
Employing FGP-3D, a Fully Gated and Anchored Methodology, to Identify Skeleton-Based Action Recognition


Abstract
1. Introduction
- 1.
- By recommending FGP-3D with a novel design approach that employs a fully gated unit mechanism and an anchored point for skeleton-based action recognition, we go beyond conventional designs.
- 2.
- We explore skeleton-based real-world action recognition with a concentration on temporal and spatial domain learning. While we used anchored points and fully gated unit features to derive spatial information, we also used fully popovicius features.
- 3.
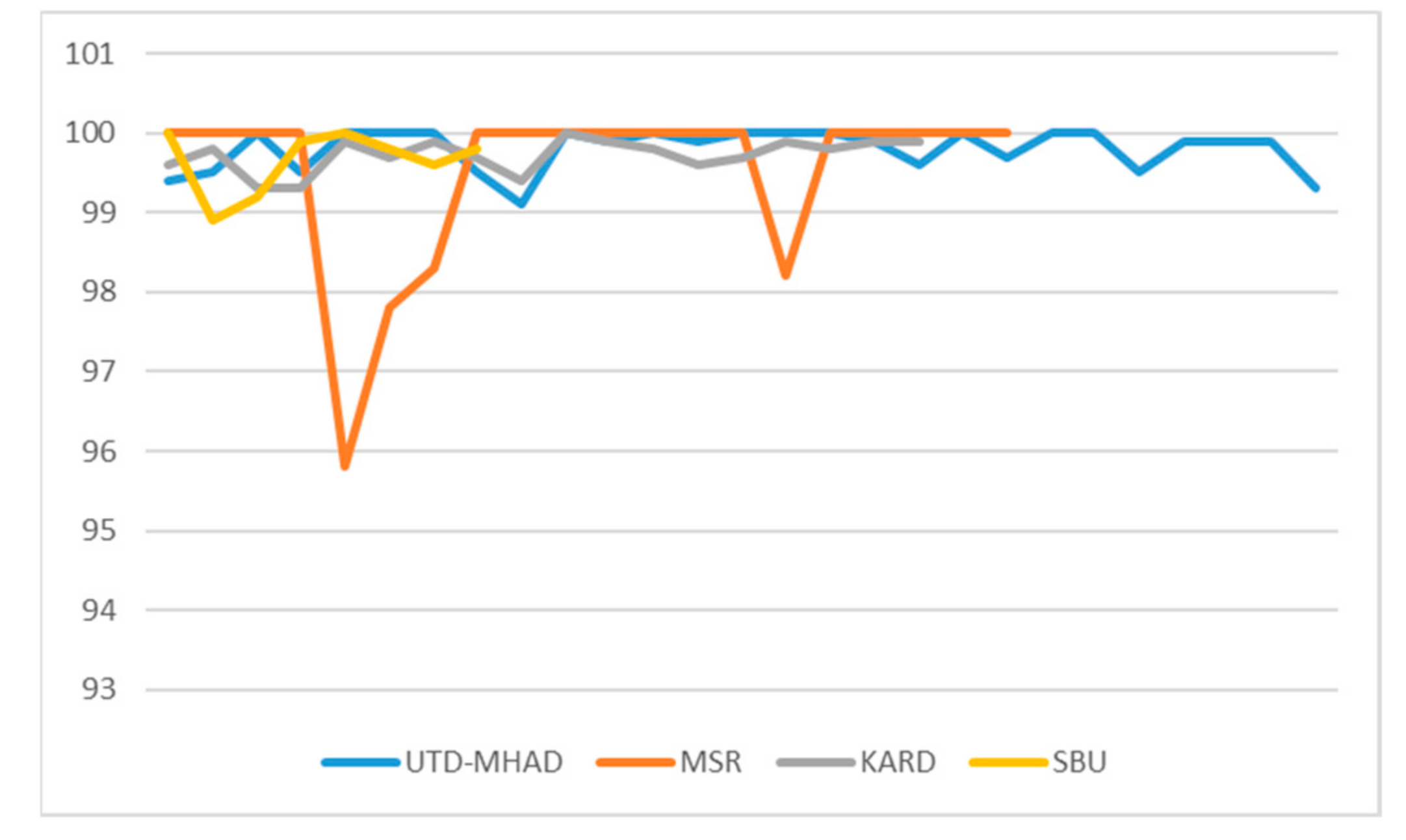
- We show that the suggested FGP-3D is tested on demanding datasets and exhibits a consistent level of accuracy, making it a useful and generic methodology for skeleton-based action classification.
