
PhotoMatch: An Open-Source Tool for Multi-View and Multi-Modal Feature-Based Image Matching

 ,
,  ,
,  and
and
Abstract
1. Introduction
- Detectors identify distinctive features (keypoints), localizing meaningful and salient regions of the image, and extracting these regions as patches. These patches are generally normalized in order to achieve invariance to geometric and radiometric transformations. These keypoints are represented by their point representatives, such as the centre of gravity or other distinctive points.
- Descriptors analyse the neighbourhood of the keypoints and create a 2D vector of information based on the different mathematical properties of the point and its neighbourhood. Usually, distance is used to establish the candidate correspondences.
- Matching identifies homologous keypoints between images using the information provided by the descriptors. The most common matching methods are brute-force and Flann [22], and robust matching by means of spatial global or local constraints, such as those provided by epipolar geometry [23] and RANdom SAmple Consensus (RANSAC) [21,22,23,24].
2. PhotoMatch
2.1. Project and Session Definition
2.2. Image Pre-Processing
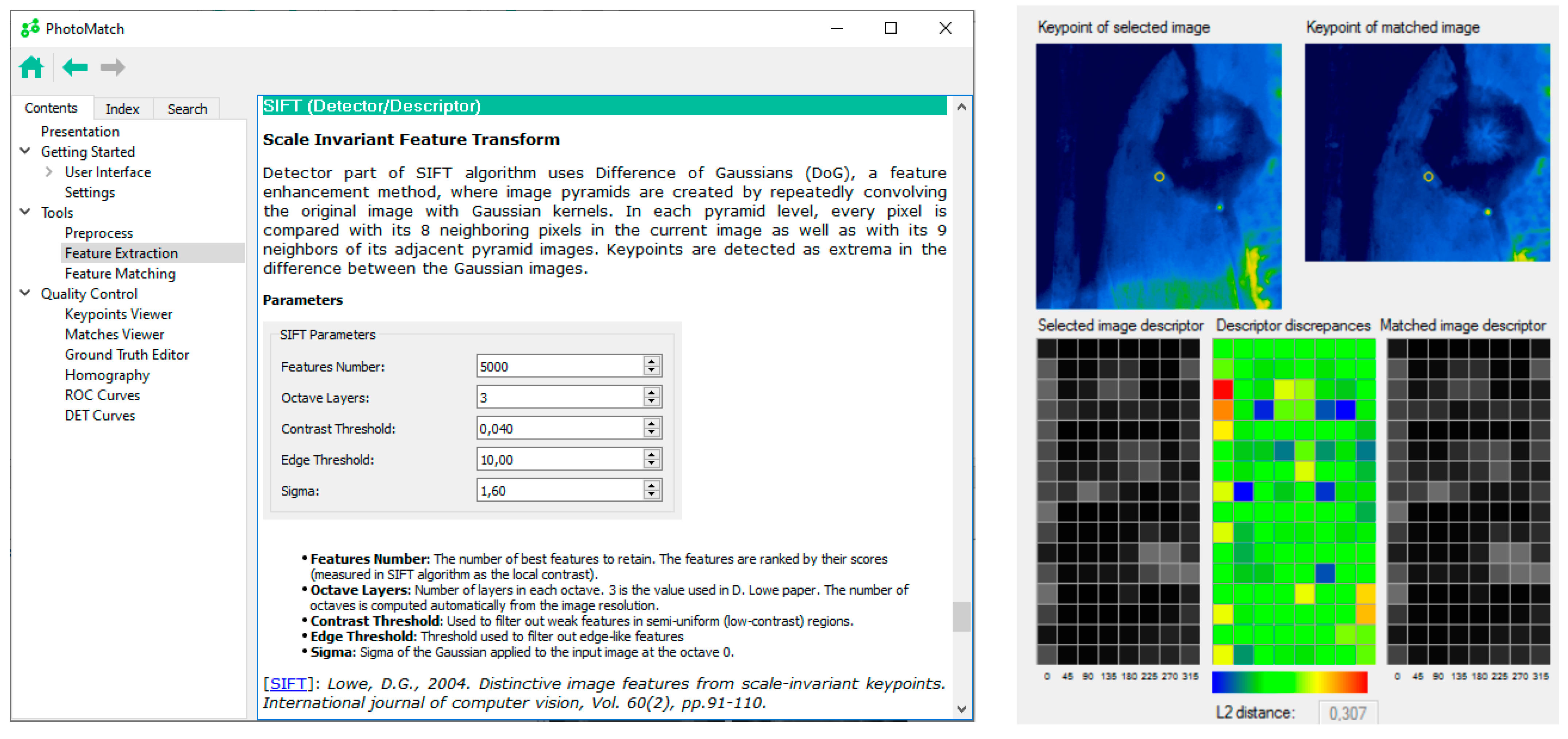
2.3. Feature Extraction
2.4. Matching
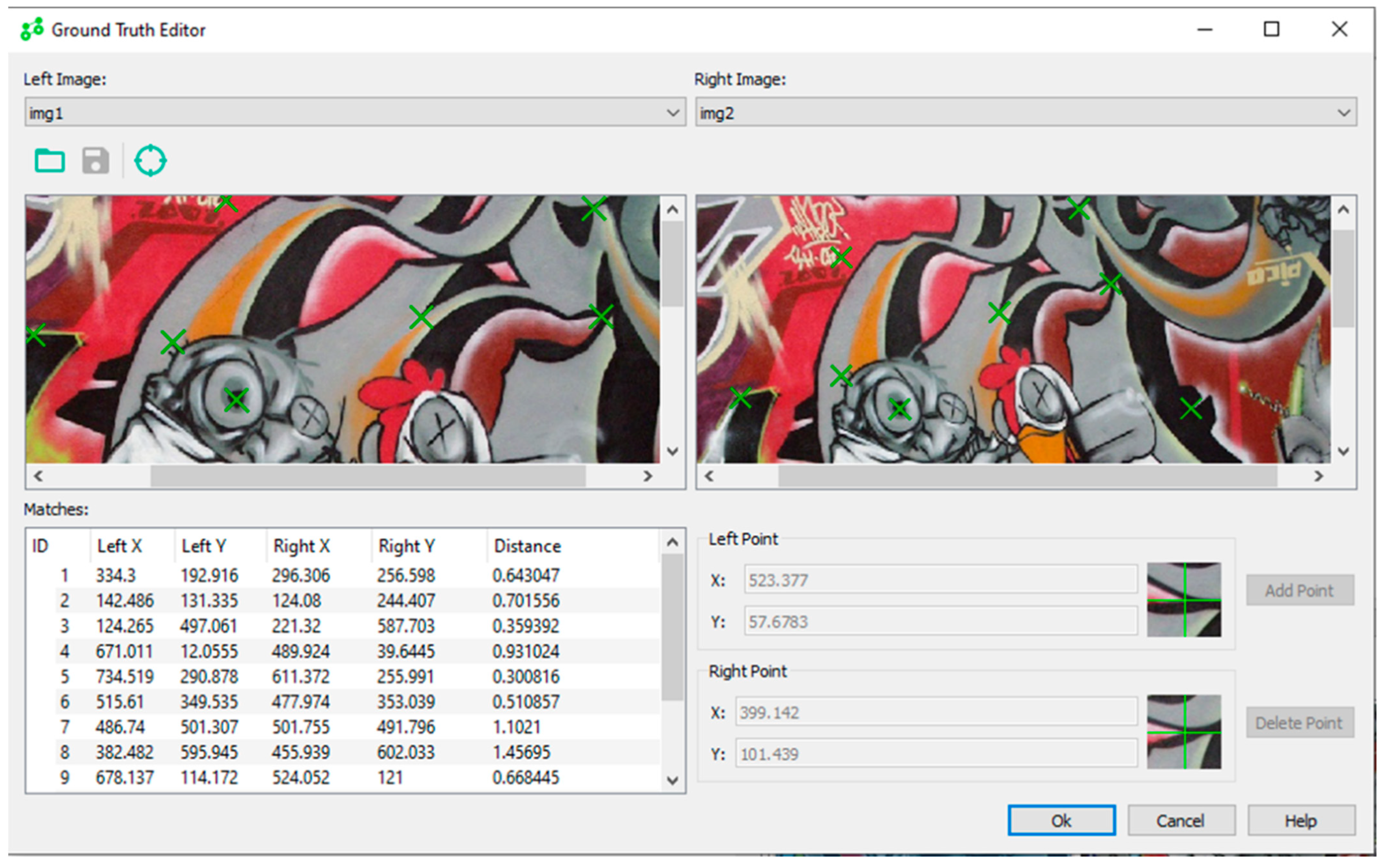
2.5. Assessment of Results
2.6. Export
2.7. Educational Information
3. Experimental Results and Discussion
3.1. Multi-View
3.2. Multi-Modal
3.3. Feature-Based Image Matching Strategies
3.4. Assessment
3.5. Results
3.5.1. Multi-View
3.5.2. Multi-Modal
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gonzalez-Aguilera, D.; López-Fernández, L.; Rodriguez-Gonzalvez, P.; Hernandez-Lopez, D.; Guerrero, D.; Remondino, F.; Menna, F.; Nocerino, E.; Toschi, I.; Ballabeni, A.; et al. GRAPHOS—Open-Source Software for Photogrammetric Applications. Photogramm. Rec. 2018, 33, 11–29. [Google Scholar] [CrossRef]
