Abstract
Rumors may bring a negative impact on social life, and compared with pure textual rumors, online rumors with multiple modalities at the same time are more likely to mislead users and spread, so multimodal rumor detection cannot be ignored. Current detection methods for multimodal rumors do not focus on the fusion of text and picture-region object features, so we propose a multimodal fusion neural network TDEDA (dual-attention based on textual double embedding) applied to rumor detection, which performs a high-level information interaction at the text–image object level and captures visual features associated with keywords using an attention mechanism. In this way, we explored the ability to enhance feature representation with assistance from different modalities in rumor detection, as well as to capture the correlations of the dense interaction between images and text. We conducted comparative experiments on two multimodal rumor detection datasets. The experimental results showed that TDEDA could reasonably handle multimodal information and thus improve the accuracy of rumor detection compared with currently relevant multimodal rumor detection methods.
1. Introduction
In recent years, with the rapid progress of multimedia technology, the form of news or tweets has gradually changed to multimedia, and traditional media has been replaced by social networks and become an important platform for information exchange; information on social networks has the advantage of a rapid dissemination, wide coverage, and other characteristics of immediacy. For example, on Weibo, Twitter, and other social networking platforms, there are a lot of tweets published every day. At the same time, the content of news or tweets is no longer just plain text but a combination of text and visual content is becoming popular. Compared with plain text, images and videos have good visual effects, which can not only spread information but also capture people’s attention and provide rich visual information [1]. The pictures and videos in rumors take advantage of this feature, using exaggerated pictures that are doctored or completely falsified and then adding text descriptions to spread negative information. However, since users on the network cannot be effectively supervised in real time when posting information, this leads to the spread of rumor by taking advantage of social network platforms, which makes it easier for false information to negatively affect the social fabric and thus may even pose a certain threat to national and regional security. Therefore, we adopt a multimodal approach to rumor detection, which is more in line with the current development trend of social network platforms and also contributes to the purification of the network environment and the maintenance of public social security.
The current paradigm of rumor detection methods is shifting from purely text-based content to a multimodal detection paradigm. Among the research approaches that focus on textual content, social information, or communication structure content, some of the works use feature-based structure detection methods with textual and user information as the main features. In contrast, other works consider factors such as transmission time, transmission structure, and language features.Among the rumor detection methods using visual features combined with textual features, Jin et al. [2] extracted text and social context features using a recurrent neural network (RNN) [3] and extracted image features using a pretrained VGG-16 network, after which the text and image features were stitched together and put into the classifier for detection. Wang et al. [4] added an event identifier to understand common features among events, which helped to detect unanticipated new events. Khattar et al. [5] proposed a multimodal variational self-encoder to discover the correlation between modalities. Zhou et al. [6] designed a similarity-aware rumor detection method that combined similarity features with the connection of text features and visual features to identify fake posts. Song et al. [7] carried out rumor detection by purposefully extracting key feature information related to the detection target mode from a mode. Chen et al. [8] used an adaptive aggregation of single-mode features and cross-mode correlation to improve the accuracy of rumor detection by analyzing cross-mode ambiguity learning problems.
In summary, many methods have been proposed to detect rumors. Although previous research has made great progress, two problems remain:
- Challenge 1: How to effectively utilize the internal dependencies of text and the dependencies of the local and global features of images to assist in the construction of multimodal rumor features?
- Challenge 2: How to make full use of the dense interaction information within and between modalities to increase the granularity of understanding and improve rumor detection performance?
To deal with the above challenges, a multimodal fusion neural network (dual-attention based on textual double embedding, TDEDA) based on textual double embedding is used for information interaction between text and visual objects. The model has three parts: modal feature extraction, modal feature fusion, and rumor detector. The multimodal feature extraction part includes a text feature extraction and visual feature extraction: for the text feature extraction, we use a pretrained BERT (Bidirectional Encoder Representations from Transformers) [9] to extract word features and sentence features; for the visual feature extraction, we use a pretrained ResNet50 [10] to obtain visual object features. The multimodal feature fusion part includes a text self-attention module and a visual self-attention module, and a text–visual coattention module. Finally, the fused textual and visual features are fed into the rumor detector for the multimodal rumor detection. The three main contributions of this paper are the following:
- A multimodal fusion neural network (TDEDA) is proposed for rumor detection. TDEDA explores the internal dependencies between local text features by building dual-embedding representations of words and sentences of text and captures the global feature representations of images through visual self-attention, helping to build and improve the feature representations of the text and image.
- Based on the enhanced text and visual feature representations, the information enhancement between modalities is achieved based on a dual coattention mechanism to discover the extensive interaction information between words and visual objects.
- A large number of experiments are conducted to validate the effectiveness of this method on a multimodal rumor detection dataset collected from Weibo and Twitter. The results show that TDEDA outperforms other baseline models in multimodal rumor detection.
This paper is organized as follows: In Section 2, we give a general introduction to the research on rumor detection and multimodal fusion. In Section 3, we introduce TDEDA and its specific implementation details. In Section 4, we present information about the relevant datasets, the comparison model, and the specific setup of the experiment. In Section 5, we report the experimental results and perform the analysis. Finally, in Section 6, the full paper is summarized.
2. Related Work
In this section, we review the related work involved in the proposed TDEDA model. It mainly deals with the rumor detection task and the fusion of features between multiple modalities.
2.1. Rumor Detection
The rumor detection task is similar to many tasks, such as spam detection [11] and satirical article detection [12]. Based on the related work of previous researchers, we define false information that can be officially confirmed as rumors.
Early research focused on effective feature extraction from manual settings, including the linguistic features of the message itself, and the contextual features of the communicative process. Castillo et al. [13] used statistics on textual information such as special characters, number of links, etc., to detect rumors. Qazvinian et al. [14] studied features such as the subject of tweets and used Bayesian networks as classifiers to identify rumors. Kwon et al. [15] found that disinformation releases had more significant periodic fluctuations and used random forests to fit time-series features. Wu et al. [1] introduced propagation trees into rumor detection models and used a kernelized random walk algorithm to construct classifiers. These research methods were mainly based on manual feature extraction for modeling, which required complex feature engineering.
With the development of deep learning, based on the above-mentioned, some scholars started to explore rumor detection using deep learning as a way to offset the drawbacks of using manual approaches for feature extraction. For example, in terms of content and propagation structure based on rumor texts, Ma et al. [16] analyzed the syntax and semantics in text using a model based on recurrent neural networks (RNNs) with complex recurrent units and additional hidden layers and features that could be used to learn hidden representations and capture contextual information about relevant posts over time, and they used the captured contextual information for rumor detection. Chen et al. [17] proposed a deep attention model that leveraged recurrent neural networks (RNNs) to selectively learn the temporal hidden representations of sequential posts, with the aim of identifying rumors. In their paper, the authors undertook a comprehensive study of the recursive nature of RNNs, analyzing features with specific weights to capture hidden feature representations of rumors and contextual changes in related posts over time. Yu et al. [18] proposed a convolutional approach for misinformation identification (CAMI), which leveraged a convolutional neural network (CNN) for the purpose of detecting rumor information. CAMI was able to extract pivotal features that were dispersed throughout an input sequence and to shape elevated-level interactions among significant features. This enabled the effective identification of rumor and facilitated the timely detection of misinformation in practice.
