

Device Position-Independent Human Activity Recognition with Wearable Sensors Using Deep Neural Networks



Abstract
1. Introduction
- Introduction of Att-ResBiGRU: We propose a novel deep learning architecture called Att-ResBiGRU. This innovative model combines convolutional layers for feature extraction, residual bidirectional gated recurrent unit (GRU) modules for capturing temporal dependencies, and attention mechanisms for focusing on crucial information. This combination enables highly accurate recognition of activities, regardless of the device’s position.
- State-of-the-art performance: Extensive testing on benchmark datasets (PAMAP2, Opportunity, and REALWORLD16) demonstrates that our proposed model achieves the best results reported for position-independent HAR. It achieves F1-scores of 86.69%, 96.44%, and 96.23% on these datasets.
- Robustness against position variations: We compare our model against existing position-dependent and -independent methods using various real-world scenarios to validate its robustness to sensor position changes. Att-ResBiGRU effectively addresses the challenges associated with position independence.
- Impact of model components: Through ablation studies, we analyze the influence of incorporating residual learning and attention blocks on the model’s performance compared to baseline recurrent models. This quantifies the specific contributions of each component to the overall accuracy.
- Simplified deployment: This work establishes a highly reliable single model for classifying complex activities, regardless of a device’s position. This simplifies deployment by eliminating the need for complex position-dependent models.
2. Related Works
2.1. Activity Recognition Constrained to Fixed Device Locations
2.2. Position-Independent Activity Recognition
2.3. Deep Learning Approaches for HAR
3. Proposed Methodology
3.1. Data Acquisition
3.1.1. Opportunity Dataset
3.1.2. PAMAP2 Dataset
3.1.3. REALWORLD16 Dataset
3.2. Data Preprocessing
3.2.1. Data Denoising
3.2.2. Data Normalization
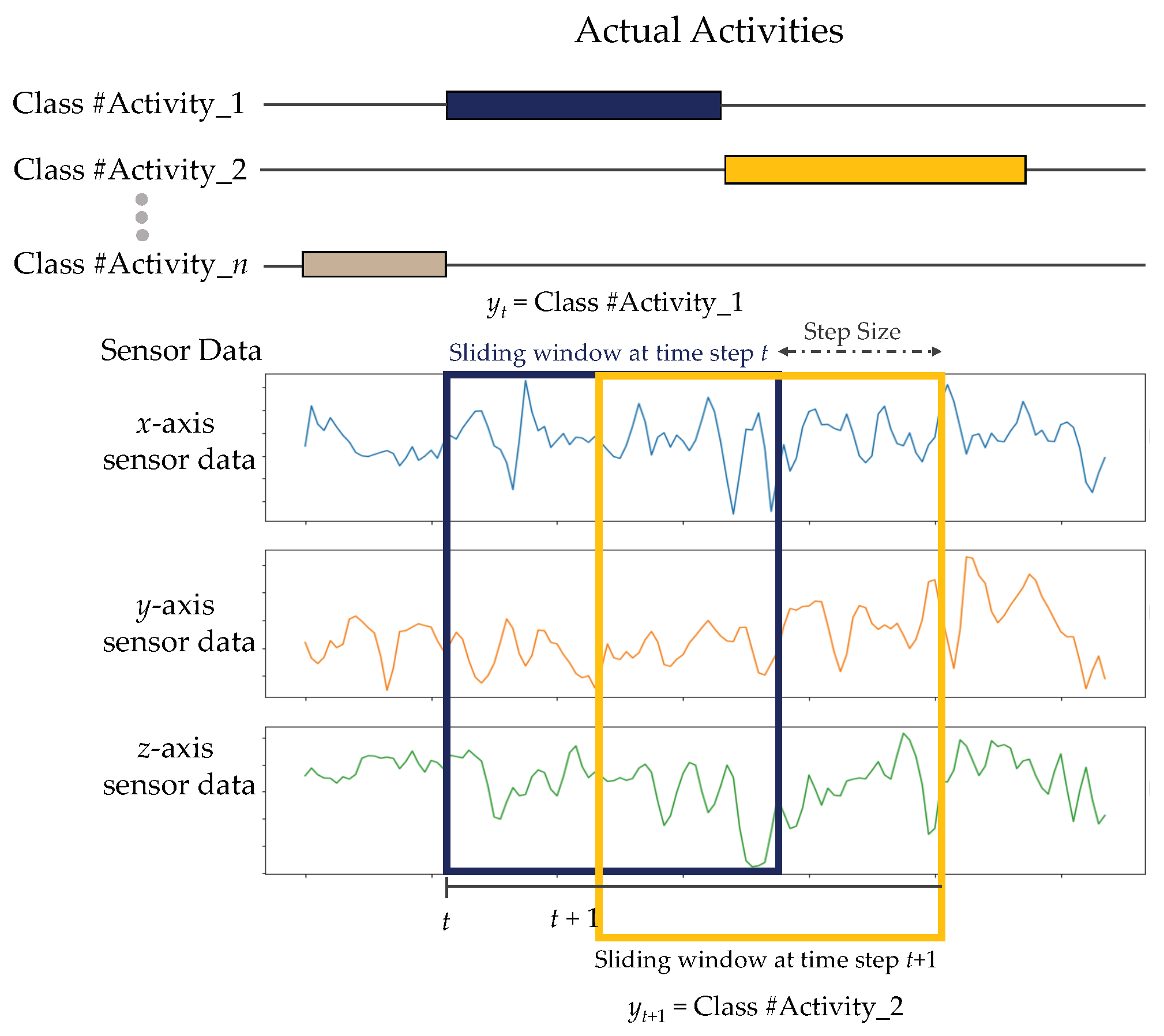
3.2.3. Data Segmentation
3.3. The Proposed Att-ResBiGRU Model
3.3.1. Convolution Block
3.3.2. Residual BiGRU Block
3.3.3. Attention Block
3.4. Evaluation Metrics
- True positive: ;
- False positive: ;
- False negative: ;
- True negative: .
