
High-Dimensional Ensemble Learning Classification: An Ensemble Learning Classification Algorithm Based on High-Dimensional Feature Space Reconstruction


Abstract
1. Introduction
2. Related Work
- (1)
- Most of the above feature selection algorithms are designed to obtain an optimal subset of features. In contrast, the classifier calls an existing subset of features and uses a fixed structure when evaluating the subset of features. Therefore, the classifier used may not be the best.
- (2)
- Different classifiers, such as decision trees, support vector machines (SVMs), etc., based on their unique learning algorithms, will produce different predictions on the same dataset. These differences arise from the different ways in which individual algorithms partition the feature space of the data and the trade-offs they make between model complexity, bias, and variance. In a numerical analysis, this prediction variability can lead to a significant impact on the overall prediction results of the integrated model.
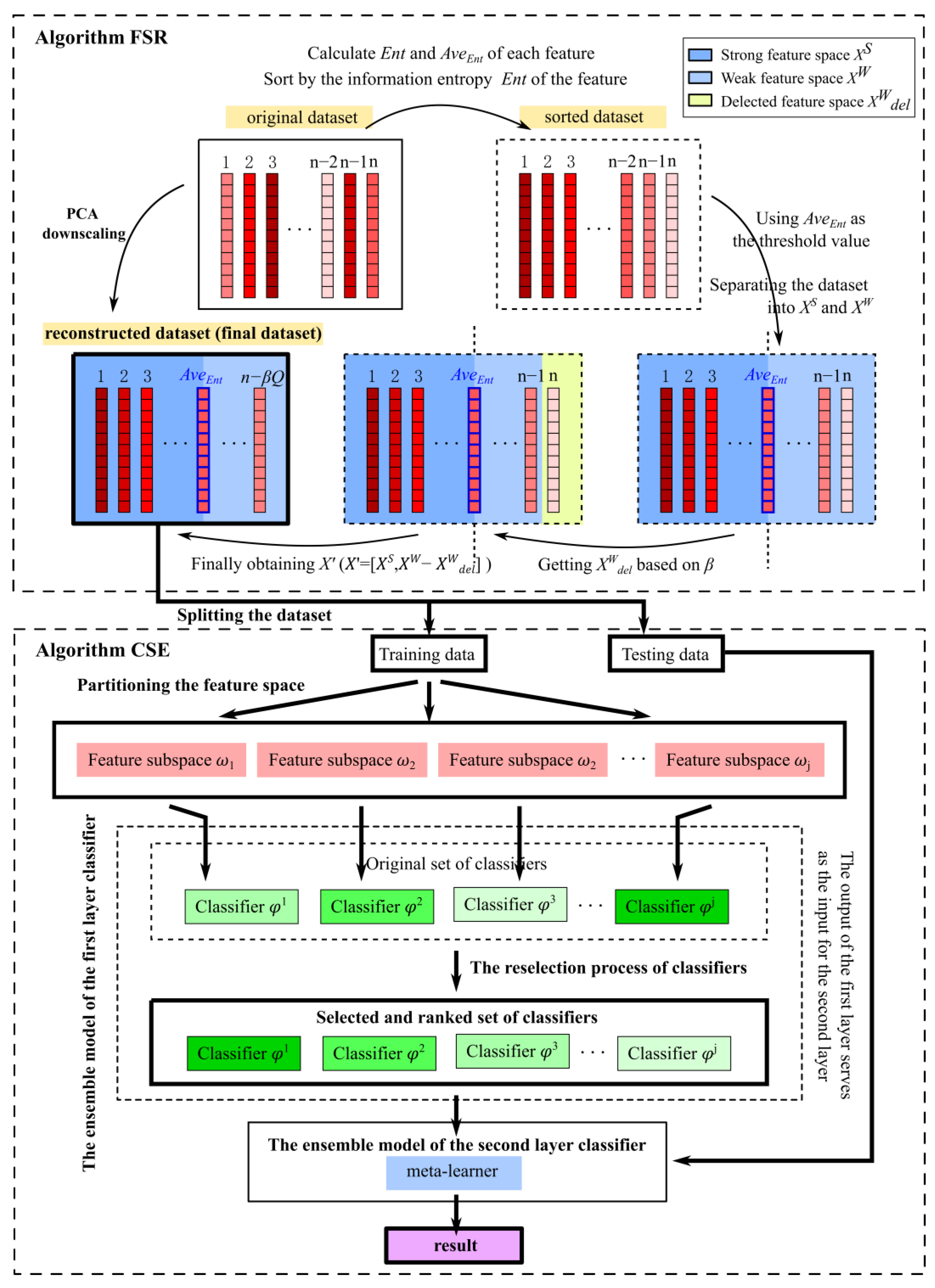
3. HDELC Algorithm
| Algorithm 1. Subspace ensemble strategy based on high-dimensional feature space reconstruction. |
| Require: Input: Original high-dimensional dataset. Procedure 1: Obtain the optimal feature space with Algorithm 2; 2: Find the feature-reconstructed dataset (final dataset); 3: Spilt the reconstructed dataset into training data and testing data; 4: Train the using the training data; 5: Sort the training results for each classifier; 6: Divide feature subspaces; 7: Select the classifiers in the ensemble model using the Algorithm 3; 8: Build the first layer of the ensemble training model; 9: Train the model using the model prediction results as input to the second-layer learner. Output: Predicted results of the HDELC model. |
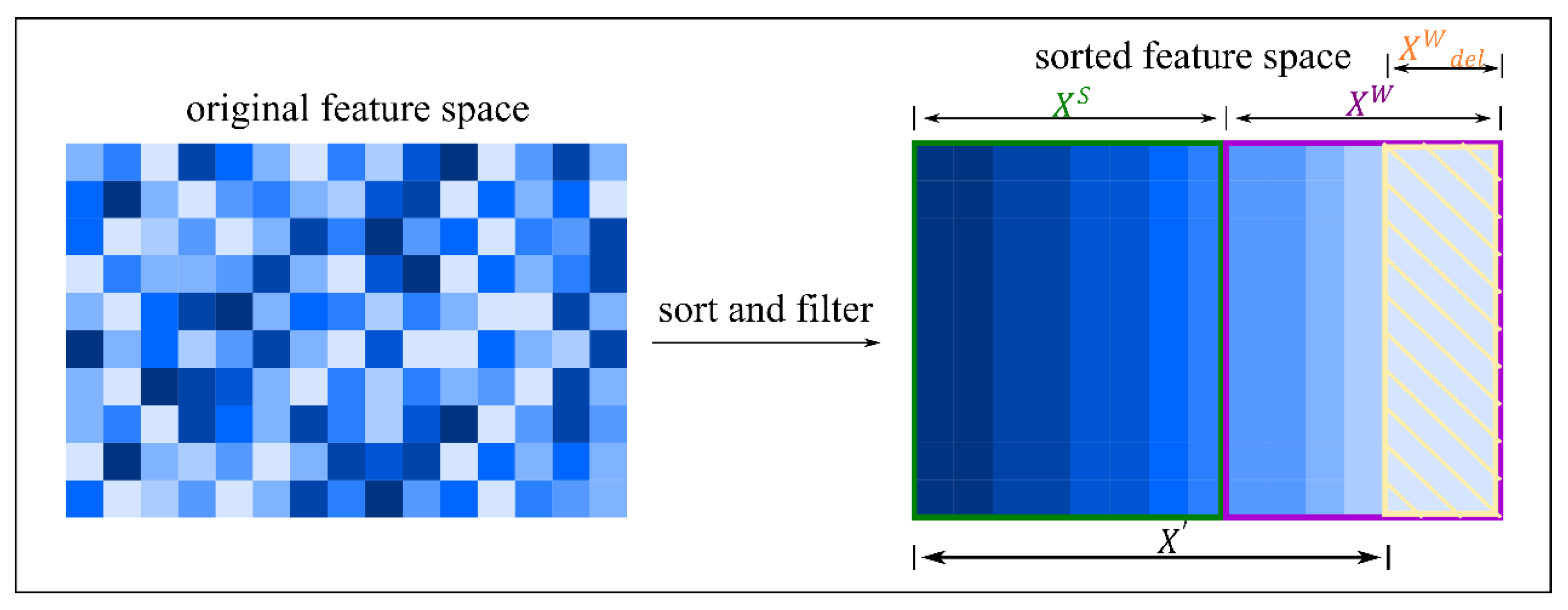
3.1. High-Dimensional Feature Space Reconstruction Process
| Algorithm 2. Feature subspace reconstruction strategy |
