
Audio-Visual Action Recognition Using Transformer Fusion Network


Abstract
1. Introduction
2. Related Work
3. Method
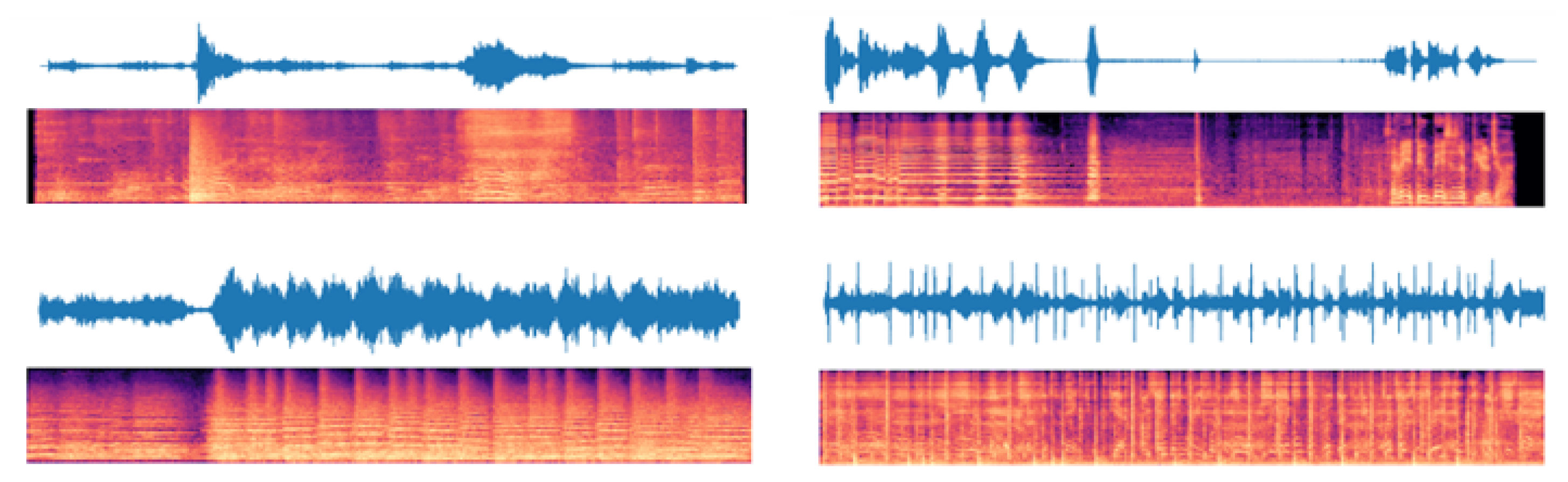
3.1. Data Processing
3.2. Audio-Visual Feature Extraction
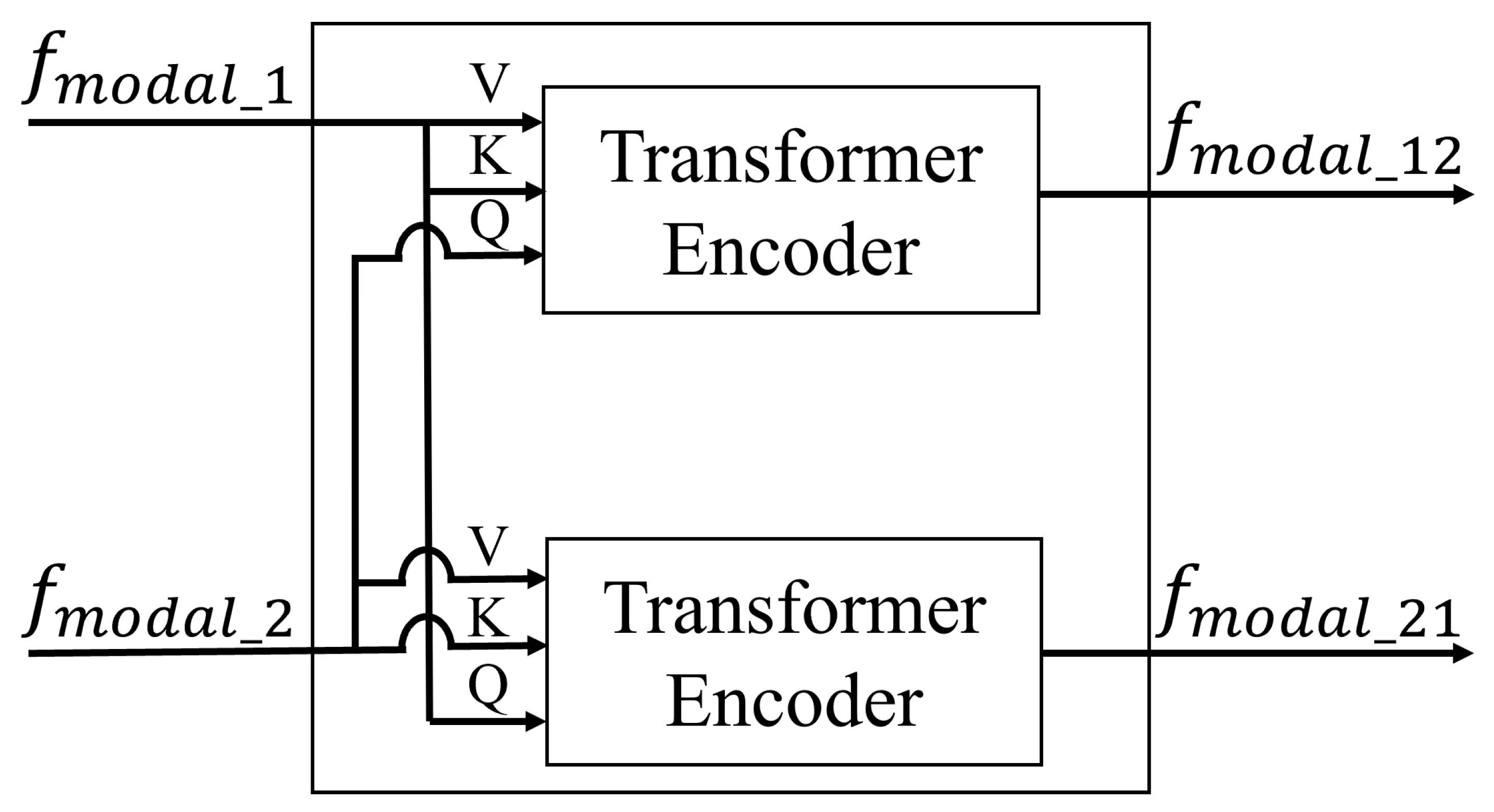
3.3. Transformer-Based Feature Fusion
4. Experimental Results
4.1. Implementation
- Swin-T: , ,
- Swin-S: , ,
- Swin-B: , ,
- Swin-L: , ,
4.2. Datasets
- applylipstick, archery, babycrawling, balancebeam, bandmarching, basketballdunk, blowdryhair, blowingcandles, bodyweightsquats, bowling, boxingpunchingbag, boxingspeedbag, brushingteeth, cliffdiving, cricketbowling, cricketshot, cuttinginkitchen, fieldhockeypenalty, floorgymnastics, frisbeecatch, frontcrawl, haircut, hammerthrow, hammering, handstandpushups, handstandwalking, headmassage, icedancing, knitting, longjump, moppingfloor, parallelbars, playingcello, playingdaf, playingdhol, playingflute, playingsitar, rafting, shavingbeard, shotput, skydiving, soccerpenalty, stillrings, sumowrestling, surfing, tabletennisshot, typing, unevenbars, wallpushups, writingonboard
- blowingnose, blowingoutcandles, blowingoutcandles, bowling, choppingwood, dribblingbasketball, laughing, mowinglawn, playingaccordion, playingbagpipes, playingbassguitar, playingclarinet, playingdrums, playingguitar, playingharmonica, playingkeyboard, playingorgan, playingpiano, playingviolin, playingxylophone, playingsaxophone, rippingpaper, shufflingcards, singing, stompinggrapes, strummingguitar, tapdancing, tappingguitar, tappingpen, tickling, playingtrumpet, playingtrombone9

