Abstract
When people tell lies, they often exhibit tension and emotional fluctuations, reflecting a complex psychological state. However, the scarcity of labeled data in datasets and the complexity of deception information pose significant challenges in extracting effective lie features, which severely restrict the accuracy of lie detection systems. To address this, this paper proposes a semi-supervised lie detection algorithm based on integrating multiple speech emotional features. Firstly, Long Short-Term Memory (LSTM) and Auto Encoder (AE) network process log Mel spectrogram features and acoustic statistical features, respectively, to capture the contextual links between similar features. Secondly, the joint attention model is used to learn the complementary relationship among different features to obtain feature representations with richer details. Lastly, the model combines the unsupervised loss Local Maximum Mean Discrepancy (LMMD) and supervised loss Jefferys multi-loss optimization to enhance the classification performance. Experimental results show that the algorithm proposed in this paper achieves better performance.
1. Introduction
The rapid development of the Internet and social media has led to an information overload problem, including the spread of lies and misinformation. These phenomena can trigger significant negative consequences such as social unrest, political interference, and economic losses. Therefore, the development of lie detection technology is of great importance for building a more honest and secure social environment. Relevant research has already found wide application in critical fields such as law, the military, and forensics [1]. The psychological state of lying is a gradual and repetitive dynamic process. When people lie, they tend to become nervous, causing subtle changes in the vocal tract structure, with the fundamental frequency of the voice being higher than when telling the truth [2,3]. In the field of speech lie detection research, many acoustic features originally designed for speech emotion recognition have been confirmed to be equally crucial in identifying lies. These features can capture the tension, anxiety, or guilt that liars experience due to emotional fluctuations, providing key clues for lie detection by analyzing the pitch, rhythm, and intensity of speech. However, relying solely on these emotion-based acoustic features has limitations in revealing the complex psychological and physiological states of liars. To gain a deeper insight into deceptive behavior, it is essential to explore a broader set of features closely related to the act of lying, thereby enhancing the accuracy and depth of lie detection. There are some acoustic features in speech associated with lying [4]. These acoustic parameters change with varying stress levels, such as formants, Bark energy features, and Mel-frequency cepstral coefficients (MFCCs) [5,6]. Compared to the truth, lies exhibit fewer details, repetitive phrases, more content, shorter expression lengths, and inconsistencies in speech. Spectrum-based features can reflect the relationship between vocal tract shape and speech behavior [7]. Bareeda et al. [8] achieved an accuracy of up to 81% in lie detection using Mel-frequency cepstral features in “Real life trial data” dataset. Hanen et al. [9] extracted Mel-frequency cepstral features and pitch frequency, achieving good performance in lie detection. With the rise of deep learning, researchers have also started applying it to lie detection. Zhou et al. [10] proposed a deep belief network based on K-means and singular value decomposition (K-SVD) for extracting deep features, showing that deep features can better represent lies compared to traditional acoustic features. Sanaullah et al. [11] used Bark spectrum energy features and neural network technology to detect subtle differences between lies and the truth.
Although the aforementioned scholars have made significant achievements in the field of lie detection, data-driven deep neural networks heavily rely on large-scale labeled high-quality speech data. The lack of labeled data has become a critical issue constraining the development of the speech lie detection field. Semi-supervised learning algorithms provide a promising approach for speech lie detection tasks. Tarvainen et al. [12] proposed a mean-teacher model method, which optimizes semi-supervised learning by averaging model weights, simplifying the learning process of large datasets and improving test accuracy. Sun et al. [13] respectively trained the bidirectional long short-term memory networks (BILSTM) and support vector machine (SVM) model, and adopted the decision-level score fusion scheme to further integrate the classification results of each model. Fang et al. [14] proposed a multi-feature fusion speech lie detection algorithm based on attention mechanisms, constructing a hybrid model training network composed of a semi-supervised Denoising Auto Encoder (DAE) and a fully supervised Long Short-Term Memory(LSTM) network, effectively improving the accuracy of semi-supervised speech lie detection. Despite some achievements in semi-supervised research, the exploration of multi-feature lie detection algorithms under a semi-supervised framework has been neglected. A single feature cannot effectively represent lie information, so some scholars have considered combining multiple features for lie detection. Researchers at Columbia University considered combining lexical, prosodic, and acoustic features for lie detection research [15]. He et al. [16] proposed a Transformer-based deep hashing multi-scale feature fusion (TDH) algorithm. This algorithm utilizes hierarchical Transformers to capture both global and local features of images to obtain richer information. Praveen et al. [17] considered the complementarity between audio and video modalities and proposed an LSTM-based joint cross-attention model to capture intra-class and inter-class temporal dependencies. This paper aims to combine feature fusion methods with semi-supervised learning techniques to address the challenges in speech lie detection research, prevent dimensional disaster caused by multi-feature fusion when labeled data is insufficient, and fully utilize the potential feature information in unlabeled data to obtain robust feature representations in a semi-supervised learning environment.
