
Distributed Unmanned Aerial Vehicle Cluster Testing Method Based on Deep Reinforcement Learning

Abstract
1. Introduction
- (1)
- A distributed testing task execution problem in the UAV cluster environment is proposed;
- (2)
- By taking advantage of the DDPG, the mathematical problem model of testing task execution in a distributed network environment is established. Deep reinforcement learning networks are iteratively trained to derive better testing task deployment strategy decisions. Through continuous interaction with the state environment, the reinforcement learning network is continuously optimized to achieve system load balancing and minimize bandwidth resource costs;
- (3)
- Compared with cutting-edge testing methods in distributed environments, the advantages of the method proposed in this work in task execution are evaluated.
2. Related Work
3. The Formalization of UTDR
4. The Proposed Algorithm
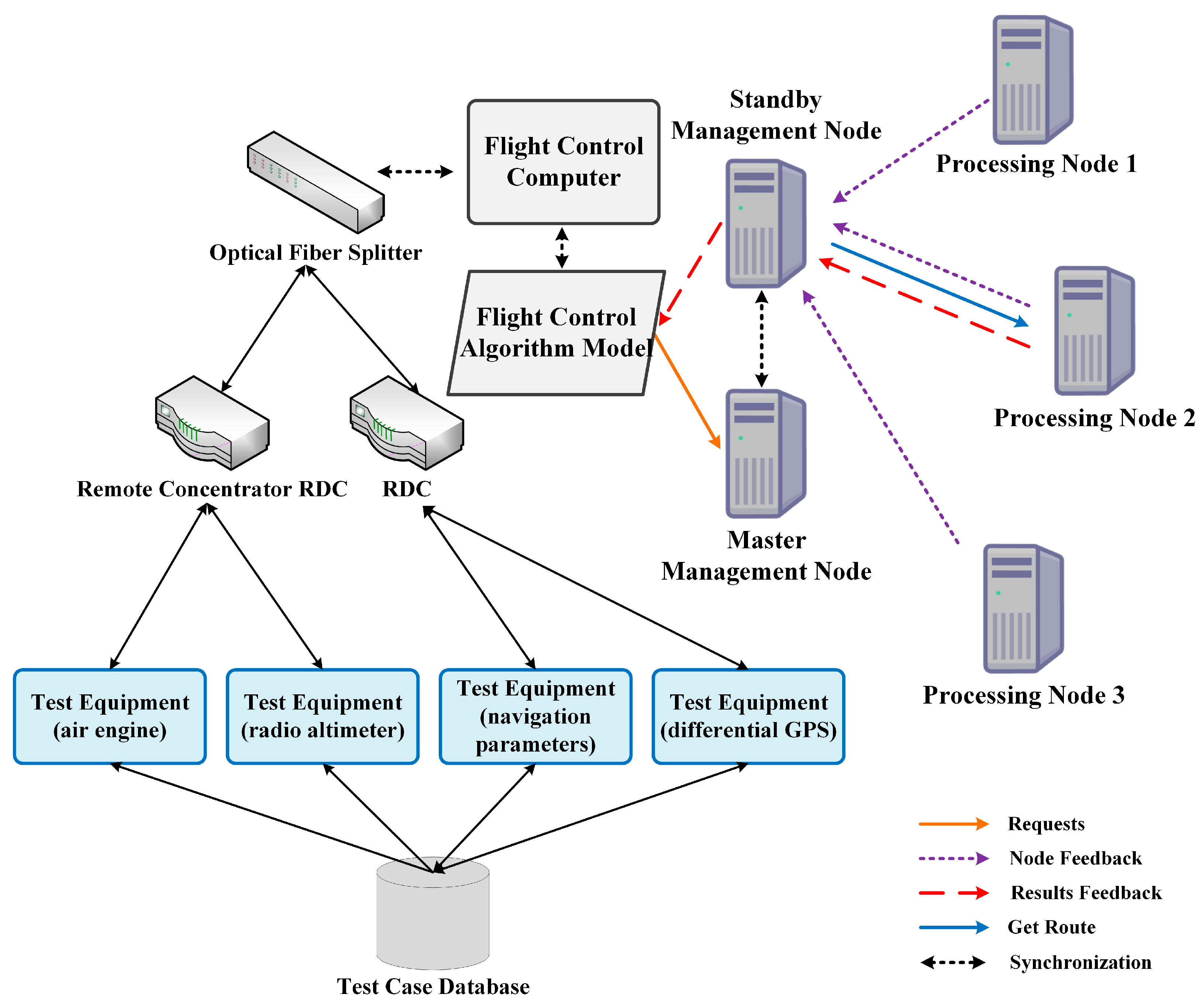
4.1. System Architecture
4.2. Main Idea
4.3. Implementation of UDTR
| Algorithm 1: Reinforcement Learning Procedure of UTDR |
| 1: Initialize the parameters of all networks in the UTDR model, θQ, θQ′, θμ, θμ′; |
| 2: Initialize the experience replay buffer B; |
| 3: for episode = 1, 2, … Max, Max is the number of training cycles |
| 4: Initialize all agents’ state st;//Initialize the state |
| 5: Each agent selects action at according to the current policy;//Select current action |
| 6: Perform action at to obtain reward rt and new state st+1;//Obtain the reward and the next state after performing the action |
| 7: Store (st, at, rt, st+1) in B;//Store the quadruple in B |
| 8: st = st+1;//Update the state |
| 9: for agent i = 1, 2, …, N |
| 10: Randomly extract some experience samples from B;//Random sampling |
| 11: Calculate the loss of Critic network via equation ; |
| 12: Using equation to calculate the gradient of Actor network;//Calculate the loss |
| 13: Update parameters for the Actor network and Critic network;//Update parameters |
| 14: Update parameters of Target network;//Update parameters |
| 15: end for |
| 16: end for |
| 17: until convergence |
5. Results
