1. Introduction
In practical scenarios such as Optical Character Recognition (OCR) and input methods, Chinese spelling errors frequently occur due to the similarities in both pronunciation and visual appearance of Chinese characters. Specifically, misspelled characters might arise when utilizing optical character recognition, speech recognition, or Chinese input methods such as Pinyin input (phonetic-based), Wubi input (shape-based), and handwriting input. An important step to tackle the problem of Chinese spelling errors is the CSC model’s performance in computational efficiency and accuracy. According to Liu et al. [
1], sound similarity and shape similarity account for 83% and 48% of spelling errors, respectively. Therefore, the main task of the CSC is aiming to detect and correct misspelled characters with similar pronunciation or similar shape. Currently, the CSC is still a challenging task. In the existing CSC models, the effects of spelling check are far from satisfactory, owing to the model’s inability to learn Chinese semantics and the difficulty to screen out the correct characters from a large number of candidate characters.
Compared with the effective spelling check based on rules and vocabulary in English, the CSC task is more arduous since there is no clear delimiter between words in a Chinese sentence. For a single English word, multiple Chinese characters might be required to represent the same idea. For example, when expressing the English word "China” in Chinese, we must employ a combination of two Chinese characters. The former pronunciation is “” which means ’middle’, and the latter pronunciation is “” which means ’country’. If feature vectors based on character granularity are used, the relationship between the current character and other characters in the sentence cannot be fully extracted.
While the semantic integrity of words can be ensured by using word granularity-based feature vector extraction, it involves text segmentation, which is prone to errors. For example, the Chinese phrase “
” translates to ’an innocent child’ in English. This phrase conveys the idea of a child who is pure and without guilt. More specifically, the Chinese term “
” translates to ’an’ in English, while “
” and “
” translate to ’innocent’ and ’child’, respectively. However, if the Chinese word “
” is split into “
” and “
”, their English translations are ’sky’ and ’true’ respectively. This can result in a meaning that is significantly different from the original sentence. As shown in
Figure 1, if this Chinese phrase is segmented incorrectly as ’
’ (lit. ’an/sky/true/child’), the resulting sentence will be semantically unintelligible and difficult to understand. Therefore, “
” (meaning ’innocent’) should be used as an inseparable phrasal adjective. If training is carried out with the incorrect word segmentation results, the semantic output of the word vectors after training will have a certain deviation, which will, to some extent, influence the CSC task. Therefore, Chinese spelling detection is pivot to Chinese spelling correction. For the detection phase, it is significantly more difficult to detect spelling errors at the character level than it is at the sentence and phrase level.
Furthermore, the CSC requires some background information and contextual reasoning ability to obtain a desirable spelling correction performance. Two sets of examples are shown in
Table 1. In the first example, the word “vector” is a mathematical term that is wrongly transcribed as “elephant” because they have similar pronunciations “
” in Chinese. This example shows that the CSC requires certain background information to detect and correct spelling errors. In the second example, the words “late” and “equator” are pronounced “
” in Chinese, so that they are misused. By incorporating the Chinese context “
” (lit. ’go to school’), it can be deduced that the correct word should be “late”.
The CSC models can be roughly divided into two categories: the traditional CSC models and those based on deep learning. The traditional CSC models share a similar pipeline scheme: first, use the word segmentation tool to segment the sentence, then replace the suspicious Chinese characters with the confusion set, and finally score the sentence via language models and select the sentence with the highest score as the CSC result. Liu et al. [
2] developed a hybrid CSC model, in which candidate characters for the misspelled character are generated first by using models based on statistical machine translation and language, and then the correct candidate character is screened out via SVM [
3] classifier. Based on N-gram, traditional models tend to have limitations since the N-gram language model can only extract limited history information and cannot capture the future information. For the CSC models based on deep learning, Wang et al. [
4] proposed a sequence labeling-based method for Chinese spelling detection. Their spelling detection approach is innovative, but the feature vectors they adopted cannot adequately convey the relationship between the current characters and other characters in a sentence.
