
Generative Artificial Intelligence in the Early Diagnosis of Gastrointestinal Disease



Abstract
1. Introduction
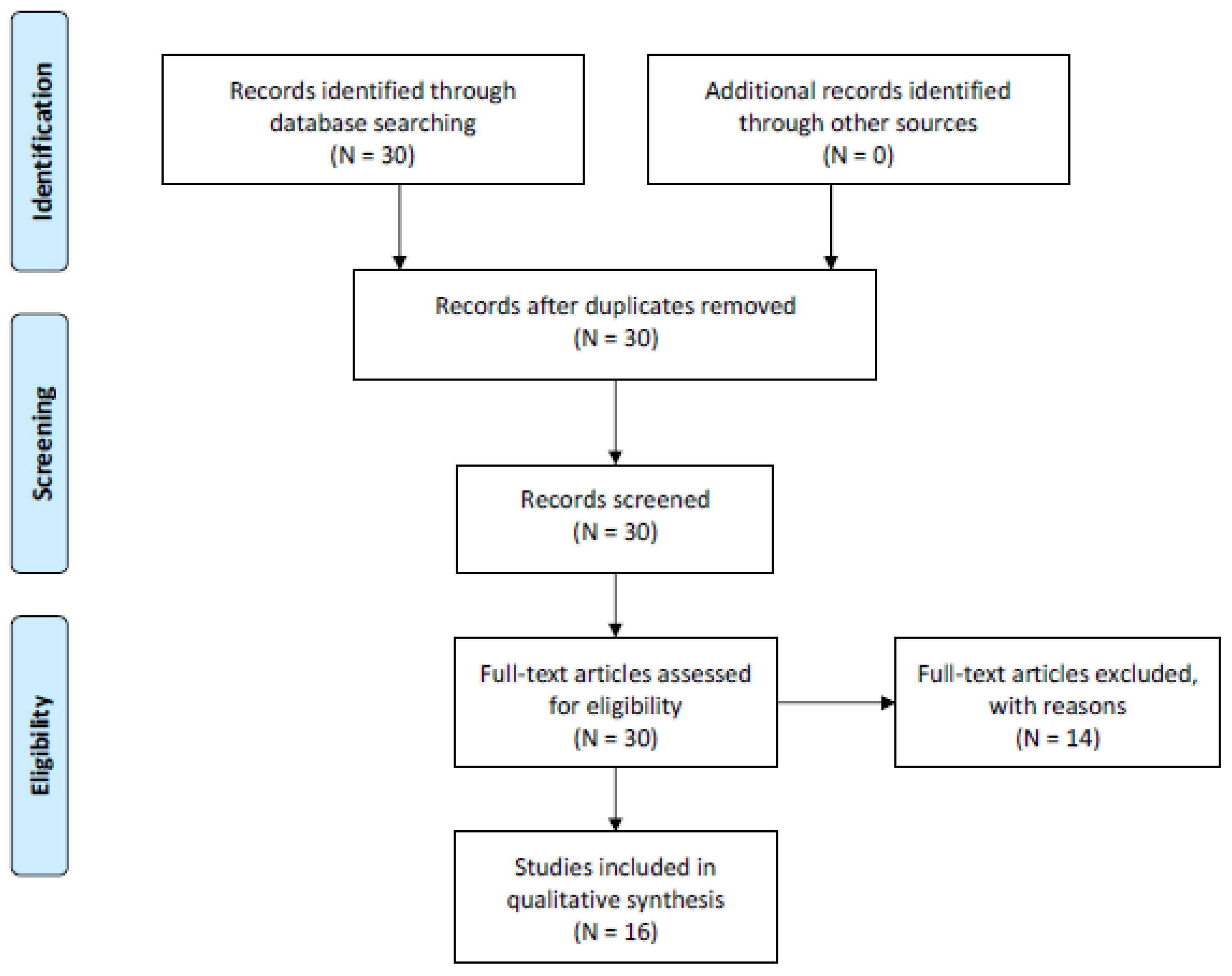
2. Methods
3. Results
3.1. Summary
3.2. GAN
3.3. Transformer
4. Discussion
4.1. Evaluation Measure of Data Generation
4.2. Generative Artificial Intelligence with Reinforcement Learning
4.3. Synthesizing Different Kinds of Generative Artificial Intelligence
4.4. Rigorous Qualitative Evaluation for Generative Artificial Intelligence
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ashwin, N.A.; Ramnik, J.X. Gastrointestinal diseases. In Hunter’s Tropical Medicine and Emerging Infectious Diseases, 20th ed.; Ryan, E.T., Hill, D.R., Solomon, T., Aronson, N., Endy, T.P., Eds.; Elsevier: Amsterdam, The Netherlands, 2020; pp. 16–26. [Google Scholar]
- Milivojevic, V.; Milosavljevic, T. Burden of gastroduodenal diseases from the global perspective. Curr. Treat. Options Gastroenterol. 2020, 18, 148–157. [Google Scholar] [CrossRef] [PubMed]
- Peery, A.F.; Crockett, S.D.; Murphy, C.C.; Jensen, E.T.; Kim, H.P.; Egberg, M.D.; Lund, J.L.; Moon, A.M.; Pate, V.; Barnes, E.L.; et al. Burden and cost of gastrointestinal, liver, and pancreatic diseases in the United States, Update 2021. Gastroenterology 2022, 162, 621–644. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.E.; Park, H.; Jo, M.W.; Oh, I.H.; Go, D.S.; Jung, J.; Yoon, S.J. Trends and patterns of burden of disease and injuries in Korea using disability-adjusted life years. J. Korean Med. Sci. 2019, 34 (Suppl. 1), e75. [Google Scholar] [CrossRef] [PubMed]
- Jung, H.K.; Jang, B.; Kim, Y.H.; Park, J.; Park, S.Y.; Nam, M.H.; Choi, M.G. Health care costs of digestive diseases in Korea. Korean J. Gastroenterol. 2011, 58, 323–331. [Google Scholar] [CrossRef] [PubMed]
- Mills, J.C.; Stappenbeck, T.S. Gastrointestinal disease. In Pathophysiology of Disease, an Introduction to Clinical Medicine, 7th ed.; Hammer, G.D., McPhee, S.J., Eds.; McGraw-Hill Education: New York, NY, USA, 2014; pp. 1–72. [Google Scholar]
- Lee, K.S.; Ahn, K.H. Application of artificial intelligence in early diagnosis of spontaneous preterm labor and birth. Diagnostics 2020, 10, 733. [Google Scholar] [CrossRef]
- Lee, K.S.; Ham, B.J. Machine learning on early diagnosis of depression. Psychiatry Investig. 2022, 19, 597–605. [Google Scholar] [CrossRef]
- Byeon, S.J.; Park, J.; Cho, Y.A.; Cho, B.J. Automated histological classification for digital pathology images of colonoscopy specimen via deep learning. Sci. Rep. 2022, 12, 12804. [Google Scholar] [CrossRef]