4. Experiments and Results
4.1. Experimental Setup
- In order to read, manipulate, and comprehend the sensor data, the data management tools Numpy and Pandas were implemented.
- In order to visually represent and illustrate the results of data exploration and model evaluation, Matplotlib and Seaborn were employed.
- The Scikit-learn (Sklearn) library was utilized in sampling and data generation studies.
- TensorFlow, Keras, and TensorBoard were utilized to implement and train the deep learning models for model construction.
4.2. Experimental Results of Position-Dependent HAR
- The model demonstrated commendable effectiveness when identifying position-dependent human activities on the Opportunity dataset. Accuracy scores spanned from 84.76% to 89.06% across the five sensor positions.
- The F1-score of 85.69% and accuracy of 89.06% for the back position indicate that it produced the most valuable signals for activity recognition on the Opportunity dataset.
- The effectiveness of the left lower arm (LLA) position was the lowest, with an accuracy of 84.76% and an F1-score of 79.84%. This finding implies that the left lower arm motion may not be as indicative of the actions designated in the Opportunity dataset.
- The sensor’s efficacy generally declined as the position transitioned from the upper body (e.g., back, right upper arm) to the lower body (e.g., left upper arm, left lower arm). This is consistent with the hypothesis that signals from the upper body are more discriminatory for numerous prevalent activities.
- The LLA position exhibited the smallest standard deviation in performance variation between trials, with approximately 0.7% for accuracy and 1.2% for the F1-score. Other positions showed a more significant variance, indicating greater inconsistency between studies.
- The model attained exceptionally high F1-scores and accuracies across all three sensor positions on the PAMAP2 dataset, with the accuracy varying from 97.11% to 97.59%.
- The torso position exhibited superior performance, achieving an accuracy of 97.59% and an F1-score of 97.46%. This finding implies that the signals produced by upper-body motion were the most valuable for activity recognition in this dataset.
- The effectiveness of the hand (97.12% accuracy) and ankle (97.25% accuracy) positions was comparable, indicating similar information provided by wrist and ankle movements for action recognition on PAMAP2.
- The mean values of accuracy and F1-score standard deviations for each trial were below 0.3% and 0.26%, respectively, indicating that the model’s effectiveness remained consistent across numerous iterations.
- All loss values were below 0.13, indicating that the model accurately represented the training data.
- The model achieved high F1-score ratings and accuracies ranging from 94.74% to 98.59% across all seven sensor positions on the REALWORLD16 dataset. Notably, the F1-score was 98.52%, and the quadriceps position achieved the highest accuracy of 98.59%, suggesting that thigh motion provided the most valuable signals for activity recognition in this dataset.
- Conversely, the accuracy and F1-score for the forearm position were the lowest, at 94.74% and 94.75%, respectively, indicating that forearm motion was the least indicative of the activities.
- Upper-body positions, including the chest, upper arm, and abdomen, consistently performed well, with accuracies above 97%. This finding supports the notion that the movement of the upper body provides valuable information regarding numerous everyday activities.
- Notably, the standard deviations for the accuracies and F1-scores were less than 0.5% across all positions, suggesting minimal variance between trials and indicating the consistent effectiveness of the model.
- Generally, the low loss values indicate that the model effectively aligned with the training data across different positions.
4.3. Experimental Findings of Position-Independent HAR
5. Discussion
5.1. Comparison Results with Baseline Deep Learning Models on Position-Dependent HAR
5.2. Comparison Results with Baseline Deep Learning Models on Position-Independent HAR
5.3. Comparison Results with State-of-the-Art Models
5.4. Effects of Complex Activities on Position-Independent HAR
5.5. Ablation Studies
5.5.1. Impact of Convolution Blocks
5.5.2. Impact of the ResBiGRU Block
5.5.3. Effect of the Attention Block
5.6. Complexity Analysis
5.6.1. Memory Consumption
5.6.2. Prediction Time
5.6.3. Trainable Parameters
5.7. Interpretation of the Proposed Model
6. Conclusions, Limitations, and Future Work
- Convolutional blocks: These blocks extract spatial features from the sensor data. Each block uses a 1D convolutional layer to capture patterns, followed by batch normalization for stability and pooling to reduce data size while preserving key information.
- ResBiGRU block: This block captures temporal features by considering both past and future data points in the sequence. This bidirectional approach effectively models the dependencies and dynamics within the data.
- Attention mechanism: This mechanism assigns greater importance to informative features, enhancing the model’s ability to distinguish between similar activities and improving recognition accuracy.
