


A Few-Shot Object Detection Method for Endangered Species


Abstract
1. Introduction
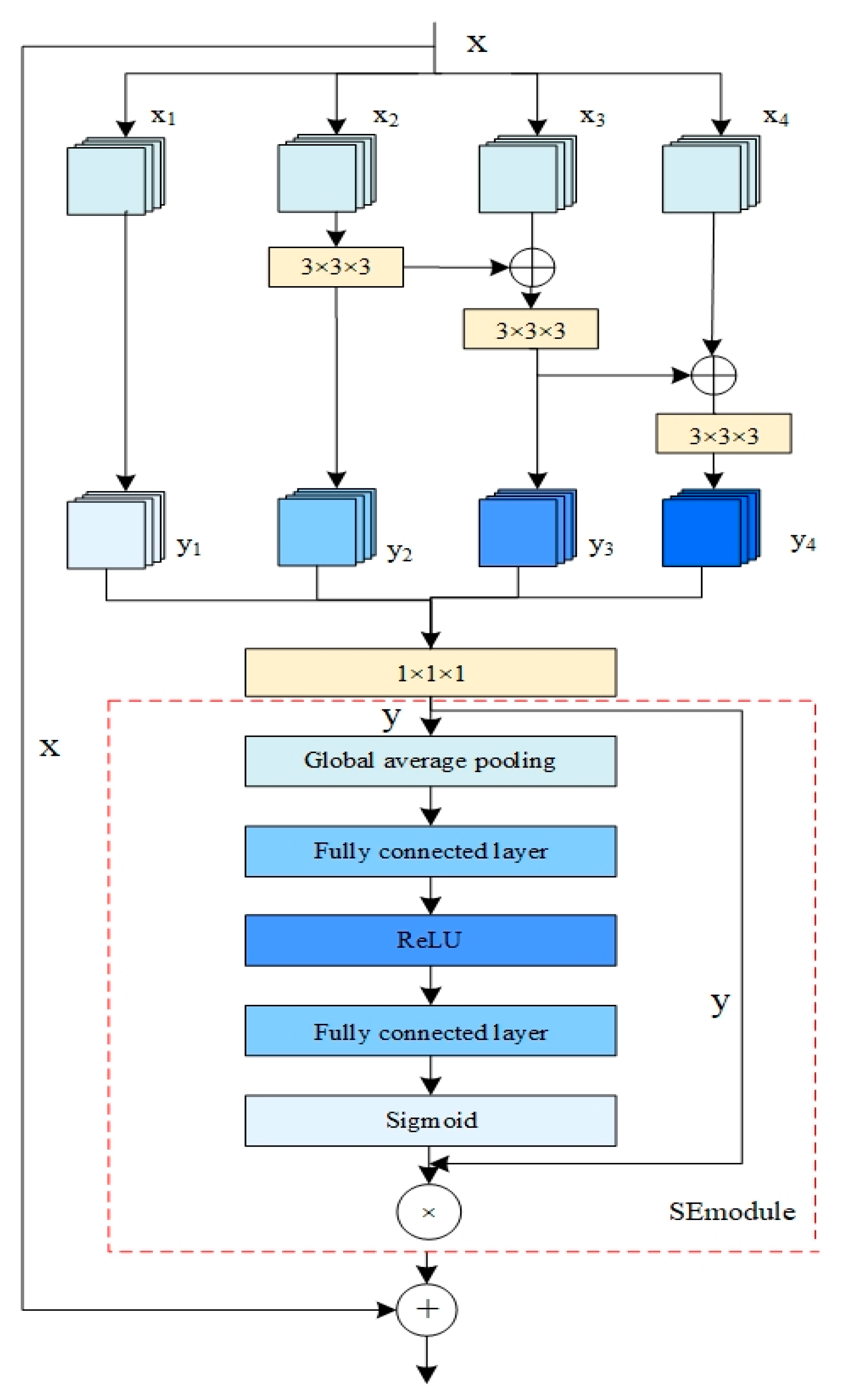
- Improve the feature extraction network by adopting Res2Net, which has stronger fine-grained expression ability, and introduce Squeeze-and-Excitation Network (SENet) to solve the problem of inter-channel correlation reduction caused by channel grouping;
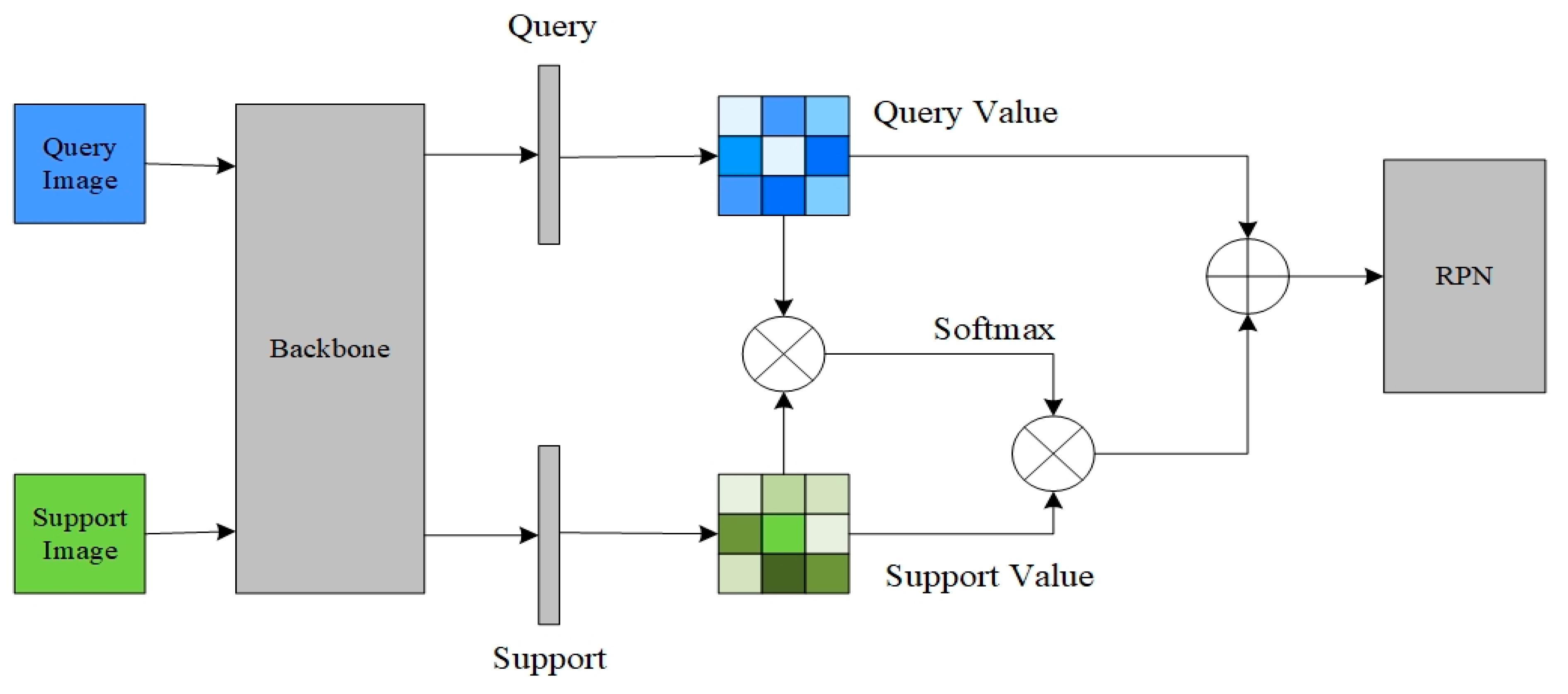
- Introducing Convolutional Block Attention Module (CBAM) between the feature extraction network and the RPN, which assigns different weights to different features to optimize the feature expression. The attention feature maps obtained through deep inter-correlation are input into the RPN network to generate more accurate object suggestion frames;
- Introducing a few-shot object detection scheme based on weighted prototype comparison branching and constructing weighted category prototype vectors using category prototype metric idea. By calculating the cosine similarity between the category prototypes and the query image, the performance of the original classifier is effectively improved;
- We demonstrate the effectiveness of this method from different perspectives and achieve good detection accuracy on the Pascal VOC and endangered species datasets.
