
A Hierarchical Parallel Graph Summarization Approach Based on Ranking Nodes



Abstract
1. Introduction
2. Materials and Methods
2.1. Related Work
2.2. Problem Statement
2.3. Hierarchical Parallel Model
2.3.1. Hybrid Weighted Importance
2.3.2. Node Ranking Based Strategy
2.3.3. Hierarchical Parallel Graph Summarization Abstraction
2.3.4. Performance Complexity Analysis
2.4. Method Implementation
| Algorithm 1 Hybrid Weighted Nodes Importance Ranking |
|
- Initialization
- Parallel summarization
| Algorithm 2 Hierarchical Parallel Graph Summarization |
|
3. Results and Discussion
3.1. Experimental Setup
3.2. Node Importance with Compression Ratio
3.3. Node Importance Distribution
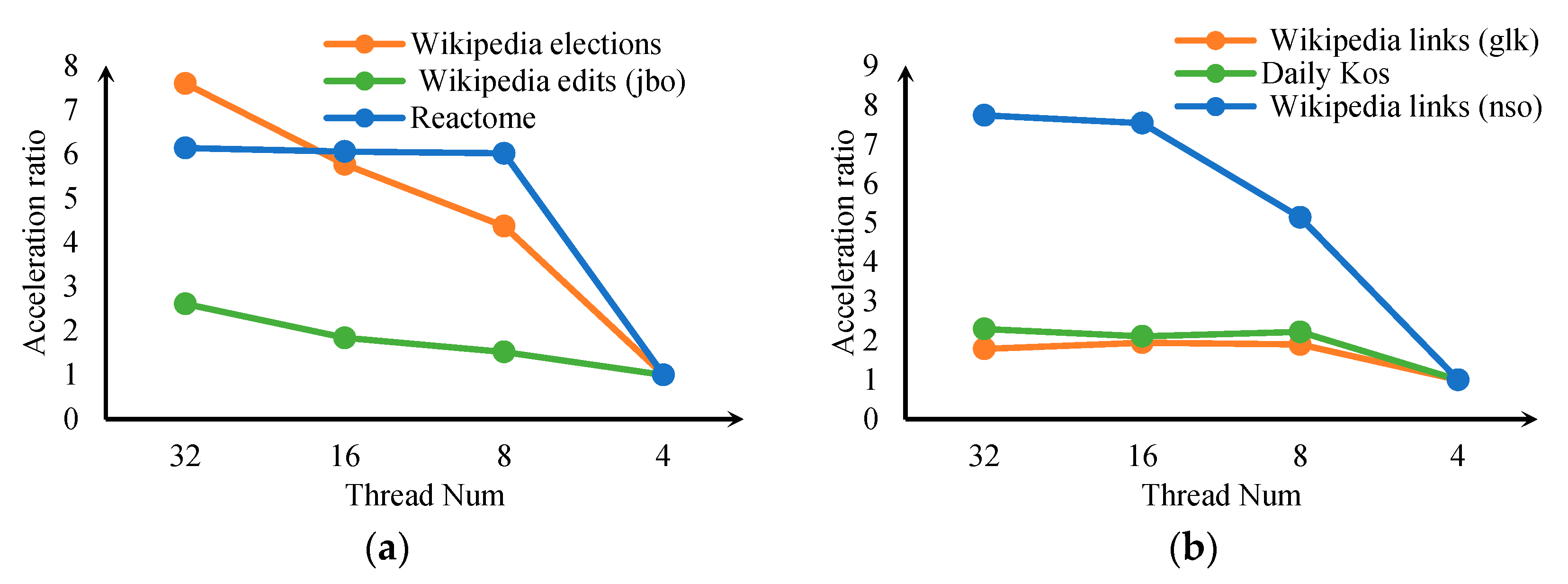
3.4. Performance
3.5. Graph Summary Error
3.6. Comparison of Multiple Node Importance Strategies
4. Conclusions and Future Work
- This paper introduces the node importance factor into the traditional MDL-style graph summarization algorithms, so that users can trivially adapt new node-merging strategies based on special attributed scenarios.
- This paper proposes a hierarchical parallel graph-contraction approach to improve execution efficiency.
- Evaluation results on both real and simulated datasets show that HRNS can efficiently summarize vertices with average importance, and achieve significant performance gain with high speedups, as the sum error ratios are also relatively lower than the traditional algorithms.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- China Internet Network Information Center. The 49th Statistical Report on China’s Internet Development. Available online: https://www.cnnic.com.cn/ (accessed on 24 April 2022).
- Shin, K.; Ghoting, A.; Kim, M.; Raghavan, H. SWeG: Lossless and Lossy Summarization of Web-Scale Graphs. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 1679–1690. [Google Scholar] [CrossRef]
- Lee, K.; Jo, H.; Ko, J.; Lim, S.; Shin, K. Ssumm: Sparse summarization of massive graphs. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Events, CA, USA, 6–10 July 2020; pp. 144–154. [Google Scholar]
- Dixon, S. Number of Monthly Active Facebook Users Worldwide as of 1st Quarter 2022 (In Millions). Available online: https://www.statista.com (accessed on 28 April 2022).
