
TSE-UNet: Temporal and Spatial Feature-Enhanced Point Cloud Super-Resolution Model for Mechanical LiDAR


Abstract
1. Introduction
- To address the shortage of available open-source datasets in the field, we construct and release a simulation dataset, CARLA32-128, for a laser beam LiDAR point cloud super-resolution task. Additionally, a real-world dataset, Ruby32-128, is provided for the 32-to-128 laser beam LiDAR point cloud super-resolution task.
- Based on the semantic segmentation model UNet, we propose a temporal and spatial feature-enhanced point cloud super-resolution model called TSE-UNet. It utilizes a temporal feature attention aggregation module and a spatial feature enhancement module to fully leverage point cloud features from neighboring timestamps, improving super-resolution accuracy.
- We validate the effectiveness of the proposed method through extensive comparative experiments, ablation experiments, and visual qualitative experiments.
2. Related Works
2.1. Image Super-Resolution
2.2. Point Cloud Super-Resolution
3. Method
3.1. Data Collection
3.1.1. Simulation Scenario
3.1.2. Real Scenario
3.2. Point Cloud Projection and Back-Projection
3.3. TSE-UNet Model
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
4.3. Comparison Experiments
4.4. Ablation Study
4.5. Visualization
4.6. Speed Performance
4.7. The Number of Frames
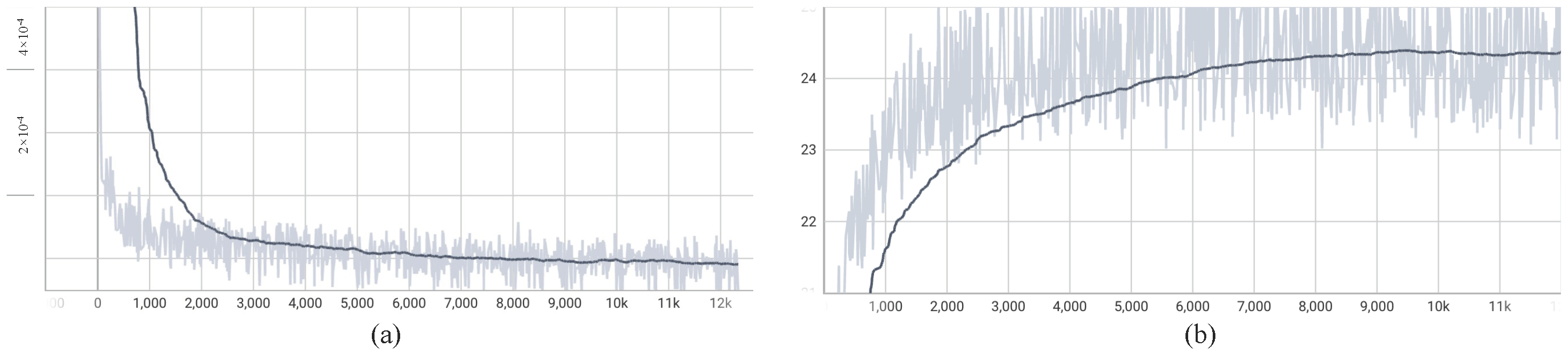
4.8. The Training Process
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, X.; Zhang, L.; Yang, J.; Cao, C.; Wang, W.; Ran, Y.; Tan, Z.; Luo, M. A review of multi-sensor fusion slam systems based on 3D LIDAR. Remote Sens. 2022, 14, 2835. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, T.; Wang, Y.; Wang, Y.; Zhao, H. Futr3d: A unified sensor fusion framework for 3d detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 172–181. [Google Scholar]
- Aijazi, A.; Malaterre, L.; Trassoudaine, L.; Checchin, P. Systematic evaluation and characterization of 3d solid state lidar sensors for autonomous ground vehicles. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 199–203. [Google Scholar] [CrossRef]
- Lin, J.; Liu, X.; Zhang, F. A decentralized framework for simultaneous calibration, localization and mapping with multiple LiDARs. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 4870–4877. [Google Scholar]
- Fei, B.; Yang, W.; Chen, W.M.; Li, Z.; Li, Y.; Ma, T.; Hu, X.; Ma, L. Comprehensive Review of Deep Learning-Based 3D Point Cloud Completion Processing and Analysis. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22862–22883. [Google Scholar] [CrossRef]
- Diab, A.; Kashef, R.; Shaker, A. Deep Learning for LiDAR Point Cloud Classification in Remote Sensing. Sensors 2022, 22, 7868. [Google Scholar] [CrossRef] [PubMed]
- Liu, K.; Gao, Z.; Lin, F.; Chen, B.M. Fg-net: A fast and accurate framework for large-scale lidar point cloud understanding. IEEE Trans. Cybern. 2022, 53, 553–564. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; He, X.; Qing, L.; Wu, Y.; Ren, C.; Sheriff, R.E.; Zhu, C. Real-world single image super-resolution: A brief review. Inf. Fusion 2022, 79, 124–145. [Google Scholar] [CrossRef]