| Require: Input: The feature space selection matrix ; Procedure 1: For in ; 2: Calculate the information entropy ; 3: Calculate the average value of information entropy ; 4: if 5: Place in the set ; 6: Or; 7: Place in the set ; 8: Set the filter factor ; 9: Calculate the number of features that are rejected in weak feature space; 10: Redivide and the weak feature space ; 11: Refactor the feature space ; 12: Use to train the decision tree classifier ; 13: Select the attribute screening factor corresponding to the maximum precision as the optimal attribute screening factor, and then determine the optimal feature selection set size ; 14: Use PCA dimensionality reduction to reduce the original feature space to dimension. Output: The optimal feature selection set size and feature-reconstructed dataset. |
3.1.1. Construction of the Feature Space Reconstruction Matrix
3.1.2. Feature Subspace Division and Reconstruction Process
3.2. Classifier Selection and Ensemble Models
| Algorithm 3. The process of high-dimensional data subspace classifier ensemble. |
| Require: Input: The collection of feature spaces after reconstruction . Procedure 1: For in 2: Calculate the accuracy of the base learner in the ensemble model; 3: Sort the accuracy of base classifiers from largest to smallest; 4: Find the optimal number of base learners; 5: Use the best classifier set as the base learner in the Stacking model; 6: Find the best training model. Output: Predicted result. |
3.2.1. Classifier-Selection Process
3.2.2. Classifier Ensemble Process
- (1)
- In ensemble learning, enhancing inter-model diversity is considered a critical factor in improving the generalization ability of integration. By endowing each classifier with specific, non-overlapping feature subspaces, parsing of the dataset from different dimensions can be achieved, thus enabling the integrated model to incorporate this multi-dimensional information, and significantly improving the model’s overall performance.
