
Combined Data Augmentation on EANN to Identify Indoor Anomalous Sound Event


Abstract
1. Introduction
- (i)
- We studied the impact of different combinations of data augmentation methods on detection sensitivity in indoor abnormal sound environments, which can provide a quantitative reference for subsequent related research.
- (ii)
- We successfully demonstrated that a data augmentation framework combining offline processing of raw audio with online enhancement of time-frequency masking of spectrograms (spectral features) can effectively improve the recognition ability of deep learning models for indoor abnormal sound in limited datasets. Even in the case of very limited data, it can avoid model overfitting and is of practical value.
2. Materials and Methods
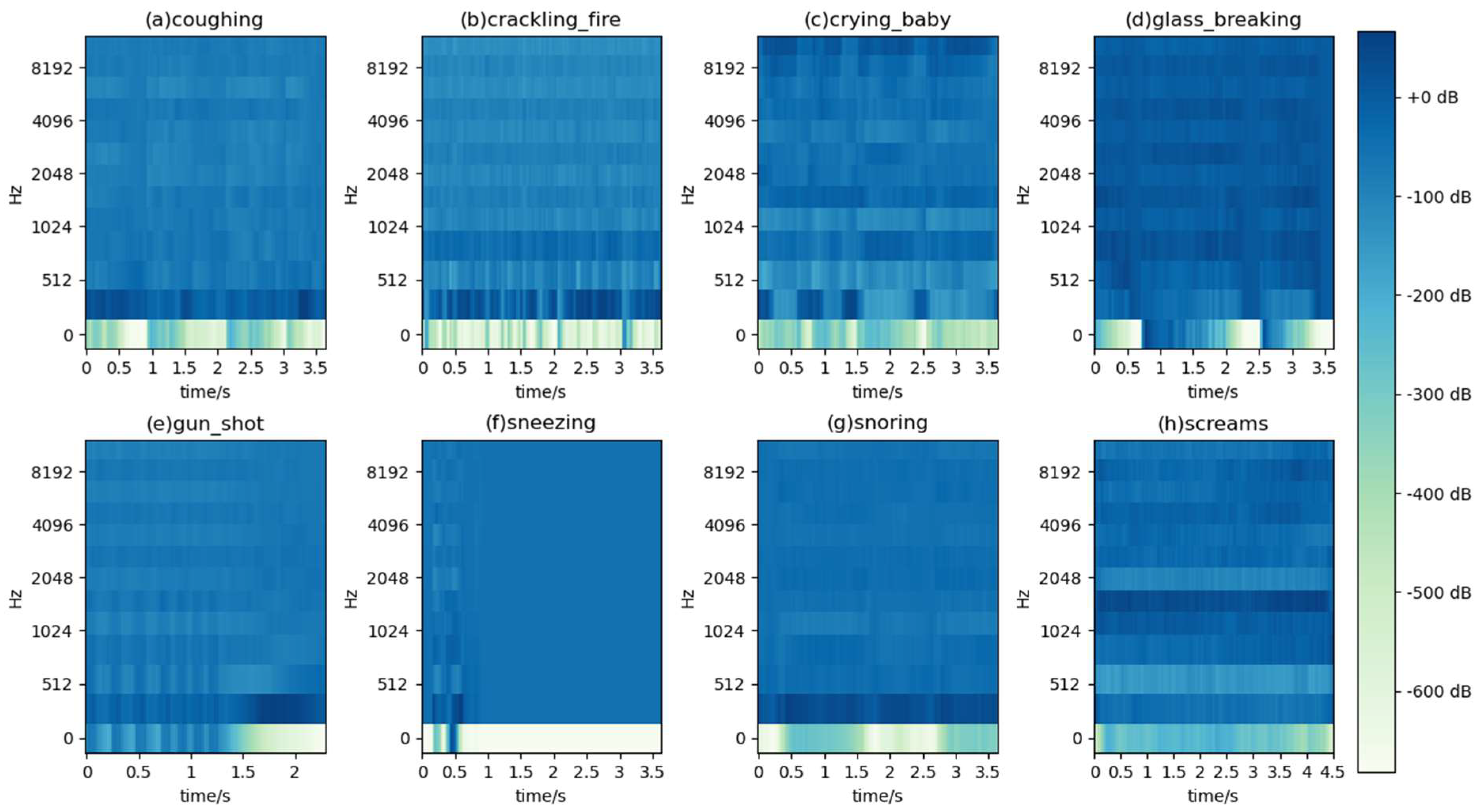
2.1. Dataset Generation
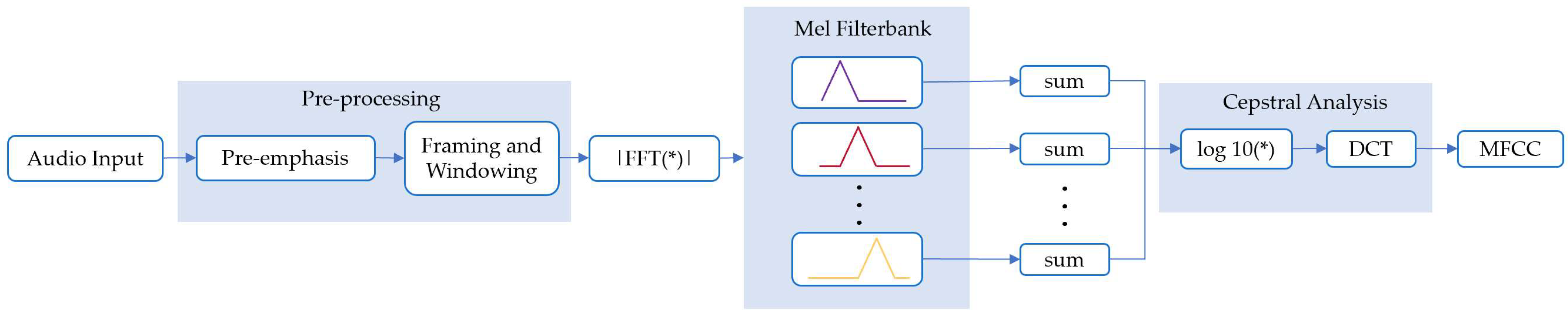
2.2. Mel-Frequency Cepstral Coefficients
2.3. Data Augmentation Methods
2.3.1. Time Stretching (TS)
2.3.2. Pitch Shifting (PS)
2.3.3. Background Noise (BN)
2.3.4. Online Augmentation
2.4. EANN Identification Model
2.5. AdamW Optimizer
2.6. Implementation Details
3. Results
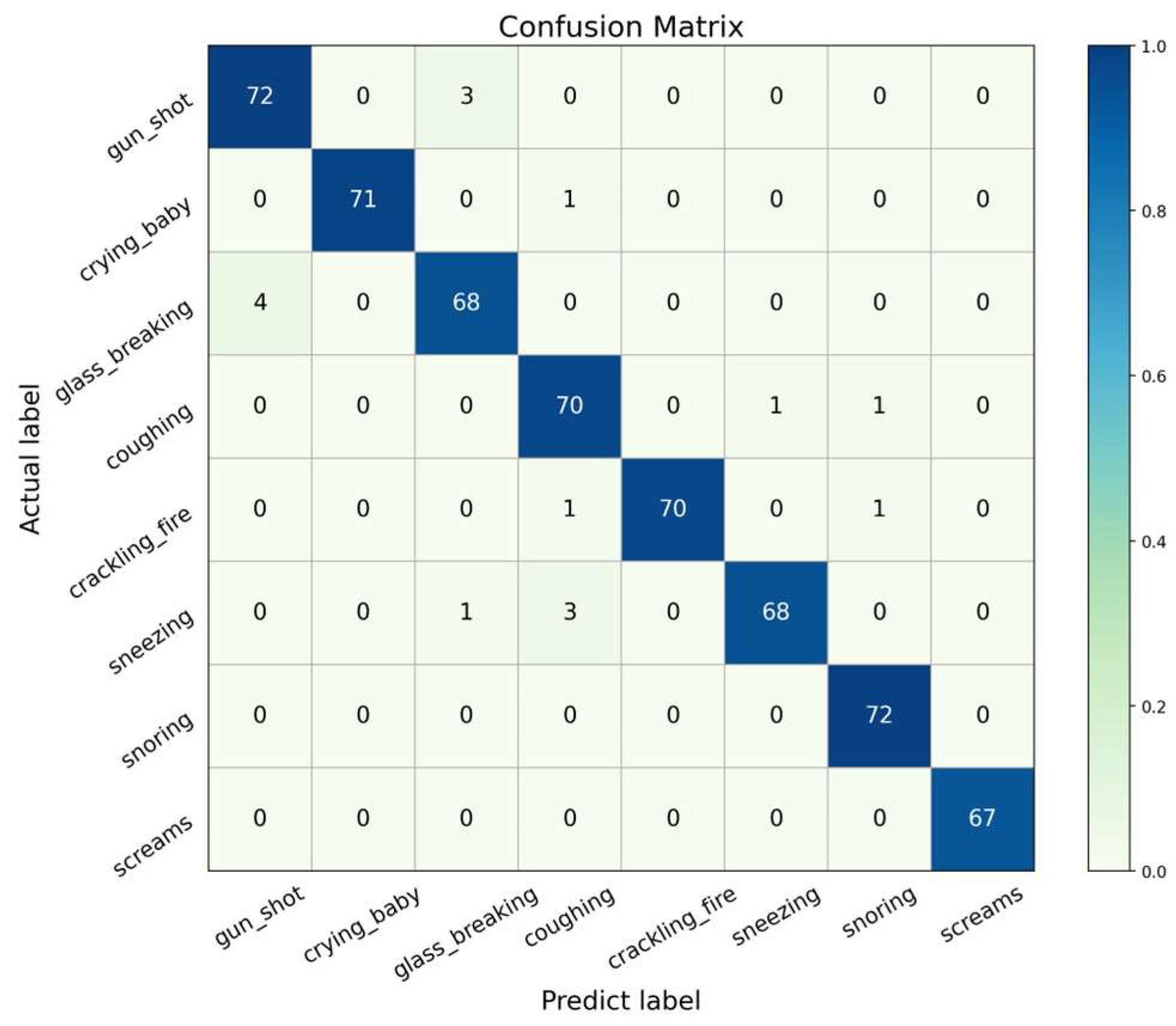
3.1. Model and Optimizer Performance
3.2. Time Stretching Performance
3.3. Pitch Shifting Performance
3.4. Background Noise Performance
3.5. Combined Augmentation Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mondal, S.; Barman, A.D. Human auditory model based real-time smart home acoustic event monitoring. Multimed. Tools Appl. 2022, 81, 887–906. [Google Scholar] [CrossRef]
- Salekin, A.; Ghaffarzadegan, S.; Feng, Z.; Stankovic, J. A Real-Time Audio Monitoring Framework with Limited Data for Constrained Devices. In Proceedings of the 2019 15th International Conference on Distributed Computing in Sensor Systems (DCOSS), Santorini, Greece, 29–31 May 2019; pp. 98–105. [Google Scholar]
- Xie, J.; Hu, K.; Zhu, M.; Yu, J.; Zhu, Q. Investigation of Different CNN-Based Models for Improved Bird Sound Classification. IEEE Access 2019, 7, 175353–175361. [Google Scholar] [CrossRef]