- Yue, J.; Wen, W.; Han, J.; Hsu, L.T. 3D point clouds data super resolution-aided LiDAR odometry for vehicular positioning in urban canyons. IEEE Trans. Veh. Technol. 2021, 70, 4098–4112. [Google Scholar] [CrossRef]
- Alaba, S.Y.; Ball, J.E. A survey on deep-learning-based lidar 3d object detection for autonomous driving. Sensors 2022, 22, 9577. [Google Scholar] [CrossRef]
- Liu, B.; Huang, H.; Su, Y.; Chen, S.; Li, Z.; Chen, E.; Tian, X. Tree species classification using ground-based LiDAR data by various point cloud deep learning methods. Remote Sens. 2022, 14, 5733. [Google Scholar] [CrossRef]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the British Machine Vision Conference, BMVC 2012, Surrey, UK, 3–7 September 2012. [Google Scholar]
- Gao, X.; Zhang, K.; Tao, D.; Li, X. Image super-resolution with sparse neighbor embedding. IEEE Trans. Image Process. 2012, 21, 3194–3205. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Zhong, B.; Fu, Y. Residual non-local attention networks for image restoration. arXiv 2019, arXiv:1903.10082. [Google Scholar]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single image super-resolution via a holistic attention network. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XII 16. Springer: Cham, Switzerland, 2020; pp. 191–207. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12299–12310. [Google Scholar]
- Li, W.; Lu, X.; Qian, S.; Lu, J.; Zhang, X.; Jia, J. On efficient transformer-based image pre-training for low-level vision. arXiv 2021, arXiv:2112.10175. [Google Scholar]
- Zhang, M.; Zhang, C.; Zhang, Q.; Guo, J.; Gao, X.; Zhang, J. ESSAformer: Efficient Transformer for Hyperspectral Image Super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 23073–23084. [Google Scholar]
- Ren, L.; Li, D.; Ouyang, Z.; Niu, J.; He, W. T-UNet: A Novel TC-Based Point Cloud Super-Resolution Model for Mechanical LiDAR. In Proceedings of the Collaborative Computing: Networking, Applications and Worksharing: 17th EAI International Conference, CollaborateCom 2021, Virtual Event, 16–18 October 2021; Part I 17. Springer: Cham, Switzerland, 2021; pp. 697–712. [Google Scholar]
- Guo, M.H.; Lu, C.Z.; Liu, Z.N.; Cheng, M.M.; Hu, S.M. Visual attention network. Comput. Vis. Media 2023, 9, 733–752. [Google Scholar] [CrossRef]
- Lin, W.; Wu, Z.; Chen, J.; Huang, J.; Jin, L. Scale-aware modulation meet transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6015–6026. [Google Scholar]
- Yu, L.; Li, X.; Fu, C.W.; Cohen-Or, D.; Heng, P.A. Pu-net: Point cloud upsampling network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2790–2799. [Google Scholar]
- Qian, Y.; Hou, J.; Kwong, S.; He, Y. PUGeo-Net: A geometry-centric network for 3D point cloud upsampling. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 752–769. [Google Scholar]
- Zhao, Y.; Hui, L.; Xie, J. Sspu-net: Self-supervised point cloud upsampling via differentiable rendering. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 2214–2223. [Google Scholar]
- Ye, S.; Chen, D.; Han, S.; Wan, Z.; Liao, J. Meta-PU: An arbitrary-scale upsampling network for point cloud. IEEE Trans. Vis. Comput. Graph. 2021, 28, 3206–3218. [Google Scholar] [CrossRef]
