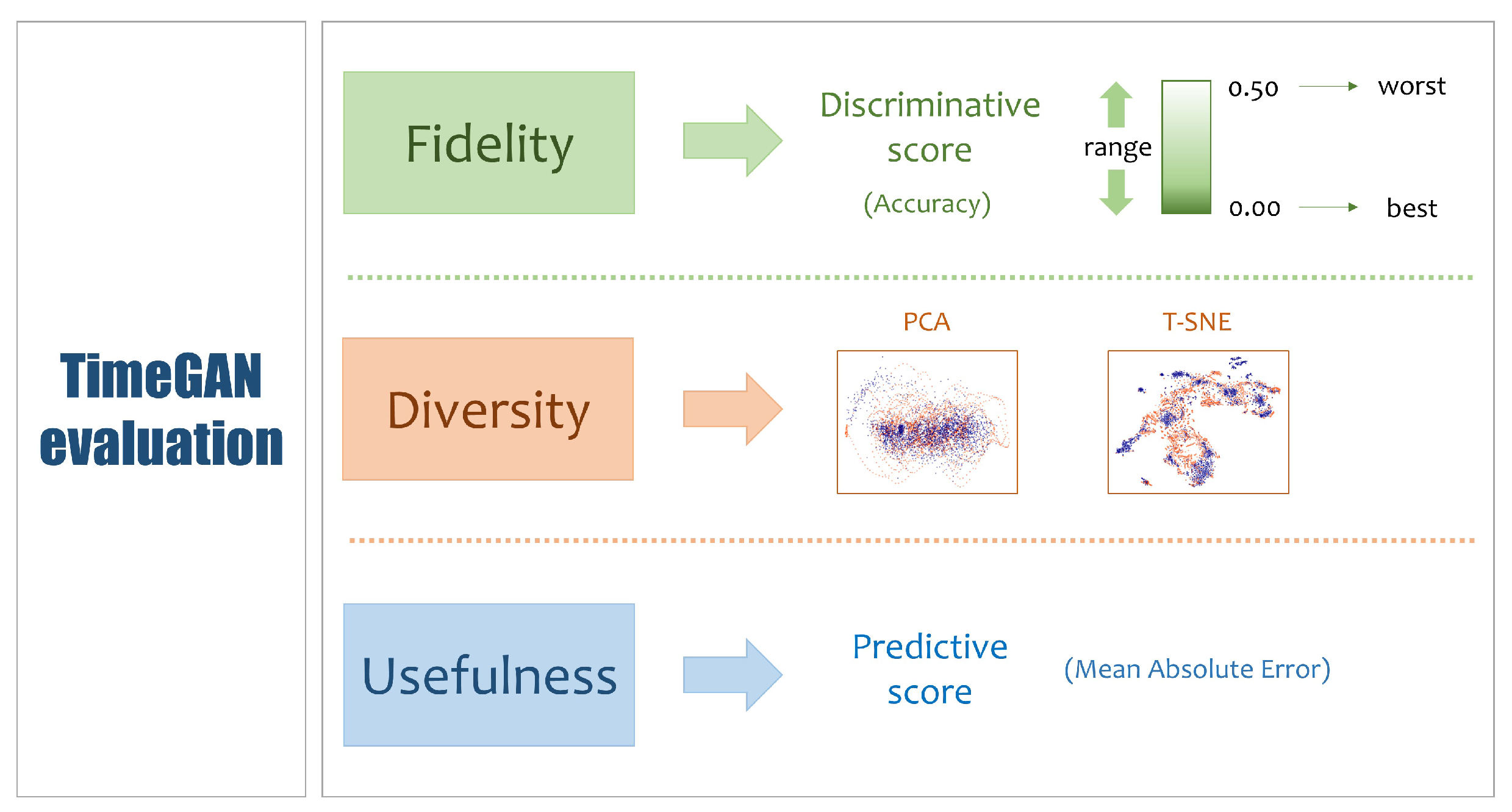
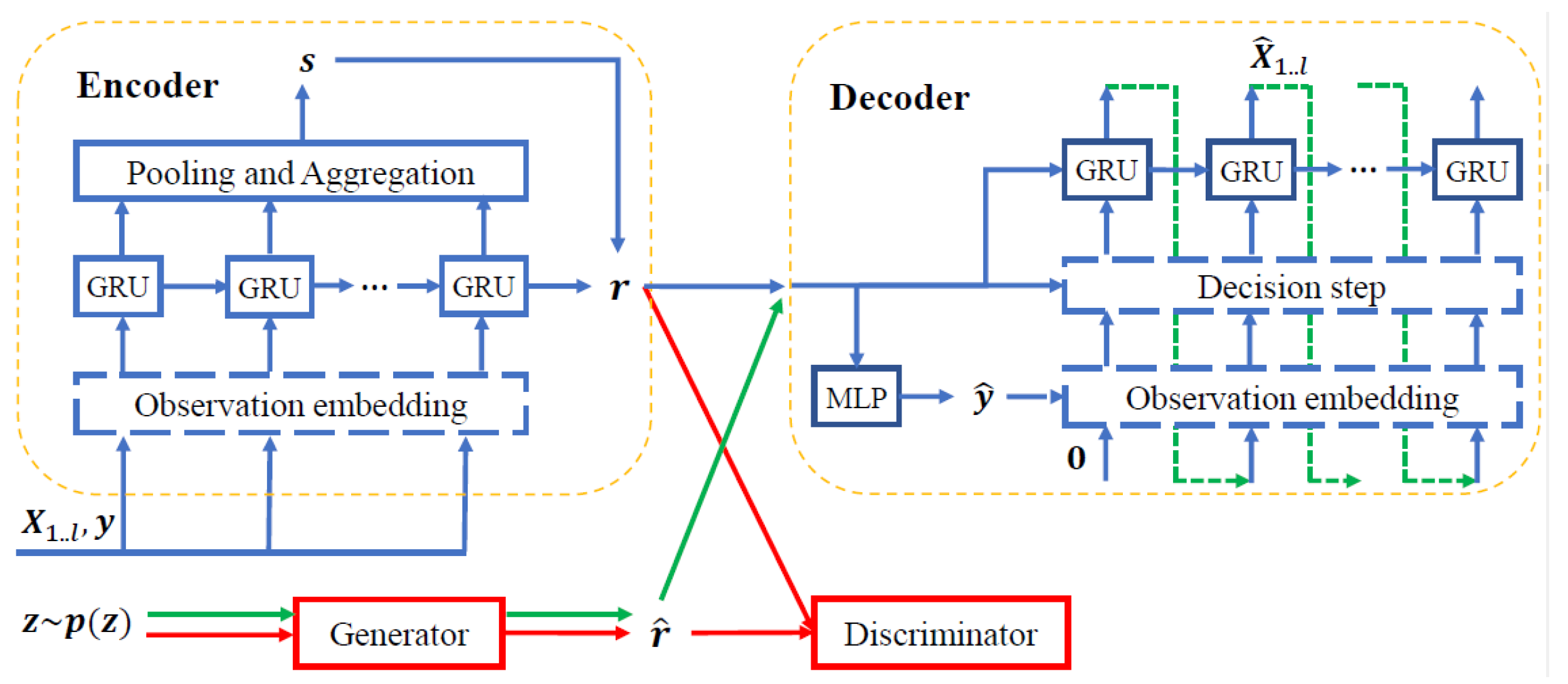
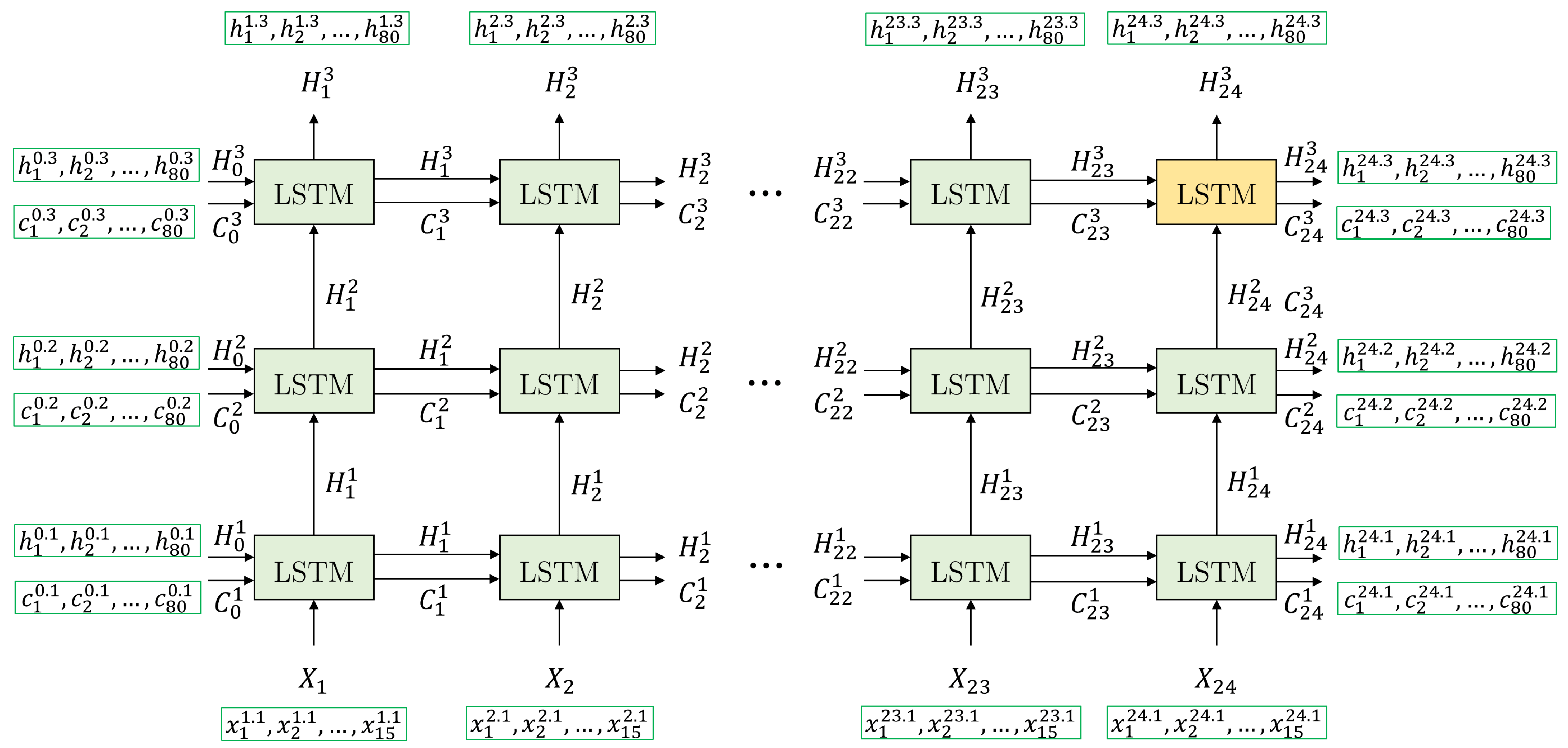
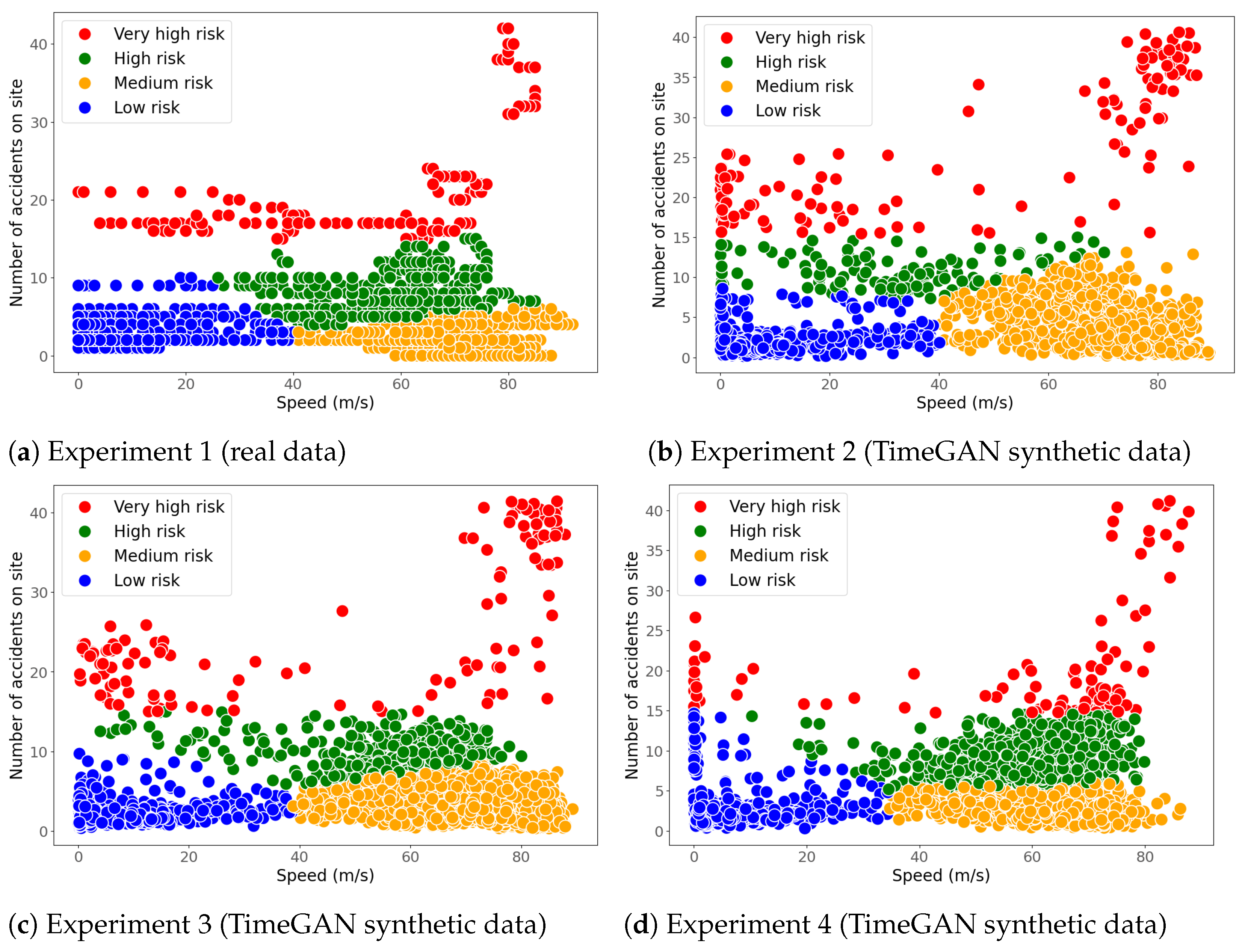
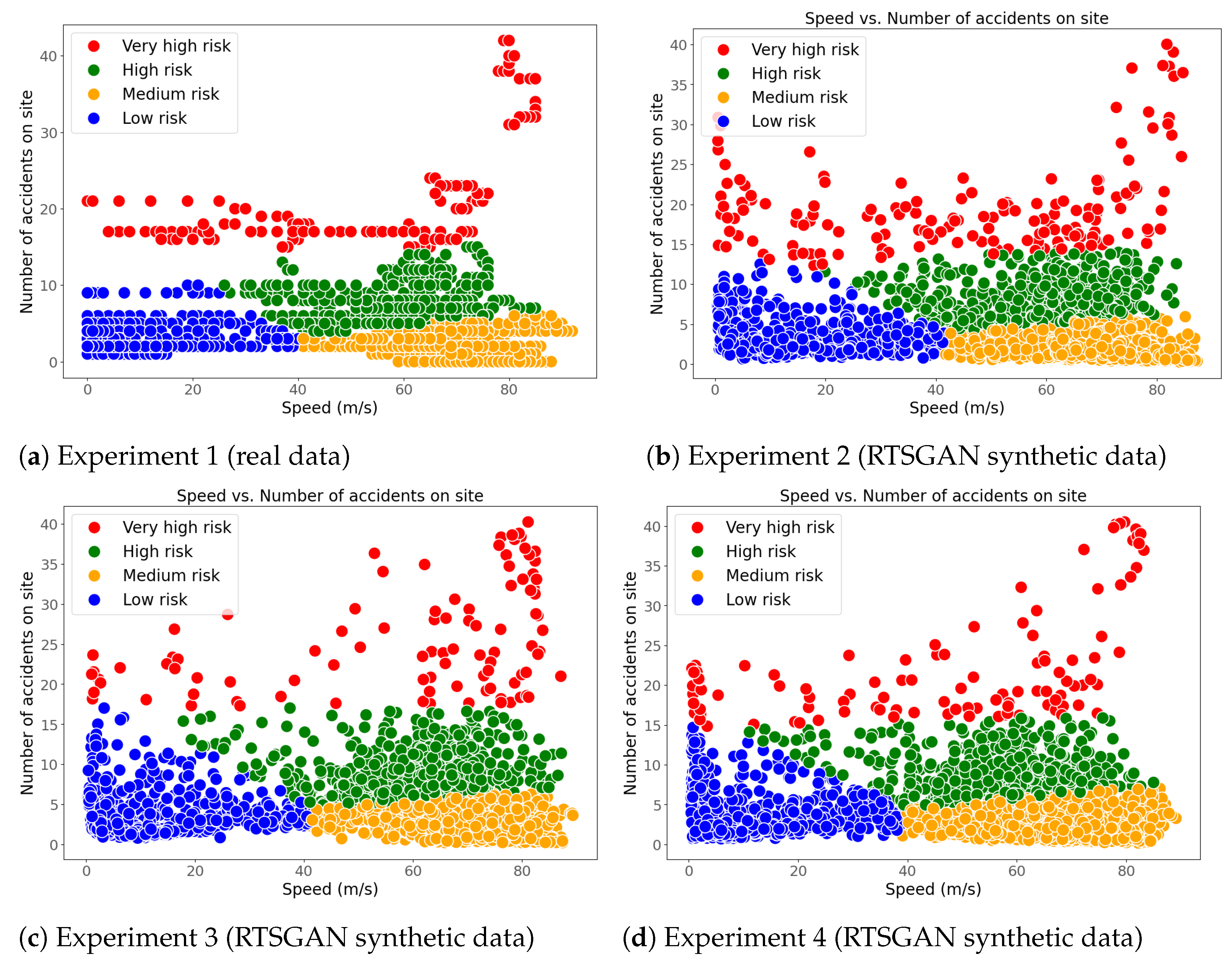
This appendix describes the experiments carried out to find the values of the hyperparameters for TimeGAN and for the discriminative and predictive networks used to evaluate the data generated by TimeGAN. The strategy adopted to find the hyperparameter values was as follows:
Appendix B.1. Candidate Hyperparameters for the Evaluation Networks
Synthetic data were generated with TimeGAN using the initial configuration in
Table 4 and then evaluated by the discriminative and predictive networks, for which the initial hyperparameters are shown in
Table 6. The hyperparameters calibrated for these two networks were (1) batch size and (2) number of iterations. In this group of experiments, the variation in the discriminative and predictive scores was analyzed by changing the values of the batch size and number of iterations together. In both cases, the average scores obtained with all batch sizes were calculated for each value of the specified number of iterations described below.