6.1. Limitations
- Computational limitations: The Att-ResBiGRU model requires up to 4MB of memory, exceeding the capabilities of low-power wearable devices like smartwatches. To address this, model compression and quantization techniques are necessary for deployment on resource-constrained devices.
- Sensor drift: Sensor performance can degrade over time, leading to changes in signal distribution and potentially impacting the model’s accuracy. Implementing mechanisms for recalibration or adaptive input normalization would enhance robustness.
- Battery life: Continuous sensor data collection for long-term activity tracking rapidly depletes battery life. Optimizing duty-cycling strategies is crucial to enable more extended monitoring periods.
- Privacy concerns: Transmitting raw, multi-dimensional sensor data raises privacy concerns, as it could reveal sensitive information about daily activities or underlying health conditions. Federated learning and selective feature-sharing approaches could mitigate these concerns and encourage user adoption
6.2. Future Work
- Expanding data sources: Although this work focused on inertial sensors from wearable devices, future studies could incorporate data from environmental sensors like pressure, humidity, and even CCTV frames. This multi-modal approach could enhance the model’s ability to recognize activities by leveraging contextual information beyond the user’s body.
- Cross-domain generalizability: By incorporating data from diverse sources, we can assess the model’s ability to adapt and perform well in different environments. This could lead to more robust and generalizable solutions.
- User-centered design: Future studies should involve qualitative user experience studies to ensure user acceptance and comfort. Gathering feedback from relevant patient populations and clinical experts will be crucial in informing the design of unobtrusive and user-friendly systems.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Hyperparameters | Values | |
|---|---|---|---|
| Architecture | 1D Convolution | Kernel Size | 5 |
| Stride | 1 | ||
| Filters | 64 | ||
| Dropout | 0.25 | ||
| Max Pooling | 2 | ||
| Flatten | - | ||
| Training | Loss Function | Cross-entropy | |
| Optimizer | Adam | ||
| Batch Size | 64 | ||
| Number of Epochs | 200 | ||
| Stage | Hyperparameters | Values |
|---|---|---|
| Architecture | LSTM Unit | 128 |
| Dropout | 0.25 | |
| Dense | 128 | |
| Training | Loss Function | Cross-entropy |
| Optimizer | Adam | |
| Batch Size | 64 | |
| Number of Epochs | 200 |
| Stage | Hyperparameters | Values |
|---|---|---|
| Architecture | BiLSTM Unit | 128 |
| Dropout | 0.25 | |
| Dense | 128 | |
| Training | Loss Function | Cross-entropy |
| Optimizer | Adam | |
| Batch Size | 64 | |
| Number of Epochs | 200 |
| Stage | Hyperparameters | Values |
|---|---|---|
| Architecture | GRU Unit | 128 |
| Dropout | 0.25 | |
| Dense | 128 | |
| Training | Loss Function | Cross-entropy |
| Optimizer | Adam | |
| Batch Size | 64 | |
| Number of Epochs | 200 |
| Stage | Hyperparameters | Values |
|---|---|---|
| Architecture | BiGRU Unit | 128 |
| Dropout | 0.25 | |
| Dense | 128 | |
| Training | Loss Function | Cross-entropy |
| Optimizer | Adam | |
| Batch Size | 64 | |
| Number of Epochs | 200 |
| Stage | Hyperparameters | Values | |
|---|---|---|---|
| Architecture | (Convolution Block) | ||
| 1D Convolution | Kernel Size | 5 | |
| Stride | 1 | ||
| Filters | 256 | ||
| Batch Normalization | - | ||
| Activation | Smish | ||
| Max Pooling | 2 | ||
| Dropout | 0.25 | ||
| 1D Convolution | Kernel Size | 5 | |
| Stride | 1 | ||
| Filters | 128 | ||
| Batch Normalization | - | ||
| Activation | Smish | ||
| Max Pooling | 2 | ||
| Dropout | 0.25 | ||
| 1D Convolution | Kernel Size | 5 | |
| Stride | 1 | ||
| Filters | 64 | ||
| Batch Normalization | - | ||
| Activation | Smish | ||
| Max Pooling | 2 | ||
| Dropout | 0.25 | ||
| 1D Convolution | Kernel Size | 5 | |
| Stride | 1 | ||
| Filters | 32 | ||
| Batch Normalization | - | ||
| Activation | Smish | ||
| Max Pooling | 2 | ||
| Dropout | 0.25 | ||
| (Residual BiGRU Block) | |||
| ResBiGRU_1 | Neural | 128 | |
| ResBiGRU_2 | Neural | 64 | |
| (Attention Block) | |||
| Dropout | 0.25 | ||
| Dense | 128 | ||
| Activation | SoftMax | ||
| Training | Loss Function | Cross-entropy | |
| Optimizer | Adam | ||
| Batch Size | 64 | ||
| Number of Epochs | 200 | ||
References
