1. Introduction
Before the rapid development of the Internet and common electronic devices, people obtained news and other information from newspapers and TV. Now, network platforms have become an important way for people to obtain and share information. These trends have led to an exponential growth of information on the Internet. With such a wealth of information, people are looking for ways to quickly access available information. Automatic text summarization has emerged at this historic moment, effectively alleviating the problem of information overload. Automatic text summarization is designed to convert text or collections of text into short summaries containing key information. Text summaries can be divided into single-document summaries and multi-document summaries according to the input type. Single-document abstracts [
1] generate abstracts from a given document, and multi-document abstracts [
2] generate abstracts from a given set of subject-related documents. According to the output type, the text summary method can be divided into extractive summaries [
3] and abstractive summaries [
4,
5,
6,
7,
8,
9,
10]. Extractive abstracts extract keywords and key phrases from the source text, thus forming the abstract. Abstractive abstracts allow the generation of new words and phrases to make up the abstract based on the original text. Compared with the extractive summary, the abstractive summary is more in line with the human habit of generating an abstract, although it is complicated to implement. First off, generative text summarizing reduces reading time and increases reading effectiveness by avoiding the extraction of extensive content from the source text, instead creating brief and to-the-point summaries. Second, rather than choosing specific sentences from the original text, people who read an article to learn its main points typically summarize it using the original text as a guide. In conclusion, generative text summarizing is more adaptable in its information-gathering and is closer to how humans produce summaries. In addition, generative summarization requires machines to imitate humans and understand more semantic information in the original text, which is even more challenging. The significance of examining it has also been reinforced by the growing rise of generative text summaries in the mainstream of research. Therefore, this article mainly studies generative text summarization.
An automatic text summarization model was first designed by Luhn [
11] in 1958, which kicked off automatic text summarization. Subsequently, graph-based abstractive text summarization [
4], linear programming-based abstractive text summarization [
5,
6], semantic-based abstractive text summarization [
7,
8], and template-based abstractive text summarization [
9,
10] followed. With the rise of deep learning in the fields of natural language processing, more and more abstractive text summary models based on deep learning have emerged. Deep-learning-based methods surpass traditional generation methods in multiple languages and evaluation metrics [