2. Related Work
3. Proposed Approach
3.1. Anchored Point
3.2. Fully Gated Unit Features
- : Skeletal joints’ three dimensions are located in the third-dimension (3D).
- : Output motion vector generated from a fully gated unit (3D).
- : Information about the anchored point is included in the 3D activation vector, i.e., , , and .
- : 3D update gate vector, containing details, i.e., , , and .
- : In order to accurately capture motion details, the reset gate vector contains the mutual information shared by all of the 3D information of skeletal joint spatial information.
- Parameter vectors will be calculated by using any particular joint , located in the 3D domain. The contain abscissa information for , contain abscissa information for , and contain abscissa information for .
- Any particular joint situated in the 3D domain will be used to construct parameter vectors.
- By employing any specific joint , located in the 3D domain, parameter vectors will be computed.
3.3. Fully Popovicius Features
3.4. Fully Gated and Anchored Approach, FGP-3D
4. Evaluation of FGP-3D
5. Experiments and Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shi, J.; Zhang, Y.; Wang, W.; Xing, B.; Hu, D.; Chen, L. A Novel Two-Stream Transformer-Based Framework for Multi-Modality Human Action Recognition. Appl. Sci. 2023, 13, 2058. [Google Scholar] [CrossRef]
- Kim, M.; Jiang, X.; Lauter, K.; Ismayilzada, E.; Shams, S. Secure human action recognition by encrypted neural network inference. Nat. Commun. 2022, 13, 4799. [Google Scholar] [CrossRef]
- Islam, M.S.; Bakhat, K.; Iqbal, M.; Khan, R.; Ye, Z.; Islam, M.M. Representation for action recognition with motion vector termed as: SDQIO. Expert Syst. Appl. 2023, 212, 118406. [Google Scholar] [CrossRef]
- Luvizon, D.C.; Picard, D.; Tabia, H. Multi-task deep learning for real-time 3D human pose estimation and action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2752–2764. [Google Scholar] [CrossRef]
- Yang, D.; Wang, Y.; Dantcheva, A.; Garattoni, L.; Francesca, G.; Bremond, F. Unik: A unified framework for real-world skeleton-based action recognition. arXiv 2021, arXiv:2107.08580. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New York, NY, USA, 9–11 February 2018. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Zheng, W.; Li, L.; Zhang, Z.; Huang, Y.; Wang, L. Relational network for skeleton-based action recognition. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 826–831. [Google Scholar]
- Kim, T.S.; Reiter, A. Interpretable 3D human action analysis with temporal convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 20–28. [Google Scholar]
- Caetano, C.; Brémond, F.; Schwartz, W.R. Skeleton image representation for 3D action recognition based on tree structure and reference joints. In Proceedings of the 2019 32nd SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Rio de Janeiro, Brazil, 28–30 October 2019; pp. 16–23. [Google Scholar]
- Li, C.; Zhong, Q.; Xie, D.; Pu, S. Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation. arXiv 2018, arXiv:1804.06055. [Google Scholar]
- Lei, S.; Zhang, Y.; Cheng, J.; Lu, H. Decoupled spatial-temporal attention network for skeleton-based action recognition. arXiv 2020, arXiv:2007.03263. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3595–3603. [Google Scholar]
- Gao, X.; Hu, W.; Tang, J.; Liu, J.; Guo, Z. Optimized skeleton-based action recognition via sparsified graph regression. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 601–610. [Google Scholar]
- Liu, Z.; Zhang, H.; Chen, Z.; Wang, Z.; Ouyang, W. Disentangling and unifying graph convolutions for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 143–152. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12026–12035. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-based action recognition with multi-stream adaptive graph convolutional networks. IEEE Trans. Image Process. 2020, 29, 9532–9545. [Google Scholar] [CrossRef]
