

Joint Object Detection and Multi-Object Tracking Based on Hypergraph Matching



Abstract
1. Introduction
- We introduce a feature extraction and detection module to initially achieve object localization and description of detection results.
- We design a deep feature aggregation module that extracts temporal information from historical tracklet information, aggregates features from object detection and feature extraction, enhances the consistency area between the current frame features and tracklet features, and avoids the impact of identity swapping and tracklet breaks caused by object detection loss or distortion.
- We construct a data association module based on the hypergraph neural network, integrating with object detection and feature extraction into a unified network. This integration transforms the data association problem into a hypergraph matching problem between the tracklet hypergraph and the detection hypergraph, thereby achieving end-to-end model optimization.
- The hypergraph framework demonstrates highly competitive performance on three MOT datasets, confirming its effectiveness in enhancing the accuracy of change detection.
2. Related Works
2.1. Detection-Based-Embedding
2.2. Joint Detection and Embedding
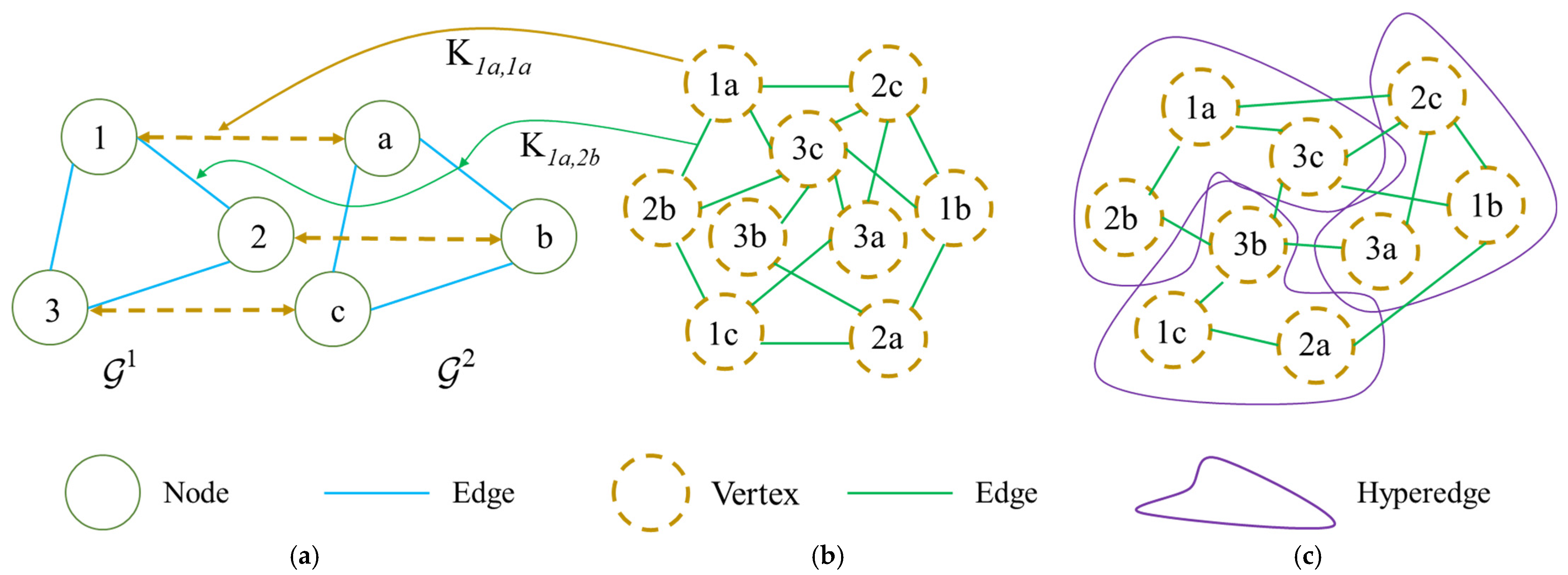
3. Preliminaries of Hypergraph Matching
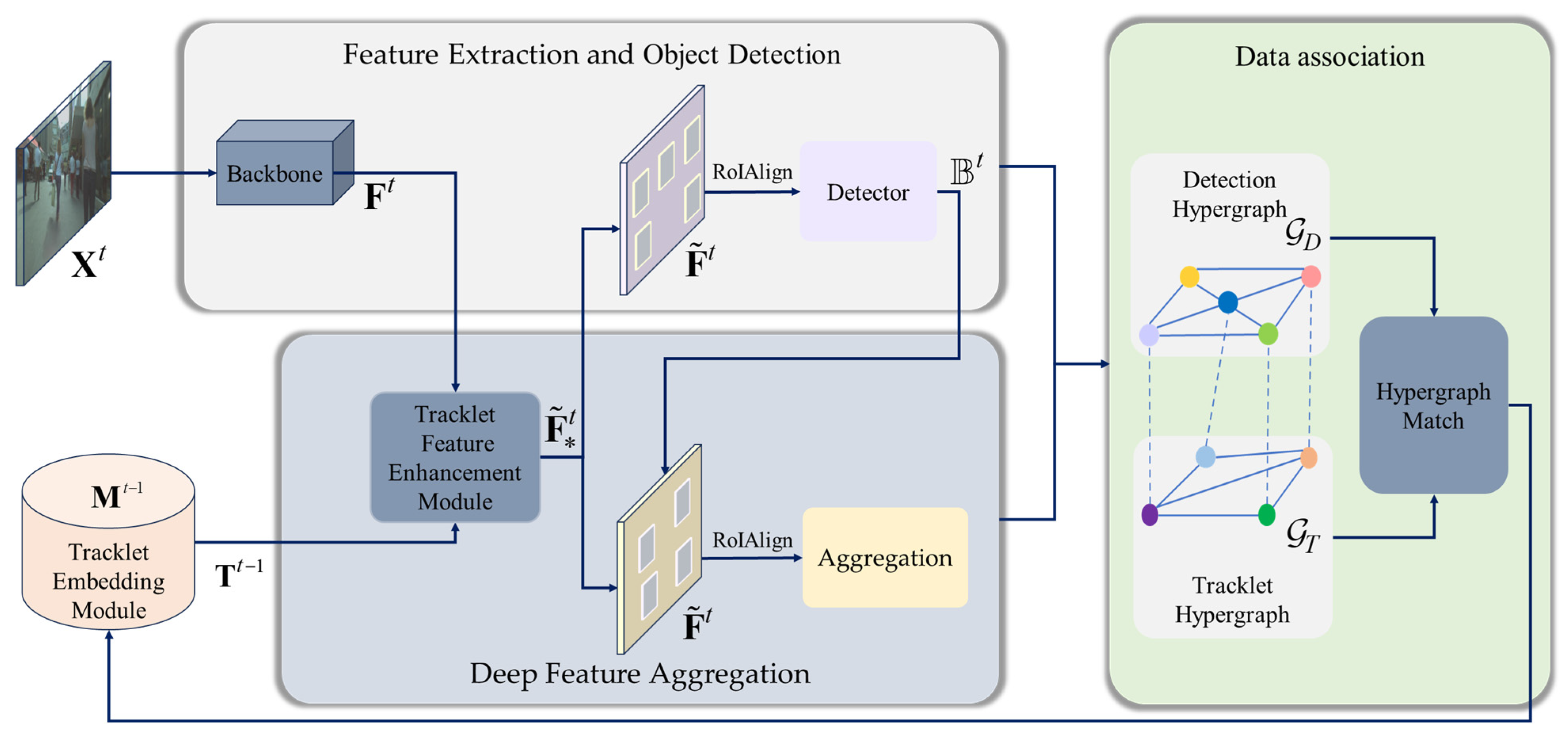
4. Methodology
4.1. Feature Extraction and Object Detection
4.2. Deep Feature Aggregation
4.3. Data Association
5. Experiments
5.1. Datasets and Evaluation Metrics
5.2. Benchmark Evaluation
5.3. Ablation Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bae, S.H.; Yoon, K.J. Confidence-Based Data Association and Discriminative Deep Appearance Learning for Robust Online Multi-Object Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 595–610. [Google Scholar] [CrossRef] [PubMed]
- Bergmann, P.; Meinhardt, T.; Leal-Taixe, L. Tracking without bells and whistles. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 941–951. [Google Scholar]
- He, J.; Huang, Z.; Wang, N.; Zhang, Z. Learnable Graph Matching: Incorporating Graph Partitioning with Deep Feature Learning for Multiple Object Tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 5295–5305. [Google Scholar]
- Ristani, E.; Tomasi, C.J. Features for Multi-target, Multi-camera Tracking and Re-identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6036–6046. [Google Scholar]
- Saleh, F.; Aliakbarian, S.; Rezatofighi, H.; Salzmann, M.; Gould, S. Probabilistic tracklet scoring and inpainting for multiple object tracking. In Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 14329–14339. [Google Scholar]
