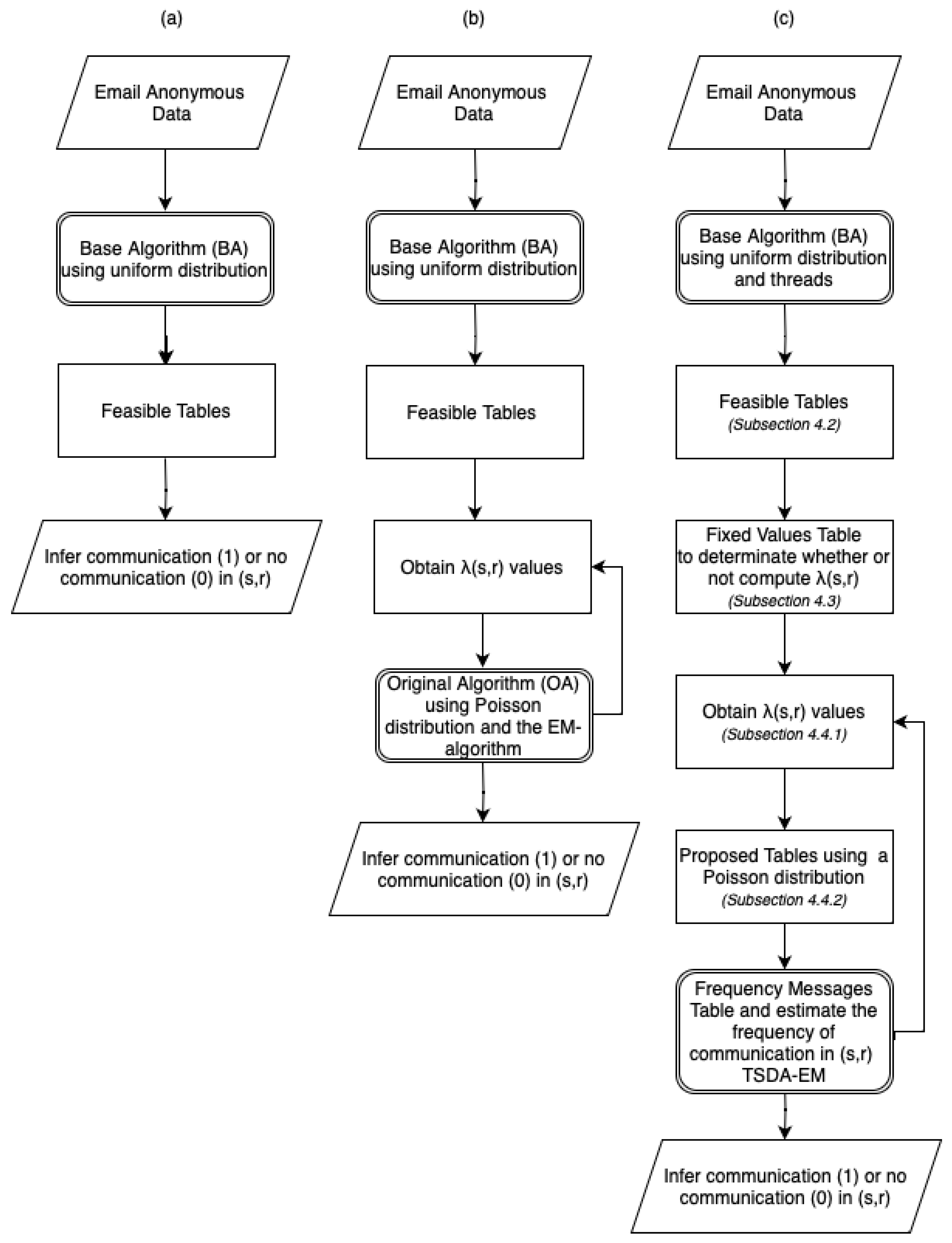
Proposed tables are defined as a set of tables with the same properties as rounds. This means that for each round, there will be a proposed table. The difference from each other is that rounds only contains participants and
. Otherwise, proposed tables, besides the participants and marginals, will contain a specific cell value that is more likely to be the real number of messages sent by a pair of senders and receivers. A proposed table is an inference generated by a set of Poisson distributions
, where each cell value (number of messages) has a high probability of being the real number of messages sent and received by the pair of communication. The more refined
for each cell is, the more accurately the proposed tables will describe the communication in a round. These proposed tables will also help to remove those excess
1s from the fixed values table. Since the fixed values table (
Table 3) knows which communication pair has a
1 (which means, the corresponding cell on every round where this pair appears must have assigned a value different to
0), we can remove such
1 when we finish the proposed table and the cell
does not have a value different to
0. That is, the fixed values table for pair
recommends putting a value different from
0, but the proposed table was complete with no need to assign a value for this cell. The final objective of these tables is to infer each round with no random values in every cell.