In terms of rumor propagation structure, Ma et al. [19] also proposed a novel neural network architecture that adopted both bottom-up and top-down tree structures. That architecture was designed to effectively extract discriminative feature content from tweets via a discontinuous propagation structure and subsequently generate multiple feature representations to enable an accurate identification and classification of rumors. Zhang et al. [20] proposed a model that could automatically determine the credibility of news based on the unknown attributes of fake news and the connection between articles, authors, and news topics. The model extracted explicit and implicit features in the text and identified rumors by building a deep spreading network. Liu et al. [21] built a time-series classifier to capture the content of tweets, the connection between author and topic, and the change of user features in the propagation path, respectively.
Currently, media news on social networks usually consists of text, images, or videos, and it has been proved that rich visual representation in media news can also provide effective information [22]. Among the text–image-based rumor detection methods, Jin et al. [2] proposed a novel recurrent neural network with an attention mechanism (att-RNN). In this end-to-end network, joint features of text and social context were extracted using an LSTM network and image features using a VGG19 network. Moreover, the multimodal features were fused to generate a reliable fusion classification and perform an effective rumor detection. Wang et al. [4] proposed an end-to-end framework called Event Adversarial Neural Network (EANN) to identify fake news in emerging events. It could derive event invariant features for the fake news detection of unseen events. It consisted of three main components: a multimodal feature extractor, a fake news detector, and an event identifier. They were used to extract features, detect rumors, remove event-specific features, and maintain shared features between events, respectively. Khattar et al. [5] used a multimodal variational autoencoder (MVAE) to explore the correlation of different modalities and obtain a direct joint representation of the modalities.Moreover, Zhou et al. [6] proposed a similarity-aware rumor detection method SAFE (Similarity-Aware FakE news detection), which investigated the relationship between features extracted across modalities, jointly learned the feature representation and the interrelationship between news text information and visual information, and identified news articles as rumor information based on the text, image, or “mismatch” between the two. Song et al. [7] proposed a model for multimodal rumor detection based on cross-modal attention residuals and multichannel convolutional neural networks, CARMN (Attention Residual and Multichannel convolutional neural Networks). The model performed a selective extraction of information related to the target modality and could extract text features from both the original text and the fused text simultaneously; based on this method, the authors reduced the noise impact of the modality fusion process. Chen et al. [8] proposed a multimodal rumor detection method based on ambiguity perception, called CAFE. The method included a cross-modal alignment module, a cross-modal ambiguity learning module, and a cross-modal fusion module. CAFE could adaptively aggregate the single-mode and cross-mode correlation features, that is, it relied on the single-mode feature when the cross-mode fuzziness was weak and referred to the cross-mode correlation when the cross-mode fuzziness was strong, so as to improve the accuracy of the rumor detection.
In summary, it can be found that the exploration of feature information within different modalities has not been fully explored, and multimodal rumor detection by feature splicing only in the fusion stage loses valid information and leads to a redundancy of modal information.
2.2. Multimodal Feature Fusion
Multimodal feature fusion refers to the effective processing of several different types of modal features; the information complementarity between modalities is reasonably accomplished and solves the possible redundancy problems to obtain richer deep fusion features. Zadeh et al. [23] proposed a matrix-based multimodal tensor fusion network (TFN) to obtain modal correlations by computing the tensor outer product between different modes. Hou et al. [24] considered modal local relations and established polynomial tensor pooling blocks that integrated multimodal features through higher-order matrices. Xu et al. [25] extracted the interactive information between modes by using an attention mechanism among different modes.
The above approaches verified that it was possible to obtain a more informative multimodal representation by combining features of multiple modalities.
To overcome the limitations of research on multimodal fusion for rumor detection, we propose a multimodal fusion neural network called TDEDA. This fusion neural network achieves internal information enhancement between words, between visual objects, and information interaction at the word–visual object level. The updated text features are fused with the visual features and received by the rumor detector to perform rumor detection.
3. Multimodal Fusion Network Based on Attention Mechanism
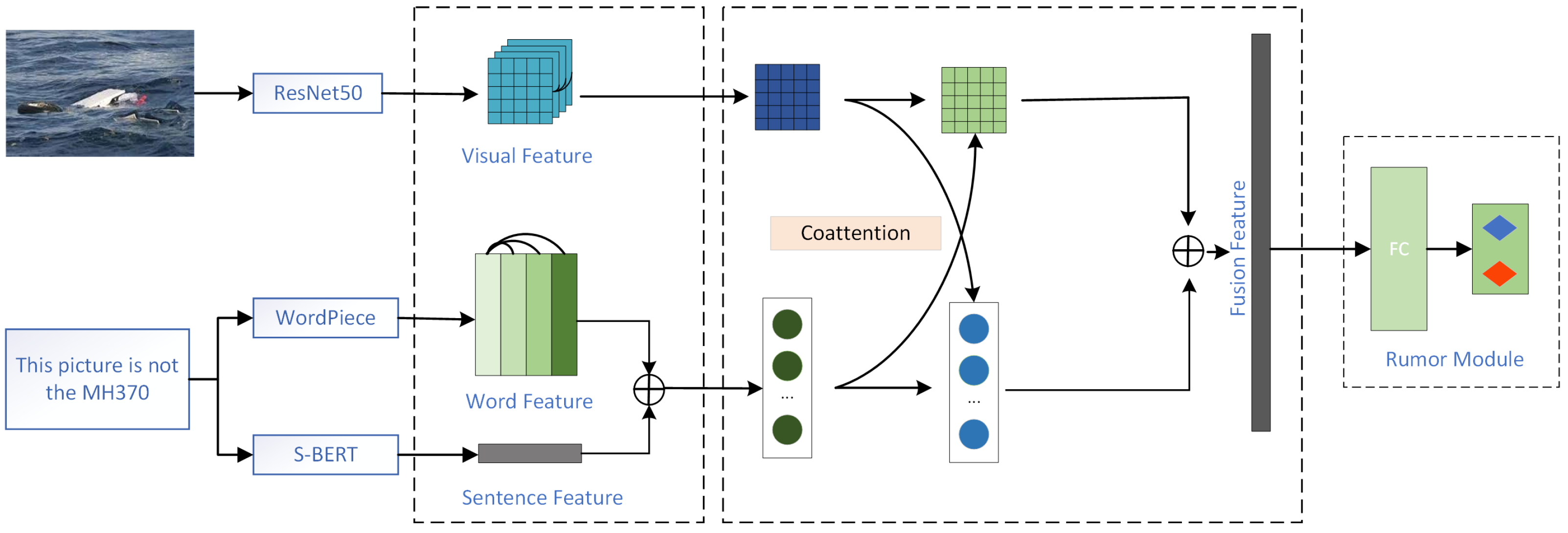
The model structure of the multimodal fusion neural network TDEDA is shown in Figure 1, where the input consists of text–image pairs, where the text is extracted as word features and sentence features, and pictures are obtained as visual object features based on picture object regions.
