

DQN-Based Shaped Reward Function Mold for UAV Emergency Communication

Abstract
1. Introduction
- Abstract modeling is carried out for typical application scenarios of communication equipment such as UAV, and environmental design is carried out based on Atari platform.
- A more effective action selection strategy is applied to replace the greedy strategy with the traditional DQN algorithm, and its performance is better than before.
- The reward function is redesigned to improve the efficiency and stability of the algorithm, and experimental verification is carried out.
2. Materials and Methods
2.1. Reinforcement Learning
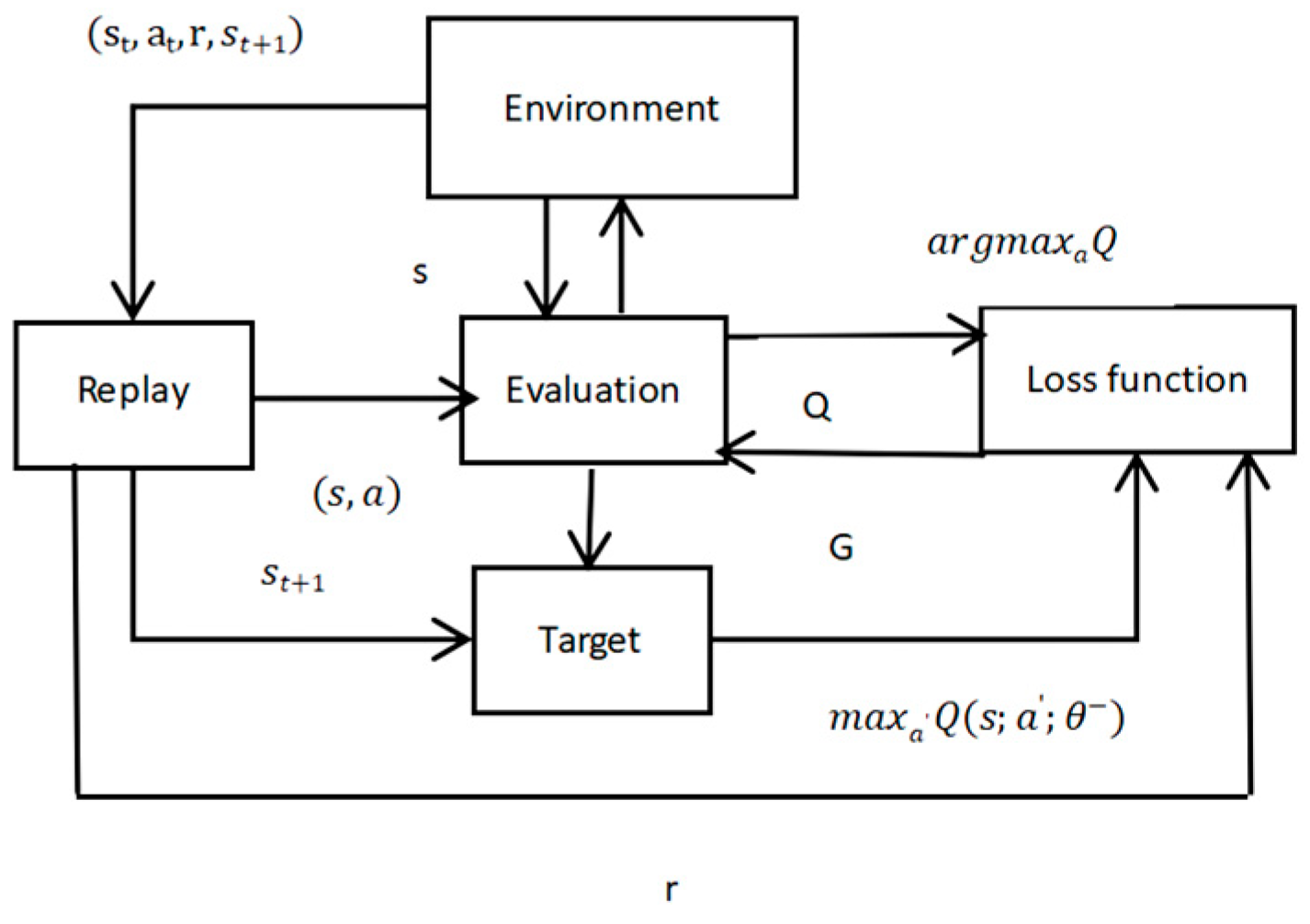
2.2. Deep Q-Learning Network
2.3. System Model
- The paper does not consider attenuation and other factors in the transmission process, simplifying the system model.