There are a lot of work using the sequence-to-sequence models, and they achieved good performance. However, most of the sequence-to-sequence models based on Bert are faced with the problem of overcorrection. When using the form of “error check first, then error correction”, the error correction model will obtain a priori information about the position of wrong characters. It can enable the model to avoid misjudgment that may be caused by context information.
In this paper, we propose a novel CSC framework Based on Multi-label Annotation (MLSL-Spell) that divides the CSC task into two sub-tasks: spelling detection and spelling correction. First, the MLSL-Spell detection model takes Chinese characters as the unit, fuses the pre-trained context vectors and the Pinyin vector, and delivers them to the neural network model for sequence labeling. After fully learning the contextual information between the characters, the detection model outputs the labeled character sequence, which corresponds to the Chinese characters in the original sentence. If the current Chinese character is correct, it will be labeled as “T”. If the current Chinese character is detected as an error of similar pronunciation, it will be labeled as “P”; if it is detected as an error of similar shape, it will be labeled as “S”; if the detected error belongs both to similar pronunciation and shape, it is labeled as “B”; if it is an error of other types, it will be labeled as “O”.
As for the spelling correction module of MLSL-Spell, it receives the character sequence output from the spelling detection module, and corrects the misspelled Chinese characters that are detected. MLSL-Spell employs the Masked Language Model (MLM) [
5] model to replace the wrong character with “[MASK]”, infers the character at the wrong position through the contextual information, generates possible candidates for the misspelled character, and then performs corresponding screenings according to the types of error to generate the final candidates. For different types of spelling errors, MLSL-Spell adopts different candidate strategies to extract character features. In the end, MLSL-Spell uses XGBoost [
6] classifier to screen out the correct characters.
We conducted experiments on three public datasets. The results reveal that the MLSL-Spell model outperforms all other contrast models in terms of CSC’s indicators. The contributions of this paper are as follows:
1. In order to fully extract the contextual information and correct the errors according to the corresponding error types, we propose MLSL-Spell, a CSC model based on pre-training context vectors and multi-label annotation.
2. Taking into account the Pinyin information of Chinese characters and the contextual information between characters, the spelling detection module of MLSL-Spell fuses the pre-trained context vectors and Pinyin vectors and uses multiple tags for sequence labeling. Moreover, its spelling correction module uses MLM model and the XGBoost classifier to screen out the correct characters.
3. Compared with the CSC model proposed recently by Wang et al. [
7], MLSL-Spell model has better CSC performance on two public datasets. On SIGHAN 2013 dataset, the spelling detection F1 score of MLSL-Spell is 18.3% higher than that of the pointer network (PN) model, and the spelling correction F1 score is 10.9% higher. On SIGHAN 2015 dataset, the spelling detection F1 score of MLSL-Spell is 15.7% higher than that of the PN model, and the spelling correction F1 score is 6.8% higher.
The rest of the paper is organized as follows. In
Section 2, the literature on the existing CSC models, including traditional ones and deep learning-based ones, is given. In
Section 3, we describe our proposed MLSL-Spell model.
Section 4 presents the experimental setup and experimental results. Finally, we provide conclusions and a summary in
Section 6.
2. Related Work
Due to the significance of CSC tasks in downstream processes such as OCR and input methods, an increasing number of researchers are dedicating their efforts to this field. For traditional CSC models, Xie et al. [
8] proposed a model of joint bigram, trigram, and Chinese word segmentation. Liu et al. [
2] combined the candidate sets selected respectively by the language model based on word segmentation and the statistical translation model and re-scored the correct characters with the SVM classifier. Yu et al. [
9] employed a character-based N-gram language model to detect potential misspelled characters with probability below the predefined threshold, and to generate a candidate set of similar pronunciation and shape for each potential misspelled character; then they screened out the candidate characters with the highest probability through the language model. Chiu et al. [
10] devised a CSC method based on similar pronunciation or shape. It relies on a Web corpus to classify similar characters and uses a character-based language model in the channel model and noise model to correct spelling errors. Jia et al. [
11] applied a graph model to the CSC task and performed a single-source shortest path algorithm on the graph to correct spelling errors. Han et al. [
12] approached CSC by training a maximum entropy model on a large corpus, treating CSC as a binary classification task. Xiong et al. [
13] proposed a method based on Logistic Regression (LR), which used confusion sets to replace text to generate new sentences, then extracted the text features of the new sentences, and used the LR model to screen out the correct sentences.