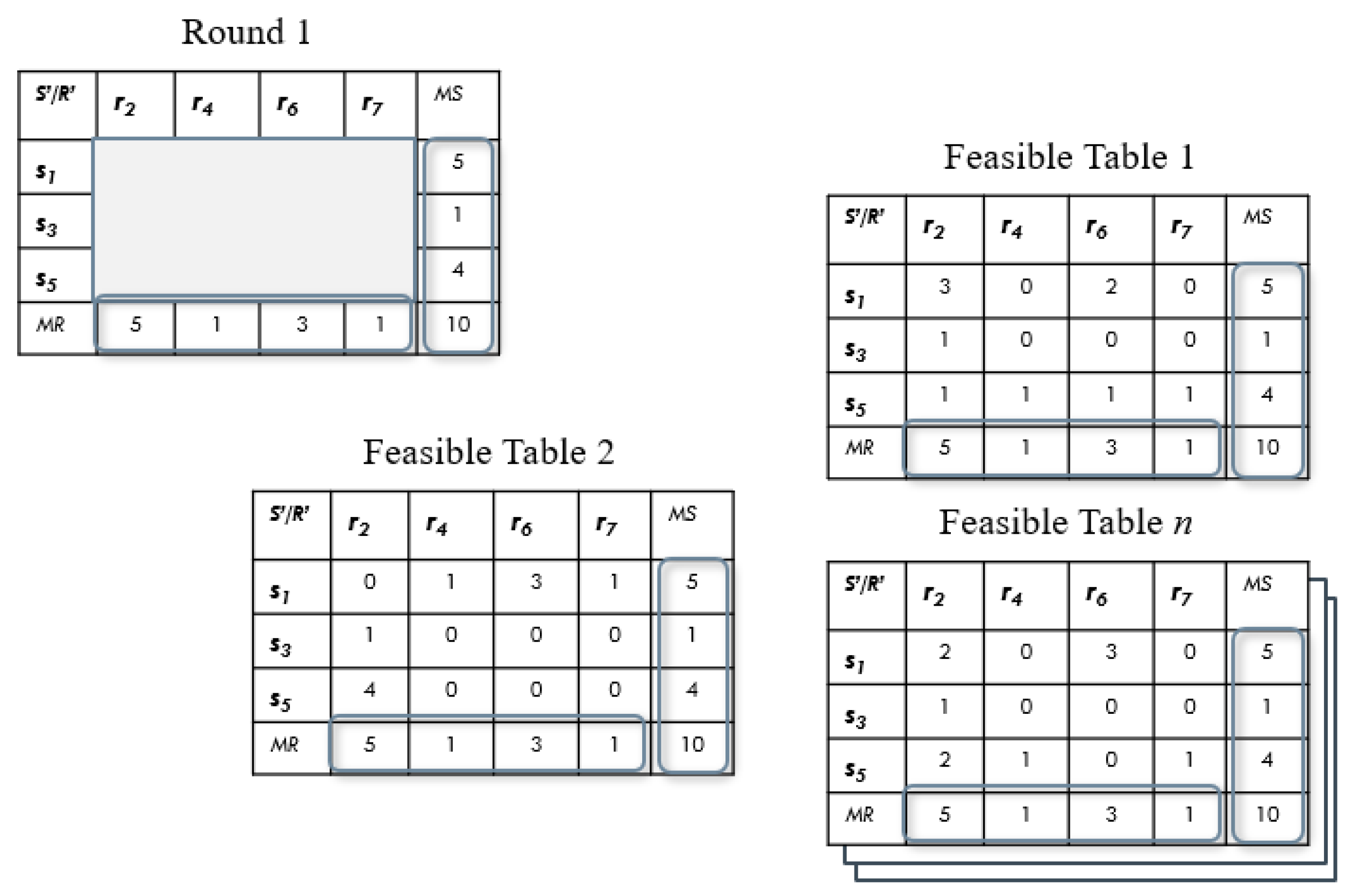
Table 4 is an example of how to set each value.