4.3. Results
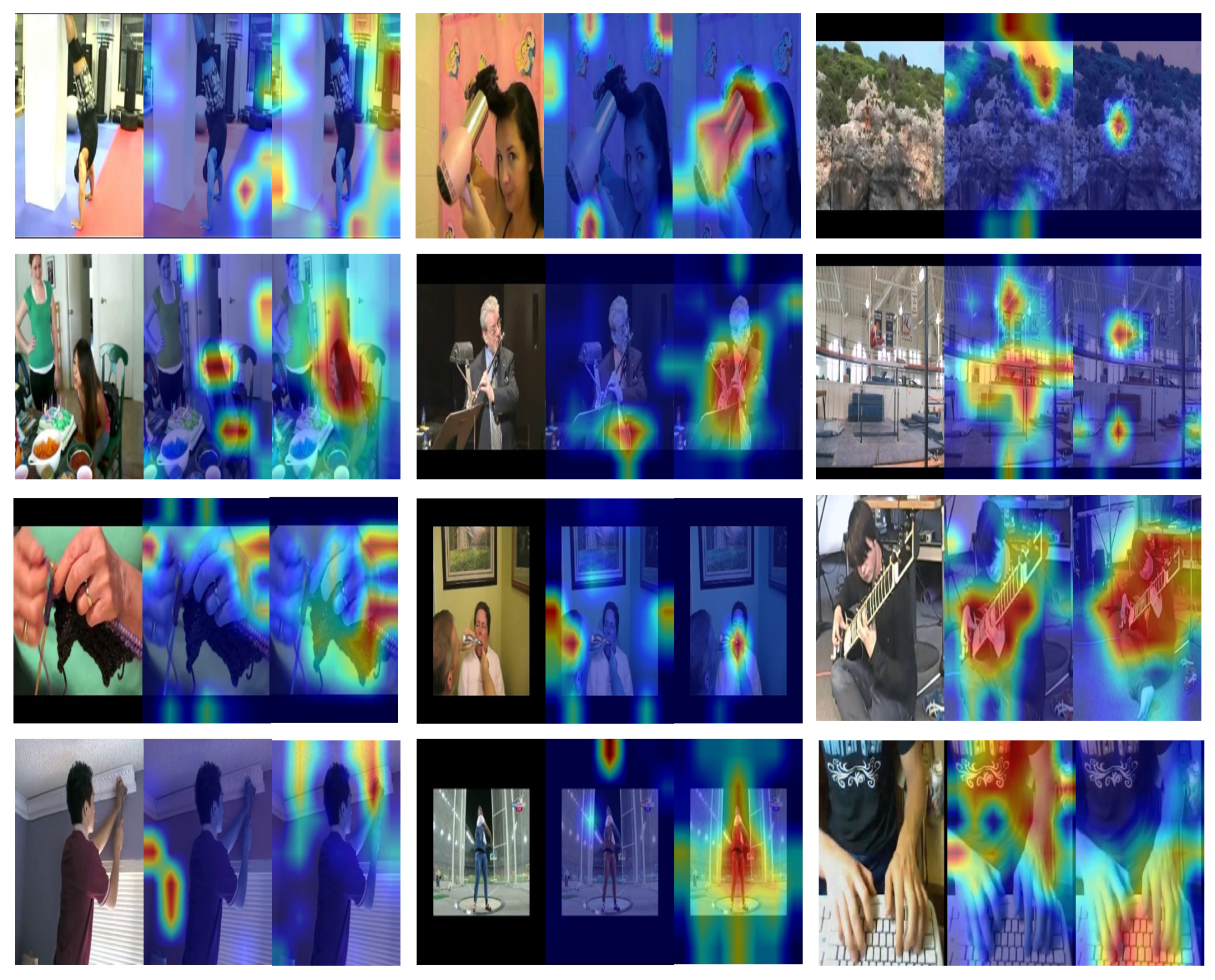
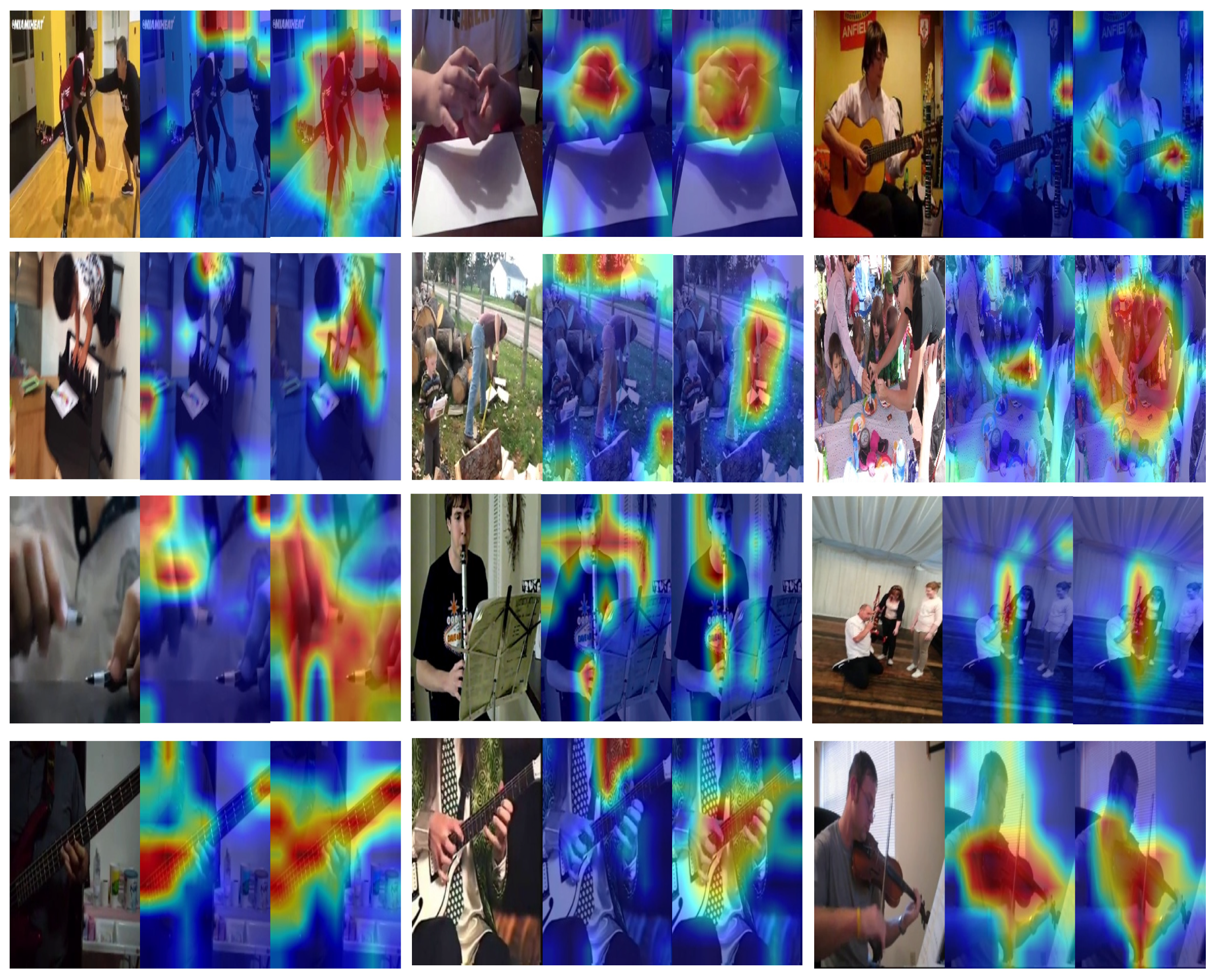
4.4. Visual Interpretation with Grad-CAM
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ukani, V.; Thakkar, P. A hybrid video based iot framework for military surveillance. Des. Eng. 2021, 5, 2050–2060. [Google Scholar]
- Zhang, Q.; Sun, H.; Wu, X.; Zhong, H. Edge video analytics for public safety: A review. Proc. IEEE 2019, 107, 1675–1696. [Google Scholar] [CrossRef]
- Kim, D.; Kim, H.; Mok, Y.; Paik, J. Real-time surveillance system for analyzing abnormal behavior of pedestrians. Appl. Sci. 2021, 11, 6153. [Google Scholar] [CrossRef]
- Prathaban, T.; Thean, W.; Sazali, M.I.S.M. A vision-based home security system using OpenCV on Raspberry Pi 3. AIP Conf. Proc. 2019, 2173, 020013. [Google Scholar]
- Ohn-Bar, E.; Trivedi, M. Joint angles similarities and HOG2 for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 465–470. [Google Scholar]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the 28th Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Bilen, H.; Fernando, B.; Gavves, E.; Vedaldi, A. Action Recognition with Dynamic