1. Introduction
Data augmentation is pivotal for bolstering the feature modeling prowess of low-resource datasets. Related research has centered on enhancing data within the same modality through strategies such as data expansion, repetition, and the incorporation of seed data. These methodologies aim to improve the efficacy of data utilization and concomitantly elevate the models’ performance [
1,
2]. Latin Cuengh, which is recognized as a low-resource language, epitomizes the quintessential challenge in training and learning paradigms due to the arduous task of procuring a wealth of high-quality textual data. The majority of the Latin Cuengh-speaking community relies predominantly on verbal communication, with a dearth of written records; even some of its members remain unacquainted with the written form. This linguistic landscape presents a formidable impediment to the annotation of text data [
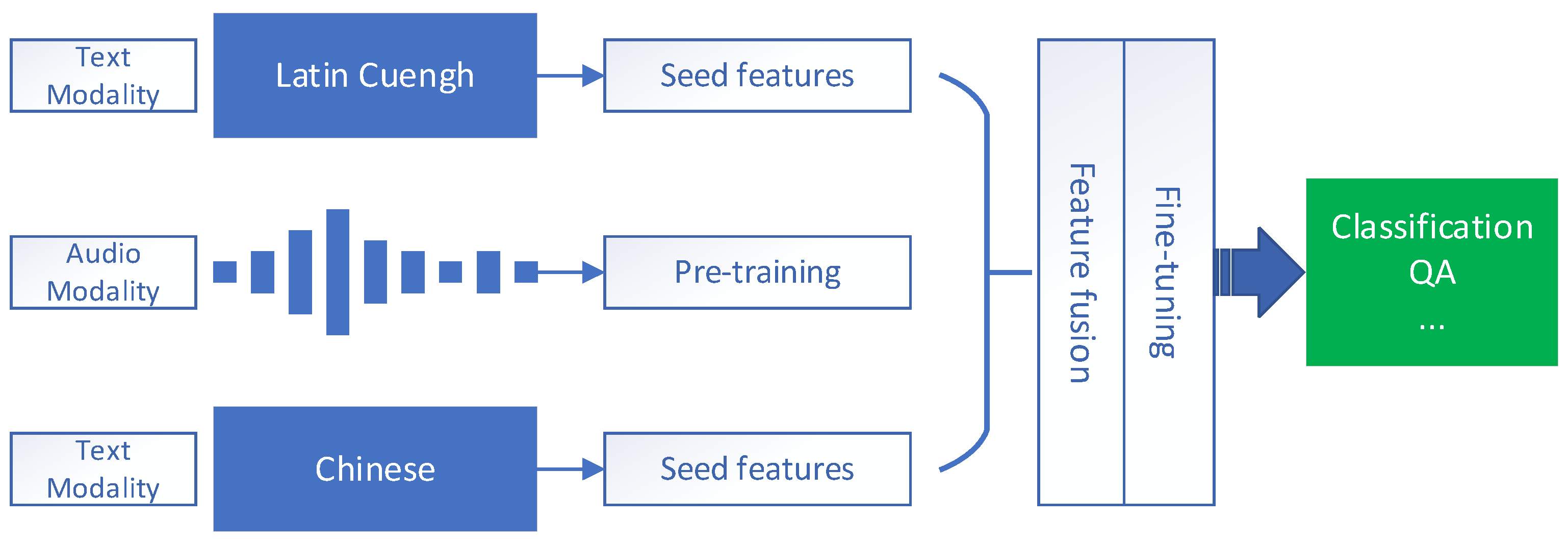
3]. In this paper, we delve into multimodal training using Latin Cuengh speech data, leveraging a wealth of existing resources. We aim to augment the model’s cognitive acuity by integrating multilingual textual data as seed information. The overarching architecture of our methodology is depicted in
Figure 1.
When juxtaposed with multimodal data that amalgamate images and text, the confluence of speech and text modalities demands a more sophisticated feature fusion acumen. Dai et al. [
4] have endeavored to synchronize speech signal slices with textual information features, leveraging the innate nonlinear expressive capabilities of neural networks to craft a multimodal model. This approach has fortified the feature articulation competencies of single-modality data. Nonetheless, the intrinsic structural and distributional disparities between speech and text data necessitate a more nuanced approach. The mere aggregation of feature vectors for fusion may culminate in the erosion of substantial semantic content. More critically, the modalities encode vital information through disparate avenues; a segment of speech data might harbor pivotal information that could be inadvertently disregarded in the aligned text data, precipitating inaccurate data alignment. Moreover, the amalgamation of diverse modalities may engender redundant information [
5]. Given the divergent internal processing mechanisms of the various modalities, the mitigation strategies for redundancy vary, potentially leading to sparse, high-quality features that fail to enhance the model’s efficacy.
The main challenges associated with this line of work are twofold: the first is the urgent need for ultra-large-scale multimodal data, a subset of which necessitates meticulous, high-quality annotation. Secondly, the modality of speech slices may lead to semantic fragmentation and disjointedness. Multimodal data augmentation, with its capacity to integrate features across divergent dimensions and modalities, promises effective feature fusion within a higher-dimensional feature space. This, in turn, affords a more efficacious array of feature options catering to downstream tasks [
6]. For Latin Cuengh, a dialect that is characterized by a scarcity of textual data, achieving commendable results through mere pre-training is onerous, and the equivalence between speech and textual data is not absolute when it comes to certain tasks. In this paper, we address the dearth of textual data by using speech data for training purposes and employing textual information as seed data to amplify instructions. This strategy guides the parameter updates of the speech model across downstream tasks [
7].
To tackle the aforementioned challenges, we introduce a novel low-resource data augmentation methodology that integrates multilingual text. This method capitalizes on feature fusion across different modalities. In this paper, we fine-tune the text modality features, fully harnessing the intrinsic characteristics of Latin Cuengh and Chinese text seed data. Our contributions are twofold: (1) pioneering the multimodal enhancement for the resource-constrained Latin Cuengh language; (2) concurrently fine-tuning the speech model utilizing Latin Cuengh and Chinese seed data.
