Abstract
As the scale and complexity of software for industrial equipment increases, the risk of defects being introduced into the software also increases. Over-the-air (OTA) technology eliminates software defects by regularly updating and maintaining the software equipment. However, downloading an upgraded file is time-consuming. The differential compression algorithm can rapidly complete OTA software upgrades. To solve the low-efficiency problem of suffix array sorting in the BsDiff algorithm, a fusion algorithm based on the suffix array induced sorting and BsDiff methods was proposed to reduce the time consumption in the OTA upgrade process. The execution of the difference algorithm in the cloud was simulated using bench experiments. Subsequently, the function and performance of the proposed algorithm were experimentally evaluated. The results showed that the optimized algorithm could save more than 35% of the time compared to the original algorithm, which improved the OTA upgrade efficiency to a certain extent.
1. Introduction
Over-the-air (OTA) technology refers to the remote management of systems through the air interface of mobile communication, which distributes updated software and updates configurations to devices using communication capabilities and secure encryption [1]. This technology can be classified as either software-over-the-air (SOTA) [2] and firmware-over-the-air (FOTA) [3]. SOTA is a technology that updates software applications on smart devices over a wireless network and is used for software systems. FOTA updates the firmware of smart devices to upgrade the core underlying hardware software.
As industrial Internet and Internet of Things technologies evolve, industrial equipment will become more advanced, the amount of software for smart devices will become richer, and the addition of OTA configurations will become more important for service updates and rollouts. OTA technology can promote rapid industrial development by decoupling the software and hardware development of industrial equipment, remotely eliminating defects, and providing continuous maintenance and updates. Decoupling software and hardware development, wherein user data are uploaded to the cloud for iterative development, results in a new model of personalized and customized software and hardware development oriented according to user needs [4]. If there are defects or errors in the use of the equipment, the remote update mechanism can solve the machine errors. In industrial production, continuous OTA maintenance and updates can further improve production efficiency without interruptions [5].
As OTA technology is increasingly being applied in the industrial field, its high demand for service bandwidth and service quality will require a large amount of bandwidth resources, without which there may be upgrade interruptions. The 5G-U (5G on unlicensed band) network has a high data transmission rate and low delay communication capability, which can significantly improve wireless communication performance [6,7]. For the centralized upgrade of various equipment in factories, the 5G-U network can meet strict requirements for the data transmission rate. However, transferring all firmware images to a large number of devices that need to be upgraded is inefficient. Sending one byte wirelessly may consume the same amount of energy as executing 1000 instructions [8]. The difference compression algorithm can record the changes between the two versions. The principle of this algorithm is to find the common string between the old and new version files and compress the data by replacing the substring with a reference copy to obtain the “delta” [9], namely the difference file between the two version files. The regression algorithm creates a new version of the file by combining the differential file (incremental) with the old file, as illustrated in Figure 1, which is typically much smaller than the entire upgraded file, thus reducing the upgrade time and mobile network consumption during the transmission and enabling rapid OTA software upgrades.
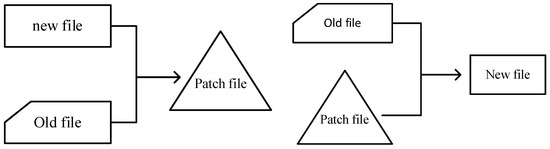
Figure 1.
Principle of the differential compression algorithm.
For differential compression algorithms, much of the literature is based on byte processing techniques or solving optimization problems to reduce increments in the differential process. Shapira et al. [10] provided a preprocessing step for the in-place sliding window (IPSW) algorithm to align the overlapping parts of the source file and new file when compared with the new file, thus reducing the space required for encoding and decoding and improving the upgrade efficiency. Kiyohara et al. [11] proposed a linked list method to reduce the impact of different operational changes on differences, which improves the similarity of firmware to optimize performance. However, such methods can lead to program memory fragmentation in the event of a change in a link, which results in significant energy consumption if the functions are called in different parts of a flash. Stolikj et al. [12] proposed a greedy algorithm to search for the smallest horizontal increment with the largest vertical increment to obtain an optimal solution to reduce the difference between software packages. [13] proposed an improved byte-pair coding (BPE) fast compression technology that combines the concepts of compressed lexicographical order and difference, realizing fast memory rewriting and achieving a compression efficiency approximately six times faster than that of the traditional BEP algorithm. Patrascu et al. [14] proposed an improved diff algorithm that records all copy and app operations from old files to new files and applies it to cloud forensic systems with high data similarity. The aforementioned method achieves minimal increments between old and new files in various ways. However, the operations of the encoding process are programmed into files, causing a certain amount of memory waste. Panta et al. Cho et al. [15] proposed an improved z-delta algorithm using a relaxed greedy matching algorithm, which reduced decoding complexity and incremental file size. However, this type of optimization method is typically suitable for creating reconfigurable incremental files in place because of its fast response. However, compared with mainstream and mature difference compression algorithms, the differential efficiency optimization of the algorithm is not obvious.