In the case of the discriminative network, batch sizes of 32, 64, 128, 256, and 512 were considered, and the obtained scores were compared when running 100, 200, 250, 500, 1000, and 2000 iterations. The results of these experiments are shown in
Table A1, where it can be seen that the best average score of 0.25954 was obtained when all batch sizes were considered and 200 iterations were run. Considering the values in
Table A1 with 200 iterations, the batch size that provides the best average value occurs when the number of iterations is 32. Therefore, the values of 32 and 200 were selected for the batch size and number of iterations hyperparameters of the discriminative network, respectively.
Table A1.
Discriminative scores by batch size and number of iterations.
Table A1.
Discriminative scores by batch size and number of iterations.
| Batch | No. of Iterations |
|---|
| Size | 100 | 200 | 250 | 500 | 1000 | 2000 | Average |
|---|
| 32 | 0.31651 | 0.12697 | 0.19681 | 0.43482 | 0.42021 | 0.49273 | 0.331346 |
| 64 | 0.15784 | 0.35663 | 0.43354 | 0.28392 | 0.41358 | 0.47525 | 0.353465 |
| 128 | 0.35287 | 0.24783 | 0.41498 | 0.43118 | 0.36524 | 0.49273 | 0.384141 |
| 256 | 0.36352 | 0.27920 | 0.27174 | 0.41613 | 0.41383 | 0.45427 | 0.366454 |
| 512 | 0.32901 | 0.28705 | 0.28730 | 0.47678 | 0.44017 | 0.48456 | 0.384152 |
| Average | 0.30395 | 0.25954 | 0.32088 | 0.40857 | 0.41061 | 0.47991 | |
For the case of the predictive network, the same variants of the discriminative network were considered for the batch size, and the numbers of iterations considered were 500, 1000, 2000, 4000, 5000, and 8000.
Table A2 shows the values found for the predictive scores, where it can be seen that the best average predictive score of 0.10597 was obtained when all batch sizes were considered and 500 iterations were executed. With 1000 iterations, a similar result is achieved; however, the lower number of iterations was preferred due to the lower computational cost. Under the same analysis as in the discriminative case, if we considered the values in
Table A2 with 500 iterations, then the batch size with the best average value is obtained when the number of iterations is 256. Therefore, values of 256 and 500 were chosen for the batch size and number of iterations hyperparameters of the predictive network, respectively.
Table A3 summarizes the best average values obtained for the hyperparameters of the discriminative and predictive networks.
Table A2.
Predictive scores by batch size and number of iterations.
Table A2.
Predictive scores by batch size and number of iterations.
| Batch | No. of Iterations |
|---|
| Size | 500 | 1000 | 2000 | 4000 | 5000 | 8000 | Average |
|---|
| 32 | 0.16399 | 0.10252 | 0.06720 | 0.35617 | 0.11546 | 0.17574 | 0.163518 |
| 64 | 0.11531 | 0.15578 | 0.10446 | 0.07016 | 0.10325 | 0.09987 | 0.108144 |
| 128 | 0.08567 | 0.10750 | 0.24060 | 0.13003 | 0.13113 | 0.09500 | 0.131659 |
| 256 | 0.09012 | 0.08453 | 0.07702 | 0.12728 | 0.07164 | 0.07150 | 0.087019 |
| 512 | 0.07475 | 0.08144 | 0.07228 | 0.13827 | 0.15466 | 0.15541 | 0.112806 |
| Average | 0.10597 | 0.10635 | 0.11231 | 0.16438 | 0.11523 | 0.11950 | |
Table A3.
Best hyperparameters for the evaluation networks.
Table A3.
Best hyperparameters for the evaluation networks.
| Hyperparameter | Discriminator | Predictor |
|---|
| Batch size | 32 | 256 |
| No. of iterations | 200 | 500 |
Appendix B.2. Determination of the Data Sequence Length Hyperparameter in TimeGAN
The TimeGAN hyperparameters determined in this section are the sequence length and number of hidden units of the LSTM networks. In these experiments, the hyperparameters for the evaluation networks of
Table 6 were used instead of the values of the hyperparameters obtained in
Appendix B.1.
Three experiments were performed with 16, 24, 32, 40, and 48 timesteps sequences to determine the most appropriate values for the TimeGAN sequence length hyperparameter. This length must be obtained carefully, as a very small value may not be sufficient to capture a practically useful sequence, while a very long sequence may require a large amount of resources and processing time. The results of the experiments to find the discriminative scores are shown in
Table A4, where it can be observed that the best average result of 0.158865 is obtained when using a sequence of length 24.
Table A4.
Discriminative scores by length of the sequences.
Table A4.
Discriminative scores by length of the sequences.
| Experiment | Sequence Length |
|---|
| 16 | 24 | 32 | 40 | 48 |
|---|
| 1 | 0.178690 | 0.126977 | 0.424268 | 0.378498 | 0.338867 |
| 2 | 0.122583 | 0.172577 | 0.294302 | 0.394288 | 0.373359 |
| 3 | 0.470293 | 0.177041 | 0.162676 | 0.463736 | 0.300644 |
| Average | 0.257189 | 0.158865 | 0.293875 | 0.412174 | 0.337623 |
The results of the experiments carried out with the predictive network are shown in
Table A5, which shows that the best average result of 0.081198 is achieved with sequences of length 24.
Table A5.
Predictive scores by length of the sequences.
Table A5.
Predictive scores by length of the sequences.
| Experiment | Sequence Length |
|---|
| 16 | 24 | 32 | 40 | 48 |
|---|
| 1 | 0.079849 | 0.090120 | 0.084412 | 0.096048 | 0.096296 |
| 2 | 0.076416 | 0.077339 | 0.087748 | 0.079849 | 0.155386 |
| 3 | 0.096282 | 0.076136 | 0.077865 | 0.147370 | 0.119579 |
| Average | 0.084182 | 0.081198 | 0.083342 | 0.107756 | 0.123754 |
Appendix B.4. Final Hyperparameters of the Networks
In this section, the following values are determined: (1) the number of iterations of TimeGAN and (2) the number of iterations and batch size of the predictive network.
Table A8 summarizes the best values found in
Appendix B.2 and
Appendix B.3.
Table A8.
Final candidate TimeGAN hyperparameters.
Table A8.
Final candidate TimeGAN hyperparameters.
| TimeGAN Hyperparameter | Value |
|---|
| Sequence length | 24 |
| No. of hidden units | 80 |
It can be observed from
Table A8 that the best value for the number of hidden units for TimeGAN networks is equal to 80 and that the best value for the sequence length is 24. We ran a set of experiments to observe the values of the scores when using several different numbers of hidden units close to 80, specifically, with 70, 80, and 90 hidden units. For the discriminative and predictive networks, the hyperparameters in
Table 6 were updated with the values obtained in
Appendix B.1.
