
Using Multiple Monolingual Models for Efficiently Embedding Korean and English Conversational Sentences


Abstract
:1. Introduction
- First, we introduce two types of new conversational test sets to evaluate sentence similarity methods. These sets capture a wider range of conversational contexts (Section 3).
- Second, we propose a sentence embedding model specifically designed for Korean conversational sentences. To develop this model, we select a pre-trained model and fine-tune it on a Korean or Korean-translated corpus (Section 4).
- Third, we compare existing public SBERT models to identify the most efficient English sentence embedding model for this task (Section 5).
- Finally, we present a hybrid approach for embedding both Korean and English sentences, which outperforms existing multilingual approaches in terms of accuracy, elapsed time, and model size (Section 6).
2. Related Work
3. Dataset Preparation
3.1. Training Data
3.2. Test Data
- We asked ChatGPT to recommend appropriate topics for generating datasets. Based on its response, we selected 10 topics (Culture, Travel, Science, Sports, Education, Food, Health, Technology, History, Humanities) and 38 subtopics.
- We manually selected 34 subtopics from the 38, eliminating the very similar ones.
- For each of the remaining 34 subtopics, we asked ChatGPT to randomly generate conversational sentences in Korean.
- For each conversational sentence, we asked ChatGPT to generate one paraphrase sentence in Korean that differed in syntax as much as possible.
- Although the generated sentences were mostly of high quality, for some subtopics, ChatGPT did not generate enough diverse sentences. In these cases, we tried switching from GPT version 3.5 to 4.0. However, generating diverse sentences was still difficult for some subtopics. For those subtopics, we stopped generating and moved on to the next ones.
4. An Efficient Korean Embedding Model
- The public model snunlp/KR-SBERT-V40K-klueNLI-augSTS (https://github.com/snunlp/KR-SBERT, accessed on 2 May 2023) is based on the KR-BERT-V40K pre-trained model. It was fine-tuned using the KLUE-NLI and KorSTS datasets. The KorSTS dataset was augmented by Augmented SBERT [19];