- Dai-Hong, J.; Lei, D.; Dan, L.; San-You, Z. Moving-Object Tracking Algorithm Based on PCA-SIFT and Optimization for Underground Coal Mines. IEEE Access 2019, 7, 35556–35563. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Fiaz, M.; Mahmood, A.; Javed, S.; Jung, S.K. Handcrafted and Deep Trackers: Recent Visual Object Tracking Approaches and Trends. ACM Comput. Surv. 2020, 52, 1–44. [Google Scholar] [CrossRef]
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Kim, T.-K. Multiple Object Tracking: A Literature Review. Artif. Intell. 2021, 293, 103448. [Google Scholar] [CrossRef]
- Pal, S.K.; Pramanik, A.; Maiti, J.; Mitra, P. Deep Learning in Multi-Object Detection and Tracking: State of the Art. Appl. Intell. 2021, 51, 6400–6429. [Google Scholar] [CrossRef]
- Wohlhart, P.; Lepetit, V. Learning Descriptors for Object Recognition and 3D Pose Estimation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3109–3118. [Google Scholar]
- Granshaw, S.I. Editorial: Imaging Technology 1430–2015: Old Masters to Mass Photogrammetry. Photogramm. Rec. 2015, 30, 255–260. [Google Scholar] [CrossRef]
- Morales, A.; González-Aguilera, D.; Gutiérrez, M.A.; López, I. Energy Analysis of Road Accidents Based on Close-Range Photogrammetry. Remote Sens. 2015, 7, 15161–15178. [Google Scholar] [CrossRef]
- Nocerino, E.; Lago, F.; Morabito, D.; Remondino, F.; Porzi, L.; Poiesi, F.; Rota Bulo, S.; Chippendale, P.; Locher, A.; Havlena, M.; et al. A Smartphone-Based 3D Pipeline for the Creative Industry—The Replicate EU Project. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2017, XLII-2-W3, 535–541. [Google Scholar] [CrossRef]
- Ortiz-Sanz, J.; Gil-Docampo, M.; Rego-Sanmartín, T.; Arza-García, M.; Tucci, G. A PBeL for Training Non-Experts in Mobile-Based Photogrammetry and Accurate 3-D Recording of Small-Size/Non-Complex Objects. Measurement 2021, 178, 109338. [Google Scholar] [CrossRef]
- Remondino, F.; Nocerino, E.; Toschi, I.; Menna, F. A Critical Review of Automated Photogrammetric Processing of Large Datasets. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2017, XLII-2-W5, 591–599. [Google Scholar] [CrossRef]
