
Automatically Expanding User-Management System for Massive Users in the Cloud Platform


Abstract
1. Introduction
2. Methodologies
2.1. Architecture of the User-Management System
2.2. Implementation of Users’ Automated Expansion Module
2.2.1. User Information Synchronization Module
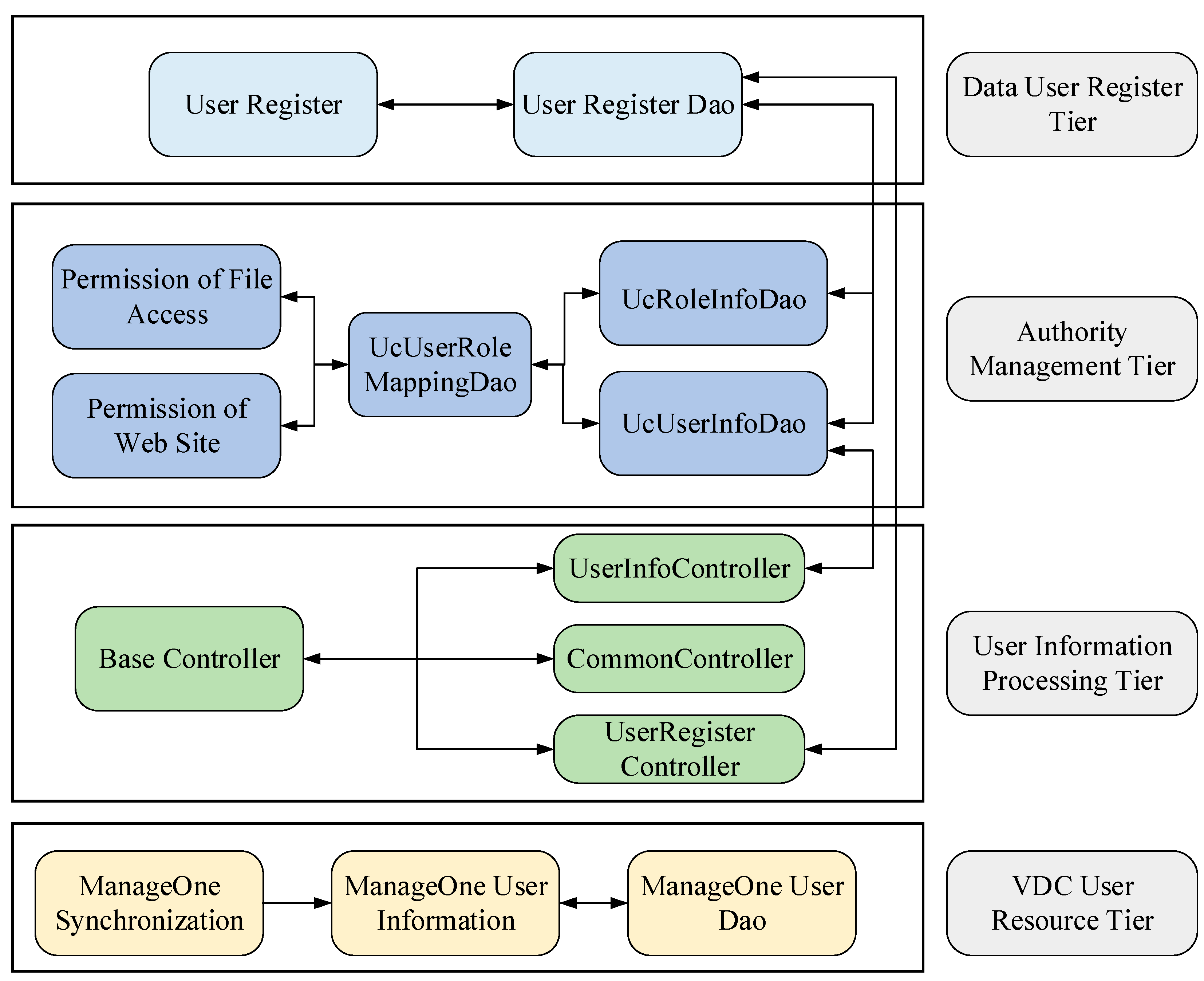
- There are more than a dozen methods in the class BaseController, so we can take advantage of most of them. A crucial method getUserByGroup of class UserInfoController was constructed to divide the user group.