- Kim, H.-G.; Kim, J.Y. Environmental sound event detection in wireless acoustic sensor networks for home telemonitoring. China Commun. 2017, 14, 1–10. [Google Scholar] [CrossRef]
- Kim, H.-G.; Kim, G.Y. Deep Neural Network-Based Indoor Emergency Awareness Using Contextual Information from Sound, Human Activity, and Indoor Position on Mobile Device. IEEE Trans. Consum. Electron. 2020, 66, 271–278. [Google Scholar] [CrossRef]
- Shilaskar, S.; Bhatlawande, S.; Vaishale, A.; Duddalwar, P.; Ingale, A. An Expert System for Identification of Domestic Emergency based on Normal and Abnormal Sound. In Proceedings of the 2023 Somaiya International Conference on Technology and Information Management (SICTIM), Mumbai, India, 24–25 March 2023; pp. 100–105. [Google Scholar]
- Mayorga, P.; Ibarra, D.; Zeljkovic, V.; Druzgalski, C. Quartiles and Mel Frequency Cepstral Coefficients vectors in Hidden Markov-Gaussian Mixture Models classification of merged heart sounds and lung sounds signals. In Proceedings of the 2015 International Conference on High Performance Computing & Simulation (HPCS), Amsterdam, The Netherlands, 20–24 July 2015; pp. 298–304. [Google Scholar]
- Rabiner, L.R. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Kong, Q.; Cao, Y.; Iqbal, T.; Wang, Y.; Wang, W.; Plumbley, M.D. PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2880–2894. [Google Scholar] [CrossRef]
- Sang, J.; Park, S.; Lee, J. Convolutional Recurrent Neural Networks for Urban Sound Classification Using Raw Waveforms. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), New York, NY, USA, 3–7 September 2018; pp. 2444–2448. [Google Scholar]
- Lezhenin, I.; Bogach, N.; Pyshkin, E. Urban Sound Classification using Long Short-Term Memory Neural Network. In Proceedings of the 2019 Federated Conference on Computer Science and Information Systems, Leipzig, Germany, 1–4 September 2019; Volume 18, pp. 57–69. [Google Scholar]
- Kumawat, P.; Routray, A. Applying TDNN Architectures for Analyzing Duration Dependencies on Speech Emotion Recognition. In Proceedings of the Interspeech 2021, Brno, Czechia, 30 August–3 September 2021; pp. 3410–3414. [Google Scholar]
