
Teacher–Student Model Using Grounding DINO and You Only Look Once for Multi-Sensor-Based Object Detection

Abstract
1. Introduction
2. Related Work
2.1. Object Detection
2.2. Research on Utilizing Various Video Sources
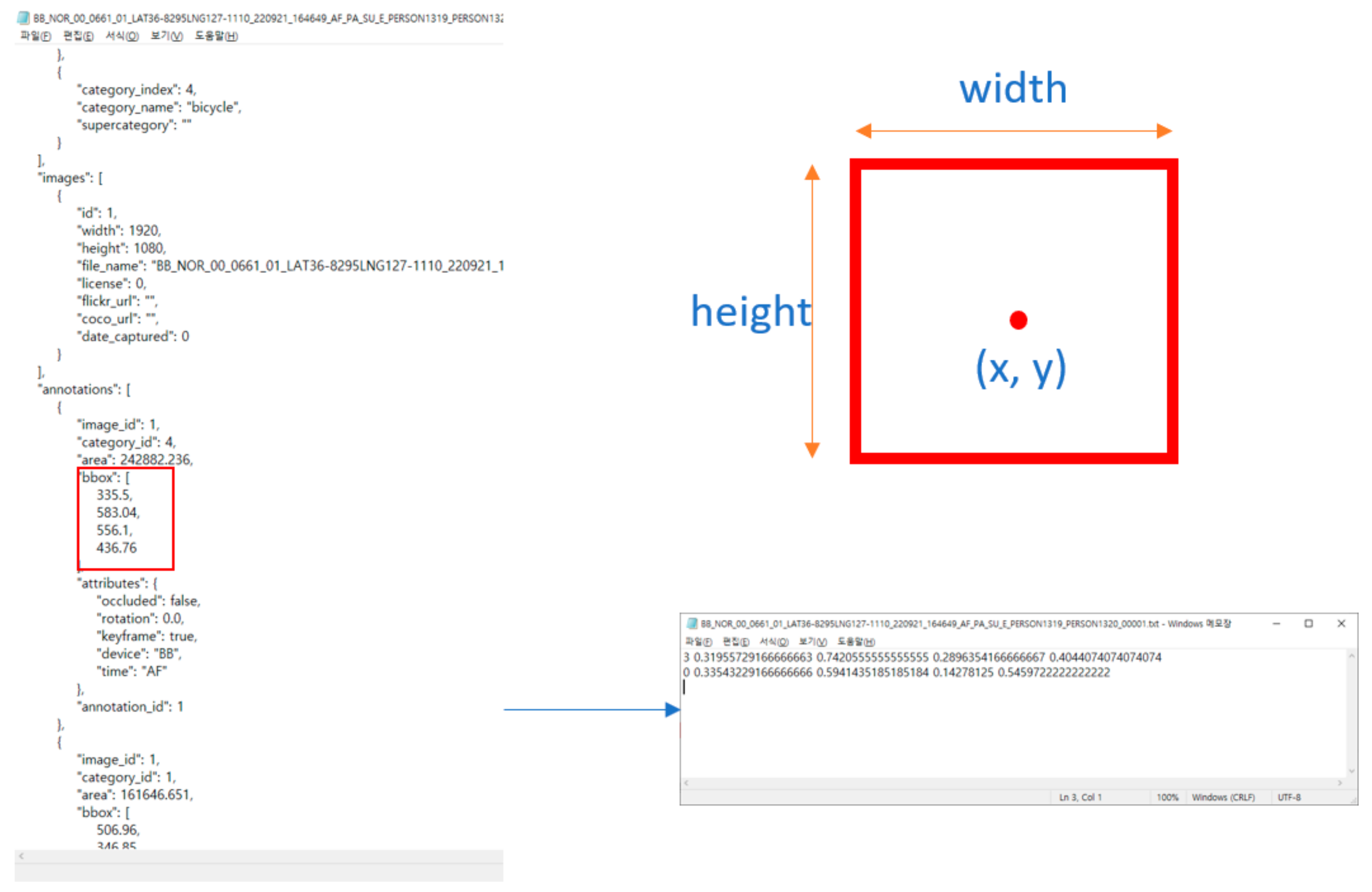
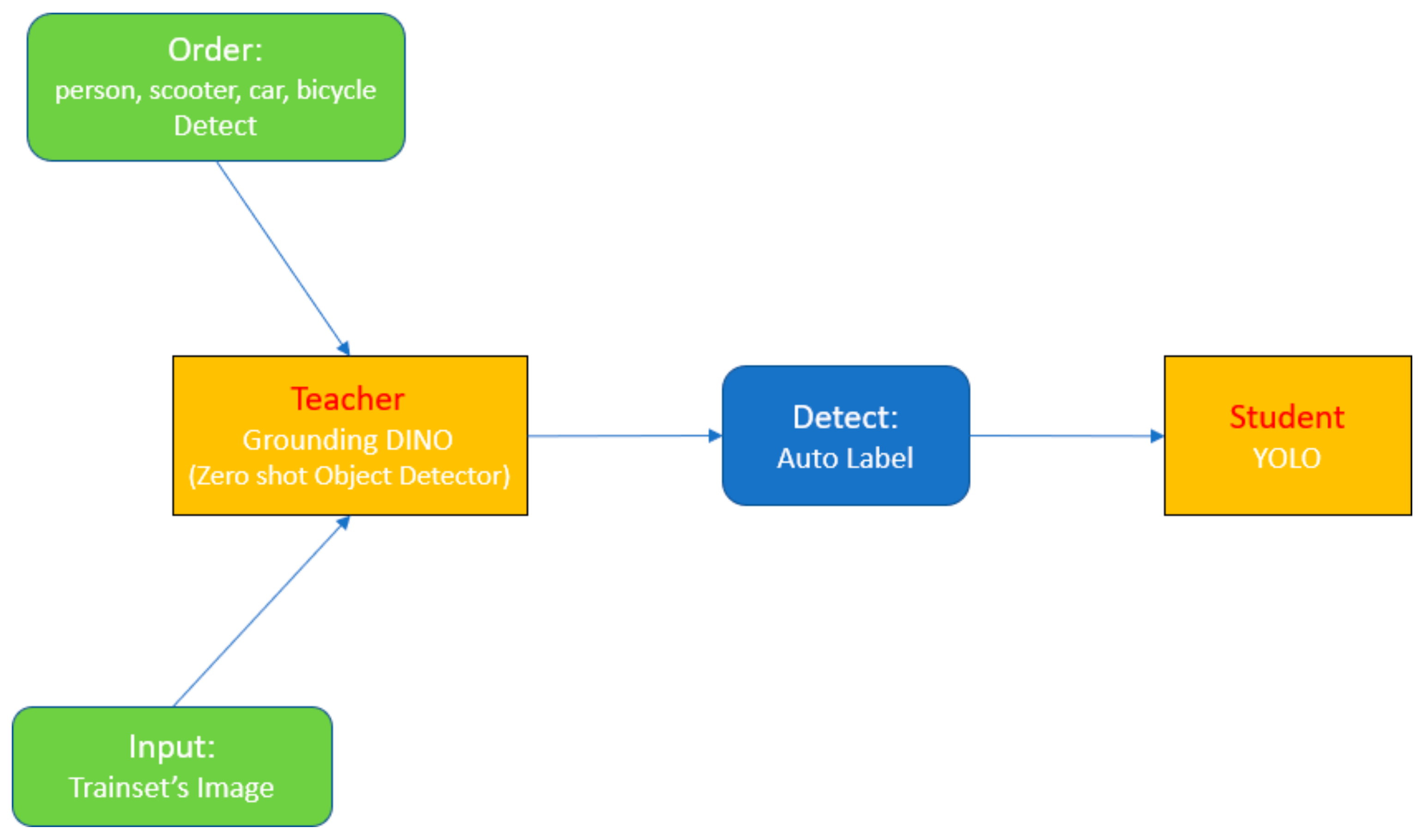
3. Proposed Method
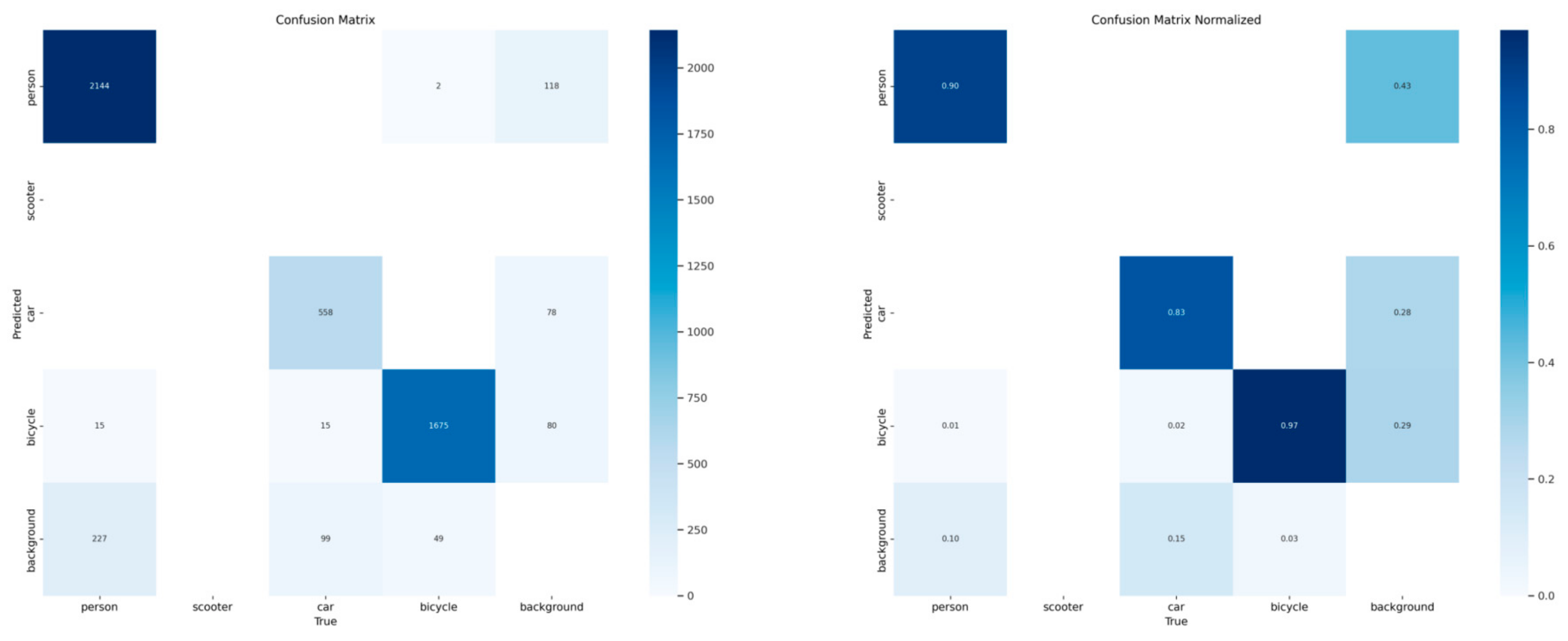
4. Experiments and Results
4.1. Dataset Group Splitting
4.2. Manual Label-Based Object Detection Experiment
4.3. Auto-Label-Based Object Detection Experiment
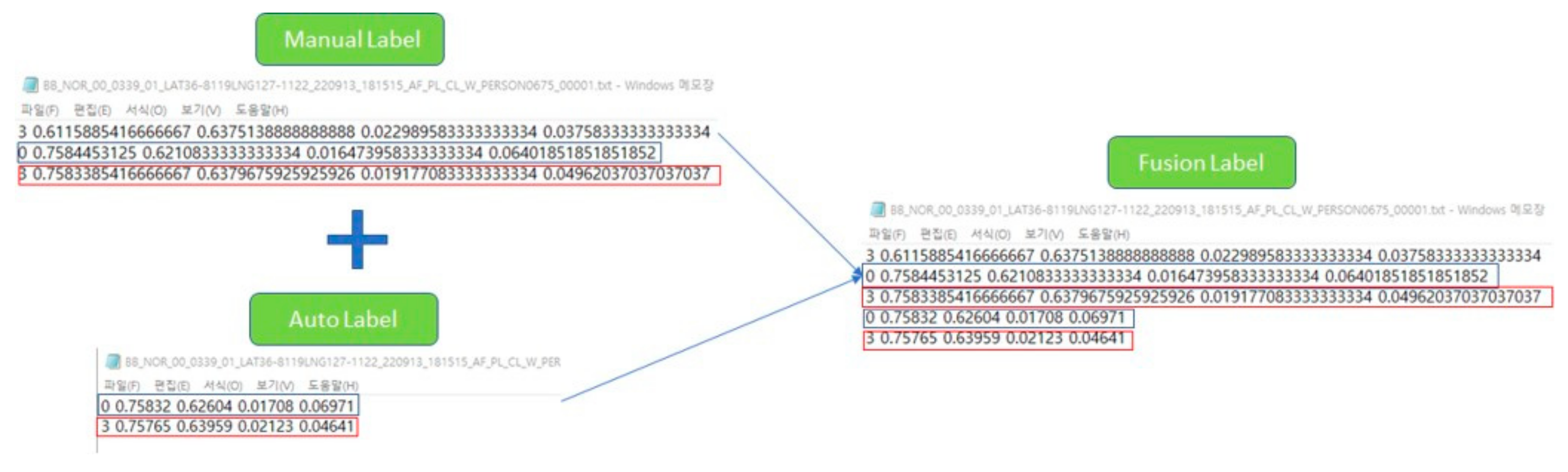
4.4. Combining Manual and Auto-Labels for Object Detection Experiment
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lyon, D. Surveillance technology and surveillance society. Mod. Technol. 2003, 161, 184. [Google Scholar]
- Lyon, D. Surveillance, power and everyday life. In Emerging Digital Spaces in Contemporary Society: Properties of Technology; Palgrave Macmillan: London, UK, 2010; pp. 107–120. [Google Scholar]
- Javed, A.R.; Shahzad, F.; ur Rehman, S.; Zikria, Y.B.; Razzak, I.; Jalil, Z.; Xu, G. Future smart cities: Requirements, emerging technologies, applications, challenges, and future aspects. Cities 2022, 129, 103794. [Google Scholar] [CrossRef]
- Murugesan, M.; Thilagamani, S. Efficient anomaly detection in surveillance videos based on multi layer perception recurrent neural network. Microprocess. Microsyst. 2020, 79, 103303. [Google Scholar] [CrossRef]
- Jha, S.; Seo, C.; Yang, E.; Joshi, G.P. Real time object detection and trackingsystem for video surveillance system. Multimed. Tools Appl. 2021, 80, 3981–3996. [Google Scholar] [CrossRef]