- Another class, UserInfoService, was introduced to the class UserInfoController for processing logical transactions. For instance, when a VDC user sets the account password, the method entryptPassword was used to encrypt the password securely. Meanwhile, user information can also be acquired via the user’s identification or user’s department through the method getUserInfoById and getUserInfoByDepartmentId.
- The class UserInfoService was inherited from the class BaseService. Some basic logical methods such as the paging querying and database table processing were contained within the class UserInfoService. These logical methods can be used as the methods of a generic class.
- The class UserInfoDao was a data tier to provide some custom methods. We can invoke these methods from the service tier to complete a variety of complicated functions on database operations.
- To call functions of synchronization service within ManageOne, we constructed a significant service class, MoUserInfoService, which created some interfaces. User name, user permission, and user creation time were all synchronized by means of this class.
- Another class, MoUserInfoDao, was a data-access tier that can obtain information from ManageOne of the HuaWei Cloud Stack user authority management so that user authorization of the user-management system would synchronize with Huawei Cloud Stack.
2.2.2. User Identification and Authentication Module
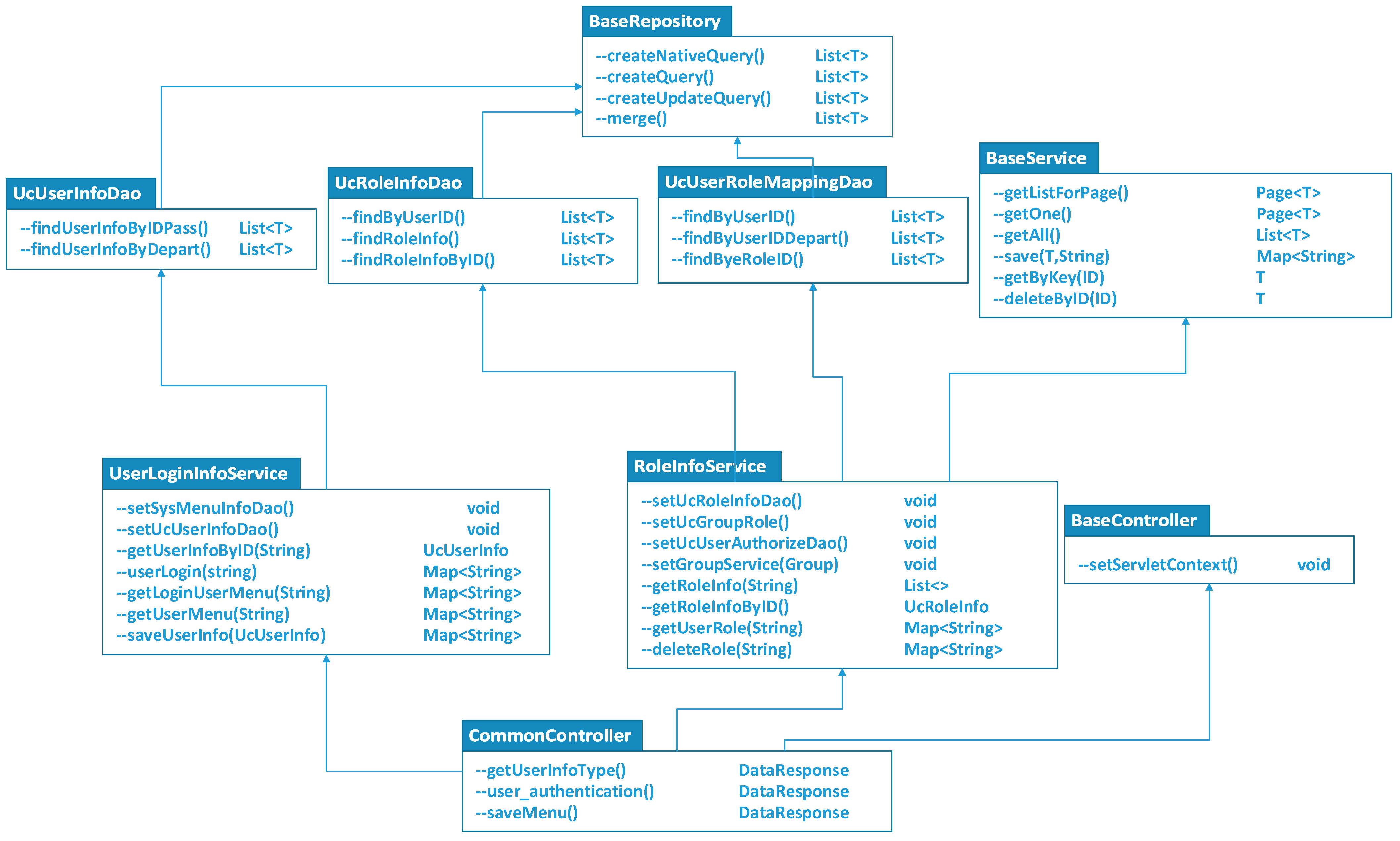
- The class CommonController was defined as a controller class to implement user identity authentication and was inherited from the class BaseController. All the authentication services interfaces consist of getUserInfoType, putAuthentication, and saveAuthentication, which are provided as Restful API. As shown in Figure 1, the class CommonController was inherited from the class BaseController and belonged to the user information process tier. The class BaseController was a customized parent class of the control tier to provide certain primitive methods in common.
