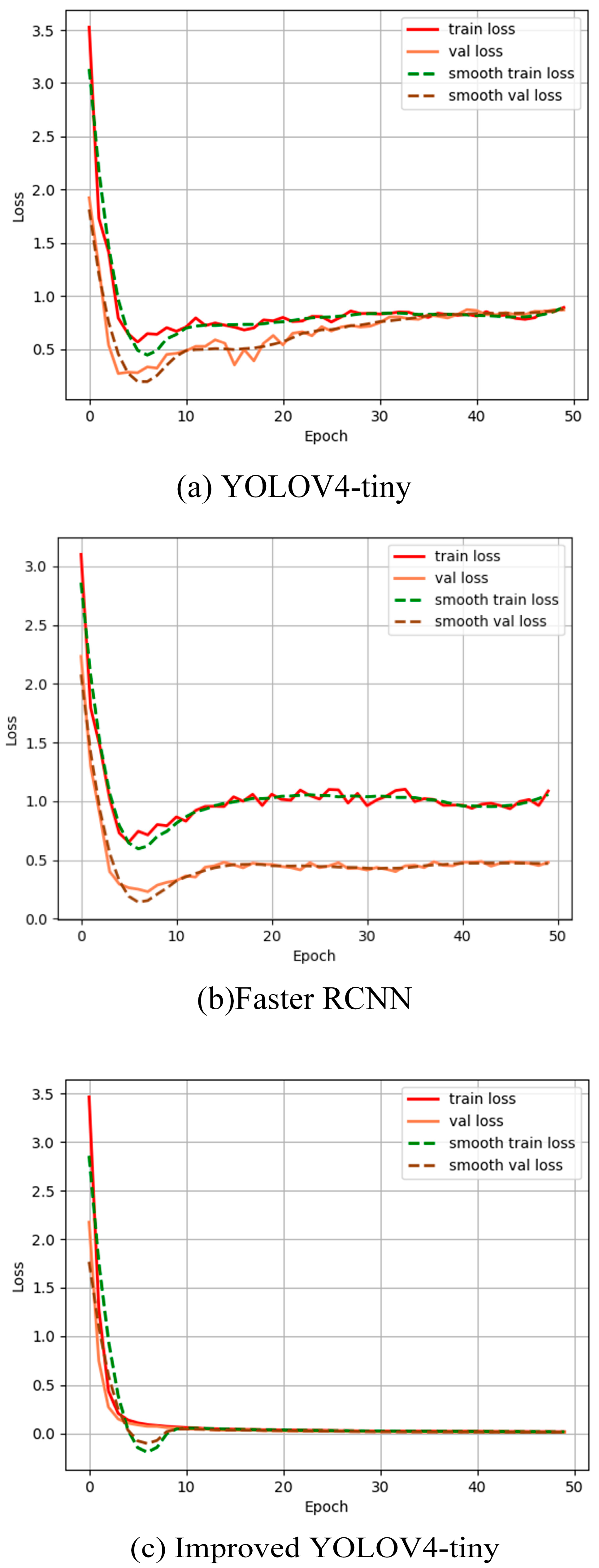
5.4. Validation of the Proposed Model
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, P.; Zhao, W. Image fire detection algorithms based on convolutional neural networks. Case Stud. Therm. Eng. 2020, 19, 100625. [Google Scholar] [CrossRef]
- Zhou, F.; Zhao, H.; Nie, Z. Safety helmet detection based on YOLOv5. In Proceedings of the 2021 IEEE International Conference on Power Electronics, Computer Applications (ICPECA), Shenyang, China, 22–24 January 2021; pp. 6–11. [Google Scholar]
- Xiao, Y.; Chang, A.; Wang, Y.; Huang, Y.; Yu, J.; Huo, L. Real-time Object Detection for Substation Security Early-warning with Deep Neural Network based on YOLO-V5. In Proceedings of the 2022 IEEE IAS Global Conference on Emerging Technologies (GlobConET), Arad, Romania, 20–22 May 2022; pp. 45–50. [Google Scholar]
- Fang, W.; Ding, L.; Luo, H.; Love, P.E.D. Falls from heights: A computer vision-based approach for safety harness detection. Autom. Constr. 2018, 91, 53–61. [Google Scholar] [CrossRef]
- Mneymneh, B.E.; Abbas, M.; Khoury, H. Evaluation of computer vision techniques for automated hardhat detection in indoor construction safety applications. Front. Eng. Manag. 2018, 5, 227–239. [Google Scholar] [CrossRef]
- Fang, Q.; Li, H.; Luo, X.; Ding, L.; Luo, H.; Li, C. Computer vision aided inspection on falling prevention measures for stee-plejacks in an aerial environment. Autom. Constr. 2018, 93, 148–164. [Google Scholar] [CrossRef]
- Liu, W.; Meng, Q.; Li, Z.; Hu, X. Applications of Computer Vision in Monitoring the Unsafe Behavior of Construction Workers: Current Status and Challenges. Buildings 2021, 11, 409. [Google Scholar] [CrossRef]
- Wang, G.; Ren, H.; Zhao, G.; Zhang, D.; Wen, Z.; Meng, L.; Gong, S. Research and practice of intelligent coal mine technology systems in China. Int. J. Coal Sci. Technol. 2022, 9, 24. [Google Scholar] [CrossRef]
- Chen, Y.; Silvestri, L.; Lei, X.; Ladouceur, F. Optically Powered Gas Monitoring System Using Single-Mode Fibre for Under-ground Coal Mines. Int. J. Coal Sci. Technol. 2022, 9, 26. [Google Scholar] [CrossRef]
- Zhou, L.; Pan, S.; Wang, J.; Vasilakos, A.V. Machine learning on big data: Opportunities and challenges. Neurocomputing 2017, 237, 350–361. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends® Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Le, Q.V.; Ngiam, J.; Coates, A.; Lahiri, A.; Prochnow, B.; Ng, A.Y. On optimization methods for deep learning. In Proceedings of the 28th International Conference on International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 265–272. [Google Scholar]
- Houben, S.; Stallkamp, J.; Salmen, J.; Schlipsing, M.; Igel, C. Detection of traffic signs in real-world images: The German Traffic Sign Detection Benchmark. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–8. [Google Scholar] [CrossRef]
- Greenhalgh, J.; Mirmehdi, M. Real-Time Detection and Recognition of Road Traffic Signs. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1498–1506. [Google Scholar] [CrossRef]