5.1. Experimental Setup
5.2. Load Balancing Effect
5.3. Bandwidth Consumption
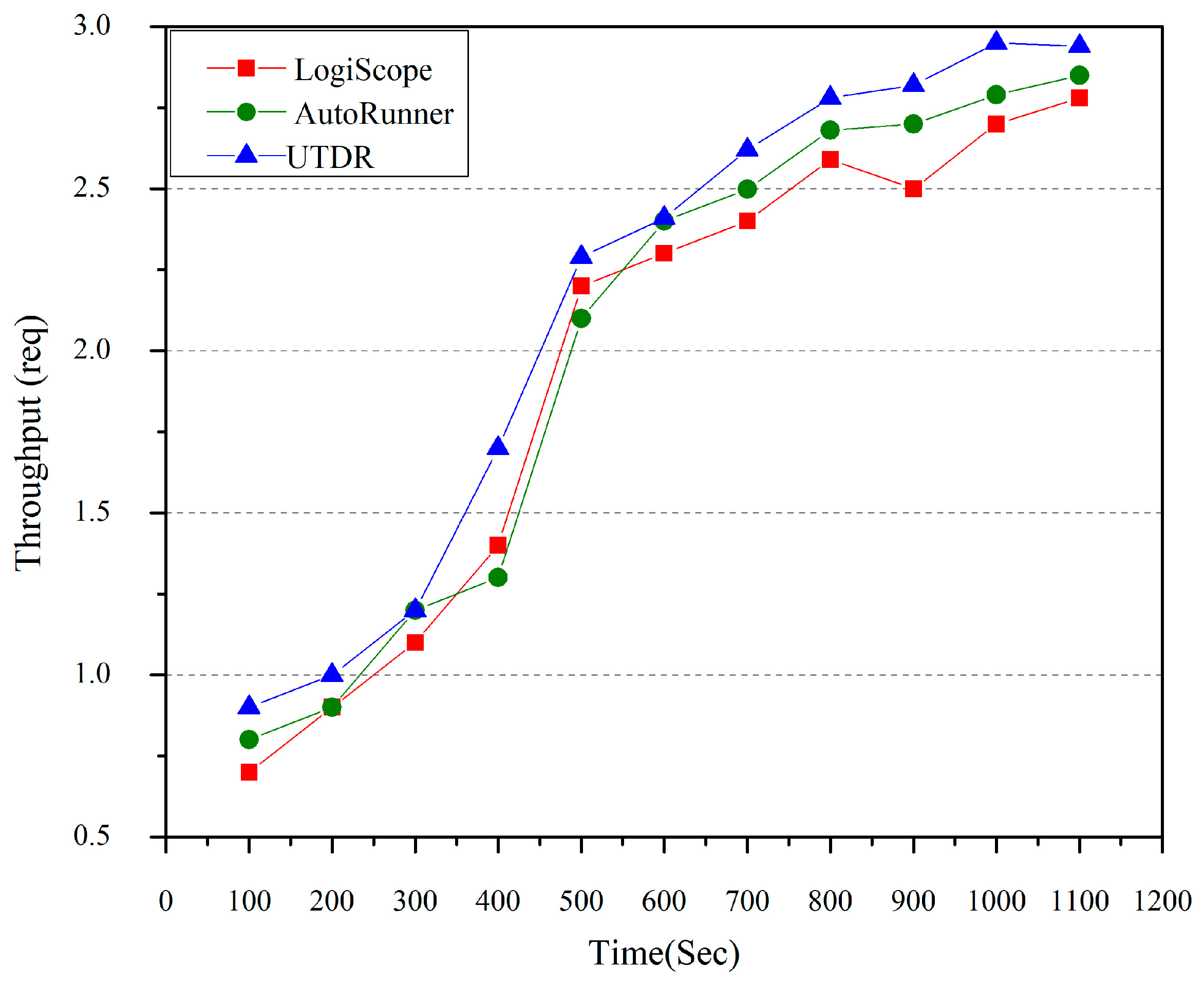
5.4. System External Service Performance
5.5. Testing Task Allocation Failure Rate
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mu, J.; Zhang, R.; Cui, Y.; Gao, N.; Jing, X. UAV meets integrated sensing and communication: Challenges and future directions. IEEE Commun. Mag. 2023, 61, 62–67. [Google Scholar] [CrossRef]
- Azari, M.M.; Geraci, G.; Garcia-Rodriguez, A.; Pollin, S. UAV-to-UAV communications in cellular networks. IEEE Trans. Wirel. Commun. 2020, 19, 6130–6144. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, L.; Zhu, L.; Zhang, T.; Xiao, Z.; Xia, X.-G. 3D deployment of multiple UAV-mounted base stations for UAV communications. IEEE Trans. Commun. 2021, 69, 2473–2488. [Google Scholar] [CrossRef]
- Zhao, J.; Gao, F.; Jia, W.; Yuan, W.; Jin, W. Integrated sensing and communications for UAV communications with jittering effect. IEEE Wirel. Commun. Lett. 2023, 12, 758–762. [Google Scholar] [CrossRef]
- Cheng, X.; Shi, W.; Cai, W.; Zhu, W.; Shen, T.; Shu, F.; Wang, J. Communication-efficient coordinated RSS-based distributed passive localization via drone cluster. IEEE Trans. Veh. Technol. 2021, 71, 1072–1076. [Google Scholar] [CrossRef]
- Ramdane, Y.; Boussaid, O.; Boukraà, D.; Kabachi, N.; Bentayeb, F. Building a novel physical design of a distributed big data warehouse over a Hadoop cluster to enhance OLAP cube query performance. Parallel Comput. 2022, 111, 102918. [Google Scholar] [CrossRef]
- Myint, K.N.; Zaw, M.H.; Aung, W.T. Parallel and distributed computing using MPI on raspberry Pi cluster. Int. J. Future Comput. Commun. 2020, 9, 18–22. [Google Scholar] [CrossRef]
- Gu, W.; Valavanis, K.P.; Rutherford, M.J.; Rizzo, A. UAV model-based flight control with artificial neural networks: A survey. J. Intell. Robot. Syst. 2020, 100, 1469–1491. [Google Scholar] [CrossRef]
- Huang, J.; Tian, G.; Zhang, J.; Chen, Y. On unmanned aerial vehicles light show systems: Algorithms, software and hardware. Appl. Sci. 2021, 11, 7687. [Google Scholar] [CrossRef]