- Rahaman, H.; Champion, E. To 3D or Not 3D: Choosing a Photogrammetry Workflow for Cultural Heritage Groups. Heritage 2019, 2, 1835–1851. [Google Scholar] [CrossRef]
- Jiang, X.; Ma, J.; Xiao, G.; Shao, Z.; Guo, X. A Review of Multimodal Image Matching: Methods and Applications. Inf. Fusion 2021, 73, 22–71. [Google Scholar] [CrossRef]
- Pamart, A.; Morlet, F.; De Luca, L.; Veron, P. A Robust and Versatile Pipeline for Automatic Photogrammetric-Based Registration of Multimodal Cultural Heritage Documentation. Remote Sens. 2020, 12, 2051. [Google Scholar] [CrossRef]
- Wei, Z.; Han, Y.; Li, M.; Yang, K.; Yang, Y.; Luo, Y.; Ong, S.-H. A Small UAV Based Multi-Temporal Image Registration for Dynamic Agricultural Terrace Monitoring. Remote Sens. 2017, 9, 904. [Google Scholar] [CrossRef]
- Kang, J.K.; Hoang, T.M.; Park, K.R. Person Re-Identification Between Visible and Thermal Camera Images Based on Deep Residual CNN Using Single Input. IEEE Access 2019, 7, 57972–57984. [Google Scholar] [CrossRef]
- Kniaz, V.V.; Knyaz, V.A.; Hladuvka, J.; Kropatsch, W.G.; Mizginov, V. ThermalGAN: Multimodal Color-to-Thermal Image Translation for Person Re-Identification in Multispectral Dataset; Springer: Cham, Switzerland, 2018; pp. 606–624. [Google Scholar]
- Remondino, F.; Menna, F.; Morelli, L. Evaluating Hand-Crafted and Learning-Based Features for Photogrammetric Applications. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2021, XLIII-B2-2021, 549–556. [Google Scholar] [CrossRef]
- Ma, J.; Jiang, X.; Fan, A.; Jiang, J.; Yan, J. Image Matching from Handcrafted to Deep Features: A Survey. Int. J. Comput. Vis. 2021, 129, 23–79. [Google Scholar] [CrossRef]
- González-Aguilera, D.; Ruiz De Oña, E.; López-Fernandez, L.; Farella, E.M.; Stathopoulou, E.K.; Toschi, I.; Remondino, F.; Rodríguez-Gonzálvez, P.; Hernández-López, D.; Fusiello, A.; et al. PHOTOMATCH: An Open-Source Multi-View and Multi-Modal Feature Matching Tool for Photogrammetric Applications. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci.-ISPRS Arch. 2020, 43, 213–219. [Google Scholar] [CrossRef]