- Brasó, G.; Leal-Taixé, L. Learning a Neural Solver for Multiple Object Tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6246–6256. [Google Scholar]
- Tang, S.; Andriluka, M.; Andres, B.; Schiele, B. Multiple People Tracking by Lifted Multicut and Person Re-identification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3701–3710. [Google Scholar]
- Leal-Taixé, L.; Ferrer, C.C.; Schindler, K. Learning by tracking: Siamese CNN for robust target association. In Proceedings of the 2016 IEEE Conference on Computer Vision & Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 418–425. [Google Scholar]
- Lu, Z.; Rathod, V.; Votel, R.; Huang, J. Retinatrack: Online single stage joint detection and tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 14656–14666. [Google Scholar]
- Wang, Z.; Zheng, L.; Liu, Y.; Li, Y.; Wang, S. Towards real-time multi-object tracking. In Proceedings of the ECCV 2020, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 107–122. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. Fairmot: On the fairness of detection and re-identification in multiple object tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Liang, C.; Zhang, Z.; Zhou, X.; Li, B.; Lu, Y.; Hu, W. One more check: Making “fake background” be tracked again. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 22 February–1 March 2021. [Google Scholar]
- Voigtlaender, P.; Krause, M.; Osep, A.; Luiten, J.; Sekar, B.B.G.; Geiger, A.; Leibe, B. Mots: Multi-object tracking and segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7934–7943. [Google Scholar]
- Guo, S.; Wang, J.; Wang, X.; Tao, D. Online multiple object tracking with cross-task synergy. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8132–8141. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple Online and Realtime Tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Zhang, L.; Gray, H.; Ye, X.; Collins, L.; Allinson, N. Automatic individual pig detection and tracking in pig farms. Sensors 2019, 19, 1188. [Google Scholar] [CrossRef]
- Lu, Y.; Lu, C.; Tang, C.K. Online Video Object Detection Using Association LSTM. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2363–2371. [Google Scholar]
- Girshick, R.J.C.S. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Red Hook: New York, NY, USA; pp. 379–387. [Google Scholar]
- Wei, L.; Dragomir, A.; Dumitru, E.; Christian, S.; Scott, R.; Cheng-Yang, F.; Berg, A.C.J.S. SSD: Single Shot MultiBox Detector. In Proceedings of the ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 14–17 March 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. Bytetrack: Multi-object tracking by associating every detection box. In Proceedings of the ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 1–21. [Google Scholar]
