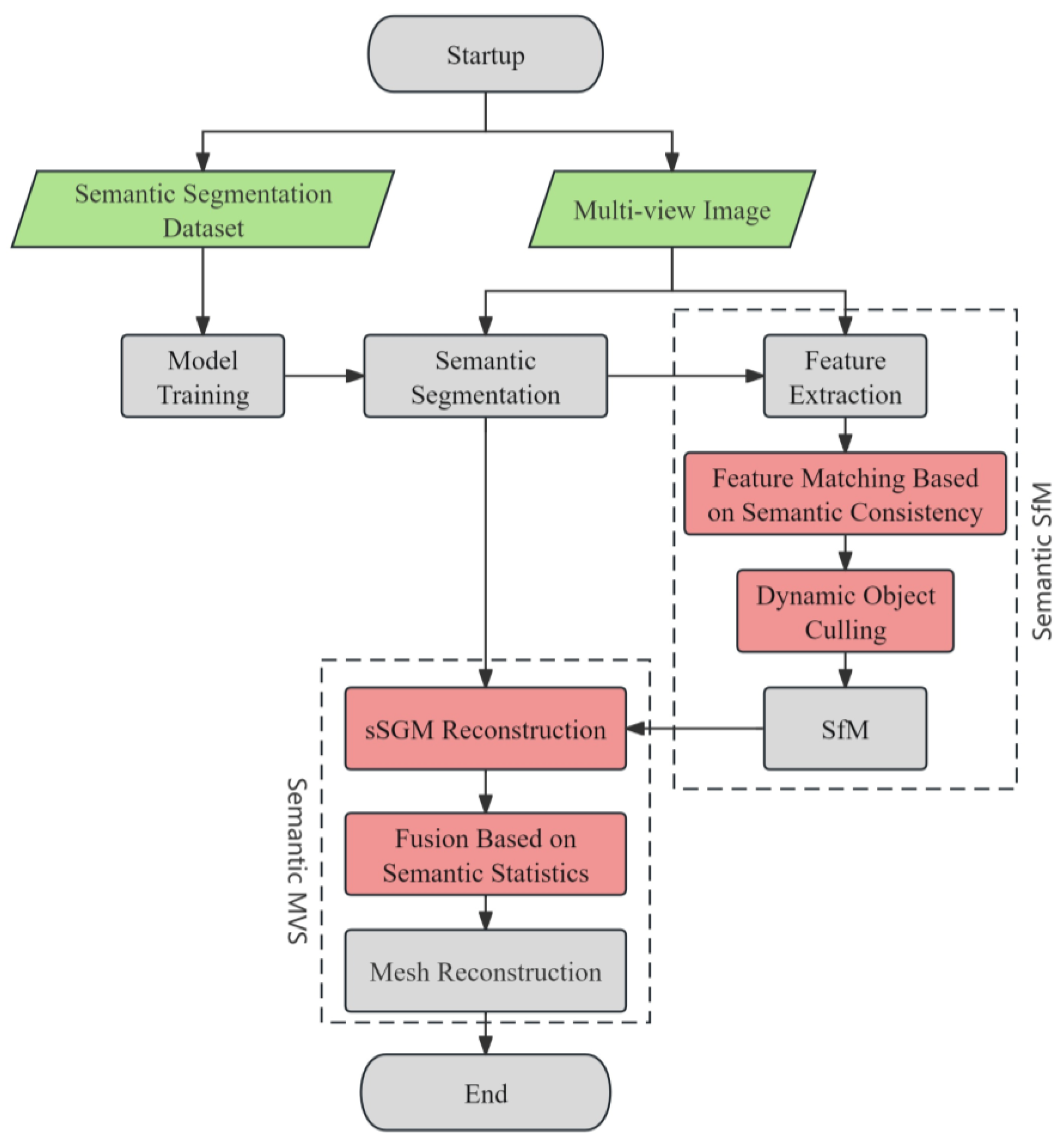
We first reorganized the categories in the Cityscapes dataset and employed three sets of semantic segmentation networks for training. We selected the network set with the highest segmentation accuracy to validate accuracy based on the reconstructed dataset. Upon achieving sufficient accuracy for semantic reconstruction, we performed semantic optimization for both sparse and dense reconstruction.