- Ko, J.; Lim, J.H.; Chen, Y.; Musvaloiu-E, R.; Terzis, A.; Masson, G.M.; Gao, T.; Destler, W.; Selavo, L.; Dutton, R.P. MEDiSN: Medical emergency detection in sensor networks. ACM Trans. Embed. Comput. Syst. 2010, 10, 1–29. [Google Scholar] [CrossRef]
- Andreyanov, N.; Sytnik, A.; Shleymovich, M. Object Detection in Images Using Deep Neural Networks for Agricultural Ma-chinery. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, England, 2022; p. 032002. [Google Scholar]
- Zuo, Z.; Yu, K.; Zhou, Q.; Wang, X.; Li, T. Traffic signs detection based on faster r-cnn. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems Workshops (ICDCSW), Atlanta, GA, USA, 5–8 June 2017; pp. 286–288. [Google Scholar]
- Gaur, L.; Bhatia, U.; Jhanjhi, N.; Muhammad, G.; Masud, M. Medical image-based detection of COVID-19 using deep convo-lution neural networks. Multimed. Syst. 2023, 29, 1729–1738. [Google Scholar] [CrossRef]
- Li, W.; Wang, D.; Li, M.; Gao, Y.; Wu, J.; Yang, X. Field detection of tiny pests from sticky trap images using deep learning in agricultural greenhouse. Comput. Electron. Agric. 2021, 183, 106048. [Google Scholar] [CrossRef]
- Delhi, V.S.K.; Sankarlal, R.; Thomas, A. Detection of Personal Protective Equipment (PPE) Compliance on Construction Site Using Computer Vision Based Deep Learning Techniques. Front. Built Environ. 2020, 6, 136. [Google Scholar] [CrossRef]
- Teizer, J.; Caldas, C.H.; Haas, C.T. Real-Time Three-Dimensional Occupancy Grid Modeling for the Detection and Tracking of Construction Resources. J. Constr. Eng. Manag. 2007, 133, 880–888. [Google Scholar] [CrossRef]
- Cheng, T.; Teizer, J. Real-time resource location data collection and visualization technology for construction safety and activity monitoring applications. Autom. Constr. 2012, 34, 3–15. [Google Scholar] [CrossRef]
- Barro-Torres, S.; Fernández-Caramés, T.M.; Pérez-Iglesias, H.J.; Escudero, C.J. Real-time personal protective equipment mon-itoring system. Comput. Commun. 2012, 36, 42–50. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Wei, L.; Jia, Y.; Sermanet, P.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; Volume 28, pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 7263–7271. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Yang, J.; Chang, B.; Zhang, Y.; Wu, M. Research on CNN Coal and Rock Recognition Method Based on Hyperspectral Data. Int. J. Coal Sci. Technol. 2022. preprints. [Google Scholar] [CrossRef]
- Chen, S.; Tang, W.; Ji, T.; Zhu, H.; Ouyang, Y.; Wang, W. Detection of safety helmet wearing based on improved faster R-CNN. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Wang, H.; Hu, Z.; Guo, Y.; Yang, Z.; Zhou, F.; Xu, P. A Real-Time Safety Helmet Wearing Detection Approach Based on CSYOLOv3. Appl. Sci. 2020, 10, 6732. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Yunyun, L.; JIANG, W. Detection of wearing safety helmet for workers based on YOLOv4. In Proceedings of the 2021 Inter-national Conference on Computer Engineering and Artificial Intelligence (ICCEAI), Shanghai, China, 27–29 August 2021; pp. 83–87. [Google Scholar]
