
A Lightweight Kernel Density Estimation and Adaptive Synthetic Sampling Method for Fault Diagnosis of Rotating Machinery with Imbalanced Data


Abstract
1. Introduction
- (1)
- Failure to account for the varying quantities of different fault types during model training limits the ability to handle the randomness of fault types and quantities in real-world scenarios.
- (2)
- The lack of high-precision lightweight models for fault diagnosis of one-dimensional signals in rotating machinery limits their application in real-time monitoring within prognostics and health management (PHM) systems.
- (3)
- Traditional oversampling methods struggle to generate enough high-quality samples near class boundaries, increasing the risk of misclassification around decision boundaries.
- (1)
- The Gaussian kernel-based KDE-ADASYN algorithm calculates the probability density distribution and weight of each minority class sample, adjusts the number of new samples generated near various minority class boundaries, and improves the classifier’s decision boundary accuracy in complex imbalanced data scenarios.
- (2)
- A lightweight 1D CNN for fault diagnosis is developed, incorporating MobileNet with an embedded SE block. The attention mechanism enhances feature extraction, and the lightweight network drastically reduces model parameters and conserves computational resources, making it ideal for mobile machinery and real-time monitoring applications.
- (3)
- Training sets with varying sample sizes for different fault types are constructed using the PU and HUST datasets, addressing the challenge of model applicability in real-world conditions.
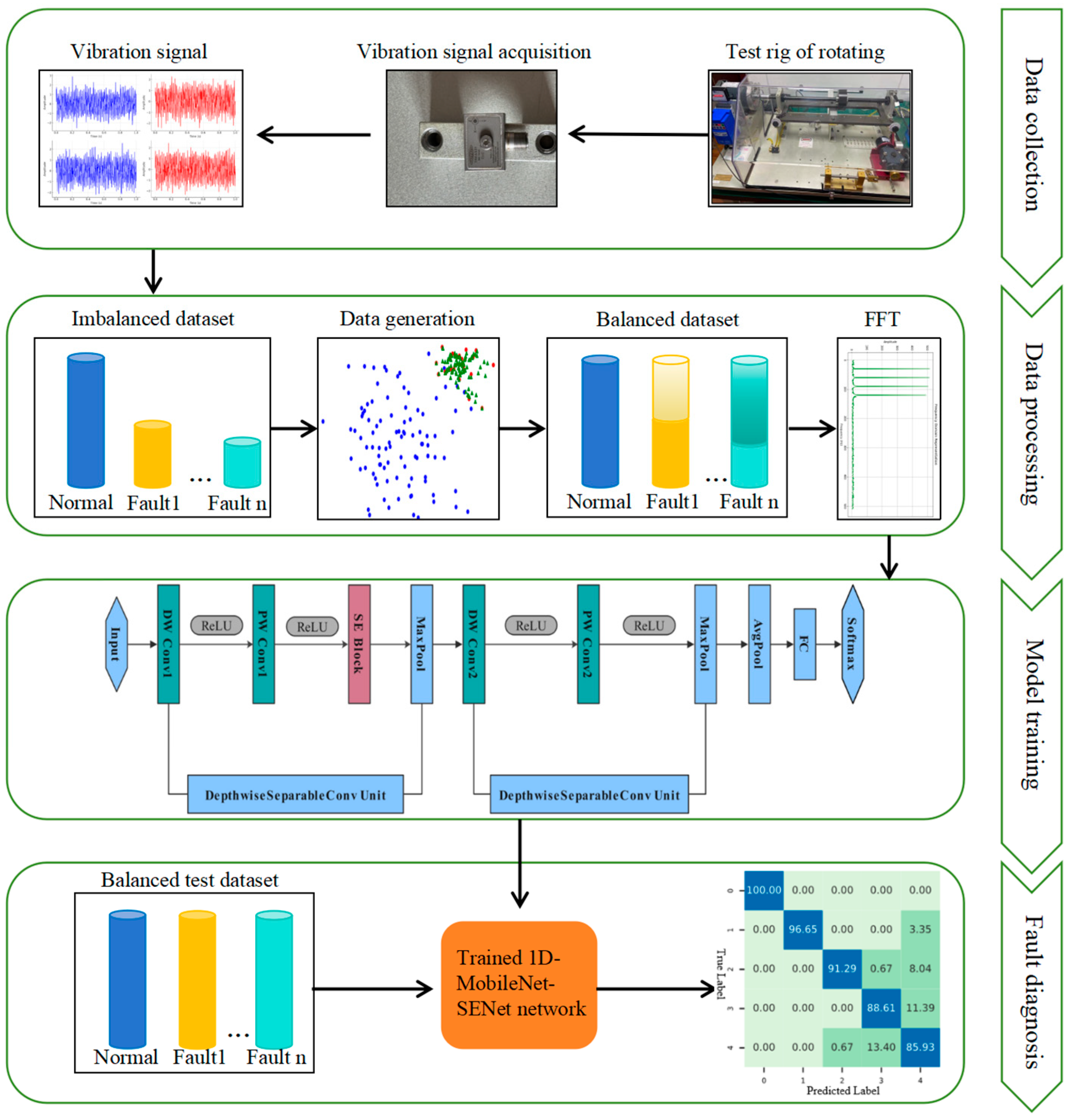
2. The Proposed Methods
2.1. KDE-ADASYN
2.2. 1D-SENet Network
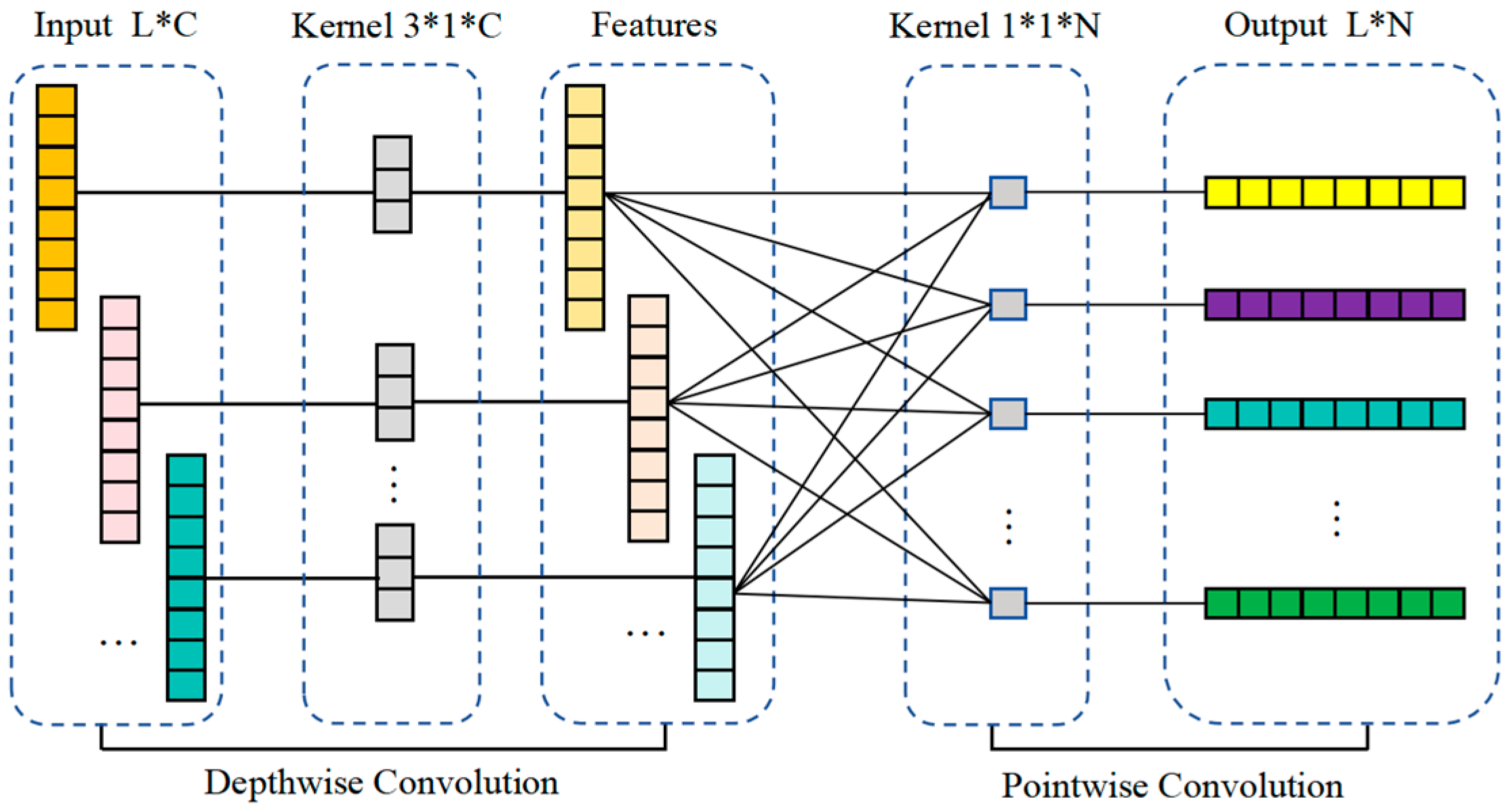
2.3. 1D-MobileNet
2.4. KAMS Model Network
3. Experimental Analysis and Discussion