- Lee, K.S.; Son, S.H.; Park, S.H.; Kim, E.S. Automated detection of colorectal tumors based on artificial intelligence. BMC Med. Inform. Decis. Mak. 2021, 21, 33. [Google Scholar] [CrossRef]
- Yu, T.; Lin, N.; Zhang, X.; Pan, Y.; Hu, H.; Zheng, W.; Liu, J.; Hu, W.; Duan, H.; Si, J. An end-to-end tracking method for polyp detectors in colonoscopy videos. Artif. Intell. Med. 2022, 131, 102363. [Google Scholar] [CrossRef]
- Cui, R.; Yang, R.; Liu, F.; Cai, C. N-Net, Lesion region segmentations using the generalized hybrid dilated convolutions for polyps in colonoscopy images. Front. Bioeng. Biotechnol. 2022, 10, 963590. [Google Scholar] [CrossRef]
- Esposito, A.A.; Zannoni, S.; Castoldi, L.; Giannitto, C.; Avola, E.; Casiraghi, E.; Catalano, O.; Carrafiello, G. Pseudo-pneumatosis of the gastrointestinal tract, its incidence and the accuracy of a checklist supported by artificial intelligence (AI) techniques to reduce the misinterpretation of pneumatosis. Emerg. Radiol. 2021, 28, 911–919. [Google Scholar] [CrossRef]
- Kang, E.A.; Jang, J.; Choi, C.H.; Kang, S.B.; Bang, K.B.; Kim, T.O.; Seo, G.S.; Cha, J.M.; Chun, J.; Jung, Y.; et al. Development of a clinical and genetic prediction model for early intestinal resection in patients with Crohn’s disease: Results from the IMPACT Study. J. Clin. Med. 2021, 10, 633. [Google Scholar] [CrossRef]
- Lipták, P.; Banovcin, P.; Rosoľanka, R.; Prokopič, M.; Kocan, I.; Žiačiková, I.; Uhrik, P.; Grendar, M.; Hyrdel, R. A machine learning approach for identification of gastrointestinal predictors for the risk of COVID-19 related hospitalization. PeerJ 2022, 10, e13124. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT, Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- OpenAI. GPT-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 x 16 words: Transformers for image recognition at scale. arXiv 2010, arXiv:2010.11929. [Google Scholar]
- Sun, Y.; Li, Y.; Wang, P.; He, D.; Wang, Z. Lesion segmentation in gastroscopic images using generative adversarial networks. J. Digit. Imaging 2022, 35, 459–468. [Google Scholar] [CrossRef]
- Rau, A.; Edwards, P.J.E.; Ahmad, O.F.; Riordan, P.; Janatka, M.; Lovat, L.B.; Stoyanov, D. Implicit domain adaptation with conditional generative adversarial networks for depth prediction in endoscopy. Int. J. Comput. Assist. Radiol. Surg. 2019, 14, 1167–1176. [Google Scholar] [CrossRef]
