

An Investigation into the Utilisation of CNN with LSTM for Video Deepfake Detection


Abstract
1. Introduction
- Conducting a comprehensive investigation of the current landscape of state-of-the-art video deepfake detection studies and tools that leverage CNN with LSTM.
- Identifying the most common feature extraction techniques employed within video deepfake detection techniques utilising CNN with LSTM.
- Examining the most commonly used datasets in the development and evaluation of video deepfake detection techniques that integrate CNN with LSTM and evaluating their performance.
- Investigating the key factors that have the most significant influence on detection accuracy when employing CNN with LSTM in video deepfake detection.
- Comparing the effectiveness of CNN-LSTM models against alternative models that do not incorporate LSTM in video deepfake detection.
- Examining the challenges of implementing CNN-LSTM-based video deepfake detection systems and offering insights into possible solutions.
- Investigating open issues and future research directions regarding the integration of CNN with LSTM in video deepfake detection.
2. Video Deepfake Detection with CNN-LSTM
2.1. Deepfake Creation and Detection
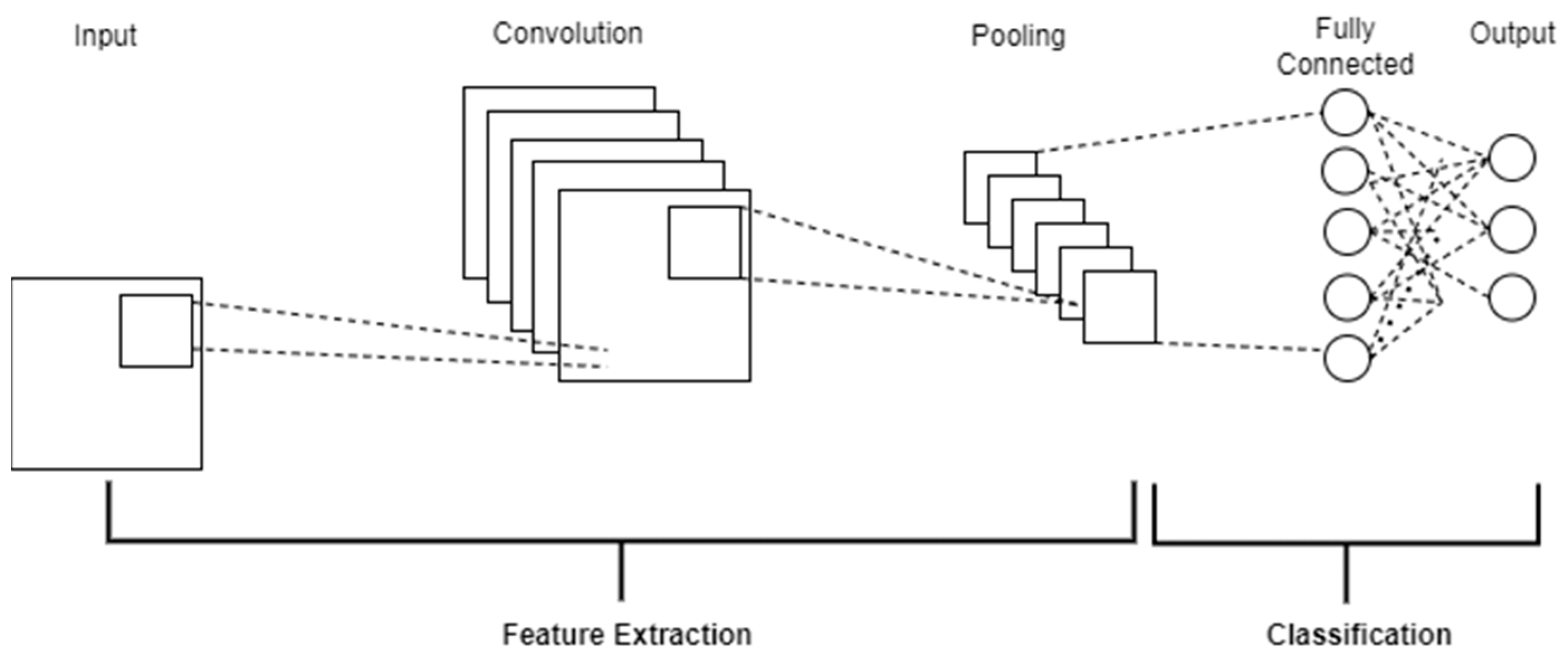
2.2. Convolutional Neural Network (CNN)
- and are the input functions;
- is the integration variable;
- is the convolution of and evaluated at
2.3. Long Short-Term Memory (LSTM)
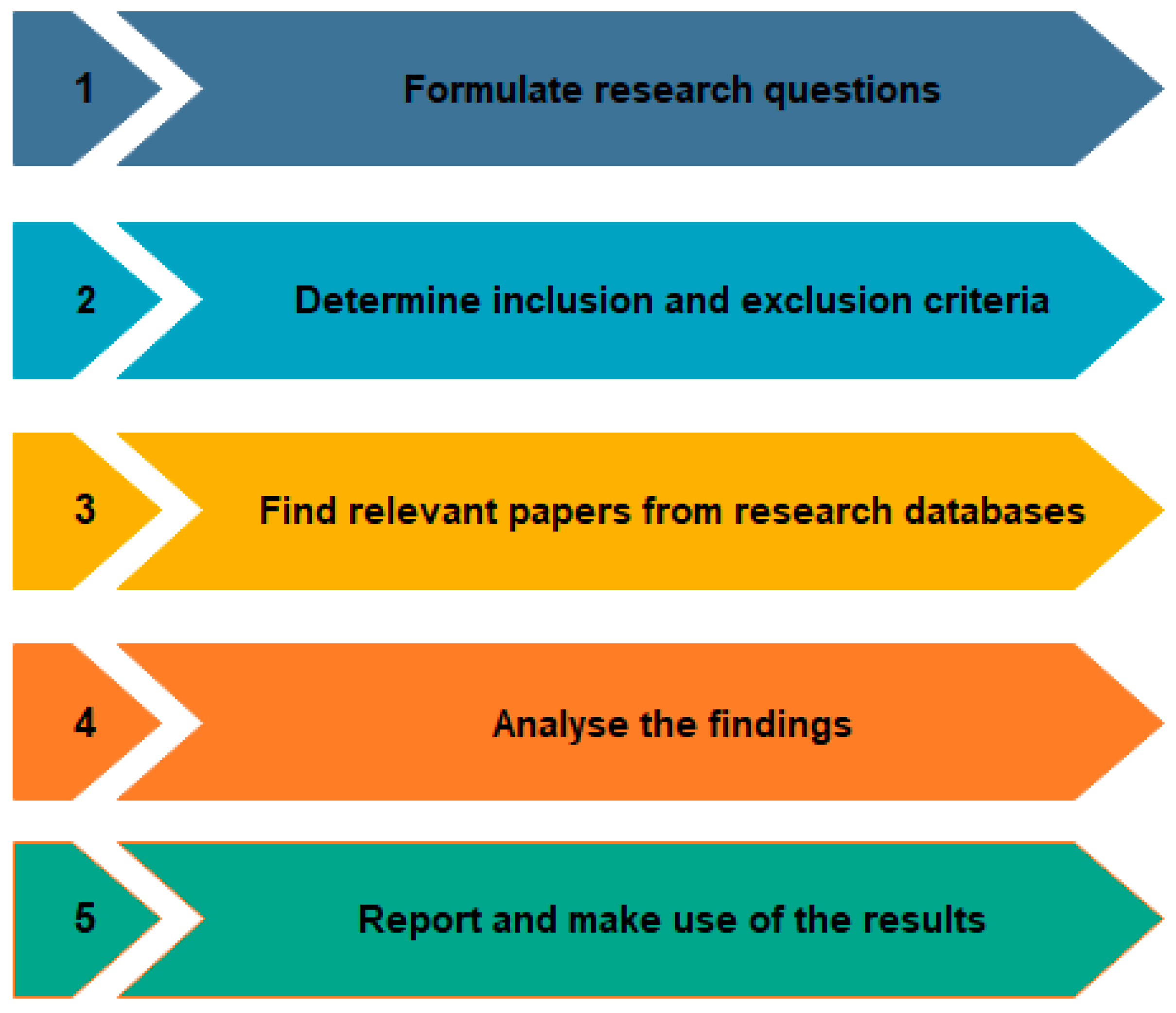
3. Research Methodology
3.1. Research Questions
- RQ1: What is the current landscape of state-of-the-art video deepfake detection studies that utilise CNN with LSTM?
- RQ2: What are the most common feature extraction techniques used in video deepfake detection tools that utilise CNN with LSTM?
- RQ3: What are the most common datasets used in the implementation of video deepfake detection tools that utilise CNN with LSTM?
- RQ4: What are the factors that have the strongest influence on detection accuracy for video deepfake detection when implementing CNN with LSTM?
- RQ5: Is using CNN with LSTM more effective for video deepfake detection compared to models that do not utilise LSTM?
- RQ6: What are the challenges involved in implementing video deepfake detection using CNN with LSTM?
3.2. Inclusion and Exclusion Criteria
- Peer-reviewed journals and conference articles to ensure high-quality and credible sources.
- Relevant to the specific research questions.
- Topic mainly on video deepfake detection using CNN and LSTM.
- Full and available articles to allow for a comprehensive review of the content.
- English-language articles to maintain consistency in analysis.
- Articles concerning all other aspects of combining CNN and LSTM apart from video deepfake detection.
- Articles focused on video deepfake detection that do not discuss CNN and LSTM.
- Unpublished articles, non-peer-reviewed articles, and editorial articles to ensure credibility.
- Articles that are not fully available.
- Non-English articles to avoid translation issues and maintain analysis consistency.
- Duplicates of already included articles to avoid redundancy.
3.3. Data Sources
- IEEE Xplore
- Google Scholar
- ACM Digital Library
- SpringerLink
- PubMed
- Elsevier ScienceDirect
3.4. Keywords
- Video deepfake detection
- Convolutional Neural Network (CNN)
- CNNs in video deepfake detection
- LSTM in video deepfake detection
- Long Short-Term Memory (LSTM)
- Deepfake detection techniques
- CNN-LSTM hybrid models
- Deepfake detection datasets
- Temporal feature extraction
- Deepfake detection feature extraction techniques
3.5. Selection of Relevant Articles
- Phase 1—Identification: Publications found during the search and those already in the collection were sorted using the inclusion and exclusion criteria. The scope of the search was narrowed to include only articles published recently.
- Phase 2—Screening: The titles and abstracts of the articles collected from several digital libraries were reviewed to determine how well they addressed the topic and the questions posed in this research work.
- Phase 3—Eligibility: During this stage, we focused on eliminating duplicates among the six digital libraries used for our publication collection.