It is imperative to acknowledge that not all enhancement methodologies predicated on seed data can attain optimal outcomes; this is contingent upon the inherent quality of the data [
8,
9]. Moreover, the heterogeneity of downstream tasks introduces further variance. Prevailing research predominantly employs uniform types of seed data as prompts for learning. For instance, a modest quantity of text is utilized as seed data; this could range from a single word or sentence to multiple paragraphs. Such seed data may engender inconsistencies in the model’s contextual semantic modeling, culminating in a proliferation of redundant and chaotic model parameters. An alternative approach entails the employment of seed data from divergent modalities, such as leveraging text data as seed information in image models or augmenting speech models with textual seed data. The methodology presented in this paper aligns with the latter but distinguishes itself by incorporating two modalities—Latin Cuengh and Chinese seed data—which collectively enhance the speech model. This approach not only expedites the acquisition of augmented data but also enriches the model’s feature information across various dimensions, further amplifying the model’s capabilities. In fact, we integrate the features of seed words into the audio features through an attention mechanism to enhance the model’s recognition capabilities with seed words that have more concentrated semantic features. Compared to the approach of training with a large amount of data, our method further validates that, when working with smaller data samples, using a selection of feature-concentrated keywords to enhance the available information offers a certain competitive edge.
2. Related Works
The landscape of multimodal data augmentation is both expansive and dynamic, with a continuous influx of innovative research. Most scholars in this field have focused on the amplification of multimodal datasets, the synthesis of varied modal features, and the architectural design of methods tailored to disparate downstream tasks [
10]. In the realm of dataset expansion, augmentation occurs at the character, word, and text levels, with potential applications in neural machine translation, generation models, and text classification endeavors [
11]. With the progression of pre-training and large-scale model technologies, methods that integrate text, speech, and image information in multimodal data augmentation have garnered widespread interest [
12].
Hua et al. [
13] introduced a text data augmentation approach grounded in ChatGPT-4o, which adeptly re-segments training sentences into semantically unique sub-samples that maintain the underlying concept, thereby enriching the dataset. Josi et al. [
14] described an off-the-shelf diffusion model capable of altering the semantic fabric of multimodal data to enhance their high-level semantic attributes. Hao et al. [
15] presented a novel hybrid data augmentation technique, fortifying the model’s parameter expression across different dimensions through the strategic introduction of mixed samples at various network stages. Shi et al. [
16] crafted a straightforward yet effective data augmentation metric designed to mitigate the effects of low-resource data and augment the efficacy of data augmentation strategies by quantifying synthetic data. Ref. [
17] fine-tuned the BERT model to simulate the impact of pre-trained models on data augmentation within the context of low-resource data scenarios. Cai et al. [
18] created an adaptive approach for the generation of long and short texts, enhancing data embedding representation within the feature space through the language models.
In the specialized field of low-resource multimodal research, methods for learning from small samples are becoming increasingly widespread [
19,
20]. Tsai et al. [
21] presented a method leveraging graph propagation algorithms to achieve low-resource data augmentation. This technique capitalizes on graph propagation to forge relationships between small samples and augmented data, amplifying the diversity of such datasets. Contrastive learning methods have demonstrated significant promise in the feature fusion of multimodal data. Hazarika et al. [
22] introduced a novel contrastive learning framework that learns generalizable features by reverse-translating text and integrating said features into the visual domain. Andersland et al. [
23] proposed a specialized data augmentation strategy for multimodal settings, extending image data to include infrared modalities. Huang et al. [
