1. Introduction
With the acceleration of urbanization in China and the improvement in safety requirements in public places, the importance of abnormal behavior recognition in dense crowds has become increasingly prominent. At the same time, various large-scale public activities and large-scale crowd gatherings show a continuous growth trend, including various exhibitions, entertainment performances, and sports events. In these scenarios, the flow of people surges, the personnel is highly dense, and the composition is diverse and complex. Once an abnormal event or emergency occurs, it is very easy to cause panic within the crowd, which in turn leads to situations such as rapid movement of the crowd, crowded collisions, and even chaotic pushing and shoving. In this case, the crowd will fall into an unstable state and even serious stampede accidents may occur, causing a tragedy of a large number of casualties [
1].
In the early computer vision tasks, artificial feature descriptors played an important role, especially in the recognition of abnormal behaviors in crowds [
2]. Through artificial feature descriptors, key attributes with discrimination and invariance are extracted from image data to represent the characteristics of pedestrians and the movement state of the crowd. However, when dealing with images with large type differences or processing complex visual scenes (such as complex backgrounds, target occlusion, and drastic changes in illumination), traditional manual feature methods can usually only capture low-level local texture and shape information in the image and cannot maintain stability and effectiveness, resulting in the performance of most abnormal detection methods being restricted by the above factors. Compared with traditional recognition methods, advanced computer vision technologies such as deep learning can automatically extract image features and better model time series data, capture the temporal and spatial characteristics of the dynamic changes in the crowd, and automatically distinguish abnormal and normal behaviors of the crowd in video frames.
In recent years, automatic recognition of abnormal behaviors in crowds based on computer vision has become a research hotspot. The literature [
3] uses the FCM clustering algorithm to group the key points of the trajectory and construct a feature histogram of the cluster group motion pattern, visualizing the motion pattern features in the form of high-dimensional coordinates. The literature [
4] proposes an abnormal crowd behavior detection algorithm, SFCNN-ABD, based on the streamlined flow Convolutional Neural Network. The literature [
5] detects possible group abnormal events, such as panic, pushing, gathering, and other dangerous behaviors by real-time analysis of the characteristics of pedestrian movement, density changes, and interaction behaviors in the surveillance video. The literature [
6] details the video-based human abnormal behavior recognition and detection technology, covering many aspects such as the classification of abnormal behaviors, feature extraction methods, and discrimination methods. The literature [
7] reviews the non-invasive human fall detection system based on deep learning and elaborates on the performance indicators of models such as CNN, Auto-Encoder, LSTM, and MLP in detail. The literature [
8] combs the research progress in the field of abnormal detection of surveillance videos, including many aspects such as abnormal classification, detection methods, feature representation, model construction, and evaluation criteria. The literature [
3,
4,
5,
6,
7,
8] represents the progress of different stages in the field of abnormal behavior recognition of crowds.
It is worth noting that there are three deficiencies in the existing literature research. (1) The analysis of abnormal behaviors in the literature is not comprehensive, and piece of the each literature only focuses on the research results of a specific development stage; (2) The pedestrian abnormal behavior detection technology has not been systematically included, and the key factors such as the characteristics and limitations of various methods have not been compared in detail; (3) For the visual problems that are common in complex scenes, such as dense crowds and severe occlusion between individuals, little of the existing literature has proposed targeted and efficient visual occlusion resolution strategies.
Therefore, given the above deficiencies, this paper conducts a comprehensive and systematic analysis of the automatic recognition technology of abnormal behaviors of crowds in the field of computer vision, so that researchers in this field can better grasp the current situation and development direction of abnormal behavior detection of crowds. The main contributions of this paper are summarized as follows:
(1) Systematic summary. This study summarizes the traditional methods of abnormal behavior detection systematically. Then we deeply explore how to use mathematical models to capture and analyze key characteristics such as the speed, direction, abnormal movement of individuals and the spatial layout, flow of people, flow speed, and direction of the group;
(2) Comprehensive method categorization. Starting from the design concept and focus of the algorithm core, the abnormal behavior detection methods based on deep learning are divided into five categories. In addition, for the scale change and occlusion problems in the crowd, this paper provides a novel dynamic pedestrian centroid model and a visual occlusion resolution strategy;
(3) Technical tools recommendation. We recommend four types of representative software tools and provide an experimental platform and practical tool reference for researchers in related fields;
(4) Character analysis of bench-mark datasets. We analyze four international bench-mark datasets of typical abnormal behaviors of crowds. Then we compare these datasets in detail from multiple perspectives such as scale, annotation, and main uses; and prospect the future development direction of abnormal behavior recognition from five aspects such as multi-modal fusion, multi-source multi-dimensional data fusion, and metaverse evolution model.
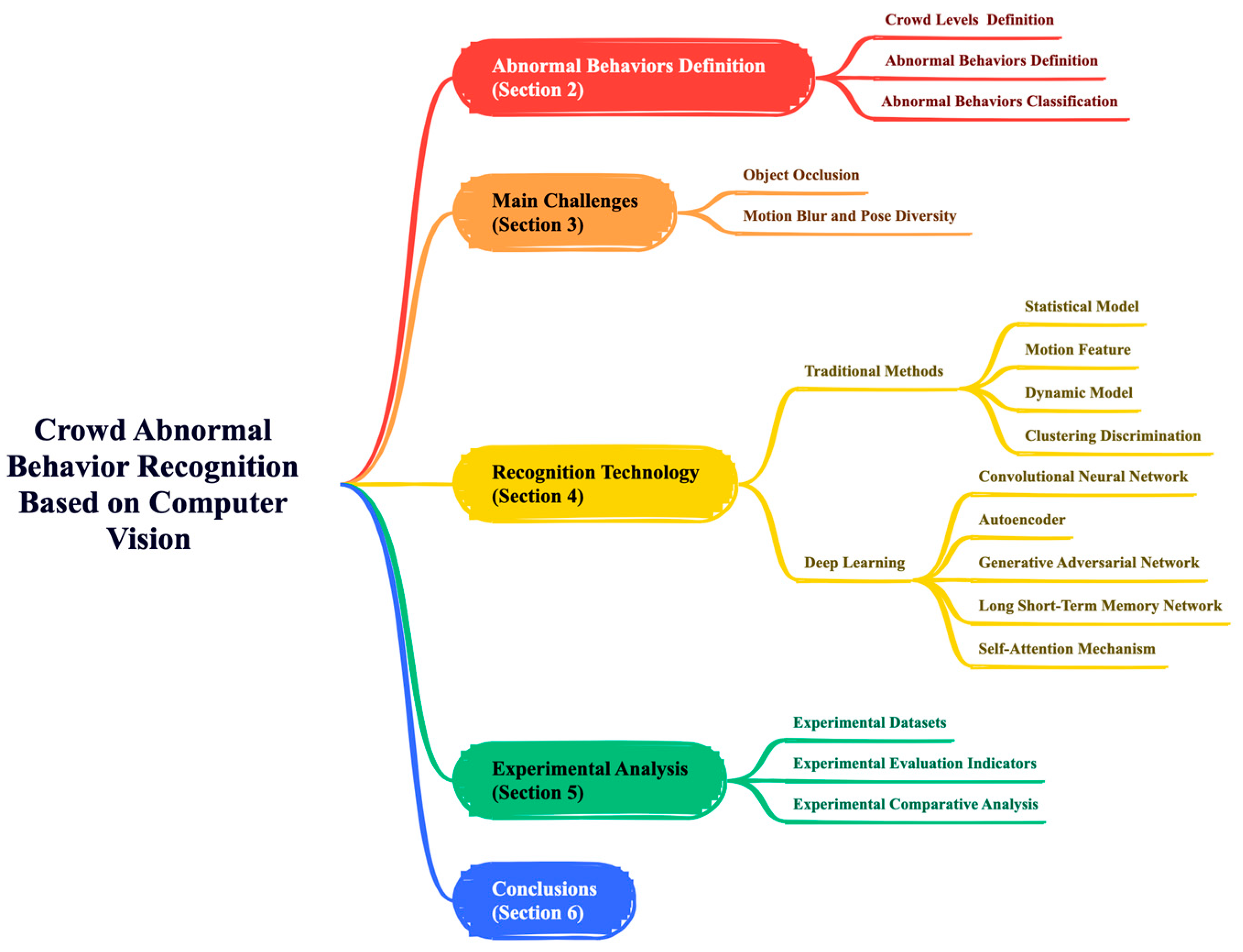
The rest of this paper is structured as follows:
Section 2 gives the definitions of crowd levels and abnormal behaviors;
Section 3 introduces the main challenges faced by the abnormal behavior recognition task in the dense crowd scene;
Section 4 comprehensively summarizes the methods of abnormal behavior recognition from the two dimensions of traditional methods and deep learning and further introduces the current mainstream software tools; and
Section 5 introduces the datasets widely used in the field of abnormal behavior detection at home and abroad and the performance indicators of each algorithm on these datasets.
Section 6 summarizes this paper and presents the future development trend of this research field. The article framework is shown in
Figure 1.
4. Research Status of Abnormal Crowd Behavior Recognition
In recent years, traditional learning methods have accumulated rich research results in the field of abnormal crowd behavior recognition. However, with the increasing complexity of crowd scenes, the recognition performance of traditional methods has certain limitations and it is often difficult to capture the subtle differences and dynamic changes in abnormal behaviors. Against this background, the development of deep learning technology and the method of integrating neural networks for efficient pedestrian abnormal behavior recognition have gradually become research hotspots. Depending on whether neural network elements are included in the model construction, the existing abnormal behavior recognition technologies can be divided into two main classifications [
19]: traditional methods-based and deep learning-based methods. The recognition technologies based on traditional methods can be classified into 4 categories: methods based on statistical models [
20], based on motion features [
21], based on dynamic models [
22], and based on clustering discrimination [
23]. And the deep learning-based methods roughly include 5 categories: methods based on Convolutional Neural Networks (CNNs) [
24], based on autoencoders (AE) [
25], based on generative adversarial networks (GAN) [
26], based on Long Short-Term Memory Networks (LSTM) [
27] and based on the self-attention mechanism (Self-Attention) [
28].
4.1. Traditional Methods
This subsection classifies traditional abnormal behavior recognition methods into the following categories according to the detection principle: abnormal behavior recognition methods based on statistical models, based on motion features, based on dynamic models, and based on clustering discrimination. Most traditional abnormal behavior recognition methods first construct a normal behavior model through visual feature extraction and motion pattern analysis and then perform abnormal behavior recognition by calculating the statistics of features and setting thresholds.
4.1.1. Methods Based on Statistical Models
The core of the method based on statistical models lies in the in-depth analysis of the intrinsic distribution law of data by applying statistical theories and methods to accurately identify behaviors that deviate significantly from the normal behavior pattern. It builds statistical probability models to describe the statistical characteristics of normal behavior features and then uses these models to detect anomalies in the data.
The Gaussian Mixture Model (GMM) [
29] is based on the Gaussian probability density function. By calculating parameters such as the mean and variance of pixel intensity, a model can be established, which can effectively distinguish the foreground and background and then identify the crowd behavior pattern. In high-density crowd scenes, GMM can be used to capture and describe different dynamic characteristics of the crowd, such as density, movement speed, trajectory, etc., thereby identifying abnormal behaviors that do not conform to the normal behavior pattern. The parameter estimation of GMM usually adopts the Expectation Maximization (EM) algorithm, which is an iterative algorithm including the E step (calculating the expected value) and the M step (maximizing the likelihood function) and continuously optimizes to approximate the true distribution of the data. Afig et al. [
30] discussed and summarized four enhanced methods based on GMM, including the basic GMM, the combination of GMM and Markov Random Field (MRF) (GMM-MRF) [
31], the Gaussian–Poisson Mixture Model (GPMM) [
32], and the combination of GMM and a Support Vector Machine (SVM) (GMM-SVM) [
33], pointing out that when dealing with complex crowd scenes, a combination of multiple methods can be used to improve the ability to recognize abnormal behaviors.
4.1.2. Methods Based on Motion Features
The methods based on motion features focus on analyzing the motion features of individuals or groups in the video, such as speed, direction, acceleration, and trajectory, to identify abnormal behaviors.
Among them, the motion behavior of the crowd can be effectively captured by the optical flow that changes continuously over time. Optical flow [
34] is a vector field that describes the motion information of objects in an image sequence, and it reflects the position change in each pixel point in the scene between adjacent frames. In high-density crowd scenes, the optical flow field can reveal the movement direction and speed distribution of individuals or groups, thereby identifying abnormal movements contrary to the normal behavior pattern, such as reverse movement and fast running.