4. Analysis of the Results
5. Results and Discussion
6. Open Issues and Future Research Directions
6.1. Real-Time Detection
6.2. Generalisation
6.3. Lack of Standardised Performance Metrics
6.4. Multimodal Deepfake Detection
6.5. Detecting Low-Quality and Compressed Deepfakes
6.6. Ethical and Privacy Concerns
6.7. Adversarial Training and Attacks
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Agre, P.; Rotenberg, M. Technology and Privacy: The New Landscape; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Chintha, A.; Thai, B.; Sohrawardi, S.J.; Bhatt, K.; Hickerson, A.; Wright, M.; Ptucha, R. Recurrent Convolutional Structures for Audio Spoof and Video Deepfake Detection. IEEE J. Sel. Top. Signal Process. 2020, 14, 1024–1037. [Google Scholar] [CrossRef]
- Lyu, S. DeepFake Detection: Current Challenges and Next Steps. arXiv 2020, arXiv:2003.09234. [Google Scholar]
- Santha, A. Deepfakes Generation Using LSTM Based Generative Adversarial Networks Networks. 2020. Available online: https://www.geeksforgeeks.org/deep-learning-introduction-to-long-short-term-memory/ (accessed on 20 November 2023).
- Rocca, J. Understanding Variational Autoencoders (VAEs). Medium. 2019. Available online: https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73 (accessed on 20 November 2023).
- Liu, Y.; Li, Q.; Deng, Q.; Sun, Z.; Yang, M.H. GAN-Based Facial Attribute Manipulation. arXiv 2022, arXiv:2210.12683. [Google Scholar] [CrossRef] [PubMed]
- Zobaed, S.; Rabby, F.; Hossain, I.; Hossain, E.; Hasan, S.; Karim, A.; Md. Hasib, K. DeepFakes: Detecting Forged and Synthetic Media Content Using Machine Learning. In Artificial Intelligence in Cyber Security: Impact and Implications: Security Challenges, Technical and Ethical Issues, Forensic Investigative Challenges; Montasari, R., Jahankhani, H., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 177–201. [Google Scholar] [CrossRef]
- Baldi, P. Autoencoders, Unsupervised Learning, and Deep Architectures. In Proceedings of the ICML Workshop on Unsupervised and Transfer Learning, Bellevue, WA, USA, 2 July 2011; Volume 27. [Google Scholar]
- OValery. Swap-Face. 2017. Available online: https://github.com/OValery16/swap-face (accessed on 4 October 2024).
- Xu, F.J.; Wang, R.; Huang, Y.; Guo, Q.; Ma, L.; Liu, Y. Countering Malicious DeepFakes: Survey, Battleground, and Horizon. arXiv 2021, arXiv:2103.00218. [Google Scholar]
- Verdoliva, L. Media Forensics and DeepFakes: An Overview. IEEE J. Sel. Top. Signal Process. 2020, 14, 910–932. [Google Scholar] [CrossRef]
- Agarwal, S.; Farid, H.; Fried, O.; Agrawala, M. Detecting Deep-Fake Videos from Phoneme-Viseme Mismatches. 2020. Available online: www.instagram.com/bill_posters_uk (accessed on 3 October 2024).
- Chugh, K.; Gupta, P.; Dhall, A.; Subramanian, R. Not Made for Each Other-Audio-Visual Dissonance-Based Deepfake Detection and Localization; Association for Computing Machinery: New York, NY, USA, 2020; pp. 439–447. [Google Scholar]
- Masi, I.; Killekar, A.; Mascarenhas, R.M.; Gurudatt, S.P.; AbdAlmageed, W. Two-branch Recurrent Network for Isolating Deepfakes in Videos. arXiv 2020, arXiv:2008.03412. [Google Scholar]
- de Lima, O.; Franklin, S.; Basu, S.; Karwoski, B.; George, A. Deepfake Detection using Spatiotemporal Convolutional Networks. arXiv 2020, arXiv:2006.14749. [Google Scholar]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional Neural Networks: An Overview and Application in Radiology; Insights into Imaging; Springer: Berlin/Heidelberg, Germany, 2018; Volume 9, pp. 611–629. [Google Scholar]
- Nunnari, G.; Calvari, S. Exploring Convolutional Neural Networks for the Thermal Image Classification of Volcanic Activity. Geomatics 2024, 4, 124–137. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Keita, Z. An Introduction to Convolutional Neural Networks (CNNs). 2023. Available online: https://www.datacamp.com/tutorial/introduction-to-convolutional-neural-networks-cnns (accessed on 25 April 2024).
- Wu, H.; Gu, X. Towards dropout training for convolutional neural networks. Neural Netw. 2015, 71, 1–10. [Google Scholar] [CrossRef]
- More, Y.; Dumbre, K.; Shiragapur, B. Horizontal Max Pooling a Novel Approach for Noise Reduction in Max Pooling for Better Feature Detect. In Proceedings of the 2023 International Conference on Emerging Smart Computing and Informatics (ESCI), Pune, India, 1–3 March 2023; pp. 1–5. [Google Scholar]
- Mishra, M. Convolutional Neural Networks, Explained. 2020. Available online: https://towardsdatascience.com/convolutional-neural-networks-explained-9cc5188c4939 (accessed on 25 April 2024).
- Jain, A.; Korshunov, P.; Marcel, S. Improving Generalization of Deepfake Detection by Training for Attribution. In Proceedings of the 2021 IEEE 23rd International Workshop on Multimedia Signal Processing (MMSP), Tampere, Finland, 6–8 October 2021; pp. 1–6. [Google Scholar]
- Graves, A. Long Short-Term Memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Graves, A., Ed.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar] [CrossRef]
- Saraswathi, R.V.; Gadwalkar, M.; Midhun, S.S.; Goud, G.N.; Vidavaluri, A. Detection of Synthesized Videos using CNN. In Proceedings of the International Conference on Augmented Intelligence and Sustainable Systems, ICAISS 2022, Trichy, India, 24–26 November 2022; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2022. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. Available online: https://www.sciencedirect.com/science/article/pii/S0893608005001206 (accessed on 4 October 2024). [CrossRef] [PubMed]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, n71. Available online: https://www.bmj.com/content/372/bmj.n71 (accessed on 3 October 2024). [CrossRef] [PubMed]
- Nightingale, A. A guide to systematic literature reviews. Surgery 2009, 27, 381–384. Available online: https://www.sciencedirect.com/science/article/pii/S0263931909001707 (accessed on 4 October 2024). [CrossRef]
- Easterbrook, P.J.; Gopalan, R.; Berlin, J.A.; Matthews, D.R. Publication bias in clinical research. Lancet 1991, 337, 867–872. [Google Scholar] [CrossRef]
- Al-Adwan, A.; Alazzam, H.; Al-Anbaki, N.; Alduweib, E. Detection of Deepfake Media Using a Hybrid CNN–RNN Model and Particle Swarm Optimization (PSO) Algorithm. Computers 2024, 13, 99. [Google Scholar] [CrossRef]
- Al-Dhabi, Y.; Zhang, S. Deepfake Video Detection by Combining Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN). In Proceedings of the 2021 IEEE International Conference on Computer Science, Artificial Intelligence and Electronic Engineering, CSAIEE 2021, Virtual, 20–22 August 2021; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2021; pp. 236–241. [Google Scholar]
- Al-Dulaimi, O.A.H.H.; Kurnaz, S. A Hybrid CNN-LSTM Approach for Precision Deepfake Image Detection Based on Transfer Learning. Electronics 2024, 13, 1662. [Google Scholar] [CrossRef]
- Amerini, I.; Caldelli, R. Exploiting Prediction Error Inconsistencies through LSTM-based Classifiers to Detect Deepfake Videos. In Proceedings of the IH and MMSec 2020, 2020 ACM Workshop on Information Hiding and Multimedia Security, New York, NY, USA, 22–24 June 2020; Association for Computing Machinery, Inc.: New York, NY, USA, 2020; pp. 97–102. [Google Scholar]
- Chan, K.; Chun, C.; Kumar, V.; Delaney, S.; Gochoo, M. Combating Deepfakes: Multi-LSTM and Blockchain as Proof of Authenticity for Digital Media. In Proceedings of the 2020 IEEE/ITU International Conference on Artificial Intelligence for Good (AI4G), Geneva, Switzerland, 21–25 September 2020. [Google Scholar]
- Chen, B.; Li, T.; Ding, W. Detecting deepfake videos based on spatiotemporal attention and convolutional LSTM. Inf. Sci. 2022, 601, 58–70. [Google Scholar] [CrossRef]
- Chinchalkar, R.; Sinha, R.; Kumar, M.; Chauhan, N.; Deokar, S.; Gonge, S. Detecting Deepfakes Using CNN and LSTM. In Proceedings of the 2023 2nd International Conference on Informatics, ICI 2023, Noida, India, 23–25 November 2023; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2023. [Google Scholar]
- Hasan Fuad, M.T.; Bin Amin, F.; Masudul Ahsan, S.M. Deepfake Detection from Face-swapped Videos Using Transfer Learning Approach. In Proceedings of the 2023 26th International Conference on Computer and Information Technology, ICCIT 2023, Cox’s Bazar, Bangladesh, 13–15 December 2023; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2023. [Google Scholar]
- Gravina, M.; Galli, A.; De Micco, G.; Marrone, S.; Fiameni, G.; Sansone, C. FEAD-D: Facial Expression Analysis in Deepfake Detection. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer Science and Business Media Deutschland GmbH: Berlin, Germany, 2023; pp. 283–294. [Google Scholar]
- Güera, D.; Delp, E.J. Deepfake Video Detection Using Recurrent Neural Networks. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Hashmi, M.F.; Ashish, B.K.K.; Keskar, A.G.; Bokde, N.D.; Yoon, J.H.; Geem, Z.W. An Exploratory Analysis on Visual Counterfeits Using Conv-LSTM Hybrid Architecture. IEEE Access 2020, 8, 101293–101308. [Google Scholar] [CrossRef]
- Jaiswal, G. Hybrid Recurrent Deep Learning Model for DeepFake Video Detection. In Proceedings of the 2021 IEEE 8th Uttar Pradesh Section International Conference on Electrical, Electronics and Computer Engineering, UPCON 2021, Dehradun, India, 11–13 November 2021; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2021. [Google Scholar]
- Jalui, K.; Jagtap, A.; Sharma, S.; Mary, G.; Fernandes, R.; Kolhekar, M. Synthetic Content Detection in Deepfake Video Using Deep Learning. In Proceedings of the 2022 IEEE 3rd Global Conference for Advancement in Technology, GCAT 2022, Bangalore, India, 7–9 October 2022; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2022. [Google Scholar]
- Jindal, A. Deepfake Video Forgery Detection. 2023. Available online: https://link.springer.com/chapter/10.1007/978-3-031-12413-6_53 (accessed on 3 October 2024).