- Hashmi, M.F.; Pal, R.; Saxena, R.; Keskar, A.G. A new approach for real time object detection and tracking on high resolution and multi-camera surveillance videos using GPU. J. Cent. South Univ. 2016, 23, 130–144. [Google Scholar] [CrossRef]
- Strbac, B.; Gostovic, M.; Lukac, Z.; Samardzija, D. YOLO multi-camera object detection and distance estimation. In Proceedings of the 2020 Zooming Innovation in Consumer Technologies Conference (ZINC), Novi Sad, Serbia, 26–27 May 2020; pp. 26–30. [Google Scholar]
- Chandan, G.; Jain, A.; Jain, H. Real time object detection and tracking using Deep Learning and OpenCV. In Proceedings of the 2018 International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 11–12 July 2018; pp. 1305–1308. [Google Scholar]
- Bhatti, M.T.; Khan, M.G.; Aslam, M.; Fiaz, M.J. Weapon detection in real-time cctv videos using deep learning. IEEE Access 2021, 9, 34366–34382. [Google Scholar] [CrossRef]
- Dimou, A.; Medentzidou, P.; Garcia, F.A.; Daras, P. Multi-target detection in CCTV footage for tracking applications using deep learning techniques. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 928–932. [Google Scholar]
- Gavrilescu, R.; Zet, C.; Foșalău, C.; Skoczylas, M.; Cotovanu, D. Faster R-CNN: An approach to real-time object detection. In Proceedings of the 2018 International Conference and Exposition on Electrical and Power Engineering (EPE), Iasi, Romania, 18–19 October 2018; pp. 165–168. [Google Scholar]
- Chan, F.H.; Chen, Y.T.; Xiang, Y.; Sun, M. Anticipating accidents in dashcam videos. In Proceedings of the Computer Vision—ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Revised Selected Papers, Part IV 13. Springer: Berlin/Heidelberg, Germany, 2017; pp. 136–153. [Google Scholar]