24] described a data augmentation technique for visual–text representation learning, creating a bridge between interpolated images and texts to yield semantically associated image–text pairs. Hasan et al. [
25] proposed a multimodal data augmentation approach based on ground truth sampling to generate content-rich synthetic scenes, circumventing the cluttered features that can arise from random sample pasting. Hazmoune et al. [
26] developed a multimodal data augmentation method to bolster speech emotion recognition, whereas Baevski et al. [
27] explored various data augmentation methods using speech and transcript data, constructing a speech graph from extracted features. Meanwhile, Wang et al. [
28] conceptualized a textualization of multimodal information to integrate non-verbal cues, translating visual cues into textual form.
Researchers have explored data augmentation methods from myriad perspectives, including data acquisition, methodological approaches, experimental designs, and evaluative metrics. Large language model technologies in particular have found extensive applications in the augmentation of low-resource data. However, current research is heavily reliant on extensive pre-training datasets, and the scarcity of existing textual data for Latin Cuengh has impeded the performance of many traditional methods. In this paper, we enhance the efficiency of low-resource data utilization through a seed data augmentation method and establish semantic links across the entire training dataset by leveraging the relationships between seed data.
3. The Proposed Method
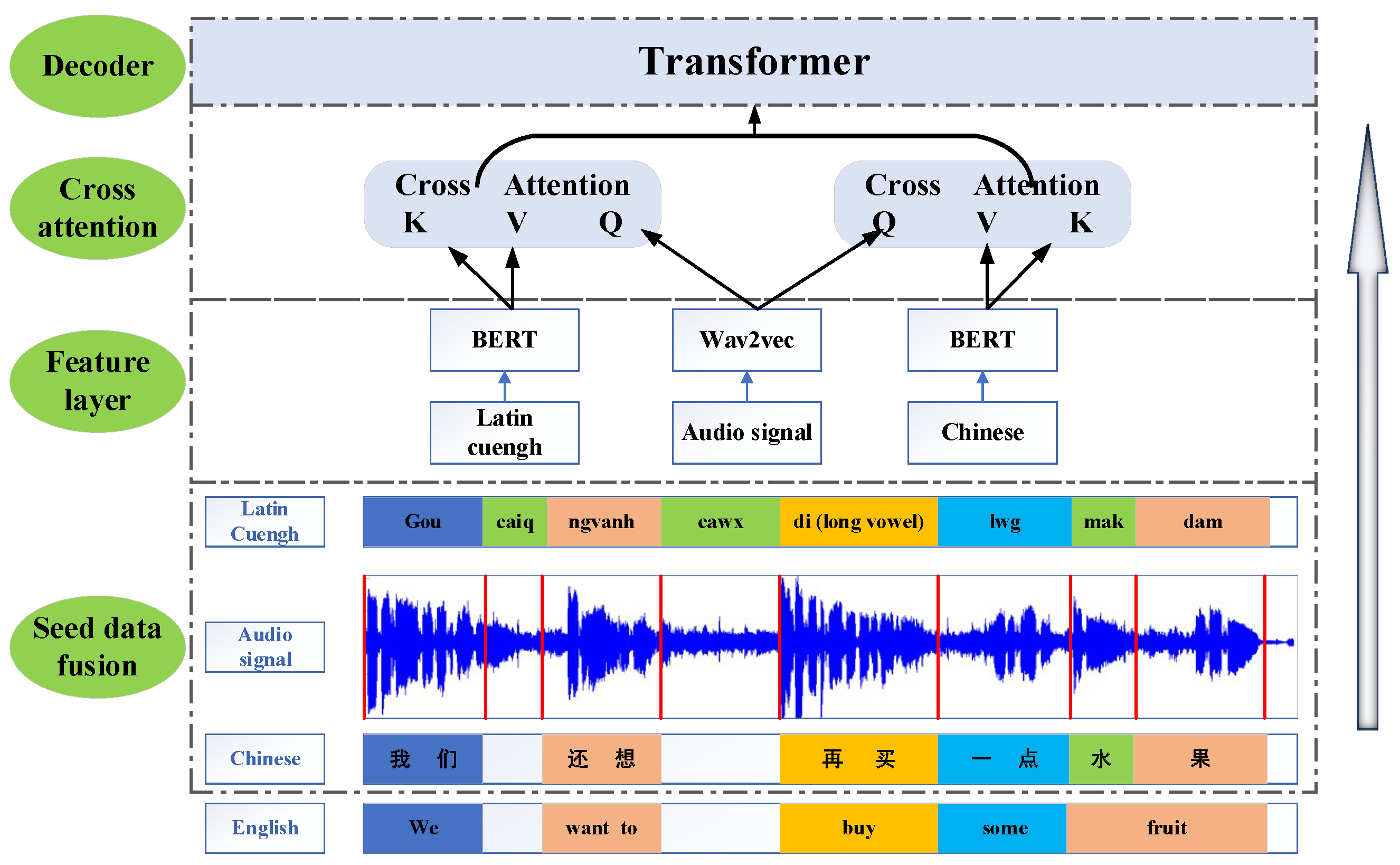
Our proposed methodology is outlined in
Figure 2 and comprises a structured, multi-component framework. A seed data input fusion layer designed to handle two distinct data modalities—speech and text—is central to our approach. The speech data serve as the foundation for model training, while the text data are bifurcated into Latin Cuengh and Chinese segments, both of which have been meticulously curated from our in-house bilingual corpus. For the feature extraction layer, we distill and amalgamate features using state-of-the-art techniques. The text data are processed through the BERT model to extract meaningful token embeddings, while the speech data are vectorized using the wav2vec framework [
29], providing robust and contextually rich feature representations. We used three types of data for encoding: Chinese text, Latin Cuengh text, and Latin audio data, in three different forms. The Chinese text and Latin text have different compositions, and the audio data consist of frequency information. The semantic consistency of the synonyms in Chinese and Latin Cuengh, as well as the slice length of the audio information, are important considerations which will allow us to ensure that the integrated information is complete after fusion. The model will not devote much time to dissecting these integrated pieces of information during decoding, ensuring the accuracy of semantics.
The cross-attention layer is a pivotal aspect of our model’s design that facilitates the interaction between the two modalities. It adopts a cross-attention mechanism in which the speech data are designated as the query (Q), and the Latin Cuengh and Chinese text data are utilized as the value (V) and key (K), respectively. This mechanism allows dynamic weighting of the input data, enhancing the model’s ability to focus on salient features. This process culminates within the transformer decoding layer, where the model’s latent representations are decoded and applied to downstream tasks, such as text classification and answering questions.
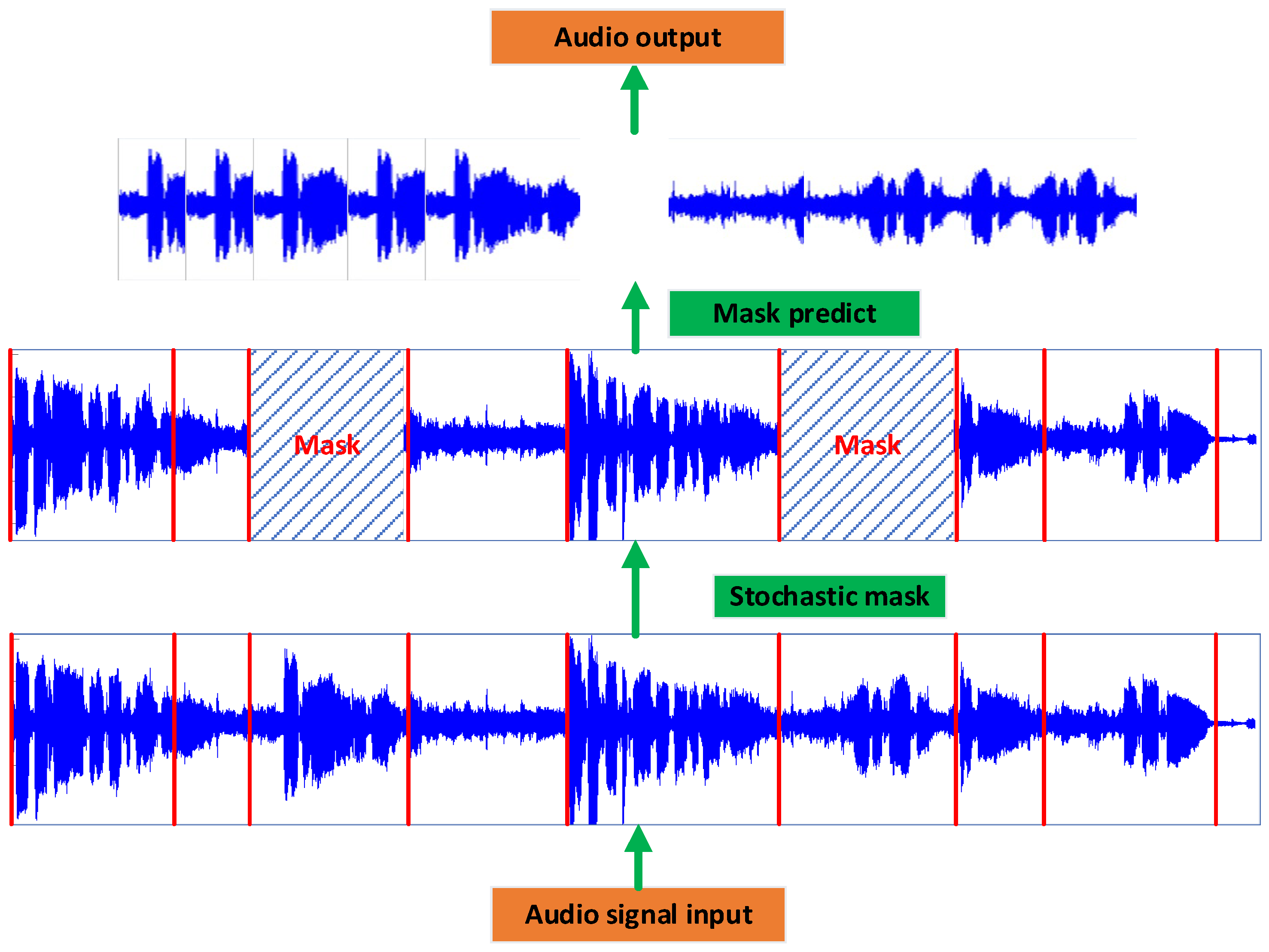
3.1. Audio Signal Pre-Training
Our methodology for pre-training audio signals is inspired by the BERT masking technique, which we have adapted for use with audio data, as shown in
Figure 3. The process begins with the preprocessing of the audio signals to enhance quality and consistency. Noise reduction is implemented to filter out unwanted noise and the audio is segmented into uniform, 10 s durations, based on the average length of speech data in our corpus, which encapsulates complete speech phrases while minimizing redundancy. Post-segmentation, the audio signals are further divided into distinct regions based on criteria such as frequency continuity and pause timing to ensure that each segment represents a coherent and complete linguistic unit. We then introduce a random masking operation that obscures portions of the audio signal, mirroring the BERT technique’s approach to predicting masked tokens.