- Cao, J.; Weng, X.; Khirodkar, R.; Pang, J.; Kitani, K. Observation-Centric SORT: Rethinking SORT for Robust Multi-Object Tracking. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2022; pp. 9686–9696. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple Online and Realtime Tracking with a Deep Association Metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dai, P.; Weng, R.; Choi, W.; Zhang, C.; He, Z.; Ding, W. Learning a Proposal Classifier for Multiple Object Tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2443–2452. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–14. [Google Scholar]
- Xu, Y.; Ban, Y.; Alameda-Pineda, X.; Horaud, R. DeepMOT: How to train your deep multi-object tracker. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6787–6796. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Shan, C.; Wei, C.; Deng, B.; Huang, J.; Hua, X.S.; Cheng, X.; Liang, K. Tracklets Predicting Based Adaptive Graph Tracking. arXiv 2020, arXiv:2010.09015. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, Q.; Sun, H.; Xue, D. HRTracker: Multi-Object Tracking in Satellite Video Enhanced by High-Resolution Feature Fusion and an Adaptive Data Association. Remote Sens. 2024, 16, 3347. [Google Scholar] [CrossRef]
- Li, J.; Piao, Y. Multi-Object Tracking Based on Re-Identification Enhancement and Associated Correction. Appl. Sci. 2023, 13, 9528. [Google Scholar] [CrossRef]
- Kim, J.S.; Chang, D.S.; Choi, Y.S. Enhancement of Multi-Target Tracking Performance via Image Restoration and Face Embedding in Dynamic Environments. Appl. Sci. 2021, 11, 649. [Google Scholar] [CrossRef]
- Zhao, H.; Shen, Y.; Wang, Z.; Zhang, Q. MFACNet: A Multi-Frame Feature Aggregating and Inter-Feature Correlation Framework for Multi-Object Tracking in Satellite Videos. Appl. Sci. 2024, 16, 1604. [Google Scholar] [CrossRef]
- Chen, T.; Pennisi, A.; Li, Z.; Zhang, Y.; Sahli, H. A Hierarchical Association Framework for Multi-Object Tracking in Airborne Videos. Remote Sens. 2018, 10, 1347. [Google Scholar] [CrossRef]
- Wen, J.; Gucma, M.; Li, M.; Mou, J. Multi-Object Detection for Inland Ship Situation Awareness Based on Few-Shot Learning. Remote Sens. 2023, 13, 10282. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A.J. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krhenbühl, P. Objects as Points. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 474–490. [Google Scholar]
- Yu, F.; Wang, D.; Shelhamer, E.; Darrell, T. Deep Layer Aggregation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE Computer Society: Washington, WA, USA, 2018; pp. 2403–2412. [Google Scholar]
- Yang, J.; Ge, H.; Yang, J.; Tong, Y.; Su, S. Online multi-object tracking using multi-function integration and tracking simulation training. Appl. Intell. 2022, 52, 1268–1288. [Google Scholar] [CrossRef]
