
A Pedestrian Detection Network Based on an Attention Mechanism and Pose Information


Abstract
1. Introduction
- (1)
- We developed a pedestrian detection method that integrates an attention mechanism with visual and pose information and includes pedestrian region proposal and pedestrian recognition networks, effectively addressing occlusion and false detection issues.
- (2)
- We found that gesture information and an attention mechanism, as supplements to visual description, are key in pedestrian detection.
- (3)
2. The Related Literature
- A.
- Object Detection
- B.
- Pedestrian Detection
- C.
- Occlusion and False Positive Error
- (1)
- (2)
- The attention mechanism enables the model to focus on the most crucial regions in an image to improve the representation of target pedestrian features and its detection performance in occlusion scenarios. The attention mechanism can also reduce irrelevant information interference and increase the robustness and detection accuracy of pedestrian targets.
3. Methodology
- A.
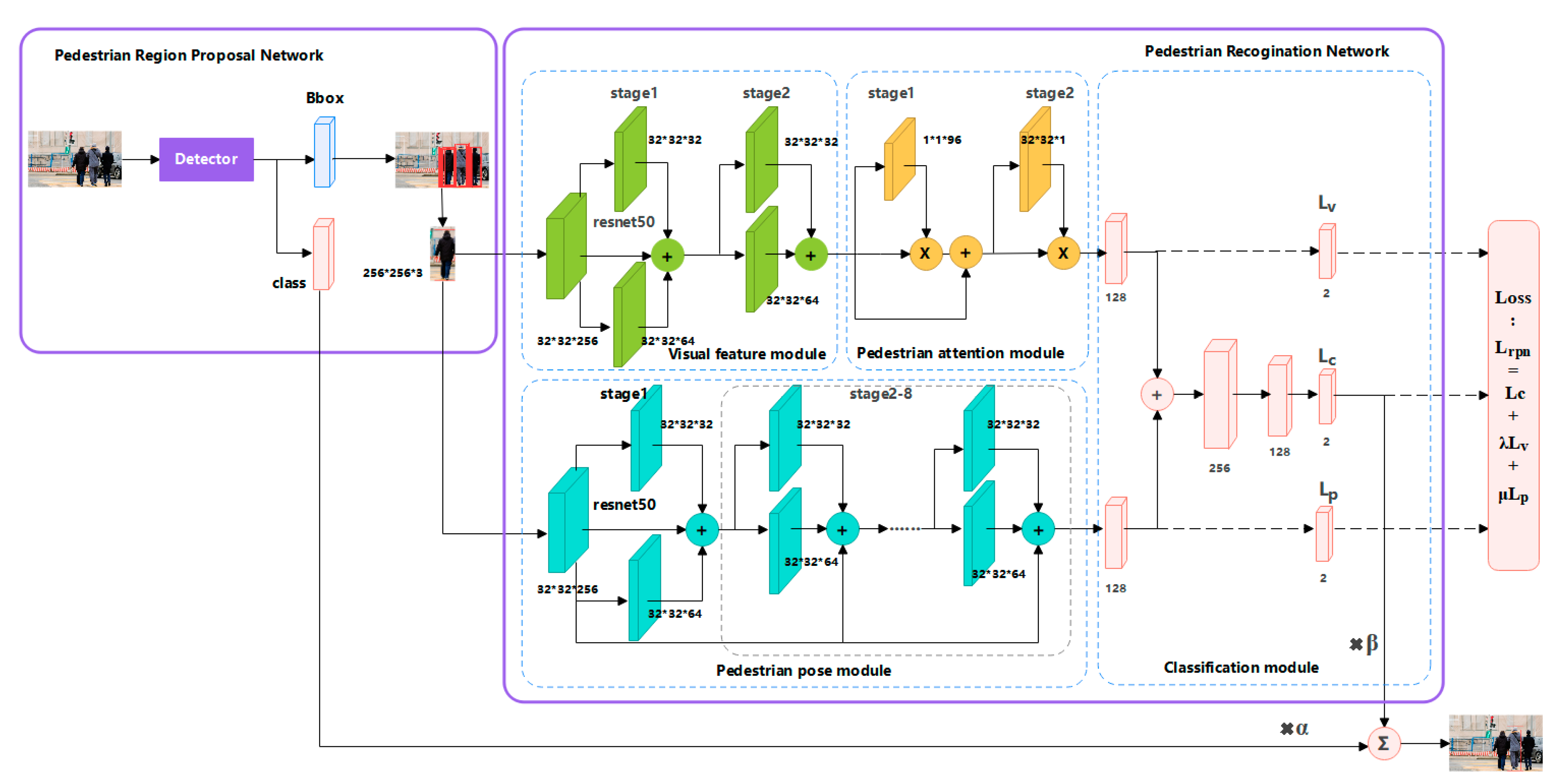
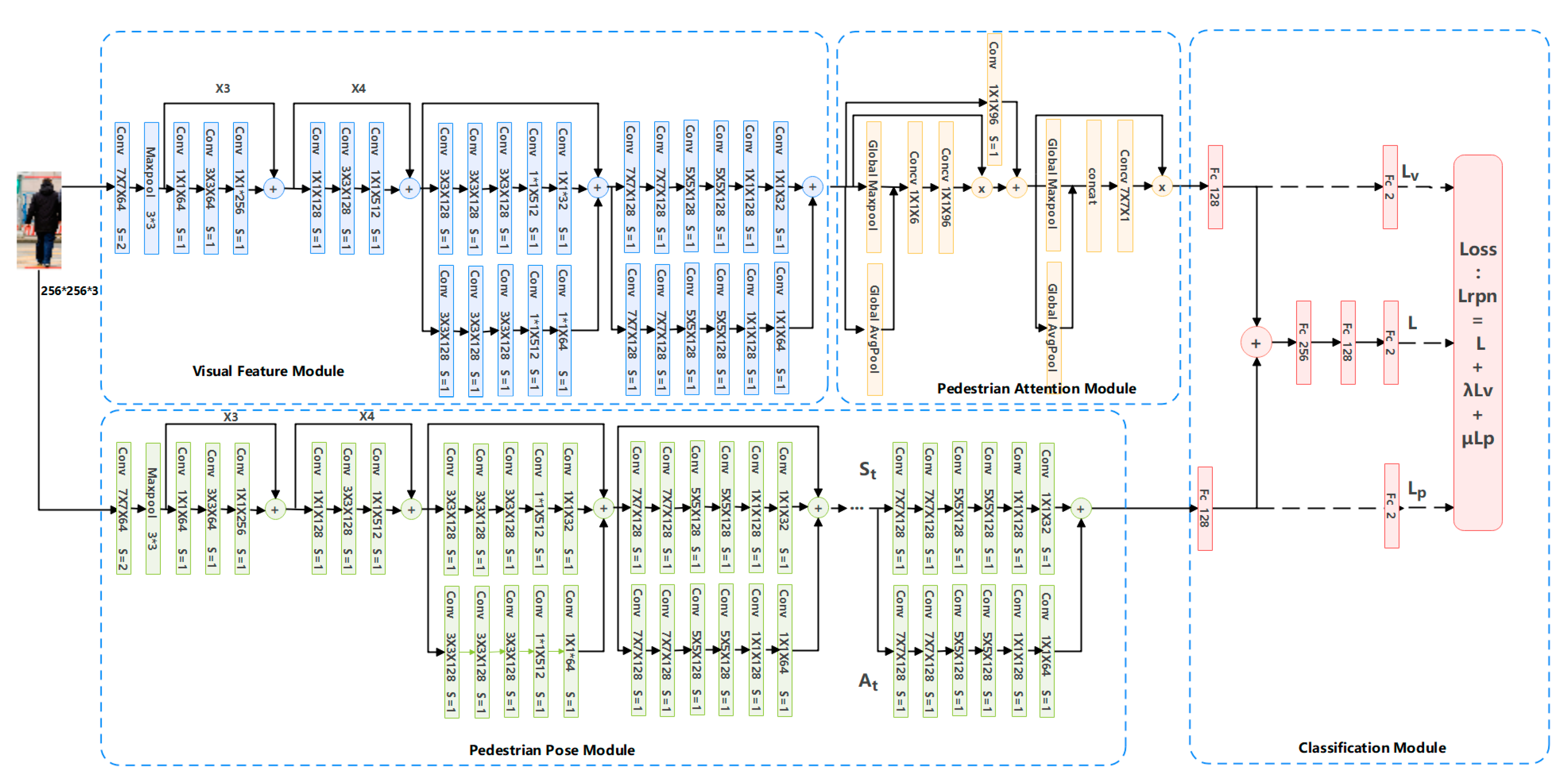
- Pedestrian Recognition Network
| Algorithm 1 Pedestrian Detection Based on Pose Information and Attention Mechanism |
| Input: Image F, first threshold parameter , second threshold parameter Output: Pedestrian detection results {Pi (i = 0,1,2…)} 1. Initialize pedestrian region proposal network (RPN) using existing detectors (e.g., ALFNet, FCOS) 2. Generate candidate bounding boxes using RPN Brpn = RPN(F) 3. Initialize pedestrian recognition network 4. For each candidate bounding box b in Brpn, 4.1. Extract visual feature descriptions 4.1.1. Resize candidate region to 256 × 256 4.1.2. Use the first 22 layers of ResNet50 and convolutional blocks to obtain 4.2. Extract pose feature descriptions 4.2.1. Resize candidate region to 256 × 256 4.2.2. Use improved OpenPose with first 22 layers of ResNet50 to extract feature map F 4.2.3. Iteratively predict confidence map M and affinity field A to obtain pose information 4.2.4. Map pose information to 128-dimensional feature description using a fully connected layer 4.3. Extract attention information using pedestrian attention module 4.4. Fuse visual, pose, and attention feature descriptions f = concatenate (, , ) f = reduce dimension(f) 4.5. Refine confidence score and remove challenging negative samples using classification module scorep = classifier(f) 5. Optimize pedestrian region proposal network using multitask loss: |
| 6. Calculate final confidence score for each candidate region, set and = 0.8: score = ∗ scorer + ∗ scorep 7. Perform non-maximum suppression (NMS) to eliminate duplicate and redundant detections 8. Return final pedestrian detection results {Pi (i = 0,1,2…)} |
4. Experiments
- A.
- Datasets