- The relay node directly transmits the signal downward after receiving it, and there is no delay in the middle.
- The UAV flies at a constant slow speed and only moves in two-dimensional space.
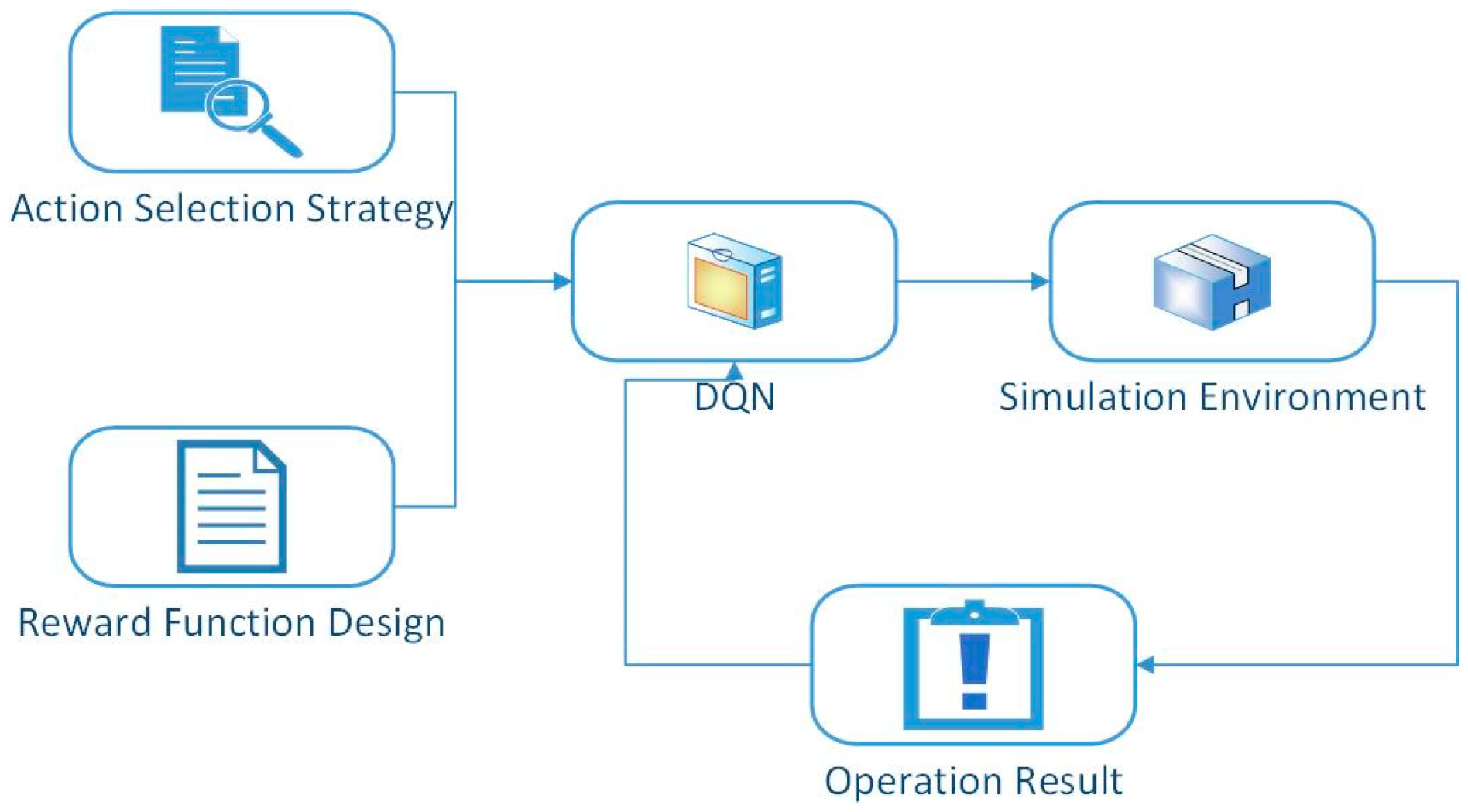
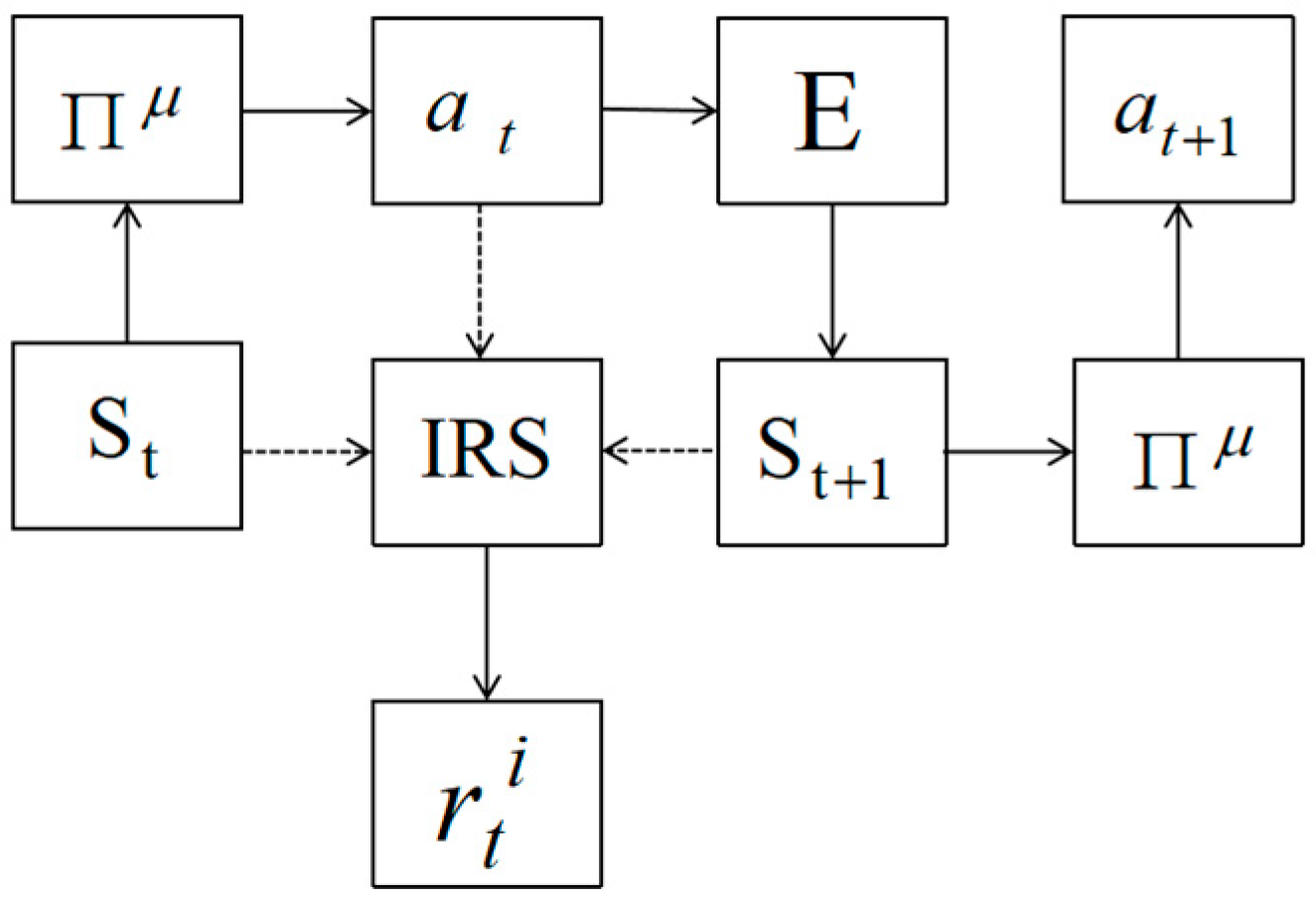
2.4. Proposed Approach
3. Improvement and Experiment
3.1. Improvement of Algorithm
| Algorithm 1 DQN with reward shaping. |
| 1. Initialize replay memory to capacity |
| 2. Initialize action-value function Q with random weights |
| 3. Initialize target action-value function with weights |
| 4. For episode = 1, X do |
| 5. Update the position of UAV |
| 6. For step = 1, M do |
| 7. Select an action with softmax policy |
| 8. Set the reward based on the step |
| 9. Implement and move on to the next state |
| 10. Store transition |
| 11. Gradient descent policy to loss function to improve |
| 12. Every K step reset |
| 13. End for |
| 14. End for |
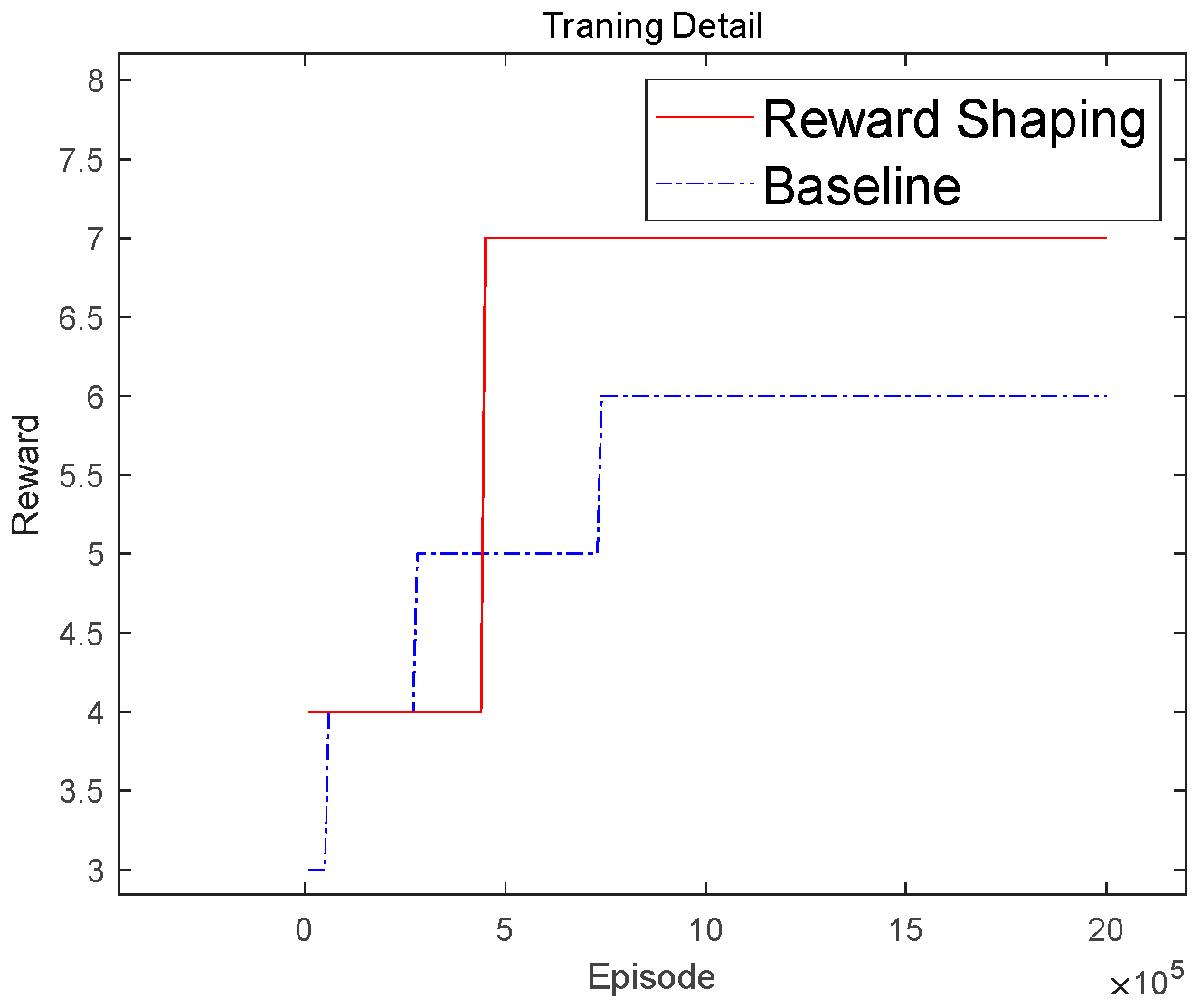
3.2. Experiment
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, L.; Fan, Q.; Ansari, N. 3-D Drone-Base-Station Placement with In-Band Full-Duplex Communications. IEEE Commun. Lett. 2018, 22, 1902–1905. [Google Scholar] [CrossRef]