- Almalioglu, Y.; Bengisu, O.K.; Gokce, A.; Incetan, K.; Irem Gokceler, G.; Ali Simsek, M.; Ararat, K.; Chen, R.J.; Durr, N.J.; Mahmood, F.; et al. EndoL2H, Deep super-resolution for capsule endoscopy. IEEE Trans. Med. Imaging 2020, 39, 4297–4309. [Google Scholar] [CrossRef]
- De Souza, L.A., Jr.; Mendel, R.; Ebigbo, A.; Probst, A.; Messmann, H.; Palm, C.; Papa, J.P. Assisting Barrett’s esophagus identification using endoscopic data augmentation based on Generative Adversarial Networks. Comput. Biol. Med. 2020, 126, 104029. [Google Scholar]
- Kumagai, Y.; Takubo, K.; Sato, T.; Ishikawa, H.; Yamamoto, E.; Ishiguro, T.; Hatano, S.; Toyomasu, Y.; Kawada, K.; Matsuyama, T.; et al. AI analysis and modified type classification for endocytoscopic observation of esophageal lesions. Dis. Esophagus 2022, 35, doac010. [Google Scholar] [CrossRef]
- Tang, S.; Yu, X.; Cheang, C.F.; Liang, Y.; Zhao, P.; Yu, H.H.; Choi, I.C. Transformer-based multi-task learning for classification and segmentation of gastrointestinal tract endoscopic images. Comput. Biol. Med. 2023, 157, 106723. [Google Scholar] [CrossRef]
- Lonseko, Z.M.; Du, W.; Adjei, P.E.; Luo, C.; Hu, D.; Gan, T.; Zhu, L.; Rao, N. Semi-supervised segmentation framework for gastrointestinal lesion diagnosis in endoscopic images. J. Pers. Med. 2023, 13, 118. [Google Scholar] [CrossRef]
- Zhou, Y.; Hu, Z.; Xuan, Z.; Wang, Y.; Hu, X. Synchronizing detection and removal of smoke in endoscopic images with cyclic consistency adversarial nets. IEEE/ACM Trans. Comput. Biol. Bioinform. 2022, 21, 670–680. [Google Scholar] [CrossRef]
- Gong, L.; Wang, M.; Shu, L.; He, J.; Qin, B.; Xu, J.; Su, W.; Dong, D.; Hu, H.; Tian, J.; et al. Automatic captioning of early gastric cancer using magnification endoscopy with narrow-band imaging. Gastrointest. Endosc. 2022, 96, 929–942.e6. [Google Scholar] [CrossRef]
- Ali, S.; Zhou, F.; Bailey, A.; Braden, B.; East, J.E.; Lu, X.; Rittscher, J. A deep learning framework for quality assessment and restoration in video endoscopy. Med. Image Anal. 2021, 68, 101900. [Google Scholar] [CrossRef]
- Govind, D.; Jen, K.Y.; Matsukuma, K.; Gao, G.; Olson, K.A.; Gui, D.; Wilding, G.E.; Border, S.P.; Sarder, P. Improving the accuracy of gastrointestinal neuroendocrine tumor grading with deep learning. Sci. Rep. 2020, 10, 11064. [Google Scholar] [CrossRef]
- Shin, K.; Lee, J.S.; Lee, J.Y.; Lee, H.; Kim, J.; Byeon, J.S.; Jung, H.Y.; Kim, D.H.; Kim, N. An image turing test on realistic gastroscopy images generated by using the Progressive Growing of Generative Adversarial Networks. J. Digit. Imaging 2023, 36, 1760–1769. [Google Scholar] [CrossRef]