- B.
- Evaluation Metrics
- C.
- Implementation Details
- D.
- Baseline
- (1)
- ALFNet + visual: In this experiment, we added a visual feature module to the ALFNet model.
- (2)
- ALFNet + visual + pose: This experiment involved adding both a visual module and pedestrian pose modules to the ALFNet model.
- (3)
- ALFNet + visual + pose + attention: For this experiment, we incorporated the visual feature module, pedestrian pose modules, and attention mechanism into the ALFNet model.
- E.
- Ablation study
- F.
- Comparison with state-of-the-art methods
- G.
- Parameter analysis
- H.
- Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, S.; Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. Towards reaching human performance in pedestrian detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 973–986. [Google Scholar] [CrossRef] [PubMed]
- Hosang, J.; Omran, M.; Benenson, R.; Schiele, B. Taking a deeper look at pedestrians. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4073–4082. [Google Scholar]
- Tian, Y.; Luo, P.; Wang, X.; Tang, X. Pedestrian detection aided by deep learning semantic tasks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5079–5087. [Google Scholar]
- Zhang, S.; Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. How far are we from solving pedestrian detection? In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1259–1267. [Google Scholar]
- Zhou, C.; Yuan, J. Multi-label learning of part detectors for heavily occluded pedestrian detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3506–3515. [Google Scholar]
- Ouyang, W.; Zeng, X.; Wang, X. Partial occlusion handling in pedestrian detection with a deep model. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 2123–2137. [Google Scholar] [CrossRef]
- Hu, Q.; Wang, P.; Shen, C.; van den Hengel, A.; Porikli, F. Pushing the limits of deep CNNs for pedestrian detection. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 1358–1368. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Tang, P.; Wang, X.; Bai, S.; Shen, W.; Bai, X.; Liu, W.; Yuille, A. PCL: Proposal cluster learning for weakly supervised object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 176–191. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He KGirshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Lin, L.; Liang, X.; He, K. Is faster R-CNN doing well for pedestrian detection? In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 443–457. [Google Scholar]
- Zhang, S.; Benenson, R.; Schiele, B. Citypersons: A diverse dataset for pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4457–4465. [Google Scholar]
- Song, T.; Sun, L.; Xie, D.; Sun, H.; Pu, S. Small-scale pedestrian detection based on topological line localization and temporal feature aggregation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 536–551. [Google Scholar]
