
GCE: An Audio-Visual Dataset for Group Cohesion and Emotion Analysis

 ,
,  , ,
, , 

Abstract
1. Introduction
- Group Cohesion and Emotion Dataset Construction: We present the Audio-Visual Dataset for Group Cohesion and Emotion Analysis (GCE). When collecting the videos for this dataset, we considered control of the age effect and only sitting conversation situations. In addition, this dataset includes annotations by counseling psychology researchers with seven cohesion levels and three emotions for each video clip.
- Addressing Class Imbalance and Duration Challenges: The dataset is deliberately designed to incorporate challenging aspects, such as unbalanced class distributions and extended video durations. These challenges are inherent in their classification and regression tasks, where the dominant classes often receive more attention than the minority classes. Additionally, longer recordings encompass various levels of cohesion and emotional states, which can complicate accurate predictive modeling. Therefore, this research encourages the development of models that mitigate the impact of skewed class distributions.
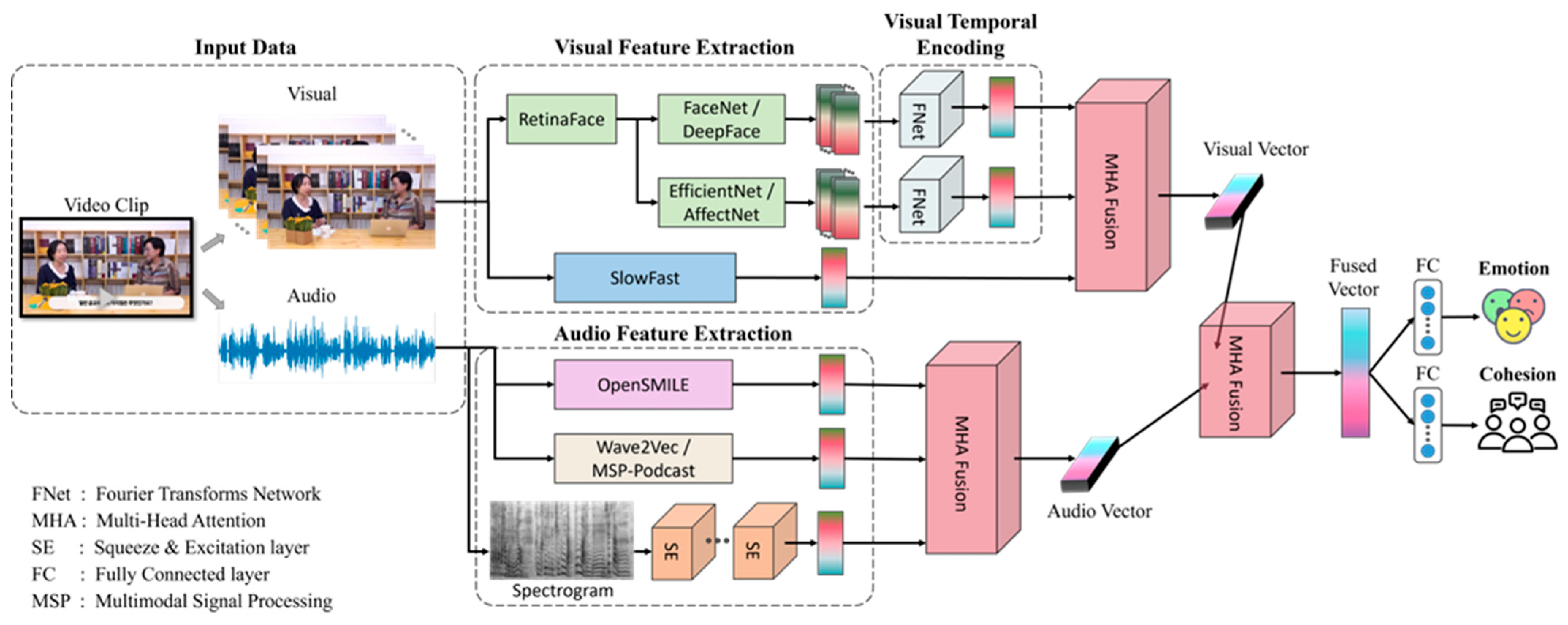
- Multimodal Fusion Model for Group Cohesion and Emotion: We develop the baseline model for the prediction of group cohesion and group emotion. This involves extracting various features from the audio and visual aspects of the dataset, including facial traits, expressions, video context, static speech characteristics, speech emotions, and spectrograms of the speaker’s voice. In addition, FNet module and Multi-Head Attention (MHA) are used to combine the visual and audio features. The baseline model effectively fuses multi-modality, showing a higher performance than single modality.