3.1. Semantic Segmentation for Complex Urban Scenes
We opted to utilize the MMSegmentation platform to train our semantic segmentation models [
34]. This platform has benchmarked models and datasets that it supports, significantly easing our model selection process. We analyzed the performance of all semantic segmentation networks supported by the platform using the Cityscapes dataset. We identified the top three semantic segmentation networks in terms of accuracy, including DeeplabV3+, Ocrnet, and Mask2Former. These networks were then trained using our new classification scheme, after which we compared the accuracy of the various networks.
In 2017, Chen conducted a study on atrous convolutions for image semantic segmentation (DeepLab V3) and employed atrous convolutions to expand the receptive field [
35]. This approach facilitated target segmentation on various scales by concatenating atrous convolutions with different dilation rates. In 2018, Chen proposed an architecture for image semantic segmentation by incorporating atrous separable convolutions within an encoder–decoder structure (DeepLab V3+) [
35]. This model aimed to integrate the best aspects of spatial pyramid pooling and the encoder–decoder framework, thereby creating a faster and more efficient overall model.
In the OCRNet (Object-Contextual Representations Network), a novel approach to constructing contextual information for semantic segmentation tasks is proposed which focuses on new object contextual information. By utilizing features corresponding to the object classes to describe pixels, this method transforms the pixel classification challenge into an object region classification problem, thereby explicitly enhancing object information [
36]. The High-Resolution Net (HRNet) is a specialized Convolutional Neural Network designed to retain high-resolution inputs throughout the network, thus enhancing the accuracy of pixel-level segmentation. Its primary goal is to improve semantic segmentation in high-resolution images while effectively managing the balance among multiple classes. This design ensures detailed and precise segmentation, which is particularly important in complex scenarios with diverse object categories [
37].
Mask2Former is composed of a backbone feature extractor, a pixel decoder, and a transformer decoder. The backbone feature extractor is typically a transformer model, such as Swin. The pixel decoder is a deconvolution network that gradually restores the feature map resolution to the original image size through deconvolution operations. Finally, the transformer decoder is used to manipulate image features to process object queries [
38,
39]. The equipment information used is shown in
Table 3.
The specific configurations for several networks are described below. We set the network batch size of OCR_hr48 to four and that of the other two networks to two. The number of training iterations was set to 100 epochs. Considering that both our reconstructed data and the Cityscape dataset images are not square, the image input for our segmentation network was set to 512 × 1024. During the training process, an SGD optimizer was used. Taking Mask2Former as an example, the semantic segmentation results of 3D reconstructed data are shown
Figure 5 below.
Pixel accuracy (
) is a metric that quantifies the proportion of correctly classified pixels in an image segmentation output relative to the total number of pixels. The formula is as follows:
where
denotes the number of target classes, and
refers to the number of pixels of class
predicted as class
. Another critical metric in the field of semantic segmentation is intersection over union (IoU). The IoU metric is based on the calculation that involves taking the intersection and the union of the predicted segmentation results and the actual segmentation results, followed by computing the ratio of the intersection to the union:
A lower IoU value signifies a closer approximation of the predicted segmentation to the actual segmentation, thus indicating higher accuracy and effectiveness of the model.