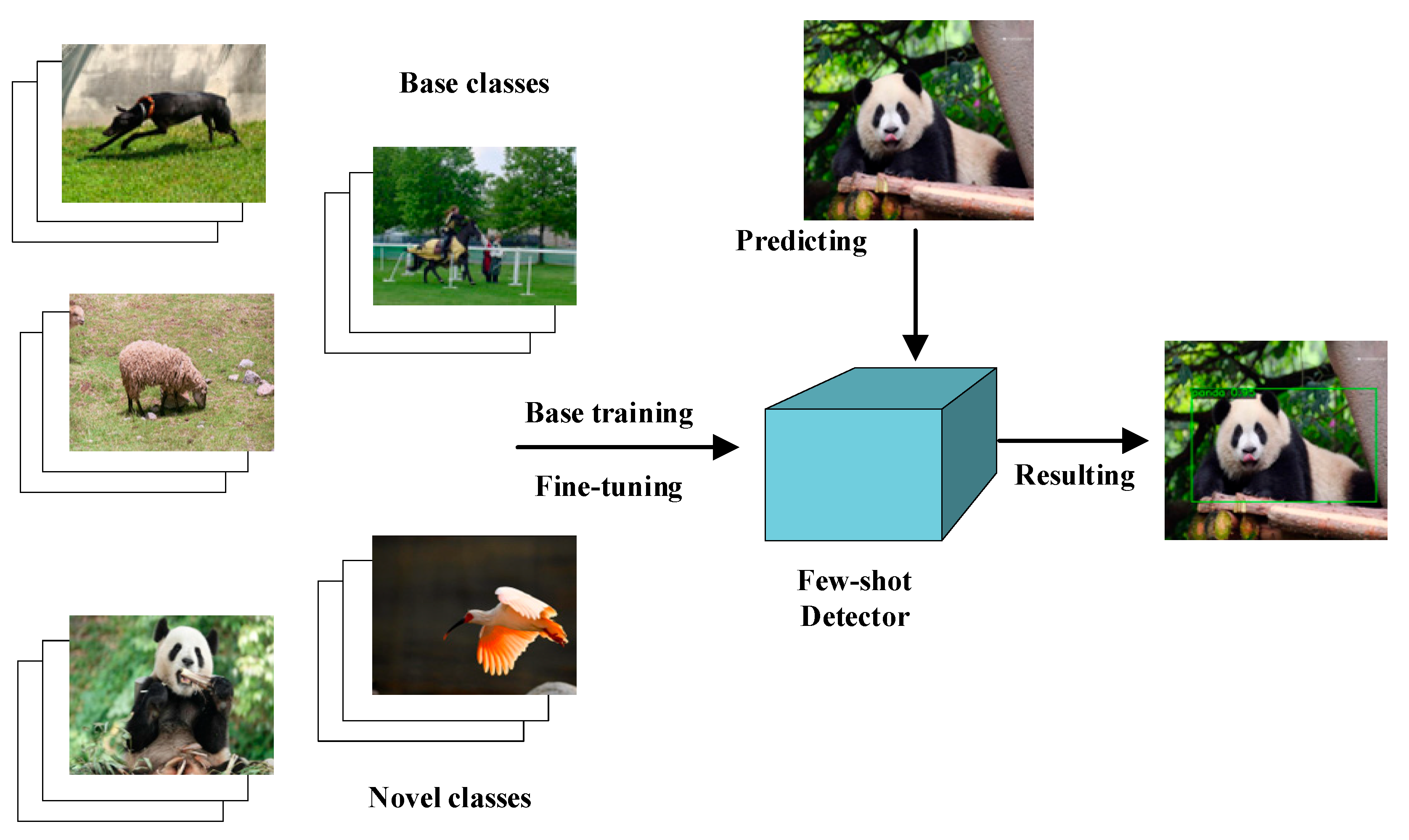
2. Fine-Tuning-Based Few-Shot Object Detection Algorithm
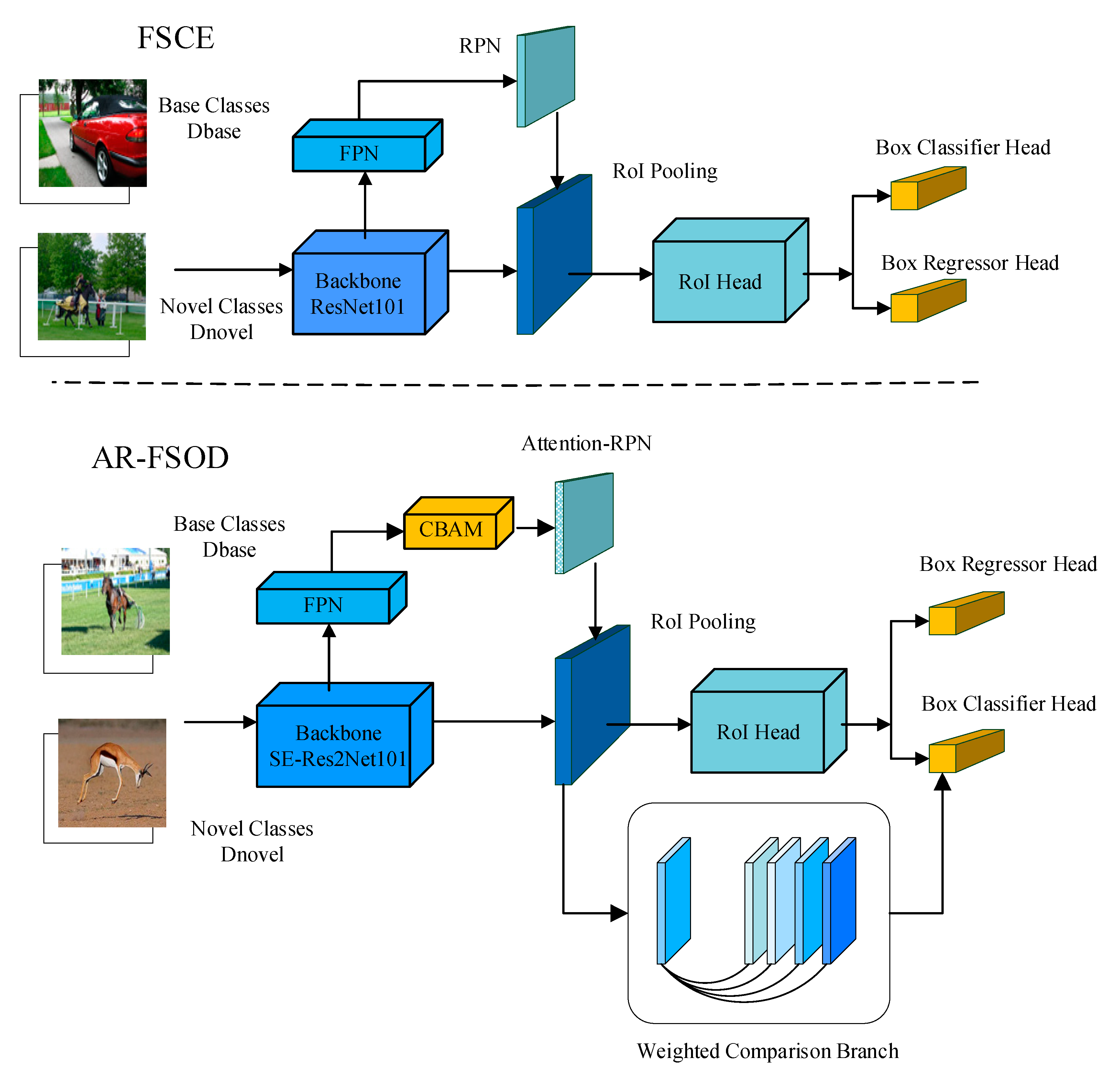
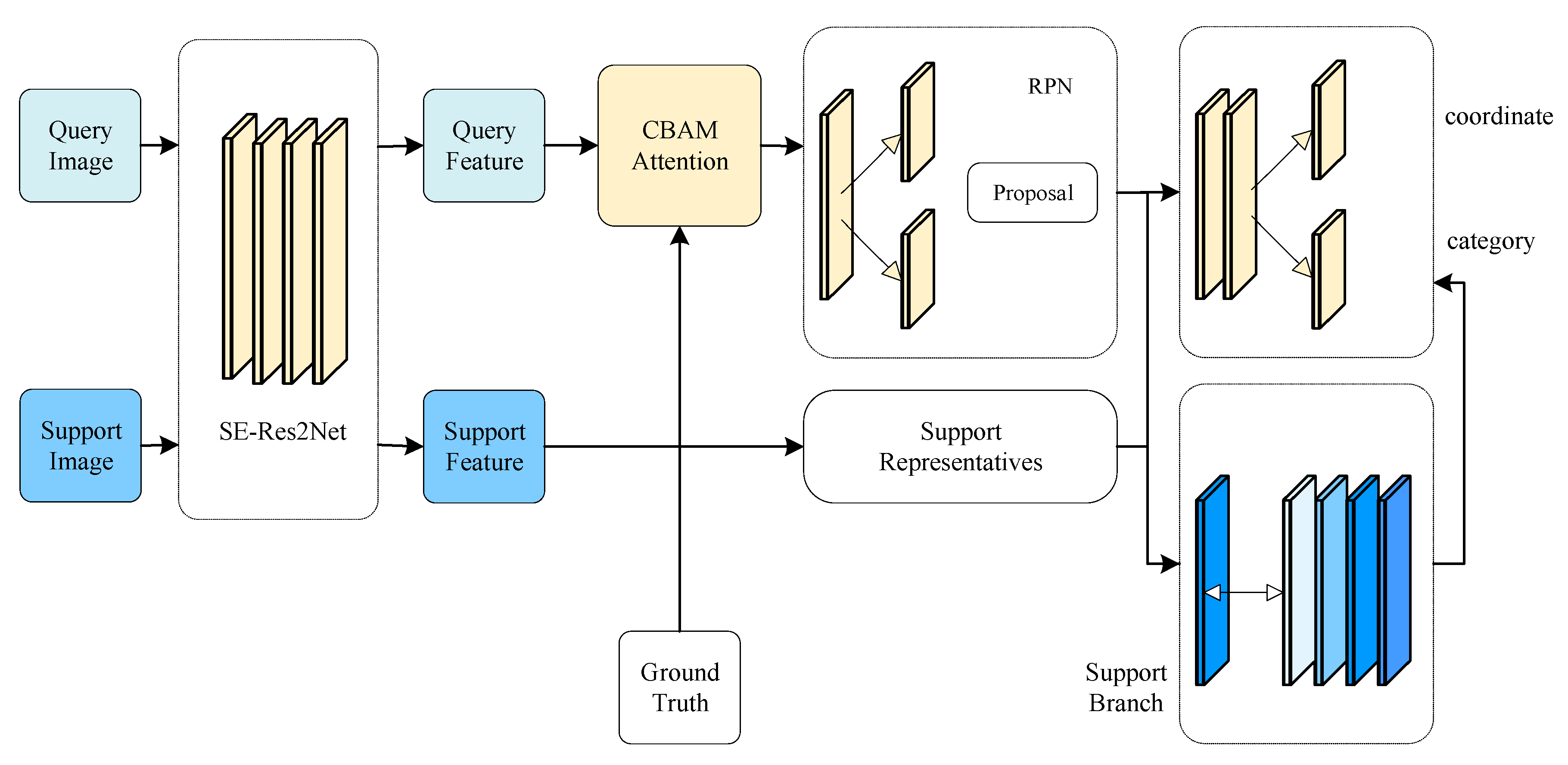
3. Improved Algorithms
3.1. Feature Extraction Network
3.2. Attention-RPN
3.3. Weighted Prototype Comparison Branch
4. Experimental Results and Analysis
4.1. Experimental Datasets

4.2. Evaluation Indicators
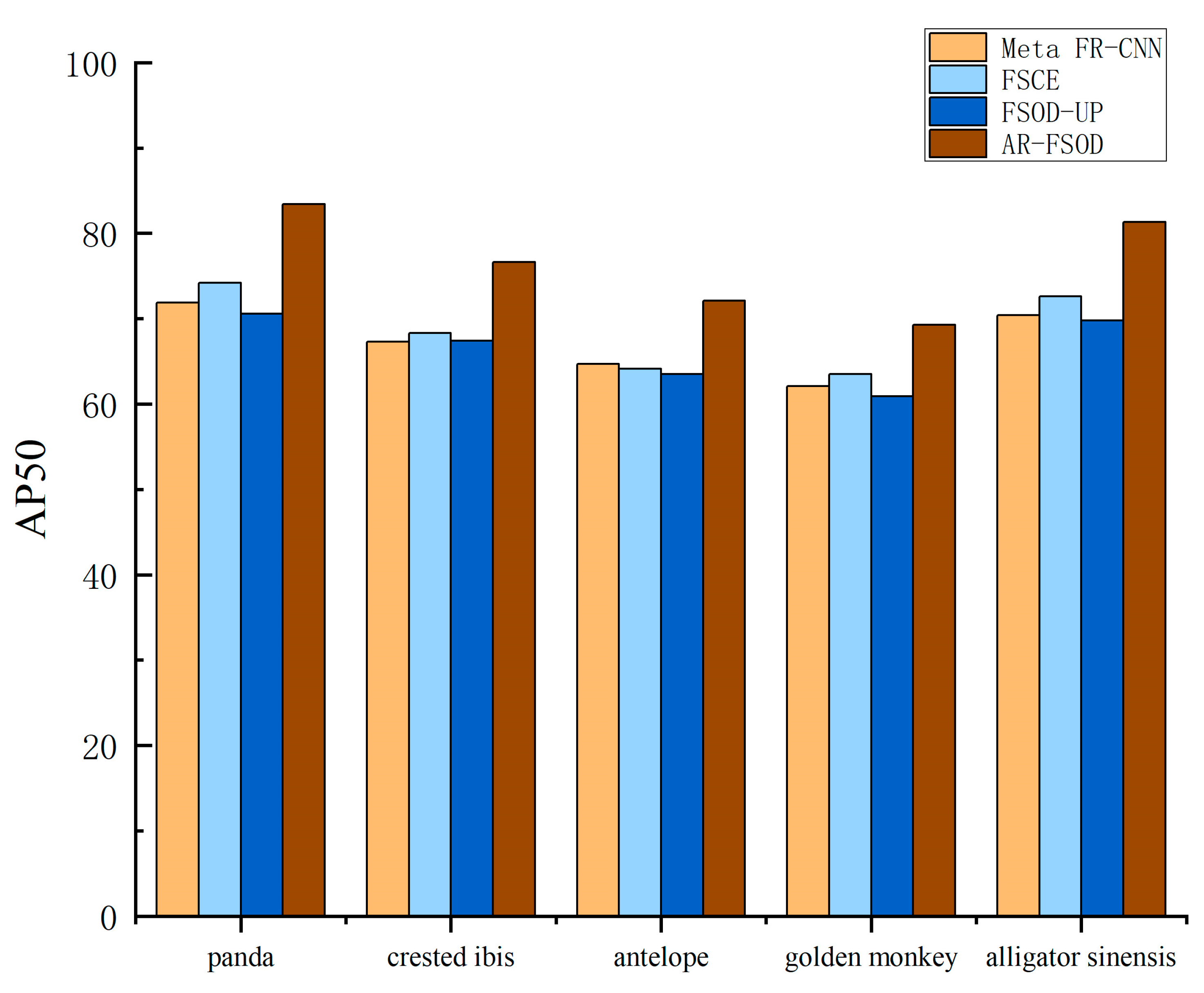
4.3. Results of the Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Andrews, D.Q.; Stoiber, T.; Temkin, A.M.; Naidenko, O.V. Discussion. Has the Human Population Become a Sentinel for the Adverse Effects of PFAS Contamination on Wildlife Health and Endangered Species? Sci. Total Environ. 2023, 901, 165939. [Google Scholar] [CrossRef] [PubMed]
- Sadanandan, K.R.; Low, G.W.; Sridharan, S.; Gwee, C.Y.; Ng, E.Y.X.; Yuda, P.; Prawiradilaga, D.M.; Lee, J.G.H.; Tritto, A.; Rheindt, F.E. The Conservation Value of Admixed Phenotypes in a Critically Endangered Species Complex. Sci. Rep. 2020, 10, 15549. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 21–23. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Thangarasu, R.; Kaliappan, V.K.; Surendran, R.; Sellamuthu, K.; Palanisamy, J. Recognition of Animal Species on Camera Trap Images Using Machine Learning and Deep Learning Models. Int. J. Sci. Technol. Res. 2019, 10, 2–11. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-Level Accuracy with 50× Fewer Parameters and <0.5 MB Model Size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-Resnet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Pillai, S.K.; Raghuwanshi, M.; Borkar, P. Super Resolution Mask RCNN Based Transfer Deep Learning Approach for Identification of Bird Species. Int. J. Adv. Res. Eng. Technol. 2021, 11, 2020. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Borana, K.; More, U.; Sodha, R.; Shirsath, V. Bird Species Identifier Using Convolutional Neural Network. Int. J. Res. Appl. Sci. Eng. Technol. 2022, 9, 340–344. [Google Scholar]
- Roy, A.M.; Bhaduri, J.; Kumar, T.; Raj, K. WilDect-YOLO: An Efficient and Robust Computer Vision-Based Accurate Object Localization Model for Automated Endangered Wildlife Detection. Ecol. Inform. 2023, 75, 101919. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Misra, D. Mish: A Self Regularized Non-Monotonic Activation Function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Köhler, M.; Eisenbach, M.; Gross, H.-M. Few-Shot Object Detection: A Comprehensive Survey. IEEE Trans. Neural Netw. Learn. Syst. 2023. early access. [Google Scholar] [CrossRef] [PubMed]
- Xin, Z.; Chen, S.; Wu, T.; Shao, Y.; Ding, W.; You, X. Few-Shot Object Detection: Research Advances and Challenges. Inf. Fusion 2024, 54, 102307. [Google Scholar] [CrossRef]
- Huang, Q.; Zhang, H.; Xue, M.; Song, J.; Song, M. A Survey of Deep Learning for Low-Shot Object Detection. ACM Comput. Surv. 2023, 56, 1–37. [Google Scholar] [CrossRef]
- Kang, B.; Liu, Z.; Wang, X.; Yu, F.; Feng, J.; Darrell, T. Few-Shot Object Detection via Feature Reweighting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8420–8429. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, NA, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Fan, Q.; Zhuo, W.; Tang, C.-K.; Tai, Y.-W. Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4013–4022. [Google Scholar]
- Wang, X.; Huang, T.E.; Darrell, T.; Gonzalez, J.E.; Yu, F. Frustratingly Simple Few-Shot Object Detection. arXiv 2020, arXiv:2003.06957. [Google Scholar]
- Sun, B.; Li, B.; Cai, S.; Yuan, Y.; Zhang, C. Fsce: Few-Shot Object Detection via Contrastive Proposal Encoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7352–7362. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (Voc) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft Coco: Common Objects in Context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-Cnn: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Gao, S.