Image Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2799–2813. [Google Scholar] [CrossRef] [PubMed]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3D convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, CA, USA, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Khan, S.; Hassan, A.; Hussain, F.; Perwaiz, A.; Riaz, F.; Alsabaan, M.; Abdul, W. Enhanced spatial stream of two-stream network using optical flow for human action recognition. Appl. Sci. 2023, 13, 8003. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3202–3211. [Google Scholar]
- Wang, H.; Zhang, W.; Liu, G. TSNet: Token Sparsification for Efficient Video Transformer. Appl. Sci. 2023, 13, 10633. [Google Scholar] [CrossRef]
- Wang, C.; Yang, H.; Meinel, C. Exploring multimodal video representation for action recognition. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1924–1931. [Google Scholar]
- Arandjelovic, R.; Zisserman, A. Look, listen and learn. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, Hawaii, 21–26 July 2016; pp. 609–617. [Google Scholar]
- Xiao, F.; Lee, Y.J.; Grauman, K.; Malik, J.; Feichtenhofer, C. Audiovisual slowfast networks for video recognition. arXiv 2020, arXiv:2001.08740. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; p. 30. [Google Scholar]
- Atrey, P.K.; Hossain, M.A.; El Saddik, A.; Kankanhalli, M.S. Multimodal fusion for multimedia analysis: A survey. Multimed. Syst. 2010, 16, 345–379. [Google Scholar] [CrossRef]