- Muja, M.; Lowe, D.G. Flann, Fast Library for Approximate Nearest Neighbors. In International Conference on Computer Vision Theory and Applications (VISAPP’09); INSTICC Press: Setúbal, Portugal, 2009; Volume 3. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003; ISBN 978-0-521-54051-3. [Google Scholar]
- Zitová, B.; Flusser, J. Image Registration Methods: A Survey. Image Vis. Comput. 2003, 21, 977–1000. [Google Scholar] [CrossRef]
- Chen, L.; Rottensteiner, F.; Heipke, C. Feature Detection and Description for Image Matching: From Hand-Crafted Design to Deep Learning. Geo-Spat. Inf. Sci. 2021, 24, 58–74. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Arandjelović, R.; Zisserman, A. Three Things Everyone Should Know to Improve Object Retrieval. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2911–2918. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded up Robust Features. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3951, pp. 404–417. [Google Scholar] [CrossRef]
- Tombari, F.; Di Stefano, L. Interest Points via Maximal Self-Dissimilarities. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9004, pp. 586–600. [Google Scholar] [CrossRef]
- Yu, K.; Zheng, X.; Duan, Y.; Fang, B.; An, P.; Ma, J. NCFT: Automatic Matching of Multimodal Image Based on Nonlinear Consistent Feature Transform. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Long, G.; Kneip, L.; Alvarez, J.M.; Li, H.; Zhang, X.; Yu, Q. Learning Image Matching by Simply Watching Video. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 434–450. [Google Scholar]
- Christiansen, P.H.; Kragh, M.F.; Brodskiy, Y.; Karstoft, H. UnsuperPoint: End-to-End Unsupervised Interest Point Detector and Descriptor. arXiv 2019, arXiv:1907.04011. [Google Scholar]
- Ono, Y.; Trulls, E.; Fua, P.; Moo Yi, K. LF-Net: Learning Local Features from Images. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Image Matching Challenge—2021 Edition. Available online: https://www.cs.ubc.ca/research/image-matching-challenge/current/ (accessed on 11 October 2022).