2. Related Works

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Purpose | Scenario | Modality | Data Size | Duration | Annotator | Annotation |
|---|---|---|---|---|---|---|---|
| MED (2016) [16] | Research on abnormal behavior understanding in crowd | Crowd outdoor | Video | 31 | 0.4 h | - | Panic, Fight, Congestion, Obstacle, Neutral |
| SALSA (2017) [17] | Identify social interactions in the wild | Conversational group | Video | 1 | 1 h | 3 | Personality, Position, Head, Body orientation, F-formation |
| MatchNMingle (2018) [19] | Analyze the social signal and group interactions | Conversational group | Video | 1 | 2 h | 3 | HEXACO, Self control scale, Sociosexual orientation, Inventory, Social cues, Social actions, F-formations |
| MULTISIMO (2018) [18] | Identify human-human interactions, group behavior | Experiment | Video | 23 | 4 h | - | Personality, Experience, Speaker segmentation, Dominance, Transcript, Turn taking, Emotions |
| VGAF (2019) [12] | Identify group cohesion and group emotion | In the wild | Video | 234 | 5 h | 20 | Cohesion, Emotional state |
| GAME-ON (2020) [20] | Identify non-verbal behavior | Game | Video | - | 11.5 h | - | Cohesion, Leadership, Emotional state, Warmth and Competences |
| GCE (ours) | Identify group cohesion scores and group emotional states | Conversational group | Video | 40 | 8.6 h | 7 | Cohesion, Emotional state |
3. Construction of the Group Cohesion and Emotion Dataset
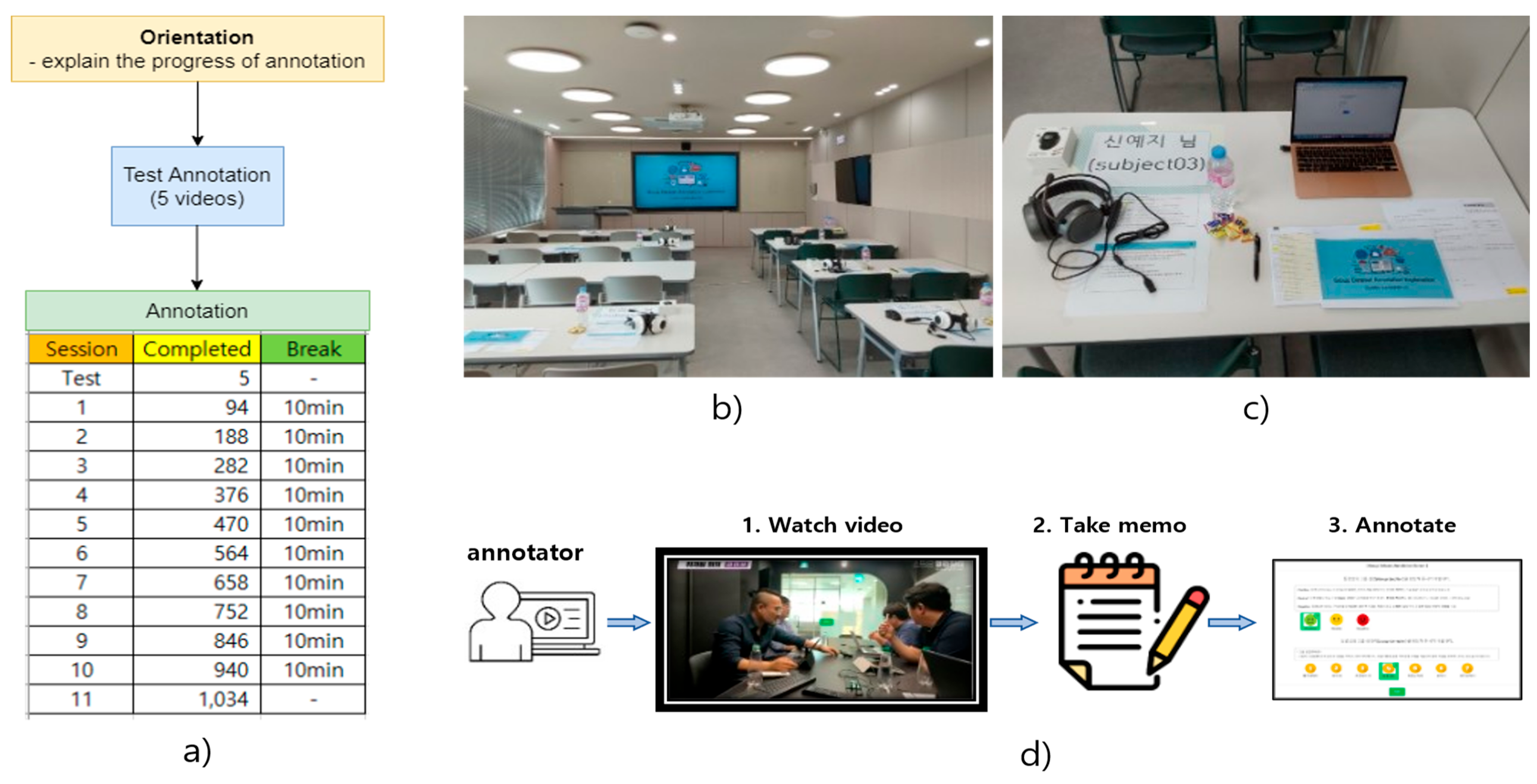
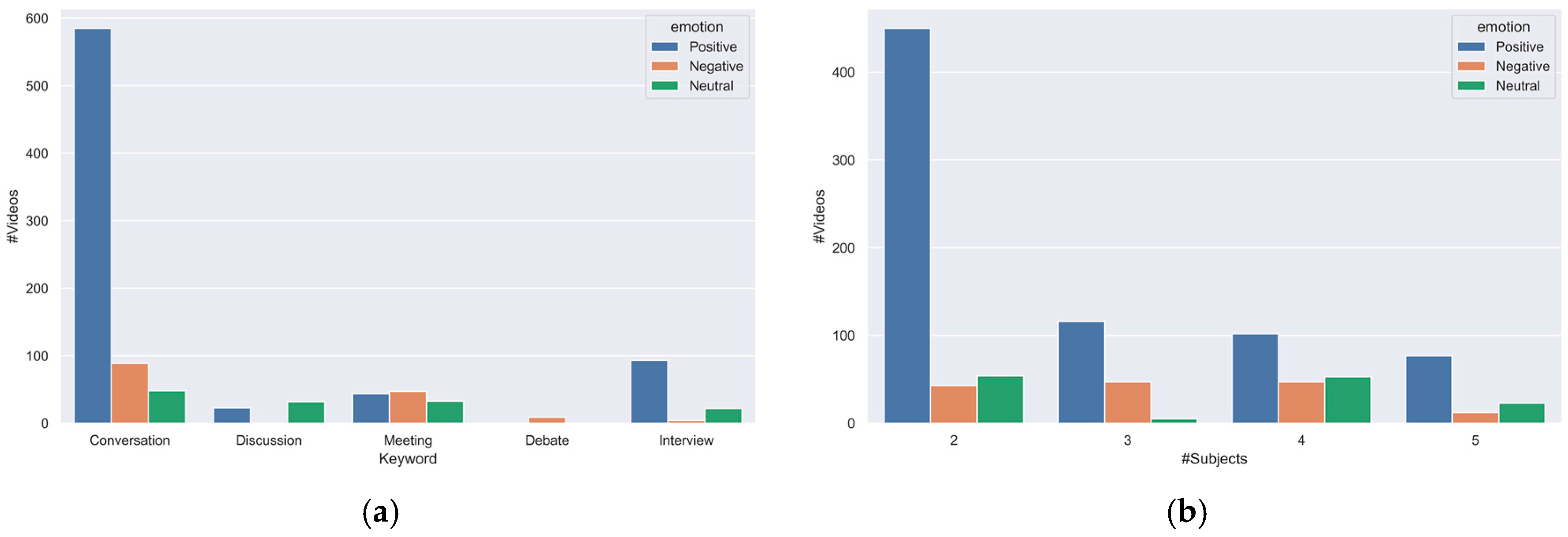
3.1. Video Data Collection
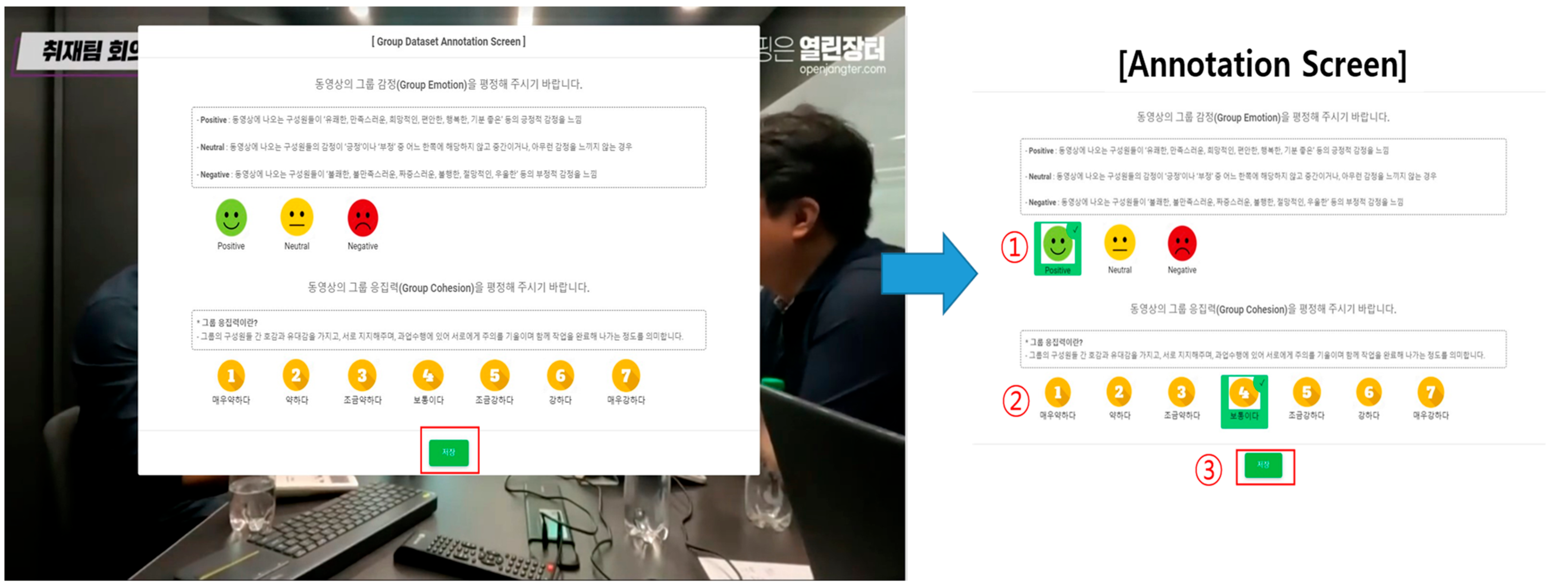
3.2. Annotation
3.3. Inter-Rater Reliability Analysis
4. Baseline Model Development for Group Cohesion and Group Emotion Prediction