- Mekruksavanich, S.; Jitpattanakul, A. LSTM Networks Using Smartphone Data for Sensor-Based Human Activity Recognition in Smart Homes. Sensors 2021, 21, 1636. [Google Scholar] [CrossRef]
- Diraco, G.; Rescio, G.; Caroppo, A.; Manni, A.; Leone, A. Human Action Recognition in Smart Living Services and Applications: Context Awareness, Data Availability, Personalization, and Privacy. Sensors 2023, 23, 6040. [Google Scholar] [CrossRef] [PubMed]
- Maity, S.; Abdel-Mottaleb, M.; Asfour, S.S. Multimodal Low Resolution Face and Frontal Gait Recognition from Surveillance Video. Electronics 2021, 10, 1013. [Google Scholar] [CrossRef]
- Khalid, A.M.; Khafaga, D.S.; Aldakheel, E.A.; Hosny, K.M. Human Activity Recognition Using Hybrid Coronavirus Disease Optimization Algorithm for Internet of Medical Things. Sensors 2023, 23, 5862. [Google Scholar] [CrossRef] [PubMed]
- Stisen, A.; Blunck, H.; Bhattacharya, S.; Prentow, T.S.; Kjærgaard, M.B.; Dey, A.; Sonne, T.; Jensen, M.M. Smart Devices Are Different: Assessing and MitigatingMobile Sensing Heterogeneities for Activity Recognition. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems (SenSys’15), Seoul, Republic of Korea, 1–4 November 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 127–140. [Google Scholar] [CrossRef]
- Nweke, H.F.; Teh, Y.W.; Al-garadi, M.A.; Alo, U.R. Deep learning algorithms for human activity recognition using mobile and wearable sensor networks: State of the art and research challenges. Expert Syst. Appl. 2018, 105, 233–261. [Google Scholar] [CrossRef]
- Ha, S.; Yun, J.M.; Choi, S. Multi-modal Convolutional Neural Networks for Activity Recognition. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; pp. 3017–3022. [Google Scholar] [CrossRef]
- Zebin, T.; Scully, P.J.; Ozanyan, K.B. Human activity recognition with inertial sensors using a deep learning approach. In Proceedings of the 2016 IEEE SENSORS, Orlando, FL, USA, 30 October–3 November 2016; pp. 1–3. [Google Scholar] [CrossRef]
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep Learning for Sensor-Based Human Activity Recognition: Overview, Challenges, and Opportunities. ACM Comput. Surv. 2021, 54, 77. [Google Scholar] [CrossRef]
- Fedorov, I.; Adams, R.P.; Mattina, M.; Whatmough, P.N. SpArSe: Sparse Architecture Search for CNNs on Resource-Constrained Microcontrollers. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates Inc.: Red Hook, NY, USA, 2019. [Google Scholar]
- Zhang, Y.; Suda, N.; Lai, L.; Chandra, V. Hello Edge: Keyword Spotting on Microcontrollers. arXiv 2018, arXiv:1711.07128. Available online: http://xxx.lanl.gov/abs/1711.07128 (accessed on 5 January 2024).
- Ojiako, K.; Farrahi, K. MLPs Are All You Need for Human Activity Recognition. Appl. Sci. 2023, 13, 11154. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A Public Domain Dataset for Human Activity Recognition using Smartphones. In Proceedings of the European Symposium on Artificial Neural Networks, Bruges, Belgium, 24–26 April 2013; pp. 437–442. [Google Scholar]
- Ronald, M.; Poulose, A.; Han, D.S. iSPLInception: An Inception-ResNet Deep Learning Architecture for Human Activity Recognition. IEEE Access 2021, 9, 68985–69001. [Google Scholar] [CrossRef]
- Shi, D.; Wang, R.; Wu, Y.; Mo, X.; Wei, J. A novel orientation- and location-independent activity recognition method. Pers. Ubiquitous Comput. 2017, 21, 427–441. [Google Scholar] [CrossRef]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity Recognition Using Cell Phone Accelerometers. SIGKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Bieber, G.; Luthardt, A.; Peter, C.; Urban, B. The Hearing Trousers Pocket: Activity Recognition by Alternative Sensors. In Proceedings of the 4th International Conference on PErvasive Technologies Related to Assistive Environments (PETRA’11), Crete, Greece, 25–27 May 2011; Association for Computing Machinery: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- Kwon, Y.; Kang, K.; Bae, C. Unsupervised learning for human activity recognition using smartphone sensors. Expert Syst. Appl. 2014, 41, 6067–6074. [Google Scholar] [CrossRef]
- Harasimowicz, A.; Dziubich, T.; Brzeski, A. Accelerometer-based Human Activity Recognition and the Impact of the Sample Size. In Proceedings of the Advances in Neural Networks, Fuzzy Systems and Artificial Intelligence, Gdansk, Poland, 15–17 May 2014. [Google Scholar]
