However, statistics such as the mean and variance of pitch, while informative, are rudimentary and may not capture the complex temporal dynamics of emotional speech. Our study advances this understanding by directly modeling dynamic F0 contours using Generalized Additive Mixed Models (GAMMs) for the classification of eight basic emotions in the RAVDESS corpus.
One of the key advantages of using GAMMs in our study is the direct modeling of dynamic F0 contours. Unlike traditional methods that might rely on summary statistics, GAMMs allow us to capture the non-linear, temporal patterns in pitch that are critical for differentiating emotions. This approach not only improves classification performance but also enhances interpretability, enabling us to understand which aspects of the pitch contour contribute to recognizing specific emotions.
4.2. Discrepancies with Previous Literature
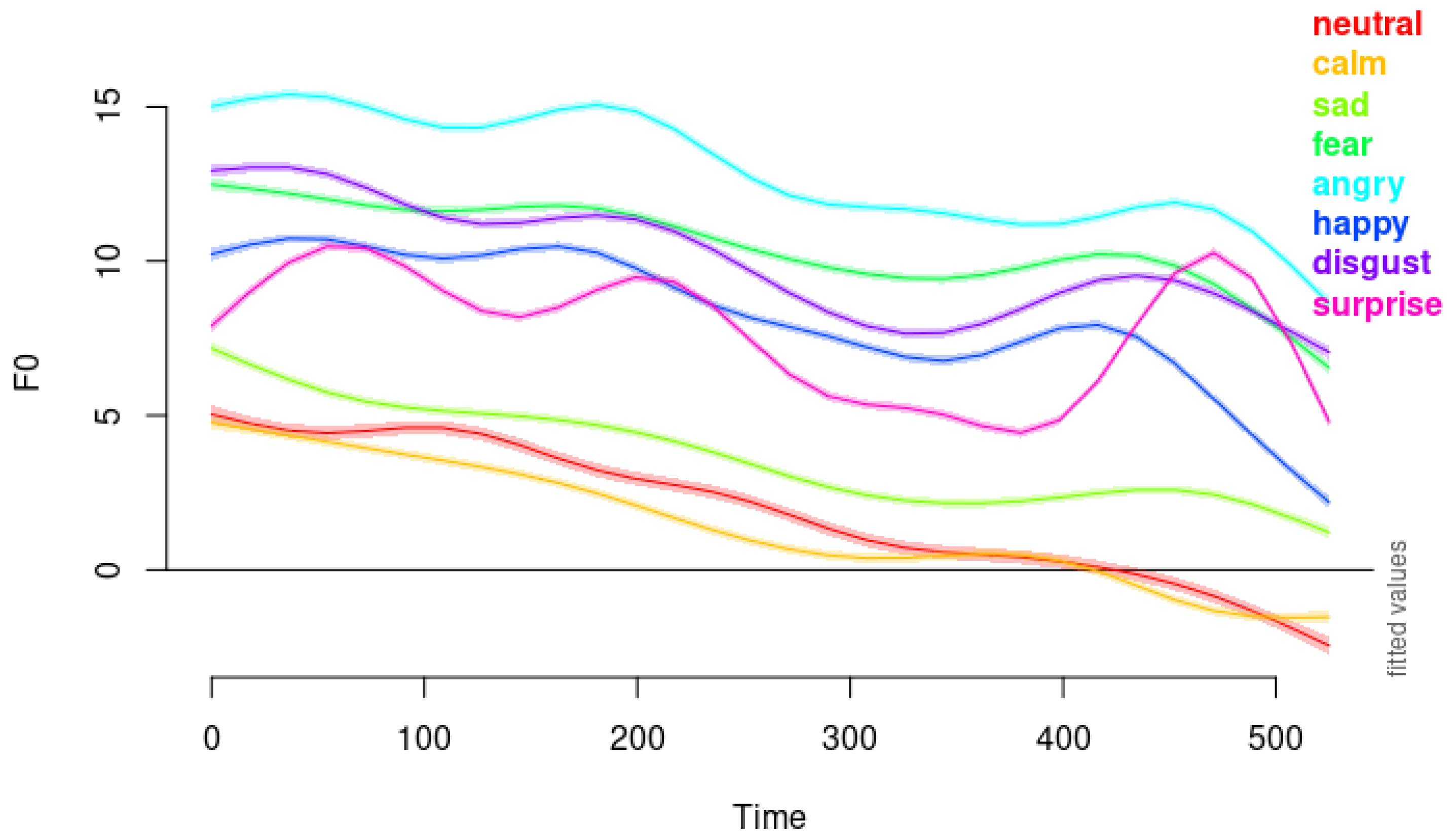
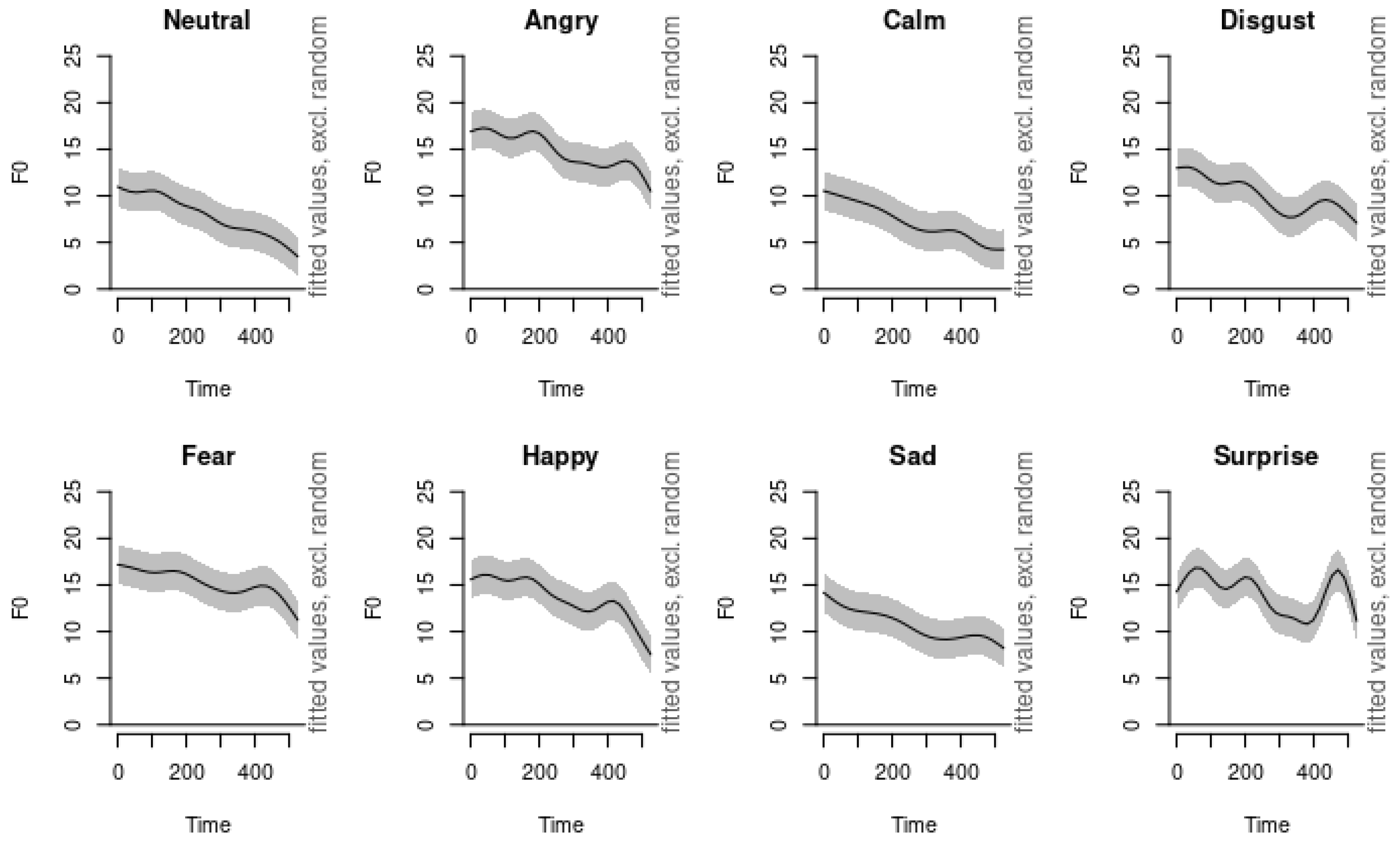
In our analysis, as illustrated in
Figure 5 and
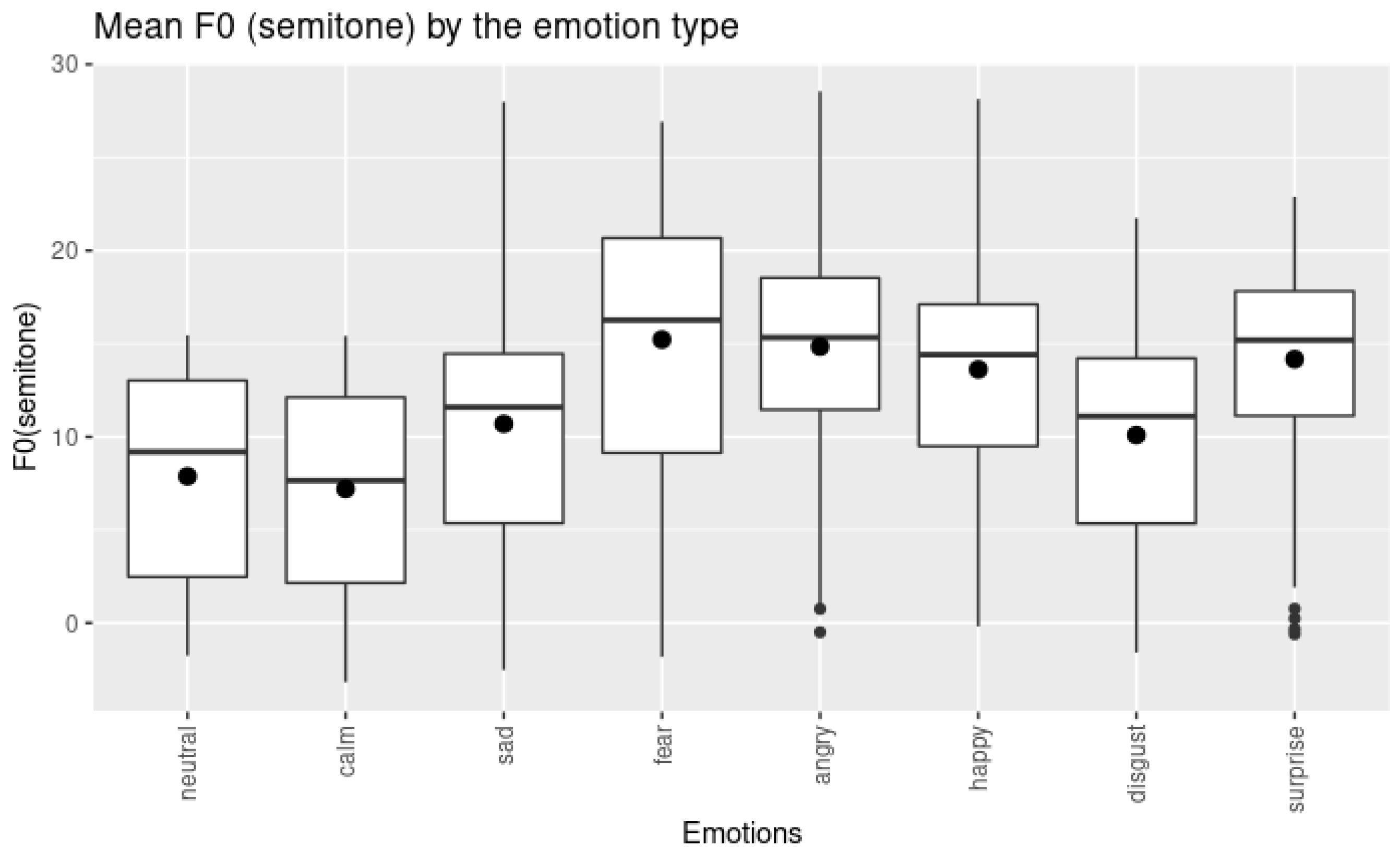
Figure 6, we observed that anger, disgust, and fear all exhibit downward pitch contours at elevated pitch levels. Emotions such as sadness, calm, and neutral are characterized by downward pitch contours at subdued pitch levels. Notably, sadness occurs at a slightly higher pitch level than calm and neutral, which might reflect a difference in emotional arousal. The similarity between the pitch contours of calm and neutral suggests that these two emotions may be challenging to distinguish for listeners, potentially leading to misclassification. This difficulty underscores the importance of nuanced acoustic analysis in emotion recognition systems.