- Haresh, S.; Kumar, S.; Zia, M.Z.; Tran, Q.H. Towards anomaly detection in dashcam videos. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1407–1414. [Google Scholar]
- Sen, S.; Chakraborty, D.; Ghosh, B.; Roy, B.D.; Das, K.; Anand, J.; Maiti, A. Pothole Detection System Using Object Detection through Dash Cam Video Feed. In Proceedings of the 2023 International Conference for Advancement in Technology (ICONAT), Goa, India, 24–26 January 2023; pp. 1–6. [Google Scholar]
- Chen, J.W.; Lin, W.J.; Cheng, H.J.; Hung, C.L.; Lin, C.Y.; Chen, S.P. A smartphone-based application for scale pest detection using multiple-object detection methods. Electronics 2021, 10, 372. [Google Scholar] [CrossRef]
- Jeong, K.; Moon, H. Object detection using FAST corner detector based on smartphone platforms. In Proceedings of the 2011 First ACIS/JNU International Conference on Computers, Networks, Systems and Industrial Engineering, Jeju, Republic of Korea, 23–25 May 2011; pp. 111–115. [Google Scholar]
- Martinez-Alpiste, I.; Golcarenarenji, G.; Wang, Q.; Alcaraz-Calero, J.M. Smartphone-based real-time object recognition architecture for portable and constrained systems. J. Real-Time Image Process. 2022, 19, 103–115. [Google Scholar] [CrossRef]
- Aziz, L.; Salam MS, B.H.; Sheikh, U.U.; Ayub, S. Exploring deep learning-based architecture, strategies, applications and current trends in generic object detection: A comprehensive review. IEEE Access 2020, 8, 170461–170495. [Google Scholar] [CrossRef]
