
Portrait Semantic Segmentation Method Based on Dual Modal Information Complementarity

Abstract
1. Introduction
- (1)
- In the encoder stage, we extract image feature based on RGB mode and gray mode: RGB image and grayscale image are simultaneously used as inputs to model encoder, corresponding feature representation is obtained, and feature fusion is carried out. The gray image can be directly converted by RGB image, which avoids the overhead of collecting other modal images in the data set, and realizes the information complementarity and feature extraction in the dual mode. The feature extraction of gray-scale image improves the ability of the model to extract the target figure under low light.
- (2)
- We propose the SK-ASSP (Selective Kernel—Atrous Spatial Pyramid Pooling) module as a new feature extraction module in the encoder stage: SK-ASSP dynamically adjusts the weight of the void convolution of different receptive fields according to the size of the target in the image through soft attention, thus providing feature extraction capabilities for portrait targets of different sizes. At the same time, SK-ASSP uses edge optimization branch to improve the edge segmentation accuracy of target portrait according to edge feature map.
- (3)
- We propose the mixed-parallel attention mechanism to improve the encoder-decoder connection process: through parallel channel attention module and position attention module, the channel information and location information of input features are captured respectively.
2. Related Works
2.1. Semantic Segmentation Based on CNN
2.2. Semantic Segmentation of Cross-Modal
3. Methods
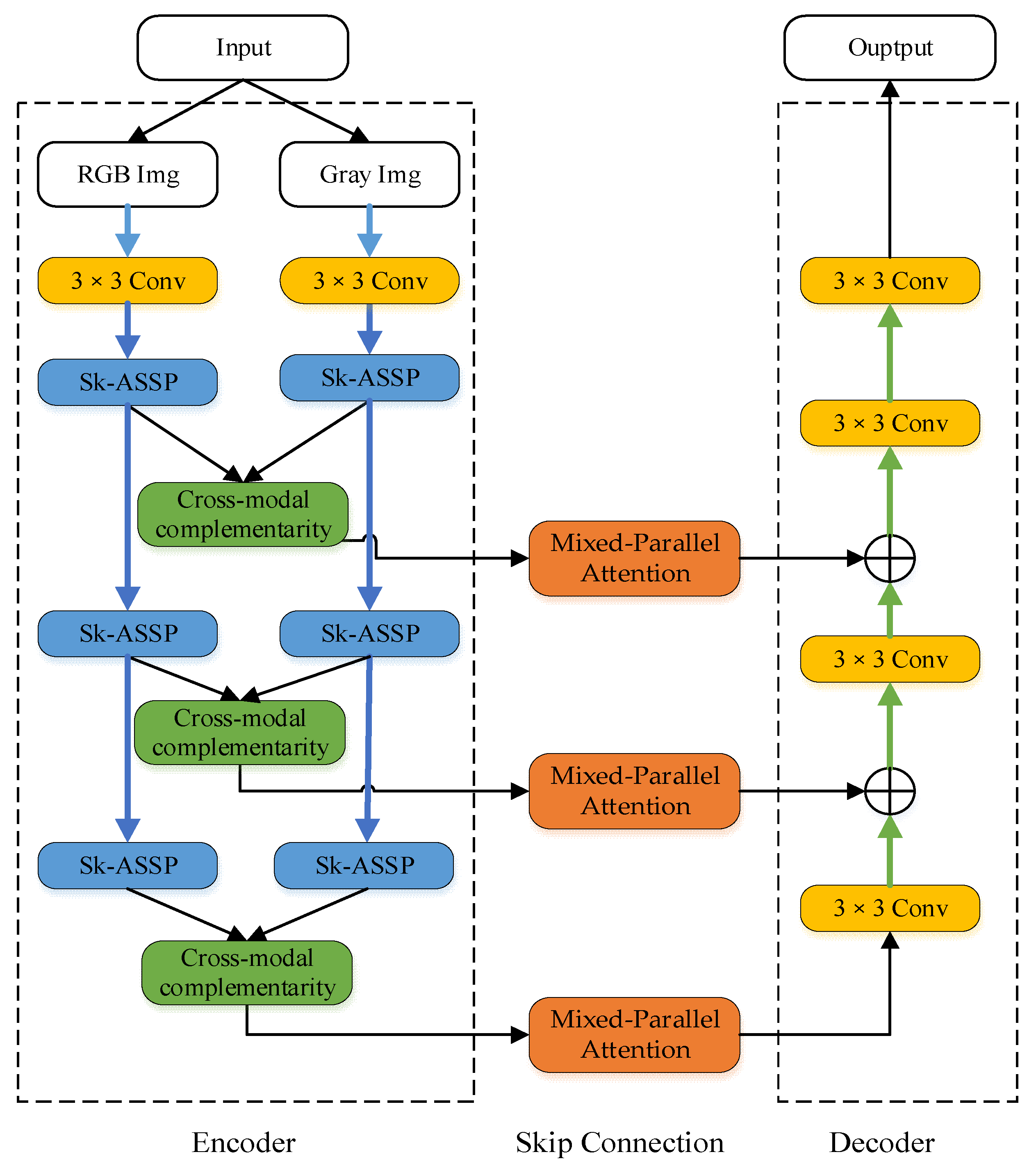
3.1. Overall Architecture
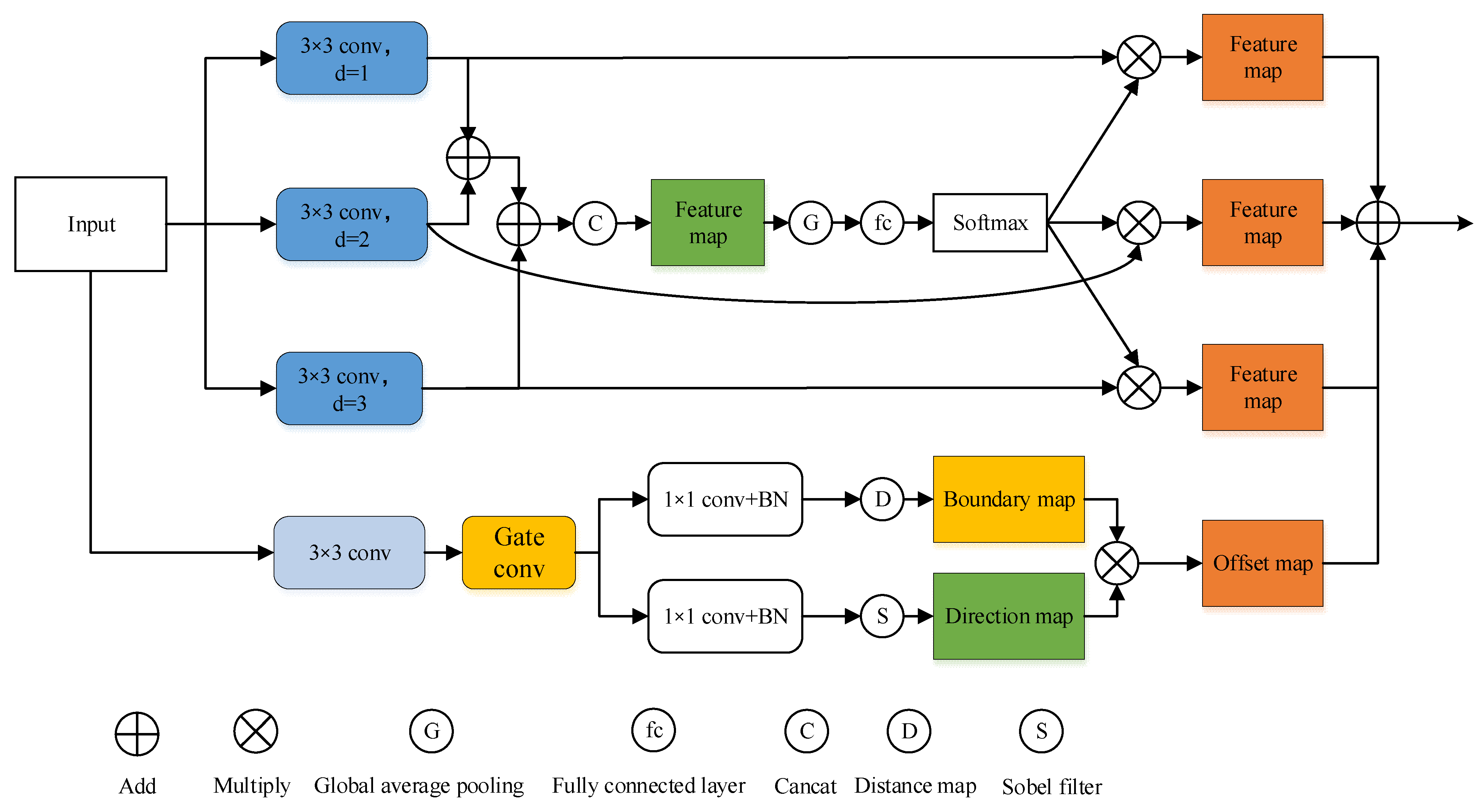
3.2. SK-ASSP Module
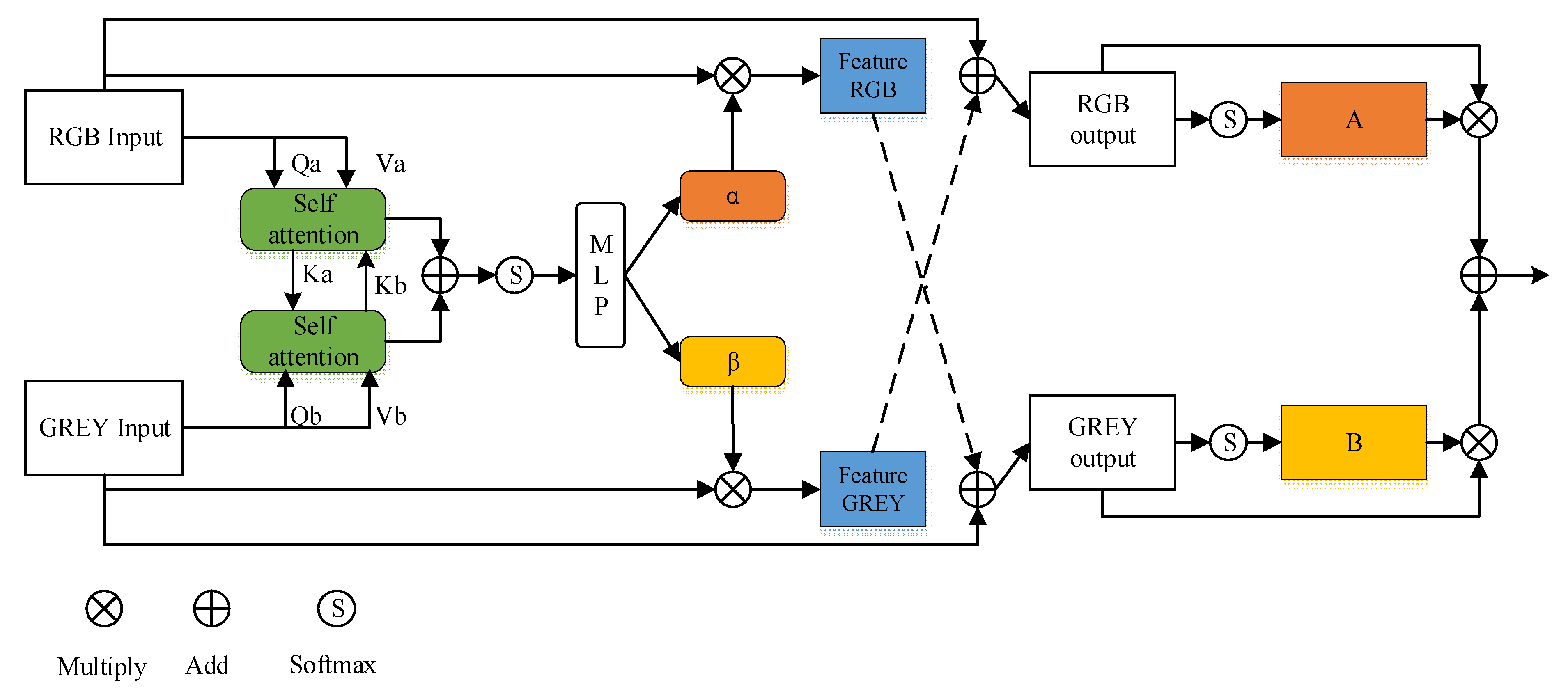
3.3. Cross-Modal Complementarity Module
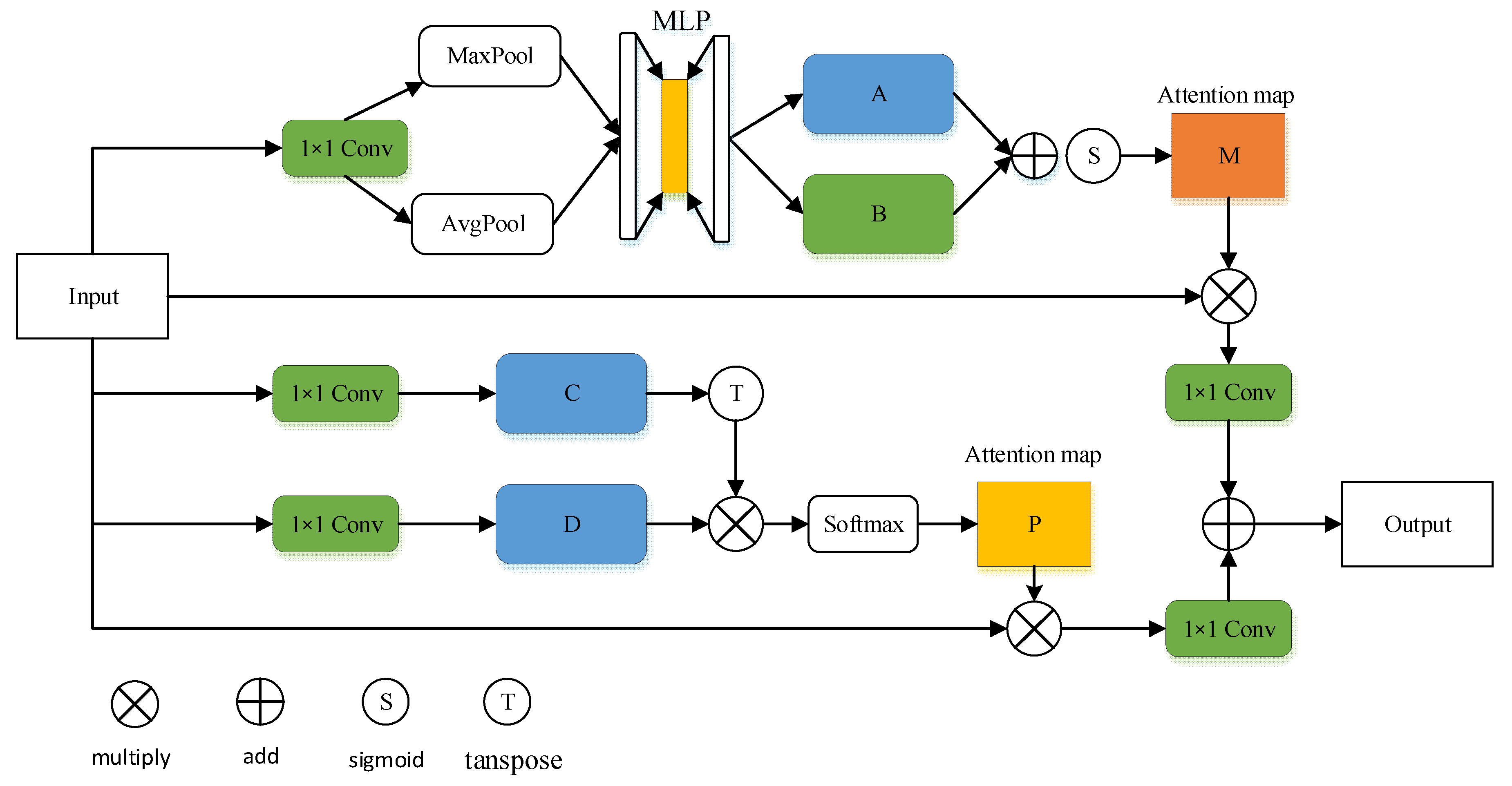
3.4. Mixed-Parallel Attention Module
3.5. Loss Function
4. Experiments
4.1. Experimental Environment
4.2. Dataset
4.3. Evaluation Metrics
4.4. Module Ablation Experiments
4.4.1. Encoder Based Ablation Experiments
4.4.2. Attention Module Based Ablation Experiments
4.4.3. Loss Function Based Ablation Experiments
4.5. Network Comparison Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cai, J.L. Research on Image Semantic Segmentation Technology Based on Deep Learning; Guangdong University of Technology: Guangzhou, China, 2021. [Google Scholar]