- Liu, Y.; Safavi, T.; Dighe, A.; Koutra, D. Graph summarization methods and applications: A survey. ACM Comput. Surv. (CSUR) 2018, 51, 1–34. [Google Scholar] [CrossRef]
- Tang, N.; Chen, Q.; Mitra, P. Graph stream summarization: From big bang to big crunch. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; pp. 1481–1496. [Google Scholar]
- Petr, C. Community detection in node-attributed social networks: A survey. Comput. Sci. Rev. 2020, 37, 100286. [Google Scholar]
- Besta, M.; Hoefler, T. Survey and taxonomy of lossless graph compression and space-efficient graph representations. arXiv 2018, arXiv:1806.01799. [Google Scholar]
- Navlakha, S.; Rastogi, R.; Shrivastava, N. Graph summarization with bounded error. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 419–432. [Google Scholar]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef]
- Stumpf, M.P.; Wiuf, C.; May, R.M. Subnets of scale-free networks are not scale-free: Sampling properties of networks. Proc. Natl. Acad. Sci. USA 2005, 102, 4221–4224. [Google Scholar] [CrossRef]
- Koutra, D.; Kang, U.; Vreeken, J.; Faloutsos, C. Summarizing and understanding large graphs. Stat. Anal. Data Min. 2015, 8, 183–202. [Google Scholar] [CrossRef]
- Goasdoué, F.; Guzewicz, P.; Manolescu, I. RDF graph summarization for first-sight structure discovery. VLDB J. 2020, 29, 1191–1218. [Google Scholar] [CrossRef]
- Goasdoué, F.; Guzewicz, P.; Manolescu, I. Incremental structural summarization of RDF graphs. In Proceedings of the EDBT 2019—22nd International Conference on Extending Database Technology, Lisbon, Portugal, 26–29 March 2019. [Google Scholar]
- Samal, A.; Kumar, S.; Yadav, Y.; Chakraborti, A. Network-centric Indicators for Fragility in Global Financial Indices. Front. Phys. 2021, 8, 624373. [Google Scholar] [CrossRef]
- Tsankov, P. Overview of network-based methods for analyzing financial markets. Proc. Tech. Univ. Sofia 2021, 71, 1–7. [Google Scholar] [CrossRef]
- Xie, T.; Ma, Y.; Kang, J.; Tong, H.; Maciejewski, R. FairRankVis: A Visual Analytics Framework for Exploring Algorithmic Fairness in Graph Mining Models. IEEE Trans. Vis. Comput. Graph. 2021, 28, 368–377. [Google Scholar] [CrossRef] [PubMed]
- Song, H.; Dai, Z.; Xu, P.; Ren, L. Interactive Visual Pattern Search on Graph Data via Graph Representation Learning. IEEE Trans. Vis. Comput. Graph. 2021, 28, 335–345. [Google Scholar] [CrossRef]
- Brin, S.; Page, L. The anatomy of a large-scale hypertextual Web search engine. Comput. Netw. ISDN Syst. 1998, 30, 107–117. [Google Scholar] [CrossRef]
- Kitsak, M.; Gallos, L.; Havlin, S.; Liljeros, F.; Muchnik, L.; Stanley, H.E.; Makse, H.A. Identification of influential spreaders in complex networks. Nat. Phys. 2010, 6, 888–893. [Google Scholar] [CrossRef]
- Freeman, L.C. Centrality in social networks conceptual clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef]
- Wang, J.; Li, C.; Xia, C. Improved centrality indicators to characterize the nodal spreading capability in complex networks. Appl. Math. Comput. 2018, 334, 388–400. [Google Scholar] [CrossRef]
- Maji, G.; Dutta, A.; Malta, M.C.; Sen, S. Identifying and ranking super spreaders in real world complex networks without influence overlap. Expert Syst. Appl. 2021, 179, 115061. [Google Scholar] [CrossRef]
- Malewicz, G.; Austern, M.H.; Bik, A.J.; Dehnert, J.C.; Horn, I.; Leiser, N.; Czajkowski, G. Pregel: A system for large-scale graph processing. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, Indianapolis, IN, USA, 6–10 June 2010; pp. 135–146. [Google Scholar]
- Liu, Y.; Wei, W.; Sun, A.; Miao, C. Distributed graph summarization. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 799–808. [Google Scholar]
- Lin, W. Large-Scale Network Embedding in Apache Spark. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 3271–3279. [Google Scholar]
- Zhang, Y.; Gao, Q.; Gao, L.; Wang, C. Maiter: An Asynchronous Graph Processing Framework for Delta-Based Accumulative Iterative Computation. IEEE Trans. Parallel Distrib. Syst. 2013, 25, 2091–2100. [Google Scholar] [CrossRef]