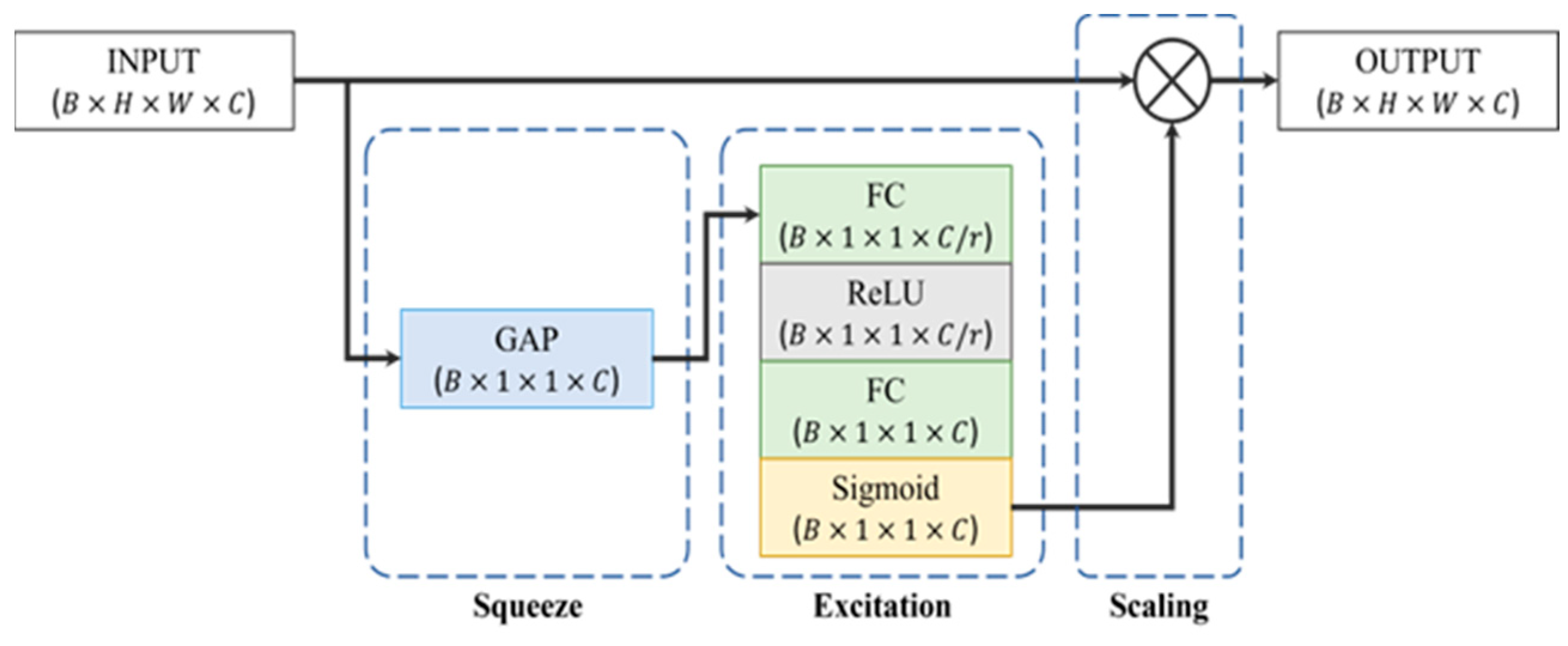
4.1. Feature Extraction
4.2. Multi-Task Multi-Feature Fusion Framework
5. Experimental Results
5.1. Experimental Settings
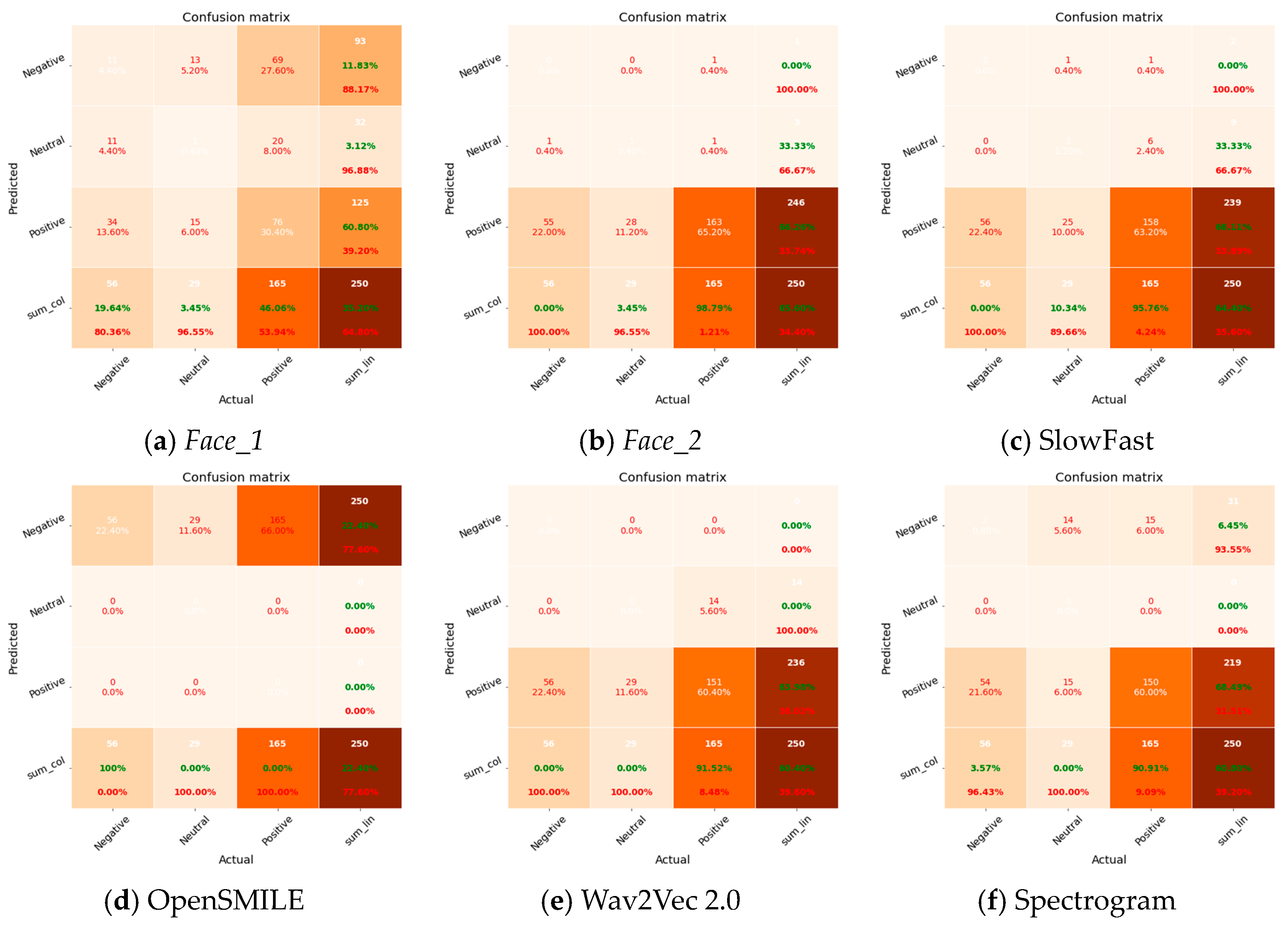
5.2. Performance
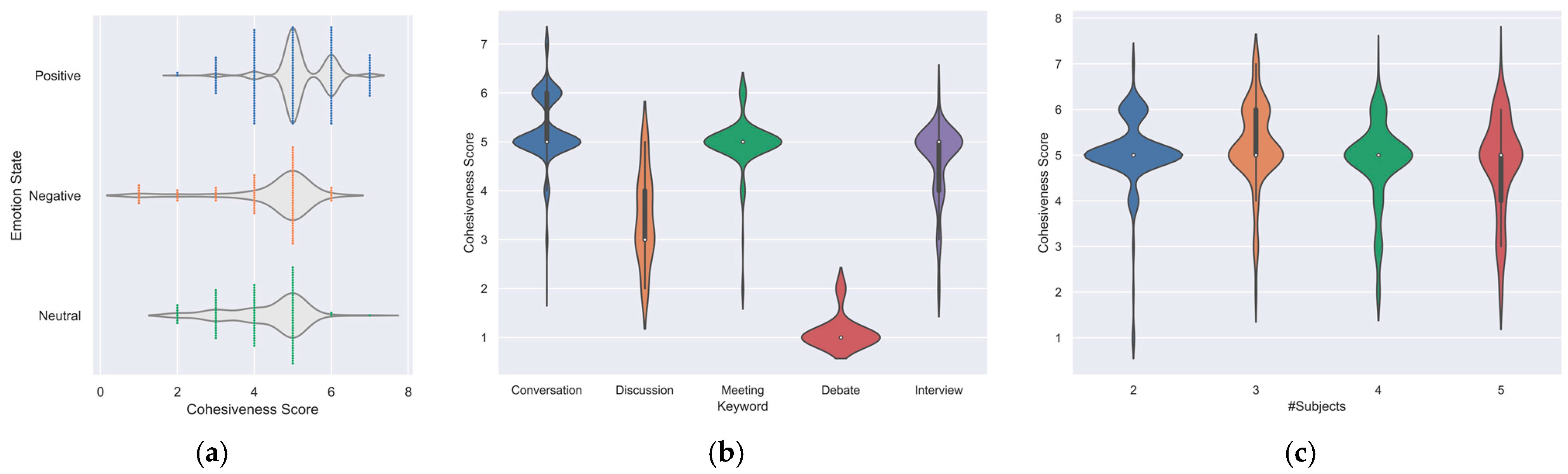
5.3. Discussion
- Data Creation: The primary objective was to construct the Group Cohesion and Emotion (GCE) dataset, which comprised 1029 segmented videos sourced from YouTube with the creative common license to address copyright concerns. These videos showcased a variety of group interactions, such as interviews, meetings, and casual conversations. Following the publication of this paper, we will make this dataset available for further research. This dataset served as a foundation for the in-depth analysis of group cohesion and emotion within social interactions.