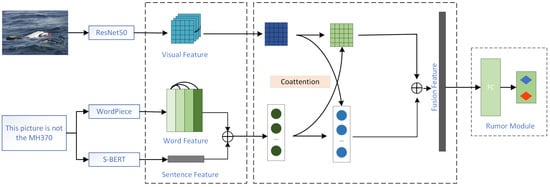
Figure 1.
Network structure of TDEDA.
TDEDA consists of the following three parts:
- A feature extractor extracts potential features from multimodal inputs consisting of text and additional images;
- A multimodal fusion module conveys information between text and visual objects, enhances the information within and the information interaction between modalities, and fuses features between modalities;
- A rumor detector uses a deep fusion of features to determine whether a tweet is a rumor or not.
3.1. Feature Extractor
The single input of TDEDA consisted of text and images, and the feature extractor allowed us to obtain potential features about the text and images. The feature extractors were classified into text feature extractors and visual feature extractors according to the input content category.
3.1.1. Text Feature Extractor
The input to the text feature extractor consisted of many sentences of unequal length, and we first split all sentences into words, where the word information can ensure that the model selects the correct keywords for visual inference to predict rumors during feature understanding. However, using only a single-word representation can lead to difficulties in correctly understanding a given rumor utterance. Therefore, we compensated for this deficiency by learning the overall semantics of the rumor text. This was to ensure that the extracted features were rich in rumor keyword information. For the given rumor text, we used a WordPiece token to mark it as a few words and then projected it to the embedding layer to obtain a sequence of n words .
To capture the underlying semantic and contextual meaning, we employed a pretrained BERT to extract sentence features. Since BERT is essentially a multilayer dual-transformer encoder based on the original implementation described in Gao et al. [26], in TDEDA, we used pretrained to extract the text feature information.
where T is the input text and the output is a sentence vector feature , where the i-th word is denoted as , d is the dimension of the word vector extracted from WordPiece, and is the dimension of the sentence vector.
The text feature extractor yielded the word feature matrix T and the sentence features S to obtain a double-embedding representation of the rumor text.
3.1.2. Visual Feature Extractor
Each image of a tweet was processed into a feature matrix consisting of a set of image objects that were extracted by a pretrained target detection. Each object represented a person, action, object, or interaction between two people in the image. CNNs have been successfully applied for various visual understanding problems [27]. In this paper, we used a pretrained [10] to extract visual features from the images on the corresponding posts, capturing n objects in the images. Moreover, to obtain more detailed visual feature information, we extracted fine-grained regional features of additional images through the penultimate layer of a ResNet model.
where represents the features corresponding to region i, represents the dimension of regional features, and R represents the feature stitching of each region of the image. The row vector corresponds to the potential features of a picture object.
3.2. Multimodal Fusion Module
Considering the feature enhancement between words and between visual objects and the potential connections that may exist between each word and visual object, we constructed three basic modules: a textual self-attention module, a visual self-attention module, and a textual-visual co-attention module.
3.2.1. Textual Double-Embedding and Self-Attention Module
For text sentences in rumor detection, recurrent neural networks with a certain amount of structure are usually used, such as LSTM and GRU layers for representation learning to build sentence models [28,29]. However, recurrent neural networks do not capture well the internal information words in different dependencies between positions. They are also costly in terms of time, especially when dealing with long sentences: the attention mechanism is more focused on capturing the internal dependencies between words than the recurrent network. To use the attention mechanism, which uses key–value pairs to query the dictionary, it is possible to reconstruct the information based on the similarity of elements [30], as shown in the following equation:
where denotes the dimension of the key. Inspired by TUDE (Transformer with Untied Positional Encoding) [31], we included sentence information in the relational modeling of each word pair to reduce the loss of semantic information.
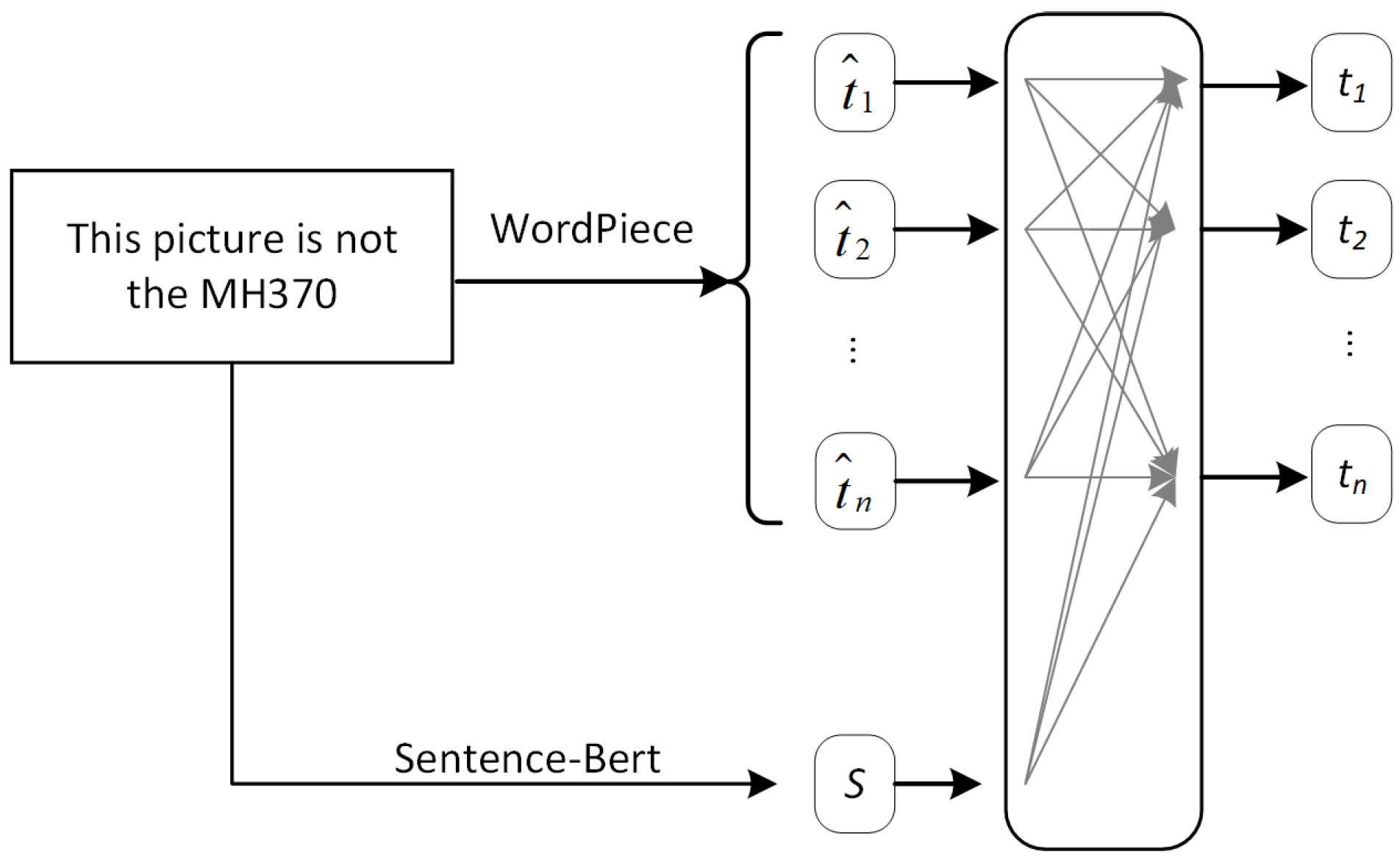
Specifically, we combined the embedded words and sentences in the following way. Word information could ensure that the TDEDA model chose the right keywords to interact with visual features in the process of feature understanding and further inferred whether the tweet was rumor information or not. The purpose of marking with WordPiece was to process the text information into continuous word information and to facilitate the presentation and extraction of word information and sentence information through a self-attention embedded representation, as shown in Figure 2.
where denotes the matrix of learnable items of . denotes the moment of learning items of the S matrix, and is the dimension of the text feature space. Then, we obtained the double-embedding representation of the rumor text, . By this method, the internal dependencies between words and the information of sentences were encoded to represent the semantics of the text more effectively.