- Wang, T. Research on UAV Deployment and Path Planning for Emergency Communication; Beijing University of Posts and Telecommunications: Beijing, China, 2022. [Google Scholar]
- Yan, L.; Guo, W.; Xu, D.; Yang, H. A Method for Station Site Planning of Maneuverable Communication Systems Based on NSGA Algorithm. Appl. Res. Comput. 2022, 39, 226–230, 235. [Google Scholar]
- Yin, C.; Yang, R.; Zhu, W.; Zou, X. Emergency communication network planning method based on deep reinforcement learning. Syst. Eng. Electron. 2020, 42, 2091–2097. [Google Scholar]
- Chen, H.; Zhu, W.; Yu, S. Emergency communication network planning method based on deep reinforcement learning. Command. Control. Simul. 2023, 45, 150–156. [Google Scholar]
- Lyu, J.; Zeng, Y.; Zhang, R.; Lim, T.J. Placement Optimization of UAV-Mounted Mobile Base Stations. IEEE Commun. Lett. 2017, 21, 604–607. [Google Scholar] [CrossRef]
- Ng, A.Y.; Harada, D.; Russell, S. Policy invariance under reward transformations: Theory and application to reward shaping. In Proceedings of the International Conference on Machine Learning, Bled, Slovenia, 27–30 June 1999. [Google Scholar]