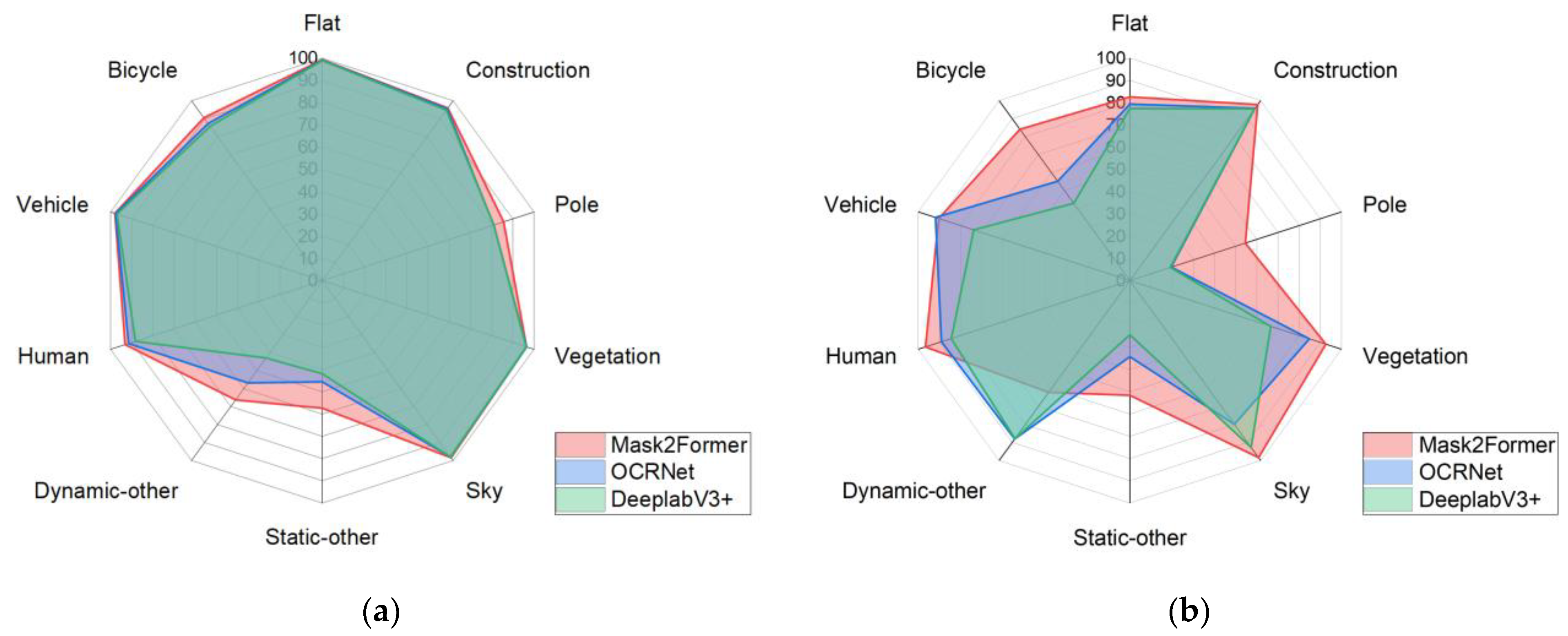
To validate the segmentation accuracy of the training results based on the Cityscape dataset and the reconstructed dataset, we annotated 10% of the reconstructed dataset and created a validation dataset for verification. We compared the semantic segmentation accuracy of the three best semantic segmentation networks using the reconstructed dataset. The results are shown in
Figure 6.
Figure 6 shows the validation accuracy when the networks were trained internally on the Cityscape dataset and the validation accuracy when trained on the reconstructed dataset. Since the dynamic-other and static-other classes inherently occupy a small proportion of the scenes, and static targets do not significantly affect our reconstruction, the segmentation accuracy is overall acceptable. In this comparison, we examined the Mask2Former, OCRNet, and DeepLabV3+ networks, which are three types of semantic segmentation networks. Among them, Mask2Former achieved the best accuracy performance, and thus, we used the training results of Mask2Former to segment the reconstructed images. The specific validation accuracy of Mask2Former on the reconstructed dataset is shown in
Table 4.
As can be seen from
Table 4, the segmentation accuracy for buildings and people, which are our primary concerns, reached over 95%, and the accuracy for cars and bicycles also exceeded 85%. These segmentation results met the requirements for our subsequent semantic reconstruction.