- Ustev, Y.E.; Durmaz Incel, O.; Ersoy, C. User, Device and Orientation Independent Human Activity Recognition on Mobile Phones: Challenges and a Proposal. In Proceedings of the Proceedings of the 2013 ACM Conference on Pervasive and Ubiquitous Computing Adjunct Publication (UbiComp’13 Adjunct), Zurich, Switzerland, 8–12 September 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 1427–1436. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J.M. Complex Human Activity Recognition Using Smartphone and Wrist-Worn Motion Sensors. Sensors 2016, 16, 426. [Google Scholar] [CrossRef]
- Qamar, N.; Siddiqui, N.; ul Haq, M.E.; Awais Azam, M.; Naeem, U. An Approach towards Position-Independent Human Activity Recognition Model based on Wearable Accelerometer Sensor. Procedia Comput. Sci. 2020, 177, 196–203. [Google Scholar] [CrossRef]
- Henpraserttae, A.; Thiemjarus, S.; Marukatat, S. Accurate Activity Recognition Using a Mobile Phone Regardless of Device Orientation and Location. In Proceedings of the 2011 International Conference on Body Sensor Networks, Dallas, TX, USA, 23–25 May 2011; pp. 41–46. [Google Scholar] [CrossRef]
- Grokop, L.H.; Sarah, A.; Brunner, C.; Narayanan, V.; Nanda, S. Activity and Device Position Recognition in Mobile Devices. In Proceedings of the 13th International Conference on Ubiquitous Computing (UbiComp ’11), Beijing China, 17–21 September 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 591–592. [Google Scholar] [CrossRef]
- Coskun, D.; Incel, O.D.; Ozgovde, A. Phone position/placement detection using accelerometer: Impact on activity recognition. In Proceedings of the 2015 IEEE Tenth International Conference on Intelligent Sensors, Sensor Networks and Information Processing (ISSNIP), Singapore, 7–9 April 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Miao, F.; He, Y.; Liu, J.; Li, Y.; Ayoola, I. Identifying typical physical activity on smartphone with varying positions and orientations. Biomed. Eng. Online 2015, 14, 32. [Google Scholar] [CrossRef]
- Gu, F.; Kealy, A.; Khoshelham, K.; Shang, J. User-Independent Motion State Recognition Using Smartphone Sensors. Sensors 2015, 15, 30636–30652. [Google Scholar] [CrossRef] [PubMed]
- Shi, X.; Li, Y.; Zhou, F.; Liu, L. Human Activity Recognition Based on Deep Learning Method. In Proceedings of the 2018 International Conference on Radar (RADAR), Brisbane, QLD, Australia, 27–31 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Ravi, D.; Wong, C.; Lo, B.; Yang, G.Z. Deep learning for human activity recognition: A resource efficient implementation on low-power devices. In Proceedings of the 2016 IEEE 13th International Conference on Wearable and Implantable Body Sensor Networks (BSN), San Francisco, CA, USA, 14–17 June 2016; pp. 71–76. [Google Scholar] [CrossRef]
- Hammerla, N.Y.; Halloran, S.; Plötz, T. Deep, Convolutional, and Recurrent Models for Human Activity Recognition Using Wearables. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI’16), New York, NY, USA, 9–15 July 2016; AAAI Press: Palo Alto, CA, USA, 2016; pp. 1533–1540. [Google Scholar]
- Xu, C.; Chai, D.; He, J.; Zhang, X.; Duan, S. InnoHAR: A Deep Neural Network for Complex Human Activity Recognition. IEEE Access 2019, 7, 9893–9902. [Google Scholar] [CrossRef]
- Bhattacharya, D.; Sharma, D.; Kim, W.; Ijaz, M.F.; Singh, P.K. Ensem-HAR: An Ensemble Deep Learning Model for Smartphone Sensor-Based Human Activity Recognition for Measurement of Elderly Health Monitoring. Biosensors 2022, 12, 393. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Phaphan, W.; Hnoohom, N.; Jitpattanakul, A. Attention-Based Hybrid Deep Learning Network for Human Activity Recognition Using WiFi Channel State Information. Appl. Sci. 2023, 13, 8884. [Google Scholar] [CrossRef]
- Roggen, D.; Calatroni, A.; Rossi, M.; Holleczek, T.; Förster, K.; Tröster, G.; Lukowicz, P.; Bannach, D.; Pirkl, G.; Ferscha, A.; et al. Collecting complex activity datasets in highly rich networked sensor environments. In Proceedings of the 2010 Seventh International Conference on Networked Sensing Systems (INSS), Kassel, Germany, 15–18 June 2010; pp. 233–240. [Google Scholar] [CrossRef]
- Reiss, A.; Stricker, D. Introducing a New Benchmarked Dataset for Activity Monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; pp. 108–109. [Google Scholar] [CrossRef]
- Sztyler, T.; Stuckenschmidt, H. On-body localization of wearable devices: An investigation of position-aware activity recognition. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communications (PerCom), Sydney, NSW, Australia, 14–19 March 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Rong, L.; Zhou, J.; Liu, M.; Hou, X. A Wearable Acceleration Sensor System for Gait Recognition. In Proceedings of the 2007 2nd IEEE Conference on Industrial Electronics and Applications, Harbin, China, 23–25 May 2007; pp. 2654–2659. [Google Scholar] [CrossRef]