Based on this, this paper proposes a semi-supervised lie detection algorithm based on integrating multiple speech emotional features. Firstly, LSTM network and self-coding network AE are used for feature extraction, followed by the introduction of joint attention method, which utilizes the correlation between different features to assist the feature fusion task and improve the accuracy of speech lie detection. Subsequently, Jefferys [18] loss is introduced to improve the supervised loss, which maximizes the target value of the output distribution and reduces the overfitting; Local Maximum Mean Discrepancy (LMMD) [19] is introduced to improve the unsupervised loss, which enables the model to learn richer feature information from unlabeled data. Experimental results demonstrate the effectiveness of the proposed algorithm.
2. Method
In this paper, we propose a semi-supervised lie detection algorithm based on integrating multiple speech emotional features, and the overall framework of the model is shown in Figure 1. First, the log Mel spectrogram features and acoustic statistical features are processed using LSTM network and self-coding network Auto Encoder (AE), respectively, to capture the contextual links between similar features, respectively. Second, the complementary relationship between different features is learned using the joint attention model to obtain feature representations with richer details. Subsequently, the Local Maximum Mean Difference (LMMD) is added to the unsupervised loss part to fully explore the unlabeled data’s potential feature structure information. Finally, the model is combined with supervised loss Jefferys for multi-loss optimization to improve the model’s classification performance.
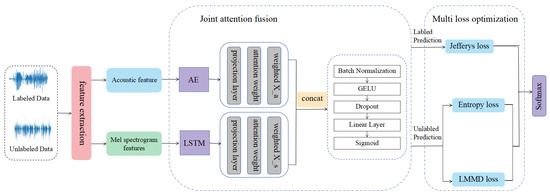
Figure 1.
A semi-supervised lie detection algorithm based on integrating multiple speech emotional features.
2.1. Feature Processing
As described in [4,5,13,14], acoustic statistical features can effectively represent false information in speech, while deep learning algorithms can extract time-frequency domain features from log-Mel spectrogram [20]. So 312-dimensional acoustic statistical features based on artificial a priori knowledge and log-Mel spectrogram features commonly used in the field of speech lie detection are used, aiming at mining the correlation information within similar features and among different features, and exploring the effect of fusion of static statistical features and dynamic time-frequency features in the time domain. In this paper, acoustic statistical features contains Pitches, spectral_centroid, spectral_flatness, Mel Frequency Ceptral Coefficients (MFCC), chroma_stft, melspectrogram, spectral_contrast, zero_crossing_rate, Magnitudes, Root-mean-square energy (Rmse).
Let and , where and denote the dimensions of acoustic statistical features and Mel spectrogram features, respectively, and is the single feature representation of all samples, and , o is the feature order number, O denoting the total number of feature samples.
Semi-supervised speech lie detection research requires a database containing a small number of labeled samples and a database containing a large number of unlabeled samples , where , , , and are representations of labeled samples. denote labels, , M are the total number of labeled samples; , , , and are representations of unlabeled samples, , N denote the total number of samples of unlabeled data, there . In order to improve the classification accuracy and robustness of the semi-supervised model, in this paper, random noise enhancement technique is used to strongly enhance and weakly enhance the unlabeled data with the following formula:
where and denote the 312-dimensional acoustic statistical features that have been weakly enhanced by noise addition and strongly enhanced by noise addition, respectively, while and denote their weak enhancement coefficients and strong enhancement coefficients, respectively; and denote the log Mel spectrogram features that have been weakly enhanced by noise addition and strongly enhanced by noise addition, respectively, while and denote their weak enhancement coefficients and strong enhancement coefficients, respectively; and is the Gaussian noise generating function, which generates the corresponding noise according to the shape of the original data noise data according to the shape of the original data.