3.1. Datasets Introduction
- (1)
- PU Dataset: This public bearing dataset, provided by Paderborn University (PU), is one of the most commonly used validation datasets for mechanical fault diagnosis [37]. The test equipment includes a test motor, shaft, bearing module, flywheel, and load motor. Experimental data were generated by installing rolling bearings with different types of damage on the test equipment in the test module. During the experiment, two types of fault groups were created: artificial damage and real damage. Specifically, artificial damage was introduced to the rolling bearings through three processes: electrical discharge machining (EDM), drilling, and electrical engraving.
- (2)
- HUST Dataset: Provided by Huazhong University of Science and Technology, this is one of the latest public datasets in the field of fault diagnosis [38]. The bearing fault experiments were conducted using the Spectra-Quest test bench, as shown in Figure 5. The test bench consists of the following: ① Speed control, ② Motor, ③ Shaft, ④ Acceleration sensor, ⑤ Bearing, and ⑥ Data acquisition board. The model of the acceleration sensor is TREA331. The dataset includes vibration signals from bearings in nine different health states under four distinct operating conditions. In our setup, only the data at the operating condition 65 Hz (3900 rpm) were used. The health states include normal (N), inner ring fault (I), outer ring fault (O), ball fault (B), and compound fault (C). The motor power used in the HUST experiment ranges from 0.56 to 0.75 kW. The health states include normal, inner ring fault (I), outer ring fault (O), ball fault (B), and compound fault (C). Except for the normal state, each fault state includes moderate and severe conditions. The experimental setup information for the two datasets is shown in Table 2.