- Benyang, D.; Xiaochun, L.; Miao, Y. Safety helmet detection method based on YOLO v4. In Proceedings of the 2020 16th In-ternational Conference on Computational Intelligence and Security (CIS), Guangxi, China, 27–30 November 2020; pp. 155–158. [Google Scholar]
- Yan, W.; Wang, X.; Tan, S. YOLO-DFAN: Effective High-Altitude Safety Belt Detection Network. Future Internet 2022, 14, 349. [Google Scholar] [CrossRef]
- Wu, S.; Zhang, L. Using popular object detection methods for real time forest fire detection. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018; pp. 280–284. [Google Scholar]
- Haibin, L.; Yuan, S.; Wenming, Z.; Yaqian, L. The detection method for coal dust caused by chute discharge based on YOLOv4-tiny. Opto-Electron. Eng. 2021, 48, 210049. [Google Scholar]
- Ullah, M.B. CPU based YOLO: A real time object detection algorithm. In Proceedings of the 2020 IEEE Region 10 Symposium (TENSYMP), Dhaka, Bangladesh, 5–7 June 2020; pp. 552–555. [Google Scholar]
- Wang, X.; Hua, X.; Xiao, F.; Li, Y.; Hu, X.; Sun, P. Multi-Object Detection in Traffic Scenes Based on Improved SSD. Electronics 2018, 7, 302. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- GB2894-2008; Safety Signs Guideline for the Use. China National Standardization Administrative Committee: Beijing, China, 2008.
- Everingham, M.R.; Eslami, S.; Gool, L.J.; Williams, C.; Winn, J.M.; Zisserman, A. The Pascal Visual Object Classes Challenge. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Safety Signs | Original Number | Augmented Number |
|---|---|---|
| Wearing protective gloves | 48 | 239 |
| Wearing safety helmet | 47 | 187 |
| Wearing dustproof mask | 49 | 195 |
| Warning electric shock | 57 | 227 |
| Warning poisoning | 44 | 176 |
| Emergency exit | 54 | 215 |
| No climbing | 52 | 207 |
| No smoking | 47 | 188 |
| No fireworks | 53 | 213 |
| Emergency shelter | 38 | 153 |
| Total | 489 | 2000 |
| Algorithm | mAP/% | FPS/s | |
|---|---|---|---|
| YOLOV4-tiny | 90.21 | 2.34 | |
| YOLOV4-tiny + Attention mechanism | ECANet | 96.03 | 1.63 |
| SENet | 90.32 | 1.46 | |
| CBAM | 94.13 | 1.62 | |
| YOLOV4-tiny + ECANet + Soft-NMS | 97.10 | 1.59 | |
| YOLOV4-tiny + ECANet + Soft-NMS + Lfl | 97.76 | 1.62 | |
| Faster RCNN | 88.53 | 1.21 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Song, Z.; Zhang, L. Detection of Safety Signs Using Computer Vision Based on Deep Learning. Appl. Sci. 2024, 14, 2556. https://doi.org/10.3390/app14062556
Wang Y, Song Z, Zhang L. Detection of Safety Signs Using Computer Vision Based on Deep Learning. Applied Sciences. 2024; 14(6):2556. https://doi.org/10.3390/app14062556
Chicago/Turabian StyleWang, Yaohan, Zeyang Song, and Lidong Zhang. 2024. "Detection of Safety Signs Using Computer Vision Based on Deep Learning" Applied Sciences 14, no. 6: 2556. https://doi.org/10.3390/app14062556
APA StyleWang, Y., Song, Z., & Zhang, L. (2024). Detection of Safety Signs Using Computer Vision Based on Deep Learning. Applied Sciences, 14(6), 2556. https://doi.org/10.3390/app14062556