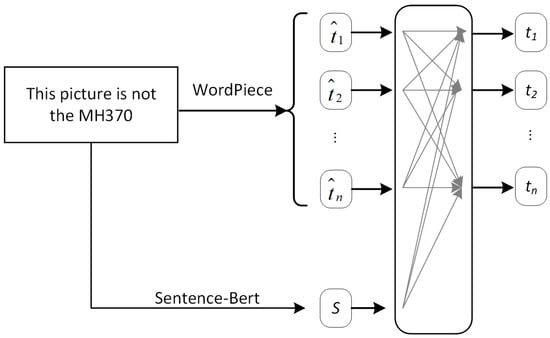
Figure 2.
Double-embedding structure of the text.
3.2.2. Image Self-Attention Module
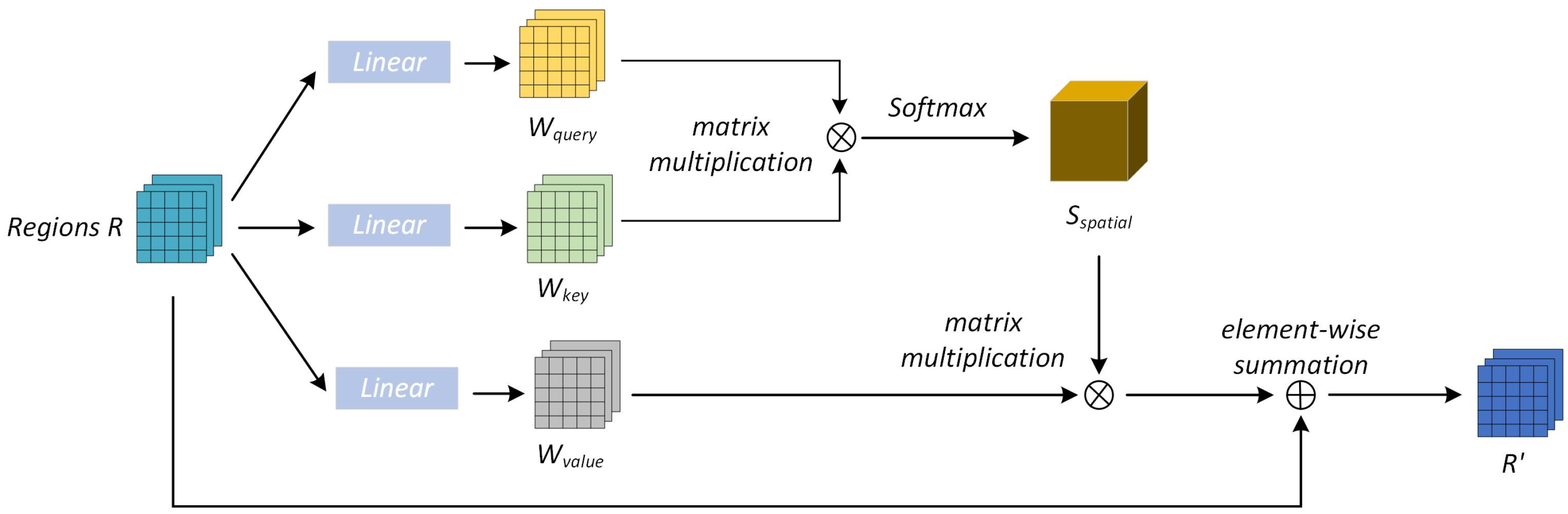
For an image in rumor detection, the key to infer whether the image representation is a rumor is usually the interactive feature information of each region. However, the regional features of images are usually extracted using pretrained deep convolutional neural networks. In deep convolutional neural networks, the computation of a self-convolution has a local acceptance domain, which cannot obtain the internal dependencies between global contextual information and local features. To address this limitation, we devised a visual self-attention method, which could take advantage of the internal dependencies of the image to capture a richer visual representation by weighting and aggregating the features in each region of the global image, as shown in Figure 3.
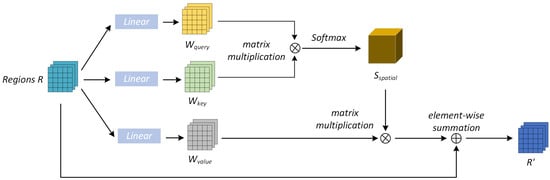
Figure 3.
Structure of the image self-attention module.
For image V, we used ResNet50 to extract regional features . Before the self-attention calculation, the dimension of the extracted image features should be reduced first. Then, the design resulted in a final feature mapping size that scaled to 1/8 of the input image and fed the region features R into a convolutional layer with a batch convolutional layer with normalization and ReLU layers. Two new feature maps and were generated, and represented and in Figure 3, respectively. Then, both and were reshaped as , and the number of regions of the image was . Then, to measure their interdependence, the transpositions of and were matrix-multiplied separately, and the spatial position of the attention map was evaluated using a softmax layer. Each element in P was calculated using the following formula:
where is to measure the influence of the ith region on the jth region. It is worth noting that the similarity of the two regions was directly proportional to the correlation. Meanwhile, the new feature map was input to the batch-normalized convolutional layer with the regional features r and ReLU layers. Here, stands for in Figure 3. Similarly, was reshaped into . Then, a matrix multiplication of the transpose of with P reshaped the result into the original image region of the same size.
Thus, for each region, the feature was a weighted sum of the original region features and the new features of all regions. Thus, it oculd be considered that feature had the global contextual information, and based on that, the extensive contextual information was encoded as local features. The mutual gain of similar regions was achieved, thus capturing a richer and more effective image representation.
3.2.3. Feature Fusion Module for Text–Visual Coattention
Given an original tweet and an attached image, the words in the tweet are actually associated with the areas of the image that are usually associated with each other. Most existing multimodal rumor detection methods use only visual attention mechanisms, and a few methods use joint-attention mechanisms to capture these multimodal correlations between images and tweets. How to effectively integrate the information between different modes and capture the more extensive information interaction between text and image modes is still a problem that needs further study.