3.2. Dataset Processing
- (1)
- PU Dataset: Four imbalanced sample datasets are designed, named Dataset A, Dataset B, Dataset C, and Dataset D. Each dataset has a different imbalance ratio range, and the calculation method is as follows:
- (2)
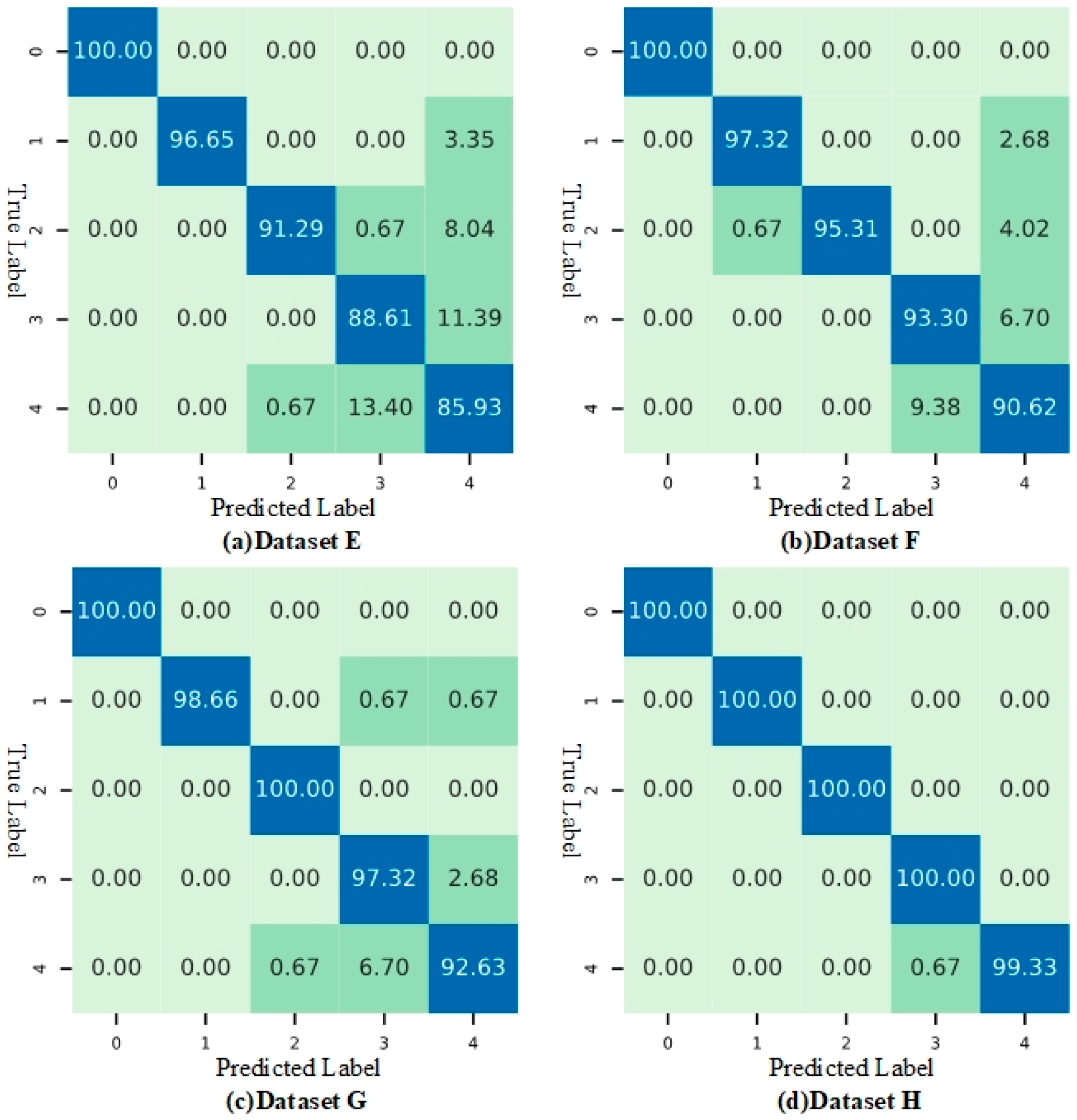
- HUST Dataset: Similarly, four imbalanced sample datasets are designed, named Dataset E, Dataset F, Dataset G, and Dataset H. Each dataset has a different imbalance ratio range, and the ratio of the number of samples between the most and least fault categories is set to 2:1. For example, Dataset E has the highest degree of imbalance, with the number of samples for fault category O being the most at 8 and for fault category C being the least at 4. According to Equation (14), the imbalance ratio range for Dataset E is . The test set is set as a balanced dataset, with 150 samples for normal and each fault category, totaling 750 samples. The detailed information of the HUST dataset is shown in Table 4.