- The public model jhgan/ko-sroberta-multitask (https://github.com/jhgan00/ko-sentence-transformers, accessed on 2 May 2023) is based on the KLUE-RoBERTa-base pre-trained model. It was fine-tuned using the KorNLI and KorSTS datasets. This model is considered the best among the models introduced on the GitHub page;
- The public model Huffon/sentence-klue-roberta-base (https://huggingface.co/Huffon/sentence-klue-roberta-base, accessed on 2 May 2023) is based on the KLUE-RoBERTa-base pre-trained model. It was fine-tuned using the KLUE-STS dataset.
5. An Efficient English Embedding Model
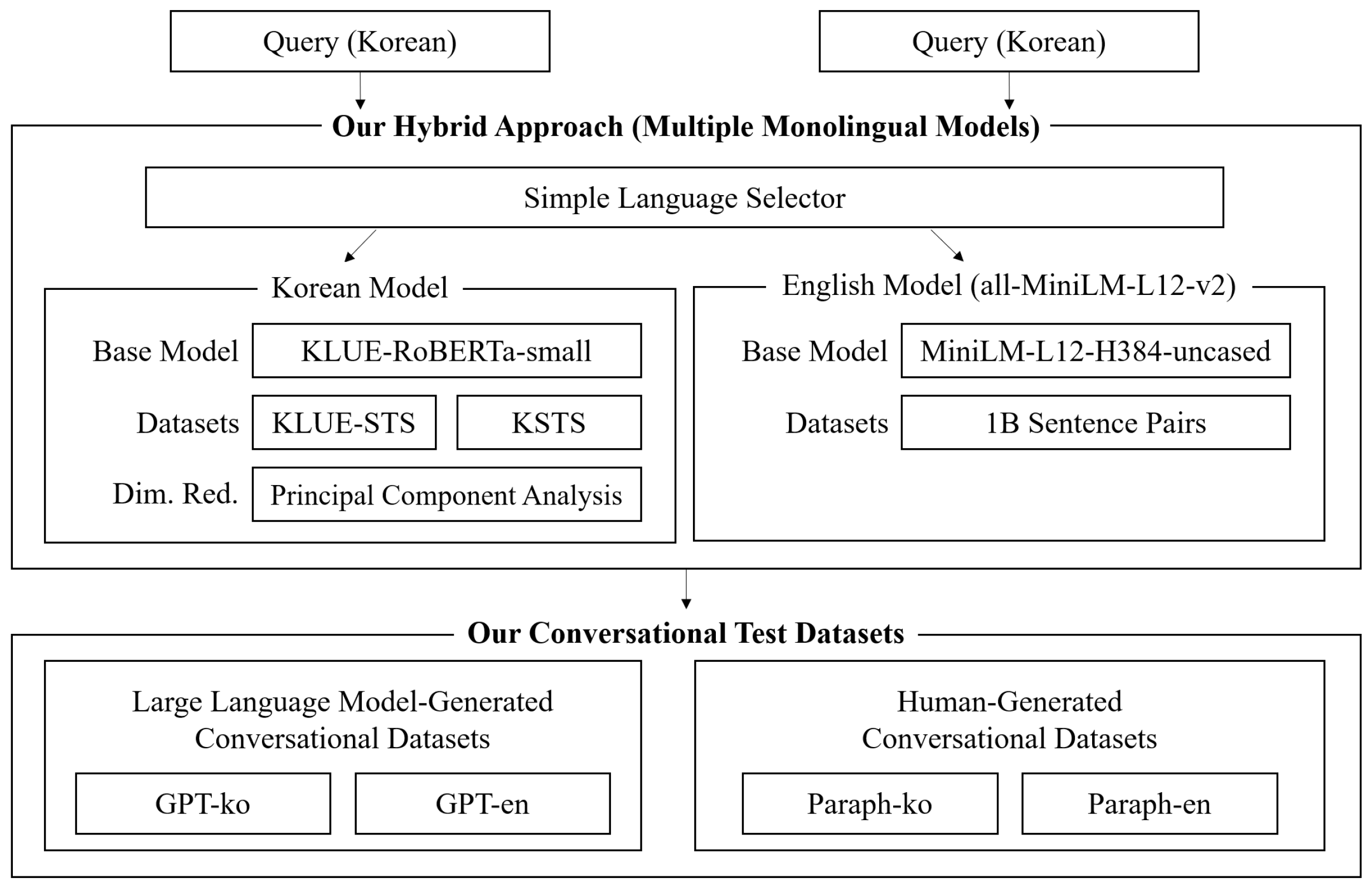
6. A Hybrid Approach
- Can we achieve better accuracy in our test datasets by using our Korean and English sentence embedding models together, compared with using state-of-the-art multilingual models?
- If so, can we achieve both higher accuracy and faster processing times in our test datasets by using even smaller versions of the two monolingual models in combination, compared with using state-of-the-art multilingual models?
- We utilized the KLUE-RoBERTa-small pre-trained model for developing a Korean monolingual model. It is worth noting that this model is smaller than the KLUE-RoBERTa-base utilized in Section 4. Hence, it may achieve lower accuracy but perform faster. To fine-tune our model, we employed the KLUE+KSTS datasets, which demonstrated the best performance on Korean test datasets, as introduced in Section 4.
- To speed up the inference time, we applied PCA (Principal Component Analysis) to reduce the dimensionality of the resulting vectors. We followed a similar approach used in sbert.net: we randomly extracted 20,000 sentences from the KLUE-NLI dataset (which is not relevant to our test datasets) to generate sample embeddings for PCA. The original dimensionality of the Korean model was 768, but our resulting vectors, applied after PCA, had a dimensionality of 384. We added the “PCA layer” to our model, and the PCA process ran very quickly.
- For the English monolingual model, we used the all-MiniLM-L12-v2 model, which was the best performing model on average in the English test sets. Because this model was already a very small model, we did not need to make the model smaller. Additionally, the output of the model is also small (384-dimensional vectors), so we did not apply PCA to reduce the dimensionality.