- Mostayed, A.; Kim, S.; Mazumder, M.M.G.; Park, S.J. Foot Step Based Person Identification Using Histogram Similarity and Wavelet Decomposition. In Proceedings of the 2008 International Conference on Information Security and Assurance (isa 2008), Busan, Republic of Korea, 24–26 April 2008; pp. 307–311. [Google Scholar] [CrossRef]
- Banos, O.; Galvez, J.M.; Damas, M.; Pomares, H.; Rojas, I. Window Size Impact in Human Activity Recognition. Sensors 2014, 14, 6474–6499. [Google Scholar] [CrossRef]
- Wang, X.; Ren, H.; Wang, A. Smish: A Novel Activation Function for Deep Learning Methods. Electronics 2022, 11, 540. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; Gordon, G., Dunson, D., Dudík, M., Eds.; PMLR: Fort Lauderdale, FL, USA, 2011; Volume 15, pp. 315–323. [Google Scholar]
- Shimodaira, H. Improving predictive inference under covariate shift by weighting the log-likelihood function. J. Stat. Plan. Inference 2000, 90, 227–244. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning (ICML’15), Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Hochreiter, S. The Vanishing Gradient Problem during Learning Recurrent Neural Nets and Problem Solutions. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef]
- Cho, K.; van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. In Proceedings of the SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, 25 October 2014; Wu, D., Carpuat, M., Carreras, X., Vecchi, E.M., Eds.; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 103–111. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. In Proceedings of the NIPS 2014 Workshop on Deep Learning, Montreal, QC, Canada, 13 December 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Asuroglu, T.; Acici, K.; Erdas, C.B.; Ogul, H. Texture of Activities: Exploiting Local Binary Patterns for Accelerometer Data Analysis. In Proceedings of the 2016 12th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Naples, Italy, 28 November–1 December 2016; pp. 135–138. [Google Scholar] [CrossRef]
- Luong, T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Màrquez, L., Callison-Burch, C., Su, J., Eds.; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 1412–1421. [Google Scholar] [CrossRef]
- Raffel, C.; Ellis, D.P.W. Feed-Forward Networks with Attention Can Solve Some Long-Term Memory Problems. arXiv 2015, arXiv:1512.08756. Available online: http://xxx.lanl.gov/abs/1512.08756 (accessed on 5 January 2024).
- Gutierrez Maestro, E.; De Almeida, T.R.; Schaffernicht, E.; Martinez Mozos, O. Wearable-Based Intelligent Emotion Monitoring in Older Adults during Daily Life Activities. Appl. Sci. 2023, 13, 5637. [Google Scholar] [CrossRef]
- Agac, S.; Durmaz Incel, O. On the Use of a Convolutional Block Attention Module in Deep Learning-Based Human Activity Recognition with Motion Sensors. Diagnostics 2023, 13, 1861. [Google Scholar] [CrossRef]
- Bisong, E. Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar] [CrossRef]
- Lawal, I.A.; Bano, S. Deep Human Activity Recognition With Localisation of Wearable Sensors. IEEE Access 2020, 8, 155060–155070. [Google Scholar] [CrossRef]
- Sztyler, T.; Stuckenschmidt, H.; Petrich, W. Position-aware activity recognition with wearable devices. Pervasive Mob. Comput. 2017, 38, 281–295. [Google Scholar] [CrossRef]
- Gao, Z.; Liu, D.; Huang, K.; Huang, Y. Context-Aware Human Activity and Smartphone Position-Mining with Motion Sensors. Remote Sens. 2019, 11, 12531. [Google Scholar] [CrossRef]
- Montaha, S.; Azam, S.; Rafid, A.K.M.R.H.; Ghosh, P.; Hasan, M.Z.; Jonkman, M.; De Boer, F. BreastNet18: A High Accuracy Fine-Tuned VGG16 Model Evaluated Using Ablation Study for Diagnosing Breast Cancer from Enhanced Mammography Images. Biology 2021, 10, 1347. [Google Scholar] [CrossRef] [PubMed]
- de Vente, C.; Boulogne, L.H.; Venkadesh, K.V.; Sital, C.; Lessmann, N.; Jacobs, C.; Sánchez, C.I.; van Ginneken, B. Improving Automated COVID-19 Grading with Convolutional Neural Networks in Computed Tomography Scans: An Ablation Study. arXiv 2020, arXiv:2009.09725. Available online: http://xxx.lanl.gov/abs/2009.09725 (accessed on 5 January 2024).
- Meyes, R.; Lu, M.; de Puiseau, C.W.; Meisen, T. Ablation Studies in Artificial Neural Networks. arXiv 2019, arXiv:1901.08644. Available online: http://xxx.lanl.gov/abs/1901.08644 (accessed on 5 January 2024).