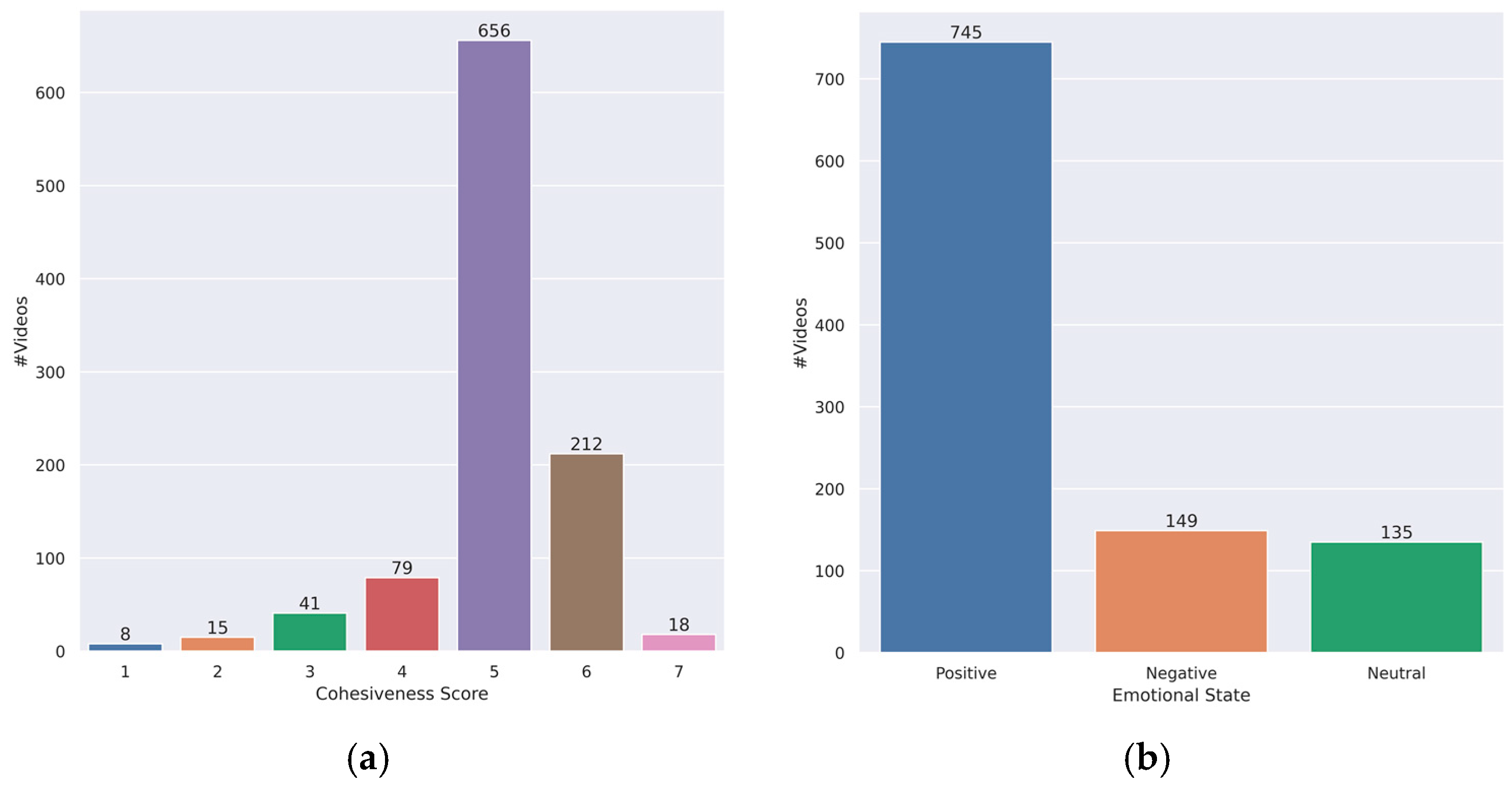
- Annotation Process: To create a reliable foundation for subsequent research, the dataset was meticulously annotated. Graduate psychology students assigned group cohesion levels within the range of 1 to 7 and categorized affective states as negative, neutral, or positive for each 30 s video segment.
- Inter-Rater Reliability Analysis: To ensure the reliability and consistency of the dataset, the study employed the Fleiss Kappa statistic to assess the level of agreement among the seven annotators for categorizing group emotions. The analysis confirmed the dependability of the annotation process.
- Model Development: The study aimed to establish a foundational model for predicting group cohesion and detecting group emotion within the GCE dataset. Advanced visual and audio embedding techniques, including RetinaFace, FaceNet, EfficientNet, SlowFast, OpenSMILE, and Wav2Vec 2.0, were utilized for feature extraction. Multi-Head Attention (MHA) fusion was incorporated to enhance cross-representation learning.