Therefore, the differential compression algorithm should be sufficiently universal to allow OTA equipment upgrades in various fields. Percival et al. [16] proposed a byte-processing technology based on the BsDiff algorithm for the differential compression of binary files. Compared with previous studies by Stolikj et al. [17], simple coding and efficient compression of the upgraded software were realized. The algorithm has good differential performance for small files; however, the encoding process for large files is time-consuming and consumes considerable hardware memory. This is because the algorithm searches for a string that matches the old and new files by comparing the suffix tree [18,19] and the generation and sorting process of the suffix tree requires considerable time and memory, resulting in a long upgrade time and wasted communication network traffic.
In Section 2, background related to OTA technology and the differential file approach are introduced. In Section 3, the deficiencies of BsDiff are summarized, and feasible optimization and improvement methods based on BsDiff/Bspatch are proposed. In Section 4, the experimental results of the proposed method are compared and analyzed. The results of this study are summarized in Section 5.
2. BsDiff Theory
The main purpose of OTA software upgrades is to effectively distribute the software files that need to be updated and to update and deploy the files that need to be upgraded to hardware devices. The BsDiff and Bspatch algorithms can realize the above process and can be used for the difference and restoration between old and new files. BsDiff generates the required upgrade patch, and the OTA update is completed through the Bspatch algorithm. The BsDiff and Bspatch algorithms are used to determine the difference and regression between the old and new files. The BsDiff algorithm searches for an identical data segment using the suffix array generation algorithm and attempts to expand the approximate but not identical data segment forward and backward. The BsDiff algorithm comprises two parts: a similarity part, which calculates the increment by subtracting the data, and a differential part, which is inserted into a new data segment using an insert command. The Bspatch algorithm generates new binaries by directly editing old binaries and opening new memories to record the results. Because the Bspatch restoration algorithm performs simple calculation operations, an improvement in its restoration performance has little impact on the overall upgrade efficiency. Therefore, this study conducted in-depth research on the BsDiff algorithm for the differential process.
Figure 2 illustrates the principle of the BsDiff algorithm. The algorithm compares the old[scan + offset… scan + offset + len − 1] and new[scan… scan + len − 1], which have a maximum matching length of more than 8 bytes, such as “hello” for input and “world” for output. BsDiff divides the previous “perfect match region” and at least 8-byte “imperfect mismatch regions” in linear time, with at least 50% mismatch between their forward and backward expansion fields. The “perfect matching region” and “imperfect matching region” together constitute the “approximate matching region.” The interval between the two “approximate match regions” forms the “completely mismatched area,” which is called the extract string.
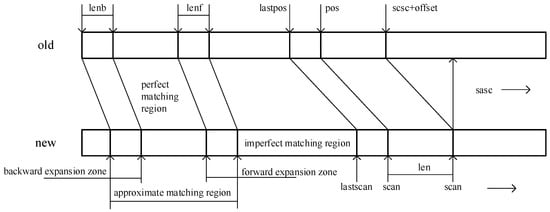
Figure 2.
BsDiff theory.
The BsDiff algorithm finds the longest common string between the old and new files by constructing a suffix array of old binary files to extract the difference between the old and new files [20]. BsDiff then represents the difference between the old and new binary files through a series of editing operations; the recorded editing operations are called differential files. When the old and new files differ, the “imperfect match zone” contains a large number of identical values, and value subtraction results in diffi, a string containing a large number of zero values. Based on the compression properties, diffi can be compressed to a very small size using the BZIP tool. Similarly, extractj is the “completely mismatched region” data that can be copied directly to the new address. The difference file of the BsDiff algorithm is combined with diffi and extractj for replication and insertion, respectively. The data format of the difference file is composed of four parts: the data header, control data, diff data, and extracted data, as shown in Figure 3. Control data <xi, yj, zk> record diffi bytes, extractj bytes, and offsets relative to the old file, respectively. When restoring the differential file, Bspatch reads the copy and inserts the information according to the control instructions to complete the modification.