3.3. Paderborn University Bearing Experiment
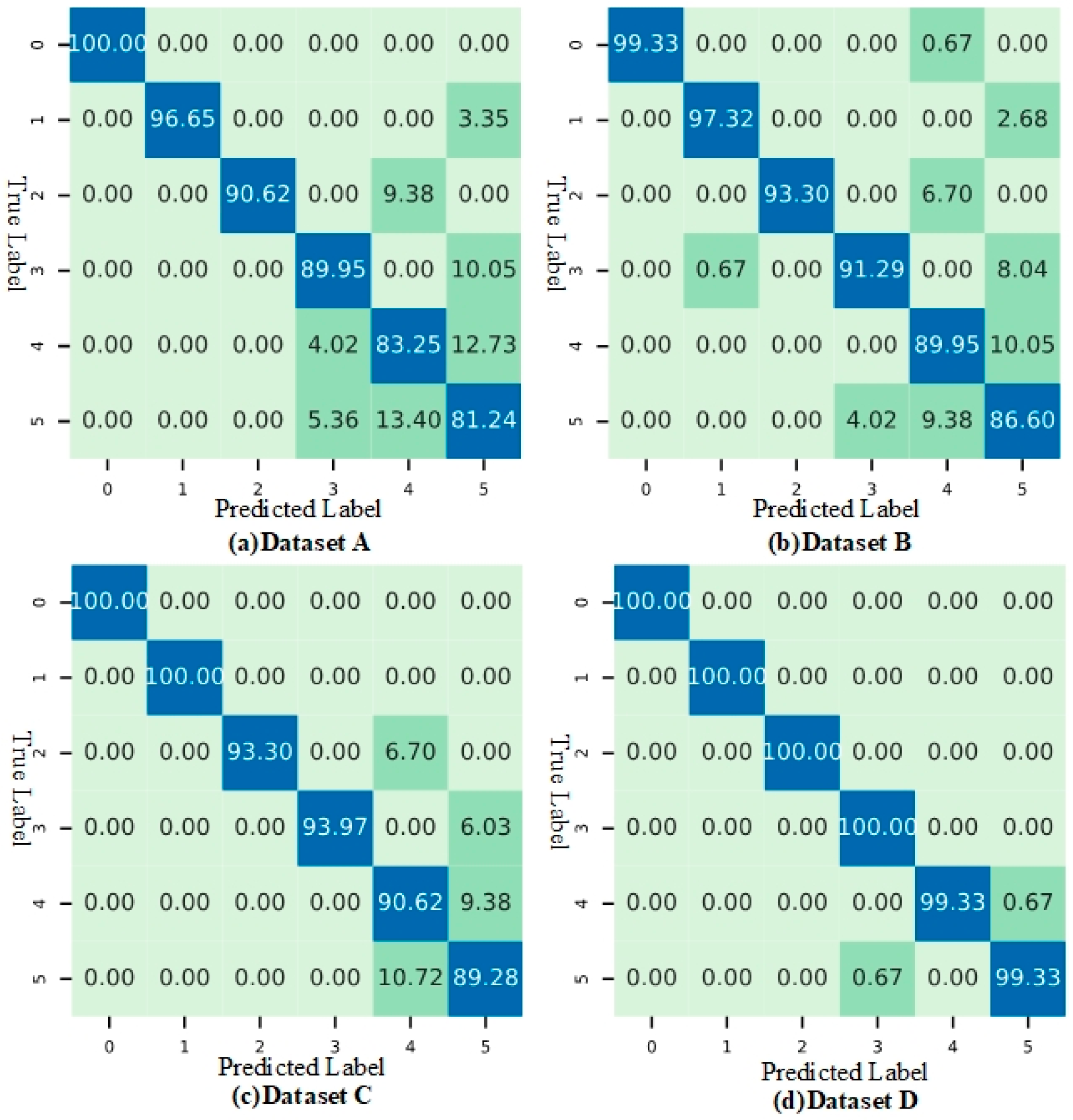
3.3.1. Analysis of Fault Diagnosis Performance
3.3.2. Comparison of Different Data Generation Methods
- (1)
- BEGSMOTE: The boundary enhancement and Gaussian mixture model optimized synthetic minority oversampling technique (BEGSMOTE) method combines boundary enhancement (BE) and the Gaussian mixture model (GMM) to optimize the synthetic minority oversampling technique. This method aims to overcome the sample density insufficiency problem in traditional SMOTE models while addressing the limitations of deep learning models in terms of training sample size and processing speed [20]. This technique was used to balance the dataset samples, followed by applying FFT transformation to the sample signals to obtain frequency-domain signal data. Finally, the data were trained and evaluated using a 1D-MobileNet network integrated with the SE block. The comparison results of each method with the method proposed in this paper are shown in Table 6.
- (2)
- ADASYN: Adaptive synthetic sampling (ADASYN) is an oversampling technique that uses a weighted distribution to calculate the density of surrounding samples, taking into account the varying learning difficulties of minority class samples. ADASYN generates more synthetic data for minority class samples that are harder to learn compared to those that are easier to learn. The same evaluation steps were applied to this technique as to BEGSMOTE.
- (3)
- GAN: The generative adversarial network (GAN) learns the data distribution of the minority class through a generator and generates new samples to address data imbalance issues [38]. This method first converts the sample signals from the time domain to the frequency domain using FFT. Then, GAN is used to generate training data to balance the samples. The data were input into a 1D-MobileNet network, which was integrated with the SE block, for training and evaluation.