- John, J.; Sherif, B.V. Multi-model DeepFake Detection Using Deep and Temporal Features. In Lecture Notes in Networks and Systems; Springer Science and Business Media Deutschland GmbH: Berlin, Germany, 2022; pp. 672–684. [Google Scholar]
- Jolly, V.; Telrandhe, M.; Kasat, A.; Shitole, A.; Gawande, K. CNN based Deep Learning model for Deepfake Detection. In Proceedings of the 2022 2nd Asian Conference on Innovation in Technology, ASIANCON 2022, Ravet, India, 26–28 August 2022; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2022. [Google Scholar]
- Jungare, M.; Ganganmale, P.; Khandagale, R.; Dhamane, S.; Susar, A. DeepFake Detection Model Using LSTM-CNN with Image and Temporal Video Analysis. Int. J. All Res. Educ. Sci. Methods 2024, 12, 94–99. Available online: www.ijaresm.com (accessed on 3 October 2024).
- Kaur, S.; Kumar, P.; Kumaraguru, P. Deepfakes: Temporal sequential analysis to detect face-swapped video clips using convolutional long short-term memory. J. Electron. Imaging 2020, 29, 033013. [Google Scholar] [CrossRef]
- Koshy, R.; Mahmood, A. Enhanced deep learning architectures for face liveness detection for static and video sequences. Entropy 2020, 22, 1186. [Google Scholar] [CrossRef] [PubMed]
- Kukanov, I.; Karttunen, J.; Sillanpää, H.; Hautamäki, V. Cost Sensitive Optimization of Deepfake Detector. In Proceedings of the APSIPA Annual Summit and Conference, Auckland, New Zealand, 7–10 December 2020; Available online: https://ieeexplore.ieee.org/abstract/document/9306476/ (accessed on 4 October 2024).
- Lai, Z.; Wang, Y.; Feng, R.; Hu, X.; Xu, H. Multi-Feature Fusion Based Deepfake Face Forgery Video Detection. Systems 2022, 10, 31. [Google Scholar] [CrossRef]
- Li, Y.; Chang, M.C.; Lyu, S. In Ictu Oculi: Exposing AI Created Fake Videos by Detecting Eye Blinking. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; Available online: https://ieeexplore.ieee.org/abstract/document/8630787 (accessed on 4 October 2024).
- Liang, P.; Liu, G.; Xiong, Z.; Fan, H.; Zhu, H.; Zhang, X. A facial geometry based detection model for face manipulation using CNN-LSTM architecture. Inf. Sci. 2023, 633, 370–383. [Google Scholar] [CrossRef]
- Malik, M.H.; Ghous, H.; Qadri, S.; Ali Nawaz, S.; Anwar, A.; Author, C. Frequency-based Deep-Fake Video Detection using Deep Learning Methods. J. Comput. Biomed. Inform. 2023, 4, 41–48. [Google Scholar] [CrossRef]
- Nawaz, M.; Javed, A.; Irtaza, A. Convolutional long short-term memory-based approach for deepfakes detection from videos. Multimed. Tools Appl. 2023, 83, 16977–17000. [Google Scholar] [CrossRef]
- Parayil, A.M.; Masood, A.; Ajas, M.; Tharun, R.; Usha, K. Deepfake Detection Using Xception and LSTM. Int. Res. J. Mod. Eng. Technol. Sci. 2023, 5, 9191–9196. [Google Scholar] [CrossRef]
- Patel, S.; Chandra, S.K.; Jain, A. DeepFake Videos Detection and Classification Using Resnext and LSTM Neural Network. In Proceedings of the 2023 3rd International Conference on Smart Generation Computing, Communication and Networking, SMART GENCON 2023, Bangalore, India, 29–31 December 2023; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2023. [Google Scholar]
- Ritter, P.; Lucian, D.; Anderies; Chowanda, A. Comparative Analysis and Evaluation of CNN Models for Deepfake Detection. In Proceedings of the 2023 4th International Conference on Artificial Intelligence and Data Sciences: Discovering Technological Advancement in Artificial Intelligence and Data Science, AiDAS 2023, Ipoh, Malaysia, 6–7 September 2023; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2023; pp. 250–255. [Google Scholar]
- Saealal, M.S.; Ibrahim, M.Z.; Mulvaney, D.J.; Shapiai, M.I.; Fadilah, N. Using cascade CNN-LSTM-FCNs to identify AIaltered video based on eye state sequence. PLoS ONE 2022, 17, e0278989. [Google Scholar] [CrossRef]
- Saif, S.; Tehseen, S.; Ali, S.S.; Kausar, S.; Jameel, A. Generalized Deepfake Video Detection Through Time-Distribution and Metric Learning. IT Prof. 2022, 24, 38–44. [Google Scholar] [CrossRef]
- Saikia, P.; Dholaria, D.; Yadav, P.; Patel, V.; Roy, M. A Hybrid CNN-LSTM model for Video Deepfake Detection by Leveraging Optical Flow Features. In Proceedings of the International Joint Conference on Neural Networks, Padua, Italy, 18–23 July 2022; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2022. [Google Scholar]
- Shende, A.; Paliwal, S.; Mahay, T.K. Using deep learning to detect deepfake videos. Turk. J. Comput. Math. Educ. 2021, 12, 5012–5017. [Google Scholar]
- Singh, A.; Saimbhi, A.S.; Singh, N.; Mittal, M. DeepFake Video Detection: A Time-Distributed Approach. SN Comput. Sci. 2020, 1, 212. [Google Scholar] [CrossRef]
- Sooda, K. DeepFake Detection Through Key Video Frame Extraction using GAN. In Proceedings of the International Conference on Automation, Computing and Renewable Systems, ICACRS 2022, Pudukkottai, India, 13–15 December 2022; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2022; pp. 859–863. [Google Scholar]
- Stanciu, D.C.; Ionescu, B. Deepfake Video Detection with Facial Features and Long-Short Term Memory Deep Networks. In Proceedings of the ISSCS 2021, International Symposium on Signals, Circuits and Systems, Iasi, Romania, 15–16 July 2021; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2021. [Google Scholar]
- Montserrat, D.M.; Hao, H.; Yarlagadda, S.K.; Baireddy, S.; Shao, R.; Horváth, J.; Bartusiak, E.; Yang, J.; Guera, D.; Zhu, F.; et al. Deepfakes detection with automatic face weighting. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 2851–2859. [Google Scholar]
- Suratkar, S.; Kazi, F. Deep Fake Video Detection Using Transfer Learning Approach. Arab. J. Sci. Eng. 2022, 48, 9727–9737. [Google Scholar] [CrossRef] [PubMed]
- Taviti, R.; Taviti, S.; Reddy, P.A.; Sankar, N.R.; Veneela, T.; Goud, P.B. Detecting Deepfakes with ResNext and LSTM: An Enhanced Feature Extraction and Classification Framework. In Proceedings of the 2023 International Conference on Signal Processing, Computation, Electronics, Power and Telecommunication, IConSCEPT 2023, Karaikal, India, 25–26 May 2023; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2023. [Google Scholar]
- Wubet, W.M. The Deepfake Challenges and Deepfake Video Detection. Int. J. Innov. Technol. Explor. Eng. 2020, 9, 789–796. Available online: https://www.ijitee.org/portfolio-item/E2779039520/ (accessed on 4 October 2024). [CrossRef]
- Yadav, P.; Jaswal, I.; Maravi, J.; Choudhary, V.; Khanna, G. DeepFake Detection Using InceptionResNetV2 and LSTM. In Proceedings of the International Conference on Emerging Technologies: AI, IoT, and CPS for Science Technology Applications, Chandigarh, India, 6–7 September 2021. [Google Scholar]
- Yesugade, T.; Kokate, S.; Patil, S.; Varma, R.; Pawar, S. Deepfake detection using LSTM-based neural network. In Object Detection by Stereo Vision Images; Wiley: Hoboken, NJ, USA, 2022; pp. 111–120. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv 2016, arXiv:1610.02357. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bansal, A.; Ma, S.; Ramanan, D.; Sheikh, Y. Recycle-gan: Unsupervised video retargeting. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 119–135. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multi-Task Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Horn, B.K.P.; Schunck, B.G. Determining optical flow. Artif. Intell. 1981, 17, 185–203. Available online: https://www.sciencedirect.com/science/article/pii/0004370281900242 (accessed on 4 October 2024). [CrossRef]
- Dolhansky, B.; Howes, R.; Pflaum, B.; Baram, N.; Ferrer, C.C. The Deepfake Detection Challenge (DFDC) Preview Dataset. arXiv 2019, arXiv:1910.08854. [Google Scholar]
- Rössler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. FaceForensics++: Learning to Detect Manipulated Facial Images. arXiv 2019, arXiv:1901.08971. [Google Scholar]
- Thies, J.; Zollhöfer, M.; Nießner, M. Deferred neural rendering: Image synthesis using neural textures. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-DF: A Large-Scale Challenging Dataset for DeepFake Forensics. arXiv 2019, arXiv:1909.12962. [Google Scholar]
- Korshunov, P.; Marcel, S. DeepFakes: A New Threat to Face Recognition? Assessment and Detection. arXiv 2018, arXiv:1812.08685. [Google Scholar]
- Jiang, L.; Li, R.; Wu, W.; Qian, C.; Loy, C.C. DeeperForensics-1.0: A Large-Scale Dataset for Real-World Face Forgery Detection. arXiv 2020, arXiv:2001.03024. [Google Scholar]
- Guilloux, L. FakeApp. 2019. Available online: https://www.malavida.com/en/soft/fakeapp/ (accessed on 29 January 2024).
- Brownlee, J. What Is the Difference Between a Batch and an Epoch in a Neural Network. Mach. Learn. Mastery 2018, 20, 1–5. [Google Scholar]
- Su, Y.; Xia, H.; Liang, Q.; Nie, W. Exposing DeepFake Videos Using Attention Based Convolutional LSTM Network. Neural Process Lett. 2021, 53, 4159–4175. [Google Scholar] [CrossRef]
- Xia, Z.; Qiao, T.; Xu, M.; Wu, X.; Han, L.; Chen, Y. Deepfake video detection based on MesoNet with preprocessing module. Symmetry 2022, 14, 939. [Google Scholar] [CrossRef]
- Selim, S. A Prize Winning Solution for DFDC Challenge. 2020. Available online: https://github.com/selimsef/dfdc_deepfake_challenge (accessed on 4 October 2024).