- (2)
- The low correlation between base learners is decisive for minimizing the overall error of the ensemble learning model. Decorrelation of the error prediction can be achieved by assigning different feature subsets to different classifiers, and this strategy naturally reduces the dependency between base learners, thus enhancing the robustness of the integrated model.
- (3)
- Assigning non-overlapping feature subspaces to classifiers may increase the bias of individual classifiers. However, by integrating these classifiers with high levels of diversity, the variance of the overall model can be reduced. In essence, this approach utilizes the ability of integrated learning to reduce variance while keeping bias as constant as possible.
- (1)
- First, the algorithm picks an initial feature subspace for the first classifier of integration. Then, it allocates mutually exclusive disjoint feature subspaces for each subsequent classifier in turn (classifier) until all the preset classifiers have been configured. All classifiers are level 1 classifiers, and each base learner is given a prediction. This approach enables the complementary contribution of information, which in turn enhances the ability of the overall integrated model to capture data diversity.
- (2)
- Using multiple linear regression (MLR) as the secondary learner, the prediction results and target values output from all models in the first tier are used as inputs to the second-tier model to train the second-tier model. The second-layer model can attenuate the effect of the error of a single model to improve the prediction accuracy of the overall ensemble model.
3.3. Time Complexity Analysis
4. Experiments and Results
4.1. Experimental Data
4.2. Experimental Setting
4.3. Experimental Results
4.3.1. Baseline Modeling and Parameterization
4.3.2. Baseline Model Analysis
4.3.3. Sensitivity Analysis of Attribute Screening Factors
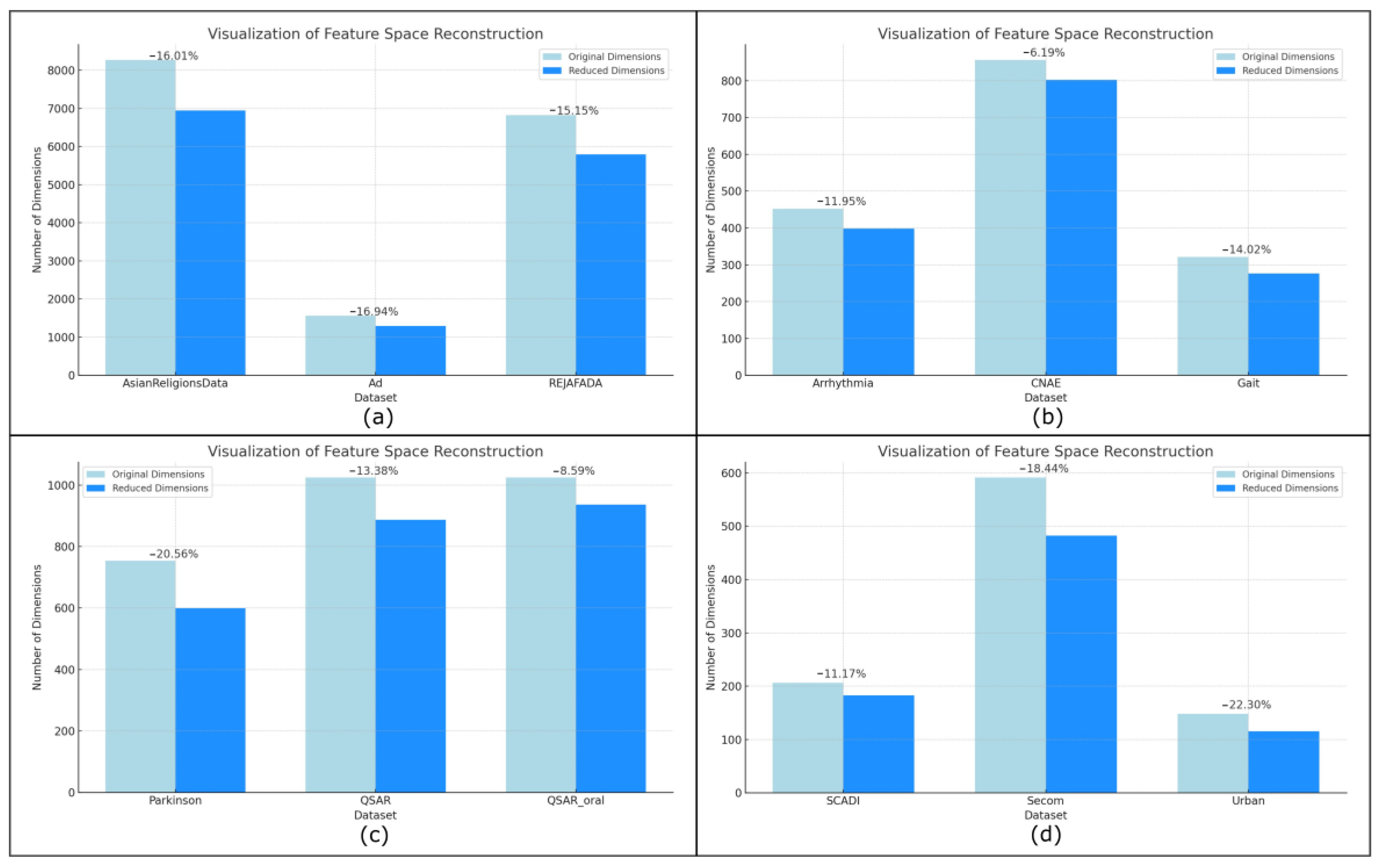
4.3.4. Ablation Experiment
- (1)
- Ablation experiments based on feature space reconstruction scale
- (2)
- Ablation experiment based on the classifier ensemble scale
4.3.5. Comparison of Advanced Aggregation Techniques for High-Dimensional Data
4.3.6. Significance Test
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sharma, A.; Kaur, A.; Singh, K.; Upadhyay, S.K. Modulation in gene expression and enzyme activity suggested the roles of monodehydroascorbate reductase in development and stress response in bread wheat. Plant Sci. 2024, 338, 111902. [Google Scholar]
- Ansori, M.A.Z.; Solehudin, E. Analysis of the Syar’u Man Qablana Theory and its Application in Sharia Financial Institutions. Al-Afkar J. Islam. Stud. 2024, 7, 590–607. [Google Scholar]
- Tartarisco, G.; Cicceri, G.; Bruschetta, R.; Tonacci, A.; Campisi, S.; Vitabile, S.; Cerasa, A.; Distefano, S.; Pellegrino, A.; Modesti, P.A. An intelligent Medical Cyber–Physical System to support heart valve disease screening and diagnosis. Expert Syst. Appl. 2024, 238, 121772. [Google Scholar] [CrossRef]