- Li, Y.; Cao, W.; Xie, W.; Huang, Q.; Pang, W.; He, Q. Low-Complexity Acoustic Scene Classification Using Data Augmentation and Lightweight ResNet. In Proceedings of the 2022 16th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 21–24 October 2022; pp. 41–45. [Google Scholar]
- Vafeiadis, A.; Votis, K.; Giakoumis, D.; Tzovaras, D.; Chen, L.; Hamzaoui, R. Audio content analysis for unobtrusive event detection in smart home. Eng. Appl. Artif. Intell. 2020, 89, 103226. [Google Scholar] [CrossRef]
- Pandya, S.; Ghayvat, H. Ambient acoustic event assistive framework for identification, detection, and recognition of unknown acoustic events of a residence. Adv. Eng. Inform. 2021, 47, 101238. [Google Scholar] [CrossRef]
- Li, Y.; Li, H.; Fan, D.; Li, Z.; Ji, S. Improved Sea Ice Image Segmentation Using U2-Net and Dataset Augmentation. Appl. Sci. 2023, 13, 9402. [Google Scholar] [CrossRef]
- Mikami, K.; Nemoto, M.; Ishinoda, A.; Nagura, T.; Nakamura, M.; Matsumoto, M.; Nakashima, D. Improvement of Machine Learning-Based Prediction of Pedicle Screw Stability in Laser Resonance Frequency Analysis via Data Augmentation from Micro-CT Images. Appl. Sci. 2023, 13, 9037. [Google Scholar] [CrossRef]
- Anvarjon, T.; Mustaqeem, M.; Kwon, S. Deep-net: A lightweight CNN-based speech emotion recognition system using deep frequency features. Sensors 2020, 20, 1–16. [Google Scholar] [CrossRef]
- Wang, M.; Yao, Y.; Qiu, H.; Song, X. Adaptive Memory-Controlled Self-Attention for Polyphonic Sound Event Detection. Symmetry 2022, 14, 366. [Google Scholar] [CrossRef]
- Nam, G.-H.; Bu, S.-J.; Park, N.-M.; Seo, J.-Y.; Jo, H.-C.; Jeong, W.-T. Data Augmentation Using Empirical Mode Decomposition on Neural Networks to Classify Impact Noise in Vehicle. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 731–735. [Google Scholar]
- Salamon, J.; Bello, J.P. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Process. Lett. (SPL) 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Abeysinghe, A.; Tohmuang, S.; Davy, J.L.; Fard, M. Data augmentation on convolutional neural networks to classify mechanical noise. Appl. Acoust. 2023, 203, 109209. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Ding, Q.; Sun, J.-Q. Intelligent rotating machinery fault diagnosis based on deep learning using data augmentation. J. Intell. Manuf. 2020, 31, 433–452. [Google Scholar] [CrossRef]