- Susanto, T.; Setiawan, M.B.; Jayadi, A.; Rossi, F.; Hamdhi, A.; Sembiring, J.P. Application of Unmanned Aircraft PID Control System for Roll, Pitch and Yaw Stability on Fixed Wings. In Proceedings of the 2021 IEEE International Conference on Computer Science, Information Technology, and Electrical Engineering (ICOMITEE), Banyuwangi, Indonesia, 27–28 October 2021. [Google Scholar]
- Štroner, M.; Urban, R.; Línková, L. A new method for UAV Lidar precision testing used for the evaluation of an affordable DJI ZENMUSE L1 scanner. Remote Sens. 2021, 13, 4811. [Google Scholar] [CrossRef]
- Sartaj, H. Automated approach for system-level testing of unmanned aerial systems. In Proceedings of the 2021 IEEE 36th IEEE/ACM International Conference on Automated Software Engineering (ASE), Melbourne, Australia, 15–19 November 2021. [Google Scholar]
- Kim, S.; Philip, O.A.; Tullu, A.; Jung, S. Development and verification of a ros-based multi-dof flight test system for unmanned aerial vehicles. IEEE Access 2023, 11, 37068–37081. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, X. Design and testing of cooperative motion controller for UAV-UGV system. Mechatron. Intell. Transp. Syst. 2022, 1, 12–23. [Google Scholar] [CrossRef]
- Santoso, F.; Garratt, M.A.; Anavatti, S.G. Hybrid PD-fuzzy and PD controllers for trajectory tracking of a quadrotor unmanned aerial vehicle: Autopilot designs and real-time flight tests. IEEE Trans. Syst. Man Cybern. Syst. 2019, 51, 1817–1829. [Google Scholar] [CrossRef]
- Li, F.; Zhang, K.; Wang, J.; Li, Y.; Xu, F.; Wang, Y.; Tong, N. Multi-UAV Hierarchical Intelligent Traffic Offloading Network Optimization Based on Deep Federated Learning. IEEE Internet Things J. 2024, 11, 21312–21324. [Google Scholar] [CrossRef]
- Xi, M.; Dai, H.; He, J.; Li, W.; Wen, J.; Xiao, S.; Yang, J. A lightweight reinforcement learning-based real-time path planning method for unmanned aerial vehicles. IEEE Internet Things J. 2024, 11, 21061–21071. [Google Scholar] [CrossRef]
- Arunarani, A.; Manjula, D.; Sugumaran, V. Task scheduling techniques in cloud computing: A literature survey. Future Gener. Comput. Syst. 2018, 91, 407–415. [Google Scholar] [CrossRef]