- Shan, T.; Wang, J.; Chen, F.; Szenher, P.; Englot, B. Simulation-based Lidar Super-resolution for Ground Vehicles. arXiv 2020, arXiv:2004.05242. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, S.; Wang, X. Learning continuous image representation with local implicit image function. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8628–8638. [Google Scholar]
- Kwon, Y.; Sung, M.; Yoon, S.E. Implicit LiDAR network: LiDAR super-resolution via interpolation weight prediction. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 8424–8430. [Google Scholar]
- Eskandar, G.; Sudarsan, S.; Guirguis, K.; Palaniswamy, J.; Somashekar, B.; Yang, B. HALS: A Height-Aware Lidar Super-Resolution Framework for Autonomous Driving. arXiv 2022, arXiv:2202.03901. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Part III 18. Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Names | Number of Frames | Laser Beams | FOV (Vertical) |
|---|---|---|---|
| CARLA32 | 7025 | 32 | (−25°, 15°) |
| CARLA128 | 7025 | 128 | (−25°, 15°) |
| Ruby-32 | 2402 | 32 | (−25°, 15°) |
| Ruby-128 | 2402 | 128 | (−25°, 15°) |
| Names | Number of Training Frames | Number of Testing Frames |
|---|---|---|
| CARLA32-128 | 5162 | 1863 |
| Ruby32-128 | 1456 | 946 |
| Datasets | Methods | PSNR | SSIM Loss |
|---|---|---|---|
| UNet | 25.11 | 30.99 | |
| T-UNet | 26.97 | 11.89 | |
| CARLA32-128 | LKA-T-UNet | 27.01 | 9.61 |
| SMT-T-UNet | 27.24 | 12.40 | |
| TSE-UNet (ours) | 27.52 | ||
| UNet | 23.96 | 24.26 | |
| T-UNet | 24.78 | 14.68 | |
| Ruby32-128 | LKA-T-UNet | 24.75 | 14.49 |
| SMT-T-UNet | 24.80 | 14.45 | |
| TSE-UNet (ours) | 24.82 |
| Methods | Components | PSNR | SSIM Loss | ||
|---|---|---|---|---|---|
| T | TE | SE | |||
| UNet | × | × | × | 25.11 | 30.99 |
| Variant 1 | ✓ | × | × | 26.97 | 11.89 |
| Variant 2 | ✓ | ✓ | × | 27.38 | 9.16 |
| TSE-UNet | ✓ | ✓ | ✓ | 27.52 | |
| Datasets | CARLA32-128 | Ruby32-128 |
| Latency | 21.22 ms | 23.85 ms |
| Frequency | 47.12 Hz | 41.92 Hz |
| Number of Frames | PSNR | SSIM Loss | Latency | Frequency |
|---|---|---|---|---|
| 8 | 27.19 | 14.44 ms | 69.26 Hz | |
| 16 | 27.52 | 21.22 ms | 47.12 Hz | |
| 32 | 27.31 | 33.64 ms | 29.72 Hz |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, L.; Li, D.; Ouyang, Z.; Zhang, Z. TSE-UNet: Temporal and Spatial Feature-Enhanced Point Cloud Super-Resolution Model for Mechanical LiDAR. Appl. Sci. 2024, 14, 1510. https://doi.org/10.3390/app14041510
Ren L, Li D, Ouyang Z, Zhang Z. TSE-UNet: Temporal and Spatial Feature-Enhanced Point Cloud Super-Resolution Model for Mechanical LiDAR. Applied Sciences. 2024; 14(4):1510. https://doi.org/10.3390/app14041510
Chicago/Turabian StyleRen, Lu, Deyi Li, Zhenchao Ouyang, and Zhibin Zhang. 2024. "TSE-UNet: Temporal and Spatial Feature-Enhanced Point Cloud Super-Resolution Model for Mechanical LiDAR" Applied Sciences 14, no. 4: 1510. https://doi.org/10.3390/app14041510
APA StyleRen, L., Li, D., Ouyang, Z., & Zhang, Z. (2024). TSE-UNet: Temporal and Spatial Feature-Enhanced Point Cloud Super-Resolution Model for Mechanical LiDAR. Applied Sciences, 14(4), 1510. https://doi.org/10.3390/app14041510