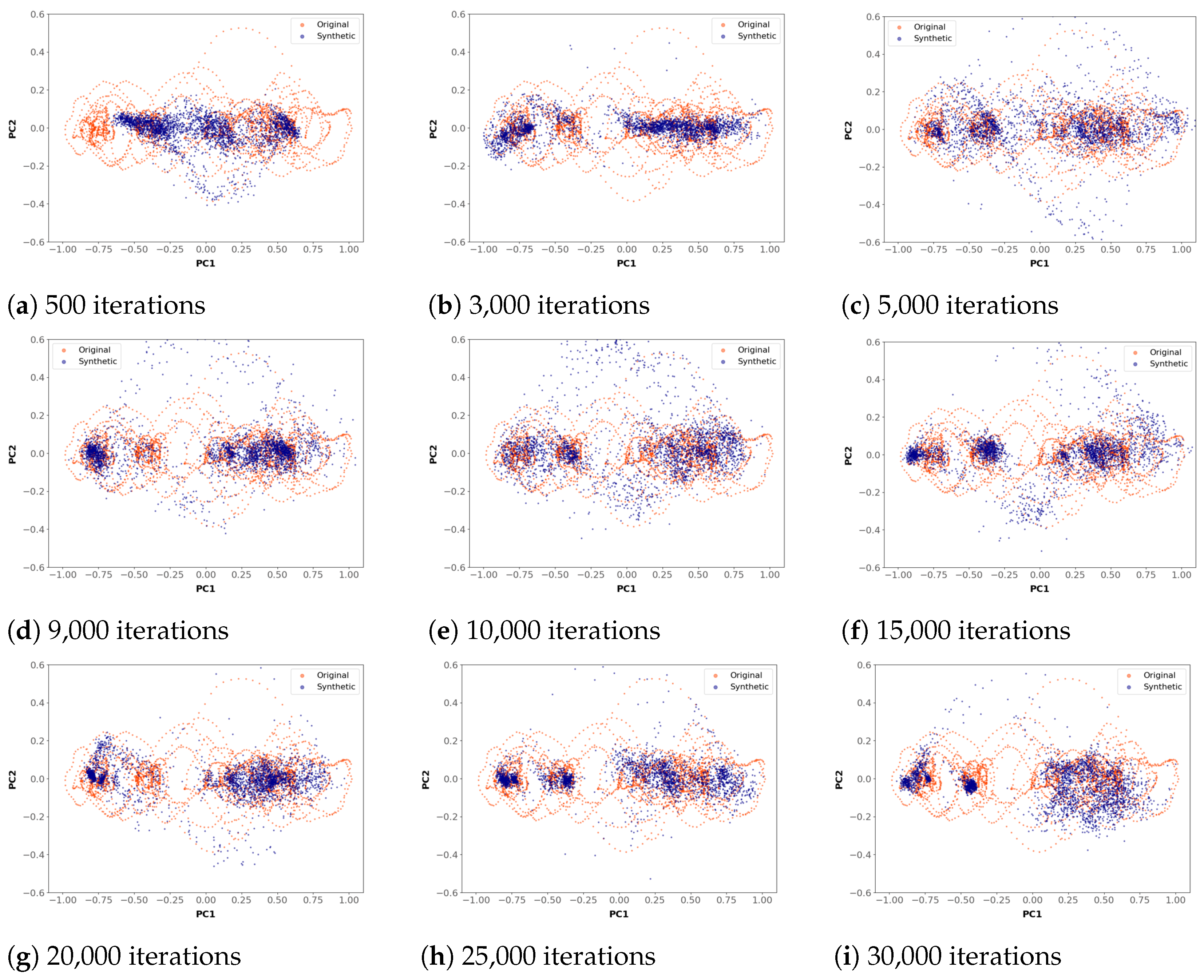
For our analysis of the discriminative scores, a series of 27 experiments were run, three for each number of hidden units for each of 500, 3000, 5000, 9000, 10,000, 15,000, 20,000, 25,000, and 30,000 iterations. This set of experiments allowed us to establish the best number of iterations to use when training the TimeGAN networks. After the first run of 27 experiments, the results shown in
Table A9 were obtained.
Table A9.
Discriminative scores for the first run of experiments.
Table A9.
Discriminative scores for the first run of experiments.
| No. of TimeGAN Iterations 1 | Hidden Units | Discriminative Score |
|---|
| 500 | 70 | 0.263010 |
| 80 | 0.230102 |
| 90 | 0.189796 |
| 3000 | 70 | 0.079337 |
| 80 | 0.092730 |
| 90 | 0.047959 |
| 5000 | 70 | 0.156378 |
| 80 | 0.044643 |
| 90 | 0.072126 |
| 9000 | 70 | 0.041199 |
| 80 | 0.057908 |
| 90 | 0.064413 |
| 10,000 | 70 | 0.045663 |
| 80 | 0.050255 |
| 90 | 0.055995 |
| 15,000 | 70 | 0.062883 |
| 80 | 0.025510 |
| 90 | 0.101913 |
| 20,000 | 70 | 0.075000 |
| 80 | 0.075255 |
| 90 | 0.054974 |
| 25,000 | 70 | 0.069005 |
| 80 | 0.127296 |
| 90 | 0.051148 |
| 30,000 | 70 | 0.076658 |
| 80 | 0.068495 |
| 90 | 0.134566 |
Regarding the analysis of predictive scores, a series of fifteen experiments were run, three for each number of hidden units for each of 500, 3000, 5000, 9000, and 10,000 iterations. After the first run of fifteen experiments, the results shown in
Table A10 were obtained.
Upon closely examining the predictive scores in
Table A10, it can be noticed that the scores do not improve very much even when the number of TimeGAN iterations increases from 500 to 10,000, and seem to stagnate. For this reason, we used one of the following best values from the set of hyperparameters obtained in
Appendix B.1 to perform a new set of experiments; in this case, the value of 8000 iterations was selected and used, instead of 500 for the discriminative network.
The variation of the predictive score on data generated with TimeGAN when changing the number of iterations of the predictive network was analyzed in experiments with 70, 80, and 90 hidden units and with 500, 2000, 5000, and 8000 iterations for the predictive network, all with 10,000 TimeGAN iterations. The results in
Table A11 reflect a considerable improvement in the predictive scores with 70, 80, and 90 hidden units when increasing the number of iterations from 500 to 8000 in the predictive network. Therefore, this value was established as the new hyperparameter for the number of iterations of the predictive network.