- For combining these two monolingual models, we used a very simple hybrid approach: if a query sentence has at least one Korean letter, then the Korean model makes the corresponding 384-dimensional vector. Otherwise, the English model makes the corresponding 384-dimensional vector.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3982–3992. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 26–28 October 2014; pp. 1532–1543. [Google Scholar]
- Conneau, A.; Kiela, D.; Schwenk, H.; Barrault, L.; Bordes, A. Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 670–680. [Google Scholar]
- Cer, D.; Yang, Y.; Kong, S.Y.; Hua, N.; Limtiaco, N.; John, R.S.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal sentence encoder. arXiv 2018, arXiv:1803.11175. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Reimers, N.; Gurevych, I. Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 4512–4525. [Google Scholar]
- Park, S.; Moon, J.; Kim, S.; Cho, W.I.; Han, J.; Park, J.; Song, C.; Kim, J.; Song, Y.; Oh, T.; et al. Klue: Korean language understanding evaluation. arXiv 2021, arXiv:2105.09680. [Google Scholar]
- Park, Y.; Shin, Y. Tooee: A novel scratch extension for K-12 big data and artificial intelligence education using text-based visual blocks. IEEE Access 2021, 9, 149630–149646. [Google Scholar] [CrossRef]
- Park, Y.; Shin, Y. A Block-Based Interactive Programming Environment for Large-Scale Machine Learning Education. Appl. Sci. 2022, 12, 13008. [Google Scholar] [CrossRef]
- Park, Y.; Shin, Y. Text Processing Education Using a Block-Based Programming Language. IEEE Access 2022, 10, 128484–128497. [Google Scholar] [CrossRef]
- Cer, D.; Diab, M.; Agirre, E.E.; Lopez-Gazpio, I.; Specia, L. SemEval-2017 Task 1: Semantic Textual Similarity Multilingual and Cross-lingual Focused Evaluation. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 1–14. [Google Scholar]
- Agirre, E.; Cer, D.; Diab, M.; Gonzalez-Agirre, A. Semeval-2012 task 6: A pilot on semantic textual similarity. In Proceedings of the First Joint Conference on Lexical and Computational Semantics, Montreal, QC, Canada, 7–8 June 2012; pp. 385–393. [Google Scholar]
- Agirre, E.; Cer, D.; Diab, M.; Gonzalez-Agirre, A.; Guo, W. SEM 2013 shared task: Semantic textual similarity. In Proceedings of the Second Joint Conference on Lexical and Computational Semantics, Atlanta GA, USA, 13–14 June 2013; pp. 32–43. [Google Scholar]
- Agirre, E.; Banea, C.; Cardie, C.; Cer, D.M.; Diab, M.T.; Gonzalez-Agirre, A.; Guo, W.; Mihalcea, R.; Rigau, G.; Wiebe, J. SemEval-2014 Task 10: Multilingual Semantic Textual Similarity. In Proceedings of the 8th International Workshop on Semantic Evaluation, Dublin, Ireland, 23–24 August 2014; pp. 81–91. [Google Scholar]
- Agirre, E.; Banea, C.; Cardie, C.; Cer, D.; Diab, M.; Gonzalez-Agirre, A.; Guo, W.; Lopez-Gazpio, I.; Maritxalar, M.; Mihalcea, R.; et al. Semeval-2015 task 2: Semantic textual similarity, english, spanish and pilot on interpretability. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; pp. 252–263. [Google Scholar]
- Agirre, E.; Banea, C.; Cer, D.; Diab, M.; Gonzalez Agirre, A.; Mihalcea, R.; Rigau, G.; Wiebe, J. Semeval-2016 task 1: Semantic textual similarity, monolingual and cross-lingual evaluation. In Proceedings of the 10th International Workshop on Semantic Evaluation, San Diego, CA, USA, 16–17 June 2016; pp. 497–511. [Google Scholar]