The masked audio segments are subsequently input into the model for prediction; the projections are compared to the original, unmasked audio segments, and the model is trained using a loss function that minimizes the discrepancy between the predicted and actual audio signals. The result is a pre-trained model that has learned to understand and reconstruct the audio signals effectively. The training employs a cross-entropy loss function, as depicted in Equation (1), which is a standard measure for classification problems, including the prediction of masked audio segments.
where
and
correspond to the true and the predicted values of the
i-th data point, respectively.
3.2. Seed Data Augmentation
The seed data for our model are derived from the Latin Cuengh language and its corresponding Chinese text, as illustrated in
Figure 4. This language, which is shaped by its phonetic rules, forms syllables from initials, vowels, and tones. Each word in Latin Cuengh is constructed from these syllables, similar to how ‘guekgya’, meaning ‘country’, is composed of ‘guek’ and ‘gya’. This phonetic consistency allows us to use syllables as stable seed data, which can be combined into various words without affecting their pronunciation.
Due to the unique structural form of Latin Cuengh, each word in this language possesses strong auditory properties. A complete Latin Cuengh word has tonal attributes, coupled with its own semantic attributes, allowing us to fully combine the characteristics of both speech and text. As stated in the example above, ‘guekgya’ comprises two parts, ‘guek’ and ‘gya’. In ‘guek’, the letter ‘k’ has a falling tone, while ‘a’ has a rising tone. In the selection of seed words, we prioritize complete Latin Cuengh words, then sort them according to their prevalence, choosing more important words as candidates. Finally, further audio and text matching is required. For words which contain the same syllables, judgments are made based on semantics, and, ultimately, the seed words are selected.
For the Chinese text data, we apply a keyword strategy for seed selection. The text undergoes word segmentation to identify complete word combinations. A keyword extraction method is then utilized to identify key Chinese words, and these keywords are expanded semantically to enrich the data and enhance the model’s understanding of the context and semantics.
3.3. Cross-Attention Mechanism
Our model’s feature layer is designed to extract and integrate vector representations of three distinct feature types: speech modality (A), Latin Cuengh text modality (L), and Chinese text modality (C). We achieve this by leveraging an attention weight matrix that separately yields the query (Q), key (K), and value (V) attention values for each modality.
The cross-attention mechanism is a pivotal component of our model, as it facilitates the interaction between the speech modality and the two text modalities. This is accomplished by sharing the query value from the speech modality (
QA) and utilizing it to compute the alignments with the values and keys of both the Latin Cuengh (
L) and Chinese text (
C). The formulas governing these computations are as follows:
Here, represents the feature alignment between Latin Cuengh and audio, while denotes the feature alignment between Chinese text and audio. Our model is structured into three feature layers, in which the initial layer is tasked with obtaining the vector embeddings for the three modalities while the second layer generates cross-modality feature representations, where signifies the fusion of Latin Cuengh and speech, and represents the fusion of Chinese text and speech.
In the subsequent layer, a multi-layer perceptron (
MLP) is employed to project the combined features into a novel space, yielding the final, integrated representation, denoted as
LAC. This final representation is obtained through the following operation:
where
symbolizes the concatenation of features, which merges the distinct modalities into a cohesive representation.
4. Experimental Results and Analyses
4.1. Experiment Dataset and Setting
In our study, both Chinese and Latin Cuengh scripts underwent processing for feature extraction using a pre-trained BERT-base model. Token embeddings were meticulously derived from the BERT model’s hidden layers, each with a feature dimension of 768, aligning with the BERT-base model’s architecture. The audio data were processed using the wav2vec-base model [
29], which employs self-supervised learning to generate audio signal embeddings, also with a dimensionality of 768. The evaluation metrics included accuracy (ACC), F1-score (F1), precision (P), and recall (R).
Benchmarking was conducted using experimental comparisons and test data sourced from Chen et al. [
3], which encompassed three notable benchmark models:
1. MAG-BERT: Ferguson et al. [
30] proposed a multimodal adaptation gate for BERT (MAG-BERT), integrating lexical representations within the transformer framework.
2. MulT: Al Roken et al. [
31] introduced a multimodal transformer model (MulT), addressing cross-modality sequence modeling in an end-to-end fashion.
3. MISA: Zhang et al. [
32] designed a multimodal integration and self-attention (MISA) model that projected features into subspaces to capture inter-feature differences, thereby fusing multimodal features.
4.2. Text Classification
Our inaugural experiment aimed to benchmark the model’s performance on a public dataset, according to the methodology described by Chen [
3]. The experiments were bifurcated into two classifications—twenty-class and binary-class—with results tabulated in
Table 1.