- Dong, Y. Research and Applicati-on of Reinforcement Learning Based on Reward Shaping; Huazhong University of Science and Technology: Wuhan, China, 2022. [Google Scholar]
- Yu, F.; Hao, J.; Zhang, Z. Action exploration strategy in reinforcement learning based on action probability. J. Comput. Appl. Softw. 2023, 40, 184–189, 226. [Google Scholar]
- Shi, H. Research on DQN Algorithm in Complex Environment; Nanjing University of Information Science and Technology: Nanjing, China, 2023. [Google Scholar]
- Wu, J. Research on Overestimation of Value Function for DQN; Sooc-how University: Taipei, China, 2020. [Google Scholar]
- Yang, W.; Bai, C.; Cai, C.; Zhao, Y.; Liu, P. Sparse rewardproblem in deep reinforcement learning. Comput. Sci. 2020, 47, 182–191. [Google Scholar]
- Liu, H. Research on UAV Communication Trajectory Optimization Based on Deep Reinforcement Learning; Nanchang University: Nanchang, China, 2023. [Google Scholar]
- Li, Q.; Geng, X. Robot path Planning based on improved DQN Algorithm. Comput. Eng. 2023, 12, 111–120. [Google Scholar]
- Yang, D. Research on Reward Strategy Techniques of Deep Reinforcement Learning for Complex Confrontation Scenarios; National University of Defense Technology: Changsha, China, 2020. [Google Scholar]