- Ham, J.; Choe, Y.J.; Park, K.; Choi, I.; Soh, H. KorNLI and KorSTS: New Benchmark Datasets for Korean Natural Language Understanding. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16–20 November 2020; pp. 422–430. [Google Scholar]
- Thakur, N.; Reimers, N.; Daxenberger, J.; Gurevych, I. Augmented SBERT: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 296–310. [Google Scholar]
- Lothritz, C.; Allix, K.; Lebichot, B.; Veiber, L.; Bissyandé, T.F.; Klein, J. Comparing multilingual and multiple monolingual models for intent classification and slot filling. In Proceedings of the 26th International Conference on Applications of Natural Language to Information Systems, Saarbrucken, Germany, 23–25 June 2021; pp. 367–375. [Google Scholar]

{kind=link}
| Language | Dataset Name | # of Sentences |
|---|---|---|
| Korean | KLUE | 24,374 |
| KorSTS | 17,250 | |
| KSTS (STS 2012~2017, Translated) | 18,874 | |
| KSICKR (Translated) | 15,612 | |
| English | STSb (STS Benchmark) | 16,080 |
| STS (STS 2012~2017) | 35,804 | |
| SICKR | 19,854 |
| Language | Dataset Name | # of Sentences | Description |
|---|---|---|---|
| Korean | GPT-ko | 2000 | Conversational sentences (across 34 topics) generated by ChatGPT. |
| Paraph-ko | 2000 | Sentences extracted from an existing paraphrase dataset. | |
| English | GPT-en | 2000 | English translations of the GPT-ko dataset, generated using the gpt-3.5-turbo. |
| Paraph-en | 2000 | English translations of the Paraph-ko, generated using the gpt-3.5-turbo. |
| Topics | # of Sentences | Examples |
|---|---|---|
| Traditional Korean Culture | 72 | What traditional holidays are celebrated in Korea? |
| K-POP | 76 | Please tell us how K-Pop idols interact with their fans. |
| Korean Drama | 60 | Please recommend a Korean drama with a prominent romance storyline. |
| Domestic Travel Destinations | 36 | Where are the travel destinations in Korea with abundant things to see? |
| Overseas Travel Destinations | 38 | What are the things to consider when planning an overseas trip? |
| Travel Tips | 44 | It’s better to pack your travel bag lightly. |
| Science and Technology | 74 | How is biotechnology being utilized in the medical field? |
| Environmental Issues | 40 | Electric cars are an effective alternative for reducing air pollution. |
| Space Exploration | 80 | What are the criteria for selecting astronauts? |
| Soccer | 74 | Please explain the concept and rules of penalty kicks in soccer games. |
| Baseball | 86 | What position do you want to play after becoming a baseball player? |
| Basketball | 54 | What is your favorite NBA team? |
| K-12 Education | 48 | What do you think is the most important thing you learned in school? |
| Student Issues | 172 | What are some ways to increase self-confidence? |
| Education System | 56 | What are the issues with South Korea’s university entrance system? |
| Korean Cuisine | 28 | I want to try Korean food. Do you have any recommended dishes? |
| Western Cuisine | 28 | What kitchen tools are necessary to cook Western-style cuisine? |