Our model demonstrated superior performance in the text-only modality compared to the conventional Text-Classifier. The incorporation of seed words further bolstered the model’s performance in this single-modality scenario. We attribute this enhancement to the supplementary information provided by seed words, which, being in the same vector space as the text during feature extraction, mitigate potential negative effects of multimodal feature fusion.
In scenarios involving “text + audio”, our model outperformed others under the same modality. However, other models that were tested under a “text + audio + video” modality yielded superior results in some instances. This discrepancy can be attributed to the limitations of our model’s design, which currently only incorporates “text + audio” and does not extend to video modules.
As mentioned earlier, the model’s cross-attention includes three modalities: audio and speech modality (A), Latin Cuengh language modality (L), and Chinese text modality (C). LA represents the fusion of the Latin Cuengh language and audio information, CA represents the fusion of Chinese and audio information, and LAC represents the fusion of the Latin Cuengh language, audio, and Chinese information. The three modalities are cross-integrated through a three-layer network. To explore the influence of features between different layers, we conducted an ablation study on the attention weights of several modalities. The results of the experiment are shown in
Table 2.
Table 2 illustrates the outcomes of an ablation study, revealing that the model achieves peak performance when all three feature representation layers are active. Individually, layer 3’s fusion method achieves the optimal performance, and when combining adjacent layers, the combination of layers 1 and 2 surpasses that of layers 2 and 3. We surmise that layer 1’s comprehensive feature extraction, coupled with the effective text and speech fusion in layer 2, contributes significantly to the model’s performance, with layer 3’s MLP operation serving as an enhancement rather than a foundational component.
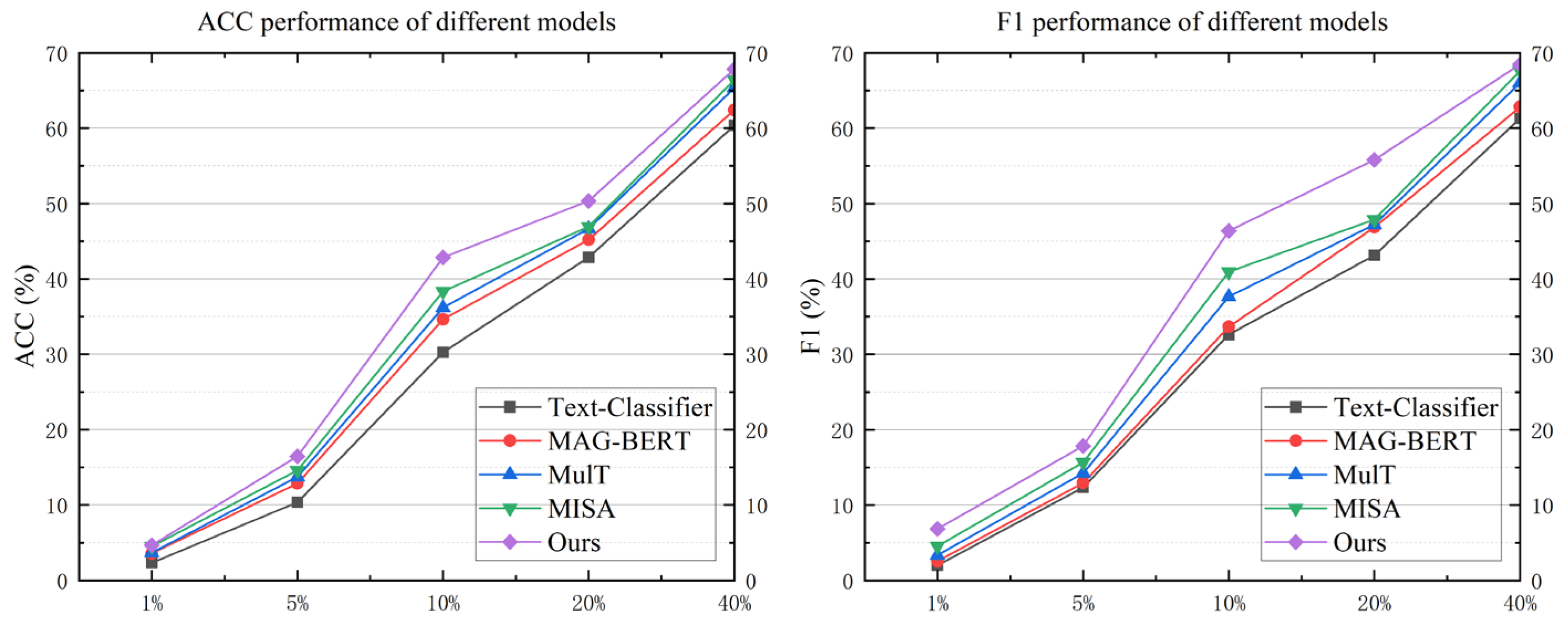
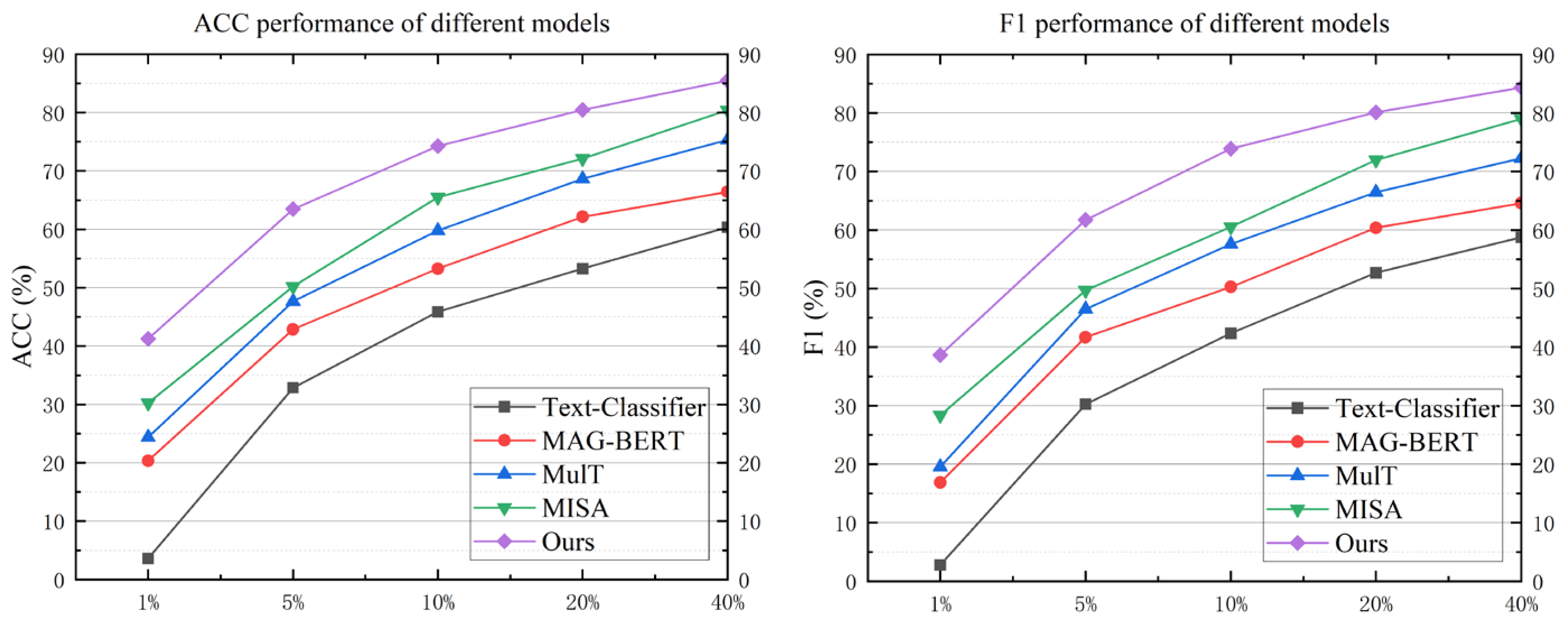