Figure 3.
Format of patch file.
The BsDiff algorithm determines the maximum approximate matching data segment length by generating suffix arrays of the old and new version files. The length of the matching string is increased by extending the forward and backward areas. The longer the block length of the string, the fewer the replication and insertion operations during packet processing; thus, the number of bytes in the control area can be effectively reduced. This approach enables the BsDiff algorithm to obtain the desired subpackage size; however, the response time is long. This is because the BsDiff algorithm searches for common strings by traversing the entire file, and string comparison is achieved by post-fix array generation and sorting. In the BsDiff algorithm, the time complexity of the qusfsort() function used to generate the suffix array and sort is as high as O(nlogn). This consumes considerable time in the process of the difference algorithm and occupies a considerable amount of hardware memory, resulting in long OTA upgrade times and communication flows.
3. SAIS–BsDiff Algorithm
In this section, we introduce the improvements based on the BsDiff algorithm. The suffix array induced sorting (SAIS) is a suffix array (SA) construction algorithm that consumes linear time and memory [21]. It uses an LMS substring to replace the original string to be processed and processes the order of the LMS substring through induced sorting, which has good suffix array sorting performance. The SAIS algorithm can be used to optimize and improve the low efficiency of suffix array sorting in the BsDiff algorithm and reduce the time complexity to O(n). A fusion algorithm based on the SAIS algorithm and the BsDiff method, called the SAIS–BsDiff algorithm, is proposed to improve the efficiency of differential compression BsDiff. The calculation process for the SAIS–BsDiff algorithm is shown in Figure 4. This optimization scheme can reduce the time consumed in the OTA upgrade process and the waste of the communication network in the upgrade process.
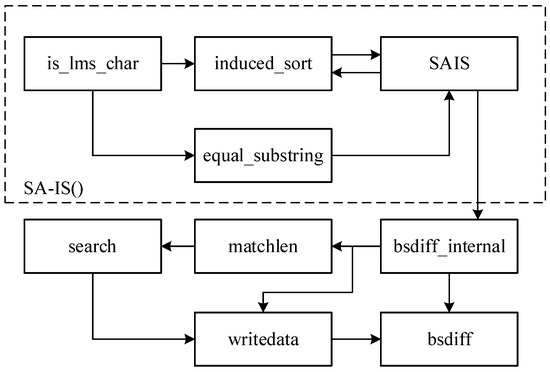
Figure 4.
SAIS–BsDiff Algorithm.
The input of the proposed algorithm is a mirror image of the old version, and the output is a Diff (difference) file. The calculation process of the proposed SAIS–Bsidff difference algorithm is as follows: first, the LMS substring is created, and the suffix array is built through is_lms_char. The LMS substring can replace the original suffix array by equal_substring, induced by induced_sort to the LMS string, and SAIS finally obtains a simple string summary. The generated string summary replaces the original suffix array as input for the BsDiff algorithm. The search function searches for the data segment matched by the old and new files by traversing the entire file; it finds the maximum matched data segment length using matchlen, which is sent to BsDiff_internal. BsDiff_internal processes data segments, such as calculating the approximate and mismatched regions of a file, and processes data segments in different regions. The processed data are copied using the writeData function. Finally, the data are collated using the BsDiff function, and the output of the algorithm is realized through BZ2P packet compression. That is, the output is a Diff file. At this point, the difference algorithm is completed. Then, when the assignment is downloaded to the networked terminal, the restore operation is performed. That is, the internal computing unit of the networked terminal performs the corresponding calculation operation, thereby restoring the difference file to the new version file. In this case, the input of the restoration algorithm is the Diff file and the old version file, and the output is the upgrade file. The output of multiple files can be based on the file number information to achieve multiple package splicing in the controller. This splitting and splicing behavior realizes the whole process of the OTA upgrade.