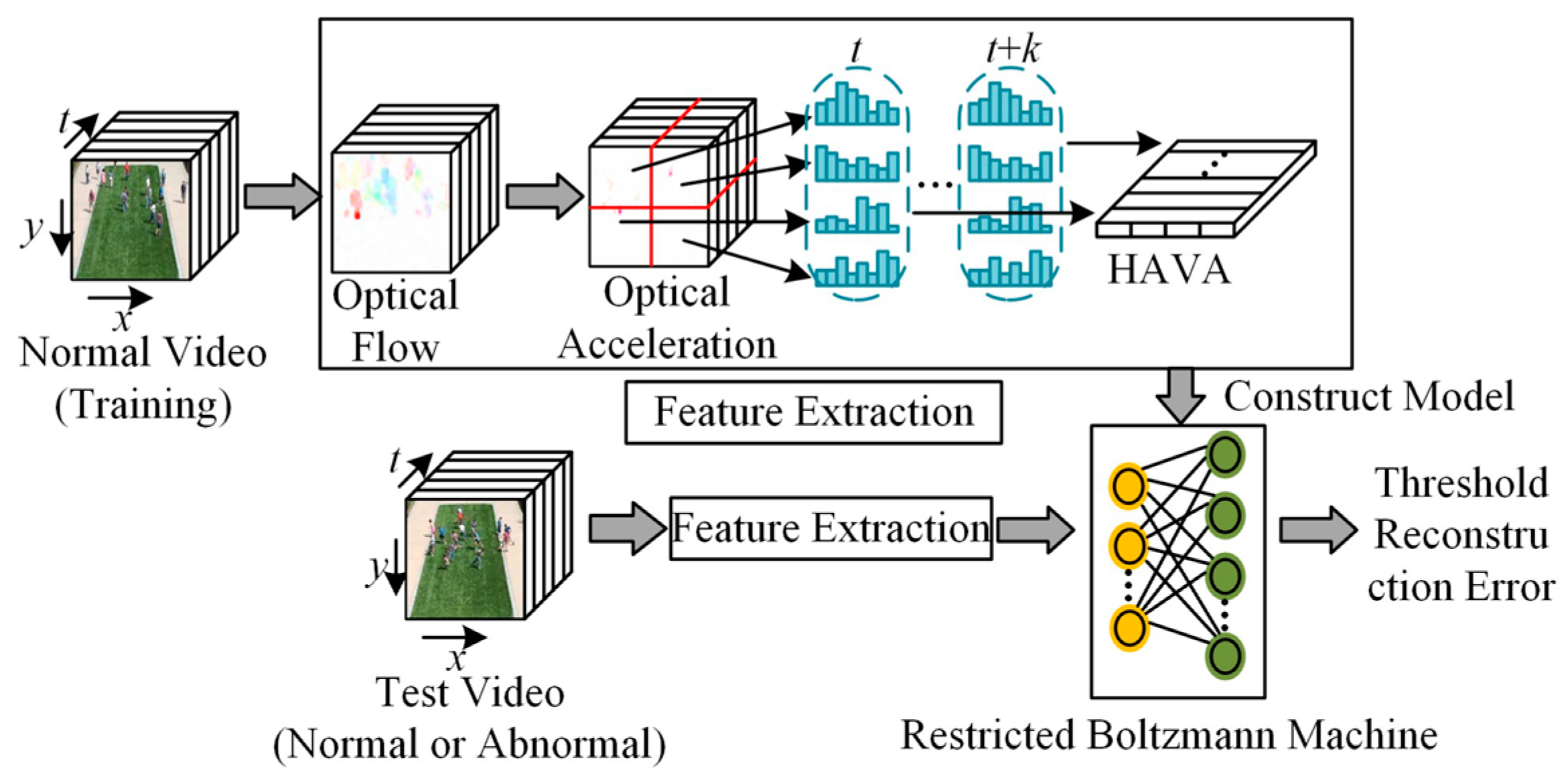
Traditional motion description techniques are mostly based on the velocity information of optical flow, but the acceleration information often contains more abundant motion details. Especially when describing complex motion patterns, it can provide the information missed by the velocity descriptor and help to better understand the motion pattern. Wang et al. [
35] studied an acceleration feature descriptor to improve the accuracy of abnormal behavior detection in videos. The process is shown in
Figure 2. First, the optical flow field information of each frame is extracted from the video. The inter-frame acceleration is calculated through the optical flow information of two consecutive frames. The acceleration histogram feature is constructed to form the acceleration descriptor (HAVA). Using the video training set containing only normal behaviors, the normal motion pattern is learned through the energy-optimized Restricted Boltzmann Machine (RBM) model [
36]. In addition, Jiang et al. [
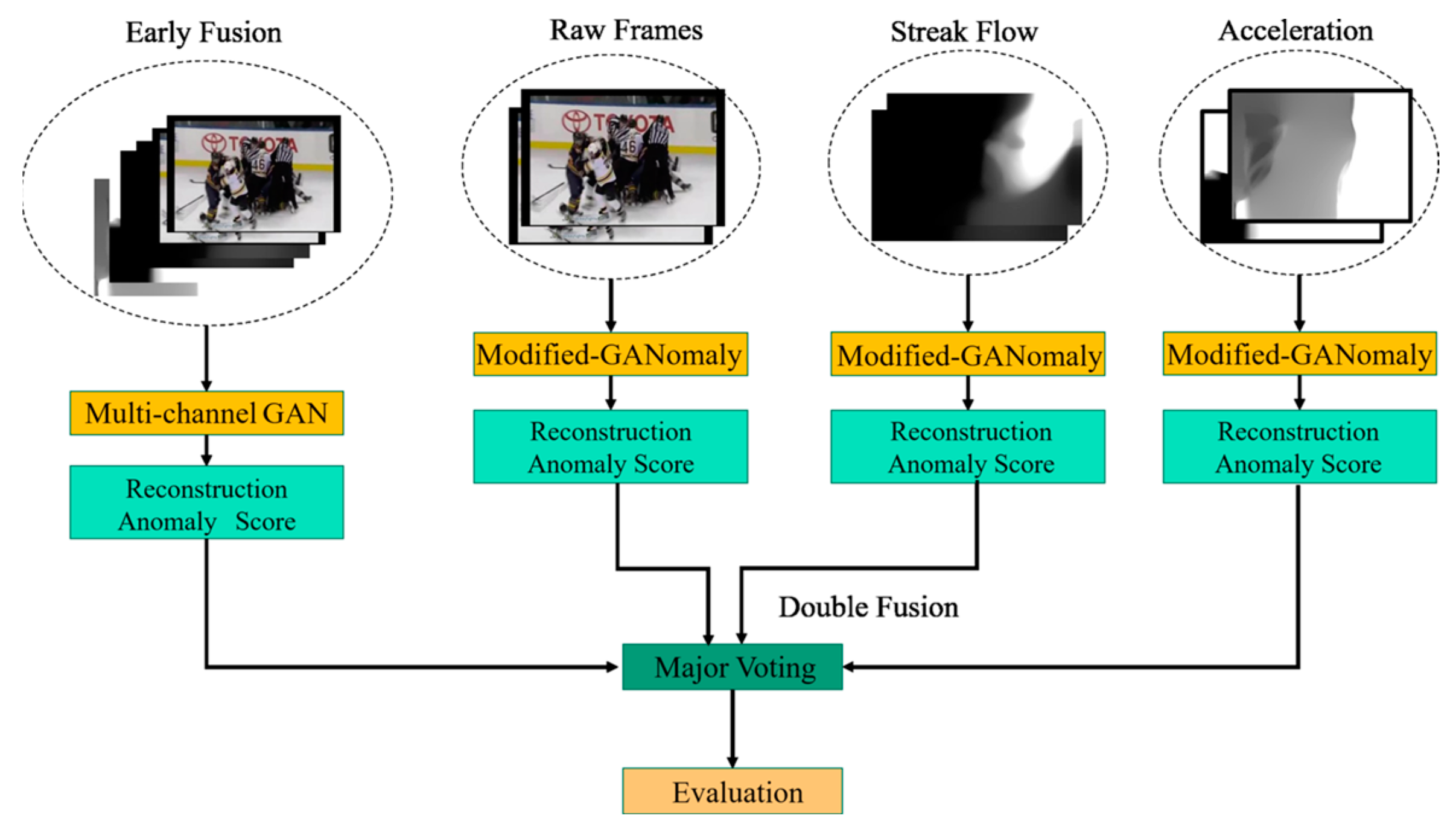
37] proposed a motion descriptor of stripe flow acceleration (SFA), and the process is shown in
Figure 3. Stripe flow is a motion representation method that can effectively capture long-term spatiotemporal changes in crowded scenes. Compared with traditional optical flow, it performs better in terms of accuracy and robustness. By introducing stripe flow acceleration to explicitly model motion information, the spatiotemporal changes in crowded scenes can be accurately represented.
4.1.3. Methods Based on Dynamic Models
Methods based on dynamic models, such as cellular automata models [
38], particle system models [
39], etc., predict the overall movement trend of the crowd by simulating the interaction between individuals and environmental constraints. These models can be used to establish a baseline behavior model for the movement of normal crowds. When the observed behavior significantly deviates from the model prediction, it can be regarded as abnormal. By adjusting model parameters, such as attractive force and repulsive force, it is possible to adapt to the dynamic characteristics of the crowd in different scenarios and improve the accuracy of abnormal behavior recognition.
Chang et al. [
40] proposed a hybrid model of cellular automata and agents, dividing the space into multiple discrete units (cells), with each cell representing an individual or a small part of the crowd in the crowd, and dynamically updating its state according to preset rules to simulate the dynamic behavior of the crowd in normal or emergencies, such as movement, aggregation, evacuation, etc. They also combined it with the Agent model to further refine individual behaviors, considering individual differences such as gender, age, physical conditions, and psychological factors such as panic and conformity on evacuation behaviors. This model can identify which individual behaviors deviate from the norm, that is, abnormal behaviors.
4.1.4. Methods Based on Clustering Discrimination
Abnormal behavior recognition technology based on clustering is an unsupervised learning method. The core idea is to group behavior data into several clusters, most of which represent normal behavior patterns, and behaviors deviating from these clusters are regarded as abnormal.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) is a density-based clustering algorithm that can identify clusters of any shape and can effectively mark noise points. For high-density crowd scenes, appropriate ε (neighborhood radius) and MinPts (minimum number of neighborhood points) parameters are selected, where ε determines the definition of density and MinPts determines the minimum number of points required to form a dense area. Then, DBSCAN clustering analysis is used to identify dense crowd areas under normal behavior patterns and detect abnormal points that cannot be assigned to any cluster. Chebi et al. [
41] proposed a method combining DBSCAN and neural networks for the dynamic detection of abnormal crowd behaviors in video analysis. This method uses the density-based feature of the DBSCAN algorithm to identify the dense areas of the crowd in video surveillance and further analyzes the behavior patterns of these areas through neural networks to identify abnormal behaviors that are different from normal behavior patterns.
In summary,
Table 3 summarizes the design idea, advantages, and disadvantages of the above various abnormal behavior recognition technologies based on traditional methods. Although these traditional methods can effectively identify abnormal behaviors to a certain extent, a common limitation is that they still rely on manually designed features and artificially set thresholds, with limited adaptability to complex and changeable scenarios, and can be vulnerable to interference from environmental factors. In addition, traditional methods cannot usually automatically learn deep-seated behavior patterns, resulting in limited generalization ability prone to false positives and false negatives. Therefore, there is an urgent need to seek new methods, which should have a strong automatic feature learning ability, adapt well to complex patterns, and capture subtle differences in crowd behaviors more accurately.
4.2. Deep Learning-Based Methods
In recent years, deep learning has become the core driving force in the field of computer vision. Compared with traditional methods, deep learning mostly uses the powerful representational learning ability of deep neural networks to automatically extract high-level abstract features from raw data, which can effectively distinguish normal behaviors from abnormal behaviors. According to the network structure and flow processing method, deep learning abnormal behavior recognition methods are classified into the following categories: abnormal behavior recognition methods based on Convolutional Neural Networks, based on autoencoders, based on generative adversarial networks, based on Long Short-Term Memory Networks, and based on self-attention mechanisms.