Among these emotions, anger starts at a higher pitch level than both disgust and fear, aligning partially with [
8]’s findings regarding anger’s high pitch. While disgust also shows a downward contour similar to anger, it displays more fluctuation in the pitch contour compared to fear.
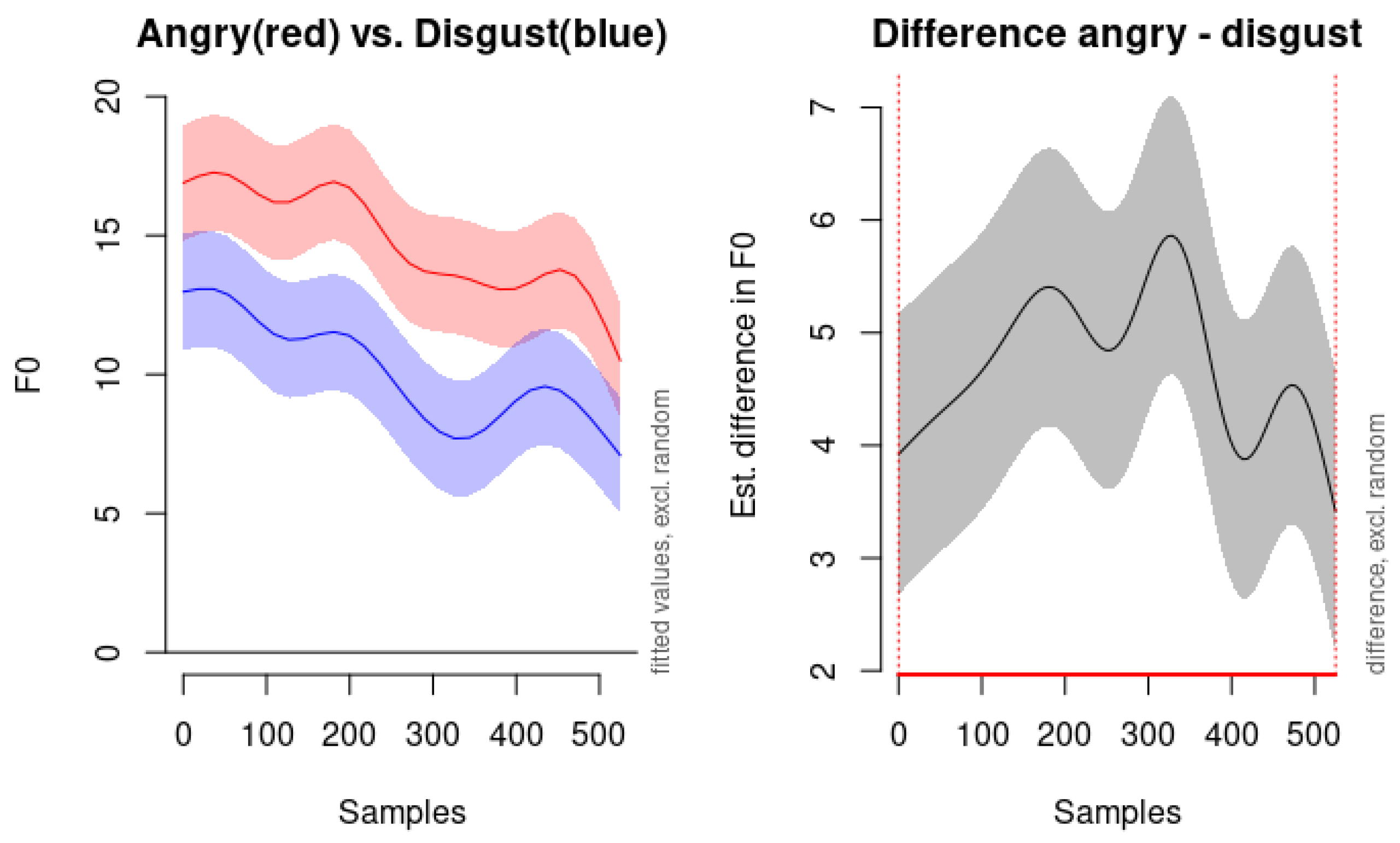
To further examine the nuances between anger and disgust, we present the modeled F0 contours for these emotions in
Figure 7. As depicted in the left panel of
Figure 7, both emotions demonstrate very similar shapes in their dynamic F0 movements, indicating a shared downward trajectory in pitch over time. However, the anger emotion (red line) consistently exhibits higher pitch levels compared to disgust (blue line) throughout the utterance.