- Li, J.; Ding, Y.; Wei, H. SimpleTrack: Rethinking and Improving the JDE Approach for Multi-Object Tracking. Sensors 2022, 22, 5863. [Google Scholar] [CrossRef]
- Wang, Y.; Weng, X.; Kitani, K. Joint Detection and Multi-Object Tracking with Graph Neural Networks. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2020; pp. 13708–13715. [Google Scholar]
- Krhenbühl, P.; Koltun, V.; Zhou, X. Tracking Objects as Points. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Xu, Y.; Ban, Y.; Delorme, G.; Gan, C.; Rus, D.; Alameda-Pineda, X. TransCenter: Transformers with Dense Queries for Multiple-Object Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 7820–7835. [Google Scholar] [CrossRef]
- Zhu, J.; Yang, H.; Liu, N.; Kim, M.; Zhang, W.; Yang, M.H. Online Multi-Object Tracking with Dual Matching Attention Networks. In Proceedings of the ECCV 2018, Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018; pp. 379–396. [Google Scholar]
- Zheng, L.; Tang, M.; Chen, Y.; Zhu, G.; Wang, J.; Lu, H. Improving Multiple Object Tracking with Single Object Tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2453–2462. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Meinhardt, T.; Kirillov, A.; Leal-Taixe, L.; Feichtenhofer, C. TrackFormer: Multi-Object Tracking with Transformers. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2021; pp. 8834–8844. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the ECCV 2020, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Wang, R.; Yan, J.; Yang, X. Neural Graph Matching Network: Learning Lawler’s Quadratic Assignment Problem with Extension to Hypergraph and Multiple-Graph Matching. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 5261–5279. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Dendorfer, P.; Rezatofighi, H.; Milan, A.; Shi, J.; Cremers, D.; Reid, I.; Roth, S.; Schindler, K.; Leal-Taixe, L. CVPR19 Tracking and Detection Challenge: How crowded can it get? arXiv 2019, arXiv:1906.04567. [Google Scholar] [CrossRef]
- Dendorfer, P.; Rezatofighi, H.; Milan, A.; Shi, J.; Cremers, D.; Reid, I.; Roth, S.; Schindler, K.; Leal-Taixé, L. MOT20: A benchmark for multi object tracking in crowded scenes. arXiv 2020, arXiv:2003.09003. [Google Scholar] [CrossRef]
- Milan, A.; Leal-Taixe, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A Benchmark for Multi-Object Tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar] [CrossRef]
- Keni, B.; Rainer, S.J. Evaluating multiple object tracking performance: The CLEAR MOT metrics. EURASIP J. Image Video Process. 2008, 2008, 246309. [Google Scholar]