The SAIS lexicographic generation framework used to optimize BsDiff is presented in Algorithm 1 SAIS lexicographical order generation framework.
| Algorithm 1 SAIS () |
| Input: Assign the input character to S[i] |
| Output: Get the suffix array SA |
| 1: t = bool[], Scan the string Si to determine the type of each suffix. |
| 2: P = int[], Scan the array t for all LMS substrings. |
| 3: bucket = int[], Bucket sort all LMS substrings. |
| 4: S1 = int[], Scan ti to determine all LMS substrings and induced sort, then generate a new stringS1. |
| 5: Is every character in S1 the same? |
| If the same, repeat steps 1~5, then recursive calculation SA1 = SAIS(S1). |
| SA1 was used for induction sequencing to obtain SA. |
| calculating SA1 directly. |
| 6: End of the algorithm |
In the calculation of the suffix array of the SAIS algorithm, the size of the recursive suffix array is halved each time [22]. The time complexity of the optimized BsDiff algorithm for generating the lexicographical order is T(n) = T(n/2) + O(n) ≈ O(n), which is better than that of the BsDiff algorithm in terms of speed, which is O(nlogn). In addition, the larger the memory of the upgraded file, the faster the upgrade speed of the proposed method.
Taking a string of “GTCCCGATGTCATGTCAGGA$” as an example, the general linear time/space lexicographical derivation method [23] was compared with the SAIS algorithm to verify the optimization effect. A string is defined as an array index with subscripts {0 … n − 1} that defines the end of the string to end with the smallest dictionary character ‘$’ symbol. To store the suffix, Suf(S, i) is used to represent suffixes in S starting with S[i] and ending with the sentinel character ‘$’. SA represents the suffix array of the string S. All the suffix arrays in S are sorted in lexicographical order from smallest to largest. SA[i] represents position j of the suffix (S, j) of the ith name in the original string S. That is, for SA[i] = j, the suffix (S, j) ranks I in the SA. Three suffix types are defined in the SA array: S-type, L-type, and LMS-type [24].
- (1)
- S characters: S[i] < S[i + 1] or (S[i] < S[i + 1] and suffix (S, i + 1) are type S).
- (2)
- L characters: S[i] > S[i + 1] or (S[i] > S[i + 1] and suffix (S, i + 1) are L-shaped).
- (3)
- LMS characters: S[i] is S-type, and S[i − 1] is L-type.
Table 1 shows the determination of string types using “*” to represent LMS characters.

Table 1.
String types.
Theorem 1.
For two suffixes with the same initial letter, the lexicographical order of the S-type suffix is greater than that of the L-type suffix.
Proof.
Assume that the suffixes of S-type and L-type begin with the same character c. and , , , , and are strings. Assume that . If , should be compared with . (for strings and , we use to denote that is lexicographically less than ). If , should be compared with : . If , should be compared with ; if and , then is deduced. □
Corollary 1.
If SA is divided into buckets alphabetically, the lexicographical order of the S suffix is larger than that of the L suffix in the same bucket, and S1 has the same lexicographical order as S.
To achieve a linear time complexity and high execution efficiency, the input characters must first be preprocessed to shorten the length of the string to be processed. The existing linear sorting method for the suffix array replaces the entire array S-suffix S sort with the S-type suffix and compares it with all the suffixes in the bucket each time. The algorithm for deriving the lexicographical order in ordinary linear time/space can be divided into the following steps:
Step 1: Assign the input character to the S array and determine the character type. According to the aforementioned theorem, find all S-suffixes in the string, sort them from smallest to largest, and replace them in order in all substring positions (I). Record the order of the SA sorted by S1, where S1 = {0, 16, 11, 6, 2, 13, 8}, as shown in Figure 5. Create different buckets according to the suffix array first letter, including $’, A’, C’, G’, and T’ buckets, and place the new string S1 at the end of the corresponding bucket in sequence.
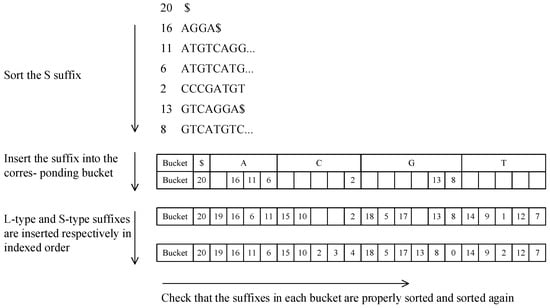
Figure 5.
Linear suffix array sort.