- Liu, L. Analyst monitoring and information asymmetry reduction: US evidence on environmental investment. Innov. Green Dev. 2024, 3, 100098. [Google Scholar] [CrossRef]
- Lee, K.; Laskin, M.; Srinivas, A.; Abbeel, P. Sunrise: A simple unified framework for ensemble learning in deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 6131–6141. [Google Scholar]
- Campagner, A.; Ciucci, D.; Cabitza, F. Aggregation models in ensemble learning: A large-scale comparison. Inf. Fusion 2023, 90, 241–252. [Google Scholar] [CrossRef]
- Zhu, X.; Li, J.; Ren, J.; Wang, J.; Wang, G. Dynamic ensemble learning for multi-label classification. Inf. Sci. 2023, 623, 94–111. [Google Scholar] [CrossRef]
- Asadi, B.; Hajj, R. Prediction of asphalt binder elastic recovery using tree-based ensemble bagging and boosting models. Constr. Build. Mater. 2024, 410, 134154. [Google Scholar] [CrossRef]
- Sun, Z.; Wang, G.; Li, P.; Wang, H.; Zhang, M.; Liang, X. An improved random forest based on the classification accuracy and correlation measurement of decision trees. Expert Syst. Appl. 2024, 237, 121549. [Google Scholar] [CrossRef]
- Jiang, J.; Liu, F.; Ng, W.W.; Tang, Q.; Wang, W.; Pham, Q.V. Dynamic incremental ensemble fuzzy classifier for data streams in green internet of things. IEEE Trans. Green Commun. Netw. 2022, 6, 1316–1329. [Google Scholar] [CrossRef]
- Lughofer, E.; Pratama, M. Evolving multi-user fuzzy classifier system with advanced explainability and interpretability aspects. Inf. Fusion 2023, 91, 458–476. [Google Scholar] [CrossRef]
- Pérez, E.; Ventura, S. An ensemble-based convolutional neural network model powered by a genetic algorithm for melanoma diagnosis. Neural Comput. Appl. 2022, 34, 10429–10448. [Google Scholar] [CrossRef]
- Deb, S.D.; Jha, R.K.; Jha, K.; Tripathi, P.S. A multi model ensemble based deep convolution neural network structure for detection of COVID-19. Biomed. Signal Process. Control. 2022, 71, 103126. [Google Scholar] [CrossRef]
- Liu, B.; Li, X.; Xiao, Y.; Sun, P.; Zhao, S.; Peng, T.; Zheng, Z.; Huang, Y. Adaboost-based SVDD for anomaly detection with dictionary learning. Expert Syst. Appl. 2024, 238, 121770. [Google Scholar] [CrossRef]
- Kedia, V.; Chakraborty, D. Randomized Subspace Identification for LTI Systems. In Proceedings of the 2023 European Control Conference (ECC), Bucharest, Romania, 13–16 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar]
- Hart, J.L.; Bhatt, L.; Zhu, Y.; Han, M.G.; Bianco, E.; Li, S.; Hynek, D.J.; Schneeloch, J.A.; Tao, Y.; Louca, D. Emergent layer stacking arrangements in c-axis confined MoTe2. Nat. Commun. 2023, 14, 4803. [Google Scholar] [CrossRef]
- Li, X.; Wang, Y.; Tang, B.; Qin, Y.; Zhang, G. Canonical correlation analysis of dimension reduced degradation feature space for machinery condition monitoring. Mech. Syst. Signal Process. 2023, 182, 109603. [Google Scholar] [CrossRef]
- Priyadarshini, J.; Premalatha, M.; Čep, R.; Jayasudha, M.; Kalita, K. Analyzing physics-inspired metaheuristic algorithms in feature selection with K-nearest-neighbor. Appl. Sci. 2023, 13, 906. [Google Scholar] [CrossRef]