3.2. SfM Based on Dynamic and Static Separation
The traditional Structure-from-Motion (SfM) 3D reconstruction process encompasses several components: feature extraction, feature matching, incremental or global reconstruction, and bundle adjustment. The entire process inputs multi-angle images of a target and outputs the target’s sparse point cloud along with the external parameters of the cameras, including their positions and orientations. The external parameters between cameras, which are crucial for subsequent dense reconstruction, significantly influence the final accuracy of the reconstruction. In our approach, alongside the input of multi-view images, we also input the semantic segmentation results corresponding to each image. By utilizing semantic information, we assessed objects within the reconstructed environment while eliminating the dynamic parts of the scene. These dynamic elements correspond to unstable landmark points in the final sparse point cloud.
For SfM based on semantic motion separation, we implemented it through secondary development using the open-source 3D reconstruction library OpenMVG. As the dataset’s image acquisition followed a chronological sequence, we adopted an incremental reconstruction strategy. Utilizing a pre-trained urban semantic segmentation model, we performed semantic segmentation on the reconstructed dataset. By inputting the semantic attributes of feature points during feature extraction, we integrated semantic information into the 3D reconstruction pipeline. We rewrote all relevant functions in OpenMVG, including feature point data formats, feature matching, and SfM, to enable the library to support semantic SfM.
Firstly, we added a control switch in the CmakeLists.txt of the OpenMVG library, which allowed us to choose whether the compiled executable supports semantics. Secondly, we rewrote the relevant code of “Regions”. The “Regions” data structure is a generic container used to store image descriptions. Regions contain features and descriptors. We rewrote everything related to features, including feature point extraction, saving, and reading. After the feature extraction process had been improved, semantic information was added while obtaining the four attributes x, y, scale, and orientation of the feature points. Then, during the feature matching process, we filtered out mismatches based on semantic consistency. Finally, in the calculation process of SfM, we added the operation of dynamic and static separation.
In our semantic classification, we categorized objects based on common urban elements, primarily distinguishing between dynamic and static objects. In urban environments, common moving objects include cars, pedestrians, and bicycles, among others. These objects move at different speeds and can have varying impacts. Due to the inability to synchronize multi-view image acquisition, dynamic objects may exhibit real-space displacements in adjacent multi-view images. These dynamic object feature points introduce errors during feature matching, SfM reconstruction, and bundle adjustment processes. By incorporating semantics, we can filter stable feature points for computation, which aids in enhancing the accuracy of external parameters from the camera calculations. We validated our method by using both the original and semantically optimized approaches on the Tsinghua University architectural dataset. The resulting sparse point cloud reconstruction is shown in
Figure 7.
We compared the accuracy of the reconstructed sparse point clouds with the ground truth (mesh model) by calculating the distance from the point clouds to the mesh, which allowed us to assess the accuracy of the Structure-from-Motion (SfM) reconstruction. With the semantically enhanced SfM, we could directly output point clouds of architectural targets based on semantic information, but the point clouds output by the original openMVG required the target architecture to be manually cropped. We used the CloudCompare 2.12.0 software for progress comparison. The results are shown in
Figure 8.
Due to the limited quantity of point clouds for the Tsinghua University’s Old Gate, we magnified the display of the gate’s sparse point clouds. We used different colors to represent the magnitude of the points’ errors. As shown in the figure, in the color transitions from blue to green to red, blue indicates smaller errors and red indicates larger errors. The assignment of colors was based on relative error values. Due to the large structure of the Tsinghua Life Sciences Building, the overall relative error is small, resulting in most points being displayed in blue. For a fair comparison, we calculated the alignment accuracy of each point cloud with the true model. We compared the reconstruction precision under the condition of ensuring the same possible alignment accuracy. The results of the accuracy evaluation are shown in
Table 5.
As shown in
Table 5, the semantic-based SfM demonstrates higher precision, even under conditions of equal or slightly lower alignment accuracy. This increase in precision is particularly evident in more complex scenes. Given that the gate is located by the roadside, where there is a higher volume of pedestrians and vehicular traffic, the scene contains more dynamic objects. Therefore, the enhancement in Sigma is more pronounced after incorporating semantic optimization in this scenario.