2.2. Feature Fusion
In order to effectively utilize the dynamic time-frequency information in the speech signal, this paper adopts LSTM to process the log Mel spectrogram features to obtain more advanced depth frame-level feature . and processes the acoustic statistical features through the self-coding network AE to extract the deep statistical features with stronger representations. Acoustic statistical features and Mel spectrogram features have a good complementary relationship, so this paper combines acoustic statistical features with Mel spectrogram features to capture finer-grained features.
First, the depth statistical features and depth frame-level features are simply spliced and fused to form the A-S joint feature vector , where , denotes the dimension of the A-S joint feature vector J. Next, in order to obtain the semantic correlation between features and fully utilize the connection between similar features and different features, the combination of deep statistical features , deep frame-level features and A-S joint feature vector J is considered to compute the joint correlation matrix. The joint correlation matrix of depth statistical features and A-S joint feature vector J is shown in Equation (5):
where denotes the learnable weight matrix mapping the relationship between the depth frame-level features and the joint A-S feature vector J. Similarly, the joint correlation matrix of the depth frame level features and the joint feature vector J can be obtained from Equation (6):
where denotes the learnable weight matrix mapping the relationship between the depth frame-level features and the joint A-S feature vector J.
Then, the attention weights of acoustic statistical features and log Mel spectrogram features are further calculated to help the feature fusion model focus on the important information and improve the efficiency of the model when learning the distribution of similar features. The attention weights of acoustic statistical features can be obtained by combining the joint correlation matrix and the deep statistical features , and the detailed calculation is shown in Equation (7).
where denotes the attention weights of the acoustic statistical features , and is the learnable weight matrix.
The attention weights of the log Mel spectrogram features can be obtained by combining the joint correlation matrix and the depth frame-level features , and the detailed calculation is shown in Equation (6).
where denotes the attention weights of the acoustic statistical features , and is the learnable weight matrix.
The attentional correlation features of the two types of features are computed by means of the attentional weights of the acoustic statistical features and the log-Mel spectrogram features , with the formulas shown in (9) and (10) as follows.
where and denote the learnable weight matrices for acoustic statistical features and log Mel spectrogram features , respectively.
Finally, the two types of attention-related features are combined to obtain the joint attention feature .
In order to obtain a better feature representation and reduce the influence of overfitting and other factors, time domain summation is used to ensure the information integrity and stability of the fused features; batch normalization, Gelu activator and Dropout are introduced to further optimize the joint attention features . In the last part of the model, a softmax classifier is used to predict the classification results. Figure 2 shows the details of joint attention fusion.
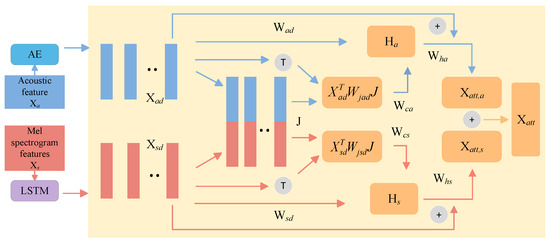
Figure 2.
Detailed map of joint attention fusion.
2.3. Multi-Loss Optimization
Semi-supervised algorithms co-optimize the performance of semi-supervised models through supervised and unsupervised losses to obtain better classification performance.
2.3.1. Supervised Loss
Supervised loss provides the correct guidance direction for model training based on the supervised signals in the labeled data, which helps the model learn accurate prediction classification. In this paper, the Jefferys-based loss function is used, and the Jefferys scatter is added to the cross-entropy loss function to maximize the target value of the output distribution, while smoothing the non-target values to reduce overfitting. The formula is as follows:
wherh denotes the predicted probability of labeled samples after model training, K denotes the total number of categories, the non-targeted output values follow a uniform distribution, and are hyperparameters.