- Grönquist, P.; Ren, Y.; He, Q.; Verardo, A.; Süsstrunk, S. Efficient Temporally-Aware DeepFake Detection Using H. 264 Motion Vectors. arXiv 2023, arXiv:231110788. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Phase 1 | Phase 2 | Phase 3 |
|---|---|---|---|
| IEEE Xplore | 38 | 20 | 13 |
| Google Scholar | 210 | 18 | 10 |
| ACM Digital Library | 195 | 12 | 7 |
| SpringerLink | 139 | 9 | 6 |
| PubMed | 2 | 1 | 1 |
| Elsevier ScienceDirect | 90 | 13 | 8 |
| Total | 674 | 73 | 45 |
| ID | Author | Year | Publication Type |
|---|---|---|---|
| 1 | Al-Adwan et al. [31] | 2024 | Journal |
| 2 | Al-Dhabi and Zhang [32] | 2021 | Conference proceedings |
| 3 | Al-Dulaimi and Kurnaz [33] | 2024 | Journal |
| 4 | Amerini and Caldelli [34] | 2020 | Conference proceedings |
| 5 | Chan et al. [35] | 2020 | Conference proceedings |
| 6 | Chen, Li, and Ding [36] | 2022 | Journal |
| 7 | Chinchalkar et al. [37] | 2023 | Conference proceedings |
| 8 | Chintha et al. [2] | 2020 | Journal |
| 9 | Fuad, Amin, and Ahsan [38] | 2023 | Conference proceedings |
| 10 | Gravina et al. [39] | 2023 | Conference proceedings |
| 11 | Guera and Delp [40] | 2018 | Conference proceedings |
| 12 | Hashmi et al. [41] | 2020 | Journal |
| 13 | Jaiswal et al. [42] | 2021 | Journal |
| 14 | Jalui et al. [43] | 2022 | Conference proceedings |
| 15 | Jindal [44] | 2023 | Journal |
| 16 | John and Sherif [45] | 2022 | Conference proceedings |
| 17 | Jolly et al. [46] | 2022 | Conference proceedings |
| 18 | Jungare et al. [47] | 2024 | Journal |
| 19 | Kaur, Kumar, and Kumaraguru [48] | 2020 | Journal |
| 20 | Koshy and Mahmood [49] | 2020 | Journal |
| 21 | Kukanov et al. [50] | 2020 | Conference proceedings |
| 22 | Lai et al. [51] | 2022 | Journal |
| 23 | Li, Chang, and Lyu [52] | 2018 | Conference proceedings |
| 24 | Liang et al. [53] | 2023 | Journal |
| 25 | Malik et al. [54] | 2023 | Journal |
| 26 | Masi et al. [14] | 2020 | Conference proceedings |
| 27 | Masud et al. [38] | 2023 | Journal |
| 28 | Nawaz, Javed, and Irtaza [55] | 2023 | Journal |
| 29 | Parayil et al. [56] | 2023 | Journal |
| 30 | Patel, Chandra, and Jain [57] | 2023 | Conference proceedings |
| 31 | Ritter et al. [58] | 2023 | Conference proceedings |
| 32 | Saealal et al. [59] | 2022 | Journal |
| 33 | Saif et al. [60] | 2022 | Journal |
| 34 | Saikia et al. [61] | 2022 | Conference proceedings |
| 35 | Saraswathi et al. [25] | 2022 | Conference proceedings |
| 36 | Shende, Paliwal, and Mahay [62] | 2021 | Journal |
| 37 | Singh et al. [63] | 2020 | Journal |
| 38 | Sooda [64] | 2022 | Conference proceedings |
| 39 | Stanciu and Ionescu [65] | 2021 | Conference proceedings |
| 40 | Su et al. [66] | 2021 | Journal |
| 41 | Suratkar and Kazi [67] | 2022 | Journal |
| 42 | Taviti et al. [68] | 2023 | Conference proceedings |
| 43 | Wubet [69] | 2020 | Journal |
| 44 | Yadav et al. [70] | 2021 | Conference proceedings |
| 45 | Yesugade et al. [71] | 2022 | Book chapter |
| Citation | Summary of Contribution | Limitations |
|---|---|---|
| Al-Adwan et al. [31] | The paper proposes a model that combines CNN with LSTM architecture, where the weight and bias values are initialised using Particle Swarm Optimisation (PSO), which is finetuned on a validation set to obtain the optimal parameters for performance. | The failure of accuracy to improve with increased iterations points to a limitation in the training process or model architecture. |
| Al-Dhabi and Zhang [32] | The paper proposes a model that uses ResNeXt-50 with LSTM and bridges the gap between training and test accuracy on sequential frames of a video using different datasets, with an extremely low training loss of 0.0053. | The proposed model has a low accuracy as the frame rate input is reduced, diminishing its effectiveness. |
| Al-Dulaimi and Kurnaz [33] | The paper introduces a hybrid CNN-LSTM model for deepfake image detection, achieving 98.21% precision on benchmark datasets (DFDC, Ciplab). This approach effectively combines spatial and temporal analysis to improve deepfake identification accuracy, addressing a critical concern in digital media | The proposed model’s 0.26% error rate highlights the inherent difficulty of deepfake detection; further research is needed to improve robustness and generalisability. |
| Amerini and Caldelli [34] | The paper proposes a CNN-LSTM method that uses the prediction error from the current to the succeeding frame to determine whether deepfake content has been inserted into the video as it would modify the intrinsic structure of the sequence. | The proposed CNN-LSTM method performed very badly on strongly compressed data, reducing accuracy to 61%. |
| Chan et al. [35] | The paper provides a theoretical framework that enables proof of authenticity using LSTM as a deep encoder for creating unique discriminative features, which are compressed and hashed into a transaction. The content is validated and can then be traced back with a label verifying its authenticity as not deepfake. | The model makes the assumption that the uploaded content is not deepfake but could be integrated. Also, the maximum uploaded payload size is only 100 MB. |
| Chen, Li, and Ding [36] | The paper introduces a spatiotemporal attention mechanism using ConvLSTM to address the difficulties presented by Xception-LSTM-based algorithms in identifying deepfake videos. | The model runs the risk of overfitting and reduced generalisability from an increase in model complexity. |
| Chinchalkar et al. [37] | The paper proposes an RNN model that is trained on 150 frames per video to check for frame consistencies before using CNN ResNet architecture to retrieve frame-level characteristics, followed by RNN-LSTM to determine video authenticity. | The proposed model is trained on a high frame rate, reducing its generalisability to lower frame rate deepfake content. |
| Chintha et al. [2] | The paper uses a CNN to obtain a vector representation of the facial region within a frame before passing a sequence of frames to a bidirectional LSTM cell. The spatial features from the XceptionNet module are passed into bidirectional LSTM cells with a double pass to give 99.7% accuracy on the FF++ dataset. | The evaluation of the proposed detection method is based on specific datasets, potentially limiting the generalisability of the results. |
| Fuad, Amin, and Ahsan [38] | The paper proposes a model that uses a Wide CNN ResNet architecture with LSTM before inputting data into a multi-head attention layer, so the model selects essential features for stronger performance on video classification. | The generalisability of the findings to a broader range of deepfake manipulations is limited as the study focuses on a specific transfer learning approach. |
| Gravina et al. [39] | The paper proposes an InceptionNetV3 CNN with LSTM that shows that emotional analysis is a robust method of deepfake detection, aiming to identify how visual emotional artefacts in deepfake videos disrupt temporal coherence. | Facial expression and representation of emotion can vary amongst contexts and cultures, therefore making a non-biased baseline hard to establish. |
| Guera and Delp [40] | The paper proposes combining InceptionV3 CNN with LSTM for sequence processing without loss functions and performs with 97% accuracy on 40–80 frames. | Where a face is not fully present, such as a facial rotation, the model has a low accuracy of 40%. |
| Hashmi et al. [41] | The paper combines CNN for feature extraction and LSTM for storing feature vectors for frames instead of saving the frame itself to train large amounts of data without memory expense. | The proposed model’s feature extraction only detects key facial landmarks, not additional features such as noise or blur. |
| Jaiswal et al. [42] | The paper proposes a hybrid approach to deepfake detection using GRU and LSTM showing that CNN has higher performance metrics than when using LSTM alone, with particular emphasis on placing the GRU layers before the LSTM layers on the DFDC dataset. | The proposed model uses the same dataset for training and testing, reducing generalisability. |
| Jalui et al. [43] | The paper combines ResNeXt-50 for feature extraction with LSTM to train the model for classification whilst intentionally reducing the number of frames fed into the network, resulting in very high detection accuracy on the DFDC dataset. | The proposed model trains on 300 frames per video and uses the same dataset for training and testing, which is computationally expensive. |
| Jindal [44] | The paper proposes a model that adopts ResNeXt-50-32×4d architecture with LSTM dimensions of 2048 and 2048 hidden layers, concluding the architecture has stronger detection accuracy at 100 frames per video analysed in comparison to any value of frames below that. | The proposed model is computationally expensive, limiting its applicability where high-speed processing is required, despite achieving high accuracy. |
| John and Sherif [45] | The paper compares the performance accuracy of using temporal-based detection and triplet loss detection. A combination of a temporal model with a triplet deep model is created to obtain higher training and testing accuracy than standalone models. | The proposed model is limited to using a frame rate of 100 frames per second (fps), with higher frames per second improving accuracy. |
| Jolly et al. [46] | The paper proposes a model that uses a CNN-LSTM followed by a Recycle-GAN with a two-stream fusion, merging the spatial and temporal data to evaluate the data whilst pushing its results back to the start of the network for continuous learning. | The proposed model failed to detect any neural textures in generated deepfakes, demonstrating a critical weakness. |
| Jungare et al. [47] | The paper proposes a novel deepfake detection model using a ResNeXt-50 CNN and LSTM. Its key contribution is achieving 83.21% accuracy while processing only 10 frames, significantly improving efficiency. | The diminishing returns after 100 frames significantly limit the model’s ability to leverage longer video sequences for improved accuracy. |
| Kaur, Kumar, and Kumaraguru [48] | The paper proposes a C-LSTM model that uses CNN with LSTM to detect face-swapped politicians and achieves an accuracy of 98.21% for 0.99 precision and 0.93 recall values. | When the video subject consistently looks away, detection accuracy is compromised. |
| Koshy and Mahmood [49] | The paper proposes a CNN-LSTM model without a pre-processing stage, applying nonlinear diffusion to enhance liveness detection on video sequences as the CNN captures spatial information and the features obtained by the LSTM layer are classified as real or fake with a test accuracy of 96%. | The proposed model’s applicability is limited by its lack of testing on non-GAN-generated fake faces, a significant class of deepfakes. |