Table A10.
Predictive scores for the first run of experiments.
Table A10.
Predictive scores for the first run of experiments.
| No. of TimeGAN Iterations 1 | Hidden Units | Predictive Score |
|---|
| 500 | 70 | 0.103060 |
| 80 | 0.078703 |
| 90 | 0.074426 |
| 3000 | 70 | 0.069205 |
| 80 | 0.071240 |
| 90 | 0.073169 |
| 5000 | 70 | 0.065946 |
| 80 | 0.068529 |
| 90 | 0.069467 |
| 9000 | 70 | 0.069823 |
| 80 | 0.070330 |
| 90 | 0.070437 |
| 10,000 | 70 | 0.070021 |
| 80 | 0.068833 |
| 90 | 0.065653 |
Table A11.
Predictive scores by number of iterations in the predictive network.
Table A11.
Predictive scores by number of iterations in the predictive network.
| Number of | Number of Iterations in the Predictive Network 1 |
|---|
| Hidden Units | 500 | 2000 | 5000 | 8000 |
|---|
| 70 | 0.070021 | 0.054281 | 0.047422 | 0.044132 |
| 80 | 0.068833 | 0.052964 | 0.043623 | 0.039589 |
| 90 | 0.065653 | 0.053009 | 0.047998 | 0.043958 |
| Average | 0.068169 | 0.053418 | 0.046348 | 0.042560 |
The 27 experiments were then run again using the value of 8000 instead of 500 for the number of iterations of the predictive network and keeping its batch size fixed at 256. The results after applying this change are shown in
Table A12.
Table A12.
Predictive scores for first fit of predictive network values.
Table A12.
Predictive scores for first fit of predictive network values.
| No. of TimeGAN Iterations 1 | Hidden Units | Predictive Score |
|---|
| 500 | 70 | 0.120283 |
| 80 | 0.068555 |
| 90 | 0.069589 |
| 3000 | 70 | 0.053960 |
| 80 | 0.048301 |
| 90 | 0.052339 |
| 5000 | 70 | 0.047269 |
| 80 | 0.046167 |
| 90 | 0.051160 |
| 9000 | 70 | 0.049712 |
| 80 | 0.045722 |
| 90 | 0.048057 |
| 10,000 | 70 | 0.044132 |
| 80 | 0.039589 |
| 90 | 0.043958 |
| 15,000 | 70 | 0.045661 |
| 80 | 0.045869 |
| 90 | 0.050569 |
| 20,000 | 70 | 0.045642 |
| 80 | 0.051687 |
| 90 | 0.046660 |
| 25,000 | 70 | 0.050789 |
| 80 | 0.054795 |
| 90 | 0.048775 |
| 30,000 | 70 | 0.044212 |
| 80 | 0.048324 |
| 90 | 0.055946 |
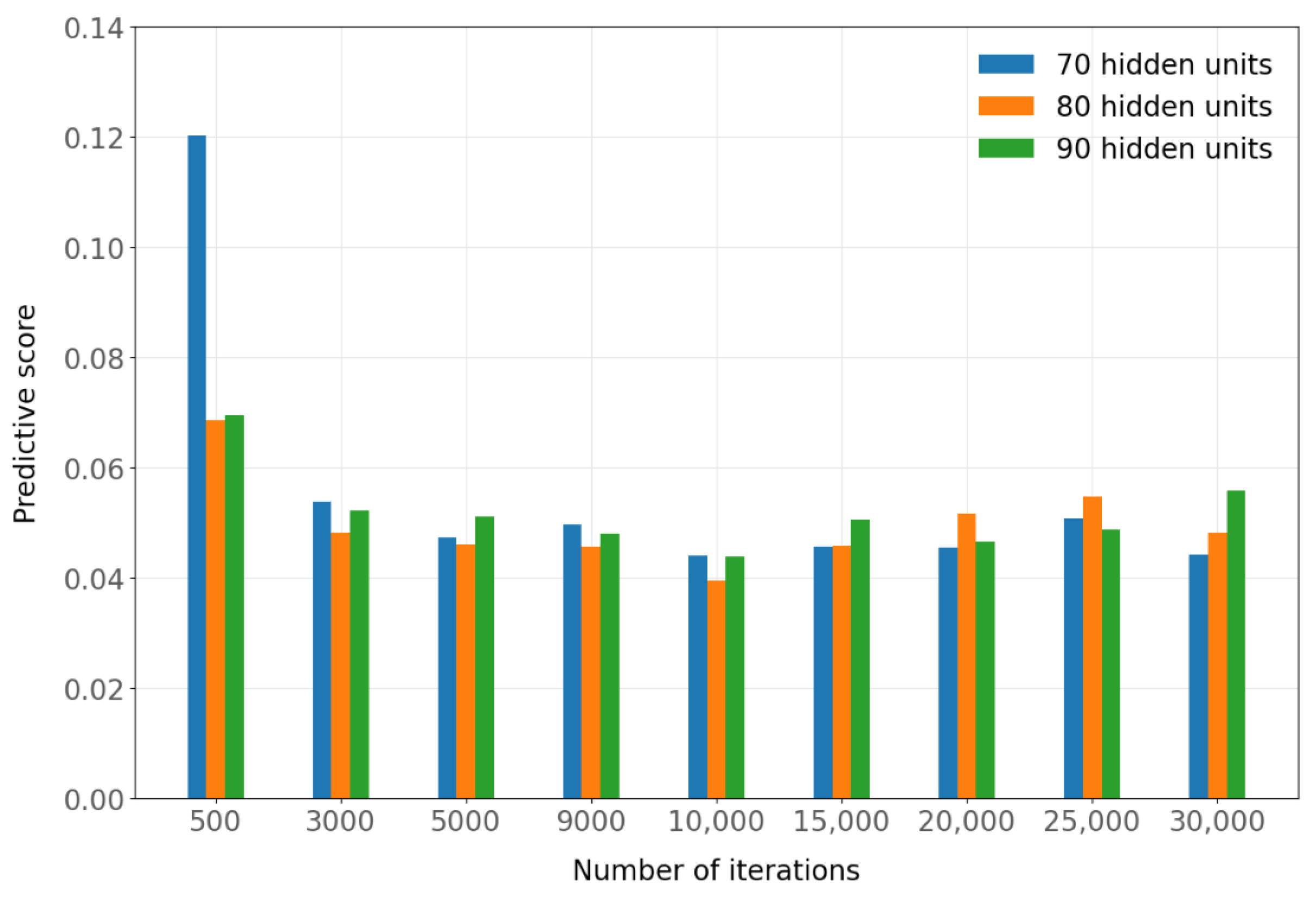
Figure A2 shows the predictive scores corresponding to
Table A12.