12]. Deep-learning-based automatic text summarization emulates how people summarize by remembering abstracts based on their comprehension of the original material. As a result, deep-learning-based text summarization technology has received considerable attention from both academia and industry due to its significant research significance and wide range of potential applications.
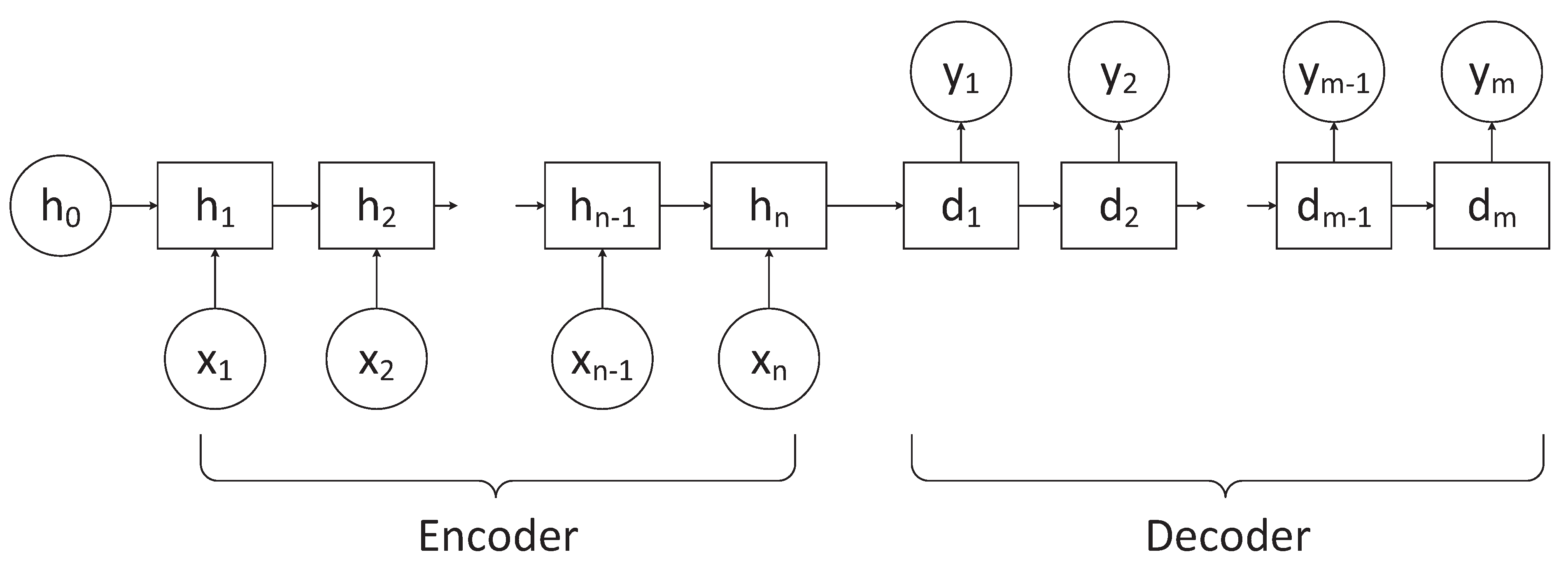
Among many automatic abstract generation models based on deep learning, the most popular one is the sequence-to-sequence (Seq2seq) [
13] model, which is presented in
Figure 1. The model generally consists of two parts: the first part is the encoder part, which is used to characterize the input sequence of length n. The second part is the decoder part, which is used to build the representation extracted from the encoder into a mapping of sequence with an output length of m. Most of the existing models are based on this model for improvement. Rush et al. [
14] proposed an abstractive text summarization model ABS based on the Seq2seq model and incorporated the attention mechanism into the model. The Seq2seq model incorporating attention is shown in
Figure 2. Based on the Seq2seq model, the researchers studied the different effects of different neural networks used for encoder and decoder. Chopra et al. [
15] constructed decoders based on recurrent neural networks(RNN). Nallapati et al. [
16] changed the encoder to a recurrent neural network as well, making it a standard recurrent neural network-based encoder–decoder model. Gehring et al. [
17] replaced the recurrent neural network used in the sequence-to-sequence model with a convolutional neural network, thus proposing the ConvS2S model. and the model has achieved good results in automatic text summarization tasks. The ConvS2S model not only realizes parallel computation at different positions in the sequence, but also can capture the long-range dependencies between words in a sentence through the hierarchical structure, which makes it possible to handle complex sentence information.
The word list of the model is composed of high-frequency words, so there will be some words that do not appear in the word list, and we call such words out-of-vocabulary (OOV).To solve the problem of OOV, Nallapati et al. [
16] also put forward the Generator-Pointer model. The model via pointer
determines whether the summary is copied from the source text or whether the generator generates a new word. During encoder–decoder training, the decoder inputs the correct reference summary, while during prediction, the decoder inputs the output from the previous time step. Once the output from the previous step is incorrect, a series of deviations will occur, resulting in poor summary quality. This is the issue of exposure bias. During the research, we also noticed this issue. Paulus et al. [
18] first proposed to address the problem of exposure bias based on reinforcement learning. The maximum-likelihood cross-entropy loss function and a strategy gradient for reinforcement learning are combined in Paulus’s paper to propose new learning objectives. This reduces bias in the reinforcement learning process.