- The class UserLoginInfoService and the class RoleInfoService were created within the class CommonController. These two classes contained a large number of methods for handling the transaction logic between the data user register tier and the user information process tier. The interface setGroupRoleMappingDao and setUserAuthorizeDao were used for user grouping and permission assignment in the class RoleInfoService.
- The classes UcUserInfoDao, UcRoleInfoDao, and UcUserRoleMappingDao were defined within the data-access class for operating the database. We can find the user’s department using the method findUserInfobyDepartmentId and the method findUserInfobyIdandPassword. So, when a new user is registered through the cloud resource user’s management system, we can map the privilege of cloud resource users to the data users using the class UcUserRoleMappingDao. Once the privileges of these two types of users are bridged, any type of user can transform permission of file accessing and website accessing each other (as shown in Figure 1). Moreover, these classes had the characteristics of some public data operating methods, which were inherited from the class BaseReposity.
2.2.3. User Registration and Request Module
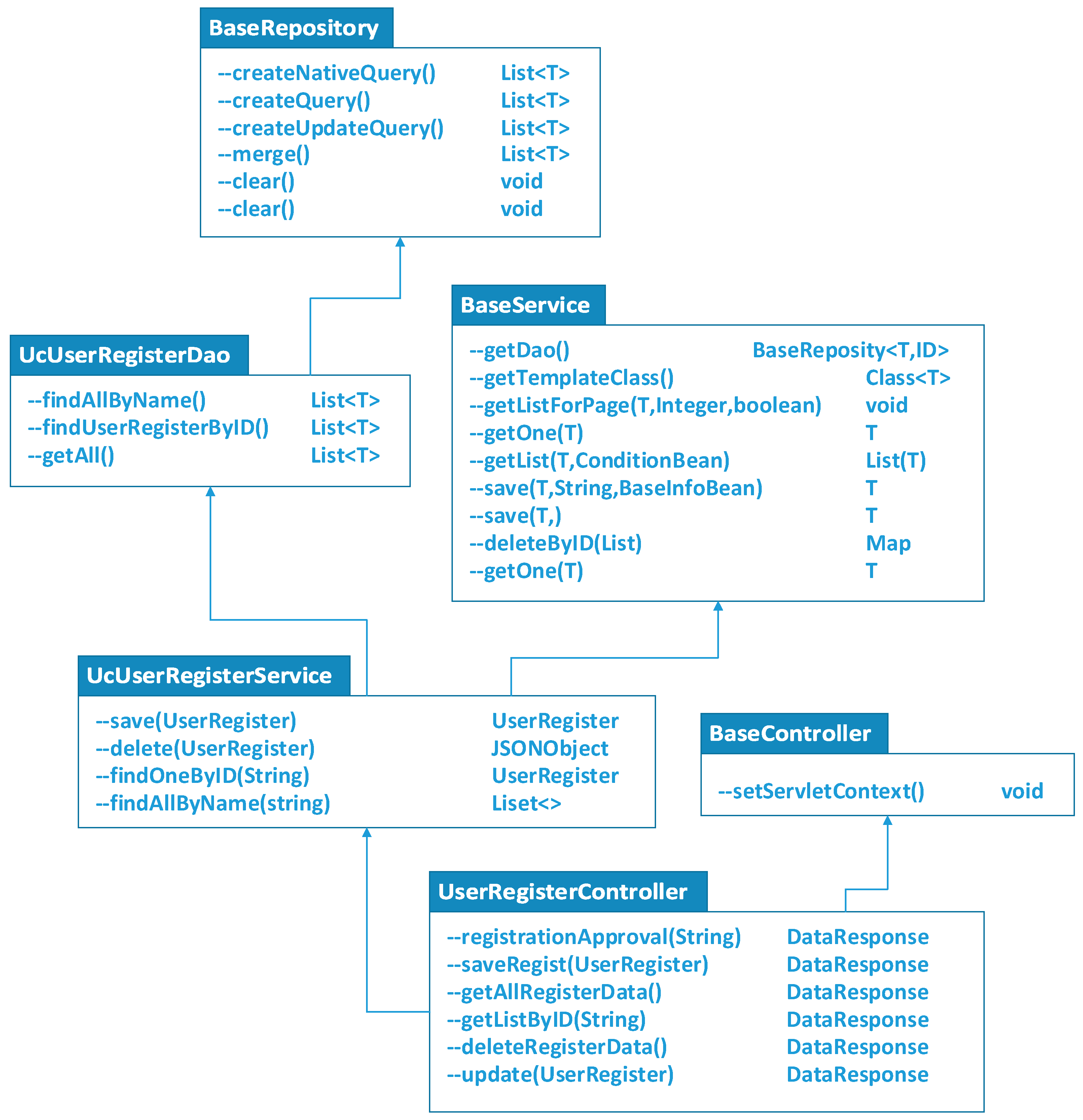
- When a user wants to apply for registration of a new account for data application or cloud resource usage, the class UserRegisterController is defined to provide the methods for filling in user approvals, saving user registration, and querying user IDs. The data user registration application and the cloud resource user registration application are differentiated as two registration flows by the class UcUserRegisterService. There are a large number of services and logical methods in this class. Once any type of user has been registered, the user identification and authentication will be synchronized with each other.
- The class UcUserRegisterService was inherited from the class BaseService. Nearly all the methods for user registration were enclosed within the class BaseService. The request for user registration is recorded and examined so that all the registration information is compliant. As shown in Figure 1, the user registration information, after validation, is passed to the class UcUserRoleMappingDao to synchronize user authentication.
- Another class, UcUserRegisterDao, was defined for some customized data-processing methods and complicated database operations. Different user authentications can be merged or detached by means of the methods provided by the class BaseRepository.
3. Load Balancing for Massive Concurrent Users
3.1. Load-Balancing Algorithms in Nginx
- Round Robin load balancing: This is a simple way to distribute client requests across a group of servers via the Ngnix master node. A client request is forwarded to each Nginx worker node in turn and submitted to each user registration node. The algorithm instructs the load balancer to go back to the top of the list and repeats again. Round robin is the most widely deployed load-balancing algorithm. Using this method, client requests are routed to available servers on a cyclical basis. Round-robin load balancing works best when servers have roughly identical computing capabilities and storage capacity.
- Weighted Load Balancing: The weighted round robin load-balancing algorithm allows the Nginx master node to assign weights to each Nginx worker node based on criteria like the traffic-handling capacity. Nodes with higher weights receive a higher proportion of client requests.