- Li, Y.; Chai, Y.; Zhou, H.; Yin, H. A novel dimension reduction and dictionary learning framework for high-dimensional data classification. Pattern Recognit. 2021, 112, 107793. [Google Scholar] [CrossRef]
- Wang, Q.; Nguyen, T.T.; Huang, J.Z.; Nguyen, T.T. An efficient random forests algorithm for high dimensional data classification. Adv. Data Anal. Classif. 2018, 12, 953–972. [Google Scholar] [CrossRef]
- Uddin, K.M.M.; Biswas, N.; Rikta, S.T.; Dey, S.K. Machine learning-based diagnosis of breast cancer utilizing feature optimization technique. Comput. Methods Programs Biomed. Update 2023, 3, 100098. [Google Scholar] [CrossRef]
- Tékouabou, S.C.K.; Chabbar, I.; Toulni, H.; Cherif, W.; Silkan, H. Optimizing the early glaucoma detection from visual fields by combining preprocessing techniques and ensemble classifier with selection strategies. Expert Syst. Appl. 2022, 189, 115975. [Google Scholar] [CrossRef]
- Xu, C.; Zhang, S. A Genetic Algorithm-based sequential instance selection framework for ensemble learning. Expert Syst. Appl. 2024, 236, 121269. [Google Scholar] [CrossRef]
- Kurutach, T.; Clavera, I.; Duan, Y.; Tamar, A.; Abbeel, P. Model-ensemble trust-region policy optimization. arXiv 2018, arXiv:1802.10592. [Google Scholar]
- Ahmed, K.; Sachindra, D.A.; Shahid, S.; Iqbal, Z.; Nawaz, N.; Khan, N. Multi-model ensemble predictions of precipitation and temperature using machine learning algorithms. Atmos. Res. 2020, 236, 104806. [Google Scholar] [CrossRef]
- Zhong, Y.; Chen, W.; Wang, Z.; Chen, Y.; Wang, K.; Li, Y.; Yin, X.; Shi, X.; Yang, J.; Li, K. HELAD: A novel network anomaly detection model based on heterogeneous ensemble learning. Comput. Netw. 2020, 169, 107049. [Google Scholar] [CrossRef]
- Rudy, S.H.; Sapsis, T.P. Output-weighted and relative entropy loss functions for deep learning precursors of extreme events. Phys. D Nonlinear Phenom. 2023, 443, 133570. [Google Scholar] [CrossRef]
- Wu, K.; Chen, P.; Ghattas, O. A Fast and Scalable Computational Framework for Large-Scale High-Dimensional Bayesian Optimal Experimental Design. SIAM/ASA J. Uncertain. Quantif. 2023, 11, 235–261. [Google Scholar] [CrossRef]
- Chen, J.; Xu, A.; Chen, D.; Zhang, Y.; Chen, Z. Discrete Boltzmann modeling of Rayleigh-Taylor instability: Effects of interfacial tension, viscosity, and heat conductivity. Phys. Rev. E 2022, 106, 015102. [Google Scholar] [CrossRef]
- Shin, M.; Lee, J.; Jeong, K. Estimating quantum mutual information through a quantum neural network. Quantum Inf. Process. 2024, 23, 57. [Google Scholar] [CrossRef]
- Du, L.; Liu, H.; Zhang, L.; Lu, Y.; Li, M.; Hu, Y.; Zhang, Y. Deep ensemble learning for accurate retinal vessel segmentation. Comput. Biol. Med. 2023, 158, 106829. [Google Scholar] [CrossRef]
- Lv, Y.; Lu, J.; Liu, Y.; Zhang, L. A class of stealthy attacks on remote state estimation with intermittent observation. Inf. Sci. 2023, 639, 118964. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2019; Available online: http://archive.ics.uci.edu/ml (accessed on 1 February 2023).