We identified several issues with the generative summary model based on the aforementioned research findings: (1) Researchers cannot truly determine the level of correlation between the vectors stored by neural networks and the original text throughout the study process because of the black box nature of neural networks. (2) It is challenging to provide coherent summaries since abstract generation models often only focus on the link between single-word vectors. (3) Humans typically combine the text’s prior information when creating abstractions, which results in abstracts that are more semantically rich. Current models frequently lack historical context. We will conduct our research from the perspective of introducing prior knowledge and richer semantic information. The main contributions of this paper are as follows:
We improve the encoder part of the original codec model by adding a weighted summation (WS) process, so that the encoder can determine how well the vectors generated by the neural network match the original text and assign higher weights to the important parts of the original text.
To improve the quality of the generated summaries, we use the word–sentence-level joint-attention mechanism (JAM) to force the decoder to focus not only on the keywords in the source text but also on the sentences where the keywords are located. Furthermore, we combine prior knowledge (PK) to enable the decoder to obtain the original information of the source text on the one hand, avoiding information loss caused by layer-by-layer transmission in the abstract generation process; on the other hand, we transmit higher-level abstract semantic information to the decoder, enabling the generation of abstracts more in line with human reading habits.
We introduce reinforcement learning (RL) for optimization to address the problems of exposure bias and inconsistency between evaluation metrics and loss functions. The readability and fluency of the summary are ensured.
The abstractive summary model based on the joint-attention mechanism and prior knowledge (JPATS) was used on two datasets, CNN/DailyMail and DUC 2004, and the results showed that our model outperformed the existing baseline model.
3. Model
In this paper, we present a model where the source text is first processed with word2vec to obtain the word-embedding
representation of each word. In addition, then input to the neural network, in turn, to obtain the hidden vector
for each word. Unlike machine translation tasks that need to retain all the information in the original text, text summaries need to retain only the most important information. Thus, inspired by the idea of a self-attention mechanism, we match the trained hidden vectors with the original text and assign higher weights to the vectors that are more relevant to the information in the original text. After this operation, further relationships between words
are obtained, enabling the decoder to obtain source text information with focus. The sentence-level vectors are obtained by averaging the word vectors, forcing the decoder to focus on the keywords while focusing on the sentences in which the keywords are located. The word-level and sentence-level vectors are used to calculate the score weights with the hidden states under each moment of the decoder, respectively, and this is used to improve the pointer network to generate more coherent and human-readable summaries. Moreover, this paper uses the original word vector without any training to obtain the sentence embedding as the prior knowledge to guide the copy generation of the pointer network. Finally, reinforcement learning is used to improve the evaluation metric Rouge and alleviate the problem of inconsistency between the evaluation metric and the loss function.The model is shown in
Figure 3.
3.1. Problem Formulation
Given the source text , l is the sentence length, , is the source text vocabulary; generate the summary , m is the summary length, , is the target summary. Generating a summary needs to satisfy . If , it means that all summaries are derived from the source text, and we define this case as an extractive summary. If , it means that not all the summary words are from the source text, and this case is defined as an abstractive summary. In the model training stage, the input of the decoder part is the correct abstract, that is, the learning function , and Y is the reference abstract extracted manually. The purpose of designing the model is to make the abstract generated by the model close to the standard abstract Y. In the test phase, the trained function f is used to generate a summary from the source text.
3.2. Encoding Side
To solve the RNN long-range dependency problem, a deformed long short-term memory (LSTM) or gated recurrent unit (GRU) of RNN is usually used in the codec model. Compared with LSTM, GRU is easier to train and can improve the training rate to a great extent. Therefore, GRU is used as the encoder in this paper. GRU is defined as follows.
where
,
, and
are the weight matrices,
is the current input, and
is the hidden state vector passed in from the previous time node, and this hidden state vector contains the relevant information of the previous node.
In this paper, we use a bidirectional GRU(Bi-GRU), as shown in
Figure 4, to retain both forward and backward time step information. The forward network reads the word-embedding vector from left to right to obtain the forward GRU hidden state
, and the backward network reads the word-embedding vector from right to left to obtain the backward GRU hidden state
. The two hidden state formulas are as follows.
The initial state of Bi-GRU is set as a zero vector, i.e., , . The forward and backward hidden states are cascaded to obtain the final hidden state. Expressed as: .