| Chinese Cuisine | 28 | What are the ingredients commonly used in Chinese cuisine? |
| Japanese Cuisine | 28 | What are the characteristics of the rice used in Japanese cuisine? |
| Bakery | 22 | I will find out what kind of cake is popular at the bakery. |
| Exercise | 96 | How many minutes of exercise is appropriate per day? |
| Diet Therapy | 86 | Please let me know about suitable types and intake amounts of fats for diet. |
| Health Management | 24 | Please tell me about various ways to manage stress. |
| Disease Prevention | 114 | What are the ways to prevent and manage high blood pressure? |
| Artificial Intelligence | 64 | What is natural language processing technology in artificial intelligence? |
| Blockchain | 72 | Please explain the concept and role of tokens in blockchain. |
| Smartphone | 60 | What kind of camera technology is available on smartphones? |
| Korean History | 50 | What was the social class system like during the Joseon Dynasty? |
| World History | 70 | Please explain the collapse of the Roman Empire and its causes. |
| Historical Events and Figures | 36 | What type of movement did Mahatma Gandhi serve as a leader? |
| Literature | 40 | The author can convey various messages to readers through their own works. |
| Philosophy | 60 | Does scientific progress make humans happier? |
| Religion | 56 | What role does religion play in human emotions? |
| Psychology | 28 | Why do we form a sense of self? |
| Korean SBERT Models | Accuracy (%) | ||||
|---|---|---|---|---|---|
| GPT-ko | Paraph-ko | GPT-en | Paraph-en | Average | |
| snunlp/KR-SBERT-V40K-klueNLI-augSTS | 65.65 | 79.40 | 30.50 | 45.90 | 55.36 |
| jhgan/ko-sroberta-multitask | 80.95 | 86.40 | 53.40 | 68.00 | 72.19 |
| Huffon/sentence-klue-roberta-base | 85.50 | 89.00 | 55.25 | 70.95 | 75.18 |
| (KLUE-RoBERTa-base) KLUE | 87.00 | 89.05 | 54.10 | 69.90 | 75.01 |
| (KLUE-RoBERTa-base) KorSTS | 80.55 | 84.85 | 57.25 | 69.55 | 73.05 |
| (KLUE-RoBERTa-base) KSTS | 84.05 | 85.95 | 60.00 | 69.55 | 74.89 |
| (KLUE-RoBERTa-base) KSICKR | 63.60 | 76.05 | 46.90 | 66.10 | 63.16 |
| (KLUE-RoBERTa-base) KLUE+KorSTS | 88.10 | 88.80 | 55.95 | 71.05 | 75.98 |
| (KLUE-RoBERTa-base) KLUE+KSTS | 88.30 | 89.85 | 61.30 | 72.05 | 77.88 |
| (KLUE-RoBERTa-base) KLUE+KSICKR | 87.60 | 89.65 | 58.20 | 72.35 | 76.95 |
| (KLUE-RoBERTa-base) KLUE+KSTS+KorSTS | 88.35 | 89.40 | 62.40 | 73.50 | 78.41 |
| (KLUE-RoBERTa-base) KLUE+KSTS+KorSTS+KSICKR | 87.40 | 89.15 | 60.75 | 69.40 | 76.68 |
| English SBERT Models | Accuracy (%) | ||||
|---|---|---|---|---|---|
| GPT-ko | Paraph-ko | GPT-en | Paraph-en | Average | |
| paraphrase-albert-small-v2 | 1.30 | 0.25 | 78.60 | 72.55 | 38.18 |
| all-MiniLM-L6-v2 | 12.60 | 17.20 | 81.25 | 77.95 | 47.25 |
| paraphrase-MiniLM-L3-v2 | 14.35 | 21.85 | 77.65 | 76.70 | 47.64 |
| multi-qa-mpnet-base-dot-v1 | 16.10 | 23.30 | 80.00 | 72.95 | 48.09 |
| all-mpnet-base-v2 | 16.50 | 21.25 | 80.45 | 74.40 | 48.15 |
| all-MiniLM-L12-v2 | 15.05 | 25.05 | 80.55 | 79.30 | 49.99 |
| multi-qa-MiniLM-L6-cos-v1 | 18.60 | 25.40 | 80.70 | 76.10 | 50.20 |
| multi-qa-distilbert-cos-v1 | 17.45 | 26.80 | 80.80 | 76.35 | 50.35 |
| all-distilroberta-v1 | 18.60 | 30.50 | 76.60 | 75.85 | 50.39 |
| (KLUE-RoBERTa-base) STSb | 74.45 | 83.65 | 65.45 | 69.95 | 73.38 |