Now notice that we have to put in a great effort to complete the tables, assigning values for every cell. For example, in the column of , we must set three values for each cell, but only assigning a 1 on the column will complete that row. So the other two cells of the column can be set to 0. In the same way with the sender and recipient .
It is important to find the most appropriate value for each cell that does not exceed the
. This means selecting a random number that falls between the lowest and highest possible values for each cell according to the
. Additionally, this number must take into account the values stored in the other rows. The BA introduced at [
17] runs first and obtains all feasible tables. Then, a rate parameter must be calculated. This parameter, denoted as
, represents the probability that there is communication between a sender
s and a receiver
r. It follows a Poisson distribution and needs to be calculated for each cell across the rounds.
4.4.1. Getting with EM
The Expectation Maximization (EM) algorithm has been used to estimate the means of
k normal distributions for the hidden variables
, given its current hypothesis
and the data
. The description of each instance can be thought of as the triplet
, where
is the observed value of the
ith instance and where
and
indicate which of the two Normal distributions was used to generate the value
[
39].
The EM algorithm searches for a maximum likelihood hypothesis by repeatedly re-estimating the expected values of the hidden variables given its current hypothesis .
As mentioned before, we use the Poisson distribution (), instead of the normal distribution (), motivated by the fact that the rounds, defined by the attacker, may be constructed by batches of messages or, alternatively, by time periods; this distribution is very useful when dealing with unpredictable events.
The EM algorithm consists of two steps:
Step 1: Calculate the expected value of each hidden variable , assuming the current hypothesis holds.
Step 2: Calculate a new maximum likelihood hypothesis , assuming the value taken on by each hidden variable is its expected value calculated in Step 1. Then replace the hypothesis by the new hypothesis and iterate.
In the context of our problem, where we have rounds where each one has cells and where for each cell we have the number of messages sent (all taken by feasible tables) and its , the EM algorithm will be implemented as:
Hypothesis , where the initial value for is the highest marginal and is the lowest marginal of the pair of communication between sender s and recipient r. In case the marginals are the same, will be 0.
Data , where will be the number of messages for the cell of every feasible table generated for the round on turn.
In order to calculate the expected value
, the first step will be:
Finally, to calculate a new maximum likelihood, we use:
For a comprehensive understanding of the Expectation Maximization algorithm implementation, please refer to Algorithms 1 and 2. Additionally, in Algorithm 2, we have chosen to provide a more detailed explanation of the process, as we are simulating an iteration for
Table 4 to calculate the values
.
| Algorithm 1 Expectation(x, ) |
- 1:
- 2:
- 3:
while do ▹ go through both hypothesis - 4:
- 5:
end while - 6:
return
|
| Algorithm 2 Maximization(). Simulating an iteration for Table 4 for the cell |
- 1:
- 2:
▹ since both marginals are the same - 3:
- 4:
▹ Set of values for cell from Feasible Tables of the round - 5:
while
do - 6:
while do - 7:
- 8:
- 9:
- 10:
- 11:
end while - 12:
- 13:
end while
|
As a result of EM, we have obtained two new refined likelihood hypotheses for cell (). These refined hypotheses represent the mean number of messages for the cell. Since each represents a different mean, we only keep the highest in order to have a mean different from 0. Remember, our goal is to generate proposed tables with the most appropriate cell values.
A value for each cell represents the mean number of messages in all the feasible tables. Once we have generated , we can use an algorithm to generate a random value with a Poisson distribution.