4.2.1. Methods Based on the Convolutional Neural Network
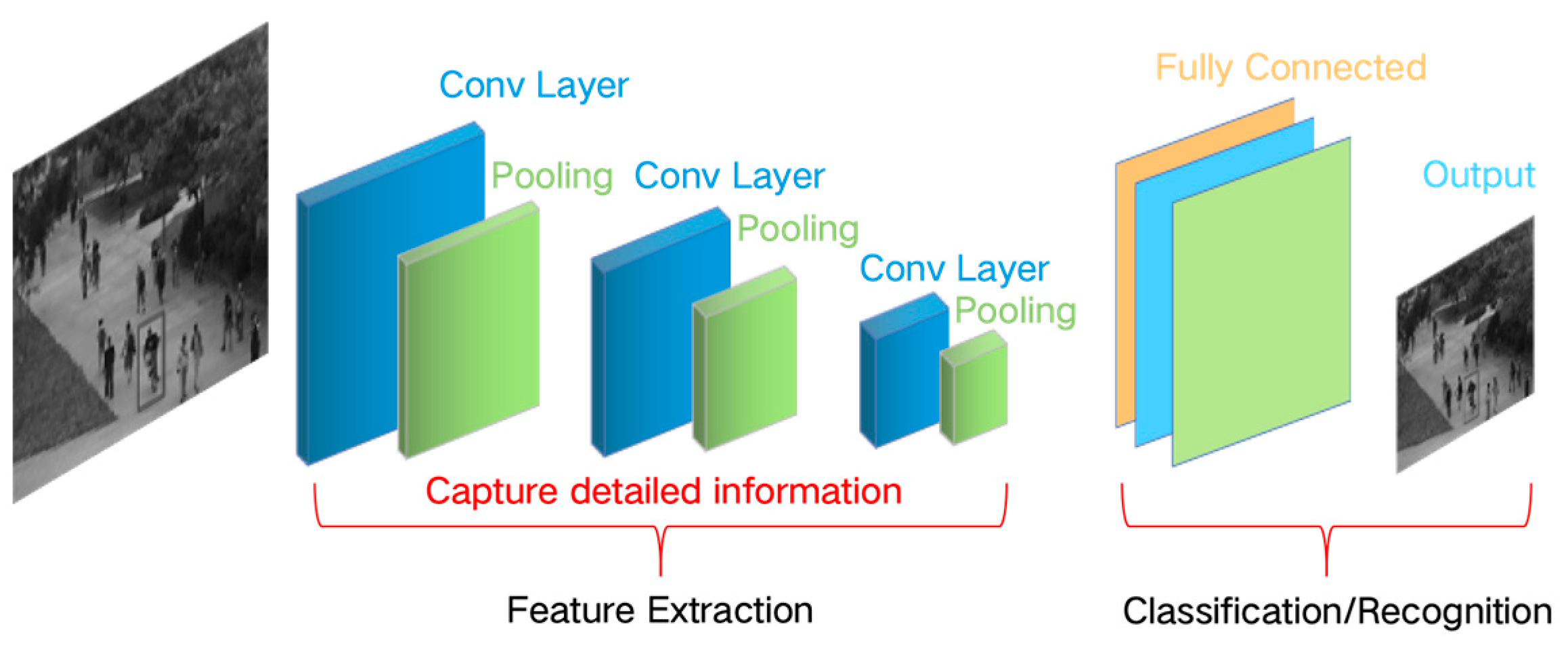
The Convolutional Neural Network (CNN), due to its strong ability to process pixel data and efficient learning feature representation, has become an indispensable part of the field of computer vision, such as image classification, semantic segmentation, and target feature analysis. As a deep feed-forward neural network system, the operation process of CNN can be divided into two major steps: feature extraction and classification decision-making, and the structure is shown in
Figure 4. In the field of abnormal crowd behavior recognition, the current CNN-based methods mainly focus on two core directions: spatial feature and spatiotemporal feature learning.
(1) Spatial feature. It focuses on extracting the appearance information of pedestrians from video frames to identify atypical behavior patterns in appearance, that is, appearance anomalies. Based on different video forms and annotations, abnormal crowd behavior recognition methods can be divided into three learning methods: supervised, semi-supervised, and unsupervised.
Supervised abnormal behavior recognition is a strategy based on annotated datasets. It extracts pedestrian features through CNN and builds a classification model to identify abnormal patterns in the original data based on normal and abnormal behavior labels [
42]. Since explicit category labels are provided during training, CNN can learn precise feature representations for specific tasks, thereby achieving a high accuracy rate for labeled abnormal behavior recognition. However, this method highly depends on the annotated datasets of abnormal behaviors, and the cumbersome manual annotation limits the development of supervised algorithms.
Unsupervised/weakly supervised learning methods can use CNN to extract and analyze pedestrian feature representations without explicit abnormal behavior category labels or with only a small number of labels. This method can detect unknown or unlabeled abnormal behavior types, adapt to a wider range of behavior patterns, and improve the generalization ability of the model in practical applications. Unsupervised/weakly supervised abnormal behavior recognition is implemented based on two stages: feature extraction and abnormal recognition. In the feature extraction stage, pedestrian appearance features in the video sequence are extracted through pre-trained CNNs, commonly including VGG [
43], ResNet50 [
44], AlexNet [
45], GoogLeNet [
46], Inception [
47], etc. After extracting the appearance features of pedestrians, abnormal classification is performed through abnormal behavior recognition algorithms, commonly including a one-class classifier [
48], Gaussian classifier [
49], Support Vector Machine (SVM) [
50], etc. Singh et al. [
51] proposed a method of Aggregation of Ensembles (AOEs), which fused and fine-tuned the three networks of AlexNet, GoogLeNet, and VGG, especially adjusting the number of output nodes of the fully connected layer to match the binary classification task, and adopted a hierarchical fine-tuning strategy, only updating the learning rate of specific layers and keeping other layers unchanged, thereby avoiding training the network from scratch and improving the efficiency of abnormal behavior recognition. At the same time, each sub-ensemble is composed of a specific classifier and the combination of three CNN models, providing multiple classification outputs for each video frame. To solve the problem of low efficiency of video frame block convolution, Sabokrou et al. [
52] proposed a method based on a Fully Convolutional Neural Network (FCN), extracting features of all regions from the entire video frame and performing convolution and pooling operations in parallel, which can achieve a processing speed of about 370 frames per second, meeting the requirements of real-time processing.
(2) Spatiotemporal feature learning. This method integrates dynamic information in the time series based on space. This is usually achieved by using optical flow data or upgrading to 3D convolution technology, aiming to capture the complex relationship between motion and time between video frames and identify abnormalities in the movement trajectories and speeds of pedestrians. Under this framework, according to the different time-perception feature fusion strategies, it is mainly divided into two implementation approaches: a two-stream CNN architecture and a three-dimensional Convolutional Neural Network (3D CNN).
The two-stream Convolutional Neural Network decomposes the processing of video data into a spatial stream and a temporal stream. The spatial stream focuses on the static content of the video frame, that is, the appearance feature in each frame image. The temporal stream focuses on analyzing the temporal changes and dynamic behaviors in the video sequence and usually uses optical flow images as the input. Hu et al. [
53] proposed a weakly supervised learning ABDL framework. Firstly, the Faster R-CNN network is used to identify objects (such as pedestrians) in the scene; then, the large-scale optical flow histogram (HLSOF) is used to describe the behavior features of the objects and finally, the behaviors are classified through the Multi-Instance Support Vector Machine (MISVM) to distinguish normal or abnormal. Wang et al. [
54] designed a two-stream Convolutional Neural Network model (TS-CNN), as shown in
Figure 5. By combining the above optical flow features and trajectory information, this network can process spatiotemporal information simultaneously and improve the accuracy of abnormal behavior detection. At the same time, the Kanade–Lucas–Tomasi (KLT) tracking algorithm is used to obtain the single-frame image of the crowd movement trajectory. This strategy enables the algorithm to better handle the occlusion problem in the crowd and further enhances the recognition of abnormal behaviors through the continuity feature of the behavior.
Three-dimensional CNN adds a time dimension based on the original 2D convolution. By performing convolution on the time axis, 3D CNN can capture the change patterns of behaviors over time, which is extremely crucial for identifying abnormal behaviors (such as falling, running, gathering, etc.) that need to consider the behavior sequence and time context. Hu et al. [
55] proposed a method based on a Deep Spatiotemporal Convolutional Neural Network (DSTCNN), extending two-dimensional convolution to three-dimensional space and comprehensively considering the spatial features of static images and the temporal features between front and rear frames. Firstly, the video screen is divided into multiple sub-regions and spatiotemporal data samples are extracted from these sub-regions and input into DSTCNN for training and classification, achieving accurate detection and location of abnormal behaviors. At the same time, to solve the problems of network dispersion and insufficient recognition ability, Gong et al. [
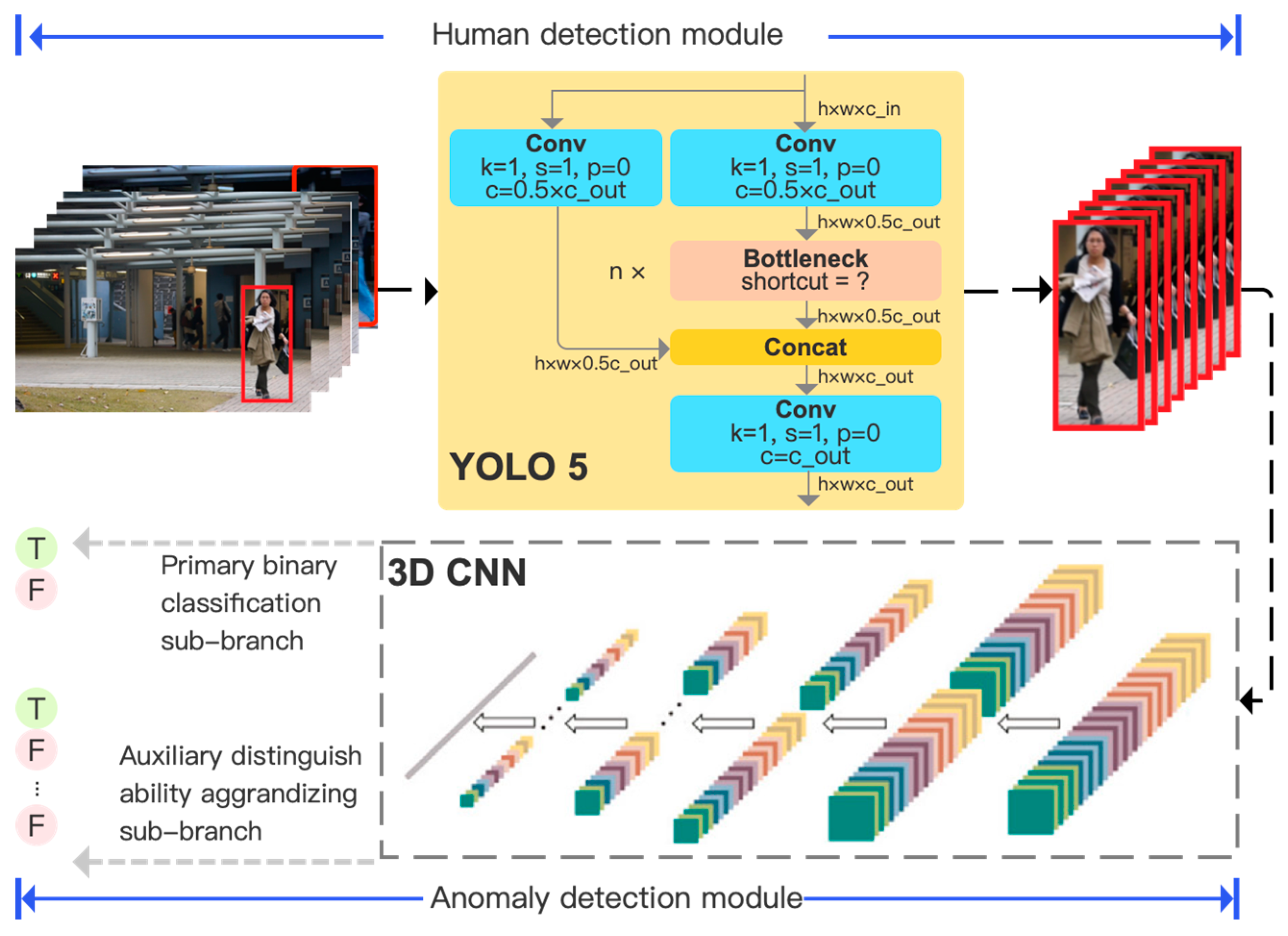
56] proposed the LDA-Net framework, as shown in
Figure 6. It consists of a human body detection module and an abnormal detection module. Among them, the YOLO algorithm is introduced in the human body detection module to make the abnormal detection module more concentrated; in the abnormal detection module, 3D CNN is used to simultaneously capture the motion information of labeled normal and abnormal action sequences from the spatial and temporal dimensions.