The self-attention mechanism can determine how relevant the current word is to other words in the sentence. Less reliance on external information and better at capturing the internal relevance of data or features. Inspired by this, we calculate the correlation between the hidden vectors trained by the neural network and the source text word vectors to avoid deviating from the original meaning. In addition, it is also possible to give higher weight to keywords, making the decoder focus on important information in the decoding process. The process is as follows.
First, obtain the similarity matrix, as shown in
Figure 5:
Weighted summation, as shown in
Figure 7:
H is the matrix corresponding to the hidden vector and W is the matrix corresponding to the word vector. To prevent the gradient from disappearing, divide the inner product by the square root of the dimensions.
The
vector after assigning weights is used for the representation of sentence vectors, meaning that to provide high-quality summaries, the decoder pays attention to both the source text’s keywords and the sentences in which they appear. The word-embedding averaging method by Kedzie et al. [
30] works well for sentence embedding across different domains and summarizer architectures. We obtain the sentence embedding, i.e.,
, by this simple method. As shown in Equation (
8).
3.3. Joint-Attention Mechanism for Word-Sentence-Level Fusion
In this paper, each word is used as input to the encoder, and after GRU training, the relationship between word-level vectors is obtained. Distinguish from the relationship between sentence-level vectors mentioned later. GRU suffers from the long-range dependency problem, i.e., when the input is too long, the later input words will forget the previously input words, which in turn causes incomplete information between words, resulting in incomplete features received by the decoder. In this paper, each sentence in the paragraph is subjected to sentence embedding processing, as follows: The vector obtained by summing and averaging the word-embedding of all the words in the sentence is used as the final sentence embedding. After this processing, there will be relationships not only between word-level vectors, but also between sentence-level vectors, and the decoder discriminates the word-level sentence-level vectors based on their relationship with the hidden state of the decoder. The specific formula is as follows.
Equations (9)–(12) is the process of obtaining word-level context vectors , and Equations (13)–(16) is the process of obtaining sentence-level context vectors .
Taking the word-level context vector calculation process as an example: First, the decoder generates a hidden vector based on the hidden vector of the previous neuron , the output of the previous neuron , and the context vector of the current neuron . Second, the neuron of the decoder calculates the correlation between the current state and each neuron in the encoder based on the hidden vector of the previous neuron . Third, obtain the generated word weight score ; Finally, the word-level context vector is obtained. Similarly, the sentence-level context vector is obtained.
Where , are the parameter vectors. n means that there are n words in the paragraph and m means that there are m sentences in the paragraph (i.e., assuming that each input text has m sentences). is the hidden vector generated by the decoder based on the hidden vector of the previous neuron, the output of the previous neuron and the context vector of the current neuron. is the hidden vector in word-level dimension and is the hidden vector in sentence-level dimension. is the output of each neuron of the encoder, and is the sentence-level representation computed from each word-level output. The jth neuron of the decoder has to calculate the correlation of the current state with each neuron in the encoder based on the hidden vector of the previous neuron. The sentence-level relevance vector is denoted as . If the dimension of is larger, it means that the current node is more correlated with the nth neuron of the encoder. is the generated word weight score and is the generated sentence weight score. As a result, the word-level context vector and the sentence-level context vector are obtained.
Integrating the above content of the article, the semantic vectors (word-level semantic vectors to ) output from the source text input encoder are obtained after the weighted summation process (word-level semantic vectors to ), and the correlation is calculated with the hidden state of the decoder at each moment to obtain the generated word weight score first and then the word-level context vector on the one hand, and the sentence embedding is obtained by the averaging method on the other hand. The word-embedding vectors ( to ) obtained by word2vec enter the encoder training to obtain the output semantic vectors ( to ) on the one hand, and obtain the a priori knowledge by averaging on the other hand.