- Elminaam, D.S.A.; Nabil, A.; Ibraheem, S.A.; Houssein, E.H. An Efficient Marine Predators Algorithm for Feature Selection. IEEE Access 2021, 9, 60136–60153. [Google Scholar] [CrossRef]
- Bai, L.; Li, H.; Gao, W.; Xie, J.; Wang, H. A joint multiobjective optimization of feature selection and classifier design for high-dimensional data classification. Inf. Sci. 2023, 626, 457–473. [Google Scholar] [CrossRef]
- Ibrahim, S.; Nazir, S.; Velastin, S.A. Feature selection using correlation analysis and principal component analysis for accurate breast cancer diagnosis. J. Imaging 2021, 7, 225. [Google Scholar] [CrossRef]
- Mafarja, M.; Thaher, T.; Al-Betar, M.A.; Too, J.; Awadallah, M.A.; Abu Doush, I.; Turabieh, H. Classification framework for faulty-software using enhanced exploratory whale optimizer-based feature selection scheme and random forest ensemble learning. Appl. Intell. 2023, 53, 18715–18757. [Google Scholar] [CrossRef] [PubMed]
- Campos, D.; Zhang, M.; Yang, B.; Kieu, T.; Guo, C.; Jensen, C.S. LightTS: Lightweight Time Series Classification with Adaptive Ensemble Distillation. Proc. ACM Manag. Data 2023, 1, 1–27. [Google Scholar] [CrossRef]
- Jiang, J.; Liu, F.; Ng, W.W.; Tang, Q.; Zhong, G.; Tang, X.; Wang, B. AERF: Adaptive ensemble random fuzzy algorithm for anomaly detection in cloud computing. Comput. Commun. 2023, 200, 86–94. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Instances | Number of Attributes | Number of Class |
|---|---|---|---|
| AsianReligionsData | 590 | 8265 | 8 |
| Arrhythmia | 279 | 452 | 16 |
| CNAE | 1080 | 856 | 9 |
| Gait | 48 | 321 | 16 |
| Ad | 3279 | 1558 | 2 |
| Parkinson | 756 | 754 | 2 |
| QSAR | 1687 | 1024 | 2 |
| QSAR_oral | 8992 | 1024 | 2 |
| REJAFADA | 1996 | 6826 | 2 |
| SCADI | 70 | 206 | 7 |
| Secom | 1567 | 591 | 2 |
| Urban | 168 | 148 | 9 |
| Parameters | Range |
|---|---|
| Attribute culling factors in feature space | 0.1, 0.2, 0.3, 0.4, 0.5 |
| The number of subsets of feature subspace | |
| The number of classifiers required for ensemble |
| Dataset | DT | RF | AdaBoost | GB | ET | SVM |
|---|---|---|---|---|---|---|
| AsianReligionsData | 0.7458 | 0.8475 | 0.5932 | 0.8220 | 0.8898 | 0.7881 |
| Arrhythmia | 0.6484 | 0.7582 | 0.6044 | 0.6923 | 0.7363 | 0.6044 |
| CNAE | 0.8333 | 0.8843 | 0.4768 | 0.9074 | 0.9074 | 0.8935 |
| Gait | 0.1000 | 0.8000 | 0.2000 | 0.6000 | 0.9000 | 0.6000 |
| Ad | 0.9695 | 0.9787 | 0.9695 | 0.9664 | 0.9741 | 0.9207 |
| Parkinson | 0.8146 | 0.8675 | 0.8808 | 0.8940 | 0.8940 | 0.7417 |
| QSAR | 0.8669 | 0.8935 | 0.8846 | 0.8876 | 0.8964 | 0.8905 |
| QSAR_oral | 0.96 | 0.9783 | 0.9988 | 0.9988 | 0.9900 | 0.9972 |
| REJAFADA | 0.9825 | 0.9900 | 0.9825 | 0.9875 | 0.9875 | 0.5965 |
| SCADI | 0.7143 | 0.8571 | 0.2143 | 0.7143 | 0.8571 | 0.8571 |
| Secom | 0.8694 | 0.9013 | 0.8822 | 0.9013 | 0.9013 | 0.9013 |
