

Universal Local Attractors on Graphs



Abstract
1. Introduction
- Step 1.
- We analyze positive definite graph filters, which are graph signal processing constructs that diffuse node representations, like embeddings of node features, through links. Graph filters are already responsible for the homophilous propagation of predictions in predict-then-propagate GNNs (Section 2.2) and we examine their ability to track optimization trajectories of their posterior outputs when appropriate modifications are made to inputs. In this case, both inputs and outputs are one-dimensional.
- Step 2.
- By injecting the prior modification process mentioned above in graph filtering pipelines, we end up creating a GNN architecture that can minimally edit input node representations to locally minimize loss functions given some mild conditions.
- Step 3.
- We generalize our analysis to multidimensional node representations/features by folding the latter to one-dimensional counterparts while keeping track of which elements correspond to which dimension indexes, and transform inputs and outputs through linear relations to account for the different dimensions between them.
- a.
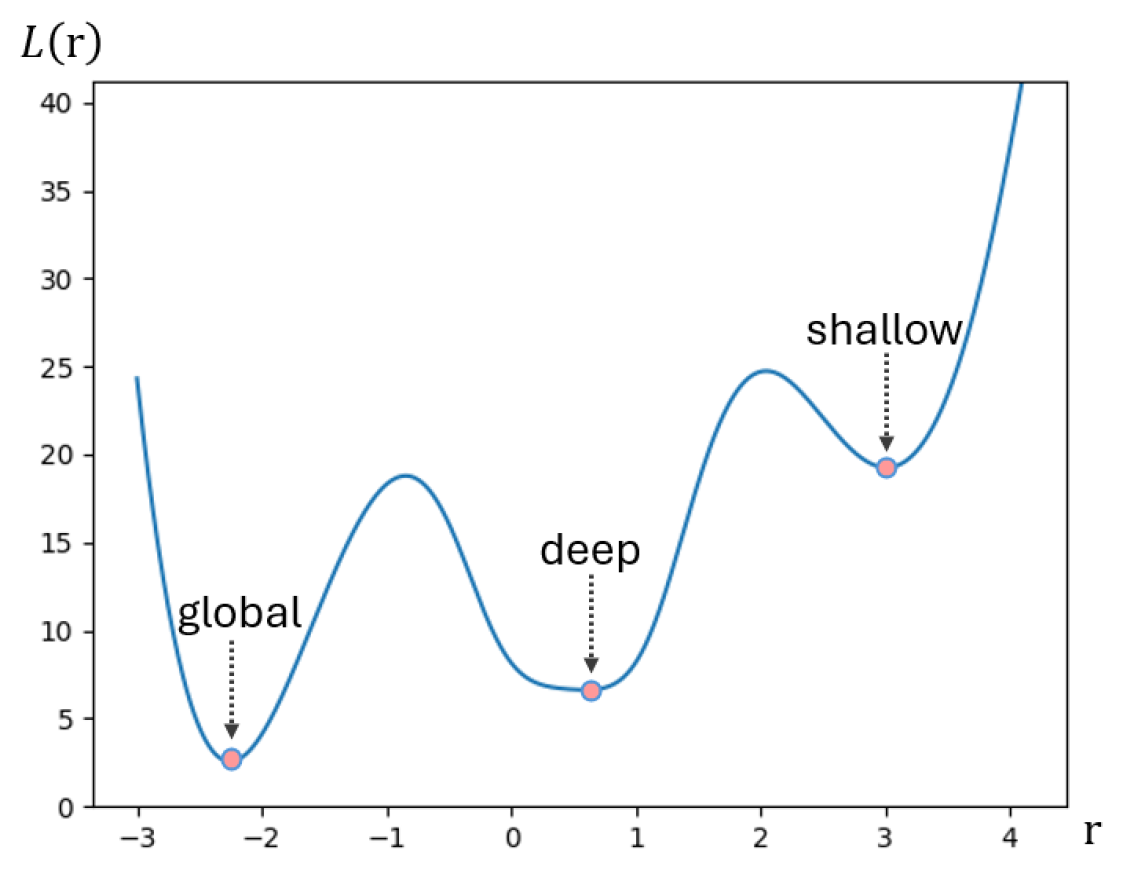
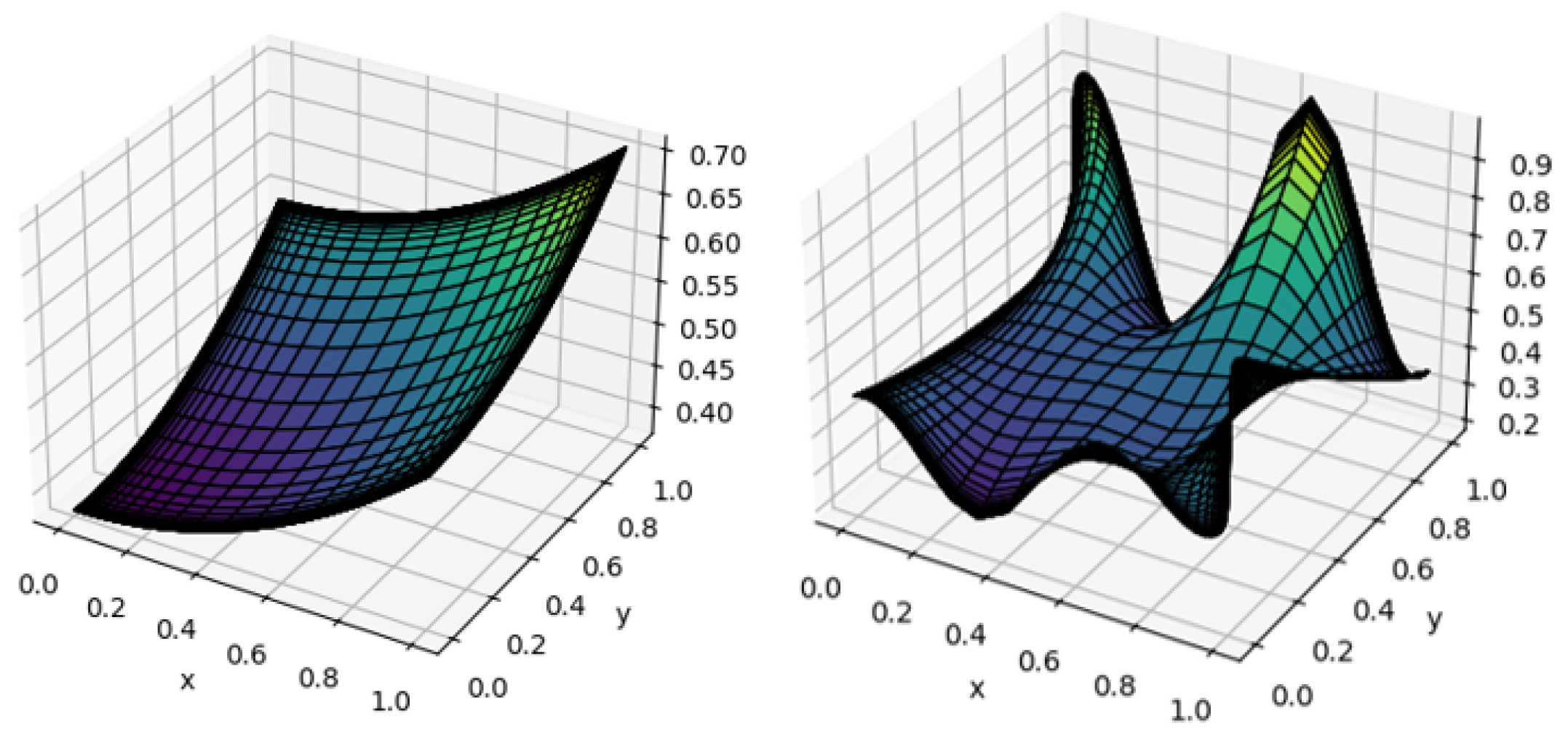
- We introduce the concept of local attraction as a means of producing architectures whose training can reach deep local minima of many loss functions.
- b.
- We develop ULA as a first example of an architecture that satisfies local attraction given the mild conditions summarized in Section 6.3.
- c.
- We experimentally demonstrate the ability of ULA to find deep minima on training losses, as indicated by improvements compared to performant GNNs in new tasks.
2. Background
2.1. Graph Filters
2.2. Graph Neural Networks
2.3. Universal Approximation of AGFs
2.4. Symbols