- Angerbauer, S.; Palmanshofer, A.; Selinger, S.; Kurz, M. Comparing Human Activity Recognition Models Based on Complexity and Resource Usage. Appl. Sci. 2021, 11, 8473. [Google Scholar] [CrossRef]
- Islam, M.S.; Hussain, I.; Rahman, M.M.; Park, S.J.; Hossain, M.A. Explainable Artificial Intelligence Model for Stroke Prediction Using EEG Signal. Sensors 2022, 22, 9859. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Choi, H.; Jung, C.; Kang, T.; Kim, H.J.; Kwak, I.Y. Explainable Time-Series Prediction Using a Residual Network and Gradient-Based Methods. IEEE Access 2022, 10, 108469–108482. [Google Scholar] [CrossRef]
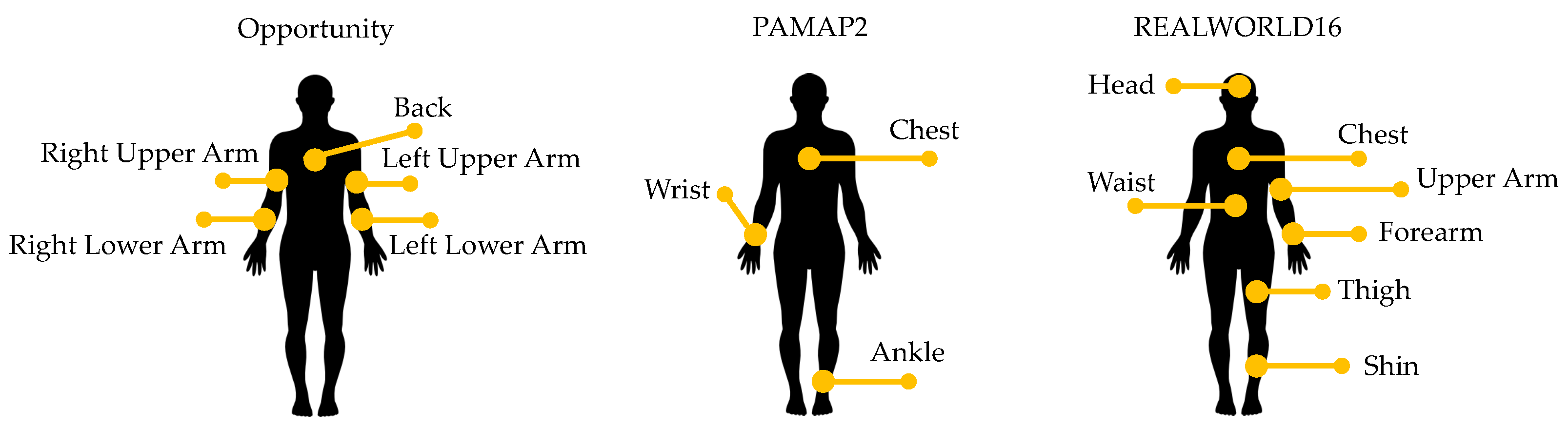










| Dataset | Number of Subjects | Sensors | Positions | Activities |
|---|---|---|---|---|
| Opportunity | 12 | Accelerometer Gyroscope Magnetometer | Left lower arm, Left upper arm, Right upper arm, Right lower arm, Back of the torso | Open door 1, Open door 2, Close door 1, Close door 2, Open and close fridge, Open and close dishwasher, Open drawer 1, Close drawer 1, Open drawer 2, Close drawer 2, Open drawer 3, Close drawer 3, Clean table, Drink from cup, Toggle switch |
| PAMAP2 | 9 | Accelerometer Gyroscope Magnetometer | Wrist, Chest, Ankle | Lying, Sitting, Standing, Walking, Running, Cycling, Nordic walking, Ironing, Vacuum cleaning, Ascending and descending stairs |
| REALWORLD16 | 15 | Accelerometer Gyroscope Magnetometer | Head, Chest, Upper arm, Forearm Waist, Thigh, Shin | Climbing stairs (down and up), Jumping, Lying, Standing, Sitting, Running, Walking |
| Position | Recognition Effectiveness | ||
|---|---|---|---|
| Accuracy (Mean ± std.) | Loss (Mean ± std.) | F1-Score (Mean ± std.) | |
| Back | 89.06% (±1.15%) | 0.52 (±0.07) | 85.69% (±1.76%) |
| RUA | 88.72% (±1.25%) | 0.53 (±0.10) | 84.90% (±1.45%) |
| RLA | 88.14% (±1.12%) | 0.53 (±0.08) | 83.99% (±1.58%) |
| LUA | 86.79% (±0.78%) | 0.60 (±0.05) | 82.56% (±1.00%) |
| LLA | 84.76% (±0.72%) | 0.66 (±0.02) | 79.84% (±1.20%) |
| Position | Recognition Effectiveness | ||
|---|---|---|---|
| Accuracy (Mean ± std.) | Loss (Mean ± std.) | F1-Score (Mean ± std.) | |
| Hand | 97.12% (±0.18%) | 0.12 (±0.01) | 96.95% (±0.16%) |
| Chest | 97.59% (±0.23%) | 0.10 (±0.01) | 97.46% (±0.25%) |
| Ankle | 97.25% (±0.11%) | 0.11 (±0.01) | 97.17% (±0.13%) |
| Position | Recognition Effectiveness | ||
|---|---|---|---|
| Accuracy (Mean ± std.) | Loss (Mean ± std.) | F1-Score (Mean ± std.) | |
| Chest | 98.08% (±0.49%) | 0.09 (±0.02) | 98.12% (±0.37%) |
| Forearm | 94.74% (±0.31%) | 0.24 (±0.02) | 94.75% (±0.33%) |
| Head | 96.62% (±0.21%) | 0.17 (±0.01) | 96.70% (±0.20%) |
| Shin | 97.89% (±0.17%) | 0.10 (±0.01) | 97.90% (±0.07%) |
| Thigh | 98.59% (±0.26%) | 0.07 (±0.01) | 98.52% (±0.31%) |
| Upper arm | 96.96% (±0.44%) | 0.14 (±0.01) | 96.93% (±0.46%) |
| Waist | 98.01% (±0.29%) | 0.09 (±0.01) | 97.93% (±0.33%) |
| Dataset | Recognition Effectiveness | ||
|---|---|---|---|
| Accuracy (Mean ± std.) | Loss (Mean ± std.) | F1-Score (Mean ± std.) | |
| Opportunity | 90.27% (±0.23%) | 0.34 (±0.01) | 86.69% (±0.30%) |
| PAMAP2 | 96.61% (±0.26%) | 0.12 (±0.01) | 96.44% (±0.25%) |
| REALWORLD16 | 96.11% (±0.17%) | 0.14 (±0.01) | 96.23% (±0.19%) |
| Classifier | F1-Score(%) | ||
|---|---|---|---|
| Hand | Chest | Ankle | |
| RF [22] | 93.50% | 96.20% | 94.40% |