The right panel of
Figure 7 illustrates the estimated difference in the F0 between the angry and disgust conditions, along with the confidence interval of the difference. This visual comparison highlights that while the dynamic patterns of pitch movement are similar for both emotions, the overall pitch level serves as a distinguishing feature. The elevated pitch levels associated with anger support the notion of increased arousal and intensity in this emotion, which is reflected acoustically.
Interestingly, disgust in our data does not conform to the low mean pitch reported previously. In [
8], disgust is expressed with a low mean pitch, a low intensity level, and a slower speech rate than the neutral state does. However, this is not the case in our data. Instead, it displays elevated pitch levels with more fluctuation in the pitch contour compared to fear. This discrepancy suggests that disgust may be expressed differently in the RAVDESS dataset, potentially due to cultural, linguistic, or methodological differences. The expression and perception of emotions can vary across cultures and languages. What is considered a typical acoustic manifestation of an emotion in one culture may differ in another. Or it can be the case that the actors in the RAVDESS dataset may have employed a different vocal strategy to convey disgust, perhaps emphasizing certain prosodic features to make the emotion more discernible. Methodological differences may have led to the differences in the finding; our use of dynamic modeling with GAMMs allows for capturing temporal variations in pitch contours that static measures like mean pitch may overlook.
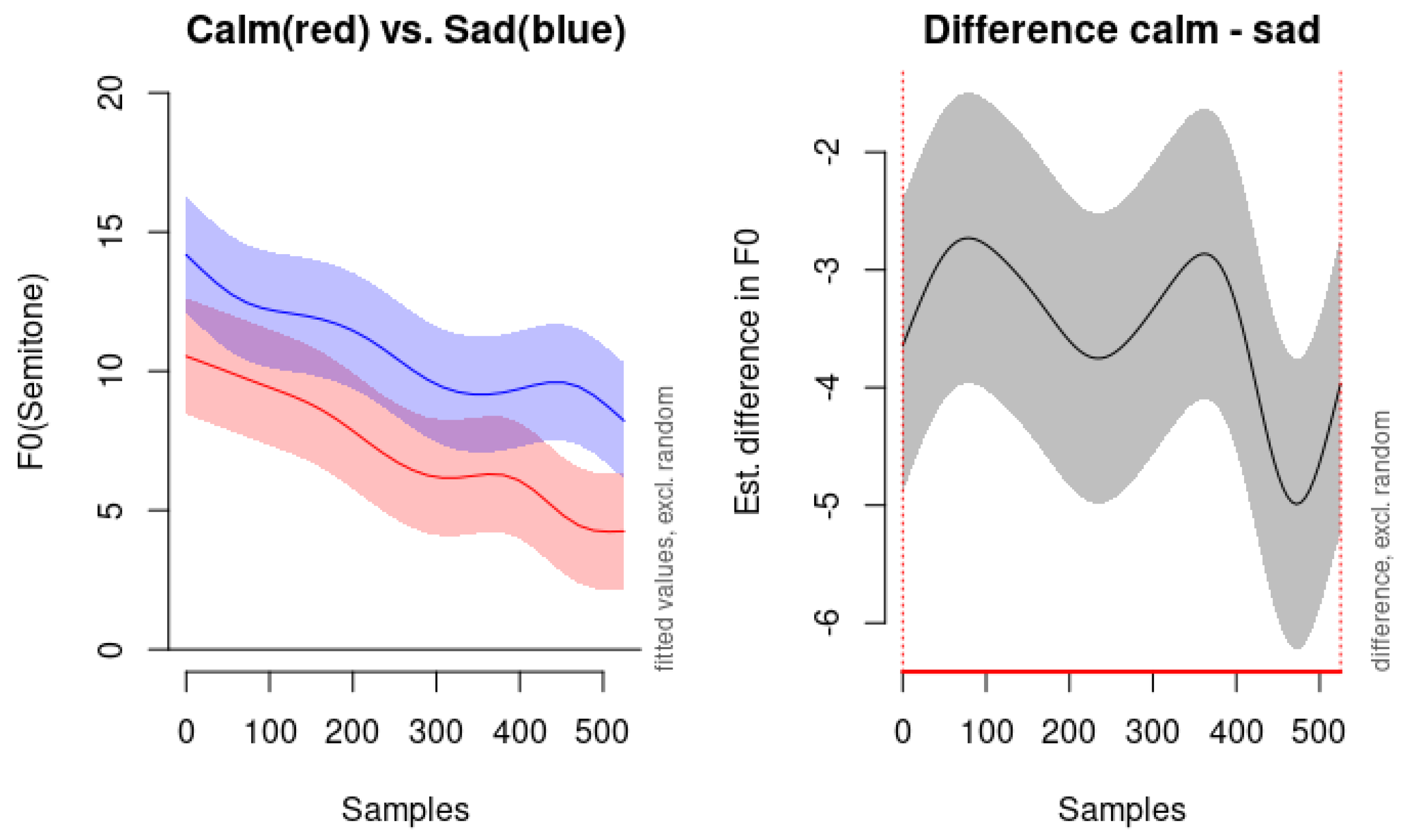
The acoustic properties of calm and sadness emotions are characterized by downward pitch contours at subdued pitch levels, reflecting their low arousal states. This downward trajectory in pitch aligns with previous research indicating that lower pitch and reduced variability are common in less active or more negative emotional states. However, there are notable differences between the two emotions. Sadness consistently exhibits a slightly higher pitch level than calm throughout the utterance. This elevated pitch in sadness may convey a sense of emotional weight or poignancy, distinguishing it from the more neutral or relaxed state of calm. While both emotions are low in arousal, sadness typically carries a negative valence, whereas calm is generally neutral or slightly positive. This difference in emotional valence might be subtly reflected in the acoustic properties, such as the slight elevation in pitch for sadness.