- Wang, X. Research on Portrait Segmentation Based on Deep Learning; Northwest A&F University: Xianyang, China, 2022. [Google Scholar]
- Jia, D.Y. Semantic Segmentation of Road Potholes Based on Deep Learning; Ningxia University: Yinchuan, China, 2022. [Google Scholar]
- Wang, X.; Wang, M.L.; Bian, D.W. Algorithm for Portrait Segmentation Combined with MobileNetv2 and Attention Mechanism. Comput. Eng. Appl. 2022, 58, 220–228. [Google Scholar]
- Kuai, Y.; Wang, B.; Wu, Y.L.; Chen, B.T.; Chen, X.D.; Xue, W.B. Urban vegetation classification based on multi-scale feature perception network for UAV images. J. Geo-Inf. Sci. 2022, 24, 962–980. [Google Scholar]
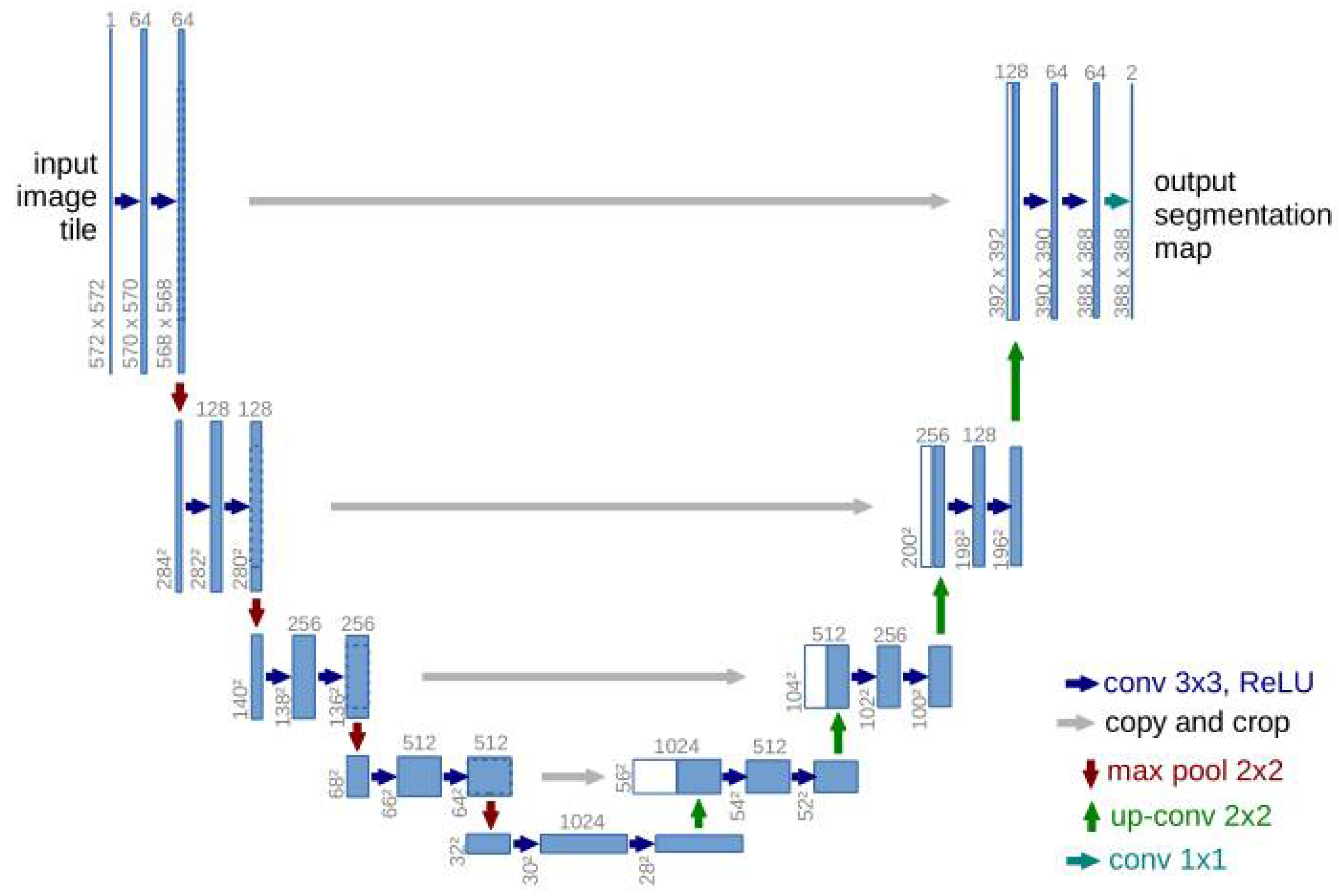
- Olaf, R.; Philipp, F.; Thomas, B. U-net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Su, R.; Zhang, D.; Liu, J.; Cheng, C. MSU-Net: Multi-Scale U-Net for 2D Medical Image Segmentation. Front. Genet. 2021, 12, 639930. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhao, W.; Chen, Y.; Xiang, S.; Liu, Y.; Wang, C. Research on Image Semantic Segmentation Algorithm Based on Improved DeepLabv3+. J. Syst. Simul. 2023, 35, 2333–2344. [Google Scholar]