3. One-Dimensional Local Attraction
3.1. Problem Statement
3.2. Local Attractors for One-Dimensional Node Features in One Graph
3.3. Attraction across Multiple Graphs
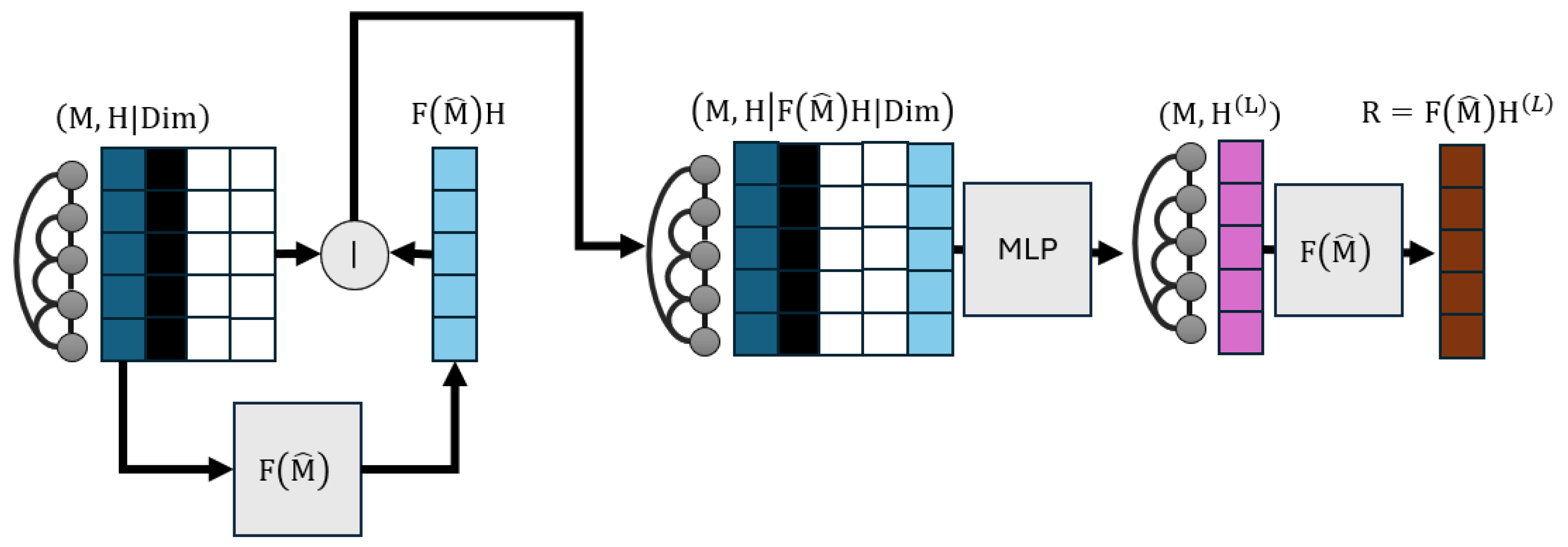
4. Universal Local Attractor
4.1. Multidimensional Universal Attraction
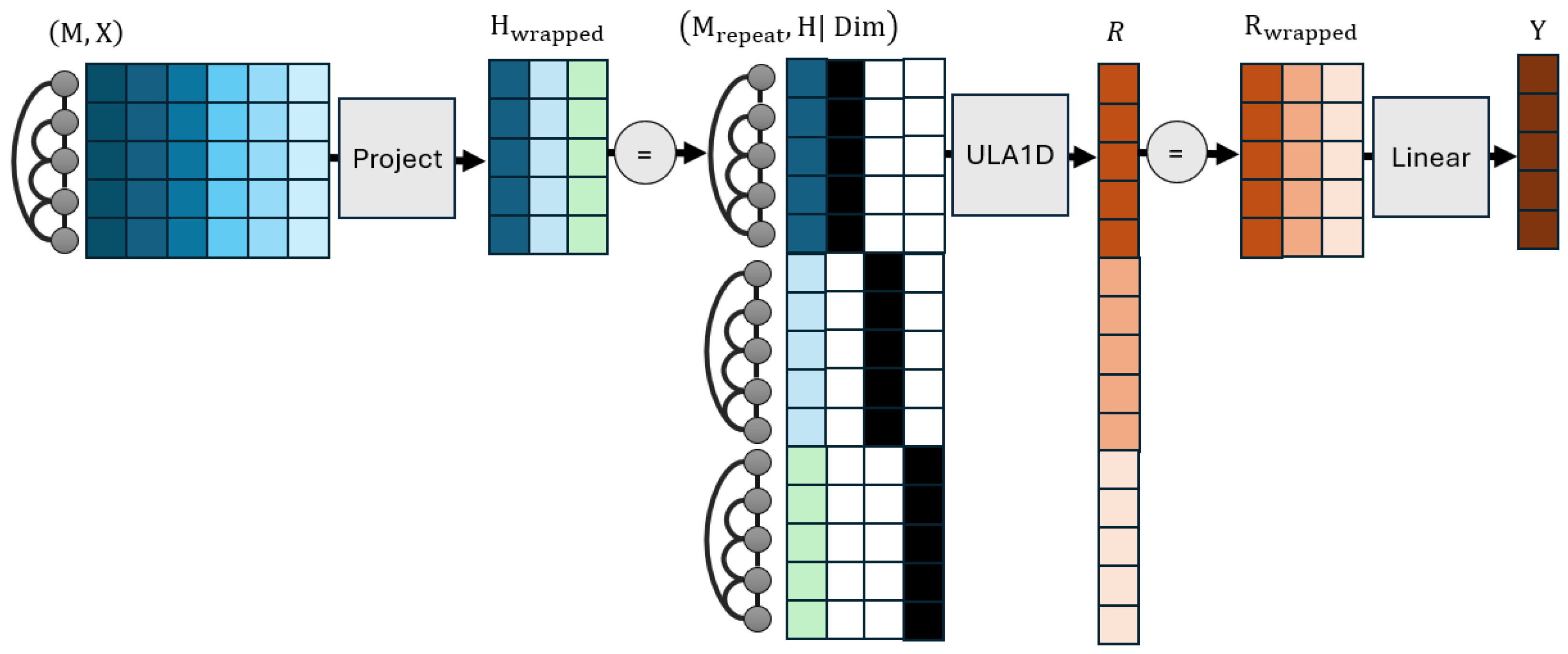
4.2. Different Node Feature and Prediction Dimensions
4.3. Implementation Details
- a.
- The output of ULA1D should be divided by 2 when the parameter initialization strategy of relu-activated layers is applied everywhere. This is needed to preserve input–output variance, given that there is an additional linear layer on top. This is not a hyperparameter. Contrary to the partial robustness to different variances exhibited by typical neural networks, having different variances between the input and output may mean that the original output starts from “bad” local minima, from which it may even fail to escape. In the implementation we experiment with later, failing to perform this division makes training become stuck near the architecture’s initialization.
- b.
- Dropout can only be applied before the output’s linear transformation. We recognize that dropout is a necessary requirement for architectures to generalize well, but it cannot be applied on input features due to the sparsity of the representation, and it cannot be applied on the transformation due to breaking any (approximate) invertibility that is being learned.
- c.
- Address the issue of dying neurons for ULA1D. Due to the few feature dimensions of this architecture, it is likely for all activations to become zero and make the architecture stop learning from certain samples from the beginning of training with randomly initialized parameters. In this work, we address this issue by employing a leaky relu as the activation function in place of . This change does not violate universal approximation results that we enlist. As per Theorem A3, activation functions should remain Lipschitz and have Lipschitz derivatives almost everywhere; both properties are satisfied by .