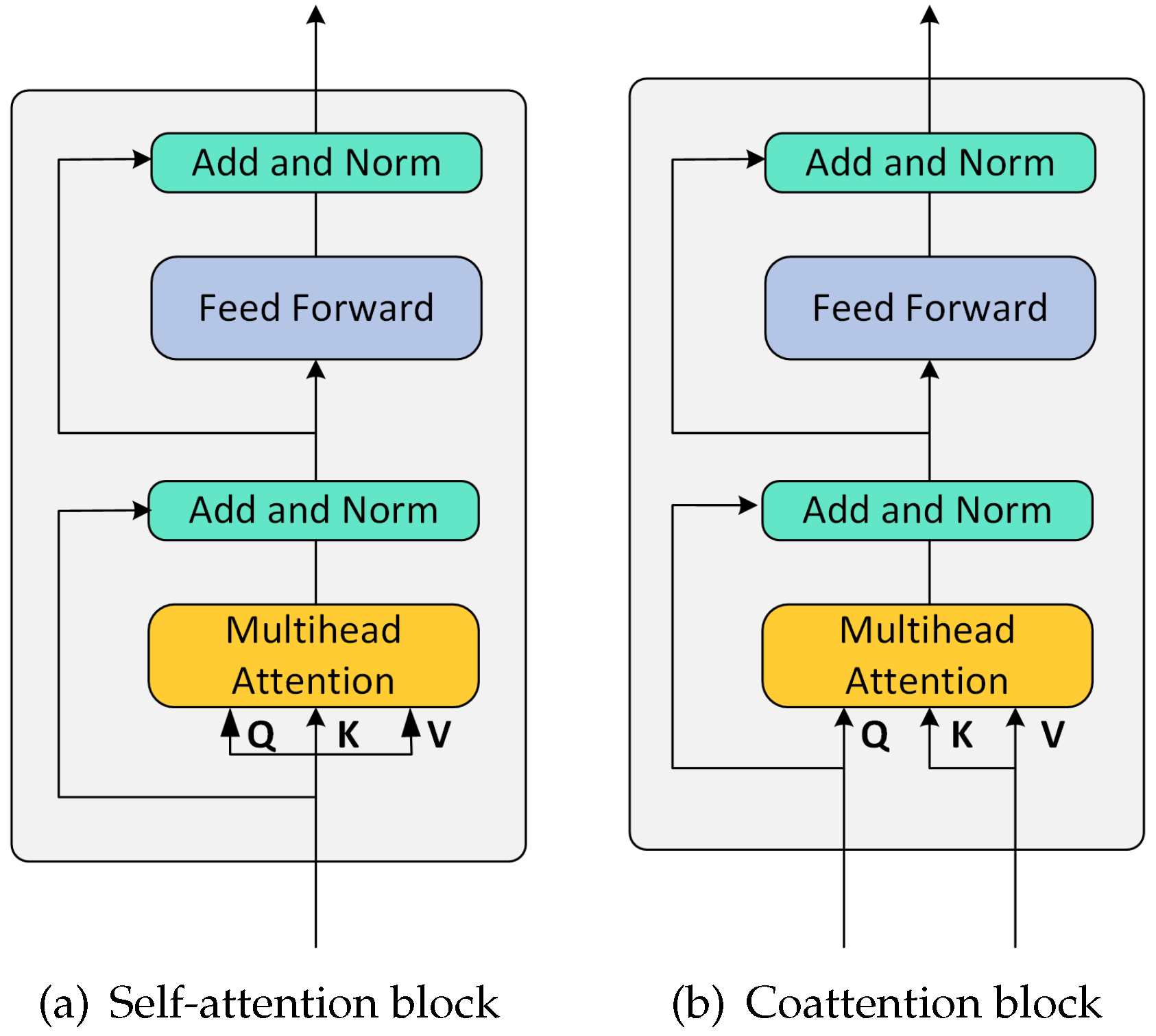
In this section, we introduce a new mechanism that combines visual attention and textual attention for reasoning. We call it visual–textual joint attention. First, we cover the two basic attention blocks, as shown in Figure 4.
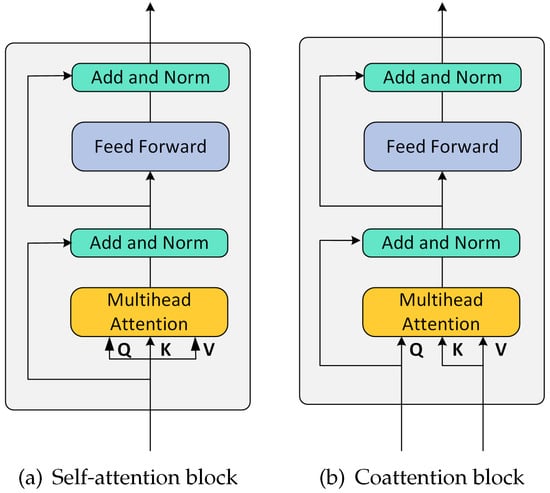
Figure 4.
Self-attention blocks and Coattention blocks.
These two blocks were inspired by the attention of the dot product adopted in the transformer model. The input to the scaled dot product attention consisted of the queries and keys of dimension and the values of dimension . To simplify the process, we set and to have the same dimension d. We computed the dot product of queries with all keys, divided each key by , and applied the softmax function to get the attention weights of the values. At the same time, the representation of the participation features was improved by introducing a multihead attention, which consisted of h parallel “heads”. Each head corresponded to an independent dot product attention function. Among the multiple self-attention (MSA) blocks [30], the coattention block [32] was a variant of its standard form, and this variant differed from previous approaches in terms of its modal fusion and the probabilistic computation of attention to obtain global dependencies for each position in the sequence. Thus, for multimodal rumors, we could obtain a richer representation of the features between the modalities.
As shown in Figure 4a, the MSA had two components: a fully connected feed-forward network and a multiheaded self-attention function, respectively. Two components used a residual connection before performing a layer normalization. The MSA first computed (d × 1) dimensional queries, keys, and values before inputting them to the matrices Q, K, and V. Where the attention distribution of V was determined by the similarity of the dot product between Q and K, and the attention function with m heads then contained m parallel self-attention functions. Then, for the i-th head, the input was obtained by transforming Q, K, and V as the following equation:
where are the projection matrices of the ith head, and is the dimensionality of the output features of each head.
The procedure for calculating the multiheaded self-attention function was as follows:
where , ⊕ represents the cascade of vectors. The fully connected feed-forward network included, in addition to the intermediate ReLU activation function, two linear transformations. For an inner dimension of , the input and output dimensions were .
In Figure 4b, a common attention block (denoted hereafter as “Co-Attn”) is shown, where the query comes from one modality and the key and value from another modality. In particular, the residual terms after the attention sublayer (multihead) were used by the query matrix, and the rest of the architecture was the same as that of MSA. The Co-Attn block generated an attention pool feature for a modality conditional on another modality. If Q was from the image and k and V were from the rumor text, then the attention values computed with Q and k could be used as a measure of similarity between the image and the text, which was then weighted by the text. In this way, feature dependencies between different modalities were obtained.
In the text–image dual coattention part, we obtained the CA layer by joining two Co-Attn blocks in a parallel way, where the CA layer was computed in the same way as in the MSA block. The query, key, and value were computed separately for each Co-Attn block. The CA layer simulated the intensive interactions between the modalities by exchanging information between the input modalities.