3.4. Decoding Side
3.4.1. Improvements to the Pointer Network
Since the summaries may contain words that do not exist in the word list, we use a pointer network between the encoder and decoder. The pointer generator network helps to copy words from the source text via pointers, which improves the accuracy and processing of out-of-vocabulary (OOV) words, while retaining the ability to generate new words. The pointer network is equivalent to a soft switch, and
serves as the probability of the soft switch, by which
determines whether the summary is copied from the original text or generated from a fixed vocabulary, and
is expressed as follows:
In this paper, we improve the pointer network with a joint-attention mechanism for the problem of unregistered words and duplication of generated summaries, as follows:
Among them, , , , , , and are learnable parameters, is the context vector, is the decoder hidden state, is the output of the decoder, is the sigmoid function, and .
Humans tend to combine background knowledge when reading the central content of overview articles, and the model-generated summaries often do not match human reading habits. We combine a priori knowledge into the pointer network to guide the coverage mechanism of the pointer network by compressing the source text semantic information through sentence embedding to assist the summary generation. A priori knowledge is that which can be possessed not through acquired experience. In the abstract, we interpret it as the original vector without any training. Therefore, we use the initial word vector obtained by word2vec to represent the sentence vector as a basis for a priori knowledge.
We still use word-embedding averaging to obtain the sentence embedding after compressing the source text, i.e.,
. As shown in Equation (
19),
represents a higher-level semantic representation.
After obtaining the sentence embedding, the weight fraction of each hidden state of the sentence embedding and decoder is found by the same method as calculating
, as independent of the empirical knowledge. That is, the matching relationship between the words to be output and the individual sentences of the source text is obtained, and then the model prefers the words in the original sentence when decoding the output.
where
is the highest probability corresponding to the sentence embedding.
has two meanings,
and
, respectively. In this way, the model generates summaries with the flexibility to consider not only word-level sentence-level vectors to convey inter-word relationships, but also to preserve the guidance of the source text to the summary through a priori knowledge.
is a pre-constructed word list that does not contain the OOV words in the input text. The improved pointer network is shown in
Figure 8.
In our experiments, we found that the summaries generated by the model have recurring problems, such as “I like you like you like you like you like you”. The coverage mechanism can add the influence of previous decisions to the current decision, avoiding the attention mechanism from continuously focusing on the same position and thus avoiding the generation of duplicate texts. The specific formula is as follows.
is the distribution over the original words, indicating the coverage these words have received from the attention mechanism so far. Notice that
is a zero vector because no words are covered in the original text at the initial moment. Since it is often the words that present the duplication problem, we only use the previous decisions of the word-level attention mechanism for the coverage vector.
The coverage vector acts as an additional input to the attention mechanism, and the formula is:
, , , and are learnable vectors.
3.4.2. Reinforcement Learning Based on Improved Pointer Networks
During the training process of the codec, the decoder part inputs the correct reference summary, while during the prediction process, the encoder inputs the output of the previous time step, and once the output of the previous step is wrong, it will cause a series of subsequent deviations, leading to the problem of poor summary quality. This is the exposure bias problem. In addition, the model-generated summaries usually suffer from incoherence and semantic irrelevance, and such problems are caused by the non-uniformity of evaluation metrics and loss functions. For the above problems, the solution in this article is as follows.
Reinforcement learning is used to describe and solve the problem of learning strategies to maximize the reward or achieve a specific goal by an intelligence agent during its interaction with the environment. The training method incorporating the reinforcement learning approach considers the supervised learning objective (maximum-likelihood method) and the RL strategy gradient objective for generating relationships between summary sentences and standard summary sentences under the Rouge criterion. The maximum-likelihood loss is the loss function used in the conventional supervised learning strategy; training by decreasing the loss function is comparable to increasing the likelihood that the real value will occur. According to the reference summary
, minimize the negative logarithmic likelihood function
.