3.3.3. Comparison of Different Network Models
3.4. Huazhong University of Science and Technology Bearing Experiment
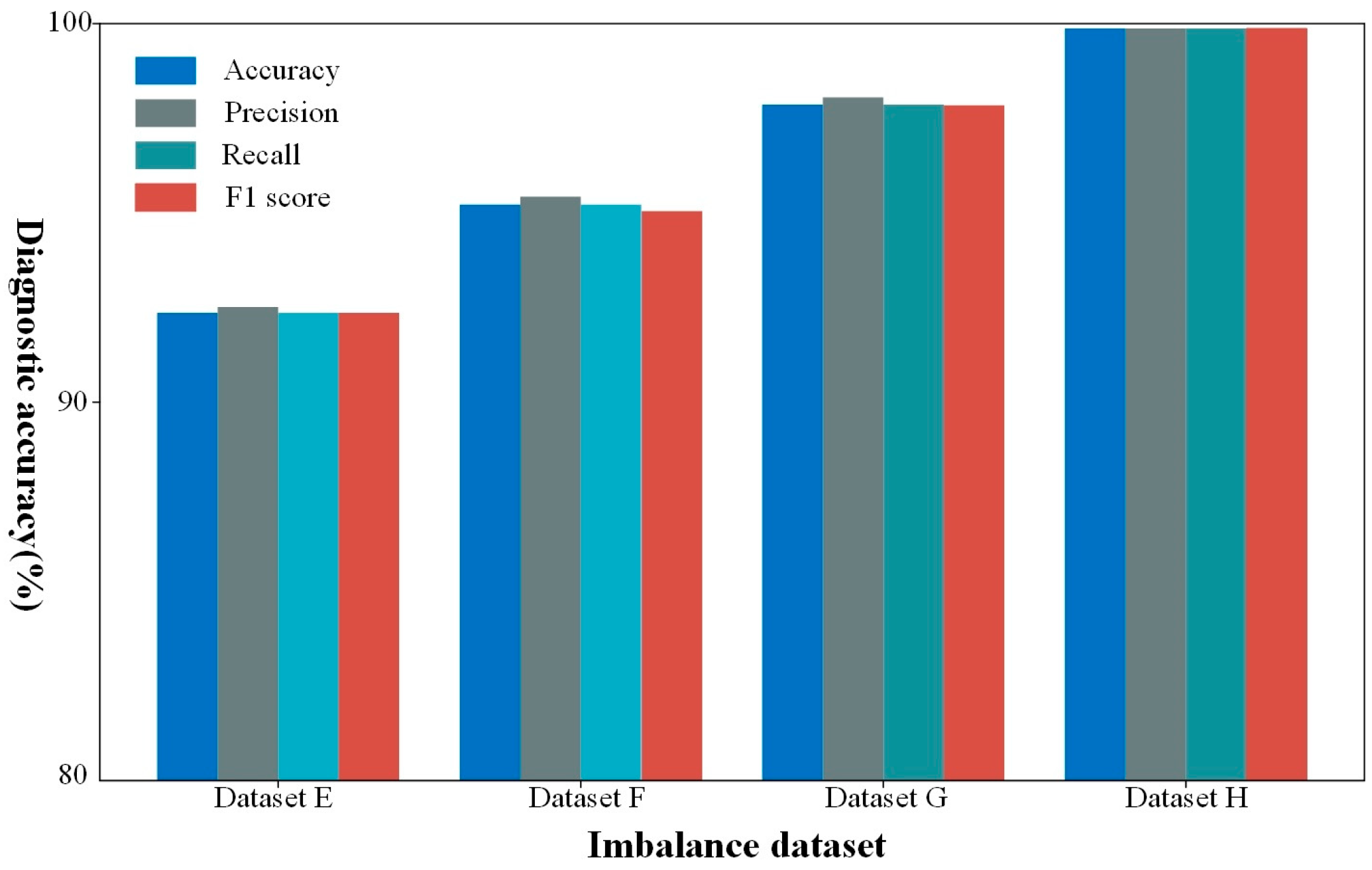
3.4.1. Analysis of Fault Diagnosis Performance
3.4.2. Comparison of Different Data Generation Methods
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Acronyms
| KDE | kernel density estimation |
| ADASYN | adaptive synthetic sampling |
| SENet | Squeeze-and-Excitation network |
| FFT | fast Fourier transform |
| SE | Squeeze and Excitation |
| KAMS | KDE-ADASYN-based MobileNet with SENet |
| CNN | convolutional neural networks |
| RNN | recurrent neural network |
| GNN | graph neural network |
| SVM | support vector machine |
| GAN | generative adversarial network |
| SMOTE | synthetic minority oversampling technique |
| VGG | visual geometry group |
| BEGSMOTE | boundary enhancement and Gaussian mixture model optimized synthetic minority oversampling technique |
References
- Zhou, P.; Chen, S.; He, Q.; Wang, D.; Peng, Z. Rotating machinery fault-induced vibration signal modulation effects: A review with mechanisms, extraction methods and applications for diagnosis. Mech. Syst. Signal Process. 2023, 200, 110489. [Google Scholar] [CrossRef]
- Li, X.; Wang, Y.; Yao, J.; Li, M.; Gao, Z. Multi-sensor fusion fault diagnosis method of wind turbine bearing based on adaptive convergent viewable neural networks. Reliab. Eng. Syst. Saf. 2024, 245, 109980. [Google Scholar] [CrossRef]
- Zou, Y.; Zhao, W.; Liu, T.; Zhang, X.; Shi, Y. Research on High-Speed Train Bearing Fault Diagnosis Method Based on Domain-Adversarial Transfer Learning. Appl. Sci. 2024, 14, 8666. [Google Scholar] [CrossRef]
- Zhang, D.; Tao, H. Bearing Fault Diagnosis Based on Parameter-Optimized Variational Mode Extraction and an Improved One-Dimensional Convolutional Neural Network. Appl. Sci. 2024, 14, 3289. [Google Scholar] [CrossRef]
- Wang, W.; Song, H.; Si, S.; Lu, W.; Cai, Z. Data augmentation based on diffusion probabilistic model for remaining useful life estimation of aero-engines. Reliab. Eng. Syst. Saf. 2024, 252, 110394. [Google Scholar] [CrossRef]
- Ma, C.; Wang, X.; Li, Y.; Cai, Z. Broad zero-shot diagnosis for rotating machinery with untrained compound faults. Reliab. Eng. Syst. Saf. 2024, 242, 109704. [Google Scholar] [CrossRef]
- Ma, C.; Li, Y.; Wang, X.; Cai, Z. Early fault diagnosis of rotating machinery based on composite zoom permutation entropy. Reliab. Eng. Syst. Saf. 2023, 230, 108967. [Google Scholar] [CrossRef]
- Yin, W.; Xia, H.; Huang, X.; Wang, Z. A fault diagnosis method for nuclear power plants rotating machinery based on deep learning under imbalanced samples. Ann. Nucl. Energy 2024, 199, 110340. [Google Scholar] [CrossRef]
- Wan, W.; Chen, J.; Xie, J. Graph-Based Model Compression for HSR Bogies Fault Diagnosis at IoT Edge via Adversarial Knowledge Distillation. IEEE Trans. Intell. Transp. Syst. 2023, 25, 1787–1796. [Google Scholar] [CrossRef]
- Han, T.; Liu, C.; Wu, L.; Sarkar, S.; Jiang, D. An adaptive spatiotemporal feature learning approach for fault diagnosis in complex systems. Mech. Syst. Signal Process. 2019, 117, 170–187. [Google Scholar] [CrossRef]
- Dorneanu, B.; Zhang, S.; Ruan, H.; Heshmat, M.; Chen, R.; Vassiliadis, V.S.; Arellano-Garcia, H. Big data and machine learning: A roadmap towards smart plants. Front. Eng. Manag. 2022, 9, 623–639. [Google Scholar] [CrossRef]
- Gong, W.; Chen, H.; Zhang, Z.; Zhang, M.; Wang, R.; Guan, C.; Wang, Q. A novel deep learning method for intelligent fault diagnosis of rotating machinery based on improved CNN-SVM and multichannel data fusion. Sensors 2019, 19, 1693. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Yan, X.; Zhang, C.; Liu, W. An ensemble convolutional neural networks for bearing fault diagnosis using multi-sensor data. Sensors 2019, 19, 5300. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Liu, F.; Kong, X.; Zhang, J.; Jiang, Z.; Mao, Z. Knowledge features enhanced intelligent fault detection with progressive adaptive sparse attention learning for high-power diesel engine. Meas. Sci. Technol. 2023, 34, 105906. [Google Scholar] [CrossRef]