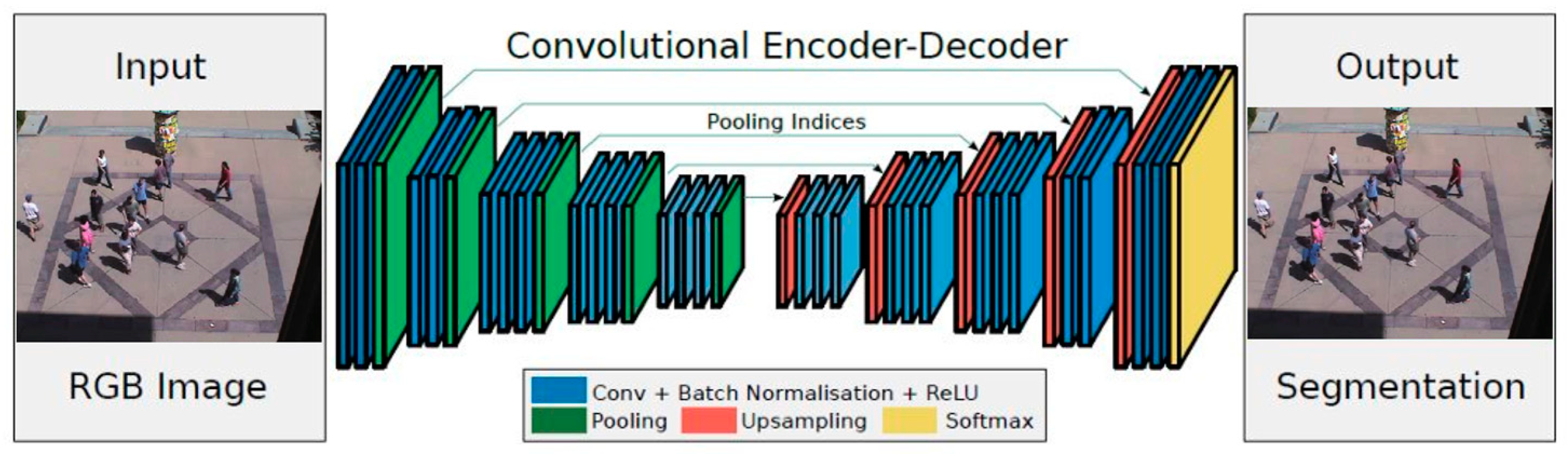
4.2.2. Methods Based on Autoencoders
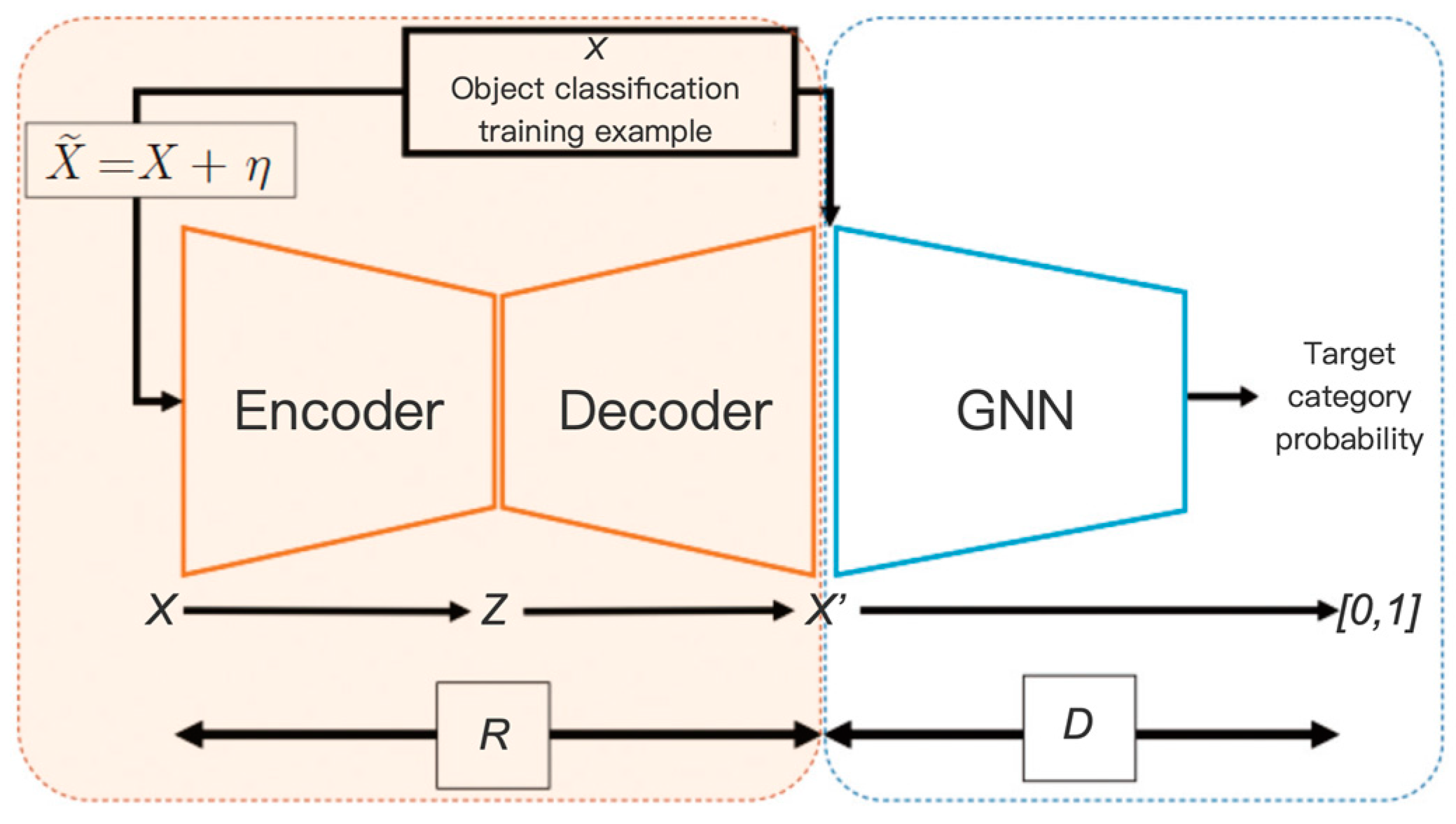
Autoencoders (AEs) [
57] constitute an unsupervised learning method. The basic architecture consists of two parts, the encoder and the decoder. It reconstructs the original input by learning the effective compressed representation of the data. The structure is shown in
Figure 7. In anomaly detection, AEs are trained to reconstruct normal behavior data. Thus, for those inputs significantly different from the training data (i.e., abnormal behaviors), their reconstruction errors will increase. During this process, the Mean Square Error (MSE) [
58] is commonly used as the loss function. MSE is a statistical indicator that measures the difference between the predicted value and the true value, and the expression is shown in Equation (1), as follows:
Among them,
is the predicted value of the model for the
ith sample,
is the true value of this sample, and
is the residual (the difference between the predicted value and the true value). The smaller the value of MSE, the smaller the average gap between the predicted value and the true value of the model, and the higher the fitting degree of the model. In recent years, Autoencoders have been widely used for abnormal crowd behavior recognition. These methods are mainly divided into two categories [
59]: methods based on similarity measurement and methods based on hidden feature representation learning.
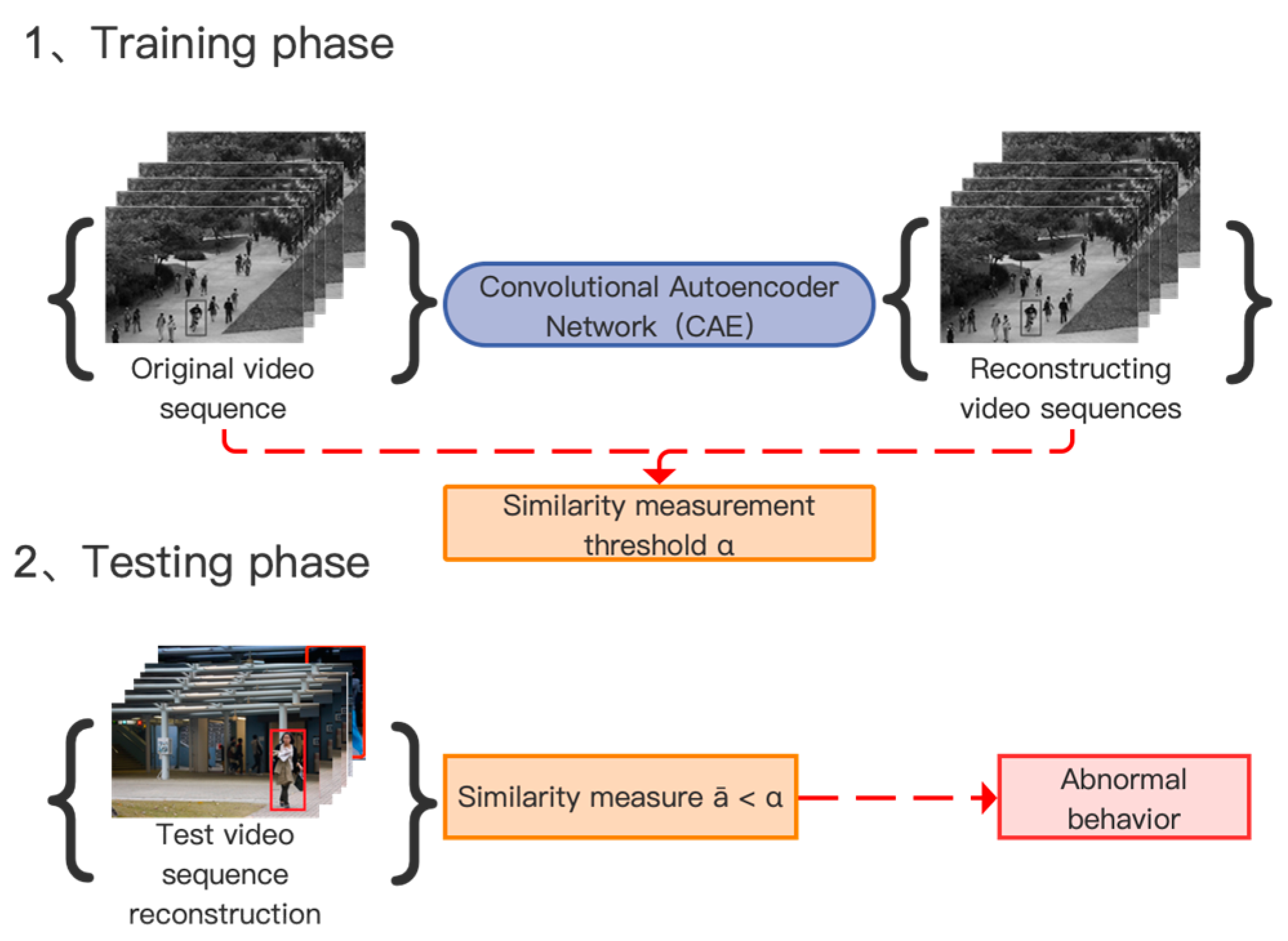
(1) The method based on similarity measurement. This is a technique used to evaluate and quantify the degree of similarity between two data objects, samples, sets or vectors. In the field of abnormal crowd behavior recognition, abnormal behavior recognition is carried out by comparing the similarity between the original input image and the reconstructed image by the Convolutional Autoencoder (CAE), and the process is shown in
Figure 8. The similarity between the original image and the reconstructed image is compared through similarity measurement techniques (such as Euclidean Distance [
60], Pearson Correlation Coefficient [
61], etc.). If the similarity is low, it indicates that there is abnormal behavior in the original image.
The original video sequence contains the appearance features of pedestrians, and the use of optical flow analysis can describe the dynamic trajectories of foreground targets. Information fusion can be carried out through the Convolutional Autoencoder (CAE) to extract the appearance attributes and dynamic features of pedestrians. Nguyen et al. [
62] designed a CNN combining CAE and U-Net, which share the same encoder. CAE is responsible for learning the normal appearance structure, while U-Net attempts to associate these structures with the corresponding motion templates. This design aims to jointly improve the detection ability of abnormal frames through two complementary streams (one dealing with appearance and the other dealing with motion) and the model supports end-to-end training.
In addition to the fusion of optical flow analysis, some recent studies have utilized the processing ability of the Convolutional LSTM network (ConvLSTM) [
63] for time series and combined it with the Convolutional Autoencoder (CAE), significantly improving the extraction ability of spatiotemporal features in videos. Xiao et al. [
64] designed the Probabilistic Memory Autoencoder Network (PMAE), integrating 3D causal convolution and time dimension shared fully connected layers in the autoencoder network to extract spatiotemporal features in video frames, while ensuring the temporal sequence of information and avoiding the leakage of future information. Based on the spatiotemporal encoder, Nawaratne et al. [
65] proposed the method of Incremental Spatiotemporal Learner (ISTL) for online learning of the spatiotemporal normal behavior patterns in video surveillance streams, thereby achieving abnormal detection and location. At the same time, an active learning strategy of fuzzy aggregation is introduced to dynamically adapt to unknown or emerging normal behavior patterns in surveillance videos, allowing the system to continuously refine the understanding of normal and abnormal behaviors based on environmental changes and the acquisition of new information.