Step 2: Find the heads of each L bucket in the SA and scan the SA from beginning to end. For each item SA[i], if S[SA[i] − 1] is of the L-type, place SA[i] − 1 to S[SA[i] − 1 in the current head of the L bucket and move it one bit backward until the scan is complete. Scan the SA from beginning to end. For each item SA[I], if S[SA[i] − 1] is of type S, place SA[i] − 1 to S[SA[i] − 1 in the current tail of the S bucket and move it forward by one bit.
Step 3: After all S-type suffixes and L-type suffixes are inserted into the bucket, sort the L-type suffixes in the bucket from small to large again, sort the S-type suffixes in the bucket from small to large again, and change the position in the bucket to obtain the correctly sorted suffix array SA.
The common suffix array sort method has a long string length and occupies significant memory space. In addition, coarse sorting in Step 2 and resorting in Step 3 result in the wastage of the operation steps. The BsDiff algorithm combined with the SAIS () function IS was adopted to select the LMS-type substring as the domain of the reduction problem, which reduces the number of strings to be processed compared to ordinary S-type suffixes replacing the original array. LMS characteristics are defined as follows [25]:
- (1)
- LMS suffix: Suf(S, i) indicates the suffix in S starting with the LMS character and ending with the sentinel character ‘$’.
- (2)
- LMS substring: String S[i… j] starts and ends with LMS-type characters and has no other LMS-type characters between them.
According to this definition, the string S can be considered a combination of all LMS substrings. LMS string S[i…j] can be regarded as a partial prefix corresponding to the suffix (S, i). The lexicographic sort order is associated with S[i…j]. Thus, the following properties were obtained:
Character: The lexicographic ordering of the suffix array (S, I) should be the same as that of the LMS string S[i…j].
For the character ‘GTCCCGATGTCATGTCAGGA$’, the LMS substring is ‘CCCGA’, ‘ATG’, ‘GTCA’, ‘ATG’, ‘GTCA’, ‘AGGA$’, ‘$’. All LMS substrings are sorted by radix sort and placed into a new string S1 = {$, AGGA$, ATG, CCCGA, GTCA}, as shown in Figure 6. Based on the aforementioned properties of S1, if we treat the LMS substring as a basic string block and effectively sort all LMS substrings, we can use the sequential index of each LMS substring as its name and replace the S-type suffix with a new LMS string index. Therefore, the problem of sorting the suffix array of string S is transformed into the problem of sorting the shorter-byte-length string S1, resulting in a new array {3, 2, 4, 2, 1, 0}. Owing to the existence of repeated blocks in S1, SAIS () is recursively called according to Step 5 of the SAIS function. S1 = {3, 2, 4, 2, 4, 1, 0} generates a new suffix array, S1‘ = {6, 5, 3, 1, 0, 4, 2}. At this point, there are no repeated blocks, and the call ends. S1 is mapped to the corresponding suffix array SA, and the same result as in Step 3 is obtained.
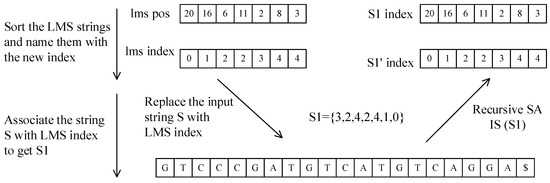
Figure 6.
Induced sorting shortens the problem domain.
The results demonstrate that the LMS substring can replace the sorting method of an ordinary linear suffix array and deduce the correct SA. This also shows that when S1 provides the lexicographic order of all suffixes of type S, the lexicographic order of all suffixes of type SA can be obtained. Because S1 is less than (|S|/2), the length of the string is reduced to at least half its original cost. Recursive and induced methods effectively reduce the length of characters to be processed during dictionary sorting.
4. Experimental Results
To verify that the proposed SAIS–BsDiff algorithm can improve the efficiency of differential compression and reduce time consumption during the OTA upgrade, an OTA hard-in-the-loop simulation test platform was established, as shown in Figure 7. The experimental platform equipment included a notebook computer, a wireless router, an industrial computer, and an STM32F407ZGT6 development board (STMicroelectronics, Geneva, Switzerland). The laptop serves as an OTA upgrade server. Wireless routers provide mobile network communication for industrial computers. As the upgraded object of industrial devices, the industrial computer can simulate the client and the automatic driving domain controller. It can receive wireless transmission protocol packets and convert them into UDS diagnosis packets through sockets. The STM32 development board serves as the minimum control unit of the object to be upgraded and is used to verify UDS diagnosis and Bootloader program jump functions during the upgrade.