- Xiao, Y.; Tian, Z.; Yu, J.; Zhang, Y.; Liu, S.; Du, S.; Lan, X. A review of object detection based on deep learning. Multimed. Tools Appl. 2020, 79, 23729–23791. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; pp. I-511–I-518. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2015; p. 28. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Shum, H.Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Liu, S.; Zeng, Z.; Ren, T.; Li, F.; Zhang, H.; Yang, J.; Zhang, L. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv 2023, arXiv:2303.05499. [Google Scholar]
- Terven, J.; Cordova-esparza, D. A comprehensive review of YOLO: From YOLOv1 to YOLOv8 and beyond. arXiv 2023, arXiv:2304.00501. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CT | BB | SP | Total | |
|---|---|---|---|---|
| Train | 2088 | 2088 | 2087 | 6263 |
| Validation | 576 | 576 | 576 | 1728 |
| Test | 1147 | 1152 | 1141 | 3440 |
| Total | 3811 | 3816 | 3804 | 11,431 |
| CT | BB | SP | Total | |
|---|---|---|---|---|
| Training Group 1 (CT, BB, SP) | 2088 | 2088 | 2087 | 6263 |
| Training Group 2 (CT) | 2088 | 2088 | ||
| Training Group 3 (BB) | 2088 | 2088 | ||
| Training Group 4 (SP) | 2087 | 2087 | ||
| Training Group 5 (CT, BB) | 2088 | 2088 | 4176 | |
| Training Group 6 (CT, SP) | 2088 | 2087 | 4175 | |
| Training Group 7 (BB, SP) | 2088 | 2087 | 4175 |
| CT | BB | SP | Total | |
|---|---|---|---|---|
| Validation Group 1 (CT, BB, SP) | 576 | 576 | 576 | 1728 |
| Validation Group 2 (CT) | 576 | 576 | ||
| Validation Group 3 (BB) | 576 | 576 | ||
| Validation Group 4 (SP) | 576 | 576 | ||
| Validation Group 5 (CT, BB) | 576 | 576 | 1152 | |
| Validation Group 6 (CT, SP) | 576 | 576 | 1152 | |