Lastly, to evaluate the model’s performance under low-resource conditions, we conducted comparative experiments using training datasets of varying sizes ([1%, 5%, 10%, 20%, 40%]) across multi-classification and binary classification tasks. In this process, the dataset is randomly selected according to the aforementioned ratios to simulate the data augmentation effect of the model under low-resource conditions. For instance, in our experiments, we used as little as 1% of the data volume. In this extreme scenario, the model’s performance was highly unstable. However, we found that, in the binary classification task, our method achieved a relatively satisfactory performance even with extremely scarce sample data. The results of these experiments are depicted in
Figure 5 and
Figure 6.
Figure 5 illustrates the impact of training data proportion on the model’s precision in the multi-text classification task. When the training data constitute less than 10% of the total dataset, the model’s precision noticeably decreases. However, once the training data reaches 40% of the total, the model’s precision surpasses 90% of the result achieved with the complete dataset, consistently outperforming other models across various data proportions.
Figure 6 compares various models’ performances in the binary classification task. Even with training data comprising as little as 1% of the total, our model’s precision exceeds 40%. At a 20% training data threshold, our model achieves 80% precision on both metrics. While the increase in training data leads to a plateau in the growth rate of precision and F1 score, our model still surpasses others under low-resource conditions. This superior performance is attributed to the model’s structural design, which is tailored for low-resource data training, and the implementation of a seed data augmentation method that adeptly addresses feature scarcity.
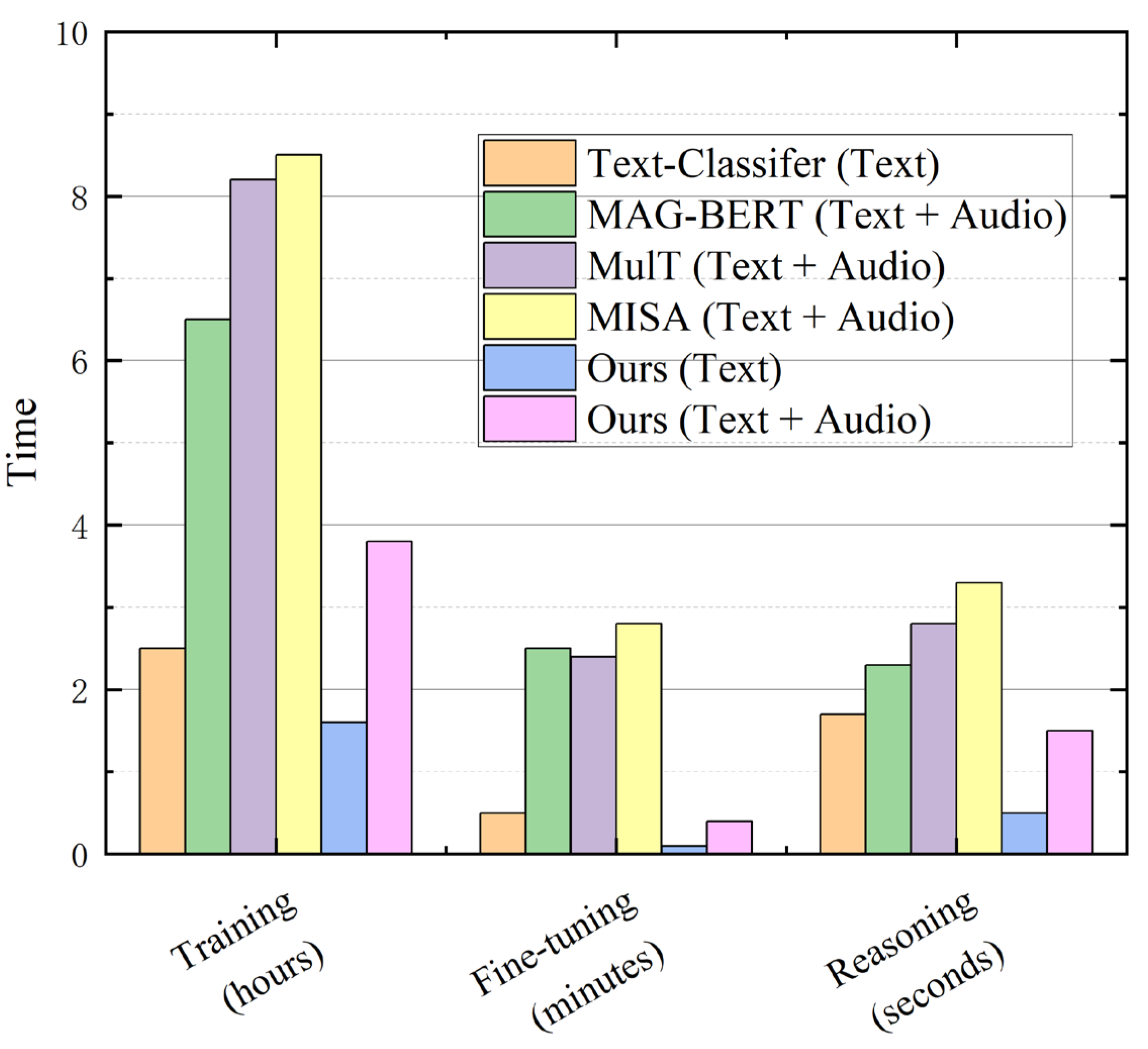
Our model distinguishes itself from other contemporary multimodal models by its lightweight nature. It selects seed data for enhancement under the text modality, thereby reducing the time required for pre-training and fine-tuning in the multimodal fusion process. To substantiate our model’s efficiency, we conducted experiments comparing the energy efficiency ratio with several benchmark models; the results are depicted in
Figure 7.