- Tong, Q.; Lu, F.; Feng, Z.; Wan, Q.; An, G.; Cao, J.; Guo, T. A Novel Method for Fault Diagnosis of Bearings with Small and Imbalanced Data Based on Generative Adversarial Networks. Appl. Sci. 2022, 12, 7346. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, J.; Huang, Y.; Li, T.; Nie, C.; Xia, Y.; Zhan, L.; Tang, Z.; Zhang, L. Fault critical point prediction method of nuclear gate valve with small samples based on characteristic analysis of operation. Materials 2022, 15, 757. [Google Scholar] [CrossRef]
- Wang, R.; Zhang, S.; Chen, Z.; Li, W. Enhanced generative adversarial network for extremely imbalanced fault diagnosis of rotating machine. Measurement 2021, 180, 109467. [Google Scholar] [CrossRef]
- Rivera, W.A. Noise reduction a priori synthetic over-sampling for class imbalanced data sets. Inf. Sci. 2017, 408, 146–161. [Google Scholar] [CrossRef]
- Swana, E.F.; Doorsamy, W.; Bokoro, P. Tomek link and SMOTE approaches for machine fault classification with an imbalanced dataset. Sensors 2022, 22, 3246. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, T.; Wu, X.; Liu, C. A diagnosis method for imbalanced bearing data based on improved SMOTE model combined with CNN-AM. J. Comput. Des. Eng. 2023, 10, 1930–1940. [Google Scholar] [CrossRef]
- Liang, X.; Jiang, A.; Li, T.; Xue, Y.; Wang, G. LR-SMOTE—An improved unbalanced data set oversampling based on K-means and SVM. Knowl.-Based Syst. 2020, 196, 105845. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. Lect. Notes Comput. Sci. 2005, 3644, 878–887. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks, Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Liu, D.; Zhong, S.; Lin, L.; Zhao, M.; Fu, X.; Liu, X. Highly imbalanced fault diagnosis of gas turbines via clustering-based downsampling and deep siamese self-attention network. Adv. Eng. Inform. 2022, 54, 101725. [Google Scholar] [CrossRef]
- Mao, G.; Li, Y.; Cai, Z.; Qiao, B.; Jia, S. Transferable dynamic enhanced cost-sensitive network for cross-domain intelligent diagnosis of rotating machinery under imbalanced datasets. Eng. Appl. Artif. Intell. 2023, 125, 106670. [Google Scholar] [CrossRef]
- Tang, B.; He, H. KernelADASYN: Kernel-based adaptive synthetic data generation for imbalanced learning. In Proceedings of the 2015 IEEE Congress on Evolutionary Computation (CEC), Sendai, Japan, 25–28 May 2015. [Google Scholar]
- Kurniawati, Y.E.; Permanasari, A.E.; Fauziati, S. Adaptive Synthetic–Nominal (ADASYN–N) and Adaptive Synthetic–KNN (ADASYN-KNN) for multiclass imbalance learning on laboratory test data. In Proceedings of the 2018 4th International Conference on Science and Technology (ICST), Yogyakarta, Indonesia, 7–8 August 2018. [Google Scholar]
- Li, J.; Liu, Y.; Li, Q. Intelligent fault diagnosis of rolling bearings under imbalanced data conditions using attention-based deep learning method. Measurement 2022, 189, 110500. [Google Scholar] [CrossRef]
- Gu, Y.; Chen, R.; Wu, K.; Huang, P.; Qiu, G. A variable-speed-condition bearing fault diagnosis methodology with recurrence plot coding and MobileNet-v3 model. Rev. Sci. Instrum. 2023, 94, 034710. [Google Scholar] [CrossRef]
- Iandola, F.N.; Moskewicz, M.W.; Ashraf, K.; Han, S.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <1 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6848–6856. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Yu, W.; Lv, P. An end-to-end intelligent fault diagnosis application for rolling bearing based on MobileNet. IEEE Access 2021, 9, 41925–41933. [Google Scholar] [CrossRef]
- Landi, E.; Spinelli, F.; Intravaia, M.; Mugnaini, M.; Fort, A.; Bianchini, M.; Corradini, B.T.; Scarselli, F.; Tanfoni, M. A MobileNet neural network model for fault diagnosis in roller bearings. In Proceedings of the 2023 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Kuala Lumpur, Malaysia, 22–25 May 2023. [Google Scholar]