- Elmadany, N.E.D.H.; He, Y.; Guan, L. Multimodal learning for human action recognition via bimodal/multimodal hybrid centroid canonical correlation analysis. IEEE Trans. Multimed. 2018, 21, 1317–1331. [Google Scholar] [CrossRef]
- Kamel, A.; Sheng, B.; Yang, P.; Li, P.; Shen, R.; Feng, D.D. Deep convolutional neural networks for human action recognition using depth maps and postures. IEEE Trans. Syst. Man Cybern. Syst. 2018, 49, 1806–1819. [Google Scholar] [CrossRef]
- Yang, T.; Hou, Z.; Liang, J.; Gu, Y.; Chao, X. Depth Sequential Information Entropy Maps and Multi-Label Subspace Learning for Human Action Recognition. IEEE Access 2020, 8, 135118–135130. [Google Scholar] [CrossRef]
- Dawar, N.; Ostadabbas, S.; Kehtarnavaz, N. Data Augmentation in Deep Learning-Based Fusion of Depth and Inertial Sensing for Action Recognition. IEEE Sens. Lett. 2018, 3, 1–4. [Google Scholar] [CrossRef]
- Dawar, N.; Kehtarnavaz, N. Action Detection and Recognition in Continuous Action Streams by Deep Learning-Based Sensing Fusion. IEEE Sens. J. 2018, 18, 9660–9668. [Google Scholar] [CrossRef]
- Ben Mahjoub, A.; Atri, M. An efficient end-to-end deep learning architecture for activity classification. Analog Integr. Circuits Signal Process. 2019, 99, 23–32. [Google Scholar] [CrossRef]
- Ahmad, Z.; Khan, N. Human action recognition using deep multilevel multimodal (${M}^{2} $) fusion of depth and inertial sensors. IEEE Sens. J. 2019, 20, 1445–1455. [Google Scholar] [CrossRef]
- Núñez, J.C.; Cabido, R.; Pantrigo, J.J.; Montemayor, A.S.; Vélez, J.F. Convolutional Neural Networks and Long Short-Term Memory for skeleton-based human activity and hand gesture recognition. Pattern Recognit. 2018, 76, 80–94. [Google Scholar] [CrossRef]
- Basly, H.; Ouarda, W.; Sayadi, F.E.; Ouni, B.; Alimi, A.M. CNN-SVM learning approach based human activity recognition. In International Conference on Image and Signal Processing; Springer: Cham, Switzerland, 2020; pp. 271–281. [Google Scholar]
- Sial, H.A.; Yousaf, M.H.; Hussain, F. Spatio-temporal RGBD cuboids feature for human activity recognition. Nucleus 2018, 55, 139–149. [Google Scholar]
- Dhiman, C.; Vishwakarma, D.K. A Robust Framework for Abnormal Human Action Recognition Using $\boldsymbol {\mathcal {R}} $-Transform and Zernike Moments in Depth Videos. IEEE Sens. J. 2019, 19, 5195–5203. [Google Scholar] [CrossRef]
- Jin, K.; Jiang, M.; Kong, J.; Huo, H.; Wang, X. Action recognition using vague division DMMs. J. Eng. 2017, 2017, 77–84. [Google Scholar] [CrossRef]
- Ashwini, K.; Amutha, R. Compressive sensing based recognition of human upper limb motions with kinect skeletal data. Multimed. Tools Appl. 2021, 80, 10839–10857. [Google Scholar] [CrossRef]
- Islam, M.S.; Bakhat, K.; Khan, R.; Iqbal, M.; Ye, Z. Action recognition using interrelationships of 3D joints and frames based on angle sine relation and distance features using interrelationships. Appl. Intell. 2021, 51, 6001–6013. [Google Scholar] [CrossRef]
- Islam, M.S.; Bakhat, K.; Khan, R.; Naqvi, N.; Ye, Z. Applied Human Action Recognition Network Based on SNSP Features. Neural Process. Lett. 2022, 54, 1481–1494. [Google Scholar] [CrossRef]
- Bakhat, K.; Kifayat, K.; Islam, M.S. Human activity recognition based on an amalgamation of CEV & SGM features. J. Intell. Fuzzy Syst. 2022, 43, 7351–7362. [Google Scholar]
- Manzi, A.; Fiorini, L.; Limosani, R.; Dario, P.; Cavallo, F. Two-person activity recognition using skeleton data. IET Comput. Vis. 2017, 12, 27–35. [Google Scholar] [CrossRef]
- Zhu, W.; Lan, C.; Xing, J.; Zeng, W.; Li, Y.; Shen, L.; Xie, X. Co-occurrence feature learning for skeleton based action recognition using regularized deep LSTM networks. In Proceedings of the AAAI Conference on Artificial Intelligence; AAAI Press: Palo Alto, CA, USA, 2016; Volume 30. [Google Scholar]