- Chen, H.; Luo, Z.; Zhou, L.; Tian, Y.; Zhen, M.; Fang, T.; Mckinnon, D.; Tsin, Y.; Quan, L. ASpanFormer: Detector-Free Image Matching with Adaptive Span Transformer. In Proceedings of the 17th European Conference, Tel Aviv, Israel, 23 October 2022. [Google Scholar]
- Sarlin, P.-E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperGlue: Learning Feature Matching With Graph Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4938–4947. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperPoint: Self-Supervised Interest Point Detection and Description. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 224–236. [Google Scholar]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-Free Local Feature Matching With Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8922–8931. [Google Scholar]
- Edstedt, J.; Athanasiadis, I.; Wadenbäck, M.; Felsberg, M. DKM: Dense Kernelized Feature Matching for Geometry Estimation. arXiv 2022, arXiv:2202.00667. [Google Scholar]
- Tyszkiewicz, M.; Fua, P.; Trulls, E. DISK: Learning Local Features with Policy Gradient. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 14254–14265. [Google Scholar]
- Bellavia, F.; Colombo, C.; Morelli, L.; Remondino, F. Challenges in Image Matching for Cultural Heritage: An Overview and Perspective. In Image Analysis and Processing; ICIAP 2022 Workshops; Mazzeo, P.L., Frontoni, E., Sclaroff, S., Distante, C., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 210–222. [Google Scholar]
- Verdie, Y.; Yi, K.; Fua, P.; Lepetit, V. TILDE: A Temporally Invariant Learned DEtector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5279–5288. [Google Scholar]
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-Net: A Trainable CNN for Joint Description and Detection of Local Features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; Volume 2019, pp. 8084–8093. [Google Scholar]
- Revaud, J.; Weinzaepfel, P.; De Souza, C.; Pion, N.; Csurka, G.; Cabon, Y.; Humenberger, M. R2D2: Repeatable and Reliable Detector and Descriptor. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar] [CrossRef]
- ISPRS Scientific Initiatives. Available online: https://www.isprs.org/society/si/SI-2019/default.aspx (accessed on 9 August 2022).
- Gaiani, M.; Apollonio, F.I.; Ballabeni, A.; Remondino, F. Securing Color Fidelity in 3D Architectural Heritage Scenarios. Sensors 2017, 17, 2437. [Google Scholar] [CrossRef]
- Lu, C.; Xu, L.; Jia, J. Contrast Preserving Decolorization with Perception-Based Quality Metrics. Int. J. Comput. Vis. 2014, 110, 222–239. [Google Scholar] [CrossRef]
- Lal, S.; Chandra, M. Efficient Algorithm for Contrast Enhancement of Natural Images. Int. Arab J. Inf. Technol. 2014, 11, 95–102. [Google Scholar]
- Abdullah-Al-Wadud, M.; Kabir, M.D.H.; Akber Dewan, M.A.; Chae, O. A Dynamic Histogram Equalization for Image Contrast Enhancement. IEEE Trans. Consum. Electron. 2007, 53, 593–600. [Google Scholar] [CrossRef]
- Liu, Y.-F.; Guo, J.-M.; Lai, B.-S.; Lee, J.-D. High Efficient Contrast Enhancement Using Parametric Approximation. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 2444–2448. [Google Scholar]