- Xu, Y.; Jiang, X. Short-term power load forecasting based on BiGRU-Attention-SENet model. Energy Sources Part A Recovery Util. Environ. Eff. 2022, 44, 973–985. [Google Scholar] [CrossRef]
- Kaiser, L.; Gomez, A.N.; Chollet, F. Depthwise separable convolutions for neural machine translation. arXiv 2017, arXiv:1706.03059. [Google Scholar]
- Zhao, C.; Zio, E.; Shen, W. Domain generalization for cross-domain fault diagnosis: An application-oriented perspective and a benchmark study. Reliab. Eng. Syst. Saf. 2024, 245, 109964. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Jia, X.; Ma, H.; Luo, Z.; Li, X. Machinery fault diagnosis with imbalanced data using deep generative adversarial networks. Measurement 2019, 152, 107377. [Google Scholar] [CrossRef]
- Zhu, F.; Liu, C.; Yang, J. An improved MobileNet network with wavelet energy and global average pooling for rotating machinery fault diagnosis. Sensors 2022, 22, 4427. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Kernel Size (Number) | Input Size | Output Size |
|---|---|---|---|
| Input | - | (1 × 1024) | - |
| DW Conv 1 | 7 × 1 (1) | (1 × 1024) | (1 × 1024) |
| PW Conv 1 | 1 × 1 (32) | (1 × 1024) | (32 × 1024) |
| SE Block 1 | - | (32 × 1024) | (32 × 1024) |
| Max Pool 1 | 2 × 1 | (32 × 1024) | (32 × 512) |
| DW Conv 2 | 7 × 1 (32) | (32 × 512) | (32 × 512) |
| PW Conv 2 | 1 × 1 (64) | (32 × 512) | (64 × 512) |
| Max Pool 2 | 2 × 1 | (64 × 512) | (64 × 256) |
| Avg Pool | - | (64 × 256) | (64 × 1) |
| Flatten | - | (64 × 1) | (64) |
| FC | - | (64) | (N) |
| Softmax | - | (N) | (N) |
| Dataset | Type of Fault | Description | Sampling Frequency |
|---|---|---|---|
| PU | Normal (K001) | Bearings with normal conditions. | 64 kHz |
| Outer ring (KA03) | Outer ring with electric engraver damage; damage level 2. | 64 kHz | |
| Outer ring (KA05) | Outer ring with electric engraver damage; damage level 1. | 64 kHz | |
| Outer ring (KA07) | Outer ring with drilling damage; damage level 1. | 64 kHz | |
| Inter ring (KI01) | Inter ring with EDM damage; damage level 1. | 64 kHz | |
| Inter ring (KI03) | Inter ring with electric engraver damage; damage level 1. | 64 kHz | |
| HUST | Normal (N) | Bearings with normal conditions. | 25.6 kHz |
| Outer race fault (O) | The severe outer race fault. | 25.6 kHz | |
| Inner race fault (I) | The severe inner race fault. | 25.6 kHz | |
| Ball fault (B) | The severe ball fault. | 25.6 kHz | |
| Combination fault (C) | The severe combination fault. | 25.6 kHz |
| Dataset | Number of Classes | Normal Sample Number | Fault Class Sample Number | p | ||||
|---|---|---|---|---|---|---|---|---|
| K001 | KA03 | KA05 | KA07 | KI01 | KI03 | |||
| A | 6 | 500 | 15 | 12 | 9 | 7 | 5 | 0.01–0.03 |
| B | 6 | 500 | 30 | 23 | 15 | 14 | 10 | 0.02–0.06 |
| C | 6 | 500 | 75 | 61 | 52 | 29 | 25 | 0.05–0.15 |
| D | 6 | 500 | 150 | 130 | 106 | 70 | 50 | 0.1–0.3 |
| Dataset | Number of Classes | Normal Sample Number | Fault Class Sample Number | p | |||
|---|---|---|---|---|---|---|---|
| N | O | I | B | C | |||
| E | 5 | 480 | 8 | 6 | 5 | 4 | 0.008–0.016 |
| F | 5 | 480 | 12 | 11 | 9 | 6 | 0.0125–0.025 |
| G | 5 | 480 | 40 | 33 | 27 | 20 | 0.042–0.083 |
| H | 5 | 480 | 96 | 82 | 65 | 48 | 0.1–0.2 |
| Dataset | Number of Classes | Normal Sample Number | Fault Class Sample Number | p | ||||
|---|---|---|---|---|---|---|---|---|
| K001 | KA03 | KA05 | KA07 | KI01 | KI03 | |||
| A | 6 | 500 | 105 | 84 | 63 | 49 | 35 | 0.07–0.21 |
| B | 6 | 500 | 210 | 161 | 105 | 98 | 70 | 0.14–0.42 |
| C | 6 | 500 | 500 | 427 | 364 | 203 | 175 | 0.35–1.0 |
| D | 6 | 500 | 500 | 500 | 500 | 490 | 350 | 0.7–1.0 |
| Dataset | Method | Acc (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|---|
| A | BEGSMOTE | 86.69 | 86.84 | 86.69 | 86.60 |
| ADASYN | 84.42 | 84.61 | 84.42 | 84.40 | |
| GAN | 88.17 | 88.32 | 88.17 | 88.23 | |
| Proposed method | 90.38 | 90.12 | 89.64 | 89.60 | |
| B | BEGSMOTE | 88.52 | 88.71 | 88.52 | 88.49 |