2.3.2. Unsupervised Loss
Unsupervised loss introduces LMMD loss on the basis of cross-entropy loss function to constrain the distribution change of unsupervised features after different data enhancement to exclude the interference of redundant or irrelevant features. The formula is as follows:
where denotes the predicted probability of the strongly enhanced unlabeled feature after model training, denotes the predicted probability of the weakly enhanced unlabeled feature after model training, and denotes the pseudo-label that will be obtained after further processing , l represents the indicator function, and represents the cross entropy loss.
where M and N denote the number of weakly enhanced unlabeled and strongly enhanced unlabeled samples, respectively, denotes the kernel matrix between strongly enhanced unlabeled, denotes the kernel matrix between weakly enhanced unlabeled, denotes the kernel matrix between strongly enhanced unlabeled and self samples, and denotes the kernel matrix between weakly enhanced unlabeled and self samples.
2.3.3. Total Loss
Algorithm 1 is an optimization process for the overall loss of the system.
| Algorithm 1 Algorithm of the Multi loss optimization |
|
2.3.4. Functions of Different Modules
The joint attention mechanism’s feature fusion technique enables the model to selectively concentrate on features that are most pertinent to the task at hand from various sources of features, uncovering the interrelationships among them. By assigning weights to the input features, it can visually display which aspects of the input features the model is inclined to focus on when making specific predictions, allowing for timely model adjustments.
The semi-supervised algorithm optimizes the performance of the model by combining supervised loss and unsupervised loss. Supervised loss directly guides the model to learn known label information, enabling the model to accurately classify on training data. Unsupervised loss helps models discover patterns and relationships in data by utilizing potential information from a large amount of unlabeled data, without relying on explicit labels. By minimizing both supervised and unsupervised losses simultaneously, the model achieves a balance between known and unknown. The model performs well on labeled data while also benefiting from unlabeled data, resulting in better generalization ability. Specifically, for supervised loss, adding the Jeffreys divergence to the cross entropy loss function maximizes the probability of the target class while reducing the model’s overconfidence in specific classes by smoothing the probability distribution of non target classes, thereby improving the model’s generalization ability. For unsupervised loss, LMMD loss measures the mean difference of local regions, allowing the model to focus on the local distribution of data and providing a more detailed explanation for the performance differences of the model in different data regions.
3. Experimental Section
3.1. Datasets
The Columbia-SRI-Colorado(CSC) [21] database is a lie detection corpus designed and recorded by researchers from Columbia University in 2006. The corpus includes 32 individuals, 16 males and 16 females, all speaking standard American English. Voice recording is divided into two stages, and participants can use lies to deceive the interviewer. In voice collection, the duration of each paragraph varies significantly depending on the type of question and the way it is answered, with some lasting 1 s and others exceeding 2–3 min. The speech sampling frequency of CSC library is 16 KHz, with a total duration of about 15.2 h. We obtained a total of 5412 voices (1 damaged) through text comparison, manual listening, and speech software cutting, with each voice lasting about 1–3 s. This article selected 5411 voices for the experiment.
3.2. Experimental Setup and Evaluation Metrics
This study investigated the practical performance of model algorithms with different numbers of labels, specifically set at 200, 600, and 1200 labels. Firstly, in the data augmentation section, different noise coefficients were selected for different types of features. For the 312-dimensional acoustic statistical features, the strong augmentation noise coefficient was set to 1, and the weak augmentation noise coefficient was set to 0.32. For the 64-dimensional log Mel spectrogram features, the strong augmentation noise coefficient was set to 1, and the weak augmentation noise coefficient was set to 0.35.
All experiments were conducted on the Windows 11 operating system, utilizing an NVIDIA RTX 3060 graphics card (NVIDIA, Santa Clara, CA, USA). The experiments were performed using the PyTorch (Version: 2.2.1+cu118) deep learning framework and coded in the Python programming language. The Adam algorithm was employed for model optimization, with the number of iterations set to 100 epochs. In the model, the Dropout parameter was set to 0.9 to mitigate overfitting. Each experiment was repeated 10 times, and the average was computed to mitigate the influence of random errors.
The WA (Weighted Accuracy) is selected as the primary evaluation metric for assessing the performance of the recognition model.
In order to verify the rationality of the proposed model, three sets of ablation experiments were designed to analyze the improvement effect of the joint attention model and unsupervised fusion loss. The specific settings are as follows:
- (1)
- MFDF: Directly concatenate and fuse the 312 dimensional acoustic statistical features and 64 dimensional logarithmic Mel spectrogram features trained by the model in one dimension for lie detection.