- IP HASH Load Balancing: The IP Hash policy uses an incoming request’s source IP address as a hashing key to route non-sticky traffic to the same user registration server. The load balancer routes requests from the same client to the same backend server as long as that server is available.
3.2. Optimization of the Weighted Load-Balancing Algorithm
4. Results and Discussion
4.1. Experimental Environment
4.2. Performance Evaluation
4.2.1. Performance of Load-Balancing Algorithm
4.2.2. Performance of Massive User Registration and Online
4.3. Comparison with Existing Schemes
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Donoho, D. 50 Years of Data Science. J. Comput. Graph. Stat. 2017, 26, 745–766. [Google Scholar] [CrossRef]
- Hey, A.J.G.; Tansley, S.; Tolle, K.M. The Fourth Paradigm: Data-Intensive Scientific Discovery; Microsoft Research: Redmond, WA, USA, 2009. [Google Scholar]
- Armbrust, M.; Fox, A.; Griffith, R.; Joseph, A.D.; Katz, R.; Konwinski, A.; Lee, G.; Patterson, D.; Rabkin, A.; Stoica, I.; et al. A view of cloud computing. Commun. ACM 2010, 53, 50–58. [Google Scholar] [CrossRef]
- Li, J.; Zhang, C. A three-dimensional role based user management model in web information systems. In Proceedings of the 2012 International Conference on Information Technology and Software Engineering: Information Technology; Volume 210 of Lecture Notes in Electrical Engineering; Springer: Berlin/Heidelberg, Germany, 2013; pp. 657–665. [Google Scholar]
- Huang, Q.; Li, J.; Li, Z. A geospatial hybrid cloud platform based on multi-sourced computing and model resources for geosciences. Int. J. Digit. Earth 2018, 11, 1184–1204. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, L.; Liu, D.; Song, W.; Ma, Y.; Liu, P.; Chen, D. Towards building a multi-datacenter infrastructure for massive remote sensing image processing. Concurr. Comput. Pract. Exp. 2013, 25, 1798–1812. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, L.; Ma, Y.; Liu, D. Design and implementation of task scheduling strategies for massive remote sensing data processing across multiple data centers. Softw. Pract. Exp. 2014, 44, 873–886. [Google Scholar] [CrossRef]
- Ren, F.; Wang, J. Turning remote sensing to cloud services: Technical research and experiment. J. Remote Sens. 2012, 16, 1331–1346. [Google Scholar] [CrossRef]
- Agostino, F.; Carlo, M.; Michela, M.; Giuseppe, P.; Mehdi, S. Hierarchical Approach for Green Workload Management in Distributed Data Centers. In Proceedings of the Euro-Par 2014 International Workshops, Porto, Portugal, 25–26 August 2014; Revised Selected Papers, Part I. Springer: Cham, Switzerland, 2014. [Google Scholar] [CrossRef]
- Agostino, F.; Carlo, M.; Giuseppe, P.; Giandomenico, S. A Proximity-Based Self-Organizing Framework for Service Composition and Discovery. In Proceedings of the 2010 10th IEEE/ACM International Conference on Cluster, Cloud and Grid Computing, Melbourne, Australia, 17–20 May 2010. [Google Scholar] [CrossRef]
- Núñez, D.; Ferrada, X.; Neyem, A.; Serpell, A.; Sepúlveda, M. A User-Centered Mobile Cloud Computing Platform for Improving Knowledge Management in Small-to-Medium Enterprises in the Chilean Construction Industry. Appl. Sci. 2018, 8, 516. [Google Scholar] [CrossRef]
- Anurag, R.; Puja, G.; Prapti, G.; Sunital, V.; Sharma, K.K.; Upendra, S. Study of Cloud Providers (Azure, Amazon, and Oracle) According To Service Availability and Price. In Proceedings of the 2023 3rd International Conference on Pervasive Computing and Social Networking (ICPCSN), Salem, India, 19–20 June 2023. [Google Scholar] [CrossRef]
- Lakshmi, D.C. Impact study of cloud computing on business development. Oper. Res. Appl. Int. J. 2014, 1, 1–7. [Google Scholar]