| Validation Group 7 (BB, SP) | 576 | 576 | 1152 |
| CT | BB | SP | Total | |
|---|---|---|---|---|
| Test Group 1 (CT, BB, SP) | 1147 | 1152 | 1141 | 3440 |
| Test Group 2 (CT) | 1147 | 1147 | ||
| Test Group 3 (BB) | 1152 | 1152 | ||
| Test Group 4 (SP) | 1141 | 1141 |
| Test Group | Group 1 mAP50 | Group 2 mAP50 | Group 3 mAP50 | Group 4 mAP50 | |
|---|---|---|---|---|---|
| Training Group | |||||
| Group 1 (CT, BB, SP) | 0.618 | 0.618 | 0.555 | 0.706 | |
| Group 2 (CT) | 0.494 | 0.636 | 0.368 | 0.479 | |
| Group 3 (BB) | 0.459 | 0.306 | 0.478 | 0.662 | |
| Group 4 (SP) | 0.558 | 0.418 | 0.597 | 0.732 | |
| Group 5 (CT, BB) | 0.548 | 0.612 | 0.498 | 0.541 | |
| Group 6 (CT, SP) | 0.627 | 0.591 | 0.626 | 0.706 | |
| Group 7 (BB, SP) | 0.579 | 0.434 | 0.586 | 0.783 | |
| Test Group | Group 1 mAP50 | Group 2 mAP50 | Group 3 mAP50 | Group 4 mAP50 | |
|---|---|---|---|---|---|
| Training Group | |||||
| Group 1 (CT, BB, SP)100 epoch | 0.467 | 0.474 | 0.402 | 0.536 | |
| Group 1 (CT, BB, SP)200 epoch | 0.508 | 0.496 | 0.499 | 0.537 | |
| Group 2 (CT) | 0.276 | 0.393 | 0.187 | 0.287 | |
| Group 3 (BB) | 0.117 | 0.0391 | 0.123 | 0.234 | |
| Group 4 (SP) | 0.264 | 0.194 | 0.263 | 0.389 | |
| Group 5 (CT, BB) | 0.419 | 0.477 | 0.345 | 0.397 | |
| Group 6 (CT, SP) | 0.476 | 0.464 | 0.42 | 0.578 | |
| Group 7 (BB, SP) | 0.302 | 0.2 | 0.312 | 0.433 | |
| Test Group | Group 1 mAP50 | Group 2 mAP50 | Group 3 mAP50 | Group 4 mAP50 | |
|---|---|---|---|---|---|
| Training Group | |||||
| Group 1 (CT, BB, SP) | 0.644 | 0.627 | 0.639 | 0.676 | |
| Group 2 (CT) | 0.473 | 0.597 | 0.374 | 0.423 | |