| ADASYN | 87.61 | 87.79 | 87.61 | 87.57 | |
| GAN | 91.73 | 91.87 | 91.73 | 91.70 | |
| Proposed method | 93.02 | 93.19 | 93.03 | 93.01 | |
| C | BEGSMOTE | 89.96 | 90.14 | 89.96 | 89.94 |
| ADASYN | 88.42 | 88.62 | 88.42 | 88.46 | |
| GAN | 92.61 | 92.78 | 92.61 | 92.60 | |
| Proposed method | 94.58 | 94.79 | 94.58 | 94.58 | |
| D | BEGSMOTE | 96.93 | 97.15 | 96.93 | 96.90 |
| ADASYN | 95.02 | 95.23 | 95.02 | 94.98 | |
| GAN | 98.83 | 99.02 | 98.83 | 98.81 | |
| Proposed method | 99.73 | 99.68 | 99.63 | 99.61 |
| Network | Description | Primary Characteristics |
|---|---|---|
| 1D-CNN | One-dimensional convolutional neural network | One-dimensional standard convolutional neural network |
| 1D-CNN-G [39] | One-dimensional CNN with GAP | Network with standard convolutional kernel and maximum pooling in the first layer and a global average pooling layer in the last layer |
| 1D-ResNet | One-dimensional ResNet | One-dimensional standard residual network |
| 1D-ShuffleNet | One-dimensional ShuffleNet | By adopting channel shuffle and group convolution, the computational cost and the number of parameters is reduced |
| Inception-v2 [40] | Improved inception architecture | Reduced computational cost and memory usage through factorized convolutions and streamlined operations |
| Parameter Count | Memory Usage (MB) | Inference Time (s) | Acc (%) | |
|---|---|---|---|---|
| 1D-ResNet | 36,913 | 0.1408 | 2.78 | 98.84 |
| 1D-CNN-G | 32,156 | 0.1227 | 2.51 | 98.51 |
| 1D-CNN | 16,983 | 0.0648 | 2.04 | 98.78 |
| Inception-v2 | 28,038 | 0.107 | 2.38 | 98.83 |
| 1D-ShuffleNet | 14,829 | 0.0566 | 1.83 | 99.21 |
| Proposed method | 2992 | 0.0114 | 1.01 | 99.72 |
| Dataset | Number of Classes | Normal Sample Number | Fault Class Sample Number | p | |||
|---|---|---|---|---|---|---|---|
| N | O | I | B | C | |||
| E | 5 | 480 | 56 | 42 | 35 | 28 | 0.056–0.112 |
| F | 5 | 480 | 84 | 77 | 63 | 42 | 0.0875–0.175 |
| G | 5 | 480 | 280 | 231 | 189 | 140 | 0.292–0.583 |
| H | 5 | 480 | 480 | 480 | 455 | 336 | 0.7–1.0 |
| Dataset | Method | Acc (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|---|
| E | BEGSMOTE | 89.14 | 89.35 | 89.14 | 89.13 |
| ADASYN | 87.39 | 87.60 | 87.39 | 87.38 | |
| GAN | 90.25 | 90.42 | 90.25 | 90.24 | |
| Proposed method | 92.36 | 92.51 | 92.36 | 92.36 | |
| F | BEGSMOTE | 92.33 | 92.53 | 92.33 | 92.32 |
| ADASYN- | 91.41 | 91.60 | 91.41 | 91.41 | |
| GAN | 93.73 | 93.90 | 9373 | 93.72 | |
| Proposed method | 95.22 | 95.43 | 95.22 | 95.21 | |
| G | BEGSMOTE | 95.71 | 95.90 | 95.71 | 95.70 |
| ADASYN | 95.12 | 95.21 | 95.12 | 95.12 | |
| GAN | 96.59 | 96.79 | 96.59 | 96.58 | |
| Proposed method | 97.86 | 98.05 | 97.86 | 97.84 | |
| H | BEGSMOTE | 97.94 | 98.14 | 97.94 | 97.94 |
| ADASYN | 97.72 | 97.91 | 97.72 | 97.70 | |
| GAN | 98.97 | 99.18 | 98.97 | 98.97 | |
| Proposed method | 99.88 | 99.87 | 99.86 | 99.86 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, W.; Wang, W.; Qin, X.; Cai, Z. A Lightweight Kernel Density Estimation and Adaptive Synthetic Sampling Method for Fault Diagnosis of Rotating Machinery with Imbalanced Data. Appl. Sci. 2024, 14, 11910. https://doi.org/10.3390/app142411910
Lu W, Wang W, Qin X, Cai Z. A Lightweight Kernel Density Estimation and Adaptive Synthetic Sampling Method for Fault Diagnosis of Rotating Machinery with Imbalanced Data. Applied Sciences. 2024; 14(24):11910. https://doi.org/10.3390/app142411910
Chicago/Turabian StyleLu, Wenhao, Wei Wang, Xuefei Qin, and Zhiqiang Cai. 2024. "A Lightweight Kernel Density Estimation and Adaptive Synthetic Sampling Method for Fault Diagnosis of Rotating Machinery with Imbalanced Data" Applied Sciences 14, no. 24: 11910. https://doi.org/10.3390/app142411910
APA StyleLu, W., Wang, W., Qin, X., & Cai, Z. (2024). A Lightweight Kernel Density Estimation and Adaptive Synthetic Sampling Method for Fault Diagnosis of Rotating Machinery with Imbalanced Data. Applied Sciences, 14(24), 11910. https://doi.org/10.3390/app142411910