To further examine the significance of our static–dynamic separation process, we analyzed the proportions of various objects in the final sparse point cloud. This helped us determine the extent to which dynamic feature points, without semantic integration, contributed to the final point cloud computation. After feature extraction, we applied a matching filter based on the fundamental matrix. We then performed semantic filtering on the matched feature point pairs, which included inconsistencies in semantic attributes of the left and right feature points or those belonging to dynamic objects. The results are presented in
Table 6.
We conducted a statistical analysis of the feature matches between all pairs of images, wherein the most significant source of error was found to be the sky, followed by the impact caused by people and vehicles. The influence of rapidly moving people and vehicles is not significant; rather, points that remain stationary for short periods or move slowly within the scene are more likely to cause errors. We compared the number of landmarks generated by the semantic SfM and the original method. Among these, landmarks belonging to dynamic objects and those with inconsistent semantic attributes accounted for approximately 6.5% of the total.
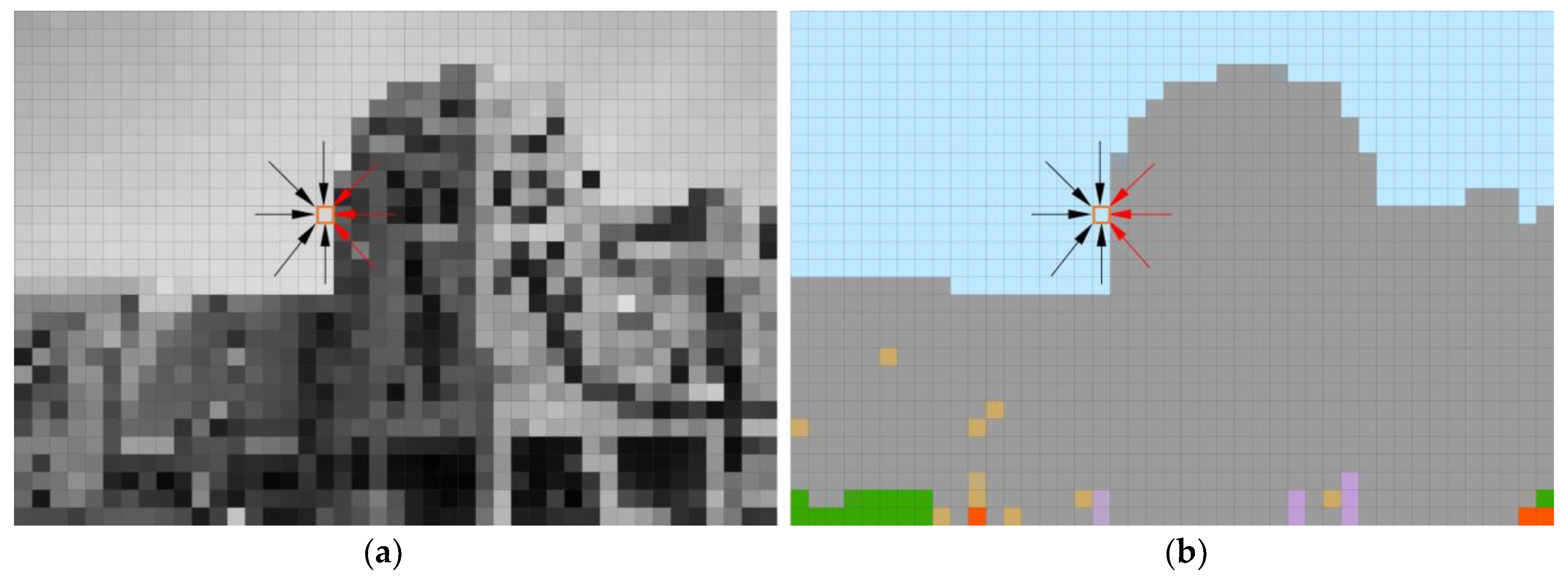
To intuitively demonstrate the positive value of adding semantic information into the feature matching process, we selected two images from the Tsinghua University‘s Old Gate dataset for detailed analysis and demonstration. The results are shown in
Figure 9.