- Jalal, A.; Khalid, N.; Kim, K. Automatic Recognition of Human Interaction via Hybrid Descriptors and Maximum Entropy Markov Model Using Depth Sensors. Entropy 2020, 22, 817. [Google Scholar] [CrossRef] [PubMed]
- Waheed, M.; Jalal, A.; Alarfaj, M.; Ghadi, Y.Y.; Al Shloul, T.; Kamal, S.; Kim, D.-S. An LSTM-Based Approach for Understanding Human Interactions Using Hybrid Feature Descriptors Over Depth Sensors. IEEE Access 2021, 9, 167434–167446. [Google Scholar] [CrossRef]
- Bakhat, K.; Kifayat, K.; Islam, M.S. Katz centrality based approach to perform human action recognition by using OMKZ. Signal Image Video Process. 2022, 1–9. [Google Scholar] [CrossRef]
- Islam, M.S.; Iqbal, M.; Naqvi, N.; Bakhat, K.; Islam, M.M.; Kanwal, S.; Ye, Z. CAD: Concatenated action descriptor for one and two person (s), using silhouette and silhouette’s skeleton. IET Image Process. 2020, 14, 417–422. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A multimodal dataset for human action recognition uti-lizing a depth camera and a wearable inertial sensor. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 168–172. [Google Scholar]
- Li, W.; Zhang, Z.; Liu, Z. Action recognition based on a bag of 3D points. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 9–14. [Google Scholar]
- Gaglio, S.; Re, G.L.; Morana, M. Human Activity Recognition Process Using 3-D Posture Data. IEEE Trans. Hum. Mach. Syst. 2014, 45, 586–597. [Google Scholar] [CrossRef]
- Yun, K.; Honorio, J.; Chattopadhyay, D.; Berg, T.L.; Samaras, D. Two-person interaction detection using body-pose features and multiple instance learning. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 28–35. [Google Scholar]
- Lu, T.-W.; Chang, C.-F. Biomechanics of human movement and its clinical applications. Kaohsiung J. Med Sci. 2012, 28, S13–S25. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Popoviciu, T. Sur certaines inégalités qui caractérisent les fonctions convexes. Analele Stiintifice Univ.“Al. I. Cuza”. Iasi Sect. Mat. 1968, 11, 155–164. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy (%) |
|---|---|
| BHCCCA [18] DCNN [19] MLSL [20] | 84.6 88.14 88.37 |
| Fusion of Depth [21] Sensing Fusion [22] End-to-end CNN-LSTM [23] [24] | 89.2 92.8 98.5 99.2 |
| FGP-3D | 99.8 |
| Method | Accuracy (%) |
|---|---|
| CNN + LSTM [25] DTR-HAR [26] | 63.10 91.56 |
| D-STIP + D-DESC [27] R-Transform + Zernike [28] DMM [29] | 92.00 94.88 96.50 |
| FGP-3D | 99.4 |
| Method | Accuracy (%) |
|---|---|
| R-Transform + Zernike [28] | 96.64 |
| Sensing [30] ASD-R [31] SNSP [32] CEV and SGM [33] | 97.22 97.6 97.8 99.4 |
| FGP-3D | 99.8 |
| Method | Accuracy (%) |
|---|---|
| Skeletal data [34] Deep LSTM [35] Hybrid feature [36] Hybrid descriptors [37] OMKZ [38] | 88 90.41 91.25 91.63 93.80 |
| CAD [39] | 95.6 |
| FGP-3D | 99.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Islam, M.S.; Algosaibi, A.; Rafaqat, W.; Bakhat, K. Employing FGP-3D, a Fully Gated and Anchored Methodology, to Identify Skeleton-Based Action Recognition. Appl. Sci. 2023, 13, 5437. https://doi.org/10.3390/app13095437
Islam MS, Algosaibi A, Rafaqat W, Bakhat K. Employing FGP-3D, a Fully Gated and Anchored Methodology, to Identify Skeleton-Based Action Recognition. Applied Sciences. 2023; 13(9):5437. https://doi.org/10.3390/app13095437
Chicago/Turabian StyleIslam, M Shujah, Abdullah Algosaibi, Warda Rafaqat, and Khush Bakhat. 2023. "Employing FGP-3D, a Fully Gated and Anchored Methodology, to Identify Skeleton-Based Action Recognition" Applied Sciences 13, no. 9: 5437. https://doi.org/10.3390/app13095437
APA StyleIslam, M. S., Algosaibi, A., Rafaqat, W., & Bakhat, K. (2023). Employing FGP-3D, a Fully Gated and Anchored Methodology, to Identify Skeleton-Based Action Recognition. Applied Sciences, 13(9), 5437. https://doi.org/10.3390/app13095437