| Urban | 0.8333 | 0.8910 | 0.8889 | 0.8889 | 0.8941 | 0.6667 |
| Dataset | The Order of Selection for Base Classifiers | |
|---|---|---|
| AsianReligionsData | 0.5 | |
| Arrhythmia | 0.4 | |
| CNAE | 0.1 | |
| Gait | 0.3 | |
| Ad | 0.4 | |
| Parkinson | 0.4 | |
| QSAR | 0.4 | |
| QSAR_oral | 0.1 | |
| REJAFADA | 0.4 | |
| SCADI | 0.2 | |
| Secom | 0.3 | |
| Urban | 0.5 |
| Dataset | Model | Accuracy | Recall | Precision | F1-Score |
|---|---|---|---|---|---|
| AsianReligionsData | HDELC-2 | 0.8544 | 0.8187 | 0.8299 | 0.8243 |
| HDELC-4 | 0.8593 | 0.8359 | 0.8168 | 0.8262 | |
| HDELC-6 | 0.8442 | 0.8366 | 0.8078 | 0.8219 | |
| Arrhythmia | HDELC-2 | 0.7214 | 0.7035 | 0.7072 | 0.7053 |
| HDELC-4 | 0.7408 | 0.7229 | 0.7277 | 0.7253 | |
| HDELC-6 | 0.7351 | 0.7040 | 0.7258 | 0.7147 | |
| CNAE | HDELC-2 | 0.8888 | 0.9098 | 0.8915 | 0.9006 |
| HDELC-4 | 0.9231 | 0.9110 | 0.9089 | 0.9099 | |
| HDELC-6 | 0.9437 | 0.9119 | 0.9080 | 0.9099 | |
| Gait | HDELC-2 | 0.7000 | 0.6838 | 0.6822 | 0.6830 |
| HDELC-4 | 0.7000 | 0.7676 | 0.7512 | 0.7593 | |
| HDELC-6 | 0.6000 | 0.6172 | 0.5975 | 0.6072 | |
| Ad | HDELC-2 | 0.9548 | 0.9602 | 0.9630 | 0.9616 |
| HDELC-4 | 0.9845 | 0.9653 | 0.9579 | 0.9616 | |
| HDELC-6 | 0.9802 | 0.9728 | 0.9732 | 0.9730 | |
| Parkinson | HDELC-2 | 0.8945 | 0.8882 | 0.8862 | 0.8872 |
| HDELC-4 | 0.8941 | 0.8808 | 0.8863 | 0.8835 | |
| HDELC-6 | 0.8872 | 0.8721 | 0.8647 | 0.8684 | |
| QSAR | HDELC-2 | 0.9004 | 0.8969 | 0.8870 | 0.8919 |
| HDELC-4 | 0.9152 | 0.9012 | 0.9217 | 0.9113 | |
| HDELC-6 | 0.9041 | 0.8991 | 0.9271 | 0.9129 | |
| QSAR_oral | HDELC-2 | 0.9921 | 0.9908 | 0.9910 | 0.9909 |
| HDELC-4 | 0.9986 | 0.9961 | 0.9950 | 0.9955 | |
| HDELC-6 | 0.9959 | 0.9934 | 0.9949 | 0.9941 | |
| REJAFADA | HDELC-2 | 0.9844 | 0.9709 | 0.9724 | 0.9716 |
| HDELC-4 | 0.9826 | 0.9697 | 0.9653 | 0.9675 | |
| HDELC-6 | 0.9733 | 0.9548 | 0.9429 | 0.9488 | |
| SCADI | HDELC-2 | 0.7842 | 0.7697 | 0.7539 | 0.7617 |
| HDELC-4 | 0.7861 | 0.8009 | 0.8045 | 0.8027 | |
| HDELC-6 | 0.7622 | 0.7535 | 0.7463 | 0.7499 | |
| Secom | HDELC-2 | 0.9488 | 0.9409 | 0.9431 | 0.9420 |
| HDELC-4 | 0.9593 | 0.9443 | 0.9457 | 0.9450 | |
| HDELC-6 | 0.9531 | 0.9441 | 0.9355 | 0.9398 | |
| Urban | HDELC-2 | 0.9452 | 0.9432 | 0.9305 | 0.9368 |
| HDELC-4 | 0.9355 | 0.9490 | 0.9314 | 0.9401 |
| Dataset | HDELC | Stacking | Bagging | Boosting | BOA [34] | JMO-FSCD [35] | PCA-Decision Tree [36] |
|---|---|---|---|---|---|---|---|
| AsianReligionsData | 0.8651 | 0.8361 | 0.8312 | 0.8367 | 0.8518 | 0.8633 | 0.8489 |
| Arrhythmia | 0.7397 | 0.7225 | 0.7411 | 0.7235 | 0.7361 | 0.7402 | 0.7296 |
| CNAE | 0.9444 | 0.9152 | 0.8600 | 0.9189 | 0.9102 | 0.9428 | 0.9225 |
| Gait | 0.7000 | 0.7000 | 0.7000 | 0.6000 | 0.6800 | 0.7000 | 0.6808 |
| Ad | 0.9842 | 0.9712 | 0.9534 | 0.9430 | 0.9847 | 0.9853 | 0.9823 |