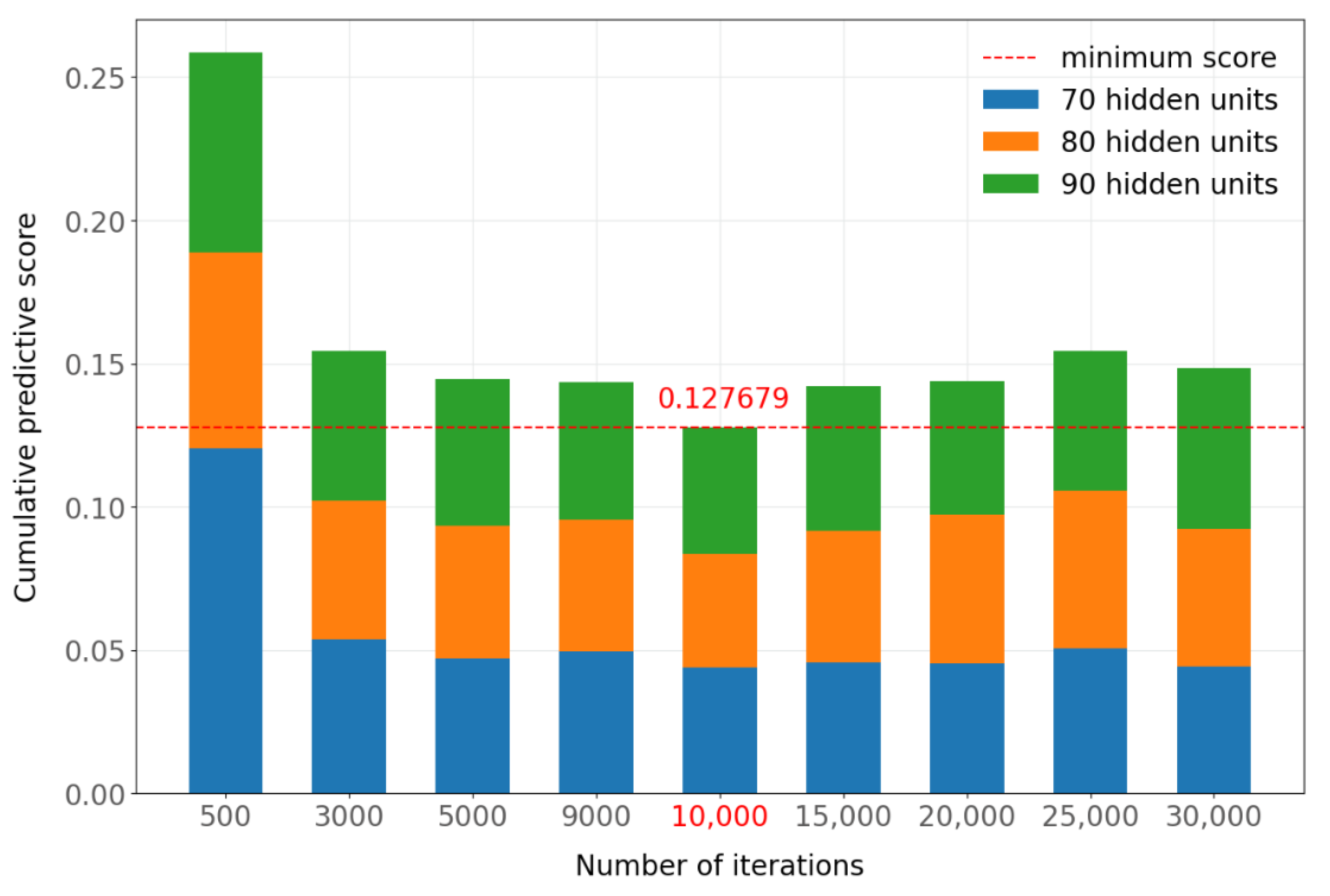
Figure A3 shows an alternative way of looking at the results of
Figure A2, showing the cumulative predictive scores for 70, 80, and 90 hidden units for each number of iterations considered. This figure shows that the lowest (best) sum of the scores occurred when 10,000 iterations were used in TimeGAN. Similar results were obtained when the experiments were repeated with 8000 iterations and a batch size of 512 instead of 256 for the predictive network, with a slight improvement in training time.
Table A13 compares the predictive scores when using batch sizes 256 and 512 in the predictive network.