- d.
- Adopt a late stopping training strategy that repeats training epochs until both training and validation losses do not decrease for a number of epochs. This strategy lets training overcome saddle points where ULA creates a small derivative. For a more thorough discussion of this phenomenon refer to Section 6.2.
- e.
- Retain linear input and output transformations, and do not apply feature dropout. We previously mentioned the necessity of the first stipulation, but the second is also needed to maintain Lipschitz loss derivatives for the internal ULA1D architecture.
4.4. Running Time and Memory
5. Experiments
5.1. Tasks
- Degree. Learning to count the number of neighbors of each node. Nodes are provided with a one-hot encoding of their identifiers within the graph, which is a non-equivariant input that architectures need to learn to transfer to equivariant objectives. We do not experiment with variations (e.g., other types of node encodings) that are promising for the improvement of predictive efficacy, as this is a basic go-to strategy and our goal is not—in this work—to find the best architectures but instead assess local attractiveness. To simplify the experiment setup, we converted this discretized task into a classification one, where node degrees are the known classes.
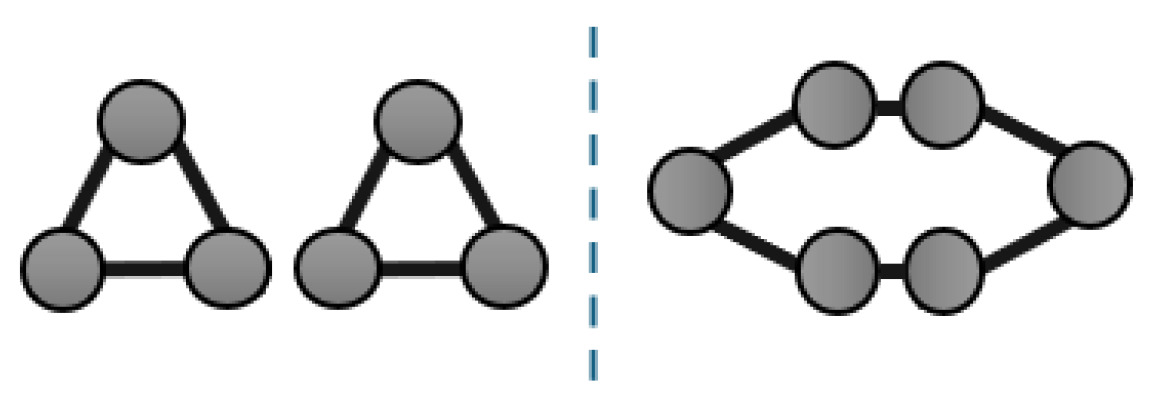
- Triangle. Learning to count the number of triangles. Similarly to before, nodes are provided with a one-hot encoding of their identifiers within the graph, and we convert this discretized task into a classification one, where the node degrees observed in the training set are the known classes.