| Kukanov et al. [50] | The paper proposes a maximal figure-of-merit (MFoM) framework, which uses the detection cost function as its performance measure and the equal error rate (EER) to optimise measures of performance and view video deepfake detection as a cost-sensitive objective. The model then follows a CNN-LSTM-based approach to determine a reduction in the EER of detection. | The proposed model fails to detect deepfake content from YouTube videos, which is viewed as the ‘worst case’, although it is the most readily available deepfake content online. |
| Lai et al. [51] | The paper proposes a feature fusion detection model where feature extraction from spatial, temporal, and frequency domains occur at the same time. The results show that the error rate is higher without feature fusion or LSTM. | The proposed model lacks generalisability to datasets it was not trained on, indicating a high variance and low bias in its predictive capabilities. |
| Li, Chang, and Lyu [52] | In the paper, a long-term recurrent CNN is employed with LSTM to detect deepfakes using a lack of blinking by detecting the number of frames an eye is open and its temporal correlation to its preceding frame. The results conclude that deepfake videos have a blinking rate ten times lower than real videos. | The threshold set to determine an open or closed eye impacts detection, affecting the precision and recall of the overall eye-state classification system. |
| Liang et al. [53] | The paper proposes a model that combines facial geometry feature maps with CNN-LSTMs to decode and detect manipulations at a pixel-wise level. The model outperforms XceptionNet and CNN-based models on a range of datasets. | The proposed model is not robust as it relies on facial standards, which can change depending on expression or if something’s blocking the view. |
| Malik et al. [54] | The paper demonstrates that a CNN with LSTM requires a larger training set than a testing set compared to standalone CNN, with higher accuracy detected on the FF++ dataset with an 80/20 split than when a 70/30 split is used, outperforming previous works. | The proposed model lacks an analysis of how image distortions and noise can affect the accuracy of its deepfake detection. |
| Masi et al. [14] | The paper proposes a model that uses a CNN with bidirectional LSTM and a loss function to place real faces within an inner hypersphere and deepfake faces in an outer hypersphere. The model improves frame-level detection for videos with medium compression rates, increasing the AUC score from 92% to 99%. | The proposed model has a low ability to detect real faces that have facial hair or are poorly illuminated, resulting in a high rate of false negatives and reduced overall accuracy. |
| Masud et al. [38] | The paper proposes a lightweight VGG16 CNN-LSTM that is 152 times smaller than existing methods, significantly improving computational efficiency and reducing resource requirements. | Adding more than 128 LSTM layer units led to overfitting and reduced performance on the validation test set. |
| Nawaz, Javed, and Irtaza [55] | The paper introduces a new feature descriptor named Dense-Swish-121, which integrates convolutional layers, dense blocks, and transitional layers with a bi-LSTM approach. The model outperforms five CNN-LSTM models on the DFDC dataset, reaching 99.3% accuracy with Dense-Swish-Net121 despite having fewer parameters. | The choice of the ReLU activation function limited the model’s ability to detect subtle visual cues, resulting in reduced detection accuracy. |
| Parayil et al. [56] | The paper uses XceptionNet with LSTM, achieving a significant reduction in computational time compared to existing methods, while maintaining comparable or even superior accuracy | There is a large discrepancy and fluctuations between training and validation accuracy, indicating overfitting. |
| Patel, Chandra, and Jain [57] | The paper uses ResNeXt-50-32x4d with LSTM to determine whether a video is a deepfake or real with 85% accuracy using only 10 frames, which is equivalent to less than a second. | The proposed model is computationally expensive to analyse 300 frames of a video. |
| Ritter et al. [58] | The paper compares baselines and concludes that EfficientNetB7 is the most effective CNN model for detecting whether a video is real or deepfake using binary classification. | The model’s testing accuracy is lower than its training and validation accuracy, which is therefore indicative of overfitting. |
| Saealal et al. [59] | The paper detects deepfake content using eye-blinking patterns, where a lack of, or too frequent, blinking can indicate deepfake content. Using a batch size of 20 with 105 epochs, the model’s optimal results occurred at 95.57% on the FF+ dataset. | The proposed model poorly detects neural texture deepfakes, resulting in a higher rate of missed detections for this specific type of deepfake. |
| Saif et al. [60] | The paper uses a multi-stream CNN-LSTM network with contrastive performing the best using EfficientNetB7 architecture on the FF++ dataset with 97.3%. Introducing contrastive loss allowed the model to learn features independent of the deepfake generation method, which influences the FF++ dataset. | The proposed model struggles to detect expression-swapping deepfakes compared to face-synthesis deepfakes due to the subtler visual artefacts present in expression swaps. |
| Saikia et al. [61] | The paper combines optical flow during feature extraction, VGG16 CNN, and LSTM; this model’s performance fares 91% on the FF+ dataset with a reduced frame rate of 70 frames a second, indicating that optical flow can assist with the early detection of deepfakes. | The proposed model does not perform as well on the DFDC dataset, with low frame frames (20) producing a 0.5 accuracy. |
| Saraswathi et al. [25] | The paper combines ResNeXt-50-32x4d architecture with LSTM and concludes the model has higher performance metrics when trained for 40 epochs over 20 epochs when using a combination of FF+, DFDC, and Celeb-DF. | The proposed model selects the first 150 sequential frames; therefore, deepfake content after the 150th frame is ignored. |
| Shende, Paliwal, and Mahay [62] | The paper proposes a model that combines ResNeXt architecture with LSTM. The results demonstrate an accuracy of 94% on the Celeb-DF dataset. | The proposed model uses a small training and testing set so it is not very generalisable. |
| Singh et al. [63] | The paper compares backbone networks using the DFDC dataset and demonstrates that EfficientNet-B1 wrapped in a time-distributed layer followed by an LSTM layer resulted in the highest AUC sore and accuracy with 14 million fewer parameters than XceptionNet and InceptionNet backbones, with performances of 86% and 92%, respectively. | There is a trade-off between frame input size and computational power, meaning larger input sizes require significantly more processing power, limiting real-time applications. |
| Sooda [64] | The paper proposes a model that performed well with an accuracy of 97.25% on compressed videos (c = 23) at 13 epochs, where it became constant. The accuracy increased by 10% from 1 epoch to 13 epochs. | Because the model was trained using only a portion of the DFDC dataset, its accuracy decreased when merged with the FF++ dataset. |
| Stanciu and Ionescu [65] | The paper integrates Xception, LSTM, and the late fusion approach for combining outputs generated from facial regions to conclude that late fusion does not increase the AUC score using the Celeb-DF or FF++ datasets but provides a high-performing baseline for when only specific facial landmarks are deepfakes. | The model is computationally expensive, limiting its applicability to resource-constrained environments and real-time applications. |
| Su et al. [66] | The paper proposes adding a soft-attention mechanism based on weights to a CNN with LSTM which reduces the network’s calculation costs and increases classification accuracy. | The effectiveness of this approach is highly dependent on the specific characteristics of the dataset and task. |
| Suratkar and Kazi [67] | The paper uses EfficientNet architecture with LSTM on the DFDC and FF++ datasets and concludes that training a model using residual image autoencoders to capture high-frequency details and improve reconstruction quality gives a higher classification accuracy of 94.75%. | The proposed model is computationally expensive due to the large input size and the long training time. |
| Taviti et al. [68] | The paper tests ResNeXt-50-32x4d CNN with 3 LSTM layers. The results showed that accuracy stabilised at 60 frames on the Celeb-DF and DFDC datasets at 97%, but when combined with FF++, performance capped at 93% at 100 frames. | Accuracy stabilised at 60 frames per second, meaning efficiency stopped increasing with longer sequences, suggesting a potential bottleneck in the model’s architecture. |
| Wubet [69] | The paper proposed a VGG16 and ResNet-50-32x4d-based CNN-LSTM model that is trained on the MRL eye image dataset and tested on the UADFV dataset. The overall detection accuracy on real videos was over 90%. | The proposed model is unable to detect deepfakes from a diverse set of eyes, suggesting a bias in its training data or architecture. |
| Yadav et al. [70] | The paper uses transfer learning using InceptionResNetV2 CNN for feature extraction and an LSTM layer, where training for 40 epochs improved accuracy by 6.73% over 20 epochs. | The model’s input is the deepfake portion of the clip; therefore, it is not representative of deepfake videos where a real video feed is used. |
| Yesugade et al. [71] | The paper presents a novel ResNeXt-50-32x4d and LSTM-based deepfake detection model achieving 88.54% accuracy on the DFDC dataset, setting a new benchmark for performance. | The model only considers the first 150 frames as input, significantly reducing its practical usability for analysing longer videos. |
| Citation | Feature Extraction Technique | Description of the Feature Extraction Technique |
|---|---|---|
| Al-Adwan et al. [31] | Hybrid CNN-LSTM with PSO algorithm | The CNN and LSTM are pre-trained on a dataset to extract facial landmarks before the PSO algorithm finetunes the weightings and biases of the CNN and LSTM architecture. |
| Al-Dhabi and Zhang [32] | Pre-trained CNN (ResNeXt-50) with LSTM | Utilises a ResNeXt-50 CNN model for feature extraction from video frames with an LSTM layer with a 2048 input vector shape and 0.4 ReLU dropout rate to capture temporal discrepancies between frames. |
| Al-Dulaimi and Kurnaz [33] | Hybrid CNN-LSTM architecture | Utilises three convolutional layers with LSTM with max pooling and the ReLU activation function. |