- Yuan, H.; Bi, J.; Zhou, M.; Liu, Q.; Ammari, A.C. Biobjective task scheduling for distributed green data centers. IEEE Trans. Autom. Sci. Eng. 2020, 18, 731–742. [Google Scholar] [CrossRef]
- Saleem, U.; Liu, Y.; Jangsher, S.; Li, Y.; Jiang, T. Mobility-aware joint task scheduling and resource allocation for cooperative mobile edge computing. IEEE Trans. Wirel. Commun. 2020, 20, 360–374. [Google Scholar] [CrossRef]
- Hosseinioun, P.; Kheirabadi, M.; Tabbakh, S.R.K.; Ghaemi, R. A new energy-aware tasks scheduling approach in fog computing using hybrid meta-heuristic algorithm. J. Parallel Distrib. Comput. 2020, 143, 88–96. [Google Scholar] [CrossRef]
- Ladosz, P.; Weng, L.; Kim, M.; Oh, H. Exploration in deep reinforcement learning: A survey. Inf. Fusion 2022, 85, 1–22. [Google Scholar] [CrossRef]
- Xiao, Y.; Zhang, Q.; Liu, F.; Wang, J.; Zhao, M.; Zhang, Z.; Zhang, J. NFVdeep: Adaptive online service function chain deployment with deep reinforcement learning. In Proceedings of the International Symposium on Quality of Service, Phoenix, AZ, USA, 24–25 June 2019. [Google Scholar]
- Zhou, C.; Wu, W.; He, H.; Yang, P.; Lyu, F.; Cheng, N.; Shen, X. Deep reinforcement learning for delay-oriented IoT task scheduling in SAGIN. IEEE Trans. Wirel. Commun. 2020, 20, 911–925. [Google Scholar] [CrossRef]
- Zhao, N.; Ye, Z.; Pei, Y.; Liang, Y.-C.; Niyato, D. Multi-agent deep reinforcement learning for task offloading in UAV-assisted mobile edge computing. IEEE Trans. Wirel. Commun. 2022, 21, 6949–6960. [Google Scholar] [CrossRef]
- Campos-Martínez, S.-N.; Hernández-González, O.; Guerrero-Sánchez, M.-E.; Valencia-Palomo, G.; Targui, B.; López-Estrada, F.-R. Consensus Tracking Control of Multiple Unmanned Aerial Vehicles Subject to Distinct Unknown Delays. Machines 2024, 12, 337. [Google Scholar] [CrossRef]
- Galicia-Galicia, L.-A.; Hernández-González, O.; Garcia-Beltran, C.D.; Valencia-Palomo, G.; Guerrero-Sánchez, M.-E. Distributed Observer for Linear Systems with Multirate Sampled Outputs Involving Multiple Delays. Mathematics 2024, 12, 2943. [Google Scholar] [CrossRef]