Figure 7.
OTA hardware-in-the-loop simulation test platform.
The server was connected to the TBOX through a 4G/5G-U wireless connection, the TBOX was connected to the domain controller through an Ethernet connection, and the STM32 development board was connected to the domain controller through a CAN network connection. Table 2 lists the configuration parameters of the test equipment.
Table 2.
Test equipment configuration.
To objectively evaluate the OTA upgrade efficiency, we assumed that the difference in time before algorithm optimization was , and the difference in time after algorithm optimization was . The difference in the time improvement ratio is as follows:
According to Formula (1), the higher the improvement ratio, the higher the upgrade efficiency and the better the optimization performance of the difference algorithm.
Based on the experimental test bench introduced, the function between modules was realized by an integrated test. First, the upgrade image was selected and downloaded. During the download, the Wireshark running in the background of the domain controller checked whether the network was properly connected and monitored. The Wireshark page displayed that the server IP address and port number were set to 196.168.31.130, 49534, and the client IP address and port number were set to 172.217.160.110, 443. After the HTTP three-way handshake succeeded, the communication was established, and the server started data transmission. In the lower pane of the Wireshark, the packet transmission body was viewable. This enabled the server access required for OTA upgrades. Then, the improved SAIS–BsDiff algorithm was tested using an OTA hardware-in-the-loop simulation test platform. The comparison algorithm used in the experiment was the open-source algorithm BsDiff 4.3. The dependent library, Bzip2, was installed before use, and the function and performance of the SAIS–BsDiff algorithm were tested. The test file was a binary execution file generated for the Keil tool chain. The BsDiff and SAIS–BsDiff algorithms were used to differentiate the same set of upgraded files. The content of the difference files obtained by the algorithm before and after optimization was consistent; there was no file loss or change, and all upgraded packages could be restored to the new version files after the restoration algorithm. It was verified that the SAIS–BsDiff algorithm could realize the correct differential compression function. Figure 8 and Figure 9 show the results of the BsDiff and SaIS–BsDiff algorithms for differentiating and restoring the same group of data; the content and structure of the two restored groups of data are correct.

Figure 8.
BsDiff’s difference reduction results.

Figure 9.
SAIS–BsDiff’s difference reduction results.
Subsequently, the SAIS–BsDiff algorithm was validated using a test platform. Upgraded image packages with sizes ranging from 10 to 900 bytes were selected, and images with adjacent sizes were divided into nine groups to perform an OTA difference effect comparison experiment using the BsDiff and SAIS–BsDiff algorithms. The BsDiff and SAIS–BsDiff algorithms were used 50 times for each group of experiments and then averaged to obtain the difference in time between the two algorithms, as shown in Figure 10. The results show that both the BsDiff and SAIS–BsDiff algorithms can correctly complete the difference and reduction tasks. As the upgraded file size increases, the differential time increases. However, compared to the BsDiff algorithm, the proposed SAIS–BsDiff algorithm consumes less time. Taking a 900-byte file as an example, the BsDiff algorithm requires approximately 610 ms, whereas the SAIS–BsDiff algorithm requires less than 400 ms, saving 39% of the original consumption time.
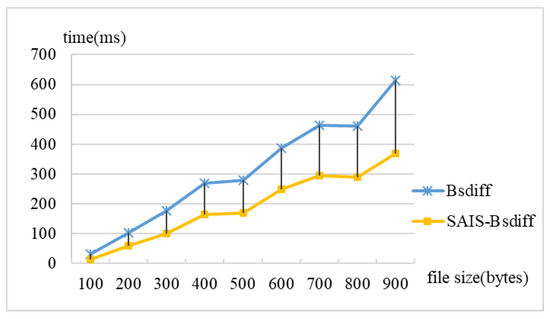
Figure 10.
Differential time contrast.
Table 3 shows the optimization effects of the BsDiff and SAIS–BsDiff algorithms. With an increase in the upgraded file size, the time difference before and after optimization also increased. Compared to the BsDiff algorithm, the difference in time of the proposed SAIS–BsDiff algorithm improved by more than 35.86%. Through the aforementioned test platform analysis, it was verified that the proposed SAIS–BsDiff algorithm can improve the efficiency of differential compression and reduce time consumption in the OTA upgrading process.