- Abayomi-Alli, O.O.; Abbasi, A.A. Detection of COVID-19 from Deep Breathing Sounds Using Sound Spectrum with Image Augmentation and Deep Learning Techniques. Electronics 2022, 11, 2520. [Google Scholar] [CrossRef]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.-C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. In Proceedings of the Interspeech 2019, 20th Annual Conference of the International Speech Communication Association, Graz, Austria, 15–19 September 2019; pp. 2613–2617. [Google Scholar]
- Padovese, B.; Frazao, F.; Kirsebom, O.S.; Matwin, S. Data augmentation for the classification of North Atlantic right whales upcalls. J. Acoust. Soc. Am. 2021, 149, 2520–2530. [Google Scholar] [CrossRef] [PubMed]
- Nam, H.; Kim, S.-H.; Park, Y.-H. Filteraugment: An Acoustic Environmental Data Augmentation Method. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 4308–4312. [Google Scholar]
- Wu, D.; Zhang, B.; Yang, C.; Peng, Z.; Xia, W.; Chen, X.; Lei, X. U2++: Unified Two-pass Bidirectional End-to-end Model for Speech Recognition. arXiv 2021, arXiv:2106.05642. [Google Scholar] [CrossRef]
- Yao, Q.; Wang, Y.; Yang, Y. Underwater Acoustic Target Recognition Based on Data Augmentation and Residual CNN. Electronics 2023, 12, 1206. [Google Scholar] [CrossRef]
- Jeong, Y.; Kim, J.; Kim, D.; Kim, J. Methods for Improving Deep Learning-Based Cardiac Auscultation Accuracy: Data Augmentation and Data Generalization. Appl. Sci. 2021, 11, 4544. [Google Scholar] [CrossRef]
- Mushtaq, Z.; Su, S.-F.; Tran, Q.-V. Spectral images based environmental sound classification using CNN with meaningful data augmentation. Appl. Acoust. 2021, 172, 107581. [Google Scholar] [CrossRef]
- Mnasri, Z.; Rovetta, S.; Masulli, F. Anomalous sound event detection: A survey of machine learning based methods and applications. Multimed. Tools Appl. 2022, 81, 5537–5586. [Google Scholar] [CrossRef]
- Damskägg, E.-P.; Välimäki, V. Audio time stretching using fuzzy classification of spectral bins. Appl. Sci. 2017, 7, 1293. [Google Scholar] [CrossRef]