- Tian, Y.; Luo, P.; Wang, X.; Tang, X. Deep learning strong parts for pedestrian detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1904–1912. [Google Scholar]
- Zhou, C.; Yuan, J. Bi-box regression for pedestrian detection and occlusion estimation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 135–151. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime multi-person 2D pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1302–1310. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June—1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhad, A.I. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Li, Z.; Chen, Y.; Gang, Y. R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Shi, S.; Guo, C.; Li, J. PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 27 October–2 November 2020; pp. 10526–10535. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar]
- Li, J.; Liang, X.; Shen, S.; Xu, T.; Feng, J.; Yan, S. Scale-aware fast R-CNN for pedestrian detection. IEEE Trans. Multimed. 2018, 20, 985–996. [Google Scholar] [CrossRef]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 354–370. [Google Scholar]
- Liu, W.; Liao, S.; Hu, W.; Liang, X.; Chen, X. Learning efficient single-stage pedestrian detectors by symptotic localization fitting. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 618–634. [Google Scholar]
- Liu, W.; Liao, S.; Ren, W.; Hu, W.; Yu, Y. High-level semantic feature detection: A new perspective for pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5187–5196. [Google Scholar]
- Hasan, I.; Liao, S.; Li, J.; Akram, S.U.; Shao, L. Generalizable pedestrian detection: The elephant in the room. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Khan, A.H.; Munir, M.; van Elst, L.; Dengel, A. F2dnet: Fast focal detection network for pedestrian detection. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022. [Google Scholar]
- Hagn, K.; Grau, O. Increasing pedestrian detection performance through weighting of detection impairing factors. In Proceedings of the 6th ACM Computer Science in Cars Symposium, Ingolstadt, Germany, 8 December 2022. [Google Scholar]
- Khan, A.H.; Nawaz, M.S.; Dengel, A. Localized semantic feature mixers for efficient pedestrian detection in autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Luo, Z.; Fang, Z.; Zheng, S.; Wang, Y.; Fu, Y. NMS-loss: Learning with non-maximum suppression for crowded pedestrian detection. In Proceedings of the 2021 International Conference on Multimedia Retrieval, Taipei, Taiwan, 16–19 November 2021. [Google Scholar]
- Liu, M.; Jiang, J.; Zhu, C.; Yin, X.C. Vlpd: Context-aware pedestrian detection via vision-language semantic self-supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Lu, R.; Ma, H.; Wang, Y. Semantic head enhanced pedestrian detection in a crowd. Neurocomputing 2020, 400, 343–351. [Google Scholar] [CrossRef]