- Reza, A.; Maryam, A.; Mahmood, F. Attention Deeplabv3+: Multi-level Context Attention Mechanism for Skin Lesion Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 251–266. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Li, H.; Qiu, K.; Chen, L.; Mei, X.; Hong, L.; Tao, C. SCAttNet: Semantic Segmentation Network with Spatial and Channel Attention Mechanism for High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 905–909. [Google Scholar] [CrossRef]
- Amer, A.; Lambrou, T.; Ye, X. MDA-Unet: A Multi-Scale Dilated Attention U-Net for Medical Image Segmentation. Appl. Sci. 2022, 12, 3676. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhu, D.L.; Ding, H.H. Street Scene Real-Time Semantic Segmentation with Fusion Cross Attention Mechanism [J/OL]. Computer Applications and Software. 2024. Available online: https://link.cnki.net/urlid/31.1260.TP.20240112.1654.002 (accessed on 15 January 2024).
- Wang, X.; Li, Z.; Huang, Y.; Jiao, Y. Multimodal medical image segmentation using multi-scale context-aware network. Neurocomputing 2022, 486, 135–146. [Google Scholar] [CrossRef]
- Zhang, J.Y.; Zhang, R.F.; Liu, Y.H.; Yuan, W.H. Multimodal image semantic segmentation based on attention mechanism. Chin. J. Liq. Cryst. Disp. 2023, 38, 975–984. [Google Scholar] [CrossRef]