- Wei, S.; Zou, S.; Liao, F.; Lang, W. A comparison on data augmentation methods based on deep learning for audio classification. J. Phys. Conf. Ser. 2020, 1453, 012085. [Google Scholar] [CrossRef]
- Zhang, F.; Dvornek, N.; Yang, J.; Chapiro, J.; Duncan, J. Layer Embedding Analysis in Convolutional Neural Networks for Improved Probability Calibration and Classification. IEEE Trans. Med. Imaging 2020, 39, 3331–3342. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Class | Baseline | Signal DA | Combined DA |
|---|---|---|---|
| coughing | 40 | 200 | 400 |
| cracking_fire | 40 | 200 | 400 |
| crying_baby | 40 | 200 | 400 |
| glass_breaking | 40 | 200 | 400 |
| gun_shot | 37 | 185 | 370 |
| sneezing | 40 | 200 | 400 |
| snoring | 40 | 200 | 400 |
| screams | 37 | 185 | 370 |
| Total | 314 | 1570 | 3140 |
| Metrics | Description | Mathematical Expression |
|---|---|---|
| Accuracy | Degree of true value (correct identification of all abnormal acoustic events) measurements against all the evaluated instances. | |
| Macro Precision | The statistical average of the ratio of true positive abnormal sounds (k class events) against the actual positive number. | |
| Macro Recall | The statistical average of the ratio of true positive abnormal sounds (k class events) against predicted positive number. | |
| Macro Specificity | The statistical average of the ratio of true negative abnormal sounds (k class events) against predicted negative number. | |
| Macro F1-Score | The weighted average of Macro Precision and Macro Recall. |
| Training Method | Acc | Pre | Rec | Spc | F1 |
|---|---|---|---|---|---|
| ANN and Adam | 78.42 | 72.24 | 67.32 | 62.86 | 69.69 |
| ANN and AdamW | 81.26 | 73.17 | 69.78 | 64.28 | 71.43 |
| EANN and Adam | 83.68 | 76.52 | 71.16 | 66.97 | 73.74 |
| EANN and AdamW | 86.81 | 78.44 | 71.71 | 67.58 | 74.92 |
| Time Stretching Ranges | Acc | Pre | Rec | Spc | F1 |
|---|---|---|---|---|---|
| no stretching (Baseline) | 86.81 | 78.44 | 71.71 | 67.58 | 74.92 |
| 88.89 | 82.21 | 76.40 | 68.63 | 79.19 | |
| [0.80, 1.20] | 89.77 | 90.13 | 89.33 | 74.24 | 89.73 |