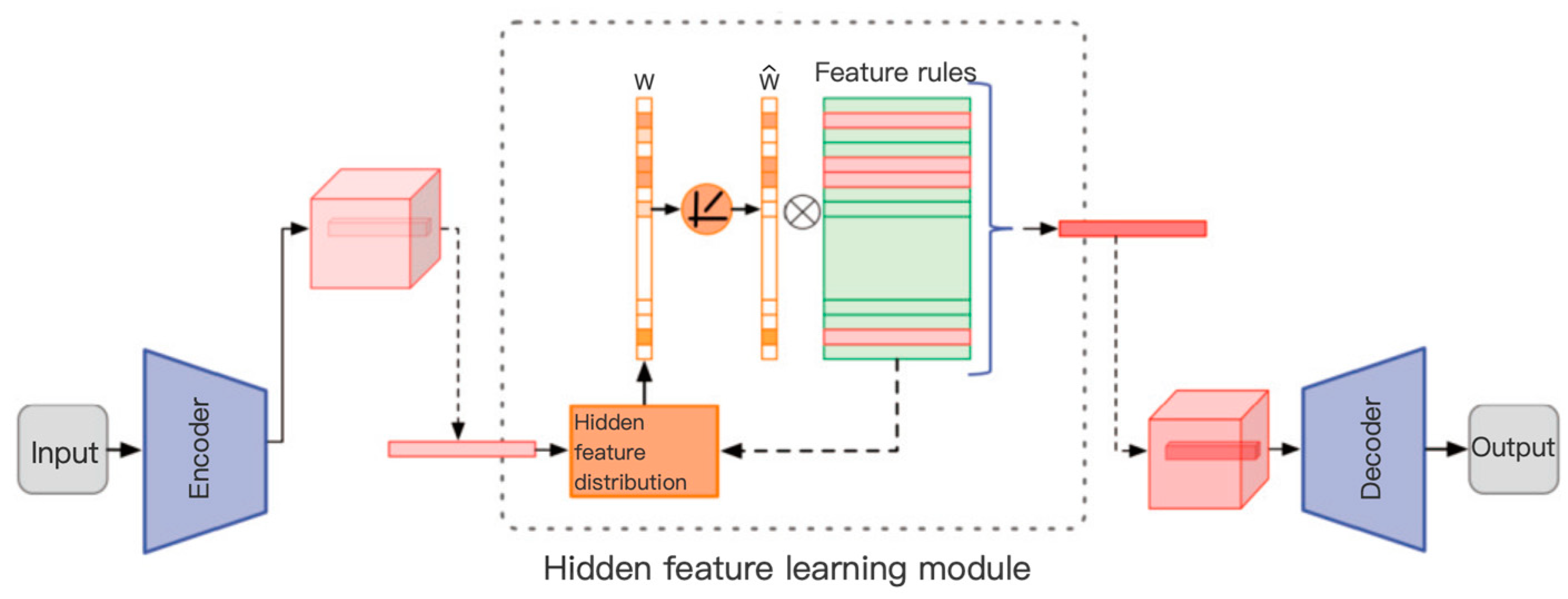
(2) The method based on hidden feature representation learning. This method focuses on using an encoder to map high-dimensional input data into a low-dimensional vector space, focusing on extracting the core information of normal behavior patterns. Subsequently, the decoder attempts to reconstruct the original data. During the optimization process, it ensures that the model captures the key structure of the behavior data. The process is shown in
Figure 9. Common autoencoders can be divided into Stacked Denoising Autoencoders (SDAEs) [
66] and Variational Autoencoders (VAEs) [
67].
SDAE extracts higher-level feature representations by combining multiple Denoising Autoencoders (DAEs) [
68]. The goal of a single DAE is to reconstruct the original data on noisy data. The main principles are the following: ① the encoder maps the noisy input data to a low-dimensional hidden representation and ② the decoder reconstructs the original noise-free data based on this and minimizes the reconstruction error to learn effective information. During the stacking process, the output of the first DAE (i.e., the denoised representation) serves as the input of the second DAE, and so on. Each layer attempts to further remove noise or extract more abstract features from the output of the previous layer. Wang et al. [
69] used two SDAEs to learn the appearance features and motion features of behaviors. For the appearance feature, the input is the image block within the spatiotemporal volume around the dense trajectory; the motion feature is based on the optical flow block. Each SDAE contains multiple encoding layers, and the number of nodes is halved layer by layer until the bottleneck layer is reached. The output of this bottleneck layer is regarded as the learned deep feature. The structure is shown in
Figure 10.
VAE is a generative model based on a probabilistic framework. Its encoder is similar to the traditional encoder, mapping the input
x to a pair of vectors
μ and
σ, representing the mean and standard deviation of the posterior distribution
q(z|x), respectively. The decoder receives the latent variable z and attempts to reconstruct the original input
x, that is, estimating
p(x|z). The output of the decoder can be regarded as the probability distribution of
x given
z. Wang et al. [
70] designed a new method called S2-VAE. This method combines the stacked fully connected variational autoencoder (SF-VAE) and the skip convolutional variational autoencoder (SC-VAE). Among them, SF-VAE is a shallow generative network designed to simulate Gaussian mixture models to adapt to the actual data distribution. Filter obvious normal samples and improve the speed of abnormal detection. SC-VAE is a deep generative network that integrates low/middle/high-level features and reduces the loss in the information transmission process by fusing the features between the encoder and decoder layers through skip connections.
4.2.3. Methods Based on Generative Adversarial Networks
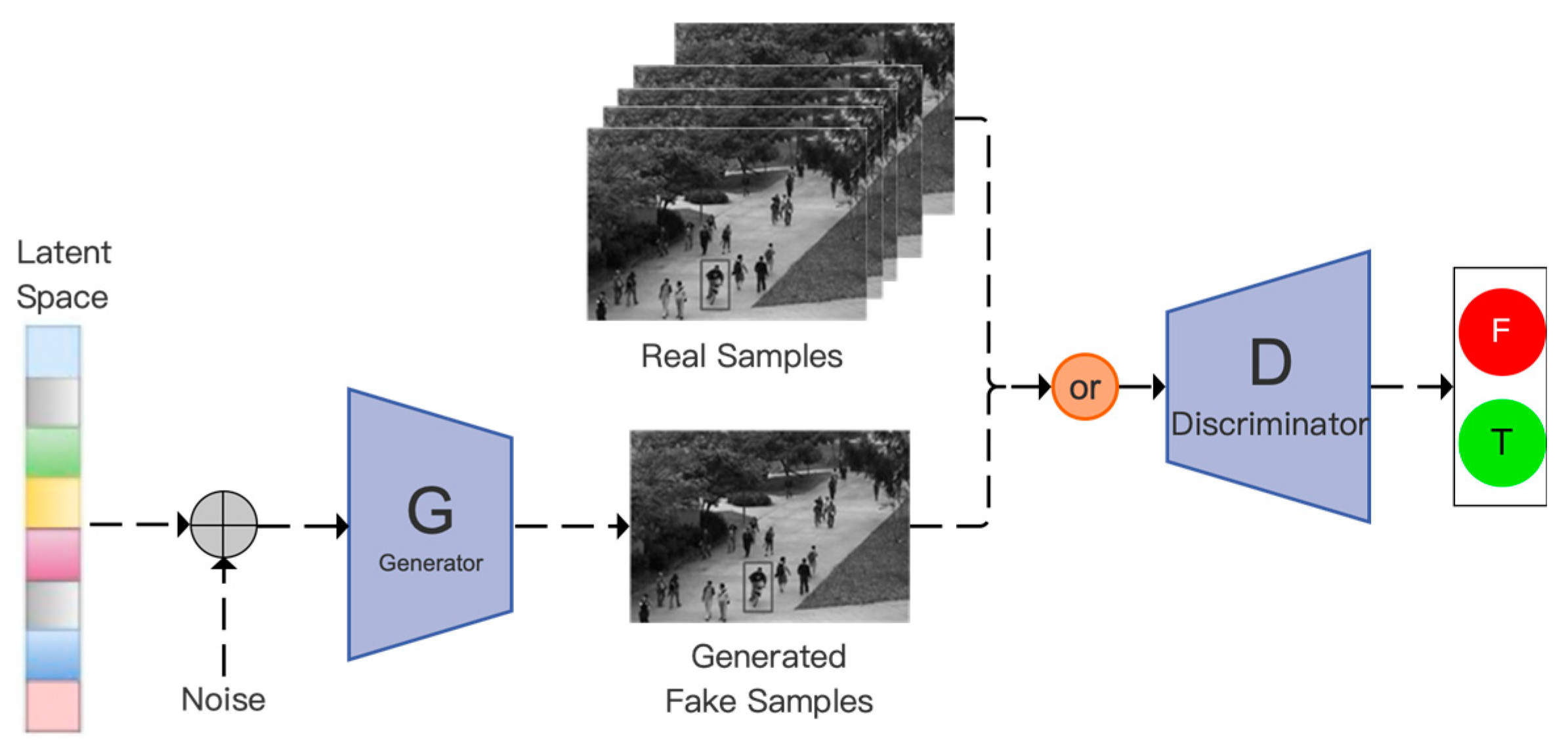
Generative adversarial networks (GAN) learn the data distribution through the adversarial process of the generator and the discriminator. In anomaly detection, a GAN can be trained to effectively generate only normal behavior data; then, the reconstruction error of the generator or the output of the discriminator can be used to determine whether the input data are normal. Abnormal behaviors are not within the distribution range of the training data and have poor generation or reconstruction effects; thus, they are identified. The GAN model structure is shown in
Figure 11. The abnormal behavior recognition strategies based on GAN can be roughly classified into two categories: the direct reconstruction or prediction error detection method and the enhanced reconstruction method combined with an autoencoder.
The core idea of the reconstruction-based method is to train a model to learn the distribution representation of normal video data. In the testing stage, it is determined whether the test sample is abnormal based on its reconstruction error. Specifically, first, a deep learning model, that is, a neural network
g, is constructed. Its goal is to learn a mapping relationship so that for any given video segment or video frame
x, the output
g(x) processed by
g is as close as possible to the original input
x. Secondly, an error function
f is designed, which can quantify the difference between
x and
g(x), that is, the reconstruction error [
71]
ε = f(x, g(x)). Then, during the training process, efforts are made to find an optimal set of neural network parameters so that for all samples
x in the entire dataset, the corresponding sum (or average, weighted sum, etc.) of the reconstruction errors
ε reaches the minimum. Song et al. [
72] proposed an Ada-Net network architecture that integrates an attention-based autoencoder with a GAN model. This architecture can adaptively learn normal behavior patterns from video data and enhance the reconstruction ability of the autoencoder through adversarial learning, making the reconstructed video frames indistinguishable from the original frames. Different from the traditional reconstruction error metric based on Euclidean distance, the researchers introduced adversarial loss for the frame discriminator to make the reconstructed frame highly similar to the original frame, thereby improving the reconstruction accuracy of the autoencoder. In addition, Chen et al. [
73] proposed an anomaly detection model called NM-GAN, which consists of a reconstruction network R and a discrimination network D, forming a GAN-like architecture. NM-GAN builds an end-to-end framework, mainly consisting of three modules. (1) An image-to-image encoder–decoder reconstruction network with appropriate generalization ability. (2) A CNN-based discrimination network for identifying the spatial distribution pattern of the reconstruction error map. (3) An estimation model for quantitatively scoring anomalies. The entire model is trained in an unsupervised manner.
The prediction-based method is based on the fact that a continuous sequence of normal videos has a certain contextual dependence and regularity. Abnormal behaviors are identified by comparing the difference between the observed test frame and its predicted frame. Specifically, given the consecutive t frames of video
, the goal of the prediction model is to generate the next frame
and strive to make
as close as possible to the actual next frame
. In the testing stage, it is determined as to whether the current video frame is abnormal by comparing the difference (prediction error) between the
predicted by the model and the actual
. Specifically, let h represent the prediction model, then
. Prediction frameworks include unidirectional prediction and bidirectional prediction: unidirectional prediction is usually based on predicting the current frame from the previous few frames. For example, Tang et al. [
74] proposed the first method that combines future frame prediction and reconstruction, which is implemented through an end-to-end network. The network consists of two continuously connected U-Net modules. The first module performs future frame prediction based on the input image sequence, and the second module reconstructs the future frame based on the predicted intermediate frame, making normal and abnormal behaviors easier to distinguish in the feature space. Lee et al. [
75] used the Bidirectional Multi-scale Aggregation Network (BMAN) for abnormal behavior recognition. By using bidirectional multi-scale aggregation and attention-based feature encoding, normal patterns including object scale changes and complex motions are learned. Based on the learned normal patterns, abnormal events are detected by simultaneously analyzing the appearance characteristics and motion characteristics of the scene through an appearance-motion joint detector.
The enhanced reconstruction method combining the autoencoder embeds the adversarial training logic of GAN in the training framework of AE. The autoencoder combined with GAN can not only minimize the reconstruction error but also be linked with the discriminator in GAN to output a data distribution closer to the real one. The process is shown in
Figure 12. A discriminator is integrated into the architecture of the autoencoder to compare and distinguish the reconstructed image of the autoencoder network and the original input image. The quality of the reconstructed image of the autoencoder network is enhanced through adversarial training. Schlegl et al. [
76] proposed a method of fast anomaly generative adversarial network (f-AnoGAN), training a Wasserstein GAN through normal samples and then training an encoder to map the image to the latent space to achieve fast inference and anomaly detection. During the anomaly detection process, the input image is reconstructed through the encoder and generator, and the combined score of the image reconstruction residual and the discriminator feature residual is used as a reliable indicator of anomaly.