| SVM [22] | 90.60% | 94.10% | 92.50% |
| K-NN [22] | 77.30% | 80.40% | 75.70% |
| BN [22] | 78.50% | 83.70% | 78.80% |
| DT [22] | 82.60% | 87.70% | 86.60% |
| Att-ResBiGRU | 96.95% | 97.46% | 97.17% |
| Classifier | F1-Score(%) | ||||||
|---|---|---|---|---|---|---|---|
| Chest | Forearm | Head | Shin | Thigh | Upper Arm | Waist | |
| Two-stream CNN [54] | 76% | 79% | 78% | 88% | 52% | 75% | 86% |
| RF [55] | 84% | 80% | 79% | 87% | 86% | 83% | 86% |
| Att-ResBiGRU | 98.12% | 94.75% | 96.70% | 97.90% | 98.52% | 96.93% | 97.93% |
| Dataset | Classifier | F1-Score (%) |
|---|---|---|
| PAMAP2 | RF [22] | 91.70% |
| SVM-SMO [22] | 78.41% | |
| K-NN [22] | 90.61% | |
| BN [22] | 78.39% | |
| DT [22] | 80.87% | |
| Att-ResBiGRU | 96.44% | |
| REALWORLD16 | MLP [56] | 89.10% |
| CNN [56] | 88.55% | |
| LSTM [56] | 89.32% | |
| RF [55] | 84.00% | |
| Two-stream CNN [54] | 90.00% | |
| Att-ResBiGRU | 96.23% |
| Model | Performance | |||||
|---|---|---|---|---|---|---|
| Opportunity | PAMAP2 | REALWORLD16 | ||||
| Accuracy | F1-Score | Accuracy | F1-Score | Accuracy | F1-Score | |
| Att-ResBiGRU without convolution blocks | 89.34% (±0.45%) | 86.56% (±0.61%) | 95.34% (±0.16%) | 95.13% (±0.22%) | 95.80% (±0.21%) | 95.80% (±0.19%) |
| Att-ResBiGRU with convolution blocks | 90.27% (±0.23%) | 86.69% (±0.30%) | 96.61% (±0.26%) | 96.44% (±0.25%) | 96.11% (±0.17%) | 96.23% (±0.19%) |
| Model | Performance | |||||
|---|---|---|---|---|---|---|
| Opportunity | PAMAP2 | REALWORLD16 | ||||
| Accuracy | F1-Score | Accuracy | F1-Score | Accuracy | F1-Score | |
| Att-ResBiGRU without the ResBiGRU block | 89.13% (±1.12%) | 85.00% (±1.37%) | 94.04% (±0.15%) | 94.89% (±0.13%) | 94.03% (±0.15%) | 94.16% (±0.15%) |
| Att-ResBiGRU with the ResBiGRU block | 90.27% (±0.23%) | 86.69% (±0.30%) | 96.61% (±0.26%) | 96.44% (±0.25%) | 96.11% (±0.17%) | 96.23% (±0.19%) |
| Model | Performance | |||||
|---|---|---|---|---|---|---|
| Opportunity | PAMAP2 | REALWORLD16 | ||||
| Accuracy | F1-Score | Accuracy | F1-Score | Accuracy | F1-Score | |
| Att-ResBiGRU without the attention block | 89.95% (±0.26%) | 86.31% (±0.28%) | 95.25% (±0.15%) | 95.07% (±0.16%) | 95.14% (±0.25%) | 95.23% (±0.25%) |
| Att-ResBiGRU with the attention block | 90.27% (±0.23%) | 86.69% (±0.30%) | 96.61% (±0.26%) | 96.44% (±0.25%) | 96.11% (±0.17%) | 96.23% (±0.19%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mekruksavanich, S.; Jitpattanakul, A. Device Position-Independent Human Activity Recognition with Wearable Sensors Using Deep Neural Networks. Appl. Sci. 2024, 14, 2107. https://doi.org/10.3390/app14052107
Mekruksavanich S, Jitpattanakul A. Device Position-Independent Human Activity Recognition with Wearable Sensors Using Deep Neural Networks. Applied Sciences. 2024; 14(5):2107. https://doi.org/10.3390/app14052107
Chicago/Turabian StyleMekruksavanich, Sakorn, and Anuchit Jitpattanakul. 2024. "Device Position-Independent Human Activity Recognition with Wearable Sensors Using Deep Neural Networks" Applied Sciences 14, no. 5: 2107. https://doi.org/10.3390/app14052107
APA StyleMekruksavanich, S., & Jitpattanakul, A. (2024). Device Position-Independent Human Activity Recognition with Wearable Sensors Using Deep Neural Networks. Applied Sciences, 14(5), 2107. https://doi.org/10.3390/app14052107