- Kim, M.; Chung, M.G. Recursively Separated and Weighted Histogram Equalization for Brightness Preservation and Contrast Enhancement. IEEE Trans. Consum. Electron. 2008, 54, 1389–1397. [Google Scholar] [CrossRef]
- Wallis, K.F. Seasonal Adjustment and Relations between Variables. J. Am. Stat. Assoc. 1974, 69, 18–31. [Google Scholar] [CrossRef]
- Alcantarilla, P.; Nuevo, J.; Bartoli, A. Fast Explicit Diffusion for Accelerated Features in Nonlinear Scale Spaces. In Proceedings of the British Machine Vision Conference 2013; British Machine Vision Association: Bristol, UK, 2013; pp. 13.1–13.11. [Google Scholar]
- Morel, J.-M.; Yu, G. ASIFT: A New Framework for Fully Affine Invariant Image Comparison. SIAM J. Imaging Sci. 2009, 2, 438–469. [Google Scholar] [CrossRef]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary Robust Invariant Scalable Keypoints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Bian, J.; Lin, W.-Y.; Matsushita, Y.; Yeung, S.-K.; Nguyen, T.-D.; Cheng, M.-M. GMS: Grid-Based Motion Statistics for Fast, Ultra-Robust Feature Correspondence. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4181–4190. [Google Scholar]
- Hamming, R.W. Error Detecting and Error Correcting Codes. Bell Syst. Tech. J. 1950, 29, 147–160. [Google Scholar] [CrossRef]
- Poursaeed, O.; Yang, G.; Prakash, A.; Fang, Q.; Jiang, H.; Hariharan, B.; Belongie, S. Deep Fundamental Matrix Estimation without Correspondences. In Proceedings of the Computer Vision—ECCV 2018 Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Aicardi, I.; Nex, F.; Gerke, M.; Lingua, A.M. An Image-Based Approach for the Co-Registration of Multi-Temporal UAV Image Datasets. Remote Sens. 2016, 8, 779. [Google Scholar] [CrossRef]
- Ancuti, C.O.; Ancuti, C.; Bekaert, P. Decolorizing Images for Robust Matching. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 149–152. [Google Scholar]
- Luo, Z.; Zhou, L.; Bai, X.; Chen, H.; Zhang, J.; Yao, Y.; Li, S.; Fang, T.; Quan, L. ASLFeat: Learning Local Features of Accurate Shape and Localization. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 13–19 June 2020; pp. 6589–6598. [Google Scholar]
- Mishchuk, A.; Mishkin, D.; Radenovic, F.; Matas, J. Working Hard to Know Your Neighbor’ s Margins: Local Descriptor Learning Loss. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Truong, P.; Apostolopoulos, S.; Mosinska, A.; Stucky, S.; Ciller, C.; Zanet, S.D. GLAMpoints: Greedily Learned Accurate Match Points. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10732–10741. [Google Scholar]
- Singh Parihar, U.; Gujarathi, A.; Mehta, K.; Tourani, S.; Garg, S.; Milford, M.; Krishna, K.M. RoRD: Rotation-Robust Descriptors and Orthographic Views for Local Feature Matching. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 1593–1600. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detector Descriptor | SIFT + SIFT | SURF + SURF | SURF + SIFT | MSD + SIFT | ASIFT | R2D2 | D2-NET | |
|---|---|---|---|---|---|---|---|---|
| Facade (Figure 5a) | CM | 24 (27.2%) | 26 (22.7%) | 47 (33.7%) | 19 (34.8%) | 190 (27.8%) | 68 (52.5%) | 27 (32.7%) |
| ME (px) | 175.1 | 170.6 | 163.8 | 123.2 | 172.2 | 110.5 | 176.9 | |
| Forest (Figure 5b) | CM | 108 (79.4%) | 89 (71.2%) | 139 (80.7%) | 77 (80.6%) | 1155 (86.4%) | 187 (94.1%) | 123 (89.1%) |
| ME (px) | 19.2 | 21.1 | 8.9 | 8.7 | 13.5 | 4.1 | 6.3 | |