The maximum likelihood only allows the generative model to learn similar representation patterns to the standard summary, while the Rouge metric allows for flexibility in sentence alignment. Therefore, we modify the loss function so that the loss function can be optimized for Rouge. Specifically, two independent output sequences
and
are generated in each training iteration.
is obtained by sampling from the
conditional probability distribution at each decoding time step, and
is obtained by maximizing the output probability distribution, which is also the model output result. We use the Rouge score as the reward function
. The generated abstracts are compared with the reference abstracts, compared by Rouge function values, and rewards are calculated.
is calculated as the similarity evaluation Rouge score between the generated abstract
y and the reference abstract
.
Minimizing
is equivalent to maximizing the conditional likelihood of the sampled sequence
, thus increasing the payoff expectation of the model. We finally mix the loss functions of the two components to obtain the overall objective function, with the following equation.
is used to balance and . The loss function is introduced through reinforcement learning to effectively alleviate the exposure bias problem on the one hand, and to optimize the evaluation metrics and improve the evaluation metric scores of the model on the other hand. At this point, we have presented all parts of the generative summary model based on the joint-attention mechanism and a priori knowledge. Next, the experimental part is elaborated.
4. Experiment
To investigate the performance of the model in this paper, we evaluate our model using two benchmark datasets CNN/DailyMail [
31] and DUC 2004 [
32] for single-text generative summarization. In addition, we compare the model in this paper with the publicly available model for analysis.
4.1. Dataset
The CNN/DailyMail dataset began as a machine reading comprehension corpus with about 1 million news data collected from CNN and the DailyMail. Later, simple changes were made to form a corpus for single-text generative abstracts. The dataset includes 286,817 training samples, 13,368 verification samples and 11,487 test samples. The training set has an average of 3–4 summary sentences, and each document has an average of 28 sentences. In addition, the average number of tags in the input and output abstracts is 781 and 56, respectively. This dataset is used to train and test the proposed model.
Meanwhile, this paper uses DUC 2004 dataset as the test set to further evaluate our model. DUC contains the 2001–2007 corpus, where the DUC2001–2004 corpus is suitable for both single-text summarization and multi-text summarization, and DUC2005–2007 is only suitable for multi-text summarization. This article proposes a model for single-text summaries, and therefore uses the DUC 2004 dataset. DUC 2004 is a small dataset for testing only. DUC 2004 contains 500 documents, and each news article contains a reference summary of the corresponding four different manually generated intercepts of 75B.
4.2. Evaluation Metrics
To demonstrate the model’s viability and efficacy after receiving the summary it provided, we must assess the model’s performance. Both manual and automatic evaluations were used to gauge the abstracts’ quality.
Automatic evaluation methods for text summarization include Rouge [
33], BLEU [
34], etc., and the commonly used one is Rouge, which is also used as an evaluation metric in this paper. Rouge measures the quality of the model-generated summaries by calculating the degree of overlap of the basic units (n-grams) between the generated summaries and the reference summaries. Rouge typically contains the following metrics.
Rouge-N: Statistics based on the co-occurrence degree of N-gram words.
where
Y is the reference summary and
S is the sentence in the reference summary. The numerator indicates the number of simultaneous
in the generated summary and the standard summary. The denominator indicates the number of
occurrences in the reference summary.
Rouge-L: refers to the longest common subsequence (LCS) in the generated abstracts and reference abstracts.
where
denotes the recall rate in Equation (
30),
denotes the precision rate in Equation (
31),
denotes the length of the longest common subsequence between the generated summary and the reference summary,
n is the length of the reference summary, and m is the length of the generated summary. In general,
is set to a large value, so
usually considers only
(recall) in this case. As shown in Equation (
32), if
is large, the inclusion of the first half of Equation
can be neglected.
When performing a manual evaluation, we primarily look at readability and whether or not the text retains important details from the original (generalization). We manually select 100 examples from the CNN/DailyMail dataset and give the generated summaries and reference summaries generated by the different models to the evaluators. The five evaluators scored the abstracts of the different models based on the above two aspects, from 1 to 5, with higher scores representing the more the resulting abstracts met the two evaluation metrics. Finally, the average value is taken as the final score of the manual evaluation of the model.