- 4Clique. Learning to identify whether each node belongs to a clique of at least four members. Similarly to before, nodes are provided with a one-hot encoding of their identifiers within the graph. Detecting instead of counting cliques yields a comparable number of nodes between the positive and negative outcome, so as to avoid complicating assessment that would need to account for class imbalances. We further improve class balance with a uniformly random number of a chance of linking nodes. Due to the high computational complexity of creating the training dataset, we restrict this task only to graphs with a uniformly random number of nodes.
- LongShort. Learning the length of the longest among the shortest paths from each node to all others. Similarly to before, nodes are provided with a one-hot encoding of their identifiers within the graph, and we convert this discretized task into a classification one, where path lengths in training data are the known classes.
- Propagate. This task aims to relearn the classification of an APPNP architecture with randomly initialized weights and uniformly random (the same for all graphs) that is applied on nodes with 16 feature dimensions, uniformly random features in the range , and four output classes. This task effectively assesses our ability to reproduce a graph algorithm. It is harder than the node classification settings below in that features are continuous.
- 0.9Propagate. This is the same as the previous task but with fixed . Essentially, this is perfectly replicable by APPNP because the latter uses the same architecture with the same hyperparameters (, layer dimensions, number of dense layers, number of propagation steps) and only needs to find the same randomly initialized layer weights. Hence, any failure of APPNP in finding deep minima for this task should be attributed to the need for better optimization strategies.
- Diffuse. This is the same task as above, with the difference that the aim is to directly replicate output scores in the range for each of the four output dimensions (these are not soft-maximized).
- 0.9Diffuse. This is the same as the previous task with fixed . Similarly to 0.9Propagate, this task is in theory perfectly replicable by APPNP.
- Cora [31]. A graph that comprises 2708 nodes and 57,884 edges. Its nodes exhibit 3703 feature dimensions and are classified into one among seven classes.
- Citeseer [32]. A graph that comprises 3327 nodes and 10,556 edges. Its nodes exhibit 1433 feature dimensions and are classified into one among six classes.
- Pubmed [33]. A graph that comprises 19,717 nodes and 88,651 edges. Its nodes exhibit 500 feature dimensions and are classified into one among three classes.
5.2. Compared Architectures
- MLP. A two-layer perceptron that does not leverage any graph information. We use this as a baseline to measure the success of graph learning.
- GAT [13]. A gated attention network that learns to construct edge weights based on the representations at each edge’s ends, and uses the weights to aggregate neighbor representations.
- GCNII [34]. An attempt to create a deeper variant of GCN that is explicitly designed to be able to replicate the diffusion processes of graph filters if needed. We employ the variation with 64 layers.
- APPNP [8]. The predict-then-propagate architecture with ppr base filter. Switching to different filters lets this approach maintain roughly similar performance, and we opt for its usage due to it being a standard player in GNN evaluation methodologies.
- ULA [this work]. Our universal local attractor presented in this work. Motivated by the success of APPNP on node classification tasks, we also adopt the first 10 iterations of personalized PageRank as the filter of choice, and leave further improvements by tuning the filter to future work.
- GCNNRI. This is the GCN-like MPNN introduced by Abboud et al. [24]; it employs random node representations to admit greater (universal approximation) expressive power and serves as a state-of-the-art baseline. We adopt its publicly available implementation, which first transforms features through two GCN layers of Equation (2) and concatenates them with a feature matrix of equal dimensions sampled anew in each forward pass. Afterwards, GCNNRI applies three more GCN layers and then another three-layered MLP. The original architecture max-pooled node-level predictions before the last MLP to create an invariant output (i.e., one prediction for each graph), but we do not perform this to accommodate our experiment settings by retaining equivariance, and therefore, create a separate prediction for each node. We employ the variation that replaces half of the node feature dimensions with random representations.
5.3. Evaluation Methodology
- Training process. For synthetically generated datasets, we create a 50%–25%–25% train–validation–test split across graphs, of which the training and validation graphs are, respectively, used to train the architecture, and to avoid overtraining by selecting parameters with minimal validation loss. For real-world graphs, we create an evaluation split that avoids class imbalance in the training set, and for this reason we perform stratified sampling to obtain 50, 50 validation, and 100 test nodes. In all settings, training epochs repeat until neither training nor validation loss decrease for a patience of 100 consecutive epochs. We retain parameter values corresponding to the best validation loss. We allow decreases in training losses to reset the stopping patience in order to prevent architectures from becoming stuck in shallow minima, especially at the beginning of training. This increases the training time of architectures to requiring up to 6000 epochs in some settings, but in return tends to find much deeper minima when convergence is slower. A related discussion is presented in Section 6.2. For classification tasks, including counting tasks where the output is an integer, the loss function is categorical cross-entropy after applying softmax activation on each architecture’s outputs. For regression tasks, the loss function is the mean absolute error.