Figure 9a shows the error of semantic inconsistency in feature point matching. These points may be matched together due to similar grayscale features, but they are actually mismatches. The result after semantic segmentation is no longer displayed in pixels but is divided into area blocks based on the essential attributes in the scene. This kind of high-dimensional information that goes beyond two dimensions is no longer affected by the gray value of a single pixel, so it is easy to find semantically inconsistent matching errors.
Figure 9b shows the impact of dynamic targets on feature matching. It can be seen that slow-moving objects in the scene or people who are stationary for a short period of time are more likely to form false matches. These people or objects are not completely static, and this mismatch has a negative impact on the SfM. Since our data were not collected synchronously, this mismatch would be more likely to be encountered in adjacent frames.
Figure 9c shows the matching results after eliminating the first two error-introduction items. It can be seen that although there are some individual mismatches, all feature point pairs matched, as a whole, are basically correct.
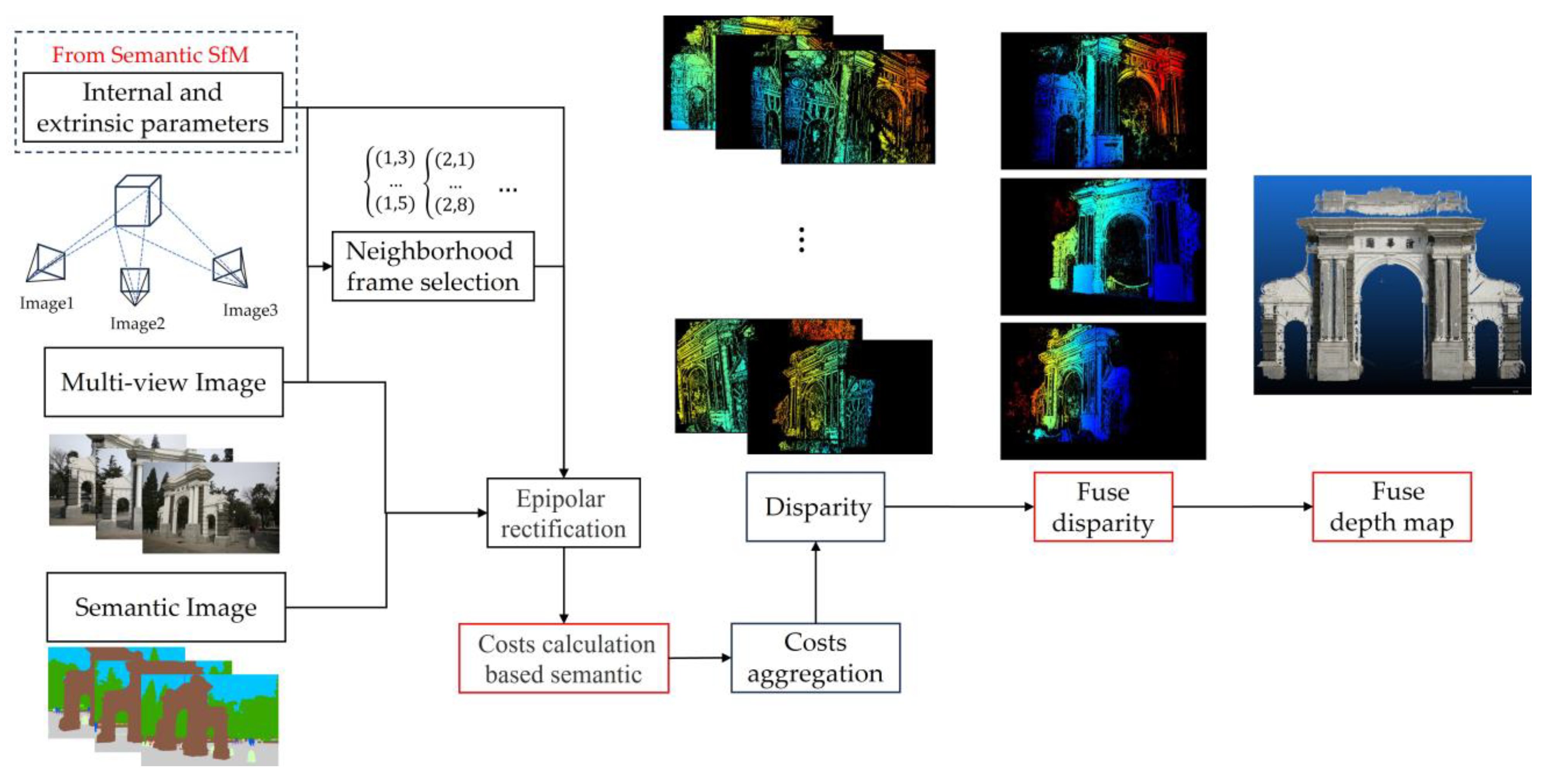
3.3. Semantic-Based SGM
The dense reconstruction of point clouds can be approached using various methods, such as PatchMatch and SGM. We opted for the SGM method for semantic optimization. The specific computation process of SGM includes the following steps:
Initialization: select the best neighborhood frames for each image based on three criteria—the angle of co-visibility points between two images, the area covered, and the scale similarity.
Depth map initialization: initialize a coarse depth map for each image using the Delaunay triangulation method based on sparse point clouds.
Perform epipolar rectification on the image pairs and calculate the matching cost per pixel by row using the WZNCC consistency measure.
Aggregate the one-dimensional path costs from various directions to approximate the calculation of the optimal two-dimensional disparity.
After cost aggregation, find the disparity value with the minimum cost for each pixel.
Fuse the three depth maps generated from the three sets of image pairs involved in the calculation for each image.
Perform a semantically based fusion on the corresponding dense point clouds calculated for all images.