4.2.4. Methods Based on Long Short-Term Memory Network
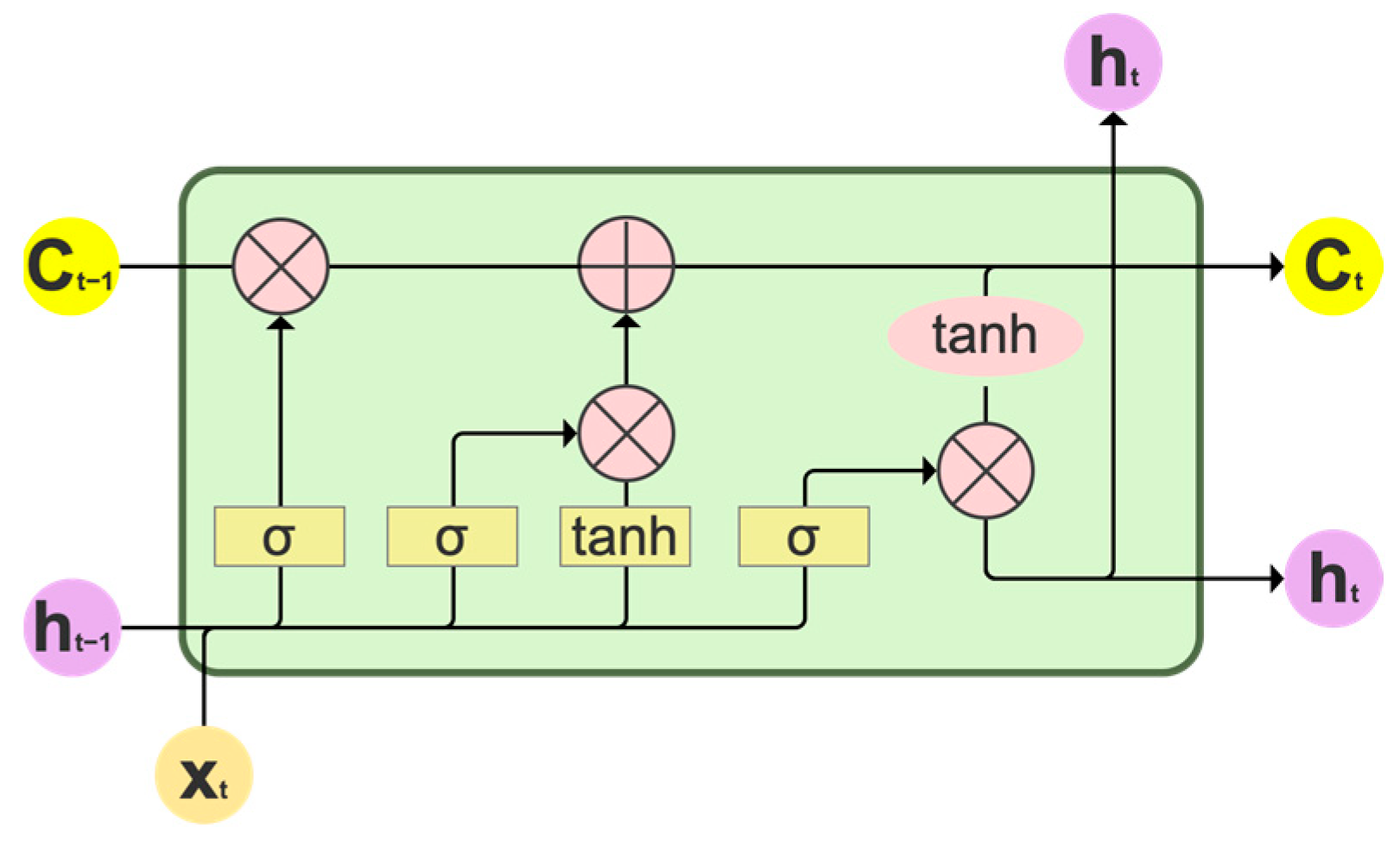
Compared with feedforward neural networks, the Recurrent Neural Network (RNN) shows significant advantages in processing sequence data and is particularly good at understanding and processing time series information. The Long Short-Term Memory (LSTM) network, as an improvement and extension of RNN, is mainly designed to solve the problems of gradient vanishing and gradient explosion encountered in the training process of long sequence data. LSTM captures and analyzes the changing patterns of behaviors over time and automatically identifies abnormal sequences that do not conform to it by learning the patterns of normal behavior sequences. LSTM introduces a gate mechanism for controlling the flow and loss of features, including three gating mechanisms: the input gate, forget gate, and output gate. The structure is shown in
Figure 13.
As shown in the figure above, Xt represents the input at the current moment, ht−1 and ht represent the output of the previous unit and the current unit of LSTM, Ct−1 and Ct represent the state of the previous unit and the current unit, σ represents the sigmoid activation function, and tanh represents the hyperbolic tangent activation function.
(1) The forget gate. This determines the information to be retained. Based on
ht−1 and
Xt, the forget gate outputs a number between 0 and 1 for the state
Ct−1. A value of 0 means elimination and 1 means retention. The expression is shown in the Equation (2):
(2) The input gate. This determines the newly incoming information. Composed of the sigmoid function and the tanh function, the result of multiplying the output values is used to update the state. The expression is shown in the Equations (3)–(5):
(3) The output gate. This determines the output information. The output state is determined through the sigmoid layer, and the output result of the state through the tanh layer is multiplied by the output result of the sigmoid layer. The expression is shown in the Equations (6) and (7), as follows:
In the field of abnormal crowd behavior recognition, researchers usually combine LSTM with other technologies to improve the recognition rate and processing speed of crowd abnormal behaviors. Meng et al. [
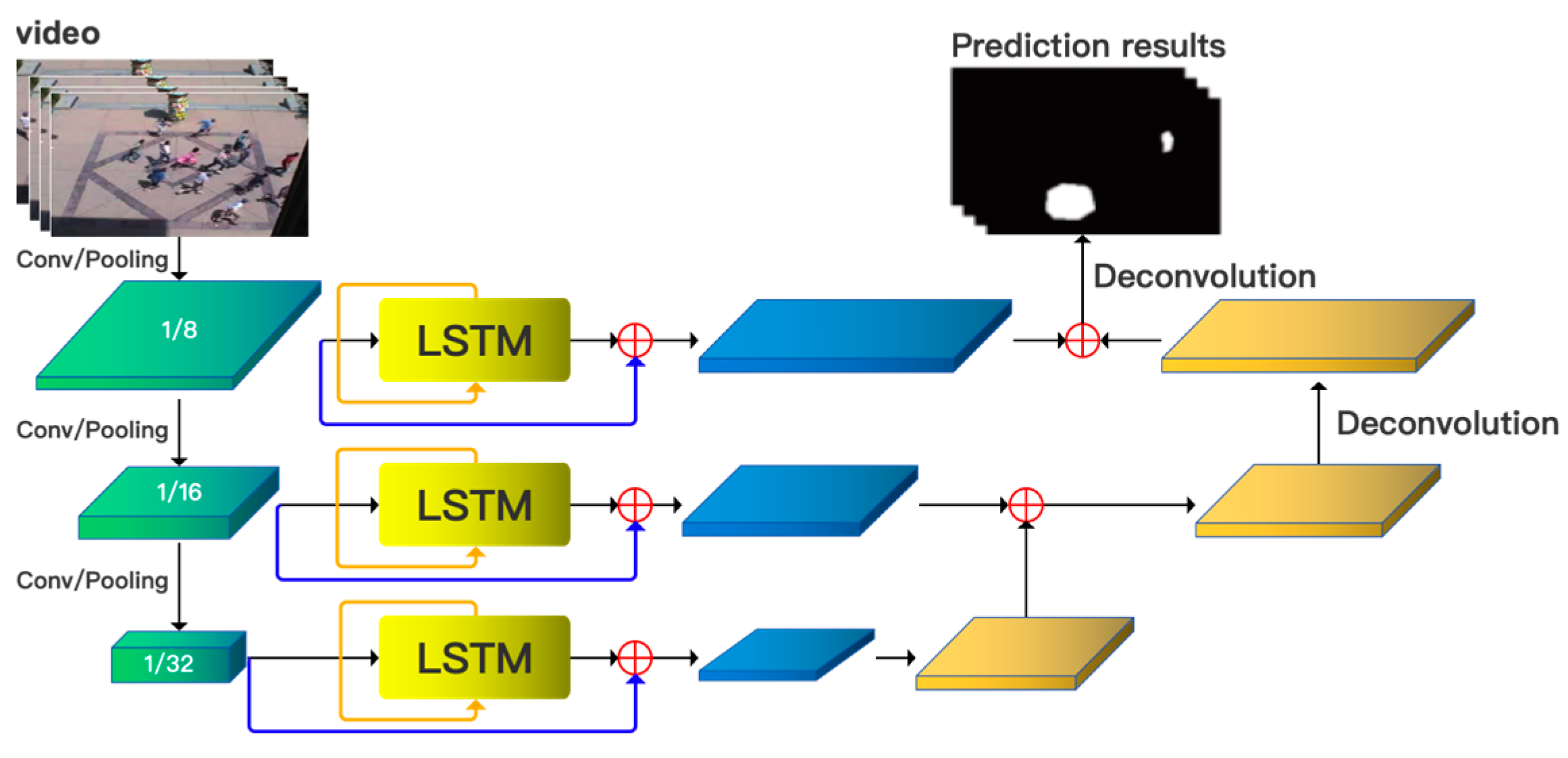
77] integrated the focal loss function into the LSTM algorithm, optimized the model’s attention to abnormal samples, and reduced the model loss. This improvement not only enhanced the sensitivity of the LSTM algorithm to abnormal behaviors but also effectively improved the detection accuracy. At the same time, the author also improved the ViBe image foreground extraction method by initializing the background model and randomly selecting the neighborhood sample set to accurately extract the foreground target, thereby simplifying the scene complexity. Wu et al. [
78] combined the FCN with strong spatial feature extraction ability and the LSTM with excellent time series modeling ability. The structure is shown in
Figure 14. FCN is responsible for extracting high-level semantic features from video frames, while LSTM is used to capture the changing patterns of these features over time. By simultaneously learning the spatial and temporal information in the video, it effectively distinguishes normal and abnormal behaviors in the video. Sabih et al. [
79] proposed an improved end-to-end supervised learning method that combines the Long Short-Term Memory Network (LSTM) and the Convolutional Neural Network (CNN), especially in processing optical flow features. CNN is used to extract the frame-level optical flow features calculated based on the Lucas–Kanade algorithm from the video, while the bidirectional LSTM captures the time series information of these features to jointly perform crowd abnormal detection. This method helps to understand the normal behavior patterns in the video and identify abnormal instances.
4.2.5. Methods Based on the Self-Attention Mechanism
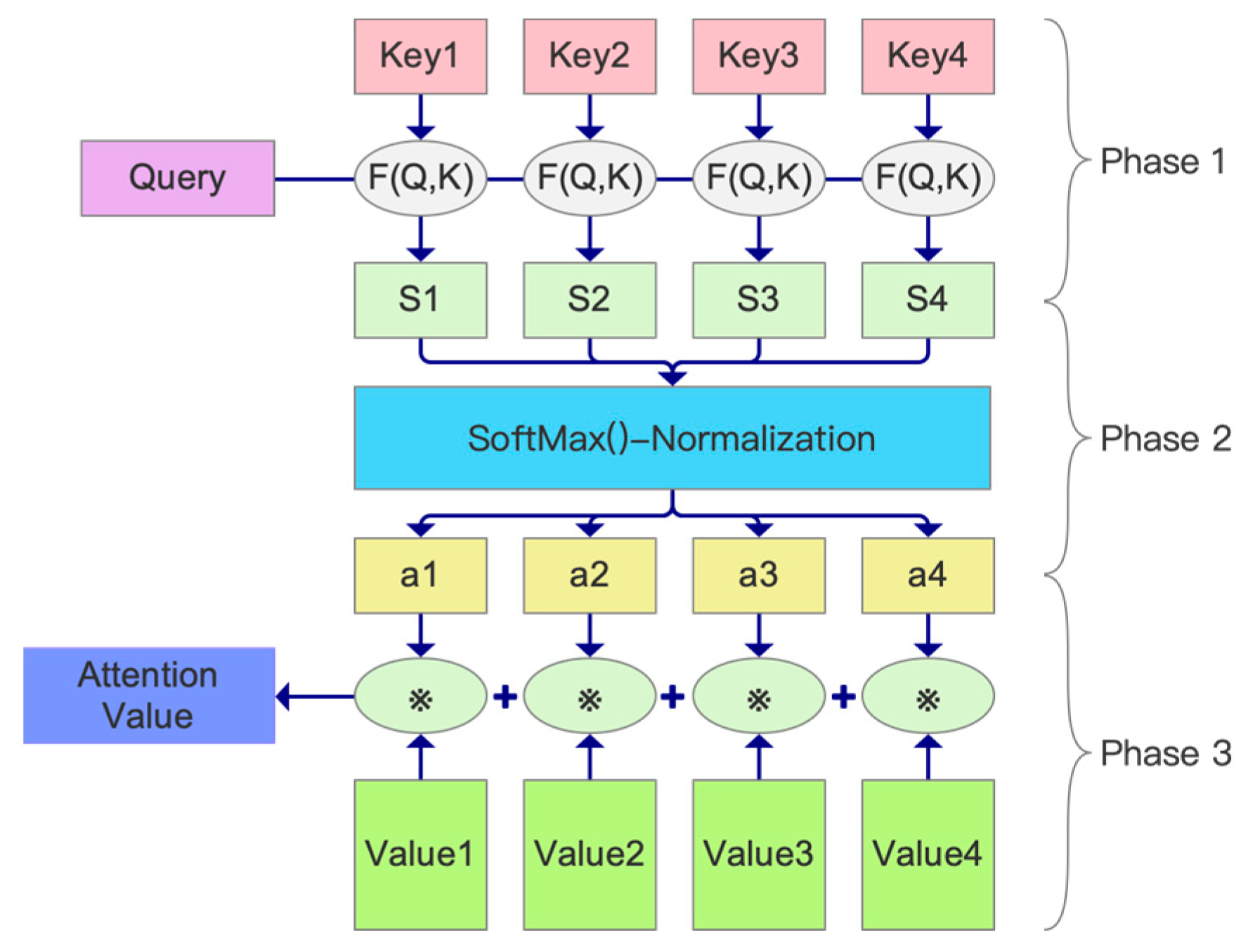
In the field of deep learning, the attention mechanism (Self-Attention SA) [
80] can be interpreted as a transformation process involving the mapping between a query vector and a series of key-value pairs, thereby generating an output vector. This output vector is obtained by performing a weighted sum of each Value vector, where the weight attached to each Value vector is determined based on the quantitative evaluation of the correlation between its corresponding Key vector and the main query vector. The calculation of the attention mechanism can be divided into three stages, as shown in
Figure 15.