- Luiten, J.; Ošep, A.; Dendorfer, P.; Torr, P.; Geiger, A.; Leal-Taixé, L.; Leibe, B. HOTA: A Higher Order Metric for Evaluating Multi-object Tracking. Int. J. Comput. Vis. 2021, 129, 548–578. [Google Scholar] [CrossRef] [PubMed]
- Ristani, E.; Solera, F.; Zou, R.S.; Cucchiara, R.; Tomasi, C.J.S. Performance measures and a data set for multi-target, multi-camera tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Hornakova, A.; Henschel, R.; Rosenhahn, B.; Swoboda, P. Lifted Disjoint Paths with Application in Multiple Object Tracking. Int. Conf. Mach. Learn. 2020, 119, 4364–4375. [Google Scholar]
- Stadler, D.; Beyerer, J. Improving Multiple Pedestrian Tracking by Track Management and Occlusion Handling. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10953–10962. [Google Scholar]
- You, S.; Yao, H.; Bao, B.K.; Xu, C. UTM: A Unified Multiple Object Tracking Model with Identity-Aware Feature Enhancement. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 21876–21886. [Google Scholar]
- Liang, C.; Zhang, Z.; Lu, Y.; Zhou, X.; Li, B.; Ye, X.; Zou, J. Rethinking the competition between detection and ReID in Multi-Object Tracking. IEEE Trans. Image Process. 2020, 31, 3182–3196. [Google Scholar] [CrossRef] [PubMed]
- Tokmakov, P.; Li, J.; Burgard, W.; Gaidon, A. Learning to Track with Object Permanence. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10840–10849. [Google Scholar]
- Wang, Q.; Zheng, Y.; Pan, P.; Xu, Y. Multiple Object Tracking with Correlation Learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3875–3885. [Google Scholar]
- Yu, E.; Li, Z.; Han, S.; Wang, H. RelationTrack: Relation-aware Multiple Object Tracking with Decoupled Representation. IEEE Trans. Multimed. 2022, 25, 2686–2697. [Google Scholar] [CrossRef]
- Papakis, I.; Sarkar, A.; Karpatne, A. GCNN Match: Graph Convolutional Neural Networks for MOT via Sinkhorn Normalization. arXiv 2020, arXiv:2010.00067. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| Graph/Hypergraph | |
| The set of vertices of | |
| The set of hyperedges of | |
| The number of vertices on . | |
| The number of hyperedges on . | |
| The adjacency matrix , where are the connectivity matrices. | |
| The diagonal matrix of vertex degrees. | |
| The diagonal matrix of hyperedge degrees. |
| Method | MOTA | HOTA | IDF1 | FP | FN | IDS |
|---|---|---|---|---|---|---|
| GMTracker [3] | 61.1 | 51.2 | 66.6 | 3891 | 66,550 | 503 |
| MPNTrack [6] | 58.6 | 48.9 | 61.7 | 4949 | 70,252 | 354 |
| DeepMOT [29] | 54.8 | 42.2 | 53.4 | 2955 | 78,765 | 645 |
| LPC [27] | 58.8 | 51.7 | 67.6 | 6167 | 68,432 | 435 |
| Lif_T [59] | 57.5 | 49.6 | 64.1 | 4249 | 72,868 | 335 |
| TMOH [60] | 63.2 | 50.7 | 63.5 | 3122 | 63,376 | 635 |
| UTM [61] | 63.8 | 53.1 | 67.1 | 8328 | 57,269 | 428 |