Finally, the outputs of the two Co-Attn blocks were connected together and fed to a fully connected layer to obtain a fused feature representation of the text and image.
where denotes the set of training parameters for the feature extractor and the multimodal fusion block, B is the mapping function, and F is the representation of the fused multimodal features. With this approach, internal dependencies and external associations between images and text sentences were captured and fused in the joint generation.
3.3. Rumor Detector
The rumor detector’s input was a fused multimodal feature representation to distinguish whether a tweet is a rumor or not, and it consisted of two fully connected layers with ReLU and softmax activation functions, respectively. We defined the rumor detector as D.
where D is the parameter of the rumor detector and the output of the rumor detector is the probability that the tweet is a rumor.
We marked a rumor as 1 and a nonrumor as 0. We used the cross-entropy to calculate the classification loss.
where X represents a set of posts consisting of text and additional images, and Y represents the corresponding tags. We optimized the parameters , during extraction, fusion, and detection by minimizing the classification loss.
4. Experiment
In this section, we first introduced the relevant dataset for the multimodal rumor detection, then describe the relevant model in detail, and finally analyze and discuss the model effect of the TDEDA model proposed in this paper through experimental results.
4.1. Dataset
To verify the effectiveness of the TDEDA method proposed in this paper, we conducted experiments on two multimodal rumor datasets from Weibo and Twitter, and the details of the two datasets are tabulated in Table 1.

Table 1.
The details of the two datasets.
4.1.1. Weibo Dataset
The Weibo dataset [2] was collected from Xinhua News Agency and Weibo. The data were collected from May 2012 to January 2016. Each post in the Weibo dataset contained text content corresponding to that post and additional unique image information. Posts in the dataset were verified by Xinhua News Agency as a rumor or nonrumor.
4.1.2. Twitter Dataset
The Twitter dataset for multimodal rumor detection was provided by [33]. It collected a large number of tweets posted on Twitter. The content of each tweet consisted of a short text and an additional image/video with tags to indicate whether it was rumor or not. The dataset was divided into two parts: the development set (9000 rumor tweets, 6000 real news tweets) and the test set (2000 tweets). Since our work focused on text and image information, tweets with video were removed from the dataset.
For a given dataset (Weibo and Twitter), we divided it into training, validation, and testing sets based on a ratio of 7:1:2.
4.2. Experimental Model
To measure the performance of the proposed TDEDA model for multimodal rumor detection, we classified the comparison models according to the input type into two categories: single-modal and multimodal.
4.2.1. Single-Modal Models
In the unimodal rumor detection model, we chose the following four models:
- SVM-TS [34]: SVM-TS uses heuristic rules and SVM-based linear classifiers for rumor detection.
- GRU [16]: GRU detects rumors by using a multilayer GRU network, treating the content of posts as a series of variable lengths.
- CNN [18]: the CNN sets fixed length windows on posts to extract features by a convolutional neural network.
- TextGCN [35]: text-graph convolutional network (TextGCN) models the entire corpus as a heterogeneous graph and inputs it into a text graph convolutional network to obtain the semantic features of the text.
4.2.2. Multimodal Models
The inputs to the multimodal rumor detection model were text content and additional images, and the design of existing multimodal models as well as our proposed model is described in the following.
- att-RNN [2]: The att-RNN is based on an LSTM (long short-term memory) model to extract text and social context features and a pretrained VGG-19 model to extract visual features. The association features between text/social context features and visual features are obtained and a rumor classification is performed by the attention mechanism.
- EANN [4]: The text features and image features are extracted with TextCNN and VGG-19, respectively, and the features are stitched and input to the rumor classifier and event discriminator. Among them, the event discriminator is used to learn the invariant representation of events, and in this paper, we removed the event discriminator to make a fair comparison.
- MVAE [5]: MVAE uses an encoding–decoding approach to construct a multimodal feature expression. By training the multimodal variational self-encoder, two modalities can be reconstructed from the learned shared representation to find the correlation between the cross-modalities.
- SAFE [6]: SAFE is a multimodal rumor detection method based on similarity-aware method, which extracts text features and visual features from posts and explores the common representations between them.
- CARMN [7]: CARMN extracts text feature representations from both the original text and fused text by a multichannel convolutional neural network (MCN) and uses VGG19 to extract image feature representations for multimodal rumor detection.
- CAFE [8]: CAFE analyzes cross-modal ambiguity learning from the perspective of information theory, adaptively aggregates single-modal and cross-modal correlation features, and performs rumor detection.
4.3. Experimental Settings
The multimodal hybrid fusion modules were stacked in two layers, first, the intermodal information interaction module, then, the intermodal information enhancement. The batch size of the model was set to 64, the model was trained 100 times, the training was stopped early, and the training results were recorded if the model accuracy no longer improved within 10 error margins. The learning rate was initialized to and adaptively decreased when the model training effect was no longer increasing. The Adam optimizer was used to find the optimal parameters of the neural network.
5. Experimental Results and Analysis
5.1. Performance Analysis
To verify the rumor detection effectiveness of the proposed TDEDA model, it was compared with other baseline models on the Weibo and Twitter datasets. Two multimodal rumor detection datasets were compared. The evaluation metrics commonly used in classification problems [36] were used: precision, recall, F1-score, and accuracy. The results of the experimental comparison are shown in Table 2.
Table 2.
Performance of TDEDA against baselines on two multimodal datasets.
In Table 2, the results of the baseline model and our proposed model on the two datasets are detailed. It can be observed that our proposed TDEDA model outperformed all baselines in terms of accuracy metrics for both datasets.
In the above two datasets, through the analysis of the results, firstly, we can find that the performance of the rumor detection model based on a multimodal approach was better than that of the rumor detection based on unimodal approach. For the TDEDA model, compared with the optimal baseline models we selected, the performance of our proposed TDEDA model on the Weibo dataset increased by 2.2%, and that on the Twitter dataset increased by 2.2%.
There were also some differences between the two datasets. The performance on the Weibo dataset was better than on the Twitter dataset, with 87.2% and 82.4%, respectively. This occurred because of a correlation with the dataset itself: in the Weibo dataset, for a tweet, the average length was about 10 times longer than that of a tweet on the Twitter dataset. This may have made the pretrained BERT model have better performance on the Weibo dataset. Moreover, in the Twitter dataset, a single event was associated with more than 70% of the tweets. Furthermore, the number of images in the Twitter dataset was only about 500, and one image tended to correspond to multiple tweets, resulting in insufficient image features in the Twitter dataset. However, each tweet in the Weibo dataset was composed of text and corresponding images, and this difference may have affected the information interaction between text and image objects. As a result, the training samples of the BERT and ResNet50 models were too similar, which made the generalization performance of the models not good enough and prone to overfitting on the Twitter dataset. However, the Weibo dataset did not have such an imbalance problem.
In summary, the proposed TDEDA model could capture more abundant internal feature information of text objects and visual objects through its dual self-attention mechanism. In addition, the potential connection between text objects and image objects could be fully mined, the relevant features in visual and text objects could be effectively captured, the feature representation between more extensive modal could be obtained, and the accuracy of rumor detection could be improved through effective fusion.
5.2. Ablation Study
In the TDEDA model, to explore whether the individual components were effective, we conducted ablation experiments on the Weibo and Twitter datasets, respectively. In this case, the individual components were designed by fixing one component of the TDEDA model while changing the other components, and based on the experimental results, it can be seen that each component of the TDEDA model played an important role in improving the performance of the multimodal rumor detection.