- Marston, S.; Li, Z.; Bandyopadhyay, S.; Zhang, J.; Ghalsasi, A. Cloud computing—The business perspective. Decis. Support Syst. 2011, 51, 176–189. [Google Scholar] [CrossRef]
- Voith, T.; Oberle, K.; Stein, M. Quality of service provisioning for distributed data center inter-connectivity enabled by network virtualization. Future Gener. Comput. Syst. 2012, 28, 554–562. [Google Scholar] [CrossRef]
- Zia-ur, R.; Omar, K.H.; Farookh, K.H. User-side cloud service management: State-of-the-art and future directions. J. Netw. Comput. Appl. 2015, 55, 108–122. [Google Scholar]
- Adam, C.; Stadler, R. Service middleware for self-managing large-scale systems. IEEE Trans. Netw. Serv. Manag. 2007, 4, 50–64. [Google Scholar] [CrossRef]
- Zhao, S.; Li, L.; Ling, X.; Xu, C.; Yang, J. Architecture and scheduling scheme design of TsinghuaCloud based on OpenStack. J. Comput. Appl. 2013, 33, 3335–3338. [Google Scholar] [CrossRef]
- Deng, Z.; Duan, Z.; Li, L. Research of dynamic scheduling of resources under the environment of OpenStack. J. Northwestern Polytech. Univ. 2016, 34, 650–655. [Google Scholar]
- Website of Huawei Cloud Stack Guide, Managing User Groups, Creating a User Group. Available online: https://support.huawei.com/enterprise/en/doc/EDOC1100296026/3a95b21f/managing-user-groups (accessed on 21 December 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | System Architecture | Load Balance of Workload | Multi-User Management |
|---|---|---|---|
| 1 | Infrastructure of multiple data lefts (MDC) | An open-source scheduler was introduced to perform load balance | No multi-user-management system automatic synchronization within all the architecture |
| 2 | Hierarchical architecture of EcoMultiCloud | An efficient management of the workload was included | |
| 3 | Major cloud service providers, such as Alibaba Cloud and Huawei Cloud | Some open-source and commercial scheduling software within cloud service providers | |
| 4 | OpenStack open-source cloud | Some open-source scheduling software was integrated in OpenStack |
| Quality of Service | Concurrent Connections | ||
|---|---|---|---|
| Complete requests | 200 | 500 | 1000 |
| File size (KB) | 1024 | 10,240 | 40,960 |
| Time cost (s) | 1.02 | 1.05 | 1.15 |
| Transfer rate (KB/s) | 1003.90 | 9752.38 | 35,617.39 |
| No. | CPU Threads | Memory (GB) | Disk Capacity (GB) |
|---|---|---|---|
| 1 | 64 | 128 | 100 |
| 2 | 32 | 64 | 100 |
| 3 | 16 | 32 | 100 |
| No. | System Architecture | Time of User Registration (s) | Time of User Authentication Synchronization (s) | Total Time (s) |
|---|---|---|---|---|
| 1 | OpenStack Private Cloud Platform (OPCP) | 6 | 3 | 9 |
| 2 | Infrastructure of multiple data centers (MDC) | 7 | 10 | 17 |
| 3 | Huawei Cloud platform | 6 | 12 | 18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Wang, Z.; Zhang, W. Automatically Expanding User-Management System for Massive Users in the Cloud Platform. Appl. Sci. 2024, 14, 2549. https://doi.org/10.3390/app14062549
Li S, Wang Z, Zhang W. Automatically Expanding User-Management System for Massive Users in the Cloud Platform. Applied Sciences. 2024; 14(6):2549. https://doi.org/10.3390/app14062549
Chicago/Turabian StyleLi, Shengyang, Zhen Wang, and Wanfeng Zhang. 2024. "Automatically Expanding User-Management System for Massive Users in the Cloud Platform" Applied Sciences 14, no. 6: 2549. https://doi.org/10.3390/app14062549
APA StyleLi, S., Wang, Z., & Zhang, W. (2024). Automatically Expanding User-Management System for Massive Users in the Cloud Platform. Applied Sciences, 14(6), 2549. https://doi.org/10.3390/app14062549