- Abhinav, V.; Rohit, M.; Wolfram, B. Self-Supervised Model Adaptation for Multimodal Semantic Segmentation. Int. J. Comput. Vis. 2020, 128, 1239–1285. [Google Scholar]
- Sun, H.Q.; Pan, C.; He, L.M.; Xu, Z. Remote Sensing Image Semantic Segmentation Network Based on Multimodal Feature Fusion. Comput. Eng. Appl. 2022, 58, 256–264. [Google Scholar]
- Wang, L.C.; Gu, N.N.; Xin, J.J.; Wang, S.F. RGB-D Dual Modal Information Complementary Semantic Segmentation Network. J. Comput.-Aided Des. Comput. Graph. 2023, 35, 1489–1499. [Google Scholar]
- Chen, W.Y. Pedestrian Detection and Scene Segmentation Based on Multimodal Image Fusion; Central South University: Changsha, China, 2022. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- Feng, W.B.; Li, S.; Tian, H.; Yang, X.; Ma, C.; Yu, C. Images semantic segmentation method based on fusion edge optimization. Saf. Coal Mines 2022, 53, 136–141. [Google Scholar]
- Yuan, Y.; Xie, J.; Chen, X.; Wang, J. SegFix: Model-Agnostic Boundary Refinement for Segmentation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 489–506. [Google Scholar]
- Bao, L.; Yang, Z.; Wang, S.; Bai, D.; Lee, J. Real Image Denoising Based on Multi-Scale Residual Dense Block and Cascaded. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 448–449. [Google Scholar]