| 90.91 | 91.69 | 90.29 | 77.36 | 90.99 | |
| [0.84, 1.16] | 91.04 | 92.08 | 90.83 | 78.43 | 91.45 |
| 92.31 | 91.52 | 92.44 | 82.61 | 91.98 | |
| [0.88, 1.12] | 93.31 | 93.73 | 93.37 | 83.62 | 93.55 |
| 94.44 | 94.51 | 94.48 | 86.23 | 94.49 | |
| [0.90, 1.10] | 87.78 | 88.66 | 86.85 | 82.52 | 87.75 |
| 88.07 | 88.60 | 87.17 | 84.72 | 87.88 | |
| [0.92, 1.08] | 87.78 | 87.37 | 87.00 | 79.46 | 87.19 |
| 89.77 | 90.32 | 89.04 | 82.21 | 89.68 | |
| [0.96, 1.04] | 86.08 | 86.27 | 86.25 | 73.92 | 86.26 |
| 87.78 | 87.27 | 88.25 | 77.46 | 87.76 |
| Pitch Shifting Ranges | Acc | Pre | Rec | Spc | F1 |
|---|---|---|---|---|---|
| no shifting (Baseline) | 86.81 | 78.44 | 71.71 | 67.58 | 74.92 |
| 88.89 | 82.21 | 76.40 | 68.63 | 79.19 | |
| [−10, 10] | 89.49 | 89.43 | 89.17 | 78.85 | 89.30 |
| 90.62 | 90.60 | 89.98 | 81.37 | 90.29 | |
| [−8, 8] | 90.34 | 90.44 | 89.67 | 83.32 | 90.05 |
| 92.04 | 92.15 | 91.69 | 84.92 | 91.92 | |
| [−5, 5] | 89.20 | 89.66 | 88.27 | 83.86 | 88.96 |
| 92.33 | 92.76 | 91.71 | 85.46 | 92.23 | |
| [−3, 3] | 88.07 | 88.13 | 87.17 | 81.65 | 87.65 |
| 90.91 | 90.87 | 90.58 | 84.28 | 90.73 | |
| [−1, 1] | 87.92 | 87.22 | 87.25 | 81.46 | 87.24 |
| 90.48 | 90.73 | 89.92 | 83.69 | 90.32 |
| Background Noise Ranges | Acc | Pre | Rec | Spc | F1 |
|---|---|---|---|---|---|
| no noise (Baseline) | 86.81 | 78.44 | 71.71 | 67.58 | 74.92 |
| 88.89 | 82.21 | 76.40 | 68.63 | 79.19 | |
| −10 | 87.19 | 86.91 | 86.60 | 72.63 | 86.75 |
| 86.26 | 85.63 | 85.35 | 71.42 | 85.49 | |
| −5 | 88.13 | 88.50 | 87.94 | 74.82 | 88.22 |
| 90.32 | 90.12 | 90.09 | 78.37 | 90.15 | |
| 0 | 90.60 | 90.75 | 90.93 | 81.29 | 90.84 |
| 91.46 | 91.60 | 91.44 | 83.84 | 91.52 | |
| 5 | 92.88 | 91.81 | 91.39 | 83.67 | 91.60 |
| 92.02 | 92.19 | 91.77 | 84.82 | 91.98 | |
| 10 | 92.88 | 92.02 | 91.71 | 85.37 | 91.86 |
| 93.44 | 92.38 | 92.33 | 86.25 | 92.36 | |
| 15 | 92.59 | 92.47 | 92.73 | 85.48 | 92.59 |
| 93.14 | 92.42 | 92.88 | 85.93 | 92.67 | |
| 20 | 92.58 | 92.47 | 92.73 | 86.02 | 92.59 |
| 92.46 | 92.62 | 92.58 | 85.74 | 92.60 |
| Combination Type | Acc | Pre | Rec | Spc | F1 |
|---|---|---|---|---|---|
| No Aug | 86.81 | 78.44 | 71.71 | 67.58 | 74.92 |