As illustrated in
Figure 8, the left panel displays the fitted pitch contours for calm (red line) and sadness (blue line) over 500 samples. Both contours demonstrate a similar downward trend, but the pitch level for sadness remains consistently higher than that of calm. The shaded areas represent the confidence intervals excluding random effects, showing the reliability of these observations. The right panel of
Figure 8 presents the estimated difference in the F0 between the calm and sad conditions, with the shaded area indicating the confidence interval of the difference. The fact that the confidence interval does not cross zero throughout the entire time window (0 to 525 samples) suggests that the difference in pitch level between calm and sadness is statistically significant across the utterance. These findings highlight the similarities between calm and sadness in terms of pitch contour shape: both exhibit a downward slope indicative of low arousal. However, the differences in the overall pitch level provide an acoustic cue for distinguishing between the two emotions. The higher pitch in sadness may reflect a slight increase in emotional intensity or a different emotional valence compared to calm.
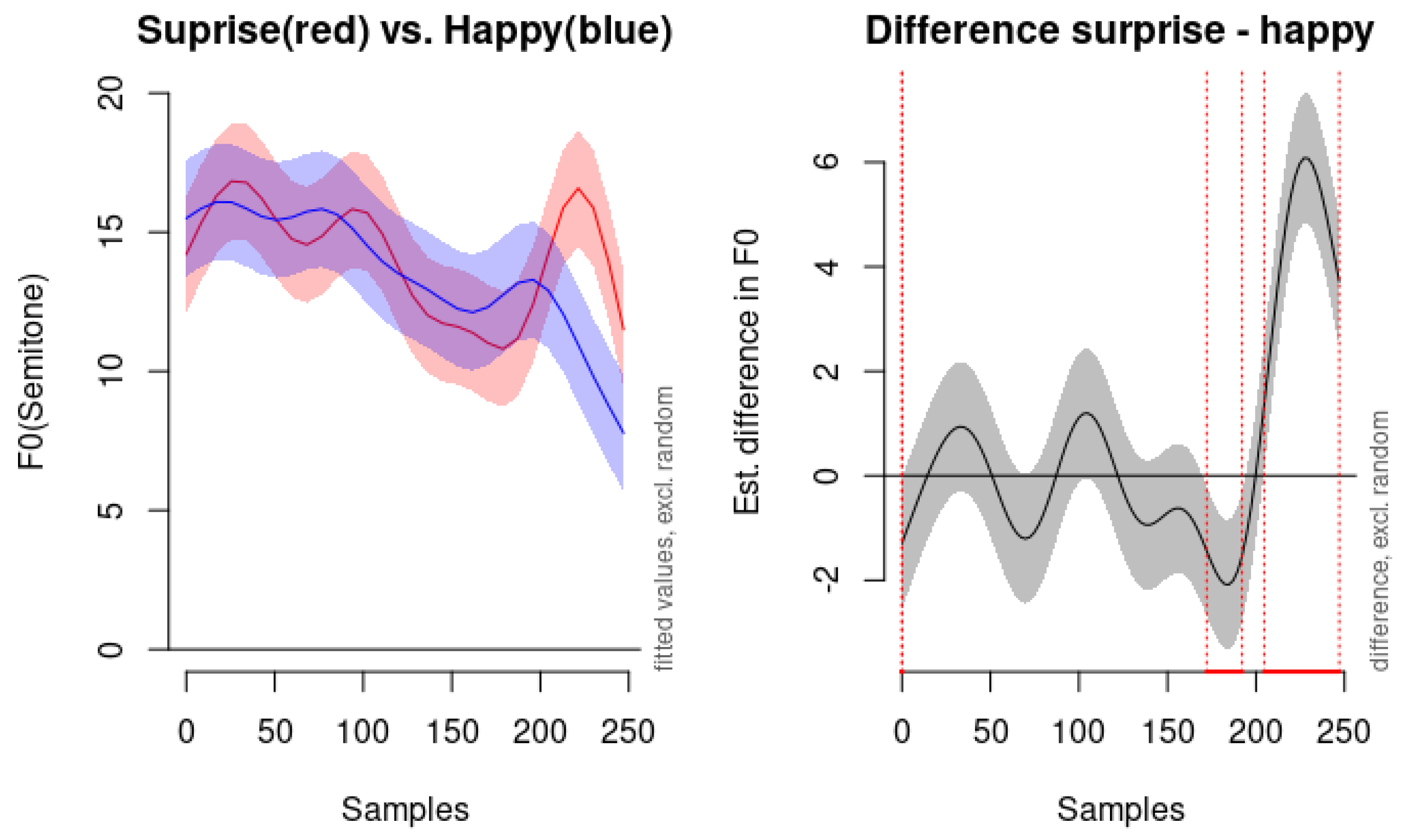
In our study, the pitch contours of happiness and surprise display distinct characteristics that aid in differentiating these emotions acoustically. The pitch contour of happiness begins at a mid-level pitch and exhibits a steeper downward slope compared to other emotions. This pattern aligns with previous research suggesting that happiness involves increased pitch variability and dynamic intonation patterns, reflecting a cheerful and expressive vocal demeanor. In contrast, the pitch contour of surprise is notably distinctive. As illustrated in
Figure 9, surprise shows significant fluctuation throughout the utterance and features an elevated pitch towards the end, surpassing even other high-activation emotions like anger and fear. This elevation in pitch at the conclusion of the utterance may mirror the suddenness and heightened intensity typically associated with surprise. The dynamic rise in pitch could be indicative of an exclamatory expression, which is characteristic of how surprise is often vocally manifested.