- Im, J.E.; Yoon, S.A.; Shin, Y.M.; Park, S. Real-time prediction for neonatal endotracheal intubation using multimodal transformer network. IEEE J. Biomed. Health Inform. 2023, 27, 2625–2634. [Google Scholar] [CrossRef]
- Li, J.; Zhang, P.; Wang, T.; Zhu, L.; Liu, R.; Yang, X.; Wang, K.; Shen, D.; Sheng, B. DSMT-Net, Dual self-supervised multi-operator transformation for multi-source endoscopic ultrasound diagnosis. IEEE Trans. Med. Imaging 2023, 43, 64–75. [Google Scholar] [CrossRef]
- Jiang, X.; Ding, Y.; Liu, M.; Wang, Y.; Li, Y.; Wu, Z. BiFTransNet, A unified and simultaneous segmentation network for gastrointestinal images of CT & MRI. Comput. Biol. Med. 2023, 165, 107326. [Google Scholar] [CrossRef]
- Qi, J.; Ruan, G.; Liu, J.; Yang, Y.; Cao, Q.; Wei, Y.; Nian, Y. PHF3 Technique, A pyramid hybrid feature fusion framework for severity classification of ulcerative colitis using endoscopic images. Bioengineering 2022, 9, 632. [Google Scholar] [CrossRef]
- Borji, A. Pros and cons of GAN evaluation measures. Comput. Vis. Image Underst. 2019, 179, 41–65. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Hambly, B.; Xu, R.; Yang, H. Recent advances in reinforcement learning in finance. Math. Financ. 2023, 33, 437–503. [Google Scholar] [CrossRef]
- Yu, C.; Liu, J.; Nemati, S. Reinforcement learning in healthcare: A survey. ACM Comput. Surv. (CSUR) 2021, 55, 1–36. [Google Scholar] [CrossRef]
- Puiutta, E.; Veith, E.M.S.P. Explainable reinforcement learning: A survey. In Proceedings of the International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Dublin, Ireland, 25–28 August 2020. [Google Scholar]
- Zhang, Y.; Bai, L.; Liu, L.; Ren, H.; Meng, M.Q.H. Deep reinforcement learning-based control for stomach coverage scanning of wireless capsule endoscopy. In Proceedings of the 2022 IEEE International Conference on Robotics and Biomimetics (ROBIO), Jinghong, China, 5–9 December 2022. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Wekesa, J.S.; Kimwele, M. A review of multi-omics data integration through deep learning approaches for disease diagnosis, prognosis, and treatment. Front. Genet. 2023, 14, 1199087. [Google Scholar] [CrossRef]
- Enhancing the Quality and Transparency of Health Research Network. Reporting Guidelines. 2024. Available online: https://www.equator-network.org/reporting-guidelines/ten-simple-rules-for-neuroimaging-meta-analysis/ (accessed on 23 November 2024).