For CSC models based on deep learning, Duan et al. [
14] introduced a new neural network architecture integrating bidirectional LSTM model and CRF model, which took the character sequence of the sentence as input. The bidirectional LSTM layer first learns the character sequence information before sending the probability vectors to CRF layer, which then outputs best-predicted label sequence as the spelling detection result. And then there is a FL-LSTM-CRF model (Wang et al. [
15]). As an extension of the LSTM-CRF model, it combines word lattice, character, and Pinyin information to perform Chinese spelling detection. Wang et al. [
4] put forward a novel method CSC dataset construction approach based on OCR and ASR. Then, in order to verify the validity of the dataset, they employed a sequence labeling-based approach to detect Chinese spelling. Moreover, Wang et al. [
7] designed an end-to-end pointer network model, through which the correct character could be copied from the input character list or generated from the confusion set instead of from the entire vocabulary. Hong et al. [
16] implemented a CSC model composed of an autoencoder and a decoder. The model has a simple structure, and faster calculation speed, and is easier to adapt to simplified or traditional Chinese text generated by humans or machines. Zhang et al. [
17] based their CSC model on BERT. The spelling detection network is connected to the spelling correction network through soft-masking technology. Chen et al. [
18] integrated Pinyin and character similarity knowledge into the language model via a customized graph convolutional neural network. Later, an end-to-end trainable model emerged (Huang et al. [
19]), which uses multi-channel information to improve the performance of CSC. A chunk-based framework for uniformly correcting single-character and multi-character word errors was presented by Bao et al. [
20]. Gou et al. [
21] implemented performing a post-processing operation on the error correction tasks. Nguyen et al. [
22] proposed a scalable adaptable filter that exploits hierarchical character embeddings. A significant amount of work emerged subsequently, such as Zhang et al. [
23], Wang et al. [
24], PLOME [
25], REALISE [
26], SpellBERT [
27], LEAD [
28], Liang et al. [
29], and PTCSpell [
30], attempting to integrate glyph or pronunciation information into models. For example, Zhang et al. [
23] designed an end-to-end model that integrated phonetics into the language model by leveraging the powerful pre-training and fine-tuning method. REALISE [
26] used a gating mechanism to fuse visual and pronunciation information. PTCSpell [
30] designed two novel pre-training objectives to capture pronunciation and shape information in Chinese characters. Another segment of research, including ECOPO [
31], CRASpell [
32], CoSPA [
33], EDMSpell [
34], and Wu et al. [
35], focused on addressing the issue of the overcorrection in the model. For instance, ECOPO [
31] introduced contrast learning to the CSC task. EDMSpell [
34] reduced overcorrection of the model through post-processing. Wu et al. [
35] employed different masking and substitution strategies to obtain a better language model.
3. Approach
In this section, we will introduce our CSC model in detail. Here are the steps of performing CSC tasks in MLSL-Spell model: firstly, initialize randomly the Pinyin vectors and then fuse the pre-trained context vectors and the Pinyin vectors; secondly, send the fusion vectors to the sequence labeling framework composed of bidirectional GRU [
36] neural network and CRF [
37] model for multi-label annotation.Compared with LSTM, GRU has fewer parameters and uses a simpler structure to achieve the same effect. And the calculation efficiency of GRU is higher. For the original RNN, it is difficult to obtain the relevant information about the long distance in the sentence.; thirdly, generate candidate characters for the misspelled characters through MLM model; fourthly, perform corresponding screening according to the error types, and generate the final candidate characters. In the end, for different error types, MLSL-Spell adopts varied feature extraction strategies of candidate character. After extracting the features of the candidate characters, MLSL-Spell employs XGBoost classifier to screen out the correct characters. The framework of MLSL-Spell model is shown in
Figure 2.