| Playground (Figure 5c) | CM | 8 (36.9%) | 51 (57.2%) | 60 (60.7%) | 30 (65.6%) | 214 (74.2%) | 47 (80.5%) | 49 (69.2%) |
| ME (px) | 607.8 | 224.6 | 66.5 | 40.6 | 137.5 | 26.3 | 45.9 | |
| Boulder (Figure 5d) | CM | 150 (80.1%) | 261 (83.2%) | 283 (86.4%) | 24 (77.8%) | 551 (98.8%) | 322 (96.1%) | 533 (91.4%) |
| ME (px) | 50.9 | 49.9 | 30.3 | 163.5 | 12.6 | 29.8 | 20.3 | |
| Graffiti low differences (Figure 5e) | CM | 681 (99.9%) | 613 (99.4%) | 602 (96.8%) | 62 (93.3%) | 8713 (99.9%) | 241 (98.4%) | 165 (94.9%) |
| ME (px) | 1.2 | 2.4 | 3.4 | 14.4 | 1.3 | 2.9 | 8.0 | |
| Graffiti high differences (Figure 5f) | CM | 91 (94.4%) | 62 (90.9%) | 50,5 (87.1%) | 1 (10.3%) | 2182 (99.8%) | 2 (38.7%) | 2 (30%) |
| ME (px) | 17.0 | 18.6 | 31.7 | 241.0 | 1.4 | 151.3 | 171.0 |
| Detector Descriptor | SIFT + SIFT | SURF + SURF | SURF + SIFT | MSD + SIFT | ASIFT | R2D2 | D2-NET | |
|---|---|---|---|---|---|---|---|---|
| Visible-Thermal (Figure 6a) | CM | 0 (0%) | 1 (3,2%) | 1 (4,2%) | 4 (22,2%) | 3 (2,9%) | 1 (6,25%) | 53 (81,54%) |
| ME (px) | 273.7 | 143.8 | 172.2 | 63.1 | 202.7 | 184.3 | 13.7 | |
| SEM (Figure 6b) | CM | 0 (0%) | 0 (0%) | 3 (33.3%) | 0 (0%) | 6 (28.6%) | 5 (62.5%) | 16 (76.2%) |
| ME (px) | 1470.0 | 983.4 | 22.0 | 860.0 | 1013.4 | 10.7 | 6.9 | |
| Visible-Range (Figure 6c) | CM | 1 (3,3%) | 13 (25%) | 154 (53,1%) | 3 (23,1%) | 47 (32,9%) | 5 (31,3%) | 77 (77,8%) |
| ME (px) | 216.9 | 141.9 | 34.4 | 136.1 | 140.8 | 88.2 | 43.4 | |
| Visible-Thermal Aerial (Figure 6d) | CM | 0 (0%) | 3 (30%) | 9 (60%) | 0 (0%) | 26 (86.7%) | 17 (100%) | 107 (97.3%) |
| ME (px) | 383.9 | 159.2 | 15.9 | 259.3 | 30.7 | 3.9 | 4.3 | |
| Satellite (Figure 6e) | CM | 0 (0%) | 0 (0%) | 7 (41,17%) | 9 (75%) | 0 (0%) | 6 (75%) | 135 (95,7) |
| ME (px) | 179.1 | 154.6 | 16.5 | 11.2 | 178.4 | 25.3 | 4.7 | |
| Magnetic Resonance (Figure 6f) | CM | 0 (0%) | 0 (0%) | 10 (66.7%) | 0 (0%) | 0 (0%) | 5 (16.4%) | 44 (92.6%) |
| ME (px) | 194.0 | 151.9 | 8.2 | 122.9 | 144.1 | 30.2 | 5.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruiz de Oña, E.; Barbero-García, I.; González-Aguilera, D.; Remondino, F.; Rodríguez-Gonzálvez, P.; Hernández-López, D. PhotoMatch: An Open-Source Tool for Multi-View and Multi-Modal Feature-Based Image Matching. Appl. Sci. 2023, 13, 5467. https://doi.org/10.3390/app13095467
Ruiz de Oña E, Barbero-García I, González-Aguilera D, Remondino F, Rodríguez-Gonzálvez P, Hernández-López D. PhotoMatch: An Open-Source Tool for Multi-View and Multi-Modal Feature-Based Image Matching. Applied Sciences. 2023; 13(9):5467. https://doi.org/10.3390/app13095467
Chicago/Turabian StyleRuiz de Oña, Esteban, Inés Barbero-García, Diego González-Aguilera, Fabio Remondino, Pablo Rodríguez-Gonzálvez, and David Hernández-López. 2023. "PhotoMatch: An Open-Source Tool for Multi-View and Multi-Modal Feature-Based Image Matching" Applied Sciences 13, no. 9: 5467. https://doi.org/10.3390/app13095467
APA StyleRuiz de Oña, E., Barbero-García, I., González-Aguilera, D., Remondino, F., Rodríguez-Gonzálvez, P., & Hernández-López, D. (2023). PhotoMatch: An Open-Source Tool for Multi-View and Multi-Modal Feature-Based Image Matching. Applied Sciences, 13(9), 5467. https://doi.org/10.3390/app13095467