-H.; Cheng, M.-M.; Zhao, K.; Zhang, X.-Y.; Yang, M.-H.; Torr, P. Res2net: A New Multi-Scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical Networks for Few-Shot Learning. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Han, G.; Huang, S.; Ma, J.; He, Y.; Chang, S.-F. Meta Faster R-Cnn: Towards Accurate Few-Shot Object Detection with Attentive Feature Alignment. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 780–789. [Google Scholar]
- Zhu, C.; Chen, F.; Ahmed, U.; Shen, Z.; Savvides, M. Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8782–8791. [Google Scholar]
- Wu, J.; Liu, S.; Huang, D.; Wang, Y. Multi-Scale Positive Sample Refinement for Few-Shot Object Detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVI 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 456–472. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Novel Split | Shot | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| EDA | panda | crested ibis | antelope | golden monkey | alligator sinensis | 1 | 3 | 5 | 10 | 30 |
| Pascol VOC | bird | bus | motorbike | cow | sofa | 1 | 2 | 3 | 5 | 10 |
| aeroplane | bottle | cow | horse | sofa | 1 | 2 | 3 | 5 | 10 | |
| boat | cat | motorbike | sheep | sofa | 1 | 2 | 3 | 5 | 10 | |
| Parameter Name | Value | Description |