| Amerini and Caldelli [34] | Prediction error with convolutional layer and LSTM-RNN ensemble | A bounding box around the face (256 × 256 pixels) is used as input, which is extracted from select video frames. Utilises prediction to detect deepfake faces. |
| Chan et al. [35] | Triplet LSTM-RNN autoencoder with VGGNet-16 backbone | Utilises a triplet LSTM-RNN autoencoder in conjunction with a VGGNet-16 backbone to capture spatial information within each frame and temporal relationships. |
| Chen, Li, and Ding [36] | Spatiotemporal attention mechanism with ConvLSTM and Xception CNN | Integrates a spatiotemporal attention mechanism to capture correlations between frames. The video is processed through Xception architecture before ConvLSTM is employed to extract spatiotemporal inconsistency features. |
| Chinchalkar et al. [37] | RNN-CNN-LSTM hybrid model | Utilises an RNN model trained on 150 frames per video after pre-processing to ensure frame consistency. Frame-level characteristics are extracted using a CNN (ResNeXt), followed by an RNN-LSTM to determine video authenticity. |
| Chintha et al. [2] | Xception CNN and bidirectional LSTM fusion with Python Dlib | Employs Dlib to locate facial regions within frames followed by linear smoothing filters. Utilises an Xception CNN to extract vector representations of facial regions from frames. |
| Fuad, Amin, and Ahsan [38] | Wide ResNet-CNN and LSTM attention layer | A pre-trained wide ResNet architecture is used for feature extraction and an LSTM layer to capture temporal data. Data are then input into a multi-head attention layer, so the model selects essential features. |
| Gravina et al. [39] | InceptionV3 for textural feature extraction | Utilises InceptionV3 CNN pre-trained on the ImageNet dataset for textural feature extraction and implements a separate CNN for emotion feature extraction. |
| Guera and Delp [40] | Pre-trained CNN (InceptionV3) with LSTM | Each frame’s features are extracted using the InceptionV3 model and the feature vectors are used as input into the LSTM. |
| Hashmi et al. [41] | Transfer learning with ResNet CNN and LSTM | Employs a pre-trained ResNet CNN where subsequent layers are removed to create a dedicated feature extractor network, which is input into an LSTM. |
| Jaiswal et al. [42] | Hybrid CNN-LSTM-GRU model with Gaussian blur pre-processing | The CNN learns spatial features by extracting frame-wise facial noise with Gaussian blur pre-processing. The extracted features are then fed into a multilayer LSTM-GRU model. |
| Jalui et al. [43] | Pre-trained CNN (ResNeXt) with LSTM | Adopts a 50-layer ResNeXt CNN architecture for feature extraction. The output of this CNN is a feature vector, which is passed into an LSTM network. |
| Jindal [44] | Pre-trained CNN (ResNeXt) with LSTM | Utilises ResNeXt-50, analysing the first 150 frames of each video and a 2048 dimensional LSTM. |
| John and Sherif [45] | ResNeXt CNN with deep triplet loss | ResNeXt architecture extracts temporal information whilst a deep model compares triplet images to distinguish between real or deepfake images. |
| Jolly et al. [46] | ResNet18 CNN with LSTM and Recycle-GAN fusion | Employs ResNet18 CNN followed by an LSTM layer and a Recycle-GAN two stream fusion to detect spatial–temporal inconsistencies. |
| Jungare et al. [47] | Pre-trained CNN (ResNeXt) with LSTM | Utilises ResNeXt-50 architecture with LSTM with an input of 150 frames for extraction. |
| Kaur, Kumar, and Kumaraguru [48] | CNN-LSTM | Utilises three convolutional layers and three max pooling layers for high-level feature extraction from each sequential video frame. The output is flattened and used as input to an LSTM. |
| Koshy and Mahmood [49] | Nonlinear anisotropic diffusion pre-processing with CNN | Applies nonlinear anisotropic diffusion to the frames of each input sequence for noise reduction, which is then fed into a CNN to capture spatial information, generating an output of 50 features per frame. |
| Kukanov et al. [50] | Pre-trained CNN (InceptionV3) with LSTM | A pre-trained InceptionV3 CNN is used for feature extraction and LSTM for temporal analysis of 20 frames. |
| Lai et al. [51] | Xception CNN with double-layer LSTM | Utilises Xception architecture for extracting spatial, frequency, and Pattern of Local Gravitational Force (PLGF) features from facial images. |
| Li, Chang, and Lyu [52] | Long-term recurrent CNN (LRCRN) with LSTM | Features are extracted using VGG-16 LRCN to find the temporal correlation between frames to detect the duration of the eyes remaining open. |
| Liang et al. [53] | Facial geometry landmarks module (FGLM) and U-Net | An FGLM acts as an encoder to extract facial landmark information, followed by feature map extraction using a U-Net network. |
| Malik et al. [54] | CNN-LSTM | Utilises a CNN model where pooling layers extract horizontal and diagonal edge features, and the fully connected layers map these features to the final output before inputting them into an LSTM network. |
| Masi et al. [14] | Pointwise CNN with bi-LSTM | A bidirectional LSTM processes facial sequences, followed by feature extraction using a pre-trained ImageNet network. |
| Masud et al. [38] | CNN (VGG-16) wrapped in a time-distributed layer | Utilises a time-distributed layer to wrap the VGG-16 encoder, generating an equal number of feature matrices to the processed frames, using one layer to learn from different frames. |
| Nawaz, Javed, and Irtaza [55] | Dense-Swish-Net-121 feature descriptor | Proposes a feature descriptor that integrates convolutional layers, dense blocks, and transitional layers with a bi-LSTM approach. |
| Parayil et al. [56] | Pre-trained CNN (Xception) with LSTM | Uses an Xception CNN for feature extraction using the 2048 dimensional feature vectors after the last pooling layer as sequential LSTM input. |
| Patel, Chandra, and Jain [57] | Pre-trained CNN (ResNeXt) architecture | Frame-level characteristics are extracted using a ResNeXt CNN model for feature extraction. |
| Ritter et al. [58] | Pre-trained CNN (EfficientNetB7) with LSTM | This experiment uses an EfficientNetB7 baseline accompanied by one LSTM layer to leverage temporal and sequential information. |
| Saealal et al. [59] | Pre-trained CNN (VGG-16) with LSTM | Utilises a pre-trained VGG-16 CNN to extract spatial information for each eye, followed by an LSTM for temporal feature extraction from the frame sequence. |
| Saif et al. [60] | Multi-stream CNN (EfficientNet-B3) with LSTM | Utilises a two-stream network to produce pairwise outputs before extracting features using a time-distributed EfficientNet-B3 CNN and LSTM. |
| Saikia et al. [61] | Optical flow analysis with CNN-LSTM | The optical flow for pairs of frames, represented as a three-channel image indicating magnitude and direction of motion, is used as input to a CNN-LSTM model with two LSTM layers following convolutional layers for temporal analysis. |
| Saraswathi et al. [25] | Pre-trained CNN (ResNeXt-50) with LSTM | ResNeXt-50 CNN retrieves the features from the frames, and after the final pooling layer, LSTM is the next sequential layer with 0.4 dropout. |
| Shende, Paliwal, and Mahay [62] | Pre-trained CNN (ResNeXt-50) with LSTM | Employs a ResNeXt-50 CNN followed by a single layer of LSTM for feature extraction and temporal analysis of frames. |
| Singh et al. [63] | MobileNet-Single shot detection (SSD) | Integrates MobileNet with SSD, a feed-forward convolutional network for object detection, to extract feature maps and apply convolutional filters. |
| Sooda [64] | CNN (ResNeXt-50)—GAN with LSTM | A GAN comprises a generator and discriminator, trained with a ResNeXt-50 CNN and LSTM to classify videos. |
| Stanciu and Ionescu [65] | Xception CNN with LSTM fusion | The Xception CNN outputs 60 feature vectors, which are input into a two-layer LSTM network. |
| Su et al. [66] | Multitask Cascaded Neural Network (MCNN) with EfficientNet-B5 and LSTM | An MCNN extracts face in pre-processing before an EfficientNet-B5 CNN extracts feature vectors. Subsequently, LSTM detects sequential inconsistencies. |
| Suratkar and Kazi [67] | EfficientNet CNN with LSTM | Frames are extracted using EfficientNet CNN, and the faces are saved instead of the full frame. The LSTM layer is used as input and is followed by two dense layers to classify the output. |
| Taviti et al. [68] | Pre-trained CNN (ResNeXt-50) with three LSTM layers | Extracts features using ResNeXt-50 architecture with ReLU to activate the convolutional layers followed by three LSTM layers. |
| Wubet [69] | VGG-16 and ResNet-50-based CNN with LSTM | A VGG16 and ResNet-50-based CNN model extracts features followed by an LSTM layer. |
| Yadav et al. [70] | InceptionResNetV2 CNN with LSTM | InceptionResNetV2 CNN is used for feature extraction followed by LSTM for temporal analysis. |
| Yesugade et al. [71] | Pre-trained CNN (ResNeXt-50) with LSTM | Utilises ResNeXt-50 architecture with LSTM for feature extraction and temporal analysis, with a dropout rate of 0.4 applied to the LSTM layer for regularisation. |
| Citation | ResNet | ResNeXt | Xception | InceptionNet | VGG-16 | EfficientNet | MobileNet | Image Net | ConvLSTM | Original |
|---|---|---|---|---|---|---|---|---|---|---|
| Al-Adwan et al. [31] | x | x | x | x | x | x | x | x | x | ✓ |
| Al-Dhabi and Zhang [32] | x | ✓ | x | x | x | x | x | x | x | x |
| Al-Dulaimi and Kurnaz [33] | x | x | x | x | x | x | x | x | x | ✓ |
| Amerini and Caldelli [34] | x | x | x | x | x | x | x | x | x | ✓ |
| Chan et al. [35] | x | x | x | x | ✓ | x | x | x | x | x |
| Chen, Li, and Ding [36] | x | x | x | x | x | x | x | x | ✓ | x |
| Chinchalkar et al. [37] | x | ✓ | x | x | x | x | x | x | x | x |
| Chintha et al. [2] | x | x | ✓ | x | x | x | x | x | ✓ | x |
| Fuad, Amin, and Ahsan [38] | ✓ | x | x | x | x | x | x | x | x | x |
| Gravina et al. [39] | x | x | x | ✓ | x | x | x | x | x | x |
| Guera and Delp [40] | x | x | x | ✓ | x | x | x | x | x | x |
| Hashmi et al. [41] | ✓ | x | x | x | x | x | x | x | ✓ | x |
| Jaiswal et al. [42] | x | x | x | x | x | x | x | x | x | ✓ |
| Jalui et al. [43] | x | ✓ | x | x | x | x | x | x | x | x |
| Jindal [44] | x | ✓ | x | x | x | x | x | x | x | x |
| John and Sherif [45] | x | ✓ | x | x | x | x | x | x | x | x |
| Jolly et al. [46] | ✓ | x | x | x | x | x | x | x | x | x |
| Jungare et al. [47] | x | ✓ | x | x | x | x | x | x | x | x |
| Kaur, Kumar, and Kumaraguru [48] | x | x | x | x | x | x | x | x | x | ✓ |
| Koshy and Mahmood [49] | x | x | x | ✓ | x | x | x | x | x | ✓ |
| Kukanov et al. [50] | x | x | x | ✓ | x | x | x | x | x | x |
| Lai et al. [51] | x | x | ✓ | x | x | x | x | x | x | x |
| Li, Chang, and Lyu [52] | x | x | x | x | ✓ | x | x | x | x | x |
| Liang et al. [53] | x | x | x | x | x | x | x | x | x | ✓ |