Table 3.
Optimization effect of SAIS–BsDiff algorithm.
5. Conclusions
With the acceleration of industrial Internet technology development, OTA technology is widely used. With the increasing complexity of industrial software, upgraded files must be reduced using a differential compression algorithm to reduce the transmission of wireless communication networks. However, existing algorithms have the characteristics of insufficient differential efficiency, considerable time consumption, and easy interruption, which increase the risk of an OTA upgrade. This study proposes a lightweight and fast differential SAIS–BsDiff algorithm. By solving the efficiency problem of suffix sorting in the BsDiff algorithm, the time consumption of the entire difference process is reduced, and the efficiency of the OTA upgrade is improved. Compared to the original BsDiff algorithm, the SAIS–BsDiff algorithm can reduce the time consumption by more than 35% through a hardware-in-the-loop simulation experiment. In the future, differential compression algorithms can be used for data cloud storage and intelligent transportation. Based on this study, we propose the use of a greedy algorithm to quickly determine the approximate matching parts of old and new files. The advantage of this method is that it avoids the memory consumption of the computing equipment caused by suffix array sorting.
Author Contributions
Conceptualization, X.Z., Y.W., Y.S., J.H. and L.K.; Methodology, X.Z. and Y.W.; Software, Y.W.; Formal analysis, H.Z.; Investigation, X.Z.; Resources, Y.S. and L.K.; Writing—original draft, X.Z. and Y.W.; Writing—review & editing, Y.S., H.Z., J.H. and L.K. All authors have read and agreed to the published version of the manuscript.
Funding
This study was supported in part by the Key Research and Development Plan of the Ministry of Science and Technology under Grant 2020YFB1710900. This study was also partially sponsored by the NSFC Program (No.52102439) and the China Postdoctoral Science Foundation Program (No.2021M701886).
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hughes, J. Comparison of Lossy and Lossless Compression Algorithms for Time Series Data in the Internet of Vehicles. Master’s Thesis, Linköping University, Linköping, Sweden, 2023. [Google Scholar]
- Halder, S.; Ghosal, A.; Conti, M. Secure over-the-air software updates in connected vehicles: A survey. Comput. Netw. 2020, 178, 107343. [Google Scholar] [CrossRef]
- Borse, M.; Shendkar, P.; Undre, Y.; Mahadik, A.; Patil, R. Study of Hybrid Cryptographic Techniques for Vehicle FOTA System. In Mobile Computing and Sustainable Informatics, Proceedings of the ICMCSI 2023, Kathmandu, Nepal, 11–12 January 2023; Springer Nature: Singapore, 2023; pp. 417–430. [Google Scholar]
- Meng, T.; Li, J.; Huang, J.; Yang, D.; Zhong, Z. Research on Software Defined Automotive Technology System. Automot. Eng. 2021, 43, 459–468. [Google Scholar]
- Varadharajan, V.S.; St Onge, D.; Guß, C.; Beltrame, G. Over-the-air updates for robotic swarms. IEEE Softw. 2018, 35, 44–50. [Google Scholar] [CrossRef]
- Beshley, M.; Kochan, V.; Beshley, H.; Medvetskyi, M.; Kahalo, I.; Shkoropad, Y. QoS-Coordinated Adaptive Spectrum Management Method for Coexistence 5G-U and Wi-Fi Networks with Short-Term Channel Failures. In Proceedings of the 2023 17th International Conference on the Experience of Designing and Application of CAD Systems (CADSM), Jarosław, Poland, 22–25 February 2023; pp. 22–26. [Google Scholar]
- Lu, X.; Sopin, E.; Petrov, V.; Galinina, O.; Moltchanov, D.; Ageev, K.; Andreev, S.; Koucheryavy, Y.; Samouylov, K.; Dohler, M. Integrated use of licensed-and unlicensed-band mmWave radio technology in 5G and beyond. IEEE Access 2019, 7, 24376–24391. [Google Scholar] [CrossRef]
- BenSaleh, M.S.; Saida, R.; Kacem, Y.H.; Abid, M. Wireless sensor network design methodologies: A survey. J. Sens. 2020, 2020, 9592836. [Google Scholar] [CrossRef]
- Stolikj, M.; Cuijpers PJ, L.; Lukkien, J.J. Energy-aware reprogramming of sensor networks using incremental update and compression. Procedia Comput. Sci. 2012, 10, 179–187. [Google Scholar] [CrossRef]
- Shapira, D.; Storer, J.A. In place differential file compression. Comput. J. 2005, 48, 677–691. [Google Scholar] [CrossRef]
- Panta, R.K.; Bagchi, S.; Midkiff, S.P. Zephyr: Efficient increment reprogramming of Sensor nodes using function call indirections and difference computation. In Proceedings of the USENIX Annual Technical Conference, San Diego, CA, USA, 14–19 June 2009; p. 65. [Google Scholar]
- Stolikj, M.; Cuijper, S.P.J.L.; Lukkien, J.J. Patching a patch-Software updates using horizontal patching. IEEE Trans. Consum. Electron. 2013, 59, 435–441. [Google Scholar] [CrossRef]
- Kiyohara, R.; Mii, S.; Matsumoto, M.; Numao, M.; Kurihara, S. A new method of fast compression of program code for OTA updates in consumer devices. IEEE Trans. Consum. Electron. 2009, 55, 812–817. [Google Scholar] [CrossRef]
- Patrascu, A.; Bica, I.; Patriciu, V. Enhanced diff for high performance forensic enabled cloud infrastructures. In Proceedings of the 13th International Conference on Informatics in Economy, Education, Research and Business Technologies, Bucharest, Romania, 15–18 May 2014. [Google Scholar]
- Cho, Y.C.; Jeon, J.W. In-place reconstructible delta compression using alleviated greedy matching algorithm. In Proceedings of the 2008 6th IEEE International Conference on Industrial Informatics, Daejeon, Republic of Korea, 13–16 July 2008; pp. 1596–1601. [Google Scholar]
- Percival, C. Naıve Differences of Executable Code. 2003. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=0bd00a5a8e458b3048d00bb70df345b9e78b194f (accessed on 27 August 2023).
- Stolikj, M.; Cuijpers, P.J.L.; Lukkien, J.J. Efficient reprogramming of sensor networks using incremental updates and data compression. Comput. Sci. Rep. 2012, 1210, 735365. [Google Scholar]
- Moshkov, M. Decision trees for binary subword-closed languages. Entropy 2023, 25, 349. [Google Scholar] [CrossRef]
- Kempa, D.; Kociumaka, T. Collapsing the hierarchy of compressed data structures: Suffix arrays in optimal compressed space. arXiv 2023, arXiv:2308.03635. [Google Scholar]
- Nakanishi, T.; Shih, H.H.; Hisazumi, K.; Fukuda, A. A Software update Scheme by airwaves for automotive equipment. In Proceedings of the 2013 International Conference on Informatics, Electronics and Vision (ICIEV), Dhaka, Bangladesh, 17–18 May 2013; pp. 1–6. [Google Scholar]
- Nong, G.; Zhang, S.; Chan, W.H. Linear Suffix array construction by almost pure induced-Sorting. In Proceedings of the 2009 Data Compression Conference, Snowbird, UT, USA, 16–18 March 2009; pp. 193–202. [Google Scholar]
- Ko, P.; Aluru, S. Space efficient linear time construction of suffix arrays. In Proceedings of the Annual Symposium on Combinatorial Pattern Matching, Michoacán, Mexico, 25–27 June 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 200–210. [Google Scholar]
- Stolikj, M.; Cuijpers, P.J.L.; Lukkien, J.J. Efficient reprogramming of wireless sensor networks using incremental updates. In Proceedings of the 2013 IEEE International Conference on Pervasive Computing and Communications Workshops (PERCOM Workshops), San Diego, CA, USA, 18–22 March 2013; pp. 584–589. [Google Scholar]
- Puglisi, S.J.; Smyth, W.F.; Turpin, A.H. A taxonomy of suffix array construction algorithms. ACM Comput. Surv. (CSUR) 2007, 39, 4-es. [Google Scholar] [CrossRef]
- Timoshevskaya, N.; Feng, W. SAIS-OPT: On the characterization and optimization of the SA-IS algorithm for suffix array construction. In Proceedings of the 2014 IEEE 4th International Conference on Computational Advances in Bio and Medical Sciences (ICCABS), Miami, FL, USA, 2–4 June 2014; pp. 1–6. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).