4.4.2. Proposed Tables
The proposed tables are auxiliary tables that help to infer real communication. Once we have the
values, we use an algorithm to generate random values based on the
’s [
40]. Since the algorithm is based on a Poisson distribution, it is important to iterate the EM algorithm to refine the values of
. There are two different ways to iterate the TSDA-EM algorithm:
Reuse previously generated feasible tables: The distribution will not vary due to the constant values of the feasible tables, but it may be difficult to store all these tables.
Generate new feasible tables at each iteration: The distribution will vary depending of the feasible tables, but these will be deleted after they have been used.
Since the number of rounds and tables can be high, we have decided to follow the second option. That is, generate the feasible tables, compute , and then drop all these tables.
Our problem is based on a defined period of time, that is, a mix network by either number of messages or a certain amount of time. We say there were exactly
n number of messages sent or delivered during one unit of time (which follows a
) where the inter times
are exponentially distributed with the rate
. It can be interpreted as the number of messages sent or received from a Poisson arrival process in one unit of time. And following these ideas, there is a relationship between the Poisson distribution and the exponential distribution. There were
n number of messages during one unit of time, but the
nth message occurred before time 1; the event
st occurred after time 1. It means the sum of the times
belongs to the first unit of time, while the sum
belongs to a second unit of time.
Equation (
6) can be expressed as
As mentioned before,
represents the inter times between events (emission and receptions of messages), and it had an exponential distribution with rate
. We can use the cumulative distribution function in order to generate a probability.
As
is the probability (it has a uniform distribution over interval
) of the cumulative distribution function
, we can generate its inverse
for
in terms of
:
A common simplification of Equation (
9) is to replace
by
to yield. Now we can define Formula:
Finally, in order to simplify Formula (
10), multiply by
, use the fact that a sum of logarithms is the logarithm of a product, and then use relation
to obtain:
An acceptation-rejection technique to generate random values using Equation (
11) with
as a parameter is shown in [
39]. It has three steps:
Step 1 set ,
Step 2 Generate a random number (over interval [0, 1]), and replace P by
Step 3 If , then accept n. Otherwise, reject the current n, increase n by one and return to step 2.
What these steps do is count the number,
n, of random values (probability
) generated and stop when the multiplication of these random values,
P, is less than
, because this represents that an event occurred in the second unit of time (the right part of Equation (
11)). Otherwise, we continue generating random values that belong to the first unit of time. More details of Equation (
11) implementation are discussed in Algorithm 3.
In order to generate the proposed tables, it is necessary to identify the cell with the highest
and generate a random value for that cell using Equation (
11). This value must be truncated to fit within the marginals or can take the value 0.
We have generated a value for the highest
to try to complete at least the row or the column and avoid the use of the rest of
’s in the row or column of this cell. For example, the highest
value in
Table 5 is cell
with
. Using Equation (
11), it returns the random value 5. A perfect value to complete the
of the column and the row.
| Algorithm 3 Equation (11) implementation to generate random values given a Poisson distribution () |
- 1:
- 2:
- 3:
while do - 4:
- 5:
- 6:
if then - 7:
return n - 8:
else - 9:
- 10:
end if - 11:
end while
|
Since the random value generated completes the row and column marginals, the
’s for the rest of the row and column are considered unnecessary, and we can assign a value of
0, as shown in
Table 6. Once we have generated a random value for the highest
, we can use the fixed values table (
Table 3) and generate a value in the cell
of the proposed table indicated by the fixed values table only if there is a
1 in cell
of the fixed values table. Remember, if there is a
1, it means that a pair of communication has been active the whole time; the value in the cell
of the round has to have a number of messages different from
0. In this way, we can continue generating a random value for the cells
in the round. Obviously, not all
1s in the fixed value tables are accurate; some of them are wrong. Identifying these wrong 1s is simple; when you do not require the generation of a random cell value, we say the
1 is wrong and does not have a reason to exist. So we change the
1 to
0 on the fixed value table in order to discard it and do not try to generate another random value for the cell in a next iteration. Following the example, these unnecessary cells so far are:
,
,
,
, and
.