We performed dense reconstruction of Tsinghua University’s Old Gate and Life Sciences Building following the steps outlined above, and we compared the results of the original method with those reconstructed using the semantic SGM method. After obtaining the disparity maps of pairwise images reconstructed by means of semantic SGM, in step f, we selected three sets of depth maps reconstructed from adjacent images for each image to be fused. During this process, we fused the images based on the semantic consistency across different images. The result is shown in the
Figure 10.
In step g, it is not sufficient to simply combine the dense point clouds reconstructed from all images, as points from different images may correspond to the same point in real three-dimensional space. Thus, it is necessary to evaluate points that are redundantly present. During the fusion process, there are instances where the same point possesses different semantic attributes in different images. We performed a weighted statistical analysis of the semantics of such a point across various depth maps, and we assigned the attribute with the highest weight to the final, fused dense point cloud of the scene. The resulting target dense point cloud is shown in
Figure 7.
The dense point cloud after semantic reconstruction not only possesses coordinates in the XYZ space but also carries semantic properties. We assigned colors based on these semantic attributes: vegetation is colored green, people are magenta, vehicles are blue, buildings are yellow, the sky is blue, and static clutter in the scene is gray. It is evident that the results obtained from our semantic SGM reconstruction exhibit less noise around the edges of objects, such as the edges of building rooftops. Moreover, dense reconstruction based on semantics yields dense point clouds containing semantic information, which is extremely important for scene perception.
After fusing a dense point cloud from all views, one can choose whether to optimize the dense point cloud using one of three options: REMOVE_SPECKLES, FILL_GAP, and ADJUST_FILTER. To assess the effectiveness of our semantic optimization, we conducted a comparison of the results before and after optimization. The comparison results for the reconstruction of the Tsinghua Life Sciences Building are shown in
Figure 11.