Figure 7 provides a comparative analysis of training, fine-tuning, and inference times across different models. For models utilizing a single text modality, the training time is relatively brief. However, the inclusion of both text and audio modalities substantially increases the training duration. Our model exhibits the lowest time consumption across all three metrics, affirming its high efficiency. The figure utilizes rectangles to represent the amount of time consumed, where a lower rectangle indicates less time and higher efficiency. The training time is measured in hours, fine-tuning in minutes, and inference in seconds.
5. Discussion
In the experiments, this study employed both binary and multi-class classification tasks. During the binary classification task, even under low-resource conditions, the model possessed strong discriminative power. The experiments also confirmed that when its learning is enhanced by seed words, our model can fully exploit the characteristics of low-resource data. Moreover, due to the inherent characteristics of the studied language, the audio data can also enhance the model’s propagation capabilities within the network. For multi-class tasks, according to the results of several models, our model’s accuracy was significantly lower than that of binary classification models, especially under low-resource conditions, in which it is challenging for the model to obtain more high-quality category features. We incorporated seed words and audio data into the model, forcibly establishing a multidimensional feature space, which enhanced our model’s multi-category features and improved its classification capabilities. However, there are still significant challenges with regard to the large-scale application to low-resource data.
Our model is not without its limitations: Firstly, while we utilized public data for training, our experiments have been confined to the Latin Cuengh language, and the model has yet to be tested on other low-resource languages. Secondly, the current seed data selection process, based on keyword extraction, focuses on the immediate textual context and does not account for the broader low-resource dataset. In the future, we aim to refine the seed data selection methodology by incorporating global attention mechanisms and harnessing the power of large models to enhance the precision of seed data selection. These improvements are expected to bolster the capabilities of our model in augmenting low-resource datasets. For instance, countries in Southeast Asia each have their own languages and scripts, but they suffer from resource scarcity and a lack of influence, impeding the creation of scaled data resources. Our research provides a completely new method for these low-resource languages.
6. Conclusions
This study presents a novel approach to data augmentation, leveraging textual seed words to construct a multimodal seed data augmentation model. We have integrated audio data training with textual seed data fine-tuning and tailored this method for intelligent processing tasks within the low-resource Latin Cuengh language. Our model has demonstrated remarkable performance in both multi-classification and binary-classification tasks utilizing a combined text and audio modality. Our analysis of the seed words’ role across different network layers, through various modal combinations, has substantiated the robustness of our method, especially in scenarios characterized by limited training data and sparse semantic features. The efficiency of our model is further highlighted by its minimal reliance on text data for augmentation, which significantly expedites training, fine-tuning, and inference processes. Our method focuses on the challenges faced by low-resource languages in the process of informatization. In the future, we aim to incorporate more restrictive, low-resource languages into our research and form relevant experiences in the intelligent processing and management of such dialects, contributing to the dissemination and preservation of low-resource languages.
Author Contributions
The authors confirm their contribution to the paper as follows: study conception and design: L.J., L.J. and X.Q.; data collection: L.J. and X.Q.; analysis and interpretation of results: L.J., J.L. and J.Z.; draft manuscript preparation: L.J., X.Q. and J.L. All authors have read and agreed to the published version of the manuscript.
Funding
This study was supported by the Middle-aged and Young Teachers’ Basic Ability Promotion Project of Guangxi (No. 2024KY0213), the Guangxi Natural Science Foundation (No. 2022GXNSFBA035510), the Guangxi Key Research and Development Program (No. Guike AB23075178), the Guangxi Key Laboratory of Image and Graphic Intelligent Processing (No. GIIP2207), and the National Natural Science Foundation of China (No. 62267002).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Garcea, F.; Serra, A.; Lamberti, F.; Morra, L. Data augmentation for medical imaging: A systematic literature review. Comput. Biol. Med. 2023, 152, 106391. [Google Scholar] [CrossRef] [PubMed]
- Alomar, K.; Aysel, H.I.; Cai, X. Data Augmentation in Classification and Segmentation: A Survey and New Strategies. J. Imaging 2023, 9, 46. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Tam, D.; Raffel, C.; Bansal, M.; Yang, D. An empirical survey of data augmentation for limited data learning in nlp. Trans. Assoc. Comput. Linguist. 2023, 11, 191–211. [Google Scholar] [CrossRef]
- Dai, H.; Liu, Z.; Liao, W.; Huang, X.; Cao, Y.; Wu, Z.; Zhao, L.; Xu, S.; Liu, W.; Liu, N.; et al. Auggpt: Leveraging chatgpt for text data augmentation. arXiv 2023, arXiv:2302.13007. [Google Scholar]
- Trabucco, B.; Doherty, K.; Gurinas, M.; Salakhutdinov, R. Effective data augmentation with diffusion models. arXiv 2023, arXiv:2302.07944. [Google Scholar]