| Group 3 (BB) | 0.458 | 0.345 | 0.495 | 0.555 | |
| Group 4 (SP) | 0.53 | 0.322 | 0.578 | 0.732 | |
| Group 5 (CT, BB) | 0.567 | 0.573 | 0.536 | 0.593 | |
| Group 6 (CT, SP) | 0.609 | 0.579 | 0.565 | 0.697 | |
| Group 7 (BB, SP) | 0.585 | 0.477 | 0.597 | 0.732 | |
| Test Group | Group 1 mAP50 | Group 2 mAP50 | Group 3 mAP50 | Group 4 mAP50 | |
|---|---|---|---|---|---|
| Training Group | |||||
| Group 1 (CT, BB, SP) | 0.652 | 0.608 | 0.635 | 0.757 | |
| Group 2 (CT) | 0.435 | 0.567 | 0.363 | 0.339 | |
| Group 3 (BB) | 0.465 | 0.365 | 0.485 | 0.607 | |
| Group 4 (SP) | 0.534 | 0.375 | 0.53 | 0.757 | |
| Group 5 (CT, BB) | 0.611 | 0.628 | 0.539 | 0.7 | |
| Group 6 (CT, SP) | 0.664 | 0.647 | 0.624 | 0.76 | |
| Group 7 (BB, SP) | 0.569 | 0.437 | 0.58 | 0.771 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Son, J.; Jung, H. Teacher–Student Model Using Grounding DINO and You Only Look Once for Multi-Sensor-Based Object Detection. Appl. Sci. 2024, 14, 2232. https://doi.org/10.3390/app14062232
Son J, Jung H. Teacher–Student Model Using Grounding DINO and You Only Look Once for Multi-Sensor-Based Object Detection. Applied Sciences. 2024; 14(6):2232. https://doi.org/10.3390/app14062232
Chicago/Turabian StyleSon, Jinhwan, and Heechul Jung. 2024. "Teacher–Student Model Using Grounding DINO and You Only Look Once for Multi-Sensor-Based Object Detection" Applied Sciences 14, no. 6: 2232. https://doi.org/10.3390/app14062232
APA StyleSon, J., & Jung, H. (2024). Teacher–Student Model Using Grounding DINO and You Only Look Once for Multi-Sensor-Based Object Detection. Applied Sciences, 14(6), 2232. https://doi.org/10.3390/app14062232