The left panel of
Figure 9 demonstrates the fitted pitch contours for both emotions. While both happiness and surprise start at similar pitch levels, their trajectories diverge significantly over time. Happiness maintains a relatively steady pitch before descending sharply, whereas surprise exhibits considerable fluctuation and culminates in a pronounced pitch increase at the end. The right panel of
Figure 9 highlights the estimated difference in the F0 between the two emotions. The areas where the confidence interval does not cross zero indicate time windows where the difference in pitch is statistically significant. These differences suggest that listeners may rely on the distinctive pitch patterns, particularly the end-of-utterance elevation in surprise, to differentiate it from happiness.
Our results emphasize the importance of considering both the shape and level of pitch contours in emotion recognition. The similarities in contour shape indicate that relying solely on the dynamic movement of pitch may not suffice for accurate classification between certain emotions. However, incorporating pitch level differences enhances the discriminative power of the model, enabling better differentiation between closely related emotional expressions like anger and disgust. The unique pitch elevation in surprise, contrasted with the steeper downward slope in happiness, provides acoustic cues that are critical for distinguishing between these two positive high-arousal emotions. This differentiation is crucial, as happiness and surprise can be easily confused due to their shared characteristics of high activation and positive valence.
Our use of Generalized Additive Mixed Models (GAMMs) allows us to capture nuanced acoustic differences among various emotional states. By modeling the dynamic F0 contours, we enhance the interpretability of the emotion classification system, providing insights into how specific acoustic features correspond to different emotions. This approach is particularly valuable for low-arousal emotions like calm and sadness, where acoustic differences are more subtle and require sophisticated modeling techniques to detect.
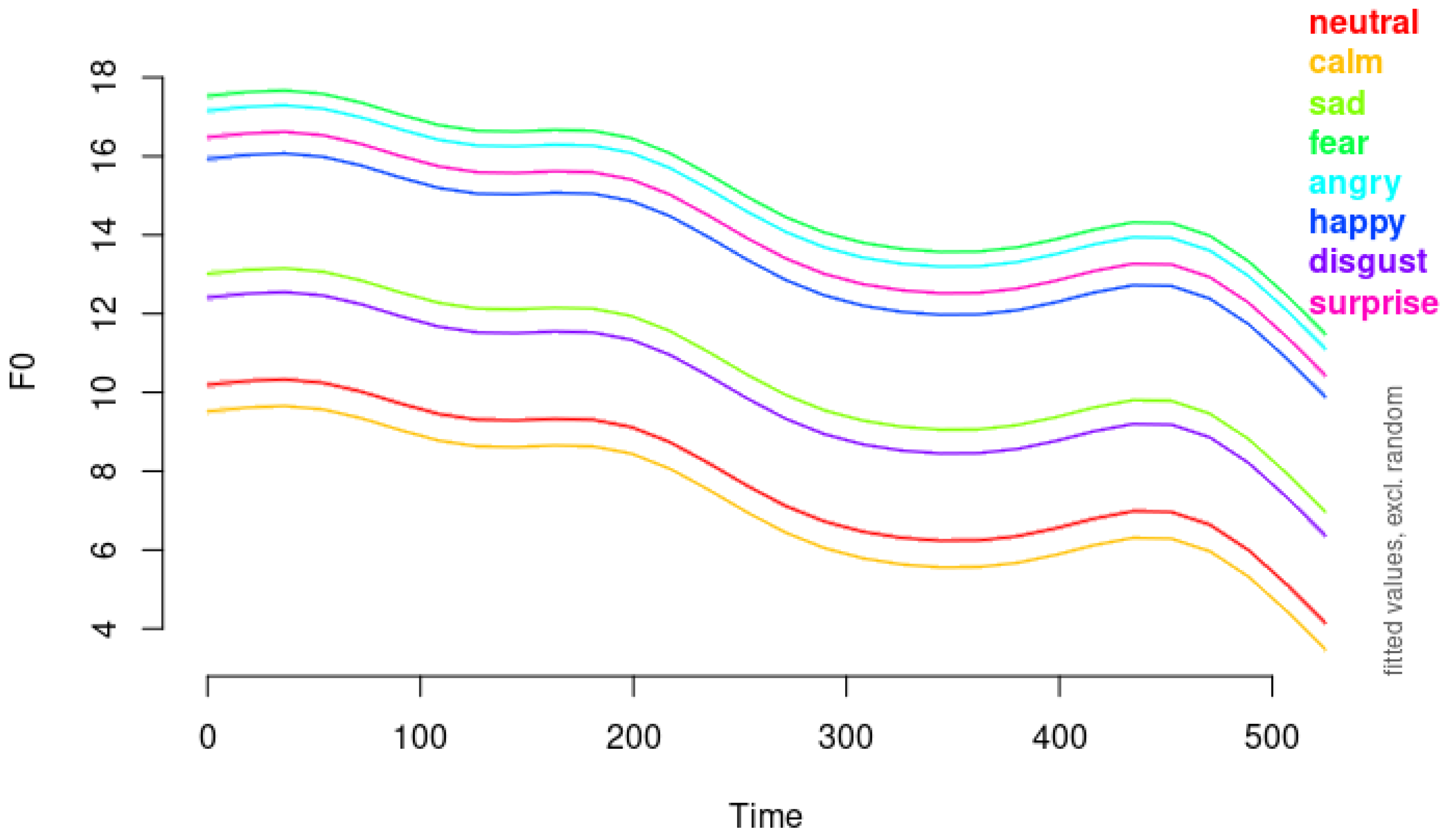
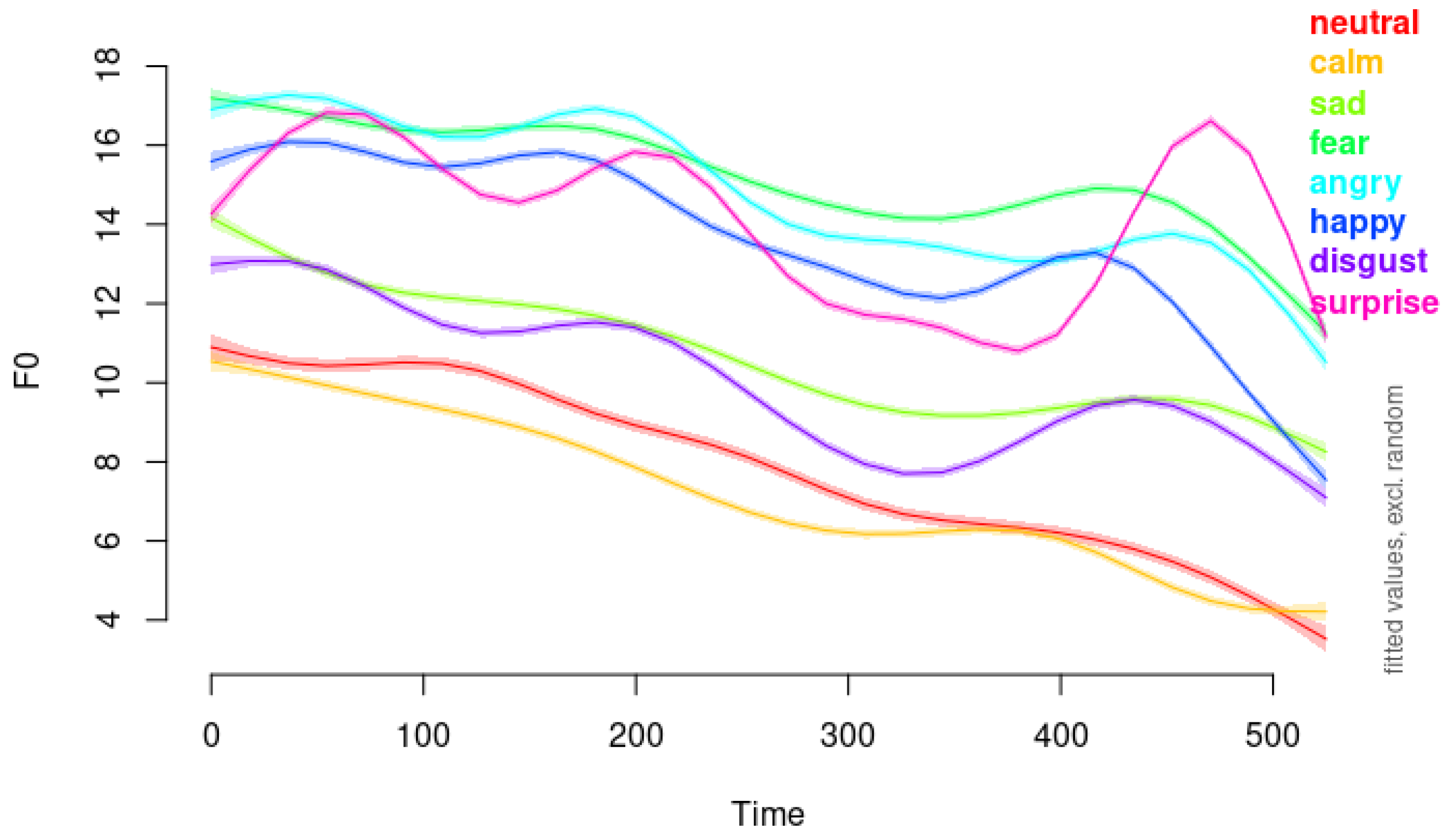
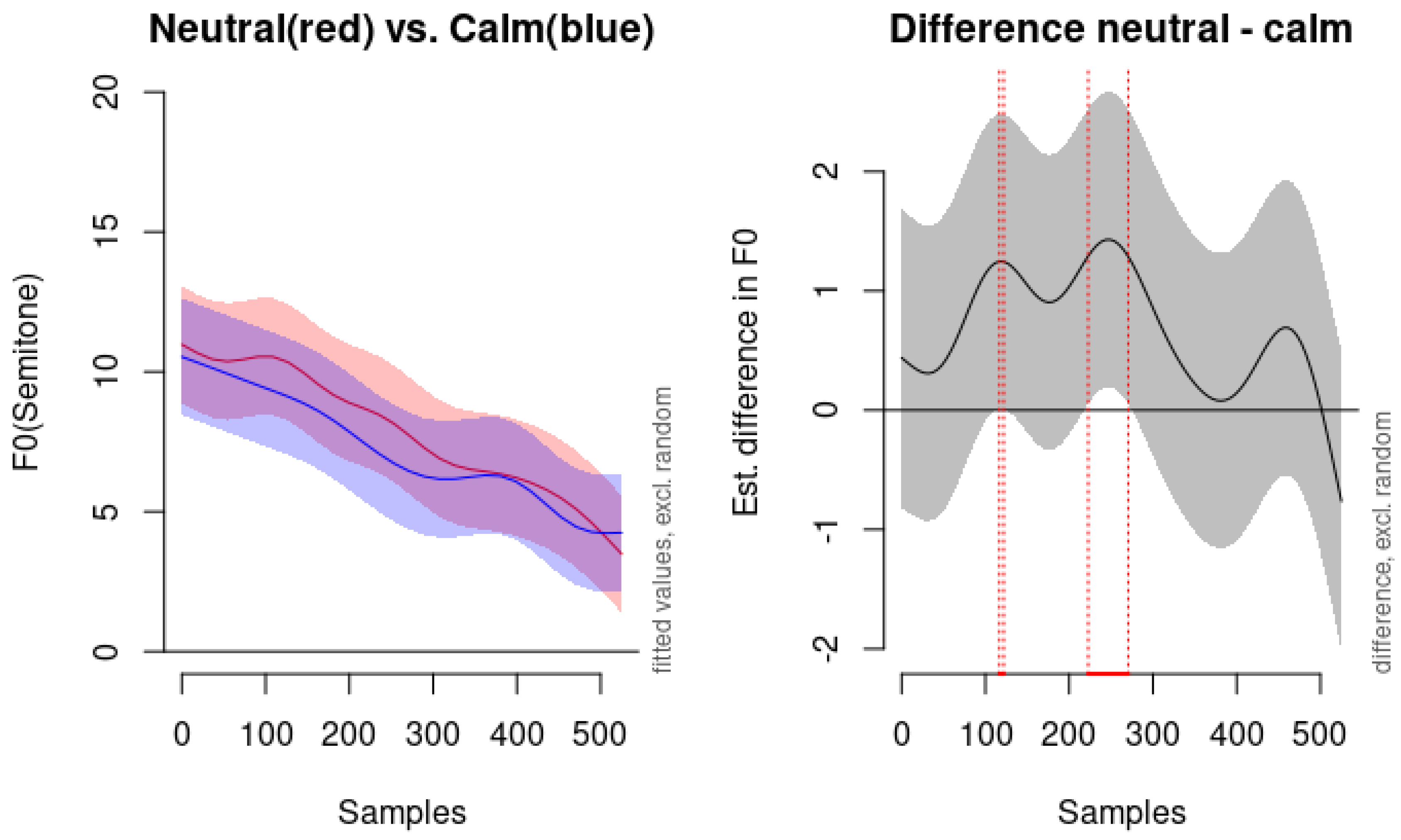
One of the challenges we encountered is the differentiation between neutral and calm emotions. According to our modeling, the neutral emotion is not statistically significantly different from calm emotion. As shown in
Figure 10, which compares the predicted F0 contours for neutral and calm, the pitch contours are remarkably similar. The right panel of
Figure 10 indicates with vertical red dots that the time window of significant difference is found merely between 116.67 and 121.97 milliseconds as well as 222.73 and 270.45 milliseconds: a very brief duration overall. The following observation from [
29] provides context for our findings: The inclusion of both neutral and calm emotions in the RAVDESS dataset acknowledges the challenges that performers and listeners face in distinguishing these states. The minimal acoustic differences captured by our GAMM analysis reflect this perceptual similarity, as noted in [
2] (note that in the quotation, the author’s citation style is replaced with numeric style citation):
“[T]he RAVDESS includes two baseline emotions, neutral and calm. Many studies incorporate a neutral or ‘no emotion’ control condition. However, neutral expressions have produced mixed perceptual results [
1], at times conveying a negative emotional valence. Researchers have suggested that this may be due to uncertainty on the part of the performer as to how neutral should be conveyed [