- Liang, W.; Liang, Y.; Jia, J. MiAMix: Enhancing Image Classification through a Multi-Stage Augmented Mixed Sample Data Augmentation Method. Processes 2023, 11, 3284. [Google Scholar] [CrossRef]
- Pellicer, L.F.A.O.; Ferreira, T.M.; Costa, A.H.R. Data augmentation techniques in natural language processing. Appl. Soft Comput. 2023, 132, 109803. [Google Scholar] [CrossRef]
- Lamar, A.; Kaya, Z. Measuring the Impact of Data Augmentation Methods for Extremely Low-Resource NMT. In Proceedings of the 6th Workshop on Technologies for Machine Translation of Low-Resource Languages (LoResMT 2023), Dubrovnik, Croatia, 2–6 May 2023; pp. 101–109. [Google Scholar]
- Stylianou, N.; Chatzakou, D.; Tsikrika, T.; Vrochidis, S.; Kompatsiaris, I. Domain-aligned Data Augmentation for Low-resource and Imbalanced Text Classification. In Proceedings of the European Conference on Information Retrieval, Dublin, Ireland, 2–6 April 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 172–187. [Google Scholar]
- Jahan, M.S.; Oussalah, M.; Beddia, D.R.; Arhab, N. A Comprehensive Study on NLP Data Augmentation for Hate Speech Detection: Legacy Methods, BERT, and LLMs. arXiv 2024, arXiv:2404.00303. [Google Scholar]
- Bayer, M.; Kaufhold, M.A.; Buchhold, B.; Keller, M.; Dallmeyer, J.; Reuter, C. Data augmentation in natural language processing: A novel text generation approach for long and short text classifiers. Int. J. Mach. Learn. Cybern. 2023, 14, 135–150. [Google Scholar] [CrossRef] [PubMed]
- Cai, J.; Huang, S.; Jiang, Y.; Tan, Z.; Xie, P.; Tu, K. Improving Low-resource Named Entity Recognition with Graph Propagated Data Augmentation. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; Volume 2, pp. 110–118. [Google Scholar]
- Hua, J.; Cui, X.; Li, X.; Tang, K.; Zhu, P. Multimodal fake news detection through data augmentation-based contrastive learning. Appl. Soft Comput. 2023, 136, 110125. [Google Scholar] [CrossRef]
- Josi, A.; Alehdaghi, M.; Cruz, R.M.; Granger, E. Multimodal data augmentation for visual-infrared person ReID with corrupted data. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 32–41. [Google Scholar]
- Hao, X.; Zhu, Y.; Appalaraju, S.; Zhang, A.; Zhang, W.; Li, B.; Li, M. Mixgen: A new multi-modal data augmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 379–389. [Google Scholar]
- Shi, P.; Qi, H.; Liu, Z.; Yang, A. Context-guided ground truth sampling for multi-modality data augmentation in autonomous driving. IET Intell. Transp. Syst. 2023, 17, 463–473. [Google Scholar] [CrossRef]
- Setyono, J.C.; Zahra, A. Data augmentation and enhancement for multimodal speech emotion recognition. Bull. Electr. Eng. Inform. 2023, 12, 3008–3015. [Google Scholar] [CrossRef]
- Cai, H.; Huang, X.; Liu, Z.; Liao, W.; Dai, H.; Wu, Z.; Zhu, D.; Ren, H.; Li, Q.; Liu, T.; et al. Exploring Multimodal Approaches for Alzheimer’s Disease Detection Using Patient Speech Transcript and Audio Data. arXiv 2023, arXiv:2307.02514. [Google Scholar]
- Zhang, S.; Yang, Y.; Chen, C.; Zhang, X.; Leng, Q.; Zhao, X. Deep learning-based multimodal emotion recognition from audio, visual, and text modalities: A systematic review of recent advancements and future prospects. Expert Syst. Appl. 2023, 237, 121692. [Google Scholar]
- Rahman, W.; Hasan, M.K.; Lee, S.; Zadeh, A.; Mao, C.; Morency, L.P.; Hoque, E. Integrating multimodal information in large pretrained transformers. In Proceedings of the Association for Computational Linguistics Meeting, Online, 5–10 July 2020; Volume 2020, p. 2359. [Google Scholar]
- Tsai, Y.H.H.; Bai, S.; Liang, P.P.; Kolter, J.Z.; Morency, L.P.; Salakhutdinov, R. Multimodal transformer for unaligned multimodal language sequences. In Proceedings of the Association for Computational Linguistics Meeting, Florence, Italy, 28 July–2 August 2019; Volume 2019, p. 6558. [Google Scholar]
- Hazarika, D.; Zimmermann, R.; Poria, S. Misa: Modality-invariant and-specific representations for multimodal sentiment analysis. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1122–1131. [Google Scholar]
- Andersland, M. Amharic LLaMA and LLaVA: Multimodal LLMs for Low Resource Languages. arXiv 2024, arXiv:2403.06354. [Google Scholar]
- Huang, S.; Qin, L.; Wang, B.; Tu, G.; Xu, R. SDIF-DA: A Shallow-to-Deep Interaction Framework with Data Augmentation for Multi-Modal Intent Detection. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; IEEE: Piscataway, NY, USA, 2024; pp. 10206–10210. [Google Scholar]
- Hasan, M.K.; Islam, M.S.; Lee, S.; Rahman, W.; Naim, I.; Khan, M.I.; Hoque, E. TextMI: Textualize multimodal information for integrating non-verbal cues in pre-trained language models. arXiv 2023, arXiv:2303.15430. [Google Scholar]
- Hazmoune, S.; Bougamouza, F. Using transformers for multimodal emotion recognition: Taxonomies and state of the art review. Eng. Appl. Artif. Intell. 2024, 133, 108339. [Google Scholar]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Wang, Y.; Li, J.; Wang, H.; Qian, Y.; Wang, C.; Wu, Y. Wav2vec-Switch: Contrastive Learning from Original-Noisy Speech Pairs for Robust Speech Recognition. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 7097–7101. [Google Scholar] [CrossRef]
- Seo, M.; Baek, J.; Thorne, J.; Hwang, S.J. Retrieval-Augmented Data Augmentation for Low-Resource Domain Tasks. arXiv 2024, arXiv:2402.13482. [Google Scholar]
- Ferguson, J.; Hajishirzi, H.; Dasigi, P.; Khot, T. Retrieval data augmentation informed by downstream question answering performance. In Proceedings of the 5th Fact Extraction and VERification Workshop (FEVER), Dublin, Ireland, 22–26 May 2022; pp. 1–5. [Google Scholar]
- Al Roken, N.; Barlas, G. Multimodal Arabic emotion recognition using deep learning. Speech Commun. 2023, 155, 103005. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, H.; Wang, X.; Zhou, Q.; Zhao, S.; Teng, J. Mintrec: A new dataset for multimodal intent recognition. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 1688–1697. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}