- Wei, W.; Tao, C.; Qiong, L. Complementarity-aware cross-modal feature fusion network for RGB-T semantic segmentation. Pattern Recognit. 2022, 131, 2473–2480. [Google Scholar]
- Du, M.M.; Sima, H.F. A-LinkNet: Semantic segmentation network based on attention and spatial information fusion. Chin. J. Liq. Cryst. Disp. 2022, 37, 1199–1208. [Google Scholar] [CrossRef]
- Bischke, B.; Helber, P.; Folz, J.; Borth, D.; Dengel, A. Multi-task learning for segmentation of building footprints with deep neural networks. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1480–1484. [Google Scholar]
- Guo, M.; Liu, H.; Xu, Y.; Huang, Y. Building Extraction Based on U-Net with an Attention Block and Multiple Losses. Remote Sens. 2020, 12, 1400. [Google Scholar] [CrossRef]
- Huang, Y.J.; Shi, Z.F.; Wang, Z.Q.; Wang, Z. Improved U-net based on Mixed Loss Function for Liver Medical I-mage Segmentation. Laser Optoelectron. Prog. 2020, 57, 74–83. [Google Scholar]
- Chen, Q.; Ge, T. Semantic human matting. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 618–626. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Zhang, S.H.; Dong, X.; Li, H.; Li, R.; Yang, Y.L. PortraitNet: Realtime portrait segmentation network for mobile device. Comput. Graph. 2019, 80, 104–113. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]