- TSA: TSA used only the textual double-embedding and self-attention without the fusion of the multimodal features part.
- VSA: VSA used only the visual self-attention without the fusion of the multimodal features part.
- DSA: DSA represented the dual self-attention part of the multimodal rumor detection, while the multimodal feature part was not fused, and the visual feature and text feature were simply connected for the prediction.
- DCA: DCA was used to indicate that the self-attention mechanism of the text and images was not used, but only dual text–visual coattention was used for the feature fusion for the prediction.
Table 3 shows the experimental results of the TDEDA model variants.
Table 3.
The details of the ablation study on two datasets.
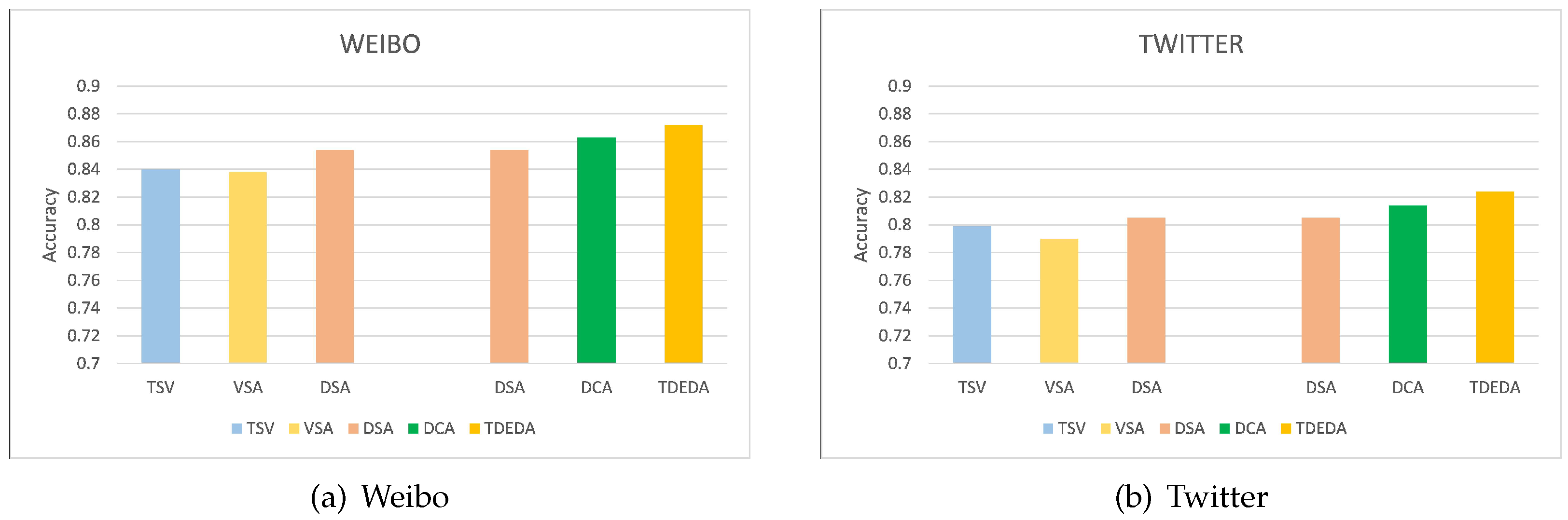
In order to more intuitively show the improvement of the rumor detection performance of each component of the proposed TDEDA model, we divided them into two groups, as shown in Figure 5.
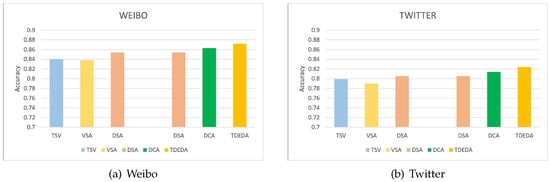
Figure 5.
Ablation study of the TDEDA model on Weibo and Twitter datasets. Each color represents a component.
The first set of experiments demonstrated the contribution of the self-attention networks for learning meaningful features, including the textual self-attention and visual self-attention networks. It can be seen that in the Weibo and Twitter datasets, the textual self-attention improves the accuracy of the rumor detection more than the visual self-attention, indicating that text description was more important than the image in the multimodal rumor detection. Moreover, the dual self-attention mechanism from text and image improved the performance more than TSA and VSA. The results showed that the self-attention mechanism network used to capture the internal features of the text and the global features of the image was helpful for rumor detection.
The second group of experiments mainly verified the effectiveness of the dual coattention module (DCA). The accuracy of the rumor prediction was also higher than that of the dual self-attention module (DSA) after combining text and visual features with DCA. This directly demonstrated the effectiveness of DCA. In addition, the rumor detection of multiple modes, the capture of characteristic information within the comparison modes, the effective interaction and fusion of information between different modes, and the analysis of the intensive correlation between modes became more important. At the same time, an experimental evaluation of the TDEDA module highlighted that the accuracy of the designed TDEDA model was better than that of DSA and DCA on the Weibo dataset, increasing by 2.1% and 1.0%, respectively. On the Twitter dataset, the accuracy increased by 2.4% and 1.2%, respectively.
5.3. Case Studies
To further illustrate the performance of the TDEDA model for the multimodal rumor detection task, we used actual text and image multimodal tweets as examples and correctly analyzed identified posts and misidentified tweets separately.
5.3.1. Case of Correct Identification
In Figure 6a, the sewer built by Germans in Qingdao a century ago is presented. It is difficult to determine the conveyed information solely based on the image. However, in the text, through the comprehensive semantic information containing the keyword “sewer”, the interaction between the textual and visual features revealed inconsistent representations across different modalities, which could not complement each other. Hence, the fused features obtained during the rumor detection classified this news as a rumor.

Figure 6.
The TDEDA model correctly classified these posts.
In Figure 6b, clouds on Mount Fuji in Japan are depicted. Although the textual description matches the visual description, the shape of the “clouds” in the image is exaggerated to the point of incredulity, thereby enabling the identification of the image as a fake and consequently inferring it as a rumor.
5.3.2. Case of Misidentification
In Figure 7a, the post related to a real event. However, when interacting with the image features based on keyword features, the key feature area of the image was small in the overall image, causing the model to identify it as a rumor.

Figure 7.
The TDEDA model misclassified these posts.
In Figure 7b, the post was a rumor event. The text description and the features of the image could complement each other during the interaction, but the specific meaning expressed by the image was ambiguous, the relevant feature representation of the “attack” in question could not be captured, and it could not be detected as a rumor.
In order to improve the accuracy of multimodal rumor detection, we will try to address these weaknesses in our future research.
6. Conclusions
In this paper, we proposed a dual-attention (self-attention and coattention) multimodal fusion neural network, TDEDA, and applied it to multimodal rumor detection. The internal information representation of the text, the region dependency of the images, and the modal feature information interaction were carried out by variants of self-attention and coattention modules; through extensive experiments on two multimodal datasets, the experimental results showed the effectiveness of our proposed TDEDA model and provided a reference for the intramodal feature representation and the exploration of multimodal feature association.