- Unimodal and Multimodal Analysis: The research conducted an in-depth analysis of group cohesion prediction and group emotion detection using both unimodal and multimodal techniques. This provided insights into the effectiveness of the different approaches and the interplay between the visual and audio features.
- Challenges of Class Imbalanced: The dataset was constructed by collecting videos of group members having conversations, which were predominantly positive in real life. Consequently, the dataset reflected the real world and had a very high proportion of positive classes. Training a model on such an imbalanced dataset posed challenges, including difficulties in model convergence and a tendency to predict only the majority class. In this study, we aimed to improve the prediction accuracy for each class by enabling the model to learn the features specific to each class. While the baseline model performed well in predicting each class, even with an imbalanced dataset, it was limited to only increasing the prediction probability for the minority class.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Carron, A.V.; Widmeyer, W.N.; Brawley, L.R. The development of an instrument to assess cohesion in sport teams: The Group Environment Questionnaire. J. Sport Exerc. Psychol. 1985, 7, 244–266. [Google Scholar] [CrossRef]
- Barsade, S.G.; Gibson, D.E. Group Emotion: A View from Top and Bottom; Gruenfeld, D.H., Ed.; Elsevier Science: Amsterdam, The Netherlands, 1998; pp. 81–102. [Google Scholar]
- Ekman, P.; Friesen, W.V. Constants across cultures in the face and emotion. J. Personal. Soc. Psychol. 1971, 17, 124–129. [Google Scholar] [CrossRef] [PubMed]
- Posner, J.; Russell, J.A.; Peterson, B.S. The circumplex model of affect: An integrative approach to affective neuroscience, cognitive development, and psychopathology. Dev. Psychopathol. 2005, 17, 715–734. [Google Scholar] [CrossRef] [PubMed]
- Guo, D.; Wang, K.; Yang, J.; Zhang, K.; Peng, X.; Qiao, Y. Exploring regularizations with face, body and image cues for group cohesion prediction. In Proceedings of the 2019 International Conference on Multimodal Interaction, Suzhou, China, 14–18 October 2019. [Google Scholar]
- Dang, X.T.; Yang, H.J.; Lee, G.S.; Kim, S.H. D2C-Based Hybrid Network for Predicting Group Cohesion Scores. IEEE Access 2021, 9, 84356–84363. [Google Scholar]
- Zhu, B.; Guo, X.; Barner, K.; Boncelet, C. Automatic group cohesiveness detection with multi-modal features. In Proceedings of the 2019 International Conference on Multimodal Interaction, Suzhou, China, 14–18 October 2019. [Google Scholar]
- Maman, L. Multimodal Groups’ Analysis for Automated Cohesion Estimation. In Proceedings of the 2020 International Conference on Multimodal Interaction, Utrecht, The Netherlands, 25–29 October 2020. [Google Scholar]
- Corbellini, N.; Ceccaldi, E.; Varni, G.; Volpe, G. An exploratory study on group potency classification from non-verbal social behaviours. In Proceedings of the International Conference on Pattern Recognition, Montréal, QC, Canada, 21–25 August 2022. [Google Scholar]
- Ghosh, S.; Dhall, A.; Sebe, N. Automatic group affect analysis in images via visual attribute and feature networks. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018. [Google Scholar]
- Mou, W.; Celiktutan, O.; Gunes, H. Group-level arousal and valence recognition in static images: Face, body and context. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015. [Google Scholar]
- Sharma, G.; Ghosh, S.; Dhall, A. Automatic group level affect and cohesion prediction in videos. In Proceedings of the 2019 8th International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW), Cambridge, MA, USA, 3–6 September 2019. [Google Scholar]
- Guo, X.; Polania, L.; Zhu, B.; Boncelet, C.; Barner, K. Graph neural networks for image understanding based on multiple cues: Group emotion recognition and event recognition as use cases. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020. [Google Scholar]
- Dhall, A.; Joshi, J.; Sikka, K.; Goecke, R.; Sebe, N. The more the merrier Analysing the affect of a group of people in images. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015. [Google Scholar]
- Ghosh, S.; Dhall, A.; Sebe, N.; Gedeon, T. Predicting group cohesiveness in images. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019. [Google Scholar]
- Rabiee, H.; Haddadnia, J.; Mousavi, H.; Kalantarzadeh, M.; Nabi, M.; Murino, V. Novel dataset for fine-grained abnormal behavior understanding in crowd. In Proceedings of the 2016 13th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Colorado Springs, CO, USA, 23–26 August 2016. [Google Scholar]
- Alameda-Pineda, X.; Subramanian, R.; Ricci, E.; Lanz, O.; Sebe, N. SALSA: A multimodal dataset for the automated analysis of free-standing social interactions. In Group and Crowd Behavior for Computer Vision; Academic Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Cabrera-Quiros, L.; Demetriou, A.; Gedik, E.; Van der Meij, L.; Hung, H. The MatchNMingle dataset: A novel multi-sensor resource for the analysis of social interactions and group dynamics in-the-wild during free-standing conversations and speed dates. IEEE Trans. Affect. Comput. 2018, 12, 113–130. [Google Scholar] [CrossRef]