3]. To compensate for this, a calm baseline condition has been included, which is perceptually like neutral but may be perceived as having a mild positive valence. To our knowledge, the calm expression is not contained in any other set of dynamic conversational expressions” [
29].
Figure 10 illustrates the modeled F0 contours and differences between neutral and calm emotions. The left panel displays the fitted pitch values in semitones over 500 samples, with shaded areas representing the confidence intervals, excluding random effects. The contours for neutral (red line) and calm (blue line) are nearly overlapping, indicating highly similar pitch patterns. The right panel shows the estimated difference in the F0 between the neutral and calm conditions, with the shaded area indicating the confidence interval of the difference. The vertical red dots mark the brief time windows where the difference is statistically significant.
Additionally,
Figure 10 also includes comparisons of the modeled F0 contours for angry and happy emotions (top panel), demonstrating how our method effectively captures and illustrates distinctions between emotions with higher arousal levels. The clear differences in pitch contours and levels between angry and happy support the effectiveness of GAMMs in modeling and interpreting emotional speech across the arousal spectrum.
In conclusion, our use of GAMMs facilitates a deeper understanding of the acoustic properties of emotional speech. By capturing both prominent and subtle differences among emotions, especially in cases where traditional statistical methods might overlook minor yet significant variations, our approach enhances both the interpretability and the accuracy of emotion classification systems.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}