3.1. Spelling Detection of MLSL-Spell
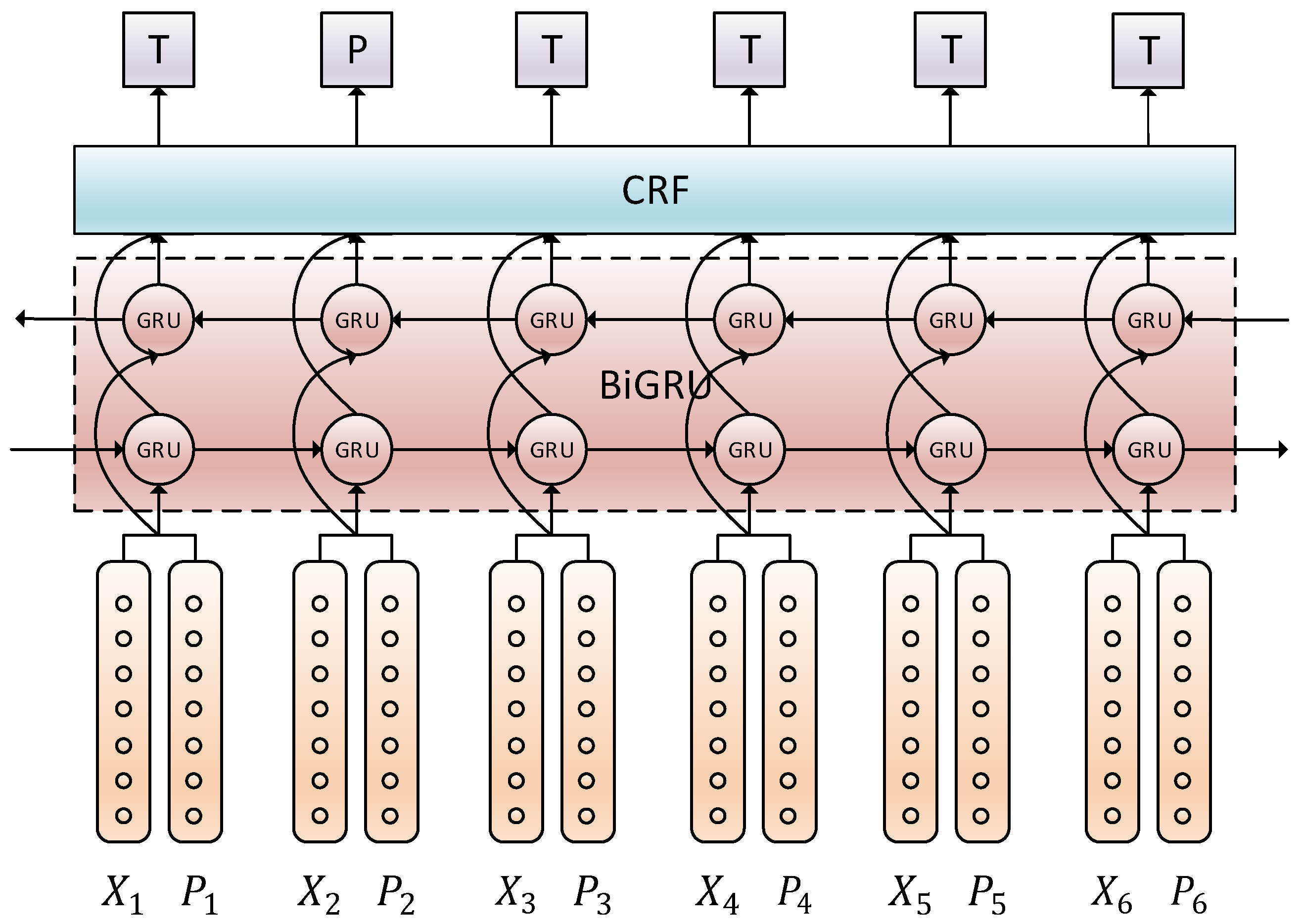
MLSL-Spell’s spelling detection module is shown in
Figure 3. Suppose the sentence to be corrected is formulated as
and the label sequence output after spelling detection as
, where
represents a Chinese character,
denotes “T”, “P”, “S”, “B” or “O”, and
i refers to the position of the Chinese character in the sentence. We fuse the context vector
and the Pinyin vector
(each pair of
and
corresponds to one character in the sentence) into the vector
, and input it to the bidirectional GRU model. The calculation formula of the fusion vector is as follows:
The hidden layer vector
of a certain direction at the current time step depends on the fusion vector
at the current time step and the hidden layer vector
at the previous time step. We concatenate the hidden layer vectors in each direction as the output vector of the BiGRU model. The calculation formulas are shown below.