Stage 1 is to calculate the similarity between Query and Key. Common methods include the vector dot product, Cosine similarity, and MLP network. The expression is shown in the Equations (8) and (9), as follows:
- (1)
Cosine similarity
- (2)
MLP network
Stage 2 introduces
SoftMax for normalization to sort out the probability distribution of all of the elements. The expression is shown in the Equation (11), as follows:
Stage 3 performs weighted summation to obtain the
Attention value. The expression is shown in Equation (12), as follows:
Self-attention is a special form of the attention mechanism. Its uniqueness lies in that, when calculating the attention weight, the query, key, and value all come from different parts of the same input sequence. It was first widely used in the “Transformer” model, which greatly promoted the development of the field of natural language processing, and is currently also widely used in crowd sequence modeling and abnormal behavior recognition tasks. Self-attention can not only capture the long-distance dependency within the sequence but also remain efficient in parallel computing, thereby overcoming some limitations of the Recurrent Neural Network (RNN) model.
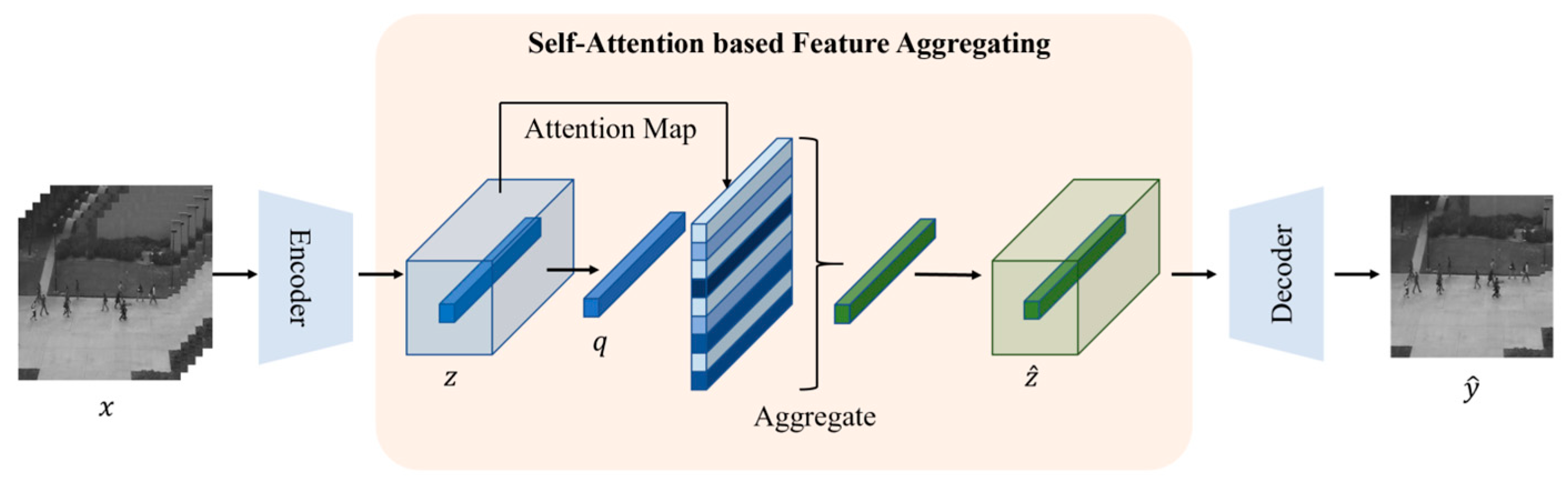
Ye et al. [
81] designed a Self-Attention Feature Aggregation (SAFA) module. The structure is shown in
Figure 16. This module regenerates the feature map by aggregating the embedding representations with similar information according to the attention map. At the same time, the prior bias on normal data is minimized through the self-suppression strategy, and it is used in combination with the pixel-level frame prediction error to jointly detect abnormal frames, enhancing the ability to recognize abnormalities.
Zhang et al. [
82] proposed an autoencoder model that integrates the global self-attention mechanism to capture the interaction information between the overall features of the image, facilitating the model to understand the context in which the behavior occurs and improving the accuracy of abnormal behavior determination. At the same time, a memory module is embedded in the bottleneck layer of the autoencoder to constrain the model’s over-generalization of normal behaviors.
Zhang et al. [
83] fused the attention mechanism and the bidirectional Long Short-Term Memory Autoencoder Network (SABiAE). The structure is shown in
Figure 17. The encoder with the self-attention mechanism captures global appearance features, and the self-attention bidirectional LSTM network is used to reduce the loss of target features, thereby extracting the information between video frames globally. The model reconstructs the frame through the decoding process and determines abnormal behaviors based on the reconstruction error.
Zhang et al. [
84] introduced the self-attention mechanism in the Generative Adversarial Network (GAN), using the autoencoder containing the dense residual network and the self-attention mechanism as the generator. At the same time, a new discriminator is proposed, which integrates the self-attention module based on the relative discriminator, thereby avoiding the problem of gradient vanishing during the training process and ensuring that the frames generated by the generator are closer to the real frames.
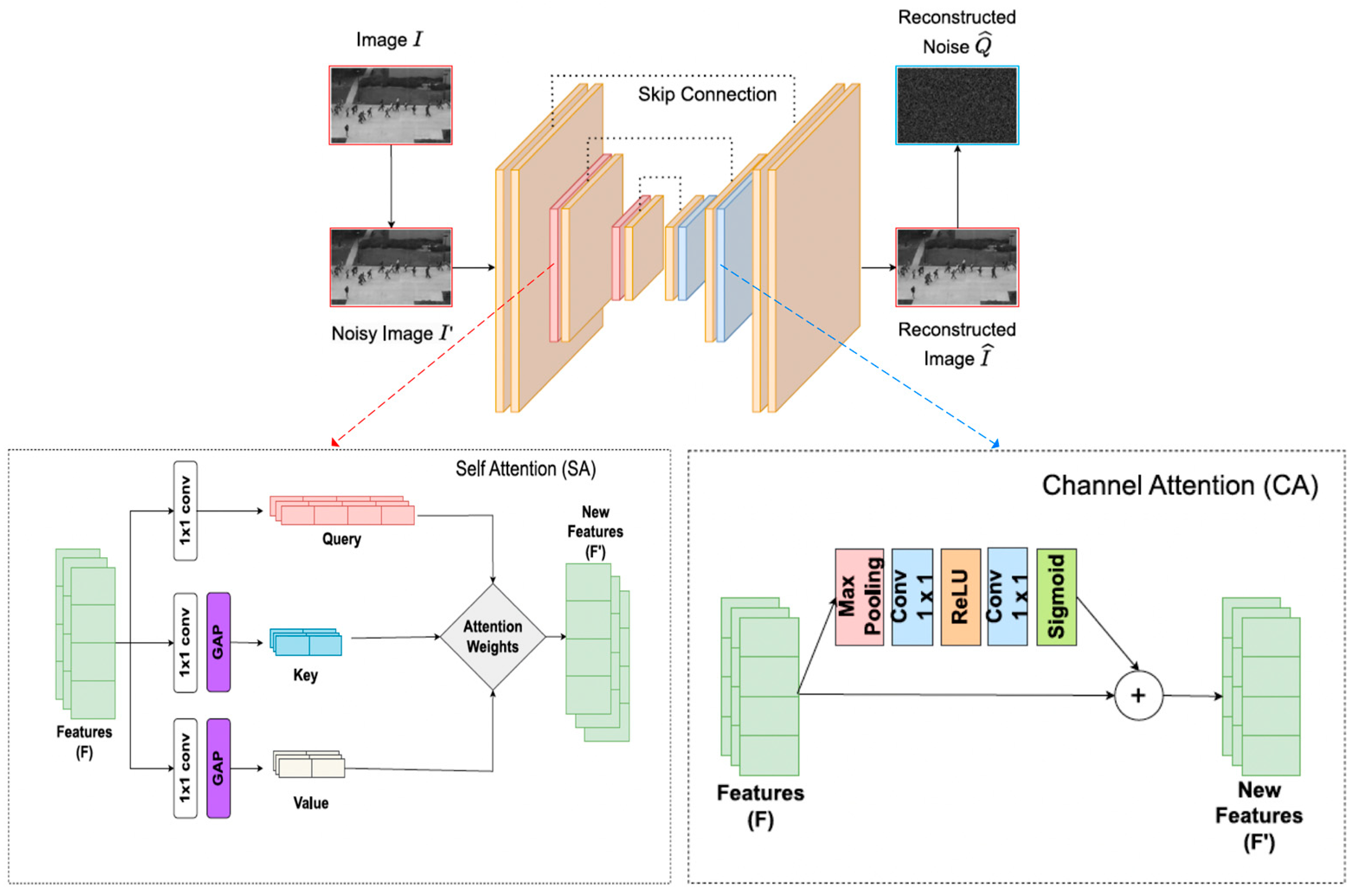
Singh et al. [
85] proposed an Attention-guided Generator and Dual Discriminator Adversarial Network (A2D-GAN), the structure if which is shown in
Figure 18, for real-time video anomaly detection. A2D-GAN utilizes the encoder–decoder architecture, in which the encoder adds multi-level self-attention to focus on key regions and capture context information, while the decoder uses channel attention to emphasize important features and identify abnormal patterns specific to each frame.