- Zhou, L.; Leng, S.; Liu, Q.; Wang, Q. Intelligent UAV swarm cooperation for multiple targets tracking. IEEE Internet Things J. 2021, 9, 743–754. [Google Scholar] [CrossRef]
- Zhou, L.; Leng, S.; Wang, Q.; Liu, Q. Integrated sensing and communication in UAV swarms for cooperative multiple targets tracking. IEEE Trans. Mob. Comput. 2022, 22, 6526–6542. [Google Scholar] [CrossRef]
- Kapoor, M.; Parikh, N.; Jhaveri, V.; Mehta, V.; Sikka, P. LogiScope: Low Cost & Portable Logical Analyzer For Single Device and Multiple Platforms. Int. J. Emerg. Technol. Adv. Eng. 2014, 4, 695–701. [Google Scholar]
- Ding, Y.; Xiang, R. An Automated Test Scheme based on AutoRunner and TestCenter. In Wireless Communication and Sensor Network, Proceedings of the International Conference on Wireless Communication and Sensor Network (WCSN 2015), Changsha, China, 12–13 December 2015; World Scientific: Singapore, 2016. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| WLif | Load balancing degree of the ith UAV node data |
| Uif | Resource utilization of the ith node |
| Ri | Total resources of the ith node |
| Mean(U) | Average resource utilization in a certain period of time |
| A | Load balancing degree of the whole system |
| B(LDAG, t) | Total bandwidth resource cost required in the collaborative processing of multi-UAV testing tasks |
| wj,k | Weight of the wireless network link |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, D.; Yang, P. Distributed Unmanned Aerial Vehicle Cluster Testing Method Based on Deep Reinforcement Learning. Appl. Sci. 2024, 14, 11282. https://doi.org/10.3390/app142311282
Li D, Yang P. Distributed Unmanned Aerial Vehicle Cluster Testing Method Based on Deep Reinforcement Learning. Applied Sciences. 2024; 14(23):11282. https://doi.org/10.3390/app142311282
Chicago/Turabian StyleLi, Dong, and Panfei Yang. 2024. "Distributed Unmanned Aerial Vehicle Cluster Testing Method Based on Deep Reinforcement Learning" Applied Sciences 14, no. 23: 11282. https://doi.org/10.3390/app142311282
APA StyleLi, D., & Yang, P. (2024). Distributed Unmanned Aerial Vehicle Cluster Testing Method Based on Deep Reinforcement Learning. Applied Sciences, 14(23), 11282. https://doi.org/10.3390/app142311282