In the bidirectional GRU model, the hidden layer vectors fully learn the contextual information under the current sentence meaning. Next, MLSL-Spell sends the trained hidden layer vectors to CRF model to label the text in sequence. We use a linear function to normalize the hidden layer vector at each time step and obtain the respective scores of the five labels. With these scores attained, we can calculate the emission matrix of CRF,
, where
n is the length of the input sentence, and
k represents the number of the labels. In this paper, we define 5 subtypes of the sequence label: “T”, “P”, “S”, “B” and “O”, representing the correct character, the misspelled character of similar pronunciation, misspelled character of similar shape, misspelled character of both similar pronunciation and similar shape, and the misspelled character caused by other reasons, respectively. Therefore,
k equals 5. The calculation formula of CRF model for constructing the emission matrix is as follows:
CRF model calculates the scores of sequence labels through the emission matrix and the label transfer matrix. The calculation formulas are as follows:
We adopt the negative logarithmic maximum likelihood function as the loss function of the model, as shown below:
y represents the real label corresponding to
X. In the end, we adopt the label sequence with the highest probability as the spelling detection result of MLSL-Spell, which is formulated as follows:
In addition, we use the adamW optimizer to optimize it, which has the L2 regularization and higher computational efficiency than the adam optimizer.
3.2. Spelling Correction of MLSL-Spell
For the misspelled characters detected by MLSL-Spell model, we replace them with “[MASK]”, and then use MLM model to infer candidate characters at the masking positions, from which we select Top 100 characters as candidate characters. If the misspelled Chinese character at the current position is a type of similar pronunciation, candidates will be screened by a similar-pronunciation confusion set. If it is a type of similar shape, candidates will be screened by a similar-shape confusion set. If it is a type of similar pronunciation and shape, candidates will be screened by the confusion set of both similar pronunciation and shape.
The number of candidate character should not be too large or too small. If it is too small, there will be fewer candidates available for the model, and the error correction ability of the model will decrease theoretically and intuitively. At the same time, if it is too large, the larger value of k makes the model get more possible candidates. But the possibility of these candidates is so very low that they can provide little help to the model. And it will increase the computational of the model to a certain extent. Based on this experience, we decided to set the number of candidate character to 100.
Additionally, We use pre-trained MLM model and it is not trained separately. But we don’t need to solve the problem of domain adaptation. Our error correction model has obtained a priori knowledge of the error location. In this case, we just need to mark the error characters as “[MASK]” and send the sentence to the MLM model. When using the MLM model, our tasks and goals are consistent with the original MLM model.
We extract the following features from the final candidate characters: (1) the change in the number of word segmentation before and after replacing the misspelled character with the candidate character; (2) the change in the perplexity of the sentence before and after replacing the misspelled character with the candidate character; (3) the Pinyin edit distance between the candidate character and the misspelled character; (4) whether or not the misspelled character is a stop word. After extracting the features of the candidate characters, we use the trained XGBoost classifier to screen out the correct characters. The architecture of MLSL-Spell’s spelling correction module is shown in
Figure 4.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}