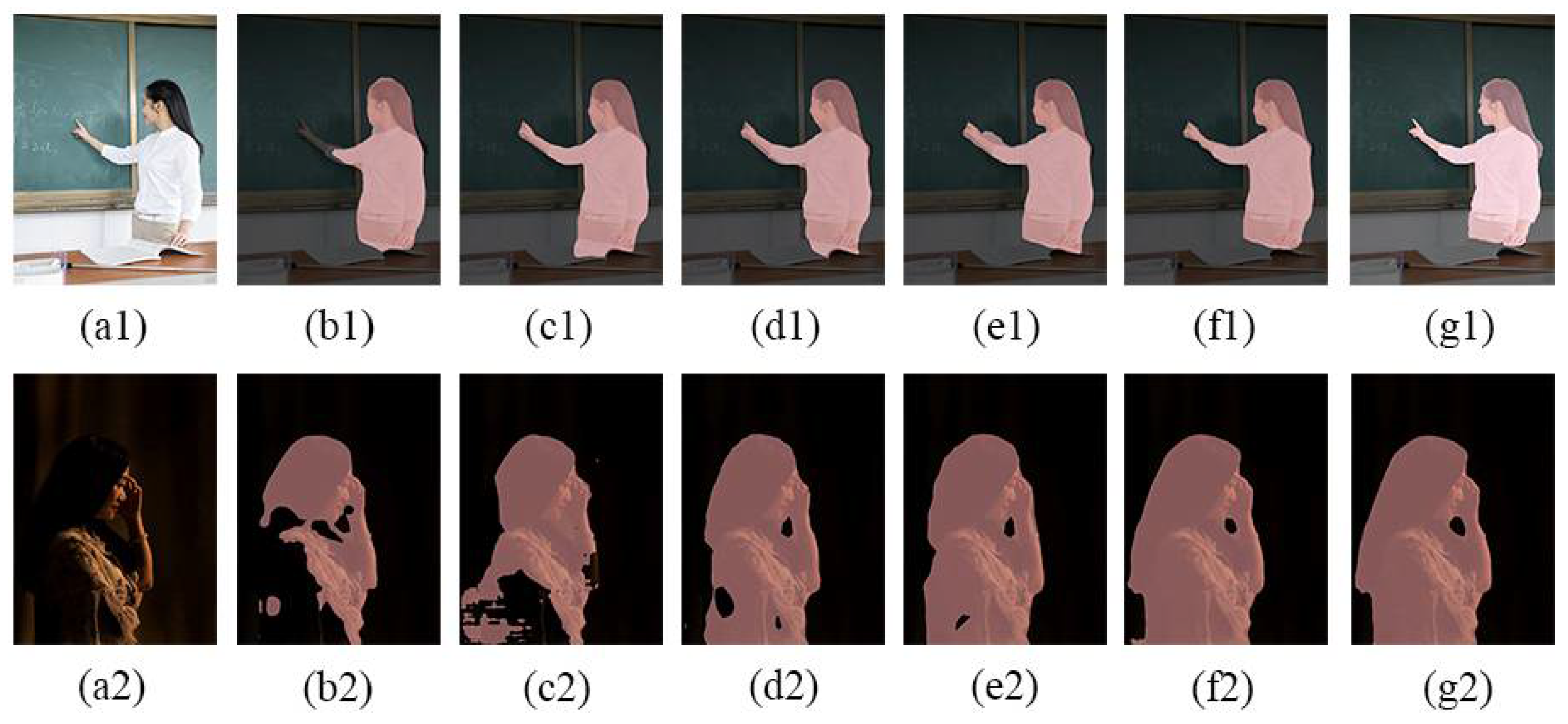

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Gray Image Input | ASSP | SK-ASSP, Adaptive ASSP Branches | SK-ASSP, Edge Optimization Branches | Cross-Modal Complementary Module | PA/% | MIoU/% |
|---|---|---|---|---|---|---|---|
| Network_1 | 94.72 | 92.06 | |||||
| Network_2 | ✓ | 94.81 | 92.17 | ||||
| Network_3 | ✓ | ✓ | 94.92 | 92.30 | |||
| Network_4 | ✓ | ✓ | ✓ | 95.54 | 93.12 | ||
| Network_5 | ✓ | ✓ | ✓ | 95.99 | 93.76 | ||
| Network_6 | ✓ | ✓ | ✓ | ✓ | 96.19 | 94.08 |
| Network | Attention Gate | CBAM | Mixed-Parallel Attention Module | PA/% | MIoU/% |
|---|---|---|---|---|---|
| Network_1 | 94.72 | 92.06 | |||
| Network_2 | ✓ | 95.22 | 93.02 | ||
| Network_3 | ✓ | 95.66 | 93.35 | ||
| Network_4 | ✓ | 95.80 | 93.56 |
| α Value | β Value | PA/% | MIoU/% |
|---|---|---|---|
| 0.1 | 0.9 | 94.85 | 92.26 |
| 0.2 | 0.8 | 94.88 | 92.28 |
| 0.3 | 0.7 | 94.91 | 92.32 |
| 0.4 | 0.6 | 94.90 | 92.30 |
| 0.5 | 0.5 | 94.86 | 92.27 |
| 0.6 | 0.4 | 94.82 | 92.23 |
| 0.7 | 0.3 | 94.80 | 92.19 |