If those pairs of communication were not used to generate a random number, then we have to change the cell value of the fixed values table to 0 (if there is a 1 on some of the cells of the round). In this way, we can reduce the excess of 1 s from our fixed values table. Those 1 s on fixed table values tell us if we need to assign a value to the cell . As we did not assign a value to the cell, it means the cell in fixed table values could be wrong.
Also, there is a possibility to find some rounds where the marginals are not complete. After assigning values to each necessary cell, we check if all marginals are complete. If some marginal are not complete, we must assign a value to complete them. The reason for that is the
. Because it is too low, it cannot generate at least one value different from
0. Remember that each
is refined in function of the values on the cell of each feasible table. If most of the cell values are
0, the
will be modeled close to
0. Another reason may be the deactivation of the cell in the last iteration. Due to the disabled cell, it returns
0 by default. For both cases, we must assign a value to complete the table, change the value for the fixed values table, and then activate the cell to get
. After the first iteration, we obtain
Table 6.


 ,
, 

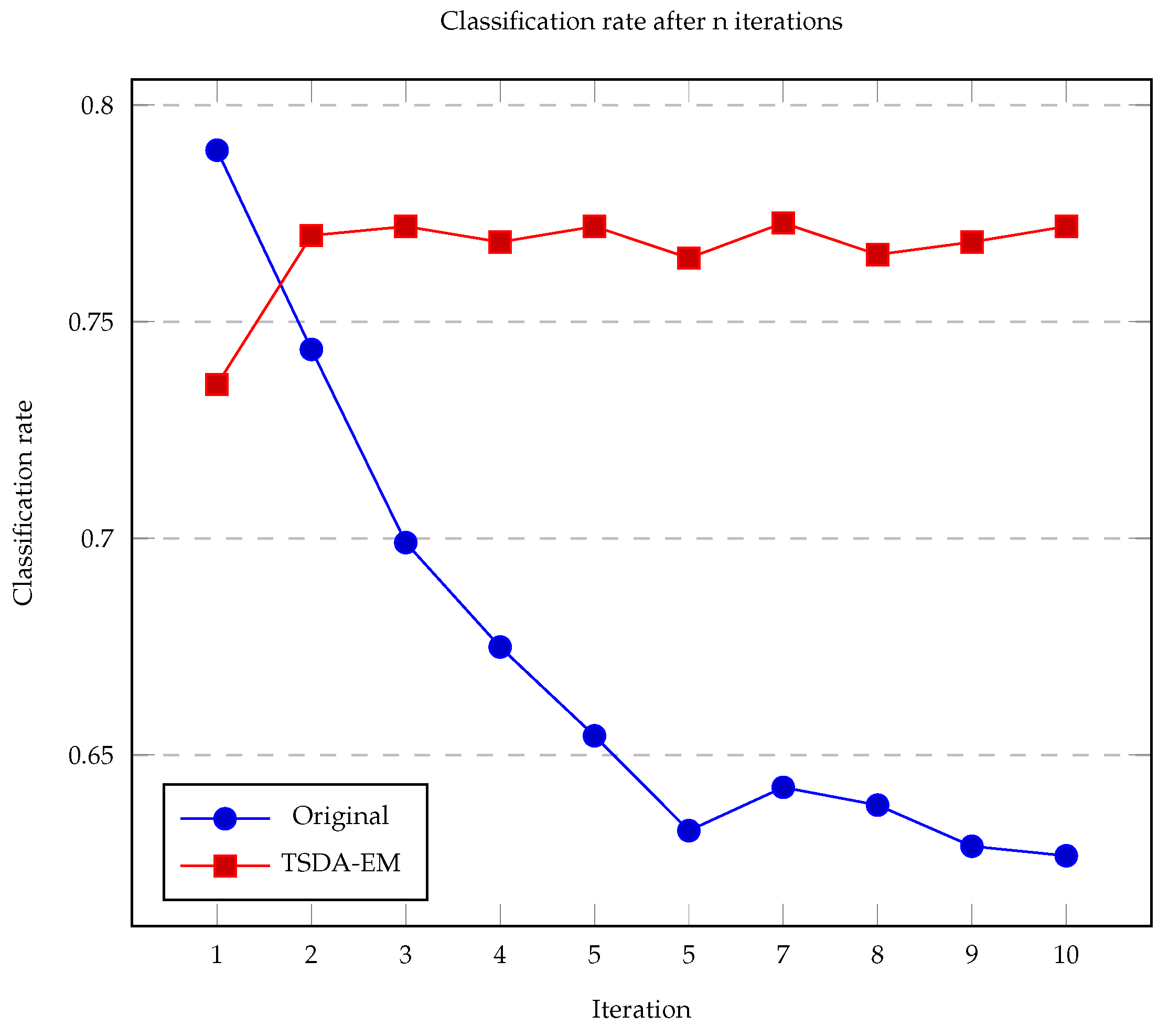
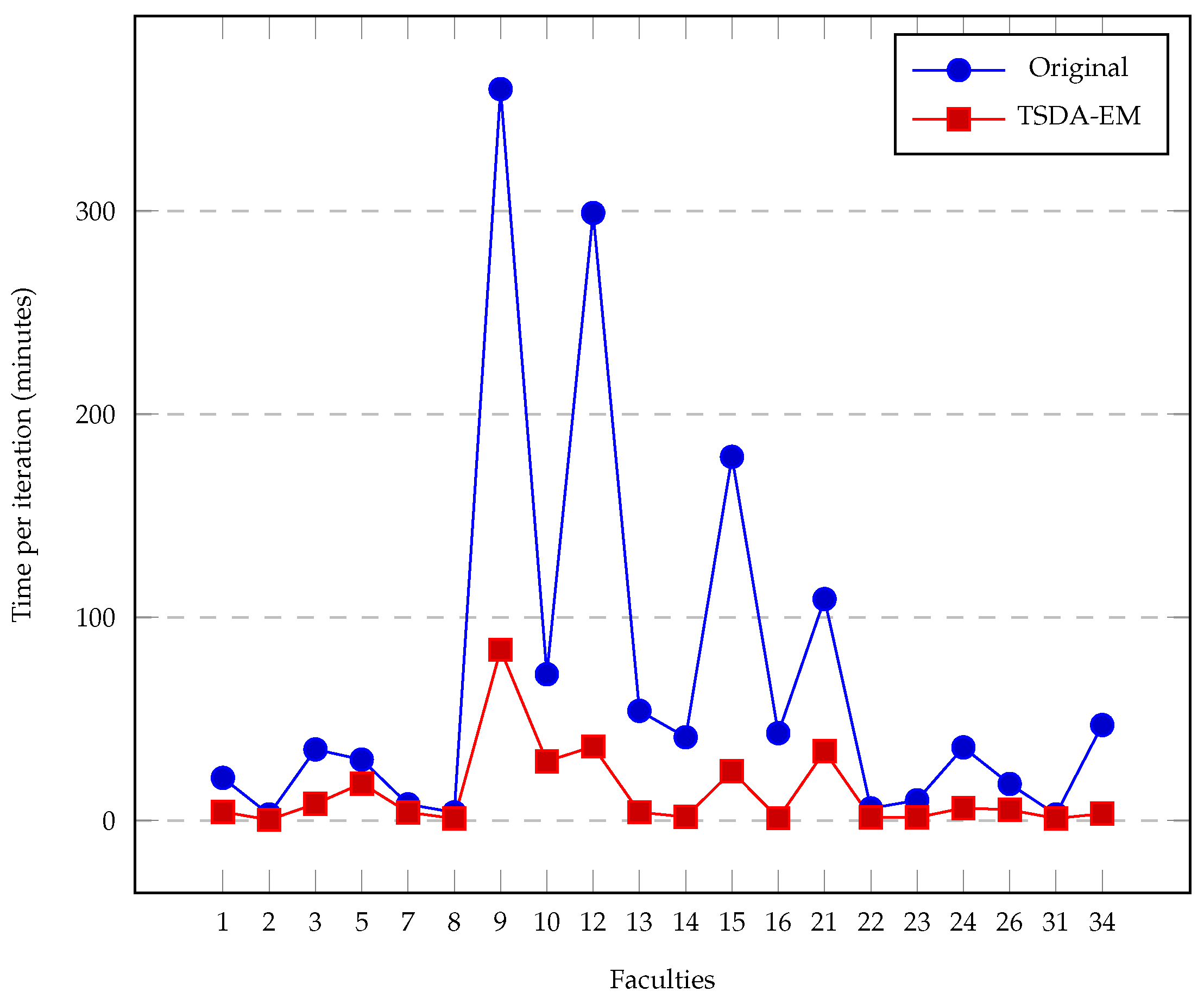
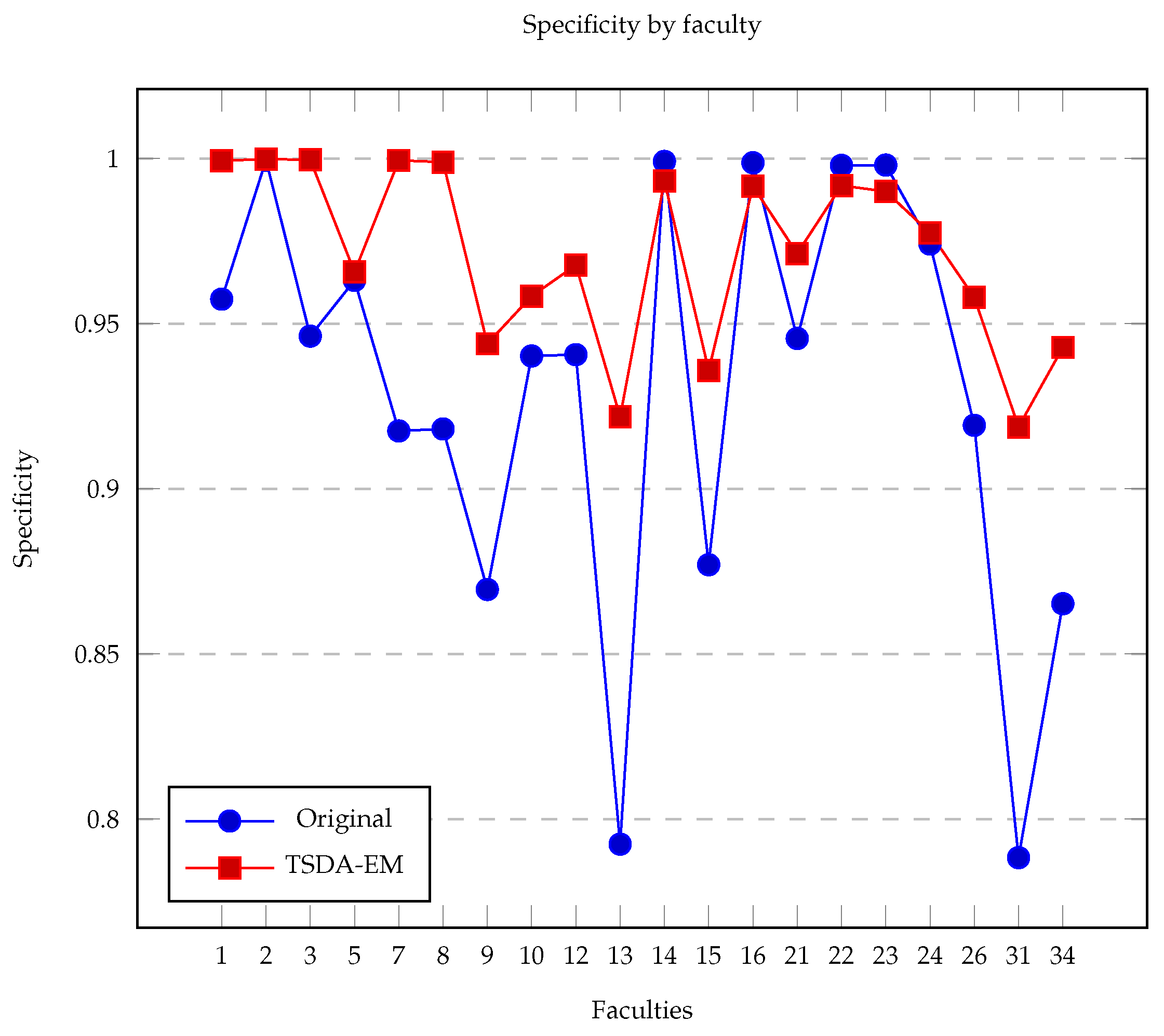
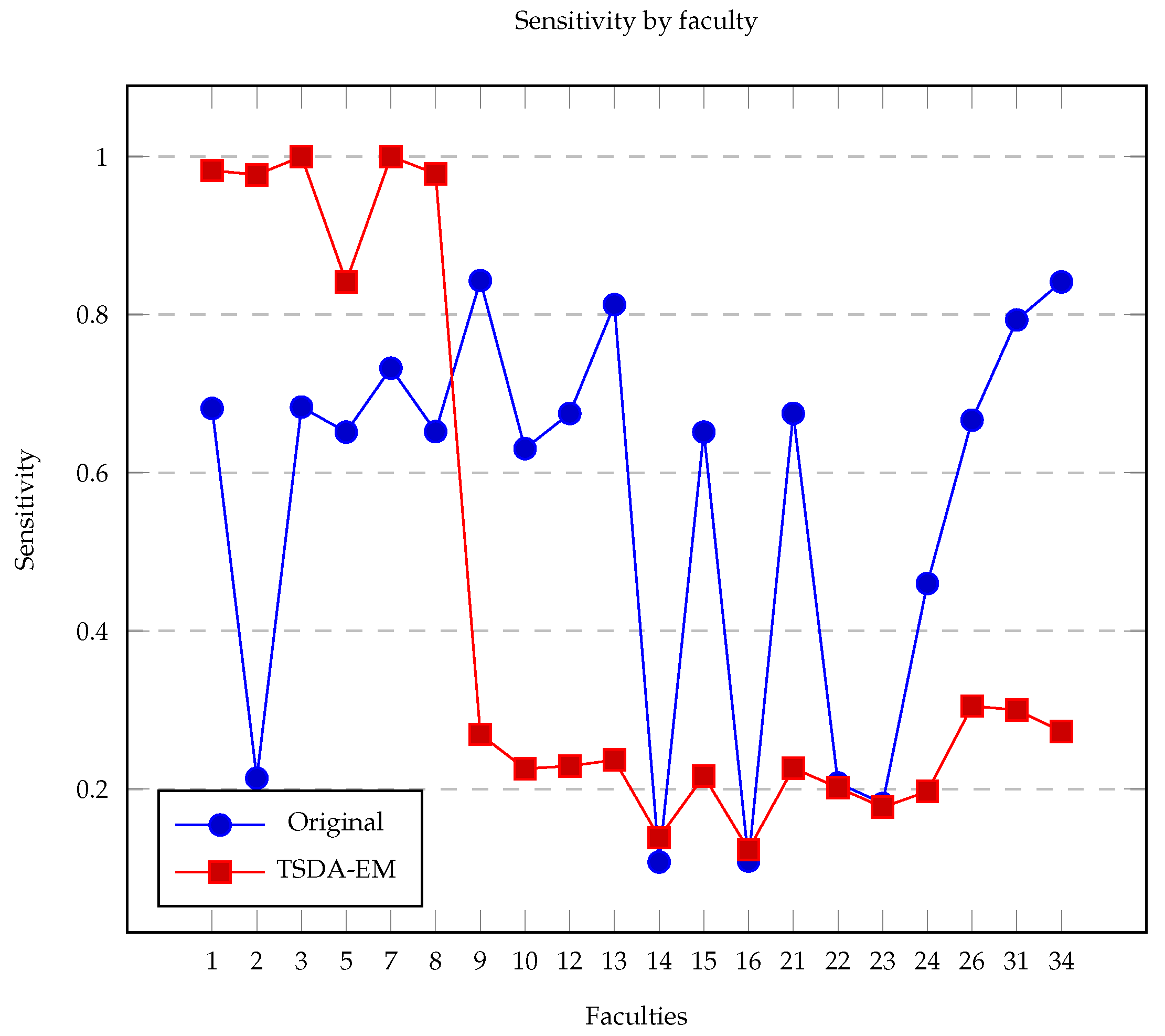

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}