- Koutsombogera, M.; Vogel, C. Modeling collaborative multimodal behavior in group dialogues: The MULTISIMO corpus. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Maman, L.; Ceccaldi, E.; Lehmann-Willenbrock, N.; Likforman-Sulem, L.; Chetouani, M.; Volpe, G.; Varni, G. Game-on: A multimodal dataset for cohesion and group analysis. IEEE Access 2020, 8, 124185–124203. [Google Scholar] [CrossRef]
- Zheng, W.-L.; Dong, B.-N.; Lu, B.-L. Multimodal emotion recognition using EEG and eye tracking data. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014. [Google Scholar]
- Park, T.J.; Park, S.H. Emotional Evaluation about IAPS in Korean University Students. Korean J. Cogn. Sci. 2009, 20, 183–195. [Google Scholar]
- Cota, A.A.; Evans, C.R.; Dion, K.L.; Kilik, L.; Longman, R.S. The structure of group cohesion. Personal. Soc. Psychol. Bull. 1995, 21, 572–580. [Google Scholar] [CrossRef]
- Joshi, A.; Kale, S.; Chandel, S.; Pal, D.K. Likert scale: Explored and explained. Br. J. Appl. Sci. Technol. 2015, 7, 396. [Google Scholar] [CrossRef]
- Al-Twairesh, N.; Al-Khalifa, H.; Al-Salman, A.; Al-Ohali, Y. Arasenti-tweet: A corpus for arabic sentiment analysis of saudi tweets. Procedia Comput. Sci. 2017, 117, 63–72. [Google Scholar] [CrossRef]
- Hallgren, K.A. Computing inter-rater reliability for observational data: An overview and tutorial. Tutor. Quant. Methods Psychol. 2012, 8, 23. [Google Scholar] [CrossRef] [PubMed]
- Fleiss, J.L. Measuring nominal scale agreement among many raters. Psychol. Bull. 1971, 76, 378. [Google Scholar] [CrossRef]
- Florian, S.; Dmitry, K.; James, P. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2015, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Mingxing, T.; Quoc, L. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning 2019, PMLR 97, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Christoph, F.; Haoqi, F.; Jitendra, M.; Kaiming, H. SlowFast Networks for Video Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 2019, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Florian, E.; Martin, W.; Björn, S. Opensmile: The munich versatile and fast open-source audio feature extractor. In Proceedings of the 18th ACM international conference on Multimedia (MM ‘10), Firenze, Italy, 25–29 October 2010; pp. 1459–1462. [Google Scholar]
- Alexei, B.; Yuhao, Z.; Abdelrahman, M.; Michael, A. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. Adv. Neural Inf. Process. Syst. (NeurIPS) 2020, 33, 12449–12460. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]



| Dataset | Purpose | Scenario | Modality | Data Size | Duration | Annotator | Annotation |
|---|---|---|---|---|---|---|---|
| HAPPEI [13] | Identify the visual cues for group happiness stages | In the wild | Image | 3134 | - | 4 | Neutral, Small smile, Large smile, Small laugh, Large laugh, Thrilled |
| MultiEmoVA [11] | Identify the arousal and valence expressed at the group-level | In the wild | Image | 250 | - | 15 | Arousal, Valence |
| GAF-Cohesion [15] | Identify the visual cues for group cohesion scores | In the wild | Image | 14,175 | - | 5 | Strongly agree, Agree, Disagree, Strongly disagree |
| GroupEmoW [14] | Identify group-level emotion in the wild | In the wild | Image | 15,894 | - | 5 | Valence states |
| Property | Value | Size | Format | Example |
|---|---|---|---|---|
| Total no. of files | 1029 | 30 s × 1029 (8.6 h) | mp4 |  |
| Features (Visual) | Facial (Face_1, Face_2) | 1029 | npz | Shape: (2, 1408) Data type: float32 |
| SlowFast | 1029 | npz | Shape: (1, 2304) Data type: float32 | |
| Features (Audio) | OpenSMILE 2.4.1 | 1029 (88 characteristics) | csv | VID, F0semitoneFrom27.5 Hz_sma3nz_amean,…, equivalentSoundLevel_dBp |
| Wav2Vec 2.0 | 1029 (1024 characteristics) | csv | VID, Feature_0, Feature_1,…, Feature_1023 | |
| Spectrogram | 1029 | jpg |  |
| Video ID | Keyword | Age Group | People | Video ID | Keyword | Age Group | People |
|---|---|---|---|---|---|---|---|
| VID_1 | Interview | Middle-aged Adults | 2 | VID_21 | Debate | Old-aged Adults | 2 |
| VID_2 | Conversation | Young Adults Middle-aged Adults | 3 | VID_22 | Conversation | Old-aged Adults | 2 |
| VID_3 | Conversation | Young Adults | 2 | VID_23 | Conversation | Old-aged Adults | 2 |
| VID_4 | Conversation | Young Adults Middle-aged Adults | 3 | VID_24 | Interview | Old-aged Adults | 2 |
| VID_5 | Meeting | Old-aged Adults | 4 | VID_25 | Conversation | Young Adults Middle-aged Adults | 2 |
| VID_6 | Conversation | Middle-aged Adults | 2 | VID_26 | Conversation | Young Adults Middle-aged Adults | 2 |
| VID_7 | Conversation | Middle-aged Adults | 2 | VID_27 | Conversation | Middle-aged Adults | 2 |
| VID_8 | Interview | Middle-aged Adults Old-aged Adults | 3 | VID_28 | Conversation | Middle-aged Adults | 2 |
| VID_9 | Conversation | Young Adults Middle-aged Adults | 3 | VID_29 | Conversation | Middle-aged Adults | 2 |