| 0.8 | 0.2 | 94.77 | 92.17 |
| 0.9 | 0.1 | 94.76 | 92.15 |
| Network | PA/% | MIoU/% | Parameters/M | Spent Time Each Image/S |
|---|---|---|---|---|
| U-net | 94.72 | 92.06 | 44.93 | 0.017 |
| LinkNet | 95.54 | 93.12 | 47.82 | 0.020 |
| PortraitNet | 95.95 | 94.33 | 49.14 | 0.016 |
| Deeplab V3+ | 96.22 | 94.69 | 54.71 | 0.022 |
| Trans UNet | 96.60 | 95.16 | 58.16 | 0.035 |
| Ours | 96.89 | 95.48 | 56.02 | 0.029 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, G.; Tang, C. Portrait Semantic Segmentation Method Based on Dual Modal Information Complementarity. Appl. Sci. 2024, 14, 1439. https://doi.org/10.3390/app14041439
Feng G, Tang C. Portrait Semantic Segmentation Method Based on Dual Modal Information Complementarity. Applied Sciences. 2024; 14(4):1439. https://doi.org/10.3390/app14041439
Chicago/Turabian StyleFeng, Guang, and Chong Tang. 2024. "Portrait Semantic Segmentation Method Based on Dual Modal Information Complementarity" Applied Sciences 14, no. 4: 1439. https://doi.org/10.3390/app14041439
APA StyleFeng, G., & Tang, C. (2024). Portrait Semantic Segmentation Method Based on Dual Modal Information Complementarity. Applied Sciences, 14(4), 1439. https://doi.org/10.3390/app14041439