| Malik et al. [54] | x | x | x | x | x | x | x | x | x | ✓ |
| Masi et al. [14] | x | x | x | x | x | x | x | ✓ | x | x |
| Masud et al. [38] | x | x | x | x | ✓ | x | x | x | x | x |
| Nawaz, Javed, and Irtaza [55] | x | x | x | x | x | x | x | x | x | ✓ |
| Parayil et al. [56] | x | x | ✓ | x | x | x | x | x | x | x |
| Patel, Chandra, and Jain [57] | x | ✓ | x | x | x | x | x | x | x | x |
| Ritter et al. [58] | x | x | x | x | x | ✓ | x | x | x | x |
| Saealal et al. [59] | x | x | x | x | ✓ | x | x | x | x | |
| Saif et al. [60] | x | x | x | x | x | ✓ | x | ✓ | x | x |
| Saikia et al. [61] | x | x | x | x | x | x | x | x | x | ✓ |
| Saraswathi et al. [25] | x | ✓ | x | x | x | x | x | x | x | x |
| Shende, Paliwal, and Mahay [62] | x | ✓ | x | x | x | x | x | x | x | x |
| Singh et al. [63] | x | x | x | x | x | x | ✓ | x | x | x |
| Sooda [64] | x | ✓ | x | x | x | x | x | x | x | x |
| Stanciu and Ionescu [65] | x | x | ✓ | x | x | x | x | x | x | x |
| Su et al. [66] | x | x | x | x | x | ✓ | x | x | x | x |
| Suratkar and Kazi [67] | x | x | x | x | x | ✓ | x | x | x | x |
| Taviti et al. [68] | x | ✓ | x | x | x | x | x | x | x | x |
| Wubet [69] | ✓ | x | x | x | ✓ | x | x | x | x | x |
| Yadav et al. [70] | x | x | x | ✓ | x | x | x | x | x | x |
| Yesugade et al. [71] | x | ✓ | x | x | x | x | x | x | x | x |
| Citation | LSTM Architecture | Training Rate | Frame Rate | Frame Quality | Facial Landmark |
|---|---|---|---|---|---|
| Al-Adwan et al. [31] | x | ✓ | x | x | x |
| Al-Dhabi and Zhang [32] | x | x | ✓ | x | x |
| Al-Dulaimi and Kurnaz [33] | ✓ | x | x | x | x |
| Amerini and Caldelli [34] | x | x | x | ✓ | x |
| Chan et al. [35] | x | x | x | x | x |
| Chen, Li, and Ding [36] | x | x | ✓ | x | x |
| Chinchalkar et al. [37] | x | x | x | x | ✓ |
| Chintha et al. [2] | ✓ | x | x | x | x |
| Fuad, Amin, and Ahsan [38] | x | x | x | ✓ | x |
| Gravina et al. [39] | ✓ | x | x | x | x |
| Guera and Delp [40] | x | x | ✓ | x | x |
| Hashmi et al. [41] | x | x | x | x | ✓ |
| Jalui et al. [43] | x | x | ✓ | x | x |
| Jindal [44] | x | x | ✓ | x | x |
| John and Sherif [45] | x | x | ✓ | x | x |
| Jungare et al. [47] | x | x | ✓ | x | x |
| Kaur, Kumar, and Kumaraguru [48] | x | x | x | x | ✓ |
| Kukanov et al. [50] | x | x | x | ✓ | x |
| Lai et al. [51] | ✓ | x | x | x | x |
| Li, Chang, and Lyu [52] | x | x | x | x | ✓ |
| Liang et al. [53] | x | x | x | x | ✓ |
| Malik et al. [54] | x | ✓ | x | x | x |
| Masi et al. [14] | x | x | x | ✓ | x |
| Masud et al. [38] | ✓ | x | x | x | x |
| Nawaz, Javed, and Irtaza [55] | ✓ | x | x | x | x |
| Parayil et al. [56] | x | x | ✓ | x | x |
| Patel, Chandra, and Jain [57] | x | ✓ | x | x | x |
| Ritter et al. [58] | x | ✓ | x | x | x |
| Saealal et al. [59] | x | ✓ | x | x | x |
| Saikia et al. [61] | x | x | ✓ | x | x |
| Saraswathi et al. [25] | x | ✓ | ✓ | x | x |
| Shende, Paliwal, and Mahay [62] | x | x | ✓ | x | x |
| Singh et al. [63] | x | x | ✓ | x | x |
| Sooda [64] | x | ✓ | x | x | x |
| Stanciu and Ionescu [65] | x | x | x | x | ✓ |
| Su et al. (2021) [66] | x | x | ✓ | x | x |
| Taviti et al. [68] | x | x | ✓ | x | x |
| Wubet [69] | x | x | x | ✓ | ✓ |
| Yadav et al. [70] | x | ✓ | x | x | x |
| Yesugade et al. [71] | x | x | ✓ | x | x |
| Citation | Backbone | CNN | CNN-LSTM | Metric | Dataset Used | Frame Rate |
|---|---|---|---|---|---|---|
| Al-Adwan et al. [31] | Original | - | 97.40% | ACC | Celeb-DF | - |
| - | 94.47% | DFDC | ||||
| Al-Dhabi and Zhang [32] | ResNeXt | - | 95.54% | ACC | FF++, DFDC, Celeb-DF | 80 |
| Al-Dulaimi and Kurnaz [33] | Original | - | 98.24% | ACC | DFDC | - |
| Amerini and Caldelli [34] | Original | 91.72% | 94.29% | ACC | FF++ (lossless) | - |
| 79.41% | 85.27% | ACC | FF++ (c23) | - | ||
| Chen, Li, and Ding [36] | ConvLSTM | - | 99% | ACC | FF++ | 30 |
| - | 99.93% | ACC | Celeb-DF | |||
| - | 92.43% | ACC | DFDC | |||
| Chinchalkar et al. [37] | ResNeXt | - | 98% | ACC | FF++, DFDC, Celeb-DF | 150 |
| Chintha et al. [2] | Xception | 96.71% | 100% | ACC | FF++ | - |
| 89.91% | 99.16% | ACC | Celeb-DF | |||
| Fuad, Amin, and Ahsan [38] | ResNet | 70% | 82.4% | ACC | DFDC | 150 |
| Gravina et al. [39] | InceptionNet | - | 84.26% | ACC | DFDC | - |
| Guera and Delp [40] | InceptionNet | - | 97.1% | ACC | HOHA | 80 |
| Hashmi et al. [41] | ResNet, ConvLSTM | - | 97.5% | ACC | DFDC, Celeb-DF, YT | - |
| Jaiswal et al. [42] | Original | - | 80% | ACC | DFDC | - |
| Jalui et al. [43] | ResNeXt | - | 97.27% | ACC | DFDC | - |
| Jindal [44] | ResNeXt | - | 93.59% | ACC | FF++, Celeb-DF | 100 |
| John and Sherif [45] | ResNeXt | - | 94.31% | ACC | DFDC | 100 |
| Jolly et al. [46] | ResNet | - | 95.73% | ACC | FF++(HQ), YT | - |
| Jungare et al. [47] | ResNeXt | - | 93.58% | ACC | DFDC, FF++, Celeb-DF | 100 |
| Kaur, Kumar, and Kumaraguru [48] | Original | 97.06% | 98.21% | ACC | DFDC | - |
| Koshy and Mahmood [49] | InceptionNet | - | 98.71% | ACC | Replay Attack | 20 |
| - | 95.41% | ACC | Replay Mobile | |||
| Kukanov et al. [50] | InceptionNet | - | 38.90 | DCF | FF++, Deepfake-TIMIT, YT | 20 |
| Lai et al. [51] | Xception | 18.84 | 14.17 | HTER | FF++ | 10 |
| 22.31 | 18.32 | HTER | FF++(c23) | |||
| 4.38 | 2.91 | HTER | DFD (c23) | |||
| 10.60 | 15.34 | HTER | Deepfake-TIMIT | |||
| Li, Chang, and Lyu [52] | VGG-16 | 0.98 | 0.99 | AUC | EBV, CEW | 30 |
| Liang et al. [53] | Original | 98% | 99% | ACC | FF++ | - |
| 91% | 94% | ACC | DFD | |||
| 63% | 75% | ACC | Celeb-DF | |||
| Malik et al. [54] | Original | 82% | 66% | ACC | FF++ | - |
| 75% | 72% | ACC | DFDC | |||
| Masi et al. [14] | Image Net | 0.92 | 0.99 | AUC | FF++ (c23) | 110 |
| 0.86 | 0.91 | AUC | FF++ (c40) | |||
| Masud et al. [38] | VGG-16 | - | 99.24% | ACC | Celeb-DF | 20 |
| Nawaz, Javed, and Irtaza [50] | Original | - | 99.31% | ACC | DFDC | - |
| Parayil et al. [56] | Xception | - | 40% | ACC | DFDC | - |
| Patel, Chandra, and Jain [57] | ResNeXt | - | 92.12% | ACC | FF++, DFDC, Celeb-DF | 100 |
| Ritter et al. [58] | EfficientNet | - | 75% | ACC | FF++ | - |
| Saealal et al. [59] | VGG-16 | - | 95.57% | ACC | FF++ | - |
| Saif et al. [60] | EfficientNet, ImageNet | - | 99.6% | ACC | FF++ | 5 |
| Saikia et al. [61] | Original | 0.89 | 0.91 | AUC | FF++ | 30 |
| 0.69 | 0.83 | AUC | Celeb-DF | 50 | ||
| 0.64 | 0.68 | AUC | DFDC | 20 | ||
| Saraswathi et al. [25] | ResNeXt | - | 90.37% | ACC | FF++, DFD, Celeb-DF | 30 |
| Shende, Paliwal, and Mahay [62] | ResNeXt | - | 94.21% | ACC | Celeb-DF | 30 |
| Singh et al. [63] | MobileNet | - | 97.63% | ACC | DFDC | 30 |
| Stanciu and Ionescu [65] | Xception | 99.40 | 99.95 | AUC | FF++ | 60 |
| 83.60 | 97.06 | AUC | Celeb-DF | |||
| Su et al. [86] | EfficientNet | - | 99.57% | ACC | FF++ | 15 |
| Suratkar and Kazi [67] | EfficientNet | 98.69% | 97.56% | ACC | DFDC | 20 |
| 85.84% | 81.23% | ACC | FF++ | |||
| Taviti et al. [68] | ResNeXt | - | 97.89% | ACC | FF++ | 100 |
| - | 97.79% | ACC | Celeb-DF | |||
| - | 97.75% | ACC | DFDC | |||
| - | 93.29% | ACC | FF++, Celeb-DF, DFDC | |||
| Wubet [69] | ResNet | - | 93.23% | ACC | UADFV (real) | 28 |
| - | 98.30% | ACC | UADFV(fake) | |||
| Yadav et al. [70] | InceptionNet | - | 91.48% | ACC | FF++, Celeb-DF, DFDC | - |
| Yesugade et al. [71] | ResNeXt | - | 88.55% | ACC | DFDC | 30 |
| Author | Challenge | Description of the Challenge |
|---|---|---|
| Al-Adwan et al. [31] | Performance plateau due to parameter tuning | Fine-tuning the parameters through iteration using the PSO algorithm did not always lead to an increase in accuracy. |
| Al-Dhabi and Zhang [32] | Discarding frames | This model only uses the first 100 sequential frames, which could discard detecting a deepfake in the later portion of the clip. |
| Al-Dulaimi and Kurnaz [33] | Computationally expensive | This model has a trade-off between accuracy and computational efficiency |
| Amerini and Caldelli [34] | Low performance metrics on highly compressed videos | The CNN-LSTM model demonstrated poor performance on strongly compressed data, indicating limitations in detecting deepfakes in highly compressed videos. |
| Chan et al. [35] | Default assumption that the content is not deepfake | The model operates under the default assumption that the content is not deepfake, which could then potentially overlook key features of a deepfake. |
| Chen, Li, and Ding [36] | Computationally expensive and time consuming | The model has an increased runtime compared to other algorithms due to the non-parallelisable convolutional operations of ConvLSTM, resulting in a worst-case time–space complexity of O(n2). |
| Chinchalkar et al. [37] | Computationally expensive | This model requires a high number of frames to be fed into the network, which is computationally expensive. |
| Chintha et al. [2] | The impact of compression | The authors deduce that video compression adversely affects detection accuracy, in particular the FaceSwap subset of FF++. |
| Fuad, Amin, and Ahsan [38] | Poor illumination within the frame | Qualitative observations state that the illumination within the frame influences detection accuracy. |
| Gravina et al. [39] | Does not consider the audio stream within the deepfake | The model accounts for only one source of inconsistency in deepfake videos, not accounting for audio. |
| Guera and Delp [40] | Generalisability | The model is trained on a very small dataset, limiting its applicability to unseen data. |
| Hashmi et al. [41] | Occlusions | Facial occlusions impact accuracy and result in a larger frame rate being required. |
| Jaiswal et al. [42] | Hybrid model complexity | Combining the CNN-LSTM with GRU increases the training process time and complexity. |
| Jalui et al. [43] | Same training and testing dataset | Using limited test data of the same dataset limits generalisability. |
| Jindal [44] | Computationally expensive | This model has a trade-off between accuracy and computational efficiency |
| John and Sherif [45] | Frame rate limitation | This model is limited to accepting a frame rate of 100 fps due to the computational expense. |
| Jolly et al. [46] | Increased data pre-processing | Due to the complexity of the feature extraction stage, the data are heavily pre-processed and then re-processed manually, which requires a lot of extra time and input. |
| Jungare et al. [47] | Diminishing returns | After 100 frames, the model’s performance plateaus. |
| Kaur, Kumar, and Kumaraguru [48] | Facial rotations limiting detection | The video subject looking away causes detection to be compromised. |
| Koshy and Mahmood [49] | Loss of spatial information and lack of interpretability | Applying anisotropic diffusion can lead to the loss of fine spatial details whilst making it difficult to distinguish which specific features are affected by the diffusion. |