- (2)
- MFDF + ML: Directly concatenate and fuse the 312 dimensional acoustic statistical features and 64-dimensional logarithmic Mel spectrogram features after model training, and combine them with a semi-supervised learning algorithm improved by LMMD loss for lie detection.
- (3)
- JAF: Using joint attention method to fuse the 312 dimensional acoustic statistical features and 64 dimensional logarithmic Mel spectrogram features after model training for lie detection.
As can be seen from Table 1, the performance of the proposed algorithm is better than other modules. This is due to the fusion of the two types of features by joint attention, which further captures the detailed information of the two types of features and improves the lie detection accuracy to a certain extent; by introducing the semi-supervised joint optimization loss, the potential feature information is deeply mined, which effectively improves the lie detection accuracy. It is worth noting that the accuracy of 600 labels is lower than that of 200 labels. As the number of labels increases, more low-quality or noisy labels will be introduced, causing the model to be disturbed during prediction, thereby reducing accuracy. However, as the number of labels further increased to 1200, the model had sufficient data and information to better learn and distinguish subtle differences between different labels, resulting in an improvement in accuracy.

Table 1.
Ablation experiment.
In Figure 3, we also show the accuracy and loss convergence curves of the algorithm in each group of experiments. To more clearly demonstrate the trend of changes, the number of iterations was set to 600. When the number of labels is 600, the experimental results indicate that the average accuracy of (d) is significantly higher than that of (a), (b), and (c), with the highest value reaching 63.3%. The highest values for (a) and (c) do not exceed 62%, and (b) performs the worst. Compared to (a) and (b), the loss for (c) and (d) has decreased. Overall, (d) demonstrates the best performance.
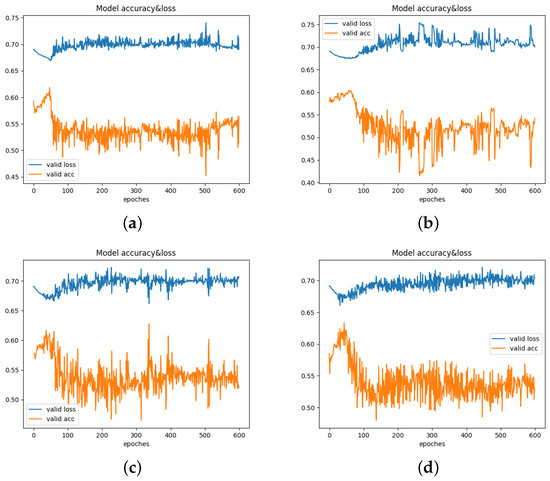
Figure 3.
Trends in accuracy and loss for each group of ablation tasks on the CSC corpus ((a) Convergence curve of the MFDF algorithm; (b) Convergence curve of the MFDF+ML algorithm; (c) Convergence curve of the JAF algorithm; (d) Convergence curve of the proposed algorithm).
3.3. Comparative Experiments
To further verify the effectiveness of the proposed algorithm, two sets of comparative experiments were designed in this chapter. The specific settings are as follows:
- (1)
- SS-AE: Utilizes a semi-supervised auto encoder [22] network for speech lie detection. This network extracts latent representations of unlabeled data using an encoder and then reconstructs features using a decoder to compute the reconstruction loss between the original and reconstructed data. This loss is utilized as an unsupervised loss to optimize the model’s generalization ability on unlabeled data.
- (2)
- Mean-teacher: Based on the Mean-teacher model [12,23], which utilizes a combination of the reconstruction loss from the autoencoder network and the consistency regularization loss from the Mean-teacher model to optimize the decision boundary, enhancing the classification ability of the semi-supervised model.
From Table 2, it can be observed that the proposed algorithm achieved accuracies of , , and for label counts of 200, 600, and 1200, respectively. These accuracies are significantly higher than those of the first comparative experiment SS-AE and the second comparative experiment Mean-teacher. These research findings indicate that the proposed method can learn the structure and features of unlabeled data and achieve better results.
Table 2.
Comparative experiments of the same algorithm.