| Parkinson | 0.8940 | 0.8921 | 0.8917 | 0.8932 | 0.8940 | 0.8944 | 0.8924 |
| QSAR | 0.9142 | 0.9108 | 0.9000 | 0.9000 | 0.9126 | 0.9132 | 0.9044 |
| QSAR_oral | 0.9989 | 0.9984 | 0.9802 | 0.9885 | 0.9892 | 0.9986 | 0.9989 |
| REJAFADA | 0.9844 | 0.9825 | 0.9813 | 0.9862 | 0.9837 | 0.9836 | 0.9840 |
| SCADI | 0.7857 | 0.7910 | 0.8427 | 0.7648 | 0.7829 | 0.7806 | 0.7844 |
| Secom | 0.9586 | 0.9562 | 0.9278 | 0.9531 | 0.9554 | 0.9546 | 0.9569 |
| Urban | 0.9444 | 0.9430 | 0.9301 | 0.9429 | 0.9355 | 0.9438 | 0.9381 |
| Algorithm | Computational Complexity |
|---|---|
| BEWOA [37] | |
| LightTS [38] | |
| AERF [39] | |
| HDELC |
| Algorithm | |||||
|---|---|---|---|---|---|
| Stacking | 0.0037 | 0.0158 | 0.0064 | 0.0064 | 0.0064 |
| Bagging | 0.0012 | 0.0069 | 0.0038 | 0.0038 | 0.0038 |
| Boosting | 0.0056 | 0.0298 | 0.0085 | 0.0085 | 0.0085 |
| BOA [34] | 2.3006 × 10−5 | 2.0887 × 10−4 | 5.9823 × 10−5 | 5.9823 × 10−5 | 5.9823 × 10−5 |
| JMO-FSCD [35] | 5.3924 × 10−10 | 2.4306 × 10−9 | 2.6731 × 10−9 | 2.6731 × 10−9 | 2.6731 × 10−9 |
| PCA-Decision Tree [36] | 1.4489 × 10−6 | 1.0351 × 10−5 | 1.0517 × 10−6 | 1.0517 × 10−6 | 1.0517 × 10−6 |
| Algorithm | |||||
|---|---|---|---|---|---|
| HDELC vs. Stacking | 0.0037 | 0.1052 | 0.0489 | 0.0396 | 0.0472 |
| HDELC vs. Bagging | 0.0012 | 0.0069 | 0.0038 | 0.0038 | 0.0038 |
| HDELC vs. Boosting | 0.0056 | 0.1398 | 0.0540 | 0.0481 | 0.0527 |
| HDELC vs. BOA [34] | 2.3006 × 10−5 | 6.4290 × 10−4 | 4.6833 × 10−4 | 3.5772 × 10−4 | 4.2085 × 10−4 |
| HDELC vs. PCA-Decision Tree [35] | 1.4489 × 10−6 | 5.7897 × 10−5 | 4.9836 × 10−5 | 2.5539 × 10−5 | 4.6791 × 10−5 |
| HDELC vs. JMO-FSCD [36] | 5.3924 × 10−10 | 1.2764 × 10−8 | 1.2273 × 10−8 | 1.0784 × 10−8 | 1.0784 × 10−8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, M.; Ye, N. High-Dimensional Ensemble Learning Classification: An Ensemble Learning Classification Algorithm Based on High-Dimensional Feature Space Reconstruction. Appl. Sci. 2024, 14, 1956. https://doi.org/10.3390/app14051956
Zhao M, Ye N. High-Dimensional Ensemble Learning Classification: An Ensemble Learning Classification Algorithm Based on High-Dimensional Feature Space Reconstruction. Applied Sciences. 2024; 14(5):1956. https://doi.org/10.3390/app14051956
Chicago/Turabian StyleZhao, Miao, and Ning Ye. 2024. "High-Dimensional Ensemble Learning Classification: An Ensemble Learning Classification Algorithm Based on High-Dimensional Feature Space Reconstruction" Applied Sciences 14, no. 5: 1956. https://doi.org/10.3390/app14051956
APA StyleZhao, M., & Ye, N. (2024). High-Dimensional Ensemble Learning Classification: An Ensemble Learning Classification Algorithm Based on High-Dimensional Feature Space Reconstruction. Applied Sciences, 14(5), 1956. https://doi.org/10.3390/app14051956