| VID_10 | Interview | Old-aged Adults | 2 | VID_30 | Conversation | Young Adults Middle-aged Adults | 5 |
| VID_11 | Discussion | Middle-aged Adults Old-aged Adults | 4 | VID_31 | Conversation | Middle-aged Adults | 2 |
| VID_12 | Debate | Old-aged Adults | 2 | VID_32 | Interview | Middle-aged Adults | 2 |
| VID_13 | Conversation | Middle-aged Adults | 4 | VID_33 | Conversation | Middle-aged Adults | 2 |
| VID_14 | Discussion | Middle-aged Adults Old-aged Adults | 5 | VID_34 | Conversation | Middle-aged Adults | 2 |
| VID_15 | Debate | Middle-aged Adults Old-aged Adults | 2 | VID_35 | Conversation | Young Adults | 2 |
| VID_16 | Interview | Middle-aged Adults | 2 | VID_36 | Conversation | Middle-aged Adults | 3 |
| VID_17 | Conversation | Middle-aged Adults | 2 | VID_37 | Conversation | Middle-aged Adults | 2 |
| VID_18 | Conversation | Young Adults Middle-aged Adults | 5 | VID_38 | Conversation | Middle-aged Adults | 2 |
| VID_19 | Conversation | Young Adults | 2 | VID_39 | Conversation | Middle-aged Adults | 2 |
| VID_20 | Discussion | Young Adults Middle-aged Adults | 4 | VID_40 | Interview | Old-aged Adults | 3 |
| Category | Definition |
|---|---|
| Positive | Members in the video feel positive emotions, such as pleasantness, satisfaction, hope, comfort, happiness, and feeling good |
| Neutral | If the emotions of the members in the video do not fall under either “positive” or “negative” and are intermediate, or if members do not feel any emotions |
| Negative | Members in the video feel negative emotions, such as unpleasantness, dissatisfaction, annoyance, unhappiness, hopelessness, and depression |
| Face_1 | Face_2 | SlowFast | OpenSMILE | Wav2Vec 2.0 | |||
|---|---|---|---|---|---|---|---|
| Input: 64 × 100 × 512 | Input: 64 × 100 × 1408 | Input: 64 × 2304 | Input: 64 × 88 | Input: 64 × 1024 | |||
| FNet: 64 × 100 × 512 | FNet: 64 × 100 × 1408 | ||||||
| AvgPool: 64 × 100 | AvgPool: 64 × 100 | FC1: 64 × 100 | FC1: 64 × 100 | FC1: 64 × 100 | |||
| FC1: 64 × 64 | FC1: 64 × 64 | FC2: 64 × 64 | FC2: 64 × 64 | FC2: 64 × 64 | |||
| FC2: 64 × 32 | FC2: 64 × 32 | FC3: 64 × 32 | FC3: 64 × 32 | FC3: 64 × 32 | |||
| Output1: 64 × 3 | Output1: 64 × 3 | Output1: 64 × 3 | Output1: 64 × 3 | Output1: 64 × 3 | |||
| Output2: 64 | Output2: 64 | Output2: 64 | Output2: 64 | Output2: 64 | |||
| Spectrogram | Fusion (Visual) | Fusion (Audio) | Fusion (Visual + Audio) | ||||
| Input: 64 × 128 × 1292 | Input: | Input: | Input: | ||||
| SE1: 64 × 64 × 323 | |||||||
| SE2: 64 × 32 × 80 | |||||||
| SE3: 64 × 16 × 40 | |||||||
| SE4: 64 × 8 × 20 | |||||||
| AvgPool: 64 × 8 | MHA: 64 × 64 | MHA: 64 × 64 | MHA: 64 × 64 | ||||
| FC1: 64 × 64 | FC1: 64 × 64 | FC1: 64 × 64 | FC1: 64 × 64 | ||||
| FC2: 64 × 32 | FC2: 64 × 32 | FC2: 64 × 32 | FC2: 64 × 32 | ||||
| Output1: 64 × 3 | Output1: 64 × 3 | Output1: 64 × 3 | Output1: 64 × 3 | ||||
| Output2: 64 | Output2: 64 | Output2: 64 | Output2: 64 | ||||
| Modality | Features | MAE ↓ | MAPE ↓ | MSE ↓ | ↑ |
|---|---|---|---|---|---|
| Visual | Face_1 | 2.600 | 0.514 | 7.533 | −8.314 |
| Face_2 | 0.773 | 0.207 | 1.153 | −0.425 | |
| SlowFast | 5.436 | 1.136 | 30.645 | −36.885 | |
| Audio | OpenSMILE | 1.223 | 0.255 | 1.788 | −1.210 |
| Wav2Vec 2.0 | 1.929 | 0.423 | 2.481 | −3.883 | |
| Spectrogram | 0.547 | 0.173 | 0.864 | −0.022 | |
| Fusion | Visual | 0.744 | 0.202 | 1.074 | −0.328 |
| Audio | 0.542 | 0.149 | 0.820 | −0.013 | |
| Visual + Audio | 0.077 | 0.116 | 0.012 | −0.160 |
| Modality | Features | Acc ↑ | Pre ↑ | Rec ↑ | ↑ | AP ↑ | AUC ↑ |
|---|---|---|---|---|---|---|---|
| Visual | Face_1 | 0.35 | 0.25 | 0.23 | 0.23 | 0.30 | 0.39 |
| Face_2 | 0.65 | 0.33 | 0.34 | 0.28 | 0.43 | 0.65 | |
| SlowFast | 0.64 | 0.33 | 0.35 | 0.31 | 0.29 | 0.37 | |
| Audio | OpenSMILE | 0.22 | 0.08 | 0.33 | 0.12 | 0.44 | 0.61 |
| Wav2Vec 2.0 | 0.60 | 0.21 | 0.30 | 0.25 | 0.22 | 0.25 | |
| Spectrogram | 0.60 | 0.25 | 0.31 | 0.27 | 0.53 | 0.73 | |
| Fusion | Visual | 0.66 | 0.22 | 0.33 | 0.27 | 0.35 | 0.54 |
| Audio | 0.66 | 0.22 | 0.33 | 0.27 | 0.33 | 0.49 | |
| Visual + Audio | 0.91 | 0.30 | 0.33 | 0.32 | 0.36 | 0.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lim, E.; Ho, N.-H.; Pant, S.; Kang, Y.-S.; Jeon, S.-E.; Kim, S.; Kim, S.-H.; Yang, H.-J. GCE: An Audio-Visual Dataset for Group Cohesion and Emotion Analysis. Appl. Sci. 2024, 14, 6742. https://doi.org/10.3390/app14156742
Lim E, Ho N-H, Pant S, Kang Y-S, Jeon S-E, Kim S, Kim S-H, Yang H-J. GCE: An Audio-Visual Dataset for Group Cohesion and Emotion Analysis. Applied Sciences. 2024; 14(15):6742. https://doi.org/10.3390/app14156742
Chicago/Turabian StyleLim, Eunchae, Ngoc-Huynh Ho, Sudarshan Pant, Young-Shin Kang, Seong-Eun Jeon, Seungwon Kim, Soo-Hyung Kim, and Hyung-Jeong Yang. 2024. "GCE: An Audio-Visual Dataset for Group Cohesion and Emotion Analysis" Applied Sciences 14, no. 15: 6742. https://doi.org/10.3390/app14156742
APA StyleLim, E., Ho, N.-H., Pant, S., Kang, Y.-S., Jeon, S.-E., Kim, S., Kim, S.-H., & Yang, H.-J. (2024). GCE: An Audio-Visual Dataset for Group Cohesion and Emotion Analysis. Applied Sciences, 14(15), 6742. https://doi.org/10.3390/app14156742