- Wöllmer, M.; Kaiser, M.; Eyben, F.; Schuller, B.; Rigoll, G. LSTM-modeling of continuous emotions in an audiovisual affect recognition framework. Image Vis. Comput. 2013, 31, 153–163. [Google Scholar] [CrossRef]
- Gupta, M.V.; Vaikole, S.; Oza, A.D.; Patel, A.; Burduhos-Nergis, D.P.; Burduhos-Nergis, D.D. Audio-Visual Stress Classification Using Cascaded RNN-LSTM Networks. Bioengineering 2022, 9, 510. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Z.-R.; Du, J. Deep fusion: An attention guided factorized bilinear pooling for audio-video emotion recognition. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Duan, B.; Tang, H.; Wang, W.; Zong, Z.; Yang, G.; Yan, Y. Audio-visual event localization via recursive fusion by joint co-attention. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual Conference, 5–9 January 2021; pp. 4013–4022. [Google Scholar]
- Nagrani, A.; Yang, S.; Arnab, A.; Jansen, A.; Schmid, C.; Sun, C. Attention bottlenecks for multimodal fusion. Adv. Neural Inf. Process. Syst. 2021, 34, 14200–14213. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual Conference, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Kim, J.-H.; Won, C.S. Action Recognition in Videos Using Pre-trained 2D Convolutional Neural Networks. IEEE Access 2020, 8, 60179–60188. [Google Scholar] [CrossRef]