The model is evaluated comprehensively using both automatic and manual evaluations. to ensure the quality of the model-generated abstracts.
4.3. Comparison with Public Models
4.3.1. Results on the Dataset CNN/DailyMail
On the CNN/DailyMail dataset, we compare the model with the following publicly available models.
TextRank [
35]: a graph-based ranking algorithm for keyword extraction and document summarization, improved from the PageRank algorithm. It extracts keywords using co-occurrence information (semantics) between words within a document, and can extract keywords, key phrases of a given text from that text, and key sentences of that text using an extractive automatic digest method.
Seq2seq + attention [
19]: a standard sequence-to-sequence model with an attention mechanism for generating summaries.
PGN [
36]: to solve the problem of words that do not appear in the word list, a pointer generation network is proposed.
PGN + Cov [
36]: an overlay mechanism is added to the pointer generation network to avoid duplication of the generated summaries.
FASum + FC [
37]: a knowledge graph is used to represent the factual information extracted from the article and a factual corrector model is used to correct factual errors.
ML + RL, intra-attention [
18]: introduces a new internal attention mechanism that combines the standard supervised word prediction and reinforcement learning training methods to reduce bias.
ML + RL Rouge + Novel, with LM [
29]: the decoder is divided into a contextual network and a pre-trained language model, and reinforcement learning is used to encourage the generation of new phrases.
Lightweight Meta-Learning [
38]: a low-resource generative summary model using meta-learning and lightweight modules. Effectively mitigates domain transfer and overfitting problems.
DEATS [
39]: proposes a dual-coding model that mutually benefits from the basic model and achieves state-of-the-art results compared to existing methods.
BERTSumABS [
40]: the pre-trained BERTSum is used as the encoder and the 6-layer Transformer [
20] is used as the decoder. In addition, a new fine-tuning scheme is proposed to separate the optimizers of the codecs.
TransformerS2S + CS + RL [
41]: an FCSF-TABS-based model is proposed, where Bert is fine-tuned for content selection in the first stage and fed into the Transformer-based summary model in the second stage to generate summary sentences.
Table 1 shows the results of comparing the model in this paper with existing models. It can be seen that JPATS outperforms most publicly available models. Compared with ML + RL, intra-attention and ML + RL Rouge + Novel, with LM, which introduced reinforcement learning, JPATS improved in all three Rouge metrics, which we attribute to the joint-attention mechanism and a priori knowledge, and we will further demonstrate our idea with ablation experiments later. It is worth noting that JPATS is slightly less effective than the models BERTSumABS, TransformerS2S + CS + RL, which incorporate Bert and Transformer, reflecting the significant effect of the pre-trained models. We will further focus on the pre-trained model and migrate the methods in this paper to the pre-trained model to obtain better results.
Table 2 shows the results of the manual evaluation of each model. Our model achieved the highest scores on both readability and general. The presence of a priori knowledge in the JPATS model is shown to help the decoder generate summaries that conform to human reading habits and improve the readability of the summaries. In addition, the model not only requires the decoder to focus on the keywords in the source text, but also forces the decoder to focus on the sentences where the keywords are located, and the combination of the two drives the model to generate more comprehensive and specific summaries. Thus, our model is also superior in the two manual evaluation metrics of readability and general. Combining Rouge evaluation metrics and manual evaluation, our model achieves good results.
4.3.2. Results on the Dataset DUC 2004
On the DUC 2004 dataset, we compared the model with the following publicly available models.
ABS [
14]: a CNN encoder and an NNLM decoder are used to accomplish the summarization task.
ABS + [
14]: an enhanced version of the ABS model, which relies on a series of individually extracted summary features that are added as log-linear features in the secondary learning step.
RAS-Elman [
15]: using an attentive encoder and RNN-based decoder.
SEASS [
12]: a selection mechanism is used to control the information input to the decoder to remove redundant information.