- Müller, V.I.; Cieslik, E.C.; Laird, A.R.; Fox, P.T.; Radua, J.; Mataix-Cols, D.; Tench, C.R.; Yarkoni, T.; Nichols, T.E.; Turkeltaub, P.E.; et al. Ten simple rules for neuroimaging meta-analysis. Neurosci. Biobehav. Rev. 2018, 84, 151–161. [Google Scholar] [CrossRef]
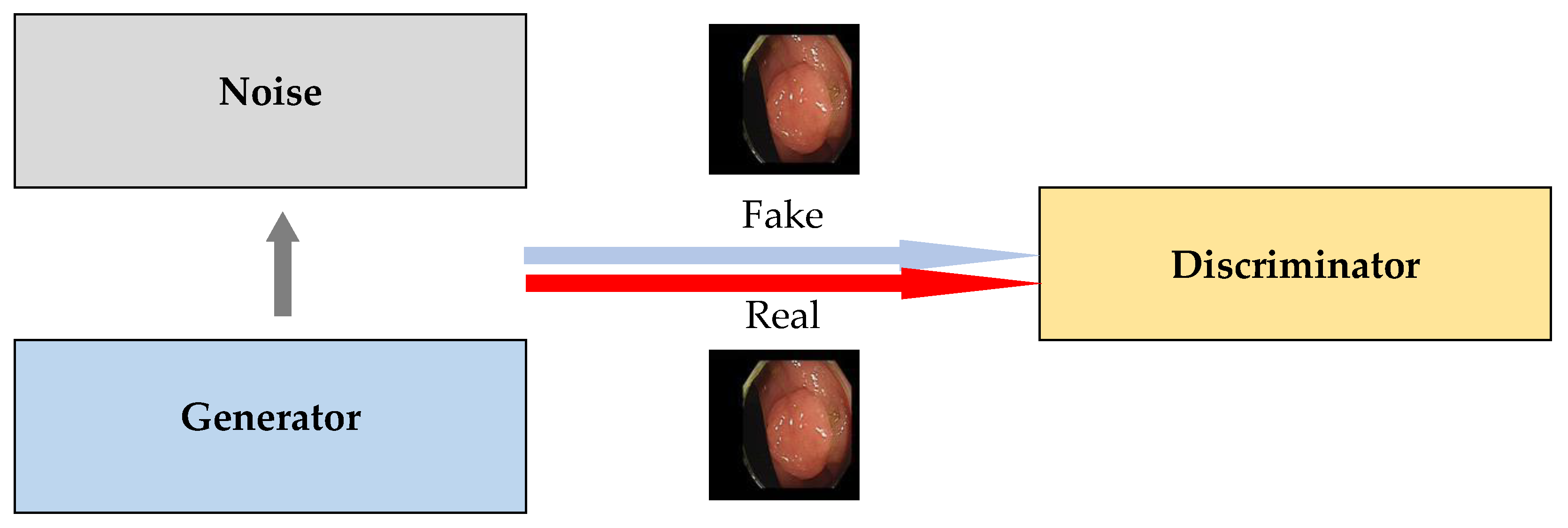

{kind=link}
{kind=link}
| ID | Sample Size | Method | Generative Adversarial Network | Performance | Dependent Variable | ||
|---|---|---|---|---|---|---|---|
| Title | Innovation | Baseline | Innovation | Baseline | |||
| 21 | 630 | Patch | Endoscopist | 91.9 | 83.6 | CL Cancer Gastric | |
| 21 | 630 | Patch | Unet | 86.6 | 77.6 | SE Cancer Gastric | |
| 22 | 16,000 | Conditional | Conditional | 0.175 | 0.236 | AU Cancer Colorectal | |
| 23 | 80,000 | EndoL2H | Conditional & Spatial Attention | Conditional | 83.0 | 69.0 | GE Adenoma Small Intestine |
| 24 | 589 | Deep Convolutional | Alex | 90.0 | 81.0 | AU Adenocarcinoma Esophagus | |
| 27 | 4880 | Semi-Supervised | Supervised | 89.4 | 82.1 | SE GID | |
| 28 | Cycle-Desmoking | Cycle | 91.0 | 81.1 | GE GID | ||
| 30 | 1290 | Cycle-Bi-Direction | Cycle-Uni-Direction | 98.8 | 96.8 | GE GID | |
| 31 | 1508 | Cycle & K-Means | K-Means | 87.1 | 84.8 | CL Cancer Gastrointestinal | |
| 32 | 107,060 | Progressive Growing | Endoscopist | 61.3 | 61.3 | GE GID | |
| Note | |||||||
| Performance | AU Accuracy CL Accuracy DE Intersection-Of-Union GE Structural-Similarity SE Dice | ||||||
| Root Mean Squared Error | |||||||
| Accuracy | |||||||
| ID | Sample Size | Method | Transformer | Performance | Dependent Variable | ||
|---|---|---|---|---|---|---|---|
| Title | Innovation | Baseline | Innovation | Baseline | |||
| 25 | 7983 | Vision | Pathologist | 91.2 | 91.2 | CL Esophageal Disease | |
| 26 | 1645 | TransMT-Net | Vision | Alex | 96.9 | 95.7 | CL GID |
| 26 | 1645 | TransMT-Net | Vision | Unet | 77.8 | 65.2 | SE GID |
| 29 | 1886 | EGCCap | Multi-Modal | Endoscopist Only | 79.5 | 74.9 | DE Cancer Gastric |
| 33 | 219 | Multi-Modal | Numeric | 85.7 | 64.8 | CL NICU-NEI | |
| 34 | 11,500 | DSMT-Net | Vision Self-Supervised | Vision | 89.2 | 79.1 | CL Cancer Breast-Pancreatic |
| 35 | 41,987 | BiFTransNet | Multi-Modal | Unet | 89.5 | 88.3 | SE Cancer Gastrointestinal |
| 36 | 15120 | PHF3 | Vision | Resnet-100 | 88.9 | 86.5 | CL Ulcerative Colitis |
| Note | |||||||
| Performance | AU Accuracy CL Accuracy DE Intersection-Of-Union GE Structural-Similarity SE Dice | ||||||
| Root Mean Squared Error | |||||||
| Accuracy | |||||||
| Measure | Description | Discriminable | Overfitting | Sensitive |
|---|---|---|---|---|
| 01 Average Likelihood | Average likelihood of model distribution given generated sample data | Low | Low | Low |
| 02 Coverage Metric | Probability mass of generated sample data covered by model distribution | Low | Low | Low |
| 03 Inception Score (IS) | Quality and overall diversity of generated sample data | High | Middle | Middle |
| 04 Modified IS | Quality and within-class diversity of generated sample data | High | Middle | Middle |