| Online Aug | 88.89 | 82.21 | 76.39 | 68.63 | 79.19 |
| BN [10] and PS [−5, 5] | 93.21 | 93.29 | 93.24 | 78.36 | 93.27 |
| 91.28 | 91.38 | 92.33 | 77.86 | 91.86 | |
| TS [0.88, 1.12] and PS [−5, 5] | 95.81 | 95.87 | 95.85 | 83.41 | 95.86 |
| 96.01 | 96.10 | 96.03 | 86.42 | 96.06 | |
| TS [0.88, 1.12] and BN [10] | 96.43 | 96.45 | 96.44 | 88.52 | 96.45 |
| 97.45 | 97.16 | 97.09 | 90.61 | 97.12 |
| Research Sound Types | Method Used | Accuracy before Augmentation | Accuracy after Augmentation |
|---|---|---|---|
| Environmental sound classification [21] | Pitch Shifting, Time Stretching, Dynamic Range Compression, Background Noise | 0.741 | 0.791 |
| Detecting COVID-19 from deep breathing sounds [24] | Color Transformation and Noise Addition + DeepShufNet | 0.749 | 0.901 |
| North Atlantic right whales upcalls [26] | SpecAugment, Mixup | 0.860 | 0.902 |
| Mechanical noise identification [22] | Background Noise and Time Stretching | 0.931 | 0.971 |
| Underwater acoustic target recognition [29] | DCGAN + ResNet18 | 0.925 | 0.964 |
| Environmental sound classification [34] | Mixed Frequency Masking | 0.924 | 0.937 |
| Indoor anomalous sound event identification | Time Stretching, Background Noise, Spectral Masking + EANN | 0.868 | 0.974 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, X.; Xiong, J.; Wang, M.; Mei, Q.; Lin, X. Combined Data Augmentation on EANN to Identify Indoor Anomalous Sound Event. Appl. Sci. 2024, 14, 1327. https://doi.org/10.3390/app14041327
Song X, Xiong J, Wang M, Mei Q, Lin X. Combined Data Augmentation on EANN to Identify Indoor Anomalous Sound Event. Applied Sciences. 2024; 14(4):1327. https://doi.org/10.3390/app14041327
Chicago/Turabian StyleSong, Xiyu, Junhan Xiong, Mei Wang, Qingshan Mei, and Xiaodong Lin. 2024. "Combined Data Augmentation on EANN to Identify Indoor Anomalous Sound Event" Applied Sciences 14, no. 4: 1327. https://doi.org/10.3390/app14041327
APA StyleSong, X., Xiong, J., Wang, M., Mei, Q., & Lin, X. (2024). Combined Data Augmentation on EANN to Identify Indoor Anomalous Sound Event. Applied Sciences, 14(4), 1327. https://doi.org/10.3390/app14041327