- Niu, S. Research on Student Motivation Based on Reinforcement Learning; University of Electronic Science and Technology of China: Chengdu, China, 2022. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Number |
|---|---|
| Seed | 25 |
| Entry 2 | data |
| Learning_rate | 0.0001 |
| Grad_clipping_value | 5 |
| Replay_buffer_size | 1,000,000 |
| Batch_size | 32 |
| Gamma | 0.98 |
| Discount factor | 0.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, C.; Zhu, W.; Guo, S.; Bai, J. DQN-Based Shaped Reward Function Mold for UAV Emergency Communication. Appl. Sci. 2024, 14, 10496. https://doi.org/10.3390/app142210496
Ye C, Zhu W, Guo S, Bai J. DQN-Based Shaped Reward Function Mold for UAV Emergency Communication. Applied Sciences. 2024; 14(22):10496. https://doi.org/10.3390/app142210496
Chicago/Turabian StyleYe, Chenhao, Wei Zhu, Shiluo Guo, and Jinyin Bai. 2024. "DQN-Based Shaped Reward Function Mold for UAV Emergency Communication" Applied Sciences 14, no. 22: 10496. https://doi.org/10.3390/app142210496
APA StyleYe, C., Zhu, W., Guo, S., & Bai, J. (2024). DQN-Based Shaped Reward Function Mold for UAV Emergency Communication. Applied Sciences, 14(22), 10496. https://doi.org/10.3390/app142210496