DEATS [
39]: a dual-coding model is proposed that mutually benefits from the basic model and achieves state-of-the-art results compared to existing methods.
Table 3 shows the results of comparing the model in this paper with existing models. As shown in the table, our models all outperformed all baseline models. It reached 29.98, 9.80, and 26.12 on Rouge-1, Rouge-2, and Rouge-L, respectively. Experiments on this dataset further demonstrate the performance of the model in this paper.
5. Discussion
To examine the function of each module in the overall model, we ran corresponding ablation experiments on the model. One or two modules are removed based on the experiment. After the WS, PK, JAM, and RL modules are removed, the fundamental model is JPATS _w/o_ALL. The PGN + Cov model in
Table 1 is now identical to JPATS _w/o_ALL.
The WS module of this model is intended to determine whether the hidden vectors generated by Bi-GRU deviate from the meaning of the original text and can assign higher weights to the important parts of the original text. In
Table 4, we obtain the scores of the model without the WS module, and the results show that the scores are slightly worse than the original JPATS model. Again, the model with the JAM, PK, and RL modules removed scored slightly higher compared to the model with all modules removed. After comparing the two data, it is proved that the WS module plays the role of judging the matching and assigning weights in the model.
The JAM module uses a joint-attention mechanism that is a fusion of the word-level attention mechanism and sentence-level attention mechanism. The joint-attention mechanism is computed separately with the state of the decoder at each moment, so that the model pays attention to both the keyword and the sentence in which the keyword is located. The captured word-level features and sentence-level features help the decoder to improve the quality of the generated summaries. In the absence of the JAM module, the Rouge score decreases by 0.88, 0.28, and 0.39, respectively. This shows that the JAM module helps the model to consider richer information and improve model performance. In addition, the Rouge score decreases more compared to the score after removing the WS module, indicating a more pronounced effect of the JAM module.
The PK module mimics the human habit of combining background knowledge when reading, and uses the original semantic information without any training to give the model more original information, prompting the generation of summaries that are more in line with human reading habits. After removing the PK model, the Rouge score of the model showed a decrease. The scores still decreased compared to the model with the WS module removed, indicating that the PK module outperformed the WS module for the summary generation task.
Based on previous studies on reinforcement learning, it is effective in improving Rouge scores. For this experiment, we also remove the RL module separately to study it. Removing the RL module resulted in a larger decrease in model scores than the model with the remaining modules removed, and we obtained the same conclusion as in previous studies. The effectiveness of the RL module for improving Rouge scores can also be derived from the scores of the model with JAM + PK removed and the model with JAM + PK + RL removed.
6. Conclusions
In this paper, we propose an abstractive summarization model based on the joint-attention mechanism and a priori knowledge. On the encoding side, we incorporate a weighted summation part to determine how well the encoder produces vectors that match the original text on the one hand, and assign higher weights to important parts on the other. On the decoding side, we first improve the pointer network using the word–sentence-level joint-attention mechanism to make the decoder focus on the keywords and the sentences where the keywords are located. The original text vector without any training is then used as a priori knowledge to further improve the pointer network to generate a summary that matches human reading habits. Finally, reinforcement learning is introduced to alleviate the exposure bias problem and optimize the evaluation metrics. After experimenting on two publicly available datasets, we find that the model in this paper shows good results compared with existing publicly available models.
Although the model in this paper achieved good results, some other problems were found in the text summary exploration phase: (1) Rouge, a commonly used evaluation metric in the field of text summarization, itself judges the degree of matching between the generated summary and the reference summary, ignoring the evaluation of coherence, conciseness, etc. The introduction of manual evaluation can be time-consuming and labor-intensive for large amounts of data. Therefore, effective improvement of evaluation indicators is crucial for both Chinese and English abstract studies. (2) The uninterpretability of deep learning also hinders the development of the text summarization field to some extent. (3) Whether the introduction of pre-trained models will further improve the model quality. In the future, we will further explore research from the above three points.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}