In our future work, we will seek a way to introduce postbackground knowledge on the existing methods and apply some techniques to extract knowledge concepts that provide useful supplementary information for rumor detection. Meanwhile, the feature selection for rumor detection can be increased. In this paper, text features and image features were mainly selected for model construction in the research method.
Author Contributions
Writing—original draft, H.H.; writing—review and editing, Z.K., X.N., L.D. and W.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China—Complex network behavior analysis, prediction and intervention in multilingual big data environments (Grant No. U1435215).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors are very thankful to the editor and referees for their valuable comments and suggestions for improving the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wu, K.; Yang, S.; Zhu, K.Q. False rumors detection on sina weibo by propagation structures. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Republic of Korea, 13–17 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 651–662. [Google Scholar]
- Jin, Z.; Cao, J.; Guo, H.; Zhang, Y.; Luo, J. Multimodal fusion with recur rent neural networks for rumor detection on microblogs. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 795–816. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinvals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Wang, Y.; Ma, F.; Jin, Z.; Yuan, Y.; Xun, G.; Jha, K.; Su, L.; Gao, J. EANN: Event adversarial neural networks for multi-modal fake news detection. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 849–857. [Google Scholar]
- Khattar, D.; Goud, J.S.; Gupta, M.; Varma, V. MVAE: Multimodal variational autoencoder for fake news detection. In Proceedings of the 10 Computer Engineering and Applications World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2915–2921. [Google Scholar]
- Zhou, X.; Wu, J.; Zafarani, R. Similarity-Aware Multi-modal Fake News Detection. In Proceedings of the Advances in Knowledge Discovery and Data Mining: 24th Pacific-Asia Conference, PAKDD 2020, Singapore, 11–14 May 2020; Proceedings, Part II. Springer: Berlin/Heidelberg, Germany, 2020; pp. 354–367. [Google Scholar]
- Song, C.; Ning, N.; Zhang, Y.; Wu, B. A multimodal fake news detection model based on crossmodal attention residual and multichannel convolutional neural networks. Inf. Process. Manag. 2021, 58, 102437. [Google Scholar] [CrossRef]
- Chen, Y.; Li, D.; Zhang, P.; Sui, J.; Lv, Q.; Tun, L.; Shang, L. Cross-modal ambiguity learning for multimodal fake news detection. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 2897–2905. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep dual transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhu, Y.; Wang, X.; Zhong, E.; Liu, N.; Li, H.; Yang, Q. Discovering spammers in social networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; Volume 26, pp. 171–177. [Google Scholar]
- Rubin, V.L.; Conroy, N.; Chen, Y.; Cornwell, S. Fake news or truth? using satirical cues to detect potentially misleading news. In Proceedings of the Second Workshop on Computational Approaches to Deception Detection, San Diego, CA, USA, 17 June 2016; pp. 7–17. [Google Scholar]
- Castillo, C.; Mendoza, M.; Poblete, B. Information credibility on twitter. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 675–684. [Google Scholar]
- Qazvinian, V.; Rosengren, E.; Radev, D.; Mei, Q. Rumor has it: Identifying misinformation in microblogs. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Scotland, UK, 27–31 July 2011; pp. 1589–1599. [Google Scholar]
- Kwon, S.; Cha, M.; Jung, K.; Chen, W.; Wang, Y. Prominent features of rumor propagation in online social media. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining, Dallas, TX, USA, 7–13 December 2013; pp. 1103–1108. [Google Scholar]
- Ma, J.; Gao, W.; Mitra, P.; Kwon, S.; Jansen, B.J.; Wong, K.F.; Cha, M. Detecting rumors from microblogs with recurrent neural networks. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16), New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Chen, T.; Li, X.; Yin, H.; Zhang, J. Call attention to rumors: Deep attention based recurrent neural networks for early rumor detection. In Proceedings of the Trends and Applications in Knowledge Discovery and Data Mining: PAKDD 2018 Workshops, BDASC, BDM, ML4Cyber, PAISI, DaMEMO, Melbourne, Australia, 3 June 2018; Revised Selected Papers 22. Springer: Cham, Switzerland, 2018; pp. 40–52. [Google Scholar]
- Yu, F.; Liu, Q.; Wu, S.; Wang, L.; Tan, T. A Convolutional Approach for Misinformation Identification. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 3901–3907. [Google Scholar]
- Ma, J.; Gao, W.; Wong, K.F. Rumor detection on twitter with tree-structured recursive neural networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018. [Google Scholar]
- Zhang, J.; Dong, B.; Philip, S.Y. Deep diffusive neural network based fake news detection from heterogeneous social networks. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1259–1266. [Google Scholar]
- Liu, Y.; Wu, Y.F. Early detection of fake news on social media through propagation path classification with recurrent and convolutional networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Jin, Z.; Cao, J.; Zhang, Y.; Zhou, J.; Tian, Q. Novel visual and statistical image features for microblogs news verification. IEEE Trans. Multimed. 2016, 19, 598–608. [Google Scholar] [CrossRef]
- Zadeh, A.; Chen, M.; Poria, S.; Cambria, E.; Morency, L.P. Tensor fusion network for multimodal sentiment analysis. arXiv 2017, arXiv:1707.07250. [Google Scholar]
- Hou, M.; Tang, J.; Zhang, J.; Kong, W.; Zhao, Q. Deep multimodal multilinear fusion with high-order polynomial pooling. Adv. Neural Inf. Process. Syst. 2019, 32, 12136–12145. [Google Scholar]
- Xu, N.; Mao, W.; Chen, G. Multi-interactive memory network for aspect based multimodal sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 371–378. [Google Scholar]
- Gao, P.; Jiang, Z.; You, H.; Lu, P.; Hoi, S.C.; Wang, X.; Li, H. Dynamic fusion with intra-and inter-modality attention flow for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6639–6648. [Google Scholar]
- Bengio, Y. Learning deep architectures for AI. Found. Trends® Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Yang, Z.; He, X.; Gao, J.; Deng, L.; Smola, A. Stacked attention networks for image question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 21–29. [Google Scholar]
- Liu, Y.; Zhang, X.; Huang, F.; Li, Z. Adversarial learning of answer-related representation for visual question answering. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 1013–1022. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Ke, G.; He, D.; Liu, T.Y. Rethinking positional encoding in language pre-training. arXiv 2020, arXiv:2006.15595. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Boididou, C.; Andreadou, K.; Papadopoulos, S.; Dang-Nguyen, D.T.; Boato, G.; Riegler, M.; Kompatsiaris, Y. Verifying multimedia use at mediaeval 2015. MediaEval 2015, 3, 7. [Google Scholar]
- Ma, J.; Gao, W.; Wei, Z.; Lu, Y.; Wong, K.F. Detect rumors using time series of social context information on microblogging websites. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; pp. 1751–1754. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. Graph convolutional networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7370–7377. [Google Scholar]
- Godbole, S.; Sarawagi, S. Discriminative methods for multi-labeled classification. In Proceedings of the Advances in Knowledge Discovery and Data Mining: 8th Pacific-Asia Conference, PAKDD 2004, Sydney, Australia, 26–28 May 2004; Proceedings 8. Springer: Berlin/Heidelberg, Germany, 2004; pp. 22–30. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).