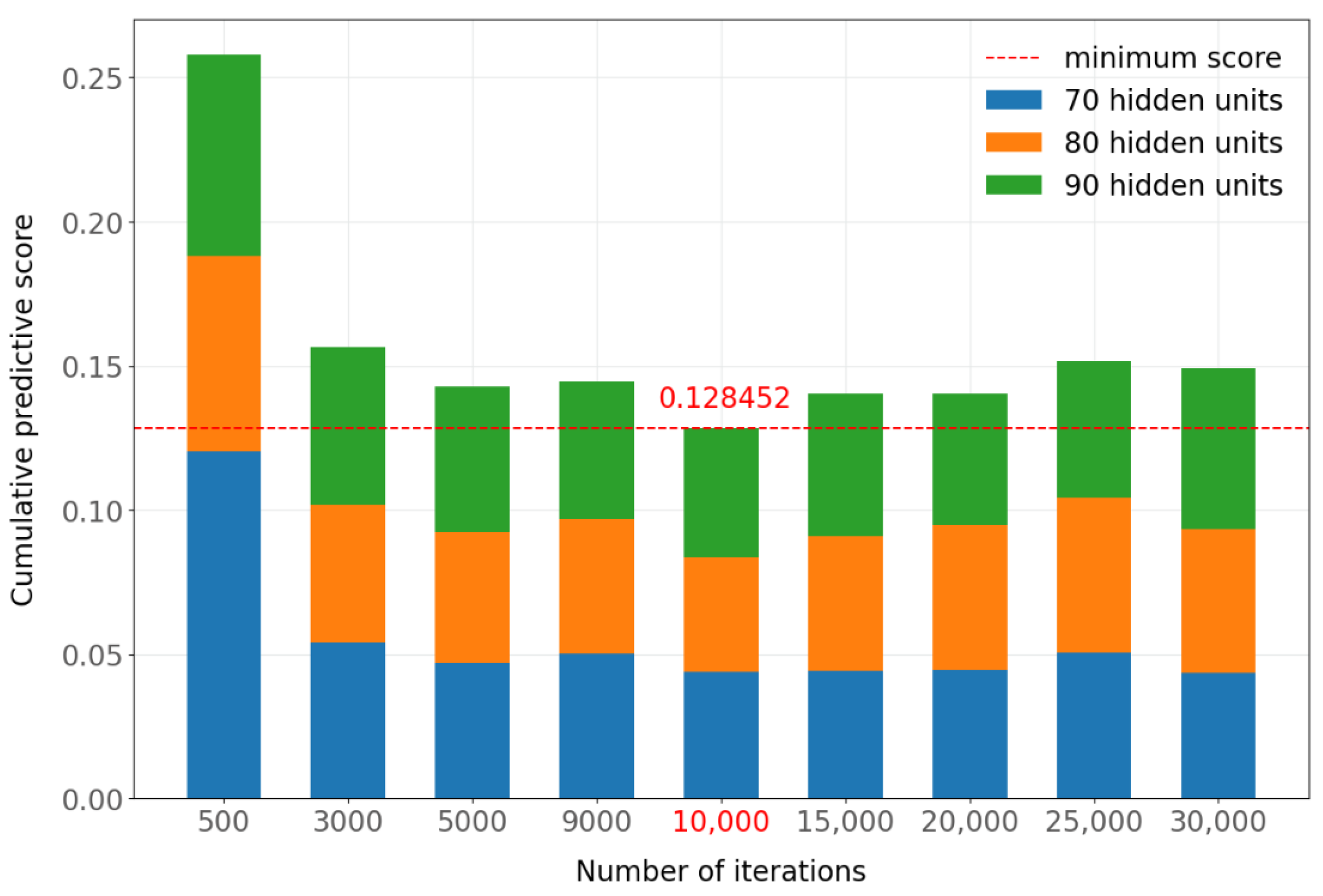
Figure A4 shows the predictive scores with a batch size of 512. The cumulative scores for each number of iterations with a batch size of 512 are shown in
Figure A5, where the best value is obtained with 10,000 iterations. When comparing the results obtained with batch sizes of 256 and 512 in the predictive network, quite similar values are obtained, with 0.127679 for a batch size of 256 and 0.128452 for a batch size of 512. In this case, 512 was chosen as the value of the batch size hyperparameter because it required a slightly shorter training time.
Table A13.
Comparison between adjusted predictive scores for different batch sizes.
Table A13.
Comparison between adjusted predictive scores for different batch sizes.
| No. of TimeGAN Iterations 1 | Hidden Units | Predictive Score (Batch Size = 256) | Predictive Score (Batch Size = 512) |
|---|
| 500 | 70 | 0.120283 | 0.120361 |
| 80 | 0.068555 | 0.067848 |
| 90 | 0.069589 | 0.069784 |
| 3000 | 70 | 0.053960 | 0.054237 |
| 80 | 0.048301 | 0.047550 |
| 90 | 0.052339 | 0.054814 |
| 5000 | 70 | 0.047269 | 0.047083 |
| 80 | 0.046167 | 0.045364 |
| 90 | 0.051160 | 0.050311 |
| 9000 | 70 | 0.049712 | 0.050340 |
| 80 | 0.045722 | 0.046526 |
| 90 | 0.048057 | 0.047894 |
| 10,000 | 70 | 0.044132 | 0.044151 |
| 80 | 0.039589 | 0.039535 |
| 90 | 0.043958 | 0.044766 |
| 15,000 | 70 | 0.045661 | 0.044439 |
| 80 | 0.045869 | 0.046439 |
| 90 | 0.050569 | 0.049636 |
| 20,000 | 70 | 0.045642 | 0.044827 |
| 80 | 0.051687 | 0.050140 |
| 90 | 0.046660 | 0.045477 |
| 25,000 | 70 | 0.050789 | 0.050622 |
| 80 | 0.054795 | 0.053755 |
| 90 | 0.048775 | 0.047294 |
| 30,000 | 70 | 0.044212 | 0.043546 |
| 80 | 0.048324 | 0.049939 |
| 90 | 0.055946 | 0.055648 |
Figure A2.
Predictive score by number of iterations of the predictive network (batch size = 256).
Figure A2.
Predictive score by number of iterations of the predictive network (batch size = 256).
Figure A3.
Cumulative score by number of iterations of the predictive network (batch size = 256).
Figure A3.
Cumulative score by number of iterations of the predictive network (batch size = 256).
Figure A4.
Predictive score by number of iterations of the predictive network (batch size = 512).
Figure A4.
Predictive score by number of iterations of the predictive network (batch size = 512).
Figure A5.
Cumulative score by number of iterations of the predictive network (batch size = 512).
Figure A5.
Cumulative score by number of iterations of the predictive network (batch size = 512).
Appendix B.5. Final Hyperparameters
Table A14.
Best candidate scores for the evaluation networks.
Table A14.
Best candidate scores for the evaluation networks.
| No. of TimeGAN Iterations | Hidden Units | Discriminative Score | Predictive Score |
|---|
| 15,000 | 80 | 0.025510 | 0.046439 |
| 10,000 | 80 | 0.050255 | 0.039535 |
The best discriminative and predictive scores were obtained with different numbers of iterations in TimeGAN; the best discriminative score was 0.025510, obtained with 15,000 iterations, while the best predictive score was 0.039535, obtained with 10,000 iterations. It was necessary to choose one of these two numbers of iterations as the final TimeGAN hyperparameter. The value of 10,000 was preferred as the hyperparameter value for the following reasons: (1) it required less training time, and (2) the cumulative discriminative scores with 10,000 iterations were lower than those obtained with 15,000 iterations.
In
Appendix B.3, we identified that the best value for the number of hidden units hyperparameter of TimeGAN was 80; however, the closest values to 80 that were considered in that analysis were 60 and 100. The results in this appendix establish that the best number of iterations to generate data with TimeGAN is 10,000; furthermore, the results in
Table A9 indicate that the best discriminative score for that number of iterations is 0.045663, which is obtained with 70 hidden units. For this reason, we updated the hidden units hyperparameter from 80 to 70.
Table A15 shows the final hyperparameters that produced the best experimental results.
Table A15.
Final TimeGAN hyperparameters.
Table A15.
Final TimeGAN hyperparameters.
| No. of TimeGAN Iterations | Sequence Length | Hidden Units |
|---|
| 10,000 | 24 | 70 |


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}