- Kim, J.-H.; Kim, N.; Won, C.S. Deep edge computing for videos. IEEE Access 2021, 9, 123348–123357. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Jia, D.; Wei, D.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. Autoaugment: Learning augmentation policies from data. arXiv 2018, arXiv:1805.09501. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Brousmiche, M.; Rouat, J.; Dupont, S. Multi-level attention fusion network for audio-visual event recognition. arXiv 2021, arXiv:2106.06736. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.W.; Gemmeke, J.F.; Jansen, A.; Moore, R.C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN architectures for large-scale audio classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 131–135. [Google Scholar]
- Gong, Y.; Chung, Y.-A.; Glass, J. AST: Audio Spectrogram Transformer. arXiv 2021, arXiv:2104.01778. [Google Scholar]
- Huh, J.; Chalk, J.; Kazakos, E.; Damen, D.; Zisserman, A. Epic-Sounds: A Large-Scale Dataset of Actions that Sound. In Proceedings of the ICASSP 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case | Swin-T | Swin-S | Swin-B | Swin-L |
|---|---|---|---|---|
| (1) | 86.63% | 91.05% | 93.00% | 92.53% |
| (2) | 84.21% | 87.79% | 91.00% | 91.95% |
| (3) | 86.63% | 90.16% | 91.79% | 91.84% |
| (4) | 74.32% | 79.26% | 89.05% | 90.84% |
| Case | Swin-T | Swin-S | Swin-B | Swin-L |