| 05 Mode Score | IS with the consideration of prior label distribution over sample data | High | Middle | Middle |
| 06 AM Score | IS with the consideration of training vs. test label distribution over sample data | High | Middle | Middle |
| 07 FID | Gaussian distance between generated sample data and real data distributions | High | Middle | High |
| 08 MMD | Discrepancy between model distributions given generated sample data | High | Low | - |
| 09 Wasserstein Critic | Wasserstein distance between generated sample data and real data distributions | High | Middle | - |
| 10 BPT | Support size of a discrete distribution | Low | High | Low |
| 11 C2ST | Classifier whether two sample data are drawn from the same distribution | High | Low | - |
| 12 Classification | Classifier how well extracted features predict class labels | High | Low | - |
| 13 Boundary Distortion | Classifier how much diversity loss boundary distortion causes | Low | Low | |
| 14 NSDB | Number of statistical different bins denoting the diversity of generated sample data | Low | High | Low |
| 15 Image Retrieval | Quality for the nearest neighbors of generated sample data in the test set retrieved | Middle | Low | - |
| 16 GAM | Likelihood ratio of two models with generators or discriminators being switched | High | Low | - |
| 17 Tournament Win | Tournament win rates of competing models | High | High | - |
| 18 NRDS | Number of training epochs needed to distinguish generated sample data from real data | High | Low | - |
| 19 AAAD | Accuracies of two classifiers on generated sample data and real data | High | Low | - |
| 20 Geometry Score | Geometric properties of generated samples data vs. real data | Low | Low | Low |
| 21 Reconstruction Error | Reconstruction error between generated sample data and real data | Low | Low | Middle |
| 22 Structural Similarity | Similarity in terms of luminance, contrast and structure | Low | Middle | High |
| 23 LLIS | Similarity in terms of four low-level image statistics such as mean power spectrum | Low | Low | Low |
| 24 F1 Score | F1 scores of two classifiers on generated sample data and real data | Low | High | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, K.-S.; Kim, E.S. Generative Artificial Intelligence in the Early Diagnosis of Gastrointestinal Disease. Appl. Sci. 2024, 14, 11219. https://doi.org/10.3390/app142311219
Lee K-S, Kim ES. Generative Artificial Intelligence in the Early Diagnosis of Gastrointestinal Disease. Applied Sciences. 2024; 14(23):11219. https://doi.org/10.3390/app142311219
Chicago/Turabian StyleLee, Kwang-Sig, and Eun Sun Kim. 2024. "Generative Artificial Intelligence in the Early Diagnosis of Gastrointestinal Disease" Applied Sciences 14, no. 23: 11219. https://doi.org/10.3390/app142311219
APA StyleLee, K.-S., & Kim, E. S. (2024). Generative Artificial Intelligence in the Early Diagnosis of Gastrointestinal Disease. Applied Sciences, 14(23), 11219. https://doi.org/10.3390/app142311219