| JDTHM | 67.6 | 56.3 | 69.1 | 6137 | 52,686 | 377 |
| Method | MOTA | HOTA | IDF1 | FP | FN | IDS |
|---|---|---|---|---|---|---|
| GMTracker [3] | 59.0 | 51.1 | 65.9 | 20,395 | 209,553 | 1105 |
| MPNTrack [6] | 58.8 | 49.0 | 61.7 | 17,413 | 213,594 | 1185 |
| FairMOT [11] | 73.7 | 59.3 | 72.3 | 27,507 | 117,477 | 3303 |
| LPC [27] | 59.0 | 51.7 | 66.8 | 23,102 | 206,947 | 1122 |
| CTTrack [44] | 61.5 | 48.2 | 59.6 | 14,076 | 200,672 | 2583 |
| TransCenter [45] | 71.9 | 54.1 | 62.3 | 17,378 | 137,008 | 4046 |
| Trackformer [49] | 74.1 | 57.3 | 68.0 | 34,602 | 108,777 | 2829 |
| Lif_T [59] | 60.5 | 51.3 | 65.6 | 14,966 | 206,619 | 1189 |
| CSTrack [62] | 74.9 | 59.3 | 72.3 | 23,847 | 114,303 | 3567 |
| PermaTrack [63] | 73.1 | 54.2 | 67.2 | 24,577 | 123,508 | 3571 |
| JDTHM | 73.9 | 59.6 | 71.7 | 25,639 | 117,756 | 3733 |
| Method | MOTA | HOTA | IDF1 | FP | FN | IDS |
|---|---|---|---|---|---|---|
| FairMOT [11] | 61.8 | 54.6 | 67.3 | 103,440 | 88,901 | 5243 |
| CSTrack [62] | 66.6 | 54.0 | 68.6 | 25,404 | 144,358 | 3196 |
| GSDT [43] | 67.1 | 53.1 | 67.5 | 31,913 | 135,409 | 3133 |
| MPNTrack [6] | 57.6 | 46.8 | 59.1 | 16,953 | 201,384 | 1210 |
| Trackformer [49] | 68.6 | 54.7 | 65.7 | 20,348 | 140,373 | 1532 |
| CorrTracker [64] | 65.2 | 57.2 | 69.1 | 79,429 | 95,855 | 5183 |
| RelationTrack [65] | 67.2 | 56.5 | 70.5 | 61,134 | 104,597 | 4243 |
| GNNMatch [66] | 54.5 | 40.2 | 49.0 | 9522 | 223,611 | 2038 |
| JDTHM | 69.3 | 56.7 | 70.9 | 29,716 | 127,135 | 2288 |
| Baseline | Feature Aggregation | Hypergraph | MOTA | HOTA | IDF1 |
|---|---|---|---|---|---|
| ✓ | - | - | 67.1 | 56.3 | 65.9 |
| ✓ | ✓ | - | 72.3 | 57.1 | 66.2 |
| ✓ | - | ✓ | 71.6 | 57.9 | 69.4 |
| ✓ | ✓ | ✓ | 73.9 | 59.6 | 71.7 |
| Order | MOTA | HOTA | IDF1 |
|---|---|---|---|
| 1 | 64.4 | 53.6 | 65.9 |
| 2 | 66.9 | 54.6 | 68.6 |
| 3 | 69.3 | 56.7 | 70.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, Z.; Dai, Y.; Duan, Y.; Tao, X. Joint Object Detection and Multi-Object Tracking Based on Hypergraph Matching. Appl. Sci. 2024, 14, 11098. https://doi.org/10.3390/app142311098
Cui Z, Dai Y, Duan Y, Tao X. Joint Object Detection and Multi-Object Tracking Based on Hypergraph Matching. Applied Sciences. 2024; 14(23):11098. https://doi.org/10.3390/app142311098
Chicago/Turabian StyleCui, Zhoujuan, Yuqi Dai, Yiping Duan, and Xiaoming Tao. 2024. "Joint Object Detection and Multi-Object Tracking Based on Hypergraph Matching" Applied Sciences 14, no. 23: 11098. https://doi.org/10.3390/app142311098
APA StyleCui, Z., Dai, Y., Duan, Y., & Tao, X. (2024). Joint Object Detection and Multi-Object Tracking Based on Hypergraph Matching. Applied Sciences, 14(23), 11098. https://doi.org/10.3390/app142311098