|---|---|---|---|---|
| (1) | 87.50% | 88.25% | 89.34% | 89.28% |
| (2) | 82.24% | 84.43% | 85.38% | 86.00% |
| (3) | 86.48% | 87.80% | 88.59% | 89.05% |
| (4) | 85.25% | 86.20% | 88.18% | 87.36% |
| Case | Accuracy |
|---|---|
| EF-NN [15] | 80.06% |
| LF-NN [15] | 61.00% |
| EF-SVM [15] | 66.10% |
| LF-SVM [15] | 82.50% |
| Proposed methods (Swin-B, case (1)) | 93.00% |
| Method | Accuracy |
|---|---|
| -Net [16] | 74.00% |
| SlowFast [17], R50 | 80.50% |
| AVSlowFast [17], R50 | 83.70% |
| SlowFast [17], R101 | 82.70% |
| MAFnet [35] | 83.94% |
| AVSlowFast [17] | 85.00% |
| MBT [24] | 85.00% |
| Proposed methods (Swin-B, case (1)) | 89.34% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.-H.; Won, C.S. Audio-Visual Action Recognition Using Transformer Fusion Network. Appl. Sci. 2024, 14, 1190. https://doi.org/10.3390/app14031190
Kim J-H, Won CS. Audio-Visual Action Recognition Using Transformer Fusion Network. Applied Sciences. 2024; 14(3):1190. https://doi.org/10.3390/app14031190
Chicago/Turabian StyleKim, Jun-Hwa, and Chee Sun Won. 2024. "Audio-Visual Action Recognition Using Transformer Fusion Network" Applied Sciences 14, no. 3: 1190. https://doi.org/10.3390/app14031190
APA StyleKim, J.-H., & Won, C. S. (2024). Audio-Visual Action Recognition Using Transformer Fusion Network. Applied Sciences, 14(3), 1190. https://doi.org/10.3390/app14031190