The above figure shows the reconstruction results for the Tsinghua Life Sciences Building. The first row of images presents the results obtained without filtering, while the second row displays the outcomes after filtering. The left side depicts the results obtained using the original method, and the right side shows the results after semantic optimization. It is evident that using the original SGM reconstruction method introduces a substantial amount of noise, particularly in areas of depth discontinuity, such as the edges of the building. Even after filtering the dense point cloud, the noise level remains significantly higher compared to that obtained using the sSGM method. In the collected multi-view images, the building is adjacent to the sky. During computation, it becomes challenging to accurately identify the positions of disparity discontinuities when using the original SGM method, especially when calculating the one-dimensional path costs transitioning from the building to the sky. This is due to the lack of distinct features in the sky region. Hence, the subsequent cost aggregation process is prone to computing some incorrect disparities.
Next, we conducted a quantitative statistical analysis to evaluate the reconstruction accuracy. Ultimately, the dense point cloud obtained from the reconstruction was aligned with the true-value grid using the Iterative Closest Point (ICP) algorithm, and the distance between the point cloud and the grid was calculated. The calculation process was consistent with that used for sparse point clouds, and the results are presented in
Table 7.
We aligned the reconstructed dense cloud point with the ground-truth grid and compared the reconstruction accuracy while ensuring the same alignment accuracy. As shown in
Table 7, we compared three sets of reconstructed data, and the results all show that the dense point clouds obtained using sSGM have a higher accuracy, which is mainly manifested as a smaller max. distance, a smaller average distance, and a lower Sigma value. There are two reasons for the smaller maximum distance. One is that sSGM has semantic perception capabilities and can judge depth continuity based on semantic consistency, which greatly improves the reconstruction accuracy of the edge areas of objects. The second reason is that we can perform directional output according to the semantic attributes contained in the reconstructed dense point clouds, thereby excluding some outliers and errors. A lower Sigma value indicates that the sSGM method can improve the overall accuracy. We also compared this method with the current mainstream PatchMatch method, and the results are shown in
Figure 12.
Figure 12 shows the reconstruction results of Tsinghua Xuetang as an example. We compared the sSGM method to the original SGM and PatchMatch methods. It is evident that in the point clouds obtained using the SGM and PatchMatch methods, the trees and building sides on both sides of the door are mixed together. However, the point cloud reconstructed by using the sSGM method can well separate the trees and building sides. Moreover, for the eaves of the building, the reconstruction error of the sSGM method is also smaller. We calculated the statistics related to the reconstruction accuracy of the three methods for the three datasets by performing an error analysis of the three models and averaging the results. The results are shown in
Table 8.
As can be seen from
Table 8, after adding semantics to the SGM method, the reconstruction accuracy is greatly improved, and the reconstruction results are better than the reconstruction results of the mainstream method PatchMatch. The max. distance may be affected by gross errors, so we compared the average distance. The accuracy of sSGM is 32.79% higher than the original SGM method, and 63.06% higher than the PatchMatch method. This is mainly reflected in the smaller distance error from the ground-truth mesh. The error caused by outliers is smaller. Our experimental results are therefore consistent with our theoretical design. After obtaining the dense point clouds, we performed a mesh reconstruction operation.
Figure 13 shows the results of mesh reconstruction from dense point clouds generated by three methods. We can find that compared to the original SGM method and the PatchMatch method, the point clouds obtained by the sSGM method have better results in the mesh reconstruction process. Buildings can be completely and independently reconstructed using the sSGM method. The original SGM method is insensitive to the location of depth mutations and inaccurately reconstructs a part of the sky at the edge of the building. The sSGM method that we proposed can well judge the depth continuity of adjacent pixels through the semantically optimized penalty term, so it can obtain high reconstruction accuracy at the edge of the building.
During the mesh reconstruction process, the point clouds obtained by sSGM can avoid simply connecting all points. Both the SGM method and the PatchMatch method inevitably reconstruct the building and other objects (such as bicycles, bushes, etc.) into a mesh as a whole. Thanks to the semantic information that we incorporated into the reconstruction process, the dense point clouds obtained by the sSGM method can improve the accuracy of subsequent mesh reconstruction.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}