In addition, we quantified the computational efficiency of the proposed algorithm. When the number of labels was set to 200, the total runtime of the model was 87.14 s, with an inference time of 6.22 s before the first iteration began. When the number of labels was set to 600, the total runtime was 204.33 s, and the inference time was 6.13 s. With 1200 labels, the total runtime increased to 402.52 s, with an inference time of 6.06 s. All experimental data are averages, and the results indicate that as the number of labels increases, the total training time of the model also increases, while the inference time shows no significant change.
3.4. Confusion Matrix
To further investigate the accuracy of lie detection, we introduced a confusion matrix to analyze the model on the CSC datasets. The confusion matrix, as shown in Figure 4, indicates that when the number of labeled data is 200, the recognition rates for truth and lies are and , respectively; when the number of labeled data is 600, the recognition rates for truth and deception are and , respectively; when the number of labels is 1200, the recognition rates for truth and lies are and , respectively. It is noteworthy that the accuracy for lies consistently exceeds .
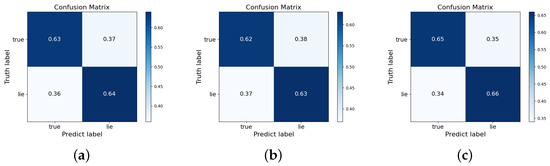
Figure 4.
Confusion matrix under different labeled data conditions ((a) 200; (b) 600; (c) 1200).
4. Conclusions
In this paper, we propose a semi-supervised lie detection algorithm based on integrating multiple speech emotional features. First, acoustic statistical features and log Mel spectrogram features are extracted from the speech. A parallel network composed of an AE network and an LSTM network is then constructed to extract deep speech deception detection features. Subsequently, a joint attention method is proposed to enhance the fusion of features by leveraging the correlation between different features. Finally, a Local Maximum Mean Discrepancy (LMMD) loss is introduced in the unsupervised loss to help the model learn the intrinsic structure and feature information of unlabeled samples. A series of ablation experiments and comparative experiments are conducted on the CSC datasets to demonstrate the effectiveness of the proposed method in this paper.
Author Contributions
Conceptualization, J.X. and H.T.; methodology, J.X.; software, H.Y.; validation, H.Y. and Z.X.; formal analysis, J.X., H.Y. and Z.X.; investigation, J.X., H.Y. and L.Z.; data curation, L.Z.; writing—original draft preparation, J.X. and H.Y.; writing—review and editing, J.X., H.Y. and H.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Science and Technology Plan Project of Changzhou: CJ20210155. This work was supported by Natural Science Foundation of the Jiangsu Higher Education Institutions of China: 23KJA520001. This work was supported by Henan Province Key Scientific Research Projects Plan of Colleges and Universities: No. 22A520004, No. 22A510001.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Viji, D.; Gupta, N.; Parekh, K.H. History of Deception Detection Techniques. In Proceedings of International Conference on Deep Learning, Computing and Intelligence: ICDCI 2021; Springer Nature Singapore: Singapore, 2022; pp. 373–387. [Google Scholar]
- Liu, Z.; Xu, J.; Wu, M.; Cao, W.; Chen, L.F.; Ding, X.W.; Hao, M.; Xie, Q. Review of emotional feature extraction and dimension reduction method for speech emotion recognition. Chin. J. Comput. 2017, 40, 1–23. [Google Scholar]
- Ekman, P.; O’Sullivan, M.; Friesen, W.V.; Scherer, K.R. Invited article: Face, voice, and body in detecting deceit. J. Nonverbal Behav. 1991, 15, 125–135. [Google Scholar]
- Kirchhuebel, C. The Acoustic and Temporal Characteristics of Deceptive Speech. Ph.D. Thesis, University of York, York, UK, 2013. [Google Scholar]
- Hansen, J.H.L.; Womack, B.D. Feature analysis and neural network-based classification of speech under stress. IEEE Trans. Speech Audio Process. 1996, 4, 307–313. [Google Scholar]