- Kusum, A.; Vora, K.; Gupta, R.; Neamtiu, I. Efficient processing of large graphs via input reduction. In Proceedings of the 25th ACM International Symposium on High-Performance Parallel and Distributed Computing, Kyoto, Japan, 31 May–4 June 2016; pp. 245–257. [Google Scholar]
- Stanley, N.; Kwitt, R.; Niethammer, M.; Mucha, P.J. Compressing Networks with Super Nodes. Sci. Rep. 2018, 8, 10892. [Google Scholar] [CrossRef]
- Ke, X.; Khan, A.; Bonchi, F. Multi-relation Graph Summarization. ACM Trans. Knowl. Discov. Data (TKDD) 2022, 16, 1–30. [Google Scholar] [CrossRef]
- Hajiabadi, M.; Singh, J.; Srinivasan, V.; Thomo, A. Graph Summarization with Controlled Utility Loss. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual Event, Singapore, 14–18 August 2021; pp. 536–546. [Google Scholar]
- Kang, S.; Lee, K.; Shin, K. Personalized Graph Summarization: Formulation, Scalable Algorithms, and Applications. arXiv 2022, arXiv:2203.14755. [Google Scholar]
- Zhou, H.; Liu, S.; Lee, K.; Shin, K.; Shen, H.; Cheng, X. DPGS: Degree-preserving graph summarization. In Proceedings of the 2021 SIAM International Conference on Data Mining (SDM), Virtual Event, 29 April–1 May 2021; pp. 280–288. [Google Scholar]
- Yong, Q.; Hajiabadi, M.; Srinivasan, V.; Thomo, A. Efficient graph summarization using weighted lsh at billion-scale. In Proceedings of the 2021 International Conference on Management of Data, Xi’an, China, 20–25 June 2021; pp. 2357–2365. [Google Scholar]
- Lee, K.; Ko, J.; Shin, K. Slugger: Lossless hierarchical summarization of massive graphs. In Proceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE), IEEE, Kuala Lumpur, Malaysia, 9 May 2022; pp. 472–484. [Google Scholar]
- Ko, J.; Kook, Y.; Shin, K. Incremental lossless graph summarization. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 6–10 July 2020; pp. 317–327. [Google Scholar]
- Gou, X.; Zou, L.; Zhao, C.; Yang, T. Graph Stream Sketch: Summarizing Graph Streams with High Speed and Accuracy. IEEE Trans. Knowl. Data Eng. 2022. early access. [Google Scholar] [CrossRef]
- LaSalle, D.; Patwary, M.M.A.; Satish, N.; Sundaram, N.; Dubey, P.; Karypis, G. Improving graph partitioning for modern graphs and architectures. In Proceedings of the 5th Workshop on Irregular Applications: Architectures and Algorithms, Austin, TX, USA, 15 November 2015; pp. 1–4. [Google Scholar]
- Gonzalez, J.E.; Xin, R.S.; Dave, A.; Crankshaw, D.; Franklin, M.J.; Stoica, I. GraphX: Graph Processing in a Distributed Dataflow Framework. In Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation(OSDI), Berkeley, CA, USA, 6–8 October 2014; pp. 599–613. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Graph Dataset | Vertices | Edges |
|---|---|---|
| UC Irvine forum (UCforum) | 899 | 14,038 |
| Blogs | 1223 | 33,433 |
| 1500 | 37,206 | |
| Bible (names) | 1773 | 18,262 |
| 2000-2 | 2000 | 10,962 |
| 2500-2 | 2500 | 14,014 |
| Cora | 2708 | 10,566 |
| Ca-GrQc | 5242 | 14,496 |
| Wikipedia edits (jbo) | 5403 | 88,756 |
| Reactome | 6229 | 292,320 |
| Daily Kos | 6906 | 699,498 |
| Wikipedia elections | 7115 | 201,386 |
| Wikipedia links (glk) | 7332 | 533,038 |
| Wikipedia links (nso) | 8152 | 589,970 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Q.; Wei, J.; Liu, H.; Ji, Y. A Hierarchical Parallel Graph Summarization Approach Based on Ranking Nodes. Appl. Sci. 2023, 13, 4664. https://doi.org/10.3390/app13084664
Liu Q, Wei J, Liu H, Ji Y. A Hierarchical Parallel Graph Summarization Approach Based on Ranking Nodes. Applied Sciences. 2023; 13(8):4664. https://doi.org/10.3390/app13084664
Chicago/Turabian StyleLiu, Qiang, Jiaxing Wei, Hao Liu, and Yimu Ji. 2023. "A Hierarchical Parallel Graph Summarization Approach Based on Ranking Nodes" Applied Sciences 13, no. 8: 4664. https://doi.org/10.3390/app13084664
APA StyleLiu, Q., Wei, J., Liu, H., & Ji, Y. (2023). A Hierarchical Parallel Graph Summarization Approach Based on Ranking Nodes. Applied Sciences, 13(8), 4664. https://doi.org/10.3390/app13084664