|---|---|---|
| weight | R-101.pkl | Base class training initial weights |
| max-items | 18,000 | Maximum number of iterations for base class training |
| lr | 0.02 | Base class training learning rate |
| weight (ft) | model_surgery.pth | Fine-tuning the training initial weights |
| lr (ft) | 0.001 | Fine-tuning training learning rates |
| momentum | 0.9 | Momentum of gradient descent |
| weight decay | 0.0001 | Weight decay factor |
| Panda | Crested Ibis | Antelope | Golden Monkey | Alligator Sinensis | |
|---|---|---|---|---|---|
| 1-shot | 15.4 | 10.3 | 9.4 | 8.6 | 14.6 |
| 3-shot | 32.7 | 28.5 | 23.6 | 21.9 | 31.2 |
| 5-shot | 57.6 | 44.4 | 38.7 | 36.2 | 56.8 |
| 10-shot | 74.8 | 65.0 | 63.2 | 59.8 | 72.5 |
| 30-shot | 83.4 | 76.6 | 72.1 | 69.3 | 81.3 |
| Method | Novel Set 1 | Novel Set 2 | Novel Set 3 |
|---|---|---|---|
| FSCE [22] | 0.436 | 0.186 | 0.355 |
| AR-FSOD | 0.469 | 0.273 | 0.396 |
| Novel Split1 | Novel Split2 | Novel Split3 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | 1 | 2 | 3 | 5 | 10 | 1 | 2 | 3 | 5 | 10 | 1 | 2 | 3 | 5 | 10 |
| Meta FR-CNN [30] | 41.8 | 46.7 | 52.7 | 59.6 | 62.3 | 26.1 | 33.6 | 43.8 | 47.8 | 50.1 | 35.6 | 42.1 | 45.8 | 53.4 | 52.3 |
| SRR-FSD [31] | 47.8 | 50.5 | 51.3 | 55.2 | 56.8 | 32.5 | 35.5 | 39.1 | 40.8 | 43.8 | 40.1 | 41.5 | 44.3 | 46.9 | 46.4 |