- Kirchhübel, C.; Howard, D.M.; Stedmon, A.W. Acoustic correlates of speech when under stress: Research, methods and future directions. Int. J. Speech, Lang. Law 2011, 18, 75–98. [Google Scholar]
- Springer. Springer Handbook of Speech Processing; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Bareeda, E.P.F.; Mohan, B.S.S.; Muneer, K.V.A. Lie detection using speech processing techniques. J. Phys. Conf. Ser. Iop Publ. 2021, 1921, 012028. [Google Scholar]
- Nasri, H.; Ouarda, W.; Alimi, A.M. ReLiDSS: Novel lie detection system from speech signal. In Proceedings of the 2016 IEEE/ACS 13th International Conference of Computer Systems and Applications (AICCSA), Agadir, Morocco, 29 November–2 December 2016; pp. 1–8. [Google Scholar]
- Zhou, Y.; Zhao, H.; Pan, X. Lie detection from speech analysis based on k–svd deep belief network model. In Proceedings of the Intelligent Computing Theories and Methodologies: 11th International Conference, ICIC 2015, Fuzhou, China, 20–23 August 2015; pp. 189–196. [Google Scholar]
- Sanaullah, M.; Gopalan, K. Deception detection in speech using bark band and perceptually significant energy features. In Circuits and Systems (MWSCAS), Proceedings of the 2013 IEEE 56th International Midwest Symposium, Columbus, OH, USA, 4–7 August 2013; IEEE: Piscataway, NJ, USA, 2013; p. 6674872. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Adv. Neural Inf. Process. Syst. 2017, 30, 1195–1204. [Google Scholar]
- Sun, B.; Cao, S.; He, J.; Yu, L. Affect recognition from facial movements and body gestures by hierarchical deep spatio-temporal features and fusion strategy. Neural Netw. Off. J. Int. Neural Netw. Soc. 2018, 105, 36–51. [Google Scholar]
- Fang, Y.; Fu, H.; Tao, H.; Liang, R.; Zhao, L. A novel hybrid network model based on attentional multi-feature fusion for deception detection. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2020, E104A, 622–626. [Google Scholar]
- Enos, F.; Shriberg, E.; Graciarena, M.; Hirschberg, J.; Stolcke, A. Detecting deception using critical segments. In Proceedings of the INTERSPEECH 2007, 8th Annual Conference of the International Speech Communication Association, Antwerp, Belgium, 27–31 August 2007; pp. 2281–2284. [Google Scholar]
- He, C.; Wei, H. Transformer-Based Deep Hashing Method for Multi-Scale Feature Fusion. In Proceedings of the ICASSP 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Praveen, R.G.; Granger, E.; Cardinal, P. Recursive joint attention for audio-visual fusion in regression based emotion recognition. In Proceedings of the ICASSP 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Bousquet, P.-M.; Rouvier, M. Jeffreys Divergence-Based Regularization of Neural Network Output Distribution Applied to Speaker Recognition. In Proceedings of the ICASSP 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Zhu, Y.; Zhuang, F.; Wang, J.; Ke, G.; Chen, J.; Bian, J.; Xiong, H.; He, Q. Deep Subdomain Adaptation Network for Image Classification. In IEEE Transactions on Neural Networks and Learning Systems, Computer Vision and Pattern Recognition; IEEE: New York, NY, USA, 2021; Volume 32, pp. 1713–1722. [Google Scholar]
- Logan, B. Mel frequency cepstral coefficients for music modeling. Ismir 2000, 270, 11. [Google Scholar]
- Hirschberg, J.; Benus, S.; Brenier, J.M.; Enos, F.; Friedman, S.; Gilman, S.; Girand, C.; Graciarena, M.; Kathol, A.; Michaelis, L.; et al. Distinguishing deceptive from non-deceptive speech. In Proceedings of theINTERSPEECH 2005 - Eurospeech, 9th European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005; pp. 1833–1836. [Google Scholar]
- Deng, J.; Xu, X.; Zhang, Z.; Frühholz, S.; Schuller, B. Semisupervised autoencoders for speech emotion recognition. IEEE ACM Trans. Audio Speech Lang. Process. 2017, 26, 31–43. [Google Scholar]
- Fu, H.; Yu, H.; Wang, X.; Lu, X.; Zhu, C. A Semi-Supervised Speech Deception Detection Algorithm Combining Acoustic Statistical Features and Time-Frequency Two-Dimensional Features. Brain Sci. 2023, 13, 725. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).