| Kukanov et al. [50] | Failure to detect online content | This model could not detect content collected from YouTube videos, which hosts a large portion of deepfake content. |
| Lai et al. [51] | Complexity | The involvement of spatial, frequency, time domain feature extraction, and LSTM is complex and computationally expensive. |
| Li, Chang, and Lyu [52] | Subjective threshold | The threshold set to what determines an open or closed eye impacts detection. |
| Liang et al. [53] | Reliance on Facial Geometry Prior Module (FGPM) | Relying on FPGM to extract facial landmarks may be ineffective in detecting deepfake techniques such as attribute manipulation, where changes in features such as hair, colours, and skin retouching do not affect the facial structure. |
| Malik et al. [54] | Pre-processing is sensitive to illumination and occlusions | The usage of the Viola–Jones algorithm is sensitive to occlusions and under/over light exposure. |
| Masi et al. [14] | Facial occlusions and poor illumination | Failure to detect real faces deduced from poor illumination and a lack of facial hair in training sets can impact results from test sets where this is present. |
| Masud et al. [38] | Poor illumination within the frame | The model struggled with low lighting, obscurity, and shadows. |
| Nawaz, Javed, and Irtaza [55] | ReLU activation function limitations | The ReLU activation function is liable to remove negative values during computation, which can potentially result in the loss of some subtle visual characteristics in the deeper layers. |
| Parayil et al. [56] | Generalisability | The model is trained on a very small dataset, limiting its applicability to unseen data. |
| Patel, Chandra, and Jain [57] | Discarding frames | This model only uses the first 150 sequential frames, which could discard the detection of a deepfake in the later portion of the clip. |
| Ritter et al. [58] | Overfitting | The model’s testing accuracy is lower than its training and validation accuracy, therefore indicative of overfitting. |
| Saealal et al. [59] | Low detection accuracy on non-GAN generated deepfakes | Deepfakes generated using neural texture architecture had a low detection accuracy. |
| Saif et al. [60] | Low detection accuracy for attribute manipulation | The model struggled to detect deepfakes where the expressions were swapped. |
| Saikia et al. [61] | Frame rate limitation | A frame rate input of 20 fps produced a 0.5 accuracy measure. |
| Saraswathi et al. [25] | Discarding frames | This model uses the first 150 sequential frames, which could discard detection of a deepfake in the later portion of the clip. |
| Shende, Paliwal, and Mahay [62] | Sequence processing | The biggest identified challenge was designing a classifier capable of recursively processing the sequence in a relevant manner. |
| Singh et al. [63] | Computationally expensive | There is a trade-off between the frame rate input into the model and the computational power used. |
| Sooda [64] | Training on small datasets | As the model was trained using a small portion of the DFDC dataset, its accuracy decreased when merged with the FF++ dataset. |
| Stanciu and Ionescu [65] | Pre-processing to handle sequential data | The model requires extra pre-processing to extract feature vectors from Xception for every fifth frame of the video. |
| Su et al. [66] | Limited to one dataset | The model trains and tests on the same FF++ dataset. |
| Suratkar and Kazi [67] | Generalisation | Training on specific manipulation techniques hinders the model’s ability to generalise against unseen deepfake attacks, limiting its effectiveness when various manipulation methods are employed. |
| Taviti et al. [68] | Performance plateau despite frame increase | At a 60-frame input, performance plateaus where 80 and 100 frames retrieve the same accuracy. |
| Wubet [69] | Limited diversity | The model might not be trained on a diverse set of eyes, potentially leading to reduced performance or bias when faced with a broader dataset of eyes. |
| Yadav et al. [70] | Lack of genuine imagery | Excluding real imagery from the input, opting to only use the deepfake limits the model’s ability to detect deepfakes in clips in which real and fake content coexist. |
| Yesugade et al. [71] | Discarding frames | This model uses the first 150 sequential frames, which could discard detection of a deepfake in the later portion of the clip. |
| Challenge | Suggested Solution |
|---|---|
| Performance trade-off | To mitigate computational requirements, the LSTM architecture can be leveraged to store essential features and temporal patterns, rather than processing and saving entire video frames on a physical server. This approach significantly reduces the memory overhead, as only relevant and condensed information is retained, instead of storing full-resolution video data for every frame. By focusing on capturing temporal dynamics, LSTM layers can efficiently encode the relationships between video frames. This allows the model to understand changes over time without the need for extensive storage or processing resources. For instance, instead of holding redundant pixel data, the model retains the most meaningful information. |
| Frame Rate Limitation | Analysing the entire video context in a computationally efficient manner, rather than sampling individual frames, offers a more holistic approach to deepfake detection. By considering the full video sequence, the model can better capture temporal inconsistencies and subtle manipulations that may be missed when only isolated frames are examined. This approach ensures that the detection system leverages both spatial and temporal information, providing a more robust understanding of how visual elements evolve over time, which is critical for detecting sophisticated deepfakes. |
| Restricted Frame Rate Input | Utilising motion vectors and information masks from the H.264 video codec significantly enhances the efficiency of detecting temporal inconsistencies in video content. Instead of analysing every individual frame, this approach leverages the motion vectors, which represent the direction and magnitude of pixel movement between frames. By focusing on these vectors, the system can identify areas of significant change without the computational overhead associated with full RGB analysis. Information masks further refine this process by highlighting critical regions within the video, enabling targeted scrutiny of potentially manipulated areas. This dual strategy not only reduces computational costs but also preserves detection effectiveness, allowing for quicker analysis while maintaining accuracy, especially in scenarios involving high frame rates or large datasets. |
| Video Compression | Pre-processing techniques that combine frequency enhancements with colour domain transformations significantly enhance the model’s resilience to compression artefacts. By fusing these enhancements, the model can better capture essential features that may be obscured in highly compressed videos. Additionally, using architecture-specific loss functions optimises training by emphasising relevant characteristics for deepfake detection, allowing the model to focus on crucial elements even when subtle details are compromised. This holistic approach ensures that the model maintains accuracy and effectiveness in identifying deepfakes, even in challenging scenarios where traditional methods may falter due to the loss of critical information. |
| Facial Occlusions | Adapting pre-processing and feature extraction techniques to focus on key landmarks associated with facial rotations enhances the model’s ability to recognise faces under various orientations. This involves training the model to identify critical facial features, such as the eyes, nose, and mouth, despite changes in position. Additionally, designing the CNN-LSTM architecture to effectively track facial dynamics over time allows for the capturing of essential temporal information, ensuring that the model maintains a coherent understanding of the face throughout the video sequence. This dual approach significantly boosts the model’s robustness against facial occlusions, improving its accuracy in detecting deepfakes even when facial information is partially obscured. |
| Lighting Conditions | Training on datasets that encompass a diverse array of facial characteristics including variations in facial hair, skin tones, and distinctive features helps to minimise bias in the model. This diversity enables the model to learn a broader range of patterns and characteristics, thereby enhancing its generalisability across different populations. As a result, the model becomes more adept at recognising authentic faces, regardless of variations in appearance. By being exposed to various features, the model improves its effectiveness in detecting unseen deepfake manipulation techniques. This approach not only strengthens the model’s performance on diverse inputs but also enhances its reliability in real-world applications, where facial characteristics can vary significantly. |
| Evolving Deepfake Techniques | Continuously testing and adapting CNN-LSTM models to keep pace with emerging deepfake techniques is crucial for maintaining their relevance and effectiveness. As new manipulation methods, such as the neural textures subset, evolve, models must be updated to recognise and respond to these advanced threats. This ongoing process involves regular evaluation of the model’s performance on new datasets and incorporation of recent findings in deepfake technology. By refining the model through iterative training and testing, it becomes more resilient to previously unseen attacks, ensuring that it can accurately detect deepfakes across a wide range of scenarios. This proactive approach not only bolsters the model’s defence mechanisms but also solidifies its role as a reliable tool in combating deepfake proliferation. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tipper, S.; Atlam, H.F.; Lallie, H.S. An Investigation into the Utilisation of CNN with LSTM for Video Deepfake Detection. Appl. Sci. 2024, 14, 9754. https://doi.org/10.3390/app14219754
Tipper S, Atlam HF, Lallie HS. An Investigation into the Utilisation of CNN with LSTM for Video Deepfake Detection. Applied Sciences. 2024; 14(21):9754. https://doi.org/10.3390/app14219754
Chicago/Turabian StyleTipper, Sarah, Hany F. Atlam, and Harjinder Singh Lallie. 2024. "An Investigation into the Utilisation of CNN with LSTM for Video Deepfake Detection" Applied Sciences 14, no. 21: 9754. https://doi.org/10.3390/app14219754
APA StyleTipper, S., Atlam, H. F., & Lallie, H. S. (2024). An Investigation into the Utilisation of CNN with LSTM for Video Deepfake Detection. Applied Sciences, 14(21), 9754. https://doi.org/10.3390/app14219754