| (KLUE-RoBERTa-base) STS | 82.60 | 85.30 | 66.65 | 69.65 | 76.05 |
| (KLUE-RoBERTa-base) SICKR | 52.15 | 74.25 | 47.60 | 58.90 | 58.23 |
| (KLUE-RoBERTa-base) STSb+STS | 83.30 | 85.90 | 69.15 | 71.40 | 77.44 |
| (KLUE-RoBERTa-base) STSb+STS+SICKR | 81.50 | 85.15 | 66.05 | 70.50 | 75.80 |
| Multilingual SBERT Models | Accuracy (%) | ||||
|---|---|---|---|---|---|
| GPT-ko | Paraph-ko | GPT-en | Paraph-en | Average | |
| clip-ViT-B-32-multilingual-v1 | 57.20 | 56.25 | 65.60 | 67.05 | 61.53 |
| distiluse-base-multilingual-cased-v2 | 51.35 | 65.10 | 60.55 | 74.60 | 62.90 |
| distiluse-base-multilingual-cased-v1 | 56.00 | 73.70 | 61.00 | 75.30 | 66.50 |
| paraphrase-multilingual-MiniLM-L12-v2 | 74.40 | 62.10 | 82.60 | 76.90 | 74.00 |
| paraphrase-multilingual-mpnet-base-v2 | 78.55 | 76.85 | 83.00 | 77.70 | 79.03 |
| (KLUE-RoBERTa-base) KLUE+KSTS+STSb | 87.65 | 88.30 | 67.05 | 71.50 | 78.63 |
| (KLUE-RoBERTa-base) KLUE+KSTS+STS | 87.35 | 88.50 | 67.60 | 72.15 | 78.90 |
| (KLUE-RoBERTa-base) KLUE+KSTS+STSb+STS | 87.15 | 88.30 | 66.35 | 70.80 | 78.15 |
| Our Hybrid Approach | 85.60 | 87.35 | 80.55 | 79.30 | 83.20 |
| Multilingual SBERT Models | Test Sets | Elapsed Time (Seconds) | Accuracy (%) | |||
|---|---|---|---|---|---|---|
| ENC-GPU | NNS-GPU | ENC-CPU | NNS-CPU | |||
| Huffon/sentence-klue-roberta-base (Total Model Size: 443 MB) | GPT-ko | 0.0102 | 0.0727 | 0.0324 | 0.0890 | 85.45 |
| Paraph-ko | 0.0097 | 0.0725 | 0.0309 | 0.0884 | 89.00 | |
| GPT-en | 0.0104 | 0.0728 | 0.0349 | 0.0882 | 55.25 | |
| Paraph-en | 0.0100 | 0.0732 | 0.0365 | 0.0887 | 70.95 | |
| Average | 0.0101 | 0.0728 | 0.0337 | 0.0886 | 75.16 | |
| paraphrase-multilingual-mpnet-base-v2 (Total Model Size: 1.11 GB) | GPT-ko | 0.0098 | 0.0731 | 0.0320 | 0.0896 | 78.55 |
| Paraph-ko | 0.0100 | 0.0732 | 0.0327 | 0.0893 | 76.85 | |
| GPT-en | 0.0100 | 0.0734 | 0.0312 | 0.0895 | 83.00 | |
| Paraph-en | 0.0099 | 0.0731 | 0.0268 | 0.0828 | 77.70 | |
| Average | 0.0099 | 0.0732 | 0.0307 | 0.0878 | 79.03 | |
| Our Hybrid Approach (Korean+English) (Total Model Size: 393 MB) | GPT-ko | 0.0055 | 0.0380 | 0.0167 | 0.0475 | 85.60 |
| Paraph-ko | 0.0057 | 0.0384 | 0.0162 | 0.0466 | 87.35 | |
| GPT-en | 0.0086 | 0.0380 | 0.0115 | 0.0429 | 80.55 | |
| Paraph-en | 0.0084 | 0.0379 | 0.0123 | 0.0431 | 79.30 | |
| Average | 0.0071 | 0.0381 | 0.0142 | 0.0450 | 83.20 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, Y.; Shin, Y. Using Multiple Monolingual Models for Efficiently Embedding Korean and English Conversational Sentences. Appl. Sci. 2023, 13, 5771. https://doi.org/10.3390/app13095771
Park Y, Shin Y. Using Multiple Monolingual Models for Efficiently Embedding Korean and English Conversational Sentences. Applied Sciences. 2023; 13(9):5771. https://doi.org/10.3390/app13095771
Chicago/Turabian StylePark, Youngki, and Youhyun Shin. 2023. "Using Multiple Monolingual Models for Efficiently Embedding Korean and English Conversational Sentences" Applied Sciences 13, no. 9: 5771. https://doi.org/10.3390/app13095771
APA StylePark, Y., & Shin, Y. (2023). Using Multiple Monolingual Models for Efficiently Embedding Korean and English Conversational Sentences. Applied Sciences, 13(9), 5771. https://doi.org/10.3390/app13095771