In addition, to solve problems such as scale changes and occlusions in the crowd, fusion models such as multi-scale feature attention fusion networks and visual occlusion resolution have emerged for abnormal crowd behavior detection. For example, Sharma et al. [
86] introduced a scale-aware attention module in CNN, using the cascade of multiple self-attention branches to enhance the recognition ability for scale changes. This architecture integrates motion information, motion influence maps, and features based on the energy level distribution to achieve frame-level abnormal behavior analysis. Zhao et al. [
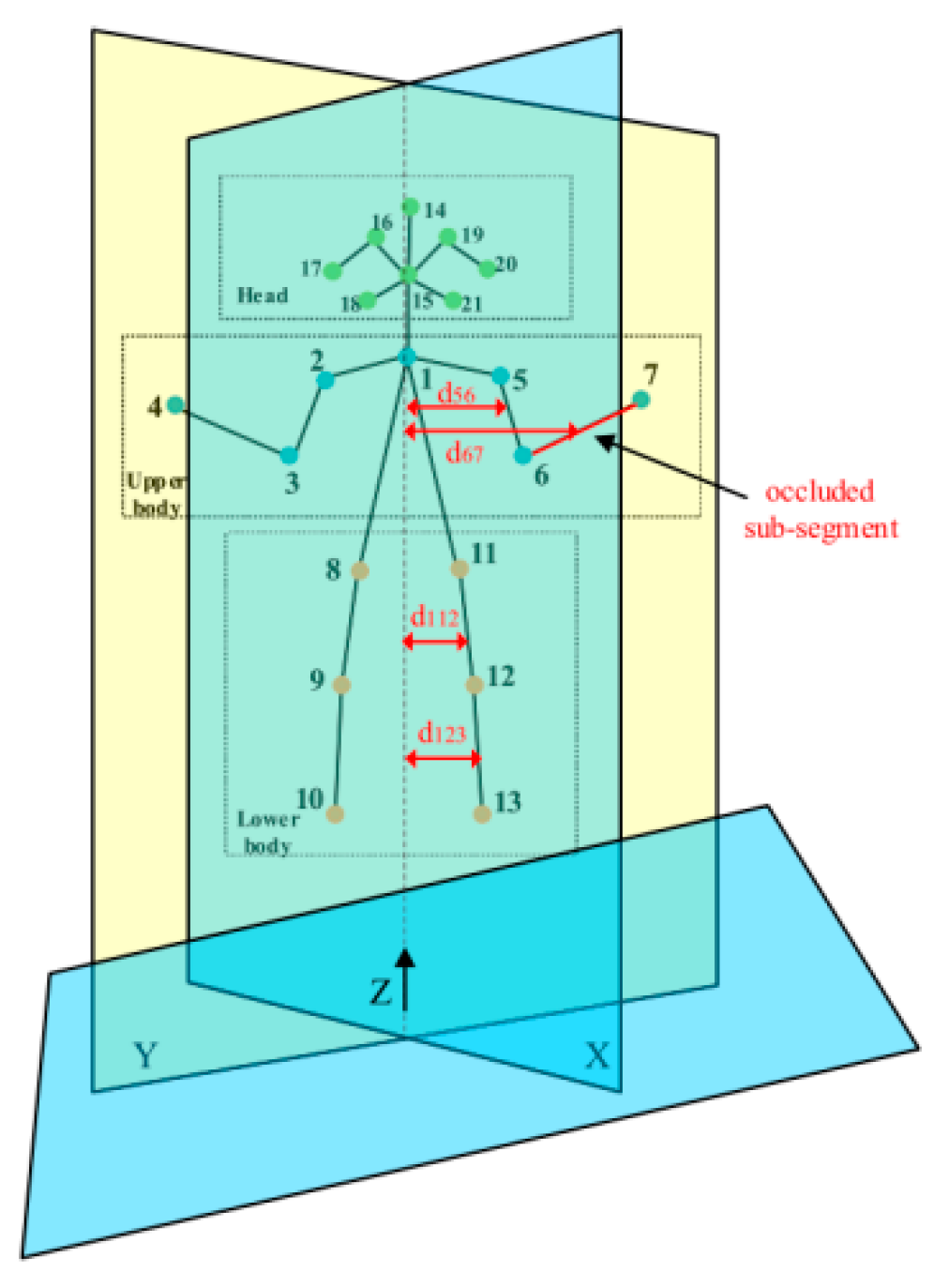
87] proposed a Dynamic Pedestrian Centroid Model (DCM). The key points of the human skeleton are extracted from the image, the pedestrian joint sub-segments are constructed accordingly, and the dynamic characteristics of pedestrians in the video sequence are described mathematically. Experiments show that DCM can detect the U-turn behavior 277 ms earlier on average and detect the fall behavior 562 ms earlier on average to find abnormalities. At the same time, to solve the problem of partial occlusion of pedestrians, this paper also designed an anti-occlusion algorithm, as shown in the schematic in
Figure 19. Firstly, cluster the key points of the pedestrian skeleton, divide the 21 key points into the head, upper body, and lower body, calculate the coordinates of the occluded part, estimate the effective position combined with the mechanical principle, and apply it in combination with DCM. This method has been verified by the fall behavior detection experiment and the AUC on the 50 Volu. The U-turn dataset reaches 82.13%, and the AUC on the 50 Volu. The fall-down dataset reaches 86.70%.
In summary,
Table 4 summarizes the design ideas, advantages, and disadvantages of the above various deep learning-based abnormal behavior recognition technologies. Overall, these deep learning-based methods benefit from the powerful learning ability of neural networks and can be applied to the recognition of abnormal behaviors of pedestrians in various crowd scenarios. At the same time, a strategy of using multiple methods in combination can be adopted to further improve the generalization ability and recognition accuracy of the model.
4.3. Mainstream Software Tools
In recent years, with the deep integration and breakthrough progress of big data and computer vision technology, the analysis of crowd abnormal behaviors has become an important research topic in the field of public safety. Algorithms and software tools in this field have also emerged continuously. Each representative software tool aims to reveal and identify changes and deviations from the normal patterns of crowd behaviors in complex scenarios from different dimensions. Many algorithm manufacturers focusing on this field have also launched a series of advanced software tools specifically for abnormal crowd behavior recognition. The following is an overview of the mainstream tools.
The PP-Human abnormal crowd behavior recognition tool (PaddleDetectionv2.7.0) is an industrial-level open-source real-time pedestrian analysis tool that integrates core capabilities such as object detection, tracking, and key point detection. It can adapt to different light conditions, complex backgrounds, and cross-lens scenarios.
The SenseTime abnormal crowd behavior recognition tool (Version 2.7.4 ©2014-2024) analyzes the overall characteristics and individual behavior characteristics of the crowd in the surveillance images, masters the activity rules of the crowd, and realizes the automation or even intelligence of video surveillance.
The Hikvision abnormal crowd behavior recognition tool (V3.12.0.7_E) provides powerful analysis data for crowd control, prevents the occurrence of crowding and stampede incidents, and provides effective guarantees for social security.
The Keda abnormal crowd behavior recognition tool (6.0.29.20230128_beta) combines the general intelligent recognition ability of the large model and the precise recognition ability of the small model to achieve group scene analysis such as holding knives, fighting, running, gathering, etc.
5. Comparative Analysis of Different Algorithm Experiments
5.1. Experimental Dataset Analysis
In the field of computer vision, due to the diversity and complexity of real abnormal behaviors in the research of abnormal crowd behavior analysis, there is a lack of high-quality datasets. To overcome this shortage and improve the performance of algorithms, researchers have constructed a series of datasets with different characteristics, focusing on parameters such as duration, size, resolution, etc., and covering various monitoring environments and scenarios, providing an important reference basis for the research of crowd anomaly recognition. Commonly used datasets mainly include UCSD, UMN, Shanghai-Tech, CUHK-Avenue, and other related datasets.
Figure 20 shows some abnormal behavior samples in these four abnormal behavior datasets.
5.1.1. UCSD
The UCSD dataset [
88] is a dataset for crowd behavior analysis and abnormal detection. The dataset contains two subsets, Ped1 and Ped2. The Ped1 subset includes 34 video clips, recording the pedestrian activities from the campus crosswalk scene; the Ped2 subset provides 12 video clips of the same specification, presenting similar but different pedestrian crossing area activities.
5.1.2. UMN
The UMN dataset [
89] is mainly used for the evaluation and research of pedestrian detection and tracking algorithms. This dataset consists of 19 videos, including a series of pedestrian video sequences in complex backgrounds, providing various indoor and outdoor environments such as campuses, shopping malls, streets, and other pedestrian activity video clips in different backgrounds.
5.1.3. ShanghaiTech
The ShanghaiTech dataset [
90] is a dataset for video abnormal detection and crowd counting. This dataset has 13 complex scenes, recording the pedestrian flow on the campus. It also contains 130 abnormal events (such as fighting, falling, running, etc.) and more than 270,000 training frames, with a duration ranging from about 30 s to 90 s.
5.1.4. CUHK-Avenue
The CUHK database [
91] is a database about crowd behavior scenes. It includes crowd videos collected from many different environments with different densities and perspective ratios, such as streets, shopping centers, airports, and parks. It consists of traffic datasets and pedestrian datasets. There are a total of 474 video clips in 215 scenes in the dataset.
Table 5 summarizes and compares the above commonly used datasets of crowd abnormal behaviors from the dimensions of scene description, scale, abnormal behavior, video resolution, objects, and limitations of the dataset.
5.2. Experimental Evaluation Indicators
The evaluation of abnormal crowd behavior recognition integrates multiple indicators to ensure that the recognition is not only accurate but also precisely located. During the evaluation, frame-level and pixel-level standards are usually considered. Frame-level detection focuses on determining whether there is any abnormality within the video frame. Even if the specific location of the abnormality is not precise, as long as there is abnormal behavior in the frame, the entire frame is marked as abnormal; the pixel-level standard further requires the precise positioning of the spatial location of the abnormal behavior, usually requiring that the predicted abnormal pixels cover at least 40% of the real abnormal area to evaluate the accuracy of abnormal positioning.
The performance of abnormal crowd behavior recognition is usually evaluated by indicators such as the confusion matrix, ROC curve and AUC, and Equal Error Rate (EER).
By comprehensively considering the four basic indicators of True Positive (TP), True Negative (TN), False Positive (FP), and False Negative (FN), the confusion matrix is used for basic classification performance evaluation.
The ROC curve depicts the classification performance of the algorithm through the changes in True Positive Rate (TPR) and False Positive Rate (FPR). AUC, that is, the area under the ROC curve, reflects the average performance of the classifier under all thresholds. The closer the AUC value is to 1, the better the performance of the classifier.
It is defined as the error classification rate when the True Positive Rate is equal to the False Positive Rate. The smaller the EER value, the better the performance of the abnormal detection method because it balances missed alarms and false alarms and is an important indicator to measure the performance of a binary classification system.
5.3. Experimental Comparison
Table 6 summarizes the performance of traditional methods and deep learning-based abnormal behavior recognition methods on UCSD, UMN, Shanghai Tech, and Avenue datasets in recent years. This paper compares and presents evaluation indicators such as AUC and EER. These evaluation data are all cited from research papers in recent years.
According to the comparison of the experimental results, the following conclusions can be drawn:
(1) The limitations of recognition technologies. Although most methods have achieved high recognition rates on some datasets, on datasets such as UCSDPed1, the EER and AUC values of many methods indicate that there are certain false alarms or missed alarms, meaning that there is still room for further optimization of abnormal behavior recognition technology, especially when dealing with specific types of data or complex scenarios;
(2) The advantages of temporal models. Two-dimensional convolutional networks that only rely on spatial features often perform worse in abnormal behavior recognition tasks than those models that integrate optical flow features, 3D convolution, and LSTM. These models incorporate temporal information and can more comprehensively capture the dynamic changes in video sequences, not only considering spatial features but also in-depth analysis of the continuity and change trends of behavior patterns in the time dimension;
(3) The advantages of Autoencoder Network. The hidden feature representation learning method based on the autoencoder network is usually superior to the similarity measurement method in terms of automatic feature learning, adaptability, and generalization ability. It is suitable for processing large-scale, high-dimensional, and complex abnormal behavior recognition tasks, especially in the unsupervised learning paradigm, and it can effectively learn the low-dimensional representation of high-dimensional data;
(4) The advantages of self-attention mechanism. The introduction of the self-attention mechanism significantly improves the accuracy and efficiency of abnormal behavior recognition. This mechanism enhances the model’s ability to capture long-distance dependencies in the sequence. By allowing the model to dynamically adjust the degree of attention to different parts of the input, key features can be extracted more effectively, promoting the abnormal behavior recognition technology to a new height.
6. Conclusions
This review conducts a comprehensive and in-depth study of abnormal crowd behavior recognition technology, performing detailed analyses from four dimensions: basic definitions, traditional methods, deep learning, and performance indicators. Through a clear classification of crowd levels, “crowd density” is quantified and divided into five levels. Next, this study analyzes recognition techniques for traditional abnormal behavior based on statistical models, motion features, dynamic models, and cluster discrimination. Although these methods are effective in specific scenarios, they still have limitations in dealing with high-dimensional, nonlinear, and complex dynamic data, such as reliance on manually designed features and limited generalization ability.
With the development of AI technologies, deep learning has become a research hotspot because of its strong automatic feature learning ability and good adaptability to complex patterns. This article discusses the methods based on the Convolutional Neural Network (CNN), Generative Adversarial Network (GAN), Long Short-Term Memory Network (LSTM), Autoencoder (AE), and Self-Attention Mechanism (SA) in detail, demonstrating their outstanding performance in abnormal behavior recognition. These methods can extract high-level features from raw data and effectively distinguish between normal and abnormal behaviors, thereby improving recognition accuracy and robustness.
In conclusion, by comparing the performance indicators of each algorithm model in
Table 4 and
Table 6, it can be found that deep learning methods show significant advantages in dealing with complex and changeable scenarios. Although each model has its application scope and limitations, combining different methods can achieve better results. For example, algorithms such as S2-VAE, TS-CNN, and SA-CNN have achieved recognition accuracy of more than 99% in dealing with some datasets in
Table 6. Therefore, in practical applications, choosing the appropriate single model or combining multiple methods based on specific requirements can effectively enhance the overall performance of the abnormal behavior recognition system and achieve more accurate and reliable detection results.
Future research can focus on improving the fusion ability of deep learning and multi-modalities, introducing context understanding and situational reasoning, and improving the robustness and adaptive learning ability of the model. It can help further broaden the recognition of multi-source and multi-dimensional data fusion, construct a self-consistent metaverse virtual–real fusion evolution model, and establish a “perception-prediction-intervention-construction” virtual–real fusion presentation mechanism. The continuous innovations in this field are expected to achieve a transformation from passive monitoring to active prevention in the future and focus on more intelligent, precise, and automated abnormal behavior recognition systems.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}