- Predictive performance. For all settings, we measure either accuracy (acc; larger is better) or mean absolute error (mabs; smaller is better) and compute their average across five experiment repetitions. We report these quantities instead of the loss because we aim to create practically useful architectures that can accurately approximate a wide range of AGF objectives. Evaluation that directly considers loss function values is even more favorable for our approach (see Section 6), though of limited practical usefulness. Since we are making a comparison between several architectures, we also compute Nemenyi ranks; for each experiment repetition, we rank architectures based on which is better (rank 1 is the best, rank 2 the second best, and so on) and average these across each task’s repetition, and afterwards across all tasks. In the end, we employ the Friedman test to reject the null hypothesis that architectures are the same at the 0.05 p-value level, and then, check for statistically significant differences at the 0.05 p-value level between every architecture and ULA with the two-tailed Bonferroni–Dunn test [35], which Demsar [36] sets up as a stronger variant of the Nemenyi test [37]. For our results of comparisons and seven compared methods, the test has critically difference rounded up; rank differences of this value or greater are considered statistically significant. We employ the Bonferroni–Dunn test because it is both strong and easy to intuitively understand.
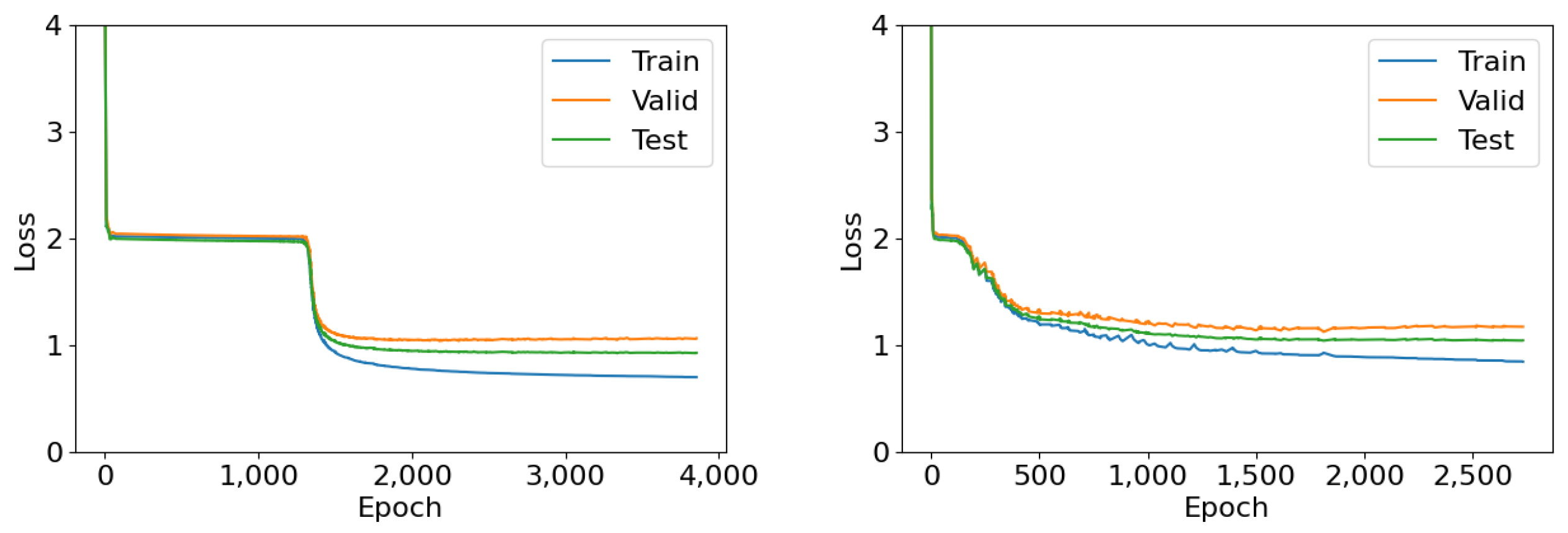
- Assessing minimization capabilities. To check whether we succeed in our main goal of finding deep minima, we also replicate experiments by equalizing training, validation, and test sets and investigating how well architectures can replicate the AGFs they are meant to reproduce. That is, we investigate the ability of architectures to either overtrain, as this is a key property of universal approximation or, failing that, to universally minimize objectives. Note that success in this type of evaluation (i.e., success in overtraining) is the property we are mainly interested in this work, as it remains an open question for GNNs. The measured predictive performance mainly lets us see how well the learned AGFs generalize.
- Hyperparameter selection. To maintain a fair comparison between the compared architectures, we employ the same hyperparameters for the same conceptually similar choices by repeating common defaults across the GNN literature. In particular, we use the same number of 64 output dimensions for each trained linear layer. We also use an 0.6 dropout rate for node features in all outputs of 64-layer representations except for ULA’s input and output layers, which do not accept dropout. For GAT, we use the number of attention heads tuned on the Cora dataset, which is eight. All architectures are also trained using the Adam optimizer with learning rate 0.01 (this is the commonly accepted default for GNNs) and use default values for other parameters. For all other choices, like diffusion rates, we defer to architecture defaults. We initialize dense parameters with Kaiming initialization [38]. Due to already high computational demands, we did not perform extensive hyperparameter tuning, other than a simple verification that statistically significant changes could not be induced for both the Degree and Cora tasks (we selected these as conceptually simple) by modifying parameters or injecting or removing layers. In Section 6.4, we explain why this is not a substantial threat to the validity of the evaluation outcomes.
5.4. Experiment Results
6. Discussion
6.1. Limitations of Cross-Entropy
6.2. Convergence Speed and Late Stopping
6.3. Requirements to Apply ULA
- a.
- The first condition is that processed graphs should be unweighted and undirected. Normalizing adjacency matrices is accepted (we perform this in experiments—in fact it is necessary to obtain the spectral graph filters we work with), but structurally isomorphic graphs should obtain the same edge weights after normalization; otherwise, Theorem A3 cannot hold in its present form. Future theoretical analysis can consider discretizing edge weights to obtain more powerful results.
- b.
- Furthermore, loss functions and output activations should be twice-differentiable, and each of their gradient dimensions should be Lipschitz. Our results can be easily extended to differentiable losses with continuous non-infinite gradients by framing their linearization needed by Theorem A1 as a locally Lipschitz derivative. However, more rigorous analysis is needed to extend results to non-differentiable losses, even when these are differentiable almost everywhere.
- c.