| MPSR [32] | 36.5 | 41.7 | 48.9 | 54.5 | 60.7 | 25.4 | 27.2 | 39.5 | 41.1 | 46.2 | 35.3 | 42.2 | 44.5 | 49.6 | 50.4 |
| FSCE [22] | 44.2 | 43.8 | 51.4 | 61.9 | 63.4 | 27.3 | 29.5 | 43.5 | 44.2 | 50.2 | 37.2 | 41.9 | 47.5 | 54.6 | 58.5 |
| FSRW [18] | 14.8 | 15.5 | 26.7 | 33.9 | 47.2 | 15.7 | 15.3 | 22.7 | 30.1 | 40.5 | 21.3 | 25.6 | 28.4 | 42.8 | 45.9 |
| AR-FSOD | 45.6 | 45.3 | 53.9 | 63.7 | 67.5 | 27.8 | 30.9 | 44.3 | 46.8 | 53.5 | 38.1 | 43.3 | 49.6 | 58.1 | 61.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, H.; Ruan, X.; Zhu, D.; Kong, H.; Liu, P. A Few-Shot Object Detection Method for Endangered Species. Appl. Sci. 2024, 14, 4443. https://doi.org/10.3390/app14114443
Yan H, Ruan X, Zhu D, Kong H, Liu P. A Few-Shot Object Detection Method for Endangered Species. Applied Sciences. 2024; 14(11):4443. https://doi.org/10.3390/app14114443
Chicago/Turabian StyleYan, Hongmei, Xiaoman Ruan, Daixian Zhu, Haoran Kong, and Peixuan Liu. 2024. "A Few-Shot Object Detection Method for Endangered Species" Applied Sciences 14, no. 11: 4443. https://doi.org/10.3390/app14114443
APA StyleYan, H., Ruan, X., Zhu, D., Kong, H., & Liu, P. (2024). A Few-Shot Object Detection Method for Endangered Species. Applied Sciences, 14(11), 4443. https://doi.org/10.3390/app14114443