- Enzweiler, M.; Eigenstetter, A.; Schiele, B.; Gavrila, D.M. Multi-cue Pedestrian Classification with Partial Occlusion Handling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 990–997. [Google Scholar]
- Noh, J.; Lee, S.; Kim, B.; Kim, G. Improving occlusion and hard negative handling for single-stage pedestrian detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 966–974. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Occlusion-aware R-CNN: Detecting pedestrians in a crowd. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 637–653. [Google Scholar]
- Wang, X.; Xiao, T.; Jiang, Y.; Shao, S.; Sun, J.; Shen, C. Repulsion loss: Detecting pedestrians in crowd. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7774–7783. [Google Scholar]
- Larsson, V.; Kukelova, Z.; Zheng, Y. Camera pose estimation with unknown principal point. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2984–2992. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7103–7112. [Google Scholar]
- Guler, R.A.; Neverova, N.; Kokkinos, I. DensePose: Dense human pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7297–7306. [Google Scholar]
- Dong, L.; Chen, X.; Wang, R.; Zhang, Q.; Izquierdo, E. ADORE: An adaptive holons representation framework for human pose estimation. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 2803–2813. [Google Scholar] [CrossRef]
- Yang, B.; Ma, A.J.; Yuen, P.C. Body parts synthesis for cross-quality pose estimation. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 461–474. [Google Scholar] [CrossRef]
- Liu, S.; Li, Y.; Hua, G. Human pose estimation in video via structured space learning and halfway temporal evaluation. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 2029–2038. [Google Scholar] [CrossRef]
- Liu, Z.; Feng, R.; Chen, H.; Wu, S.; Gao, Y.; Gao, Y.; Wang, X. Temporal Feature Alignment and Mutual Information Maximization for Video-Based Human Pose Estimation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 10996–11006. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9627–9636. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), 8–14 September 2018; pp. 3–19. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 7–12 June 2015; pp. 770–778. [Google Scholar]
- Jiao, Y.; Yao, H.; Xu, C. PEN: Pose-Embedding Network for Pedestrian Detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 1150–1162. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Brazil, G.; Liu, X. Pedestrian detection with autoregressive network phases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7231–7240. [Google Scholar]
- Du, X.; El-Khamy, M.; Lee, J.; Davis, L. Fused DNN: A deep neural network fusion approach to fast and robust pedestrian detection. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Santa Rosa, CA, USA, 24–31 March 2017; pp. 953–961. [Google Scholar]
- Brazil, G.; Yin, X.; Liu, X. Illuminating pedestrians via simultaneous detection and segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4950–4959. [Google Scholar]
- Fu, C.-Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional single shot detector [EB/OL]. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Zhou, P.; Zhou, C.; Peng, P.; Du, J.; Sun, X.; Guo, X.; Huang, F. NOH-NMS: Improving Pedestrian Detection by Nearby Objects Hallucination. In Proceedings of the ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1967–1975. [Google Scholar]
- Xu, Z.; Li, B.; Yuan, Y.; Dang, A. Beta R-CNN: Looking into Pedestrian Detection from Another Perspective. arXiv 2022, arXiv:2210.12758. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | MR−2 (%) |
|---|---|
| ALFNet | 5.13 |
| ALFNet + visual | 4.99 |
| ALFNet + visual + pose | 4.79 |
| ALFNet + visual + pose + attention | 4.71 |
| FCOS(ResNet50) | 4.68 |
| FCOS(ResNet50) +visual | 4.53 |
| FCOS(ResNet50) + visual + pose | 4.39 |
| FCOS(ResNet50) + visual + pose + attention | 4.26 |
| FCOS(VoVNet39) | 4.57 |
| FCOS(VoVNet39) + visual | 4.41 |
| FCOS(VoVNet39) + visual + pose | 4.27 |
| FCOS(VoVNet39) + visual + pose + attention | 4.13 |
| Model | Proposals | TP | FP | AP |
|---|---|---|---|---|
| ALFNet | 9459 | 2158 | 7301 | 0.23 |
| ALFNet + visual | 8141 | 2113 | 6028 | 0.26 |
| ALFNet + visual + pose | 6233 | 2035 | 4198 | 0.32 |
| ALFNet + visual + pose + attention | 6019 | 2027 | 3992 | 0.34 |
| FCOS(ResNet50) | 17,823 | 3858 | 13,969 | 0.22 |
| FCOS(ResNet50) + visual | 12,838 | 3703 | 9080 | 0.29 |
| FCOS(ResNet50) + visual + pose | 8965 | 3526 | 5239 | 0.39 |
| FCOS(ResNet50) + visual + pose + attention | 7721 | 3329 | 4392 | 0.43 |
| Model | Reasonable | Bare | Partial | Heavy |
|---|---|---|---|---|
| ALFNet | 16.01 | 9.96 | 13.85 | 52.47 |
| ALFNet + visual | 15.68 | 9.53 | 13.25 | 52.40 |
| ALFNet + visual + pose | 15.29 | 9.25 | 12.97 | 50.70 |
| ALFNet + visual + pose + attention | 14.93 | 9.02 | 12.76 | 49.62 |
| FCOS(ResNet50) | 11.97 | 7.87 | 11.52 | 49.17 |
| FCOS(ResNet50) + visual | 11.69 | 7.53 | 11.25 | 48.53 |
| FCOS(ResNet50) + visual + pose | 11.32 | 7.25 | 10.71 | 47.70 |
| FCOS(ResNet50) + visual + pose + attention | 10.73 | 7.02 | 10.36 | 47.12 |
| FCOS(VoVNet39) | 11.09 | 7.16 | 10.51 | 48.77 |
| FCOS(VoVNet39) + visual | 10.78 | 7.03 | 10.12 | 47.39 |
| FCOS(VoVNet39) + visual + pose | 10.52 | 6.95 | 9.57 | 46.28 |
| FCOS(VoVNet39) + visual + pose + attention | 10.11 | 6.56 | 9.23 | 45.40 |
| Model | Proposals | TP | FP | AP |
|---|---|---|---|---|
| ALFNet | 17,401 | 2943 | 14,458 | 0.17 |
| ALFNet + visual | 7377 | 2587 | 4790 | 0.35 |
| ALFNet + visual + pose | 7208 | 2642 | 4566 | 0.37 |
| ALFNet + visual + pose + attention | 6502 | 2637 | 3865 | 0.41 |
| FCOS(ResNet50) | 23,029 | 5309 | 17,720 | 0.23 |
| FCOS(ResNet50) + visual | 18,013 | 5292 | 12,721 | 0.29 |
| FCOS(ResNet50) + visual + pose | 13,396 | 5011 | 8185 | 0.37 |
| FCOS(ResNet50) + visual + pose + attention | 8677 | 4783 | 3894 | 0.55 |
| Method | MR−2(%) |
|---|---|
| MS-CNN [28] | 8.08 |
| RPN + BF [11] | 7.28 |
| F-DNN [55] | 6.89 |
| SDS-RCNN [56] | 6.44 |
| ALFNet [29] | 6.10 |
| RepLoss [41] | 5.00 |
| CSP [30] | 4.59 |
| AR-Ped [54] | 4.36 |
| Ours (PEAN) | 4.13 |
| Method | Reasonable | Bare | Partial | Heavy |
|---|---|---|---|---|
| YOLOv2 [19] | 23.36 | 14.23 | 22.65 | 52.50 |
| SSD [22] | 22.54 | 16.91 | 21.95 | 50.66 |
| DSSD [57] | 19.70 | 15.75 | 18.90 | 51.88 |
| TLL [13] | 15.50 | 10.00 | 17.20 | 53.60 |
| Faster R-CNN [10] | 15.40 | 9.30 | 18.90 | 55.00 |
| RepLoss [41] | 13.20 | 7.60 | 16.80 | 56.90 |
| OR-CNN [40] | 12.80 | 6.70 | 15.30 | 55.70 |
| ALFNet [29] | 12.00 | 8.40 | 11.40 | 51.90 |
| CSP [30] | 11.00 | 7.30 | 10.40 | 49.30 |
| NOH-NMS [58] | 10.80 | 6.60 | 11.20 | 53.00 |
| Beta R-CNN [59] | 10.60 | 6.40 | 10.30 | 47.10 |
| Ours (PEAN) | 10.11 | 6.56 | 9.23 | 45.40 |
| Method | α and β | MR−2 (%) |
|---|---|---|
| ALFNet + visual + pose + attention | α = 1.0, β = 0.0 | 15.52 |
| α = 0.9, β = 0.1 | 15.11 | |
| α = 0.8, β = 0.2 | 14.93 | |
| α = 0.7, β = 0.3 | 15.71 | |
| α = 0.6, β = 0.4 | 15.93 | |
| FCOS(ResNet50) + visual + pose + attention | α = 1.0, β = 0.0 | 11.33 |
| α = 0.9, β = 0.1 | 11.02 | |
| α = 0.8, β = 0.2 | 10.73 | |
| α = 0.7, β = 0.3 | 11.41 | |
| α = 0.6, β = 0.4 | 11.57 | |
| FCOS(VoVNet39) + visual + pose + attention | α = 1.0, β = 0.0 | 10.65 |
| α = 0.9, β = 0.1 | 10.34 | |
| α = 0.8, β = 0.2 | 10.11 | |
| α = 0.7, β = 0.3 | 10.72 | |
| α = 0.6, β = 0.4 | 10.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Z.; Huang, S.; Li, M. A Pedestrian Detection Network Based on an Attention Mechanism and Pose Information. Appl. Sci. 2024, 14, 8214. https://doi.org/10.3390/app14188214
Jiang Z, Huang S, Li M. A Pedestrian Detection Network Based on an Attention Mechanism and Pose Information. Applied Sciences. 2024; 14(18):8214. https://doi.org/10.3390/app14188214
Chicago/Turabian StyleJiang, Zhaoyin, Shucheng Huang, and Mingxing Li. 2024. "A Pedestrian Detection Network Based on an Attention Mechanism and Pose Information" Applied Sciences 14, no. 18: 8214. https://doi.org/10.3390/app14188214
APA StyleJiang, Z., Huang, S., & Li, M. (2024). A Pedestrian Detection Network Based on an Attention Mechanism and Pose Information. Applied Sciences, 14(18), 8214. https://doi.org/10.3390/app14188214