- Lipschitz continuity of loss and activation derivatives is typically easy to satisfy, as any Lipschitz constant is acceptable. That said, higher constant values are expected to create architectures that are harder to train, as they require more fine-grained discretization to separate between graphs with similar attributes. Note that the output activation is considered part of the loss in our analysis, which can drastically simplify matters. Characteristically, passing softmax activation through a categorical cross-entropy loss is known to create gradients equal to the difference between predictions and true labels, which is a 1-Lipschitz function, and therefore, accepts ULA. Furthermore, having no activation with mabs or L2 loss is admissible in regression strategies, as this loss has a 1-Lipschitz derivative. However, employing higher powers of score differences or KL-divergence is not acceptable, as their second derivatives are unbounded, and thus, their first derivatives are not Lipschitz.
- d.
- Finally, ULA admits powerful minimization strategies but requires positional encodings to exhibit stronger expressive power. To this end, we suggest following progress in the respective literature.
6.4. Threats to Validity
7. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Terminology
- Boundedness. This is a property of quantities that admit a fixed upper numerical bound, matrices whose elements are bounded, or functions that output bounded values.
- Closure. Closed sets are those that include all their limiting points. For example, a real-valued closed set that contains open intervals also includes their limit points .
- Compactness. We use the sequential definition of compactness, for which compact sets are closed and bounded.
- Connectivity. This is a property of sets that cannot be divided into two disjoint non-empty open subsets. Equivalently, all continuous functions from connected sets to are constant.
- Density. In the text we often claim that a space A is dense in a set B. The spaces often contain functions, in which case we consider a metric the worst deviation under any input, which sets up density as the universal approximation property of being able to find members of A that lie arbitrarily close to any desired elements of B.
- Lipschitz continuity. We refer to multivariate multi-value functions as c-Lipschitz if they satisfy the property for some chosen p-norm . Throughout this work, we consider this property for the norm , which computes the maximum of absolute values. If a Lipschitz function is differentiable, then it is c-Lipschitz only if . If two functions are Lipschitz, their composition and sum are also Lipschitz. If they are additionally bounded, their product is also Lipschitz.
Appendix B. Theoretical Proofs
Appendix C. Algorithmic Complexity
Appendix D. ULA as an MPNN
References
- Loukas, A. What graph neural networks cannot learn: Depth vs width. arXiv 2019, arXiv:1907.03199. [Google Scholar]
- Nguyen, Q.; Mukkamala, M.C.; Hein, M. On the loss landscape of a class of deep neural networks with no bad local valleys. arXiv 2018, arXiv:1809.10749. [Google Scholar]
- Sun, R.Y. Optimization for deep learning: An overview. J. Oper. Res. Soc. China 2020, 8, 249–294. [Google Scholar] [CrossRef]
- Bae, K.; Ryu, H.; Shin, H. Does Adam optimizer keep close to the optimal point? arXiv 2019, arXiv:1911.00289. [Google Scholar]
- Ortega, A.; Frossard, P.; Kovačević, J.; Moura, J.M.; Vandergheynst, P. Graph signal processing: Overview, challenges, and applications. Proc. IEEE 2018, 106, 808–828. [Google Scholar] [CrossRef]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The Pagerank Citation Ranking: Bringing Order to the Web. 1999. Available online: https://www.semanticscholar.org/paper/The-PageRank-Citation-Ranking-%3A-Bringing-Order-to-Page-Brin/eb82d3035849cd23578096462ba419b53198a556 (accessed on 1 April 2024).
- Chung, F. The heat kernel as the pagerank of a graph. Proc. Natl. Acad. Sci. USA 2007, 104, 19735–19740. [Google Scholar] [CrossRef]
- Gasteiger, J.; Bojchevski, A.; Günnemann, S. Predict then propagate: Graph neural networks meet personalized pagerank. arXiv 2018, arXiv:1810.05997. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural message passing for quantum chemistry. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1263–1272. [Google Scholar]
- Balcilar, M.; Héroux, P.; Gauzere, B.; Vasseur, P.; Adam, S.; Honeine, P. Breaking the limits of message passing graph neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 599–608. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. Stat 2017, 1050, 10–48550. [Google Scholar]
- Cai, J.Y.; Fürer, M.; Immerman, N. An optimal lower bound on the number of variables for graph identification. Combinatorica 1992, 12, 389–410. [Google Scholar] [CrossRef]
- Maron, H.; Ben-Hamu, H.; Serviansky, H.; Lipman, Y. Provably powerful graph networks. Adv. Neural Inf. Process. Syst. 2019, 32, 2153–2164. [Google Scholar]
- Morris, C.; Ritzert, M.; Fey, M.; Hamilton, W.L.; Lenssen, J.E.; Rattan, G.; Grohe, M. Weisfeiler and leman go neural: Higher-order graph neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January 2019–1 February 2019; Volume 33, pp. 4602–4609. [Google Scholar]
- Zaheer, M.; Kottur, S.; Ravanbakhsh, S.; Poczos, B.; Salakhutdinov, R.R.; Smola, A.J. Deep sets. Adv. Neural Inf. Process. Syst. 2017, 30, 3391–3401. [Google Scholar]
- Keriven, N.; Peyré, G. Universal invariant and equivariant graph neural networks. Adv. Neural Inf. Process. Syst. 2019, 32, 7092–7101. [Google Scholar]
- Maron, H.; Fetaya, E.; Segol, N.; Lipman, Y. On the universality of invariant networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 4363–4371. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How powerful are graph neural networks? arXiv 2018, arXiv:1810.00826. [Google Scholar]
- Wang, H.; Yin, H.; Zhang, M.; Li, P. Equivariant and stable positional encoding for more powerful graph neural networks. arXiv 2022, arXiv:2203.00199. [Google Scholar]
- Keriven, N.; Vaiter, S. What functions can Graph Neural Networks compute on random graphs? The role of Positional Encoding. Adv. Neural Inf. Process. Syst. 2024, 36, 11823–11849. [Google Scholar]
- Sato, R.; Yamada, M.; Kashima, H. Random features strengthen graph neural networks. In Proceedings of the 2021 SIAM International Conference on Data Mining (SDM), SIAM, Virtual, 29 April–1 May 2021; pp. 333–341. [Google Scholar]
- Abboud, R.; Ceylan, I.I.; Grohe, M.; Lukasiewicz, T. The surprising power of graph neural networks with random node initialization. arXiv 2020, arXiv:2010.01179. [Google Scholar]
- Krasanakis, E.; Papadopoulos, S.; Kompatsiaris, I. Applying fairness constraints on graph node ranks under personalization bias. In Complex Networks & Their Applications IX: Volume 2, Proceedings of the Ninth International Conference on Complex Networks and Their Applications Complex Networks, Madrid, Spain, 1–3 December 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 610–622. [Google Scholar]
- Kidger, P.; Lyons, T. Universal approximation with deep narrow networks. In Proceedings of the Conference on Learning Theory, PMLR, Graz, Austria, 9–12 July 2020; pp. 2306–2327. [Google Scholar]
- Hoang, N.; Maehara, T.; Murata, T. Revisiting graph neural networks: Graph filtering perspective. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 8376–8383. [Google Scholar]
- Huang, Q.; He, H.; Singh, A.; Lim, S.N.; Benson, A.R. Combining Label Propagation and Simple Models Out-performs Graph Neural Networks. arXiv 2020, arXiv:2010.13993. [Google Scholar]
- Zhou, D.; Bousquet, O.; Lal, T.; Weston, J.; Schölkopf, B. Learning with local and global consistency. Adv. Neural Inf. Process. Syst. 2003, 16, 321–328. [Google Scholar]
- Fey, M.; Lenssen, J.E. Fast graph representation learning with PyTorch Geometric. arXiv 2019, arXiv:1903.02428. [Google Scholar]
- Bojchevski, A.; Günnemann, S. Deep gaussian embedding of graphs: Unsupervised inductive learning via ranking. arXiv 2017, arXiv:1707.03815. [Google Scholar]
- Sen, P.; Namata, G.; Bilgic, M.; Getoor, L.; Galligher, B.; Eliassi-Rad, T. Collective classification in network data. AI Mag. 2008, 29, 93. [Google Scholar] [CrossRef]
- Namata, G.; London, B.; Getoor, L.; Huang, B.; Edu, U. Query-driven active surveying for collective classification. In Proceedings of the Workshop on Mining and Learning with Graphs (MLG-2012), Edinburgh, UK, 1 July 2012; Volume 8, p. 1. [Google Scholar]
- Chen, M.; Wei, Z.; Huang, Z.; Ding, B.; Li, Y. Simple and deep graph convolutional networks. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 1725–1735. [Google Scholar]
- Dunn, O.J. Multiple comparisons among means. J. Am. Stat. Assoc. 1961, 56, 52–64. [Google Scholar] [CrossRef]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Hollander, M.; Wolfe, D.A.; Chicken, E. Nonparametric Statistical Methods; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Nunes, M.; Fraga, P.M.; Pappa, G.L. Fitness landscape analysis of graph neural network architecture search spaces. In Proceedings of the Genetic and Evolutionary Computation Conference, Lille, France, 10–14 July 2021; pp. 876–884. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Interpretation |
|---|---|
| The set of all AGFs | |
| A GNN architecture function with parameters | |
| An attributed graph with adjacency M and features | |
| The node feature matrix predicted by on attributed graph | |
| M | A graph adjacency matrix |
| A finite or infinite set of attributed graphs | |
| Gradients of a loss computed at | |
| A normalized version of a graph adjacency matrix | |
| A graph filter of a normalized graph adjacency matrix; it is itself a matrix | |
| X | A node feature matrix |
| Y | A node prediction matrix of a GNN |
| R | A node output matrix of ULA1D |
| H | A node representation matrix, often procured as a transformation of node features |
| A loss function defined over AGFs A | |
| A loss function defined over attributed graphs for node prediction matrix Y | |
| Node representation matrix at layer ℓ of some architecture; nodes are rows | |
| Learnable dense transformation weights at layer ℓ of a neural architecture | |
| Learnable biases at layer ℓ of a neural architecture | |
| Activation function at layer ℓ of a neural architecture | |
| The number of columns of matrix | |
| The integer ceiling of real number x | |
| The number of set elements | |
| The set of a graph’s nodes | |
| The set of a graph’s edges | |
| A domain in which some optimization takes place | |
| Parameters leading to local optimum | |
| A connected neighborhood of | |
| A graph signal prior from which optimization starts | |
| A locally optimal posterior graph signal of some loss | |
| The L2 norm | |
| The maximum element | |
| Horizontal matrix concatenation | |
| Vertical matrix concatenation | |
| Multilayer perceptron with trainable parameters |
| Task | Eval. | MLP | GCN [12] | APPNP [8] | GAT [13] | GCNII [34] | GCNNRI [24] | ULA |
|---|---|---|---|---|---|---|---|---|
| Generalization | ||||||||
| Degree | acc ↑ | 0.162 (5.6) | 0.293 (2.8) | 0.160 (6.2) | 0.166 (5.6) | 0.174 (4.6) | 0.473 (2.0) | 0.541 (1.2) |
| Triangle | acc ↑ | 0.522 (5.2) | 0.523 (3.6) | 0.522 (5.2) | 0.522 (5.2) | 0.522 (5.2) | 0.554 (2.4) | 0.568 (1.2) |
| 4Clique | acc ↑ | 0.678 (4.9) | 0.708 (4.1) | 0.677 (6.2) | 0.678 (4.9) | 0.678 (4.9) | 0.846 (2.0) | 0.870 (1.0) |
| LongShort | acc ↑ | 0.347 (5.8) | 0.399 (3.0) | 0.344 (6.4) | 0.350 (4.2) | 0.348 (5.6) | 0.597 (2.0) | 0.653 (1.0) |
| Diffuse | mabs ↓ | 0.035 (4.0) | 0.032 (2.8) | 0.067 (7.0) | 0.035 (5.0) | 0.037 (6.0) | 0.030 (2.2) | 0.012 (1.0) |
| 0.9Diffuse | mabs ↓ | 0.021 (4.6) | 0.015 (3.0) | 0.034 (7.0) | 0.021 (4.4) | 0.021 (6.0) | 0.009 (1.8) | 0.007 (1.2) |
| Propagate | acc ↑ | 0.531 (2.6) | 0.501 (4.0) | 0.510 (3.6) | 0.455 (6.1) | 0.443 (6.9) | 0.503 (3.8) | 0.861 (1.0) |
| 0.9Propagate | acc ↑ | 0.436 (5.3) | 0.503 (3.0) | 0.452 (4.0) | 0.418 (5.8) | 0.401 (6.7) | 0.546 (2.2) | 0.846 (1.0) |
| Cora | acc ↑ | 0.683 (6.6) | 0.855 (4.2) | 0.866 (1.4) | 0.850 (4.1) | 0.863 (2.4) | 0.696 (6.4) | 0.859 (2.9) |
| Citeseer | acc ↑ | 0.594 (6.0) | 0.663 (3.9) | 0.676 (2.3) | 0.661 (4.0) | 0.679 (1.8) | 0.443 (7.0) | 0.669 (3.0) |
| Pubmed | acc ↑ | 0.778 (6.4) | 0.825 (3.7) | 0.835 (2.0) | 0.821 (4.0) | 0.835 (2.1) | 0.747 (6.6) | 0.829 (3.2) |
| Average (CD = 1.1) | (5.2) | (3.5) | (4.7) | (4.8) | (4.7) | (3.5) | (1.6) | |
| Deepness (overtraining capability) | ||||||||
| Degree | acc ↑ | 0.172 (5.7) | 0.331 (3.0) | 0.170 (6.6) | 0.175 (5.7) | 0.186 (4.0) | 0.632 (1.2) | 0.571 (1.8) |
| Triangle | acc ↑ | 0.510 (4.7) | 0.510 (4.2) | 0.510 (4.7) | 0.510 (4.7) | 0.510 (4.7) | 0.536 (3.8) | 0.568 (1.2) |
| 4Clique | acc ↑ | 0.665 (5.0) | 0.779 (3.0) | 0.657 (6.4) | 0.665 (5.0) | 0.663 (5.6) | 0.898 (1.4) | 0.894 (1.6) |
| LongShort | acc ↑ | 0.347 (6.0) | 0.391 (3.0) | 0.347 (6.0) | 0.351 (4.0) | 0.347 (6.0) | 0.588 (2.0) | 0.688 (1.0) |
| Diffuse | mabs ↓ | 0.032 (4.4) | 0.028 (3.0) | 0.061 (7.0) | 0.032 (4.6) | 0.033 (6.0) | 0.026 (2.0) | 0.012 (1.0) |
| 0.9Diffuse | mabs ↓ | 0.021 (4.6) | 0.015 (3.0) | 0.034 (7.0) | 0.021 (4.4) | 0.021 (6.0) | 0.009 (1.8) | 0.007 (1.2) |
| Propagate | acc ↑ | 0.477 (4.2) | 0.502 (2.4) | 0.454 (4.4) | 0.461 (4.9) | 0.413 (6.6) | 0.503 (4.5) | 0.844 (1.0) |
| 0.9Propagate | acc ↑ | 0.493 (4.8) | 0.527 (2.8) | 0.534 (3.2) | 0.444 (6.3) | 0.451 (6.5) | 0.534 (3.4) | 0.873 (1.0) |
| Cora | acc ↑ | 0.905 (5.6) | 0.914 (3.2) | 0.905 (5.4) | 0.911 (3.8) | 0.864 (7.0) | 0.930 (2.0) | 0.996 (1.0) |
| Citeseer | acc ↑ | 0.865 (2.2) | 0.818 (3.8) | 0.794 (6.0) | 0.808 (5.0) | 0.767 (7.0) | 0.849 (3.0) | 0.959 (1.0) |
| Pubmed | acc ↑ | 0.868 (3.8) | 0.871 (2.0) | 0.862 (5.2) | 0.855 (6.8) | 0.859 (6.0) | 0.869 (3.2) | 0.956 (1.0) |
| Average (CD = 1.1) | (4.2) | (3.0) | (5.6) | (5.0) | (6.0) | (2.6) | (1.2) | |
| loss (↓) | acc (↑) | |||||
|---|---|---|---|---|---|---|
| Train | Valid | Test | Train | Valid | Test | |
| MLP | 0.113 (min 0.103) | 1.061 | 1.059 | 1.000 | 0.657 | 0.659 |
| GCN | 0.198 (min 0.194) | 0.541 | 0.564 | 0.986 | 0.863 | 0.860 |
| APPNP | 0.288 (min 0.284) | 0.544 | 0.563 | 0.971 | 0.869 | 0.860 |
| GAT | 0.261 (min 0.254) | 0.546 | 0.574 | 0.983 | 0.866 | 0.854 |
| GCNII | 0.425 (min 0.423) | 0.656 | 0.668 | 0.951 | 0.866 | 0.849 |
| GCNNRI | 0.262 (min 0.015) | 0.839 | 0.936 | 0.929 | 0.789 | 0.759 |
| ULA | 0.161 (min 0.007) | 0.479 | 0.890 | 0.974 | 0.854 | 0.846 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krasanakis, E.; Papadopoulos, S.; Kompatsiaris, I. Universal Local Attractors on Graphs. Appl. Sci. 2024, 14, 4533. https://doi.org/10.3390/app14114533
Krasanakis E, Papadopoulos S, Kompatsiaris I. Universal Local Attractors on Graphs. Applied Sciences. 2024; 14(11):4533. https://doi.org/10.3390/app14114533
Chicago/Turabian StyleKrasanakis, Emmanouil, Symeon Papadopoulos, and Ioannis Kompatsiaris. 2024. "Universal Local Attractors on Graphs" Applied Sciences 14, no. 11: 4533. https://doi.org/10.3390/app14114533
APA StyleKrasanakis, E., Papadopoulos, S., & Kompatsiaris, I. (2024). Universal Local Attractors on Graphs